1896-2021历届奥运会奖牌榜(Python数据处理)
阅读本文大约需要 3 分钟
![]()
摘 要

这两天在平台上看到一些创作者失去创作动力的感慨,OF只想说往事如昙花一现,我们都需要时刻静下心来,认真地考虑下自己的创作目标并付诸行动。遥想当年OF做软件系统的时候,开源社区还没有像现在这样健全。再看看如今,衷心感谢创作者们孜孜不倦地分享,建立了一个良好的创作氛围。说不定再写几年,也可以出本书啥的。

主要内容:Excel 办公自动化和数据分析
适用人群:办公室职员 / Python 初学者 / 有志从事数据分析工作的人员
准备内容:Anaconda-Spyder;re、Pandas库
![]()
二、数据处理
言归正传,上篇OF介绍了运用数据爬虫获取到了历届奥运会的奖牌数据
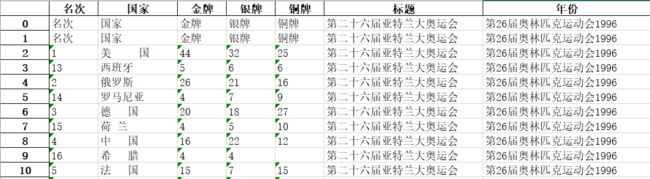
观察下这些数据,先列出需要改善的点:

1、知识点1去掉空格:替换replace()
str.replace(正则式/字符串,替换的目标字符)
#将国家列字符串中的空格都去除
df['国家'].replace('\s+','',regex=True,inplace=True) 2、知识点2删除多列空值的行:删除dropna()
df.dropna(axis=0, how='any', thresh=None, subset=None, inplace=False)参数说明:
- axis:默认为 0,表示逢空值剔除整行,如果设置参数 axis=1 表示逢空值去掉整列。
- how:默认为 'any' 如果一行(或一列)里任何一个数据有出现 NA 就去掉整行,如果设置 how='all' 一行(或列)都是 NA 才去掉这整行。
- thresh:设置需要多少非空值的数据才可以保留下来的。
- subset:设置想要检查的列。如果是多个列,可以使用列名的 list 作为参数。
- inplace:如果设置 True,将计算得到的值直接覆盖之前的值并返回 None,修改的是源数据。
当金牌、银牌、铜牌都为空时,我们可以删除该行,用dropna(thresh=1)就是保留至少1个非空值的数据可以保留,那我们想办法先把其他列数据都置空,再判断每行只要有一个数据就保留
cols=['金牌','银牌','铜牌']
#df[cols]!="" 判断3列数据各是True or False
#df[df[cols]!=""] 呈现所有列数据,只留下3列数据,其他列都置空
#df[df[cols]!=""].dropna(thresh=1).index 保留至少有1个非空值的行集合3、知识点3删除含有XX内容的行:-df[].isin([])
当我们进行数据处理时,最重要的是学会找规律,用最简单的方法实现我们想要达到的效果,比如我们看到的问题是要把奖牌都为中文的行删除,我们同时可以观察到,这些行的名次列都是“名次”
#删除原中文标题(名次列为"名次"的行删除)
df = df[-df["名次"].isin(["名次"])]4、知识点4通过条件找其他列数据并删除
1)我们的条件是:非数字行,首先筛选['名次']列中非数字行
2)找到的某列数据会有很多重复,我们可以进行去重处理drop_duplicates()
3)最后对含该列的数据进行删除
#筛选列中非数字的行
a = df[['名次']].apply(pd.to_numeric, errors='coerce').notnull().all(axis=1)
#筛选列中不为数字的行对应的标题名称
title_list = df.loc[a==False,"标题"].drop_duplicates()
#删除标题列中含有title_list内容的行
df = df[-df["标题"].isin(title_list)]5、知识点5多个字符替换:replace({})
df.replace({'-':'0','–':'0','_':'0'},inplace=True)6、知识点6替换空值为'0':fillna()
df.fillna('0', inplace=True) 7、知识点7修改列的数据类型:astype()
df[cols].astype(int)8、知识点8匹配内容替换

#规范年份列数据
year = []
for y in df['年份']:
a = re.search("[0-9][0-9][0-9][0-9]", y, re.X).group()
year.append(a)
df.loc[:, '年份'] = year完整代码如下:
import pandas as pd
import re
df = pd.read_excel("./data/Olympic2.xlsx")
#将国家列字符串中的空格都去除
df['国家'].replace('\s+','',regex=True,inplace=True)
#删除金牌、银牌、铜牌都为空的行
cols=['金牌','银牌','铜牌']
df=df.loc[df[df[cols]!=""].dropna(thresh=1).index]
#删除原中文标题(名次列为"名次"的行删除)
df = df[-df["名次"].isin(["名次"])]
##删除奖牌数为国家的数据
#筛选列中不为数字的行
a = df[['名次']].apply(pd.to_numeric, errors='coerce').notnull().all(axis=1)
#筛选列中不为数字的行对应的标题名称
title_list = df.loc[a==False,"标题"].drop_duplicates()
df = df[-df["标题"].isin(title_list)]
#规范年份列数据
year = []
for y in df['年份']:
a = re.search("[0-9][0-9][0-9][0-9]", y, re.X).group()
year.append(a)
df.loc[:, '年份'] = year
df.replace({'-':'0','–':'0','_':'0'},inplace=True)
df.fillna('0', inplace=True)
df[cols].astype(int)
df.to_excel("./data/Olympic10.xlsx")输出结果:

![]()
结 语
通过我们一系列操作,看到处理完成的数据,是不是感觉焕然一新。OF在本篇文章中对数据处理又补充了几个知识点,相信我们都对数据处理有了更深的理解。今天就写到这里,希望初学者们好好体会下思路,将复杂的事项拆分成一个个步骤,这样一点点积累起来就能把项目做成功。在写python程序前,先构思下步骤,再根据步骤一个个完成。本系列还剩下最后一篇文章动态排序正向您招手,尽请期待。
1、数据采集-爬虫;
1896-2021历届奥运会奖牌动态排序动画(Python数据采集)
2、数据处理-数据清洗;(本篇文章)
3、数据动态排序。
