自动驾驶轨迹预测论文阅读(二)TPNet: Trajectory Proposal Network for Motion Prediction
论文链接:https://openaccess.thecvf.com/content_CVPR_2020/papers/Fang_TPNet_Trajectory_Proposal_Network_for_Motion_Prediction_CVPR_2020_paper.pdf
精读】FANG L, JIANG Q, SHI J, et al., 2020. TPNet: Trajectory Proposal Network for Motion Prediction[C/OL]//2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR). Seattle, WA, USA: IEEE: 6796-6805[2022-08-22]. https://ieeexplore.ieee.org/document/9156890/. DOI:10.1109/CVPR42600.2020.00683.TPNet:运动预测的轨迹建议网络
Abstract
对周围交通主体(例如行人、车辆和骑自行车的人)进行准确的运动预测对于自动驾驶至关重要。最近的数据驱动运动预测方法试图学习从大量轨迹数据中直接回归确切的未来位置或其分布。然而,这些方法仍然难以提供多模式预测以及整合交通规则和可移动区域等物理约束。在这项工作中,我们提出了一种新颖的两阶段运动预测框架,即轨迹提议网络(TPNet)。 ==TPNet 首先生成一组候选的未来轨迹作为假设提议,然后通过对满足物理约束的提议进行分类和细化来做出最终预测。==通过指导建议生成过程,可以实现安全和多模式的预测。因此,该框架有效地减轻了运动预测问题的复杂性,同时确保了多模态输出。在四个大规模轨迹预测数据集(即 ETH、UCY、Apollo 和 Argoverse 数据集)上的实验表明,TPNet 在数量和质量上都达到了最先进的结果。 1
Introduction
预测周围交通主体(例如车辆、行人和骑自行车的人)的运动对于自动驾驶系统做出信息丰富且安全的决策至关重要。交通代理的行为本质上是多模态的,其中可能有多个合理的意图来确定他们的未来路径。如图 1 所示,当仅接收到有限数量的观测值时,在这种情况下,绿色的车辆 1 可以右转或直行。此外,交通代理人的移动不仅取决于他们的意图,而且还受到附近交通规则(例如可能的可移动区域)的规则化。例如,车辆应在道路上行驶,并且行人应在人行道或人行横道上行走。因此,可靠的运动预测应该涉及代理先前轨迹的建模以及目标的交通限制。确保安全和多模态预测对于自动驾驶系统至关重要。

运动预测的早期工作通过利用基于卡尔曼滤波器的动态模型 [5, 6] 或高斯混合模型 [9] 等来考虑时间序列预测任务。然而,这些模型对观测噪声非常敏感,并且由于建模主体意图的失败,对于长期预测变得不可靠。最近,已经开发了许多基于深度神经网络的数据驱动运动预测方法 [1, 11, 13, 25, 31, 39, 42, 44, 48]。他们中的大多数人试图**通过从大量轨迹数据中直接回归确切的未来位置或其分布来学习运动模式。**多模态预测是通过从预测分布中采样生成的 [25,49,28]。然而,**当不同意图的未来位置分布很大(例如左转和右转)时,数据驱动的方法很难提供合理的多模式预测。**为了进一步确保预测符合交通规则,环境信息通常被编码为语义图,然后输入神经网络[10, 4]。然而,这些端到端的深度网络缺乏使输出预测严格遵循交通规则或语义图的安全保障,同时也难以有效地结合周围的物理约束。
在这项工作中,我们提出了一种称为轨迹提议网络 (TPNet) 的新型两阶段框架,以更好地处理多模态运动预测和交通约束。**在第一阶段,TPNet 预测一个粗略的未来终点位置以减少轨迹搜索空间,然后基于预测的终点生成假设作为一组可能的未来轨迹建议。在第二阶段,TP Net对proposal进行分类和细化,然后输出得分最高的proposal作为最终预测。**可以在第一阶段产生具有不同意图的提案,以实现多样化的多模态预测。利用可移动区域约束等先验知识过滤提案结果,使该模块更加有效和透明。大量的实验结果表明,提出和细化未来轨迹使得运动预测比直接回归未来位置的预测更准确。
本文的贡献总结如下:1)我们提出了一个针对车辆和行人的统一的两阶段运动预测框架。 2)该框架可以在提案生成过程中结合先验知识,以确保通过多模式预测进行预测,其中考虑了代理的多种意图,以及交通规则和条件的遵守。 3) 我们在最近的大规模轨迹预测数据集 ETH [35]、UCY [27]、ApolloScape [32] 和 Argoverse [8] 上取得了最先进的结果。
Related work
运动预测方法大致可以分为两类,经典方法和基于深度学习的方法。**大多数经典的基于运动的算法使用运动学方程来模拟代理的运动,并预测车辆的未来位置和机动。这些方法的综合概述可以在 [26, 37] 中找到。**对于未来的位置预测,已经部署了多项式拟合[16]、高斯过程[23、43]、高斯混合模型[9]等统计模型。基于卡尔曼滤波器的动态模型 [5, 6] 也被广泛用于运动预测。对于机动识别,贝叶斯网络 [41]、隐马尔可夫模型 [9, 23]、SVM [3, 33]、随机森林分类器 [40] 等模型得到了广泛的探索。他们中的一些人建议使用场景信息来改进预测 [21, 36]。这些经典方法仅基于先前的动作对固有行为进行建模,而没有考虑驾驶员决策的不确定性,因此在长期预测中无法达到满意的性能。
最近,许多基于深度学习的方法已被用于运动预测 [18,19,22,47]。他们中的大多数专注于如何从环境中提取有用的信息。 [46]中提出了卷积神经网络(CNN)编码器解码器,用于从代理过去的位置和方向中提取特征,并直接回归未来的位置。在 [10] 中,车辆的位置和上下文信息被编码为二进制掩码,并提出了一种感知 RNN 来预测车辆的位置热图。基于学习的预测方法的典型管道首先对输入特征进行编码,然后使用 CNN 或长短期记忆 (LSTM) [15] 提取特征并回归未来位置 [2, 24, 34, 45]。然而,对于这些数据驱动和基于深度学习的方法,很难保证预测的安全性和物理约束。还有另一个管道,首先基于大量运动信息(速度、加速度、角加速度等)生成可能的轨迹集,然后优化设计的成本函数以获得最终预测[16]。然而,这种方法在很大程度上依赖于物理测量的准确性、高清地图和轨迹集的质量。与 [16] 不同,所提出的 TPNet 可以仅基于轨迹位置生成完整的建议。所提出的两阶段管道对建议进行了进一步的细化,从而降低了生成建议的相关性并保证了预测的多样性。同时,通过将先验知识应用到提案生成过程中,我们的方法可以有效地考虑物理约束。
Trajectory Proposal Network
为了促进安全和多模态运动预测,我们提出了一种新的两阶段框架,称为轨迹提议网络(TPNet)。框架如图2所示:在第一阶段,从目标代理中提取基本特征,然后预测一个粗略的端点以减少提议搜索空间。然后利用该预测终点生成建议。在第二阶段,对提案进行分类以找到最可能的未来轨迹,然后对其进行细化以确保最终预测的多样性。
通过在第一阶段监控提案生成过程中生成的提案,基于深度学习的预测方法可以更具可解释性和灵活性。给定生成的proposals,TPNet的第二阶段只需要选择最合理的轨迹,与以前直接回归轨迹的方法相比,这简化了预测问题。此外,通过分别检查两个阶段的输出,可以方便地调试和解释可能的错误预测。

Base Feature Encoding Module基本特征编码模块
基本特征编码模块被设计为编码器-解码器网络,因为它可以灵活地将不同类型的输入特征扩展到模块。编码器和解码器块分别由几个卷积层和反卷积层组成。详细的模型结构如图 2 所示。
该模块将目标agent在时间间隔[0, Tobs]内的**一系列过去位置pobs = {p0, p1, …, pTobs }及其周围的道路信息rTobs作为输入,道路信息对于不同的数据集是可选的.道路信息由许多语义元素表示,例如车道线、人行横道等,并与代理的位置有关。为了简单起见,我们将道路信息编码为图像,并在图像上绘制目标过去的位置**,与[10]相同。一个小的骨干 ResNet-18 [14] 用于从道路语义图像中提取特征。
Proposal Generation生成建议轨迹
在本节中,我们将介绍 Proposal Generation 的详细过程。根据是否使用道路信息,有两种建议生成方法。 Base Proposal Generation 仅使用位置信息,可以应用于没有道路信息的数据集。当与道路信息相结合时,**多模式提案生成(the multimodal proposal generation)**可以为每个可能的意图生成提案,确保更紧凑的假设集。
Problem Defifinition问题定义
在我们的 TPNet 中,我们将有限时间内的代理轨迹建模为连续曲线,以实现效率、灵活性和鲁棒性。**连续曲线 [16] 避免了未来轨迹集的低效组合爆炸和某些组合中缺乏物理约束,而不是传统的离散点序列 [31, 10] 预测表示。**通过改变较少的曲线参数,我们可以灵活地生成一组曲线。曲线表示对噪声也具有鲁棒性,可以反映运动趋势和意图。
由于其简单性,我们选择多项式曲线来表示轨迹[16]。为了找到最佳多项式拟合度,我们进行了不同程度的实验,并计算了时间长度T=Tobs+Tpre的轨迹的拟合误差,其中Tobs是历史观测的长度,Tpre是未来预测的长度。我们选择在准确性和复杂性之间取得平衡的三次曲线。 ApolloScape 数据集上行人的平均拟合误差为 0.048 m,Argoverse 数据集上车辆的平均拟合误差为 0.068 m,这对于大多数情况来说足够准确(详细分析可以在补充材料中找到)。
由于曲线对参数敏感且难以优化,我们建议使用一组点来表示曲线:两个控制点,即终点和曲率点(如图 3 所示),沿与过去的点。曲率点反映了曲线的弯曲度,由一个名为 γ 的距离变量确定。 γ 定义为轨迹曲线与当前点和终点的中点之间的距离,如图 3 所示。将曲率点编码为 γ 可以灵活地生成具有不同弯曲度的曲线。

Base Proposal Generation基础提案生成
一个好的提案生成过程应该能够基于较少的轨迹信息生成完整的提案。因此,Base Proposal Generation 方法仅根据轨迹位置生成建议,这是几乎所有轨迹预测数据集 [8, 27, 32, 35] 提供的最基本和最常见的特征之一。给定代理的过去位置,可以通过在第3.2.1节中定义的曲线表示下改变不同的控制点来生成建议。 基于第一阶段预测的端点pe,可以通过枚举以pe为中心的N×N网格来生成可能的端点:
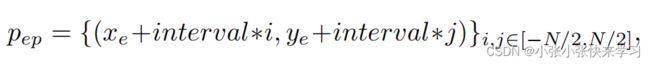
其中 pep 是可能的端点集, (xe, ye) 是 pe 的坐标,interval和N是网格的间隔和大小。通过改变 γ 的值,可以为每个可能的端点生成不同的曲率点。
最后,建议使用方程式1,仅基于位置生成。
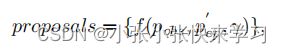
其中 f(·) 是三次多项式拟合函数,pep ∈ pep 和 γ ∈ [-2, -1, 0, 1, 2]。
Multimodal Proposal Generation多式联运提案生成
Base Proposal Generation 对第一阶段的回归端点有很强的依赖性,这可能导致生成的提案的多样性较低。 Multimodal Proposal Generation 利用道路信息生成多个端点,因为道路对车辆有很强的限制。
基于道路信息的基本要素(车道线及其方向等)和车辆过去的位置,我们可以获得一组参考线,代表车辆可能到达的中心车道线[8]。因此方程1可以扩展到为不同的参考线生成多个提案集。
具体来说,预测的是沿参考线的相对 1D 终点位置位移 dep,而不是 2D 终点 pe。然后我们根据预测的深度对每条参考线上的未来端点进行采样,从而减少对单个回归端点的依赖,确保预测的多样性。最后,使用等式1为每个采样端点生成建议, 流程如图 4 所示。

Proposal Classifification and Refifinement提案分类和细化
给定一组提案,分类模块选择最佳提案,而细化模块细化提案的端点和 γ。
分类模块。在训练期间,将表示良好轨迹与否的二进制类标签分配给每个提议。我们将地面实况的统一采样点与提案轨迹曲线之间的平均距离定义为提案质量的标准,记为:

其中 N 是采样点的数量,pi gt 和 pi pp 分别是 ground truth 轨迹和建议的第 i 个采样点。我们将积极标签分配给 AD 低于阈值的提案,例如1米。剩下的建议是潜在的负样本。为了避免过多负样本的压倒性影响,我们采用统一抽样的方法,将负样本和正样本的比例保持在 3:1。
**细化模块。**对于提案细化,我们采用 2 个坐标和 1 个变量的参数化:
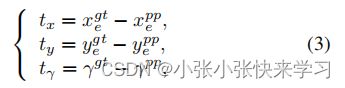
其中 (x gt e , y gt e) 和 (x pp e , y pp e ) 是真实轨迹和提议的终点坐标。 tx、ty 和 tγ 是训练期间使用的监督信息。
模型设计。对于每个提议,我们使用第3.1节中提到的相同的编码器-解码器模块提取特征。然后将基本特征与提议特征连接起来。最后两个全连接层分别用于对提案进行分类和细化。
Prior Knowledge先验知识
车辆在道路上行驶倾向等先验知识将使轨迹预测结果更加稳定和安全。然而,由于模型的复杂性和无法解释的性质,基于DNN的解决方案无法保证这些约束。
由于基于提案的管道,我们可以使用先验知识来明确过滤提案。**结合历史轨迹和高清地图,确定了agent未来可以旅行的多边形区域,即可移动区域。**我们建议通过使用方程式4衰减可移动区域之外的提议的分类分数来明确限制推理期间的预测轨迹。

其中 r 是提案轨迹指向可移动区域之外的比率,σ 是衰减因子。
与放弃可移动区域外的预测结果相比,衰减分类分数保证了预测的多样性。
Objective Function目标函数
在训练期间,我们将多任务损失最小化为:

其中 pe 和 p∗e 是预测的终点和对应的 ground-truth,ci 和 ti 是每个提议的预测置信度和轨迹参数,c∗i 和 t∗i 是对应的 ground-truth 标签,α 是权重项。
欧几里得损失被用作终点预测损失 Lep 和细化损失 Lref 。使用二元交叉熵损失作为分类损失 Lcls。由于未来轨迹的多模态特性,我们使用正样本和部分随机采样的负样本来计算细化损失,并使用 β 来控制采样负样本的比例。
Experiments
TPNet 在四个公共数据集上进行评估,ETH [35]、UCY [27]、ApolloScape [31] 和 Argoverse [8]。**ETH 和 UCY 数据集专注于行人轨迹预测。**总共有五个子集,分别命名为 ETH、HOTEL、ZARA01、ZARA-02 和 UCY。我们遵循与 Social GAN [12] 相同的数据预处理策略。轨迹长度有两个设置,Tobs = Tpre = 3.2s 和 Tobs = 3.2s,Tpre = 4.8s。两种设置的时间间隔均设置为 0.4 秒,即 8 帧用于观察,8/12 帧用于预测。 **ApolloScape 包含目标代理轨迹的鸟瞰坐标及其周围代理的轨迹。**需要预测三种对象类型,即车辆、行人、骑自行车的人。对于轨迹的长度,ApolloScape 设置 Tobs = Tpre = 3s,时间间隔为0.5s,这样观察和预测都是 6 帧。 Argoverse 数据集专注于车辆轨迹的预测。除了每辆车的鸟瞰坐标外,Argoverse 数据集还提供了高清地图。对于轨迹的长度,Argoverse 设置 Tobs = 2s,Tpre = 3s,时间间隔为 0.1s。训练集、验证集和测试集分别包含 205942、39472 和 78143 个序列。
**评估指标。**平均位移误差 (ADE) 和最终位移误差 (FDE) 是运动预测中最常用的指标。 ApolloScape 还使用 ADE 的加权和 (WSADE) 和 FDE 的加权和 (WSFDE) 作为不同代理类型之间的指标。 Argoverse 还计算最小 ADE (minADE)、最小 FDE (minFDE) 和可行驶区域合规性 (DAC)。
- WSADE/WSFDE:不同代理类型之间 ADE/FDE 的加权和。
- minADE/minFDE:是多个预测中的最小 ADE/FDE(最高 K=6)。
- DAC:是可行驶区域内预测位置的比率。
基线。由于我们提出的方法中的多模态建议生成和安全保证依赖于高清地图,因此比较方法分为两组。第一组由不使用高清地图的方法组成,包括 Social LSTM [1] 和 Social GAN [12]。这些基线在 ApolloScape、ETH 和 UCY 数据集上进行了比较。第二组由使用高清地图的方法组成,包括最近邻 [8] 和 LSTM ED [8]。这些基线在 Argoverse 数据集上进行比较。
- Social LSTM (S-LSTM):使用 LSTM 提取轨迹特征,并提出社会池化模型,对行人轨迹预测的社会影响进行建模。
- Social GAN (S-GAN):提出了一个条件 GAN,它将所有代理的轨迹作为输入。
- 最近邻(NN):使用top-K 假设中心线的加权最近邻回归。
- LSTM ED:以路线图信息作为输入的 LSTM 编码器-解码器模型。
实施细节。对于网络输入,相对于目标代理 70m × 70m 范围内的道路元素被编码为分辨率为 0.5 m/像素的语义地图。ResNet-18 [14] 用于提取语义图的特征。在训练期间,我们**通过随机旋转和翻转轨迹来使用数据增强。**负样本和正样本之间的比率设置为 3:1,正 AD 阈值在实验上设置为 3m。我们使用 Adam [20] 优化网络,批量大小为 128 50 个 epoch,学习率为0.001,衰减率为 0.9。
Comparison with Baselines与基线比较
所提出的两阶段框架的有效性在 ETH、UCY 和 Apollo 数据集上进行了评估,只有目标的鸟瞰过去位置作为 Tab1和Tab2中的输入。为了验证我们提出的方法的多模态预测和安全保证,在 Argoverse 数据集上进行了实验,如 Tab.3所示。



两阶段框架的评估。提出的TPNet与 ETH 和 UCY 数据集的基线在 Tab1 中的两个指标 ADE 和 FDE 方面进行了比较。遵循 S-GAN 中的评估方法,我们将结果报告为 TPNet-1 和 TPNet-20,其中 TPNet-1 是分类得分最高的预测,而 TPNet-20 结果是分类得分最高的预测中的最佳预测K分类分数。结果表明,TPNet-1结果已经优于社会LSTM和社会GAN的多模态结果。在使用TPNet-20结果后,TPNet与所有数据集上的所有基线具有竞争力。请注意,TPNet仅使用目标代理的过去位置,而其他基线也使用周围代理的位置,这可能会使我们的方法在某些数据集上变得更糟。
然后,TPNet 的性能结果和 ApolloScape 数据集上的比较方法显示在表2中。从表中我们可以看到 TPNet 在所有代理类型上都优于基线方法。具体来说,TPNet 在车辆轨迹预测方面表现更好,我们认为这是因为曲线表示对车辆轨迹更友好。
多模态预测的评估。 在Tab. 3中TPNet-map-mm 根据 Sec.3 中提到的参考线生成具有不同意图的提案。在表中,TPNet 被称为我们的方法,只有过去的位置作为输入,TPNet-map 作为我们的方法,过去的位置和道路语义图作为输入。 TPNet-map-safe 和 TPNet map-mm 分别被称为使用先验知识来约束提案和生成多模态提案。为了评估预测方法的多样性,Argoverse [8] 使用 minADE 和 minFDE 作为指标。这两个指标计算每个目标轨迹的 K 个样本中的最佳 ADE 和 FDE。在生成不同意图的proposal后,minADE和minFDE分别提高了60cm和1m。此外,即使不使用参考线,所提出的 TPNet 也可以生成多模态预测。如表中所示。如图 1 所示,在不使用参考线的情况下,ETH 和 UCY 数据集上的 TPNet-20 结果大大优于 TPNet-1 结果。由于提案生成过程,可以确保具有不同意图的预测更有效。
**安全保障评估。**评估第 3.4 节中提到的安全保障的有效性。我们在Tab3中展示了Argoverse数据集上的实验结果。Tab3显示 TPNet 大大优于 Argoverse [8] 中提出的基线,尤其是在 FDE 上。这表明 TPNet 可以生成更准确的端点。
此外,在以道路语义图为输入后,TPNet-map 取得了更好的效果。然而,预测结果仍可能在可驱动区域之外,因为DAC度量仍有改进的空间。
通过使用等式在可驾驶区域之外衰减提案的分类分数。如公式 4 所示,TPNet-map-safe 的 DAC 提高到 0.99,这表明我们提出的方法可以产生更安全的预测结果。
Ablation Study消融研究
在本节中,我们将说明 TPNet 各部分的有效性。我们选择 Argoverse 数据集进行消融研究有两个原因,1) Argoverse 数据集的规模比其他数据集大,2) Argoverse 数据集为验证集提供了真实标签。

两阶段框架。为了进一步验证建模轨迹预测作为两阶段框架的有效性,进行了逐步去除分类和回归模块的实验。结果显示在表4中。通过同时去除分类和回归,模型在 FDE 指标上达到 4.01 m。预测轨迹是通过对过去位置和预测结束位置拟合的曲线上的位置进行采样得到的。然后使用级联回归器来细化预测的终点,并将 FDE 进一步提高 5 cm,如表4中第二行所示。最终完成了完整的两级管道实验,FDE可以进一步提高8 cm。

网格大小。所提出的方法依赖于生成提案的质量。网格大小对提案生成的影响如表 5 所示。当网格范围设置为 6m × 6m 时,TPNet 会有更好的结果。随着网格范围的增长,随着搜索空间变大,性能变得更差。并且较小的间隔大小更好。
Qualitative Evaluation定性评价
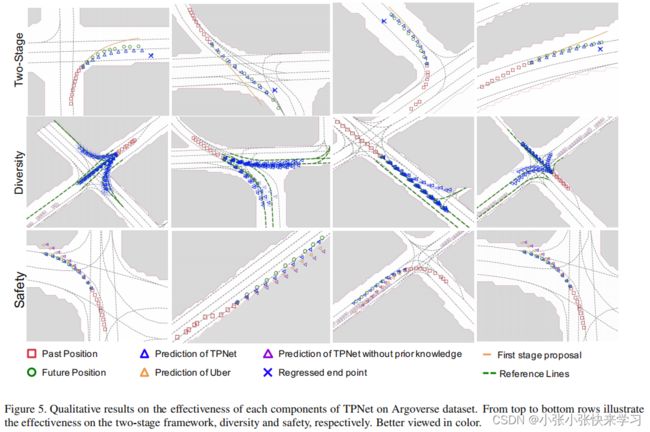
预测交通代理的运动是一项挑战,因为代理在同一场景下可能有不同的意图。此外,未来可能的路径不仅取决于他们的意图,还受到附近交通规则的约束。 Argoverse 验证集的定性结果如图 5 所示。大多数选定的场景都接近十字路口。图 5 表明我们的方法可以产生更安全和多样化的预测。
**两阶段框架。**所提出的两阶段框架的有效性如图 5 的第一行所示。回归的终点可能不准确,但分类和回归过程将改善预测结果。
多模式输出。在图 5 的第二行中,显示了在十字路口附近情景下的预测结果。我们可以观察到围绕每个可能意图的多模式预测。此外,每个意图的预测也是多种多样的,例如,车辆可能会沿着中心车道线行驶或偏离中心车道线。
安全。在图 5 的最后一行中,我们展示了 TPNet(紫色三角形)、Uber [10](黄色三角形)和具有安全保证的 TPNet(蓝色三角形)的结果。Uber[10]将道路元素编码为光栅图像,并使用CNN预测未来位置。从图中可以看出,将语义路线图输入到 DNN 并不能保证预测的安全性,而提出的衰减函数 Eq. 4更可靠。
Conclusion
在这项工作中,我们提出了一个用于更有效的运动预测的两阶段管道。**提出的两阶段 TPNet 首先生成可能的未来轨迹作为建议,并使用基于 DNN 的模型对建议进行分类和细化。多模式预测是通过为不同的意图生成建议来实现的。此外,还可以通过过滤可移动区域之外的建议来确保安全预测。**在公共数据集上的实验证明了我们提出的框架的有效性。所提出的两阶段管道可以灵活地将先验知识编码到深度学习方法中。例如,我们可以使用指示车辆意图的灯状态来过滤提案,这将包含在未来的工作中。
此外,在以道路语义图为输入后,TPNet-map 取得了更好的效果。
接下来要阅读的References
- Social gan: Socially acceptable trajectories with generative adversarial networks Social gan:具有生成对抗网络的社会可接受的轨迹
- Desire:Distant future prediction in dynamic scenes with interacting agents Desire:动态场景中具有交互代理的遥远未来预测
- Probabilistic vehicle trajectory prediction over occupancy grid map via recurrent neural network.基于循环神经网络的占用网格地图的概率车辆轨迹预测。
- Sequence-to-sequence prediction of vehicle trajectory via lstm encoder-decoder architecture.通过 lstm 编码器-解码器架构对车辆轨迹进行序列到序列预测。
- Intention-aware long horizon trajectory prediction of surrounding vehicles using dual lstm networks.使用双 lstm 网络对周围车辆进行意图感知的长视野轨迹预测。
- Motion prediction of traffific actors for autonomous driving using deep convolutional networks.使用深度卷积网络对自动驾驶的交通参与者进行运动预测