第 2 章 马尔可夫决策过程
策略评估
智能体与环境之间的交互,智能体得到环境的状态后,它会采取动作,并把这个采取的动作返还给环境。环境得到智能体的动作后,它会进入下一个状态,把下一个状态传给智能体。
1. 马尔可夫奖励过程
马尔可夫奖励过程(Markov reward process, MRP) 是马尔可夫链加上奖励函数。在马尔可夫奖
励过程中,状态转移矩阵和状态都与马尔可夫链一样,只是多了奖励函数(reward function) 。奖励函数 R 是一个期望,表示当我们到达某一个状态的时候,可以获得多大的奖励。这里另外定义了折扣因子 γ。如果状态数是有限的,那么 R 可以是一个向量。
1)回报与价值函数
回报(return) 是指把奖励进行折扣后所获得的奖励。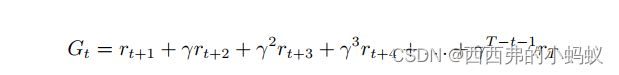
这里有一个折扣因子,越往后得到的奖励,折扣越多。这说明我们更希望得到现有的奖励,对未来的奖励要打折扣。
1.1)定义状态的价值了,就是状态价值函数(state-value function)。
其中, Gt 是之前定义的折扣回报(discounted return) 。我们对 Gt 取了一个期望,期望就是从这个状态开始,我们可能获得多大的价值。
当我们有了一些轨迹的实际回报时,怎么计算它的价值函数呢?
1.2)贝尔曼方程
另外一种计算方法,从价值函数里面推导出贝尔曼方程
贝尔曼方程描述的就是当前状态到未来状态的一个转移
 1.3)计算马尔可夫奖励过程价值的迭代算法
1.3)计算马尔可夫奖励过程价值的迭代算法
可以将迭代的方法应用于状态非常多的马尔可夫奖励过程(large MRP),比如:动态规划的方
法,蒙特卡洛的方法(通过采样的办法计算它), 时序差分学习(temporal-difference learning, TD learning) 的方法(时序差分学习是动态规划和蒙特卡洛方法的一个结合)
2. 马尔可夫决策过程

在当前状态与未来状态转移过程中多了一层决策性,这是马尔可夫决策过程与之前的马尔可夫过程/马尔可夫奖励过程很不同的一点.马尔可夫决策过程,它的中间多了一层动作 a ,即智能体在当前状态的时候,首先要决定采取某一种动作,这样我们会到达某一个黑色的节点
2.1)马尔可夫决策过程中的价值函数



2.2)策略评估
已知马尔可夫决策过程以及要采取的策略 π ,计算价值函数 Vπ(s) 的过程就是策略评估。策略评估在有些地方也被称为(价值)预测 [(value) prediction) ],也就是预测我们当前采取的策略最终会产生多少价值。
例子:

马尔可夫决策过程的不同之处在于有一个智能体控制船,这样我们就可以尽可能多地获得奖励。
贝尔曼方程来得到价值函数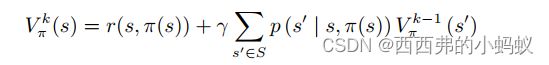

2.3) 预测与控制

在马尔可夫决策过程里面,预测和控制都可以通过动态规划解决。要强调的是,这两者的区别就在于,预测问题是给定一个策略,我们要确定它的价值函数是多少。而控制问题是在没有策略的前提下,我们要确定最佳的价值函数以及对应的决策方案。实际上,这两者是递进的关系,在强化学习中,我们通过解决预测问题,进而解决控制问题
 在控制问题中,问题背景与预测问题的相同,唯一的区别就是:不再限制策略。也
在控制问题中,问题背景与预测问题的相同,唯一的区别就是:不再限制策略。也
就是动作模式是未知的,我们需要自己确定

控制问题要做的就是,给定同样的条件,求出在所有可能的策略下最优的价值函数是什么,最优策略是什么
2.4)动态规划
动态规划(dynamic programming, DP) 适合解决满足最优子结构(optimal substructure) 和
重叠子问题(overlapping subproblem) 两个性质的问题
马尔可夫决策过程是满足动态规划的要求的,在贝尔曼方程里面,我们可以把它分解成递归的结构。
动态规划应用于马尔可夫决策过程的规划问题而不是学习问题,我们必须对环境是完全已知的,才能做动态规划,也就是要知道状态转移概率和对应的奖励。使用动态规划完成预测问题和控制问题的求解,是解决马尔可夫决策过程预测问题和控制问题的非常有效的方式。
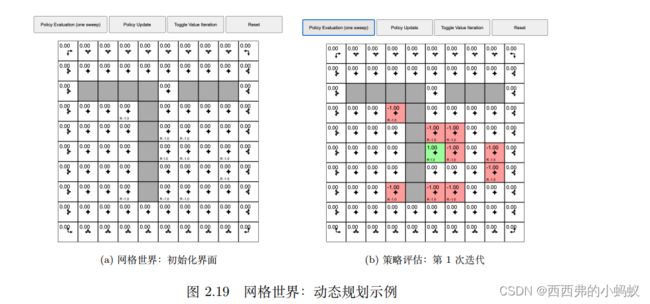
2.5)马尔可夫决策过程中的策略评估
策略评估就是给定马尔可夫决策过程和策略,评估我们可以获得多少价值,即对于当前策略,我们可以得到多大的价值。可以把贝尔曼期望备份转换成动态规划的迭代
策略评估的核心思想就是把如式 (2.39) 所示的贝尔曼期望备份反复迭代,然后得到一个收敛的价值函数的值。



2.6)马尔可夫决策过程控制

策略迭代和价值迭代来解决马尔可夫决策过程的控制问题
2.7)策略迭代
策略迭代由两个步骤组成:策略评估和策略改进(policy improvement)。在初始化的时候,我们有一个初始化的状态价值函数 V 和策略 π ,然后在这两个步骤之间迭代
第一个步骤是策略评估,当前我们在优化策略 π,在优化过程中得到一个最新的策略。我们先保证这个策略不变,然后估计它的价值,即给定当前的策略函数来估计状态价值函数。第二个步骤是策略改进,得到状态价值函数后,我们可以进一步推算出它的 Q 函数。得到 Q 函数后,我们直接对 Q 函数进行最大化,通过在Q 函数做一个贪心的搜索来进一步改进策略。这两个步骤一直在迭代进行。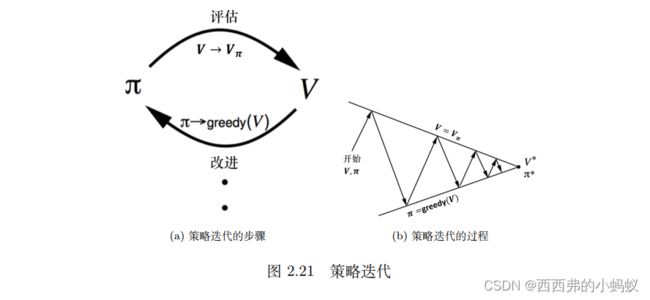
图 2.21b 上面的线就是我们当前状态价值函数的值,下面的线是策略的值。策略迭代的过程与踢皮球一样。我们先给定当前已有的策略函数,计算它的状态价值函数。算出状态价值函数后,我们会得到一个Q 函数。我们对 Q 函数采取贪心的策略,这样就像踢皮球,“踢”回策略。然后进一步改进策略,得到一个改进的策略后,它还不是最佳的策略,我们再进行策略评估,又会得到一个新的价值函数。基于这个新的价值函数再进行 Q 函数的最大化,这样逐渐迭代,状态价值函数和策略就会收敛。
策略改进:状态价值函数后,我们就可以通过奖励函数以及状态转移函数来计算 Q 函数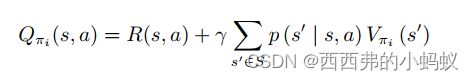
对于每个状态,策略改进会得到它的新一轮的策略,对于每个状态,我们取使它得到最大值的动作,即
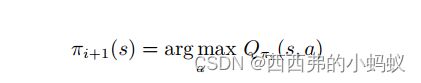

2.8)价值迭代
价值迭代就是把贝尔曼最优方程当成一个更新规则来进行



2.9)马尔可夫决策过程中的预测和控制总结
我们使用动态规划算法来解马尔可夫决策过程里面的预测和控制,并且采取不同的贝尔曼方程。对于预测问题,即策略评估的问题,我们不停地执行贝尔曼期望方程,这样就可以估计出给定的策略,然后得到价值函数。对于控制问题,如果我们采取的算法是策略迭代,使用的就是贝尔曼期望方程;如果我们采取的算法是价值迭代,使用的就是贝尔曼最优方程
总结