- MongoDB + Voyage AI 详解:重塑数据库与AI的协同范式
csdn_tom_168
NoSQL数据库mongodb人工智能AI
MongoDB+VoyageAI详解:重塑数据库与AI的协同范式2025年2月,MongoDB官方宣布收购VoyageAI,这一举措标志着数据库与人工智能技术的深度融合迈入新阶段。通过整合VoyageAI的先进AI检索与嵌入模型能力,MongoDB旨在重新定义AI时代的数据库架构,为企业构建智能应用提供端到端的数据基础设施。一、收购背景与技术战略1.行业趋势驱动AI数据挑战:随着生成式AI与大语言
- HarmonyOS5.0仓颉引擎与盘古大模型:个性化作业批改系统架构设计与实现
H老师带你学鸿蒙
系统架构HarmonyOS5.0鸿蒙华为仓颉教育
人工智能与边缘计算的融合正在重塑教育评价体系。本文将展示如何基于HarmonyOS5.0仓颉并发引擎和盘古大模型,构建新一代智能作业批改系统。系统架构全景graphTDA[学生端设备]-->|提交作业|B[仓颉边缘处理]B-->C[盘古大模型分析]C-->D[个性化反馈生成]D-->E[学生终端]D-->F[教师仪表盘]subgraphHarmonyOS分布式系统B-->|设备协同|G[教室平板集
- 阿里云瑶池数据库 Data Agent for Meta 正式发布,让 AI 更懂你的业务!
数据库观点资讯人工智能
背景随着生成式人工智能(GenerativeAI)从概念验证迈向规模化商业落地,AIAgent已成为企业核心业务流程的重要组成部分。然而,当模型调用日益便捷时,核心痛点已不再是模型本身,而是集中在一个关键要素上:数据。AIAgent的落地瓶颈已从技术能力转向高质量、高相关性、安全合规的数据供给。企业面临的核心挑战在于:数据孤岛导致知识库分散,通用大模型难以理解专业业务传统数据管理依赖人工开发维护,
- 【TVM 教程】如何处理 TVM 报错
ApacheTVM是一个深度的深度学习编译框架,适用于CPU、GPU和各种机器学习加速芯片。更多TVM中文文档可访问→https://tvm.hyper.ai/运行TVM时,可能会遇到如下报错:---------------------------------------------------------------AnerroroccurredduringtheexecutionofTVM.F
- 【PaddleOCR】OCR文本检测与文本识别数据集整理,持续更新......
博主简介:曾任某智慧城市类企业算法总监,目前在美国市场的物流公司从事高级算法工程师一职,深耕人工智能领域,精通python数据挖掘、可视化、机器学习等,发表过AI相关的专利并多次在AI类比赛中获奖。CSDN人工智能领域的优质创作者,提供AI相关的技术咨询、项目开发和个性化解决方案等服务,如有需要请站内私信或者联系任意文章底部的的VX名片(ID:xf982831907)博主粉丝群介绍:①群内初中生、
- 多模态大模型的技术应用与未来展望:重构AI交互范式的新引擎
zhaoyi_he
重构人工智能
一、引言:为什么多模态是AI发展的下一场革命?过去十年,深度学习推动了计算机视觉和自然语言处理的飞跃,但两者的发展路径长期割裂。随着生成式AI和大模型时代的到来,**多模态大模型(MultimodalFoundationModels)**以统一的建模方式处理图像、文本、音频、视频等多源数据,重塑了“感知-认知-决策”链条,为AGI迈出关键一步。OpenAI的GPT-4o、Google的Gemini
- 使用 C++ 实现 MFCC 特征提取与说话人识别系统
whoarethenext
c++开发语言mfcc语音识别
使用C++实现MFCC特征提取与说话人识别系统在音频处理和人工智能领域,C++凭借其卓越的性能和对硬件的底层控制能力,在实时音频分析、嵌入式设备和高性能计算场景中占据着不可或缺的地位。本文将引导你了解如何使用C++库计算核心的音频特征——梅尔频率倒谱系数(MFCCs),并进一步利用这些特征构建一个说话人识别(声纹识别)系统。Part1:在C/C++中计算MFCCs直接从零开始实现MFCC的所有计算
- ImportError: /nvidia/cusparse/lib/libcusparse.so.12: undefined symbol: __nvJitLinkComplete_12_4
爱编程的喵喵
Python基础课程pythonImportErrortorchnvJitLink解决方案
大家好,我是爱编程的喵喵。双985硕士毕业,现担任全栈工程师一职,热衷于将数据思维应用到工作与生活中。从事机器学习以及相关的前后端开发工作。曾在阿里云、科大讯飞、CCF等比赛获得多次Top名次。现为CSDN博客专家、人工智能领域优质创作者。喜欢通过博客创作的方式对所学的知识进行总结与归纳,不仅形成深入且独到的理解,而且能够帮助新手快速入门。 本文主要介绍了ImportError:/home/
- 【机器学习&深度学习】多分类评估策略
一叶千舟
深度学习【理论】深度学习【应用必备常识】大数据人工智能
目录前言一、多分类3大策略✅宏平均(MacroAverage)✅加权平均(WeightedAverage)✅微平均(MicroAverage)二、类比理解2.1宏平均(MacroAverage)2.1.1计算方式2.1.2适合场景2.1.3宏平均不适用的场景2.1.4宏平均一般用在哪些指标上?2.1.5怎么看macroavg指标?2.1.6宏平均值低说明了什么?2.1.7从宏平均指标中定位模型短板
- 网络安全相关专业总结(非常详细)零基础入门到精通,收藏这一篇就够了
网络安全工程师教学
兼职副业黑客技术网络安全web安全安全人工智能网络运维
一、网络工程专业专业内涵网络工程是指按计划进行的以工程化的思想、方式、方法,设计、研发和解决网络系统问题的工程,一般指计算机网络系统的开发与构建。该专业培养具备计算机科学与技术学科理论基础,掌握网络技术领域专业知识和基本技能,在计算机、网络及人工智能领域的工程实践和应用方面受到良好训练,具有深厚通信背景、可持续发展、能力较强的高水平工程技术人才。学生可在计算机软硬件系统、互联网、移动互联网及新一代
- 大语言模型应用指南:ReAct 框架
AI大模型应用实战
javapythonjavascriptkotlingolang架构人工智能
大语言模型应用指南:ReAct框架关键词:大语言模型,ReAct框架,自然语言处理(NLP),模型融合,多模态学习,深度学习,深度学习框架1.背景介绍1.1问题由来近年来,深度学习技术在自然语言处理(NLP)领域取得了显著进展。尤其是大语言模型(LargeLanguageModels,LLMs),如BERT、GPT系列等,通过在大规模无标签数据上进行预训练,获得了强大的语言理解和生成能力。然而,预
- 大语言模型原理基础与前沿 基于语言反馈进行微调
AI天才研究院
计算AI大模型企业级应用开发实战AI人工智能与大数据计算科学神经计算深度学习神经网络大数据人工智能大型语言模型AIAGILLMJavaPython架构设计AgentRPA
大语言模型原理基础与前沿基于语言反馈进行微调作者:禅与计算机程序设计艺术/ZenandtheArtofComputerProgramming1.背景介绍1.1问题的由来随着深度学习技术的飞速发展,自然语言处理(NLP)领域取得了显著的进展。大语言模型(LargeLanguageModels,LLMs)如GPT-3、BERT等在各项NLP任务上取得了令人瞩目的成绩。然而,如何进一步提高大语言模型的理
- 《北京市加快推动“人工智能+医药健康“创新发展行动计划(2025-2027年)》深度解读
引言随着新一轮科技革命和产业变革的深入推进,人工智能技术与医药健康的深度融合已成为全球科技创新的重要方向。北京市于2025年7月正式发布《北京市加快推动"人工智能+医药健康"创新发展行动计划(2025-2027年)》,旨在充分发挥北京在人工智能技术策源、头部医疗资源汇聚、健康数据高度富集等方面的突出优势,构建形成"人工智能+医药健康"创新和应用并举的产业生态体系,打造具有国际影响力的创新策源地、应
- 「源力觉醒 创作者计划」_文心大模型开源:开启 AI 新时代的大门
小黄编程快乐屋
人工智能
在人工智能的浩瀚星空中,大模型技术宛如一颗璀璨的巨星,照亮了无数行业前行的道路。自诞生以来,大模型凭借其强大的语言理解与生成能力,引发了全球范围内的技术变革与创新浪潮。百度宣布于6月30日开源文心大模型4.5系列,这一消息如同一颗重磅炸弹,在AI领域掀起了惊涛骇浪,其影响之深远,意义之重大,足以改写行业的发展轨迹。百度这次放大招,直接把文心大模型4.5开源了,这操作就像往国内AI圈子里空投了一个超
- 四种微调技术详解:SFT 监督微调、LoRA 微调、P-tuning v2、Freeze 监督微调方法
当谈到人工智能大语言模型的微调技术时,我们进入了一个令人兴奋的领域。这些大型预训练模型,如GPT-3、BERT和T5,拥有卓越的自然语言处理能力,但要使它们在特定任务上表现出色,就需要进行微调,以使其适应特定的数据和任务需求。在这篇文章中,我们将深入探讨四种不同的人工智能大语言模型微调技术:SFT监督微调、LoRA微调方法、P-tuningv2微调方法和Freeze监督微调方法。第一部分:SFT监
- 2023年搜索领域的技术认证与职业发展指南
搜索引擎技术
搜索引擎ai
2023年搜索领域的技术认证与职业发展指南关键词搜索领域、技术认证、职业发展、搜索引擎技术、人工智能搜索摘要本指南旨在为搜索领域的从业者和有志于进入该领域的人士提供全面的技术认证与职业发展参考。首先介绍搜索领域的概念基础,包括其历史发展和关键问题。接着阐述相关理论框架,分析不同认证背后的原理。架构设计部分展示搜索系统的组成与交互。实现机制探讨算法复杂度和代码优化。实际应用部分给出实施和部署策略。高
- 探索AI人工智能医疗NLP实体识别系统的架构设计
AI学长带你学AI
人工智能自然语言处理easyuiai
探索AI人工智能医疗NLP实体识别系统的架构设计关键词:人工智能、医疗NLP、实体识别、系统架构、深度学习、自然语言处理、医疗信息化摘要:本文将深入探讨医疗领域NLP实体识别系统的架构设计。我们将从基础概念出发,逐步解析医疗文本处理的特殊性,详细介绍实体识别技术的核心原理,并通过实际案例展示如何构建一个高效可靠的医疗实体识别系统。文章还将探讨当前技术面临的挑战和未来发展方向,为医疗AI领域的从业者
- AI智能体原理及实践:从概念到落地的全链路解析
you的日常
人工智能大语言模型人工智能机器学习深度学习神经网络自然语言处理
AI智能体正从实验室走向现实世界,成为连接人类与数字世界的桥梁。它代表了人工智能技术从"知"到"行"的质变,是能自主感知环境、制定决策、执行任务并持续学习的软件系统。在2025年,AI智能体已渗透到智能家居、企业服务、医疗健康、教育和内容创作等领域,展现出强大的生产力与创造力。然而,其发展也伴随着技术挑战、伦理困境和安全风险,需要从架构设计到落地应用的全链条思考与平衡。一、AI智能体的核心定义与技
- 人工智能动画展示人类的特征
AGI大模型与大数据研究院
AI大模型应用开发实战javapythonjavascriptkotlingolang架构人工智能
人工智能,动画,人类特征,情感识别,行为模拟,机器学习,深度学习,自然语言处理1.背景介绍人工智能(AI)技术近年来发展迅速,已渗透到生活的方方面面。从智能语音助手到自动驾驶汽车,AI正在改变着我们的世界。然而,尽管AI技术取得了令人瞩目的成就,但它仍然难以完全模拟人类的复杂行为和特征。人类的特征是多方面的,包括情感、认知、社交和创造力等。这些特征是人类区别于其他生物的重要标志,也是人类社会文明发
- 深度学习篇---简单果实分类网络
下面我将提供一个使用Python从零实现果实分类模型的完整流程,包括数据准备、模型构建、训练和部署,不依赖任何深度学习框架,仅使用NumPy进行数值计算。1.数据准备与预处理首先需要准备果实图像数据集,将其分为好果和坏果两类,并进行预处理:importosimportnumpyasnpfromPILimportImagefromsklearn.model_selectionimporttrain_
- Python深度学习:3步实现AI人脸识别,效果堪比专业软件!
小筱在线
python人工智能python深度学习
引言:AI人脸识别的时代已经到来在当今数字化时代,人脸识别技术已经从科幻电影走进了我们的日常生活。从手机解锁到机场安检,从银行身份验证到智能门禁系统,这项技术正以前所未有的速度改变着我们的生活方式。而令人振奋的是,借助Python和深度学习技术,普通人也能构建出专业级的人脸识别系统。本文将带领您通过三个关键步骤,使用Python深度学习技术实现一个准确率高达99%的人脸识别系统。这个系统不仅原理简
- Spring AI 第二讲 之 Chat Model API 第八节ZhiPu AI Chat
疼死老夫了
人工智能
SpringAI支持知普人工智能的各种人工智能语言模型。您可以与知普人工智能语言模型互动,并基于知普人工智能模型创建多语言对话助手。先决条件您需要与ZhiPuAI创建一个API,以访问ZhiPuAI语言模型。在ZhiPuAI注册页面创建账户,并在APIKeys页面生成令牌。SpringAI项目定义了一个名为spring.ai.zhipuai.api-key的配置属性,你应将其设置为从APIKeys
- Chat Model API
虾条_花吹雪
SpringAIjava
聊天模型API为开发人员提供了将人工智能聊天完成功能集成到应用程序中的能力。它利用预训练的语言模型,如GPT(生成预训练转换器),以自然语言对用户输入生成类似人类的响应。API通常通过向人工智能模型发送提示或部分对话来工作,然后人工智能模型根据其训练数据和对自然语言模式的理解生成对话的完成或继续。然后将完成的响应返回给应用程序,应用程序可以将其呈现给用户或用于进一步处理。Spring人工智能聊天模
- 【推荐算法课程二】推荐算法介绍-深度学习算法
盒子6910
运维视角下的广告业务算法推荐算法深度学习运维开发运维人工智能
三、深度学习在推荐系统中的应用3.1深度学习推荐模型的演化关系图3.2AutoRec——单隐层神经网络推荐模型3.2.1AutoRec模型的基本原理AutoRec模型是一个标准的自编码器,它的基本原理是利用协同过滤中的共现矩阵,完成物品向量或者用户向量的自编码。再利用自编码的结果得到用户对物品的预估评分,进而进行推荐排序。什么是自编码器?自编码器是指能够完成数据“自编码”的模型。无论是图像、音频,
- 巅峰对决,超三十万奖金等你挑战!第十届信也科技杯全球AI算法大赛火热开赛!
中杯可乐多加冰
前沿资讯分享科技人工智能算法计算机视觉机器学习深度学习
信也科技今年跟IJCAI和CIKM这两大全球顶级AI会议合作,这场比赛被全球人工智能顶会CIKM收录为官方赛事单元,获奖选手有机会全球人工智能顶会创造更大的影响力。一、赛事概况随着深度伪造技术的高度发展,人工智能产业走深向实,生成合成技术开始呈现工具化和普及化趋势。在生成合成内容质量显著提升的当下,基于换脸攻击的身份冒用和欺诈事件在全球范围内激增,严重威胁个人隐私和公共数据安全。第十届信也科技杯全
- 【AI智能推荐系统】第二篇:深度学习在推荐系统中的架构设计与优化实践
DeepFaye
人工智能深度学习
第二篇:深度学习在推荐系统中的架构设计与优化实践提示语:“从Wide&Deep到Transformer,深度推荐模型如何突破性能瓶颈?本文将揭秘Netflix、淘宝都在用的深度学习推荐架构,手把手教你设计高精度推荐系统!”目录深度学习推荐系统的核心优势主流深度学习推荐架构解析2.1Wide&Deep模型2.2DeepFM与xDeepFM2.3神经协同过滤(NCF)2.4基于Transformer的
- OPENAI中Assistants API的实现原理及示例代码python实现
dzend
aigcpythonai
OPENAI中AssistantsAPI的实现原理及示例代码前言OPENAI是一家人工智能公司,致力于研究和开发人工智能技术。其中,AssistantsAPI是OPENAI推出的一项人工智能服务,可以帮助开发者快速构建智能助手。本文将介绍AssistantsAPI的实现原理,并提供使用Python实现的示例代码。AssistantsAPI实现原理AssistantsAPI的实现原理主要包括以下几个
- 【深度学习】神经网络剪枝方法的分类
烟锁池塘柳0
机器学习与深度学习深度学习神经网络剪枝
神经网络剪枝方法的分类摘要随着深度学习模型,特别是大语言模型(LLM)的参数量爆炸式增长,模型的部署和推理成本变得异常高昂。如何在保持模型性能的同时,降低其计算和存储需求,成为了工业界和学术界的核心议题。神经网络剪枝(Pruning)作为模型压缩的关键技术之一,应运而生。本文将解析剪枝技术的不同分类,深入探讨其原理、优缺点。文章目录神经网络剪枝方法的分类摘要1为什么我们需要剪枝?2分类方法一:剪什
- Python 图像分类入门
超龄超能程序猿
机器学习python分类开发语言
一、介绍图像分类作为深度学习的基础任务,旨在将输入图像划分到预定义的类别集合中。在实际的业务中,图像分类技术是比较常用的一种技术技能。例如,在安防监控中,可通过图像分类识别异常行为;在智能交通系统中,实现对交通标志和车辆类型的快速识别等。本文将通过安装包已有数据带你逐步了解使用Python进行图像分类的全过程。二、环境搭建在开始图像分类项目前,需要确保Python环境中安装了必要的库。主要包括:T
- 初始CNN(卷积神经网络)
超龄超能程序猿
机器学习cnn人工智能神经网络
卷积神经网络(ConvolutionalNeuralNetwork,简称CNN)作为深度学习的重要分支,在图像识别、目标检测、语义分割等领域大放异彩。无论是手机上的人脸识别解锁,还是自动驾驶汽车对道路和行人的识别,背后都离不开CNN的强大能力一、CNN诞生的背景与意义在CNN出现之前,传统的图像识别方法主要依赖人工提取特征,例如使用SIFT(尺度不变特征变换)、HOG(方向梯度直方图)等算法。这些
- JVM StackMapTable 属性的作用及理解
lijingyao8206
jvm字节码Class文件StackMapTable
在Java 6版本之后JVM引入了栈图(Stack Map Table)概念。为了提高验证过程的效率,在字节码规范中添加了Stack Map Table属性,以下简称栈图,其方法的code属性中存储了局部变量和操作数的类型验证以及字节码的偏移量。也就是一个method需要且仅对应一个Stack Map Table。在Java 7版
- 回调函数调用方法
百合不是茶
java
最近在看大神写的代码时,.发现其中使用了很多的回调 ,以前只是在学习的时候经常用到 ,现在写个笔记 记录一下
代码很简单:
MainDemo :调用方法 得到方法的返回结果
- [时间机器]制造时间机器需要一些材料
comsci
制造
根据我的计算和推测,要完全实现制造一台时间机器,需要某些我们这个世界不存在的物质
和材料...
甚至可以这样说,这种材料和物质,我们在反应堆中也无法获得......
- 开口埋怨不如闭口做事
邓集海
邓集海 做人 做事 工作
“开口埋怨,不如闭口做事。”不是名人名言,而是一个普通父亲对儿子的训导。但是,因为这句训导,这位普通父亲却造就了一个名人儿子。这位普通父亲造就的名人儿子,叫张明正。 张明正出身贫寒,读书时成绩差,常挨老师批评。高中毕业,张明正连普通大学的分数线都没上。高考成绩出来后,平时开口怨这怨那的张明正,不从自身找原因,而是不停地埋怨自己家庭条件不好、埋怨父母没有给他创造良好的学习环境。
- jQuery插件开发全解析,类级别与对象级别开发
IT独行者
jquery开发插件 函数
jQuery插件的开发包括两种: 一种是类级别的插件开发,即给
jQuery添加新的全局函数,相当于给
jQuery类本身添加方法。
jQuery的全局函数就是属于
jQuery命名空间的函数,另一种是对象级别的插件开发,即给
jQuery对象添加方法。下面就两种函数的开发做详细的说明。
1
、类级别的插件开发 类级别的插件开发最直接的理解就是给jQuer
- Rome解析Rss
413277409
Rome解析Rss
import java.net.URL;
import java.util.List;
import org.junit.Test;
import com.sun.syndication.feed.synd.SyndCategory;
import com.sun.syndication.feed.synd.S
- RSA加密解密
无量
加密解密rsa
RSA加密解密代码
代码有待整理
package com.tongbanjie.commons.util;
import java.security.Key;
import java.security.KeyFactory;
import java.security.KeyPair;
import java.security.KeyPairGenerat
- linux 软件安装遇到的问题
aichenglong
linux遇到的问题ftp
1 ftp配置中遇到的问题
500 OOPS: cannot change directory
出现该问题的原因:是SELinux安装机制的问题.只要disable SELinux就可以了
修改方法:1 修改/etc/selinux/config 中SELINUX=disabled
2 source /etc
- 面试心得
alafqq
面试
最近面试了好几家公司。记录下;
支付宝,面试我的人胖胖的,看着人挺好的;博彦外包的职位,面试失败;
阿里金融,面试官人也挺和善,只不过我让他吐血了。。。
由于印象比较深,记录下;
1,自我介绍
2,说下八种基本类型;(算上string。楼主才答了3种,哈哈,string其实不是基本类型,是引用类型)
3,什么是包装类,包装类的优点;
4,平时看过什么书?NND,什么书都没看过。。照样
- java的多态性探讨
百合不是茶
java
java的多态性是指main方法在调用属性的时候类可以对这一属性做出反应的情况
//package 1;
class A{
public void test(){
System.out.println("A");
}
}
class D extends A{
public void test(){
S
- 网络编程基础篇之JavaScript-学习笔记
bijian1013
JavaScript
1.documentWrite
<html>
<head>
<script language="JavaScript">
document.write("这是电脑网络学校");
document.close();
</script>
</h
- 探索JUnit4扩展:深入Rule
bijian1013
JUnitRule单元测试
本文将进一步探究Rule的应用,展示如何使用Rule来替代@BeforeClass,@AfterClass,@Before和@After的功能。
在上一篇中提到,可以使用Rule替代现有的大部分Runner扩展,而且也不提倡对Runner中的withBefores(),withAfte
- [CSS]CSS浮动十五条规则
bit1129
css
这些浮动规则,主要是参考CSS权威指南关于浮动规则的总结,然后添加一些简单的例子以验证和理解这些规则。
1. 所有的页面元素都可以浮动 2. 一个元素浮动后,会成为块级元素,比如<span>,a, strong等都会变成块级元素 3.一个元素左浮动,会向最近的块级父元素的左上角移动,直到浮动元素的左外边界碰到块级父元素的左内边界;如果这个块级父元素已经有浮动元素停靠了
- 【Kafka六】Kafka Producer和Consumer多Broker、多Partition场景
bit1129
partition
0.Kafka服务器配置
3个broker
1个topic,6个partition,副本因子是2
2个consumer,每个consumer三个线程并发读取
1. Producer
package kafka.examples.multibrokers.producers;
import java.util.Properties;
import java.util.
- zabbix_agentd.conf配置文件详解
ronin47
zabbix 配置文件
Aliaskey的别名,例如 Alias=ttlsa.userid:vfs.file.regexp[/etc/passwd,^ttlsa:.:([0-9]+),,,,\1], 或者ttlsa的用户ID。你可以使用key:vfs.file.regexp[/etc/passwd,^ttlsa:.: ([0-9]+),,,,\1],也可以使用ttlsa.userid。备注: 别名不能重复,但是可以有多个
- java--19.用矩阵求Fibonacci数列的第N项
bylijinnan
fibonacci
参考了网上的思路,写了个Java版的:
public class Fibonacci {
final static int[] A={1,1,1,0};
public static void main(String[] args) {
int n=7;
for(int i=0;i<=n;i++){
int f=fibonac
- Netty源码学习-LengthFieldBasedFrameDecoder
bylijinnan
javanetty
先看看LengthFieldBasedFrameDecoder的官方API
http://docs.jboss.org/netty/3.1/api/org/jboss/netty/handler/codec/frame/LengthFieldBasedFrameDecoder.html
API举例说明了LengthFieldBasedFrameDecoder的解析机制,如下:
实
- AES加密解密
chicony
加密解密
AES加解密算法,使用Base64做转码以及辅助加密:
package com.wintv.common;
import javax.crypto.Cipher;
import javax.crypto.spec.IvParameterSpec;
import javax.crypto.spec.SecretKeySpec;
import sun.misc.BASE64Decod
- 文件编码格式转换
ctrain
编码格式
package com.test;
import java.io.File;
import java.io.FileInputStream;
import java.io.FileOutputStream;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
- mysql 在linux客户端插入数据中文乱码
daizj
mysql中文乱码
1、查看系统客户端,数据库,连接层的编码
查看方法: http://daizj.iteye.com/blog/2174993
进入mysql,通过如下命令查看数据库编码方式: mysql> show variables like 'character_set_%'; +--------------------------+------
- 好代码是廉价的代码
dcj3sjt126com
程序员读书
长久以来我一直主张:好代码是廉价的代码。
当我跟做开发的同事说出这话时,他们的第一反应是一种惊愕,然后是将近一个星期的嘲笑,把它当作一个笑话来讲。 当他们走近看我的表情、知道我是认真的时,才收敛一点。
当最初的惊愕消退后,他们会用一些这样的话来反驳: “好代码不廉价,好代码是采用经过数十年计算机科学研究和积累得出的最佳实践设计模式和方法论建立起来的精心制作的程序代码。”
我只
- Android网络请求库——android-async-http
dcj3sjt126com
android
在iOS开发中有大名鼎鼎的ASIHttpRequest库,用来处理网络请求操作,今天要介绍的是一个在Android上同样强大的网络请求库android-async-http,目前非常火的应用Instagram和Pinterest的Android版就是用的这个网络请求库。这个网络请求库是基于Apache HttpClient库之上的一个异步网络请求处理库,网络处理均基于Android的非UI线程,通
- ORACLE 复习笔记之SQL语句的优化
eksliang
SQL优化Oracle sql语句优化SQL语句的优化
转载请出自出处:http://eksliang.iteye.com/blog/2097999
SQL语句的优化总结如下
sql语句的优化可以按照如下六个步骤进行:
合理使用索引
避免或者简化排序
消除对大表的扫描
避免复杂的通配符匹配
调整子查询的性能
EXISTS和IN运算符
下面我就按照上面这六个步骤分别进行总结:
- 浅析:Android 嵌套滑动机制(NestedScrolling)
gg163
android移动开发滑动机制嵌套
谷歌在发布安卓 Lollipop版本之后,为了更好的用户体验,Google为Android的滑动机制提供了NestedScrolling特性
NestedScrolling的特性可以体现在哪里呢?<!--[if !supportLineBreakNewLine]--><!--[endif]-->
比如你使用了Toolbar,下面一个ScrollView,向上滚
- 使用hovertree菜单作为后台导航
hvt
JavaScriptjquery.nethovertreeasp.net
hovertree是一个jquery菜单插件,官方网址:http://keleyi.com/jq/hovertree/ ,可以登录该网址体验效果。
0.1.3版本:http://keleyi.com/jq/hovertree/demo/demo.0.1.3.htm
hovertree插件包含文件:
http://keleyi.com/jq/hovertree/css
- SVG 教程 (二)矩形
天梯梦
svg
SVG <rect> SVG Shapes
SVG有一些预定义的形状元素,可被开发者使用和操作:
矩形 <rect>
圆形 <circle>
椭圆 <ellipse>
线 <line>
折线 <polyline>
多边形 <polygon>
路径 <path>
- 一个简单的队列
luyulong
java数据结构队列
public class MyQueue {
private long[] arr;
private int front;
private int end;
// 有效数据的大小
private int elements;
public MyQueue() {
arr = new long[10];
elements = 0;
front
- 基础数据结构和算法九:Binary Search Tree
sunwinner
Algorithm
A binary search tree (BST) is a binary tree where each node has a Comparable key (and an associated value) and satisfies the restriction that the key in any node is larger than the keys in all
- 项目出现的一些问题和体会
Steven-Walker
DAOWebservlet
第一篇博客不知道要写点什么,就先来点近阶段的感悟吧。
这几天学了servlet和数据库等知识,就参照老方的视频写了一个简单的增删改查的,完成了最简单的一些功能,使用了三层架构。
dao层完成的是对数据库具体的功能实现,service层调用了dao层的实现方法,具体对servlet提供支持。
&
- 高手问答:Java老A带你全面提升Java单兵作战能力!
ITeye管理员
java
本期特邀《Java特种兵》作者:谢宇,CSDN论坛ID: xieyuooo 针对JAVA问题给予大家解答,欢迎网友积极提问,与专家一起讨论!
作者简介:
淘宝网资深Java工程师,CSDN超人气博主,人称“胖哥”。
CSDN博客地址:
http://blog.csdn.net/xieyuooo
作者在进入大学前是一个不折不扣的计算机白痴,曾经被人笑话过不懂鼠标是什么,
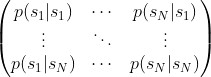
 时刻的状态
时刻的状态  和动作
和动作  发生后,根据一定概率使得状态变为
发生后,根据一定概率使得状态变为  来选择动作
来选择动作 ![\begin{align*}V(s)&=\mathbb{E}[G_t|s_t=s]\\ &=\mathbb{E}[r_{t+1}+{\gamma}G_{t+1}|s_t=s]\\ &=R(s)+\gamma\mathbb{E}[G_{t+1}|s_t=s]\end{align*}](http://img.e-com-net.com/image/info8/da3917c850e543868314f4454f3c153a.gif)
 时刻的回报函数求期望,相当于对
时刻的回报函数求期望,相当于对 
