强化学习课程笔记(二)——马尔科夫决策过程和动态规划寻找最优策略
参考材料
1.强化学习入门课程(英文)https://www.bilibili.com/video/av37295048
2.课程对应知乎讲解https://zhuanlan.zhihu.com/reinforce
3.强化学习(莫烦)https://www.bilibili.com/video/BV13W411Y75P
4.《强化学习入门——从原理到实践》-叶强
第二章 马尔科夫决策过程
当环境状态是完全可观测时,个体可以通过构建马尔科夫决策过程来描述整 个强化学习问题。有时候环境状态并不是完全可观测的,此时个体可以结合自身对于环境的历史观测数据来构建一个近似的完全可观测环境的描述。
2.1马尔科夫性
在一个时序过程中,如果 t + 1 时刻的状态仅取决于 t 时刻的状态 St 而与 t 时刻之前的任何状态都无关时,则认为 t 时刻的状态 St 具有马尔科夫性 (Markov property)。若过程中的每一个状态都具有马尔科夫性,则这个过程具备马尔科夫性。具备了马尔科夫性的随机过程称为马尔科夫过程 (Markov process),又称马尔科夫链 (Markov chain)。
![]()
公式 (2.1) 中的状态转移概率矩阵定义了从任意一个状态 s 到其所有后继状态 s’ 的状态转移概率

其中,矩阵 P 中每一行的数据表示从某一个状态到所有n 个状态的转移概率值。每一行的这些值加起来的和应该为 1。
通常使用一个元组
2.2马尔科夫奖励过程
马尔科夫过程只涉及到状态之间的转移概率,并未触及强化学习问题中伴随着状态转换的奖励反馈。如果把奖励考虑进马尔科夫过程,则成为马尔科夫奖励过程(Markov reward process, MRP)。它是由
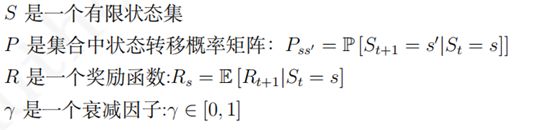
每一个状态旁增加了一个奖励值,表明到达该状态后(或离开该状态时)可以获得的奖励,如此构成了一个学生马尔科夫奖励过程。
收获(return)是一个马尔科夫奖励过程中从某一个状态 St 开始采样直到终止状态时所有奖励的有衰减的之和。数学表达式如下:

价值(value) 是马尔科夫奖励过程中状态收获的期望。数学表达式为:
![]()
![]()
上式中,根据马尔科夫奖励过程的定义,Rt+1 的期望就是其自身,因为每次离开同一个状 态得到的奖励都是一个固定的值。而下一时刻状态价值的期望,可以根据下一时刻状态的概率分布得到。如果用 s′ 表示 s 状态下一时刻任一可能的状态:
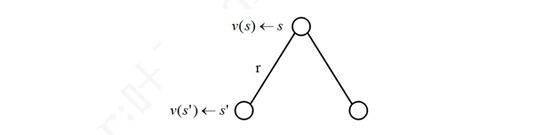
那么上述方程可以写成:
![]()
上式称为马尔科夫奖励过程中的贝尔曼方程(Bellman equation),它提示一个状态的价值 由该状态的奖励以及后续状态价值按概率分布求和按一定的衰减比例联合组成。
2.3马尔科夫决策过程
马尔科夫奖励过程并不能直接用来指导解决强化学习问题,因为它不涉及到个体行为的选 择,因此有必要引入马尔科夫决策过程。马尔科夫决策过程(Markov decision process, MDP)是由

马尔科夫决策过程由于引入了行为,使得状态转移矩阵和奖励函数与之前的马尔科夫奖励 过程有明显的差别。在马尔科夫决策过程中,个体有根据自身对当前状态的认识从行为集中选择 一个行为的权利,而个体在选择某一个行为后其后续状态则由环境的动力学决定。个体在给定状态下从行为集中选择一个行为的依据则称为策略 (policy),用字母 π 表示。策略 π 是某一状态下基于行为集合的一个概率分布:
![]()
当给定一个马尔科夫决策过程:M =
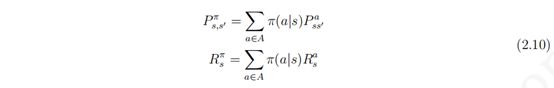
定义:价值函数 vπ(s) 是在马尔科夫决策过程下基于策略 π 的状态价值函数,表示从状态 s 开始,遵循当前策略 π 时所获得的收获的期望:
![]()
同样,由于引入了行为,为了描述同一状态下采取不同行为的价值,我们定义一个基于策略 π 的行为价值函数 qπ(s, a),表示在遵循策略 π 时,对当前状态 s 执行某一具体行为 a 所能的到的收获的期望:
![]()
定义了基于策略 π 的状态价值函数和行为价值函数后,依据贝尔曼方程,我们可以得到如下两个贝尔曼期望方程:
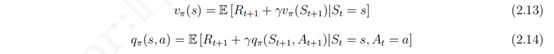
由于行为是连接马尔科夫决策过程中状态转换的桥梁,一个行为的价值与状态的价值关系 紧密。具体表现为一个状态的价值可以用该状态下所有行为价值来表达:
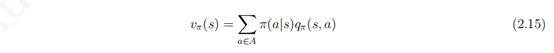
类似的,一个行为的价值可以用该行为所能到达的后续状态的价值来表达:
![]()
结合可得:
![]()
![]()
解决强化学习问题意味着要寻找一个最优的策略让个体在与环境交互过程中获得始终比其 它策略都要多的收获,这个最优策略用 π表示。一旦找到这个最优策略 π,那么就意味着该强化学习问题得到了解决。寻找最优策略是一件比较困难的事情,但是可以通过比较两个不同策略的优劣来确定一个较好的策略。
定义:最优状态价值函数(optimal value function)是所有策略下产生的众多状态价值函数中的最大者:
![]()
定义:最优行为价值函数(optimal action-value function)是所有策略下产生的众多行为价值函数中的最大者:
![]()
定义:策略 π 优于 π′(π ⩾ π′),如果对于有限状态集里的任意一个状态 s,不等式:vπ(s) ⩾ vπ′(s) 成立。
存在如下的结论:1.对于任何马尔科夫决策过程,存在一个最优策略 π* 优于或至少不差于所有其它策略。2.一个马尔科夫决策过程可能存在不止一个最优策略,但最优策略下的状态价值函数均等同于最优状态价值函数:vπ* (s) = v*(s);最优策略下的行为价值函数均等同于最优行为价值函数:qπ*(s, a) = q* (s, a)。
最优策略可以通过最大化最优行为价值函数 q* (s, a) 来获得:

各状态以及相应行为对应的最优价值可以通过回溯法递推计算得到。其中,状态 s 的最优价值可以由下面的贝尔曼最优方程得到:
![]()
上式表示:一个状态的最优价值是该状态下所有行为对应的最优行为价值的最大值。
由于一个行为的奖励和后续状态并不由个体决定,因此在状态 s 时选择行为 a 的最优行为价值将不能使用最大化某一可能的后续状态的价值来计算。它由下面的贝尔曼最优方程得到:
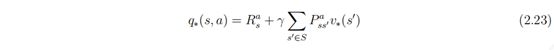
结合2.22和2.23可得:
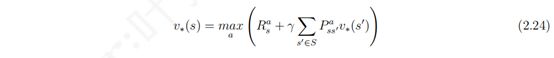
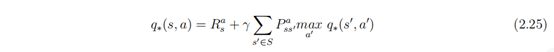
贝尔曼最优方程不是线性方程,无法直接求解,通常采用迭代法来求解,具体有价值迭代、策略迭代、Q 学习、Sarsa 学习等多种迭代方法,后续几章将陆续介绍。
第三章 动态规划寻找最优策略
预测和控制是规划的两个重要内容。预测是对给定策略的评估过程,控制是寻找一个最优策略的过程。对预测和控制的数学描述是这样:
预测 (prediction):已知一个马尔科夫决策过程 MDP
控制 (control):已知一个马尔科夫决策过程 MDP
3.1策略评估
策略评估 (policy evaluation) 指计算给定策略下状态价值函数的过程。对策略评估,我们可以使用同步迭代联合动态规划的算法:从任意一个状态价值函数开始,依据给定的策略,结合贝 尔曼期望方程、状态转移概率和奖励同步迭代更新状态价值函数,直至其收敛,得到该策略下最终的状态价值函数。理解该算法的关键在于在一个迭代周期内如何更新每一个状态的价值。该迭代法可以确保收敛形成一个稳定的价值函数,关于这一点的证明涉及到压缩映射理论。

3.2策略迭代
一般的情况,当给定一个策略 π 时,可以得到基于该策略的价值函数 vπ,基于产生的价值函数可以得到一个贪婪策略 π′ = greedy(vπ)。依据新的策略 π′ 会得到一个新的价值函数,并产生新的贪婪策略,如此重复循环迭代将最终得到最优价值函数 v* 和最优策略 π*。策略在循环迭代中得到更新改善的过程称为策略迭代(policy iteration)。
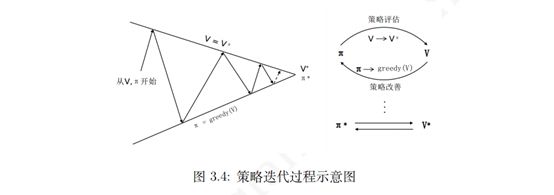



3.3价值迭代
任何一个最优策略可以分为两个阶段,首先该策略要能产生当前状态下的最优行为,其次对于该最优行为到达的后续状态时该策略仍然是一个最优策略。可以反过来理解这句话:如果一个策略不能在当前状态下产生一个最优行为,或者这个策略在针对当前状态的后续状态时不能产生一个最优行为,那么这个策略就不是最优策略。与价值函数对应起来,可以这样描述最优化原则:一个策略能够获得某状态 s 的最优价值当且仅当该策略也同时获得状态 s 所有可能的后续状态 s′ 的最优价值。对于状态价值的最优化原则告诉我们,一个状态的最优价值可以由其后续状态的最优价值通过前一章所述的贝尔曼最优方程来计算:

可以看出价值迭代的目标仍然是寻找到一个最优策略,它通过贝尔曼最优方程从前次迭代 的价值函数中计算得到当次迭代的价值函数,在这个反复迭代的过程中,并没有一个明确的策略参与,由于使用贝尔曼最优方程进行价值迭代时类似于贪婪地选择了最有行为对应的后续状态的价值,因而价值迭代其实等效于策略迭代中每迭代一次价值函数就更新一次策略的过程。需要注意的是,在纯粹的价值迭代寻找最优策略的过程中,迭代过程中产生的状态价值函数不一定对应一个策略。迭代过程中价值函数更新的公式为:
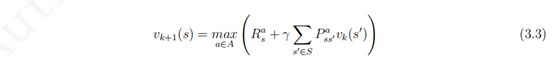
上述公式和图示中,k 表示迭代次数。
其中迭代法策略评估属于预测问题,它使用贝尔曼期望方程来进行求解。策略迭代和价值迭代则属于控制问题,其中前者使用贝尔曼期望方程进行一定次数的价值迭代更新,随后在产生的价值函数基础上采取贪婪选择的策略改善方法形成新的策略,如此交替迭代不断的优化策略;价值迭代则不依赖任何策略,它使用贝尔曼最优方程直接对价值函数进行迭代更新。前文所述的这三类算法均是基于状态价值函数的,其每一次迭代的时间复杂度为 O(mn2),其中 m,n 分别为行为和状态空间的大小。
3.4异步动态规划算法
前文所述的系列算法均为同步动态规划算法,它表示所有的状态更新是同步的。与之对应的还有异步动态规划算法。在这些算法中,每一次迭代并不对所有状态的价值进行更新,而是依据一定的原则有选择性的更新部分状态的价值,这种算法能显著的节约计算资源,并且只要所有状态能够得到持续的被访问更新,那么也能确保算法收敛至最优解。比较常用的异步动态规划思想有:原位动态规划、优先级动态规划、和实时动态规划等。下文将简要叙述各类异步动态规划算法的特点。
原位动态规划 (in-place dynamic programming):与同步动态规划算法通常对状态价值保留一个额外备份不同,原位动态规划则直接利用当前状态的后续状态的价值来更新当前状态的价值。
优先级动态规划 (prioritised sweeping):该算法对每一个状态进行优先级分级,优先级越高的状态其状态价值优先得到更新。通常使用贝尔曼误差来评估状态的优先级,贝尔曼误差被表示为新状态价值与前次计算得到的状态价值差的绝对值。直观地说,如果一个状态价值在更新时变化特别大,那么该状态下次将得到较高的优先级再次更新。这种算法可以通过维护一个优先级队列来较轻松的实现。
实时动态规划 (real-time dynamic programming):实时动态规划直接使用个体与环境交互产生的实际经历来更新状态价值,对于那些个体实际经历过的状态进行价值更新。这样个体经常访问过的状态将得到较高频次的价值更新,而与个体关系不密切、个体较少访问到的状态其价值得到更新的机会就较少。
动态规划算法使用全宽度(full-width)的回溯机制来进行状态价值的更新,也就是说,无论是同步还是异步动态规划,在每一次回溯更新某一个状态的价值时,都要追溯到该状态的所有可能的后续状态,并结合已知的马尔科夫决策过程定义的状态转换矩阵和奖励来更新该状态的价值。这种全宽度的价值更新方式对于状态数在百万级别及以下的中等规模的马尔科夫决策问题还是比较有效的,但是当问题规模继续变大时,动态规划算法将会因贝尔曼维度灾难而无法使用,每一次的状态回溯更新都要消耗非常昂贵的计算资源。为此需要寻找其他有效的算法,这就是后文将要介绍的采样回溯。这类算法的一大特点是不需要知道马尔科夫决策过程的定义,也就是不需要了解状态转移概率矩阵以及奖励函数,而是使用采样产生的奖励和状态转移概率。这类算法通过采样避免了维度灾难,其回溯的计算时间消耗是常数级的。由于这类算法具有非常可观 的优势,在解决大规模实际问题时得到了广泛的应用。