强化学习——马尔科夫决策过程和贝尔曼方程
学习目标
-
Agent和Environment之间的交互过程;
-
理解马尔科夫决策过程(Markov Decision Processes,MDPs)和如何解读转换图;
-
理解值函数(Value Functions)、动作值函数(Action-Value Functions)和决策函数(Policy Functions)
-
理解贝尔曼方程(Bellman Equations)和值函数或者动作值函数的贝尔曼最优方程。
Agent与Environment的交互
对于从交互过程中学习,最终达到目标的这种问题,MDPs旨在建立一种简单直接的框架来描述这种问题,上一节已经简单的说明了Agent与Environment的关系,如下图所示

Agent每完成一个action,就会从environment得到反馈——state和reward。总结起来说,action就是一个任务中agent做出的选择;state是做出选择的基础;reward是评价这个选择做的好不好的基础。
马尔科夫过程(Markov Process,MP)
我们说一个state若满足 ,则其具有马尔可夫性,即该state完全包含了历史中的所有信息。马尔科夫过程是无记忆的随机过程,即随机状态序列 具有马尔可夫属性。
一个马尔科夫过程可以由一个元组组成 ⟨ S , P ⟩ \langle\mathcal{S}, \mathcal{P}\rangle ⟨S,P⟩
- S \mathcal{S} S 为(有限)的状态(state)集;
- P \mathcal{P} P 为状态转移矩阵, P s s ′ = P [ S t + 1 = s ′ ∣ S t = s ] \mathcal{P}_{s s^{\prime}}=\mathbb{P}\left[S_{t+1}=s^{\prime} | S_{t}=s\right] Pss′=P[St+1=s′∣St=s] 。所谓状态转移矩阵就是描述了一个状态到另一个状态发生的概率,所以矩阵每一行元素之和为1。
马尔科夫决策过程(Markov Decision Process,MDP)
MDP相对于MP加入了瞬时奖励 R \mathcal{R} R(Immediate reward)、动作集合 A \mathcal{A} A 和折扣因子 γ \gamma γ(Discount factor),这里的瞬时奖励说的是从一个状态 s s s 到下一个状态 s ′ s^{\prime} s′ 即可获得的rewards,虽然是“奖励”,但如果这个状态的变化对实现目标不利,就是一个负值,变成了“惩罚”,所以reward就是我们告诉agent什么是我们想要得到的,但不是我们如何去得到。
MDP由元组 ⟨ S , A , P , R , γ ⟩ \langle\mathcal{S}, \mathcal{A}, \mathcal{P}, \mathcal{R}, \gamma\rangle ⟨S,A,P,R,γ⟩ 定义。其中
- S \mathcal{S} S 为(有限)的状态(state)集;
- A \mathcal{A} A 为有限的动作集;
- P \mathcal{P} P 为状态转移矩阵。所谓状态转移矩阵就是描述了一个状态到另一个状态发生的概率,所以矩阵每一行元素之和为1。 P s s ′ a = P [ S t + 1 = s ′ ∣ S t = s , A t = a ] \mathcal{P}_{s s^{\prime}}^{a}=\mathbb{P}\left[S_{t+1}=s^{\prime} | S_{t}=s, A_{t}=a\right] Pss′a=P[St+1=s′∣St=s,At=a]
- R \mathcal{R} R 为回报函数(reward function), R s a = E [ R t + 1 ∣ S t = s , A t = a ] \mathcal{R}_{s}^{a}=\mathbb{E}\left[R_{t+1} | S_{t}=s, A_{t}=a\right] Rsa=E[Rt+1∣St=s,At=a]
- γ \gamma γ 为折扣因子,范围在[0,1]之间, 越大,说明agent看得越“远”。
值函数(Value Function)和动作值函数(action-value function)
这里就不得不提一个概念——回报 G t G_{t} Gt (Return),回报 描述了从时间 t t t 起的总折扣奖励,即
G t = R t + 1 + γ R t + 2 + … = ∑ k = 0 ∞ γ k R t + k + 1 G_{t}=R_{t+1}+\gamma R_{t+2}+\ldots=\sum_{k=0}^{\infty} \gamma^{k} R_{t+k+1} Gt=Rt+1+γRt+2+…=k=0∑∞γkRt+k+1
一般来说,我们的任务分两种类型,一种是可以分为一个个episode的任务,我们称之为episodic tasks,这里的折扣因子一般取 γ = 1 \gamma=1 γ=1 ;另一种是连续的任务,与前一种相对应,我们称之为continuing tasks,这时折扣因子一般取0到1之间的一个数。
我们的最终的目标就是让回报的期望(expected return)最大。
我们如何去衡量一个agent转移到一个state对于我们达到目的有“多有用(how good)”呢?上面也提到了,那就是使回报的期望最大,而agent每一步得到的reward与其采取的action有关,所以值函数是在一个(一组)action下定义的,我们称之为策略(policy)。所以 MDP中一个状态s在策略 π \pi π 下的值函数记为 v π ( s ) v_{\pi}(s) vπ(s) ,它代表从s开始的回报的期望。
v π ( s ) = E π [ G t ∣ S t = s ] v_{\pi}(s)=\mathbb{E}_{\pi}\left[G_{t} | S_{t}=s\right] vπ(s)=Eπ[Gt∣St=s]
相似的,我们定义从状态s开始,并执行动作a,然后遵循策略 π \pi π 所获得的回报的期望记为动作值函数(action-value function)
q π ( s , a ) = E π [ G t ∣ S t = t , A t = a ] q_{\pi}(s, a)=\mathbb{E}_{\pi}\left[G_{t} | S_{t}=t, A_{t}=a\right] qπ(s,a)=Eπ[Gt∣St=t,At=a]
我刚接触这两个概念的时候很迷惑,为什么要定义这么两个概念,不就是在状态s多执行了一个动作a么?这样做有什么意义呢?于是我请教了 @咸鱼天,他这样回答道:
这是两个概念,分别是状态价值V(s)和动作价值Q(s,a),前者是对环境中某一个状态的价值大小做的评估,后者是对在某状态下的动作的价值大小的评估。概念类似,但主要区别应该是体现在用途以及算法上吧,比如对于离散型的动作空间,可以单纯基于动作Q值去寻优(DQN算法),如果是动作空间巨大或者动作是连续型的,那么可以判断状态价值并结合策略梯度来迭代优化(AC算法)~
简单来说就是不同场景下我们会选择动作值函数或者状态值函数来寻找最优策略,学到后面就会有更深的体会了。下面学习就带着这个问题思考。
贝尔曼方程(Bellman Equation)
状态值函数可以分解为瞬时回报加上后续状态的折扣值,即
v π ( s ) = E π [ R t + 1 + γ v π ( S t + 1 ) ∣ S t = s ] v_{\pi}(s)=\mathbb{E}_{\pi}\left[R_{t+1}+\gamma v_{\pi}\left(S_{t+1}\right) | S_{t}=s\right] vπ(s)=Eπ[Rt+1+γvπ(St+1)∣St=s]
动作值函数也可以如此分解:
q π ( s , a ) = E π [ R t + 1 + γ q π ( S t + 1 , A t + 1 ) ∣ S t = s , A t = a ] q_{\pi}(s, a)=\mathbb{E}_{\pi}\left[R_{t+1}+\gamma q_{\pi}\left(S_{t+1}, A_{t+1}\right) | S_{t}=s, A_{t}=a\right] qπ(s,a)=Eπ[Rt+1+γqπ(St+1,At+1)∣St=s,At=a]
下面这幅图叫做backup diagrams,其中每一个空心圆圈代表一个状态(state),一个实心的圆圈代表一个状态-动作对(state-action pair)
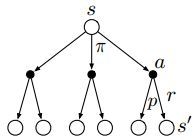
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) q π ( s , a ) v_{\pi}(s)=\sum_{a \in \mathcal{A}} \pi(a | s) q_{\pi}(s, a) vπ(s)=a∈A∑π(a∣s)qπ(s,a)
q π ( s , a ) = R s a + γ ∑ s ′ ∈ S P s s ′ a v π ( s ′ ) q_{\pi}(s, a)=\mathcal{R}_{s}^{a}+\gamma \sum_{s^{\prime} \in \mathcal{S}} \mathcal{P}_{s s^{\prime}}^{a} v_{\pi}\left(s^{\prime}\right) qπ(s,a)=Rsa+γs′∈S∑Pss′avπ(s′)
于是有
v π ( s ) = ∑ a ∈ A π ( a ∣ s ) ( R s a + γ ∑ s ′ ∈ S P s s ′ a v π ( s ′ ) ) v_{\pi}(s)=\sum_{a \in \mathcal{A}} \pi(a | s)\left(\mathcal{R}_{s}^{a}+\gamma \sum_{s^{\prime} \in \mathcal{S}} \mathcal{P}_{s s^{\prime}}^{a} v_{\pi}\left(s^{\prime}\right)\right) vπ(s)=a∈A∑π(a∣s)(Rsa+γs′∈S∑Pss′avπ(s′))
q π ( s , a ) = R s a + γ ∑ s ′ ∈ S P s s ′ a ∑ a ′ ∈ A π ( a ′ ∣ s ′ ) q π ( s ′ , a ′ ) q_{\pi}(s, a)=\mathcal{R}_{s}^{a}+\gamma \sum_{s^{\prime} \in \mathcal{S}} \mathcal{P}_{s s^{\prime}}^{a} \sum_{a^{\prime} \in \mathcal{A}} \pi\left(a^{\prime} | s^{\prime}\right) q_{\pi}\left(s^{\prime}, a^{\prime}\right) qπ(s,a)=Rsa+γs′∈S∑Pss′aa′∈A∑π(a′∣s′)qπ(s′,a′)
上述两个式子分别称为关于 v π ( s ) v_{\pi}(s) vπ(s) 和 q π ( s , a ) q_{\pi}(s, a) qπ(s,a) 的贝尔曼方程,其描述了当前状态值函数和其后续状态值函数之间的关系,即状态值函数(动作值函数)等于瞬时回报的期望加上下一状态的(折扣)状态值函数(动作值函数)的期望。
贝尔曼最优方程(Bellman Optimality Equation)
强化学习的目标是找到一个最优策略,使得回报最大。准确的说是使值函数最大,包括状态值函数和动作值函数,分别记为 v ∗ ( s ) v_{*}(s) v∗(s) 和 q ∗ ( s , a ) q_{*}(s, a) q∗(s,a)
v ∗ ( s ) = max π v π ( s ) v_{*}(s)=\max _{\pi}\ v_{\pi}(s) v∗(s)=πmax vπ(s)
q ∗ ( s , a ) = max π q π ( s , a ) q_{*}(s, a)=\max _{\pi}\ q_{\pi}(s, a) q∗(s,a)=πmax qπ(s,a)
对于任意一个MDPs,总是存在一个最优的策略 π ∗ \pi_{*} π∗ ,在使用这个策略时就能取得最优值函数,即 v π ∗ ( s ) = v ∗ ( s ) v_{\pi_{*}}(s)=v_{*}(s) vπ∗(s)=v∗(s) , q π ∗ ( s , a ) = q ∗ ( s , a ) q_{\pi_{*}}(s, a)=q_{*}(s, a) qπ∗(s,a)=q∗(s,a) ,于是我们可以得到贝尔曼最优方程
v ∗ ( s ) = max a R s a + γ ∑ s ′ ∈ S P s s ′ a v ∗ ( s ′ ) v_{*}(s)=\max _{a} \mathcal{R}_{s}^{a}+\gamma \sum_{s^{\prime} \in \mathcal{S}} \mathcal{P}_{s s^{\prime}}^{a} v_{*}\left(s^{\prime}\right) v∗(s)=amaxRsa+γs′∈S∑Pss′av∗(s′)
q ∗ ( s , a ) = R s a + γ ∑ s ′ ∈ S P s s ′ a max a ′ q ∗ ( s ′ , a ′ ) q_{*}(s, a)=\mathcal{R}_{s}^{a}+\gamma \sum_{s^{\prime} \in \mathcal{S}} \mathcal{P}_{s s^{\prime}}^{a} \max _{a^{\prime}} q_{*}\left(s^{\prime}, a^{\prime}\right) q∗(s,a)=Rsa+γs′∈S∑Pss′aa′maxq∗(s′,a′)
上述贝尔曼最优方程是非线性的,不存在闭式解,常常使用一些迭代的方法求解,比如值迭代、策略迭代、Q-learning、Sarsa等,这就是我们后面要学习的内容了。
学习资料
- Reinforcement Learning: An Introduction- Chapter 3: Finite Markov Decision Processes
- David Silver’s RL Course Lecture 2 - Markov Decision Processes (video, slides)
《Reinforcement Learning: An Introduction 第二版》PDF书籍与David Silver课程,欢迎关注我的公众号“野风同学”,回复“RL”即可获取。
一个程序员的自我成长之路,持续分享机器学习基础与应用、LeetCode面试算法和Python基础与应用等技术干货文章,同时也经常推荐高质量软件工具、网站和书籍。
