这是 MySQL 5.6 全局事务 ID(GTID) 系列的第三篇博客。
在之前的两篇博客中, 第一篇 介绍了全局事务 ID 的定义与数据结构。 第二篇 介绍了 MySQL 5.6 新增的全局事务状态(Gtid_state)。
这里准备介绍的是全局事务 ID 如何参与 MySQL 的主备复制流程。
MySQL 5.6 引入全局事务 ID 的首要目的,是保证 Slave 在复制的时候不会重复执行相同的事务操作;其次,是用全局事务 IDs 代替由文件名和物理偏移量组成的复制位点,定位 Slave 需要复制的 binlog 内容。
因此,MySQL 必须在写 binlog 时记录每个事务的全局 GTID,保证 Master / Slave 可以根据这些 GTID 忽略或者执行相应的事务。在实现上,MySQL 没有修改旧的 binlog 事件,而是新增了两类事件:
+----------------------------+----------------------------------------+
| 名称 | 功能 |
+----------------------------+----------------------------------------+
| Previous_gtids_log_event | 该事件之前的全局事务 ID 集合。 |
+----------------------------+----------------------------------------+
| Gtid_log_event | 标记之后的事务对应的全局事务 ID。 |
+----------------------------+----------------------------------------+
Gtid_log_event
在 MySQL 5.6 的 binlog 文件中,每个事务的开始不是 "BEGIN" ,而是 Gtid_log_event 事件:
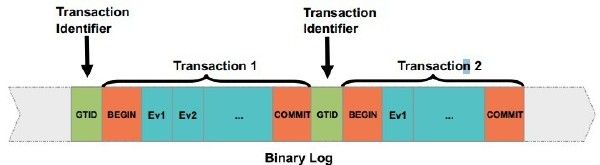
(图片来源: MySQL_Innovation_Day_Replication_HA.pdf)
它里面只包含一条 GTID,记录结构如下:
Gtid_log_event := (commit_flag, sid, gno) // commit_flag 目前总是 true
里面 sid 就是产生该事务的 server_uuid,gno 是顺序编号的 transaction_id。
把 Gtid 记录在事务的开头是为了便于 MySQL 过滤 binlog:检查到某个 Gtid 不需要时,可以直接忽略后面的整段事务。
MySQL 5.6 保证同时写入 Gtid_log_event 和全局 logged_gtids 状态:
第一步,在向 binlog_cache_data 写入第一条 binlog 前,MySQL 会在缓存的 buffer 中写入一个空的 Gtid_log_event 占位。
第二步,当 binlog_cache_data 的内容刷到 binlog 文件时,MySQL 会把位于缓存 buffer 的 Gtid_log_event 内容替换成实际的 GTID,重新写入缓存。
最后,MySQL 调用 Gtid_state 的 update_on_flush() 把 GTID 写入 logged_gtids,再调用 sync_binlog_file() 保证内容更新到磁盘。
在主备复制中,Slave 不像 Master 那样自动产生 GTID,而是直接拷贝 Gtid_log_event 中包含的 GTID。这个特性是这样实现的 —— MySQL 5.6 维护了一个线程(Session)级别的变量 gtid_next,类型为 Gtid_specification:
Gtid_specification := (enum_group_type, Gtid)
enum_group_type :=enum(AUTOMATIC_GROUP, GTID_GROUP, ANONYMOUS_GROUP, INVALID_GROUP, UNDEFINED_GROUP)
在 Master 执行事务时,gtid_next 的类型默认是 AUTOMATIC_GROUP,表示应该调用 generate_automatic_gno() 自动产生全局事务 ID。
而在 Slave 执行事务时,先用 Gtid_log_event 内的 Gtid 覆盖 gtid_next,使它的类型为 GTID_GROUP。这样的话,MySQL 会使用 gtid_next 内设置的 Gtid 值作为下一个全局事务 ID。
Previous_gtids_log_event
这个事件出现在 MySQL 5.6 每个 binlog 文件的开始处。
MySQL 创建一个新的 binlog 文件后,首先写入一个 Format_description_log_event 描述,接着写入一个 Previous_gtids_log_event,内容是在创建这个 binlog 文件之前执行的全局事务 GTIDs。
事件的格式很简单,就是字符串编码的 Gdit_set:(编码格式参考本文 第一篇)
Previous_gtids_log_event := buffer of Gtid_set
(例如:3E11FA47-71CA-11E1-9E33-C80AA9429562:1-5)
这个事件只是作为记录。在主备复制时,Slave 会忽略 binlog 里的 Previous_gtids_log_event 事件。
Binlog 与持久化全局事务状态
在 上一篇 没有讲到 MySQL 5.6 如何持久化全局事务状态的 —— logged_gtids 和 lost_gtids 状态里存储了这台数据库 有史以来 执行的所有 GTIDs(包括删除 binlog 中的 GTIDs)—— 如果数据库停机或崩溃前不做持久化,之后肯定丢失信息。
MySQL 的解决方案很简单,在启动时扫描剩余的 binlog 文件,用文件存储的 Previous_gtids_log_event 和 Gtid_log_event 事件内容恢复全局 logged_gtids 和 lost_gtids 状态。
具体的代码如下:(源代码:mysql-5.6.9-rc\sql\binlog.cc,line 2558)
第一步,找到最后一个 binlog 文件,读出 Previous_gtids_log_event 记录;再遍历 binlog 文件中所有的 Gtid_log_event, 把找到的 GTID 记录合并起来,作为这台数据库历史上执行的所有 GTIDs 放入全局 logged_gtids 记录;
第二步,找到第一个 binlog 文件,用它的 Previous_gtids_log_event 信息代替全局 lost_gtids 的内容。因为这是第一个未删除的 binlog 文件,这里记录的就是之前已经删除的 binlog 文件所包含的全部 GTIDs。
由于 MySQL 在提交事务中是最后才写入真实 Gtid_log_event 信息的,从 binlog 恢复信息,可以保证读到的 GTIDs 与成功执行的事务一致。
CHANGE MASTER TO ...
MySQL 5.6 主备复制的一个改变,是新增了 COM_BINLOG_DUMP_GTID 协议,支持在 Slave 切换到新 Master 时,用 MASTER_AUTO_POSITION = 1 (auto_position 方式)代替原来的 binlog 文件名和物理偏移量。
COM_BINLOG_DUMP_GTID 协议并不复杂,请求格式如下:
Request = { server_id, binlog_name, binlog_offset, gtids_executed }
如果采用 auto_position 方式连接 Master,现在 Slave 发送的 binlog_name 和 binlog_offset 都是空白,Master 只使用 gtids_executed 定位 Slave 上需要执行的 binlog。
实现逻辑是这样的:Master 从第一个文件开始读取 binlog,逐个检查 Gdit_log_event 事件的全局事务 ID 是不是包含在 Slave 发送的 gtids_executed 集合中。如果发现这个 GTID 已经包含在 gtids_executed 集合内,就忽略后面的整段事务,不向 Slave 发送 binlog 内容。
其实这个过程还不是很优化,因为如果是正常情况,Master 需要遍历若干 G 的 binlog 才能找到 Slave 需要复制的 binlog 内容 —— 这应该是一个改进点。
全局事务 ID 与并发复制
MySQL 5.6 主备复制的另一个改变,是实现了多线程并行复制。这个功能必须有全局事务 ID 的支持,原因是:
1) 在并行复制方式下,有些操作是不按照记录在 binlog 中的顺序执行的。这样的话,如果按照文件名 + 物理偏移量的方式记录复制位点,则停止 / 恢复主备复制时,可能会有一些操作被重复执行。
2) 我们知道,即使是 Mixed / Row 模式下记录的 binlog,仍有些 DDL 操作是用 Statement 的方式编码的,这些 DDL 操作不能在 Slave 重复执行(因为非幂等)。一旦操作在 Slave 执行出错,结果就是复制中断。
因此,Slave 必须依赖 binlog 中的全局事务 ID,在停止 / 恢复主备复制时,精确的记录哪些事务在 Slave 执行过,哪些没有。
现在,MySQL 5.6 可以用 COM_BINLOG_DUMP_GTID 来保证这一点:在恢复主备复制时,Slave 向 Master 发送自己所有执行过的 GTIDs(logged_gtids),在上次中断主备复制时,已经执行过的 binlog 被 Master 直接滤掉,不向 Slave 传送。
总结
在主备复制上,MySQL 5.6 新增了三个特性:
1)使用 GTIDs 作为主备复制的位点,在写 binlog 时用 Gtid_log_event 标记事务。
2)支持 auto_position 方式进行主备切换。在新增的协议中,使用 GTIDs 作为复制位点向主库请求 binlog 信息。
3)多线程并发复制,使用 GTIDs 防止事务重复执行。
全局事务 ID(GTID)可以很好的支持这几个功能。而且,使用 GTIDs 避免了在传送 binlog 逻辑上依赖文件名和物理偏移量,能够更好的支持自动容灾切换。
但是个人感觉,全局事务 ID 这里还有些待解决的问题:
1)GTID 是局部有序的,不能记录事务的全局顺序。因此在双写 / 快速主备切换场景下,不能根据 GTID 顺序来解决更新冲突的问题。
2)容灾切换时,MASTER_AUTO_POSITION 只能解决记录位点的问题。为了保证一致性,停写和等待主备 Caught up 仍然是必须的,通常这是服务无法快速恢复的主要原因。
补充:参考资料
这篇博客用到的参考资料:
MySQL 5.6 Manual:Replication with Global Transaction Identifiers( link)
WL#4677: Unique Server Ids for Replication Topology (UUIDs)(link)
WL#3584: Global Transaction Identifiers (GTIDs)( link)
顺便提下, MySQL Worklog 是个好地方,你可以从这里了解 MySQL 的原始需求,开发人员的想法,还有值得关注的问题。