神网站PaperWithoutCode:举报无法复现的论文,让一作社死??

文 | 小戏
几乎是可以肉眼可见的看到机器学习领域的论文几何级的增长,在铺天盖地的论文雪花纸片般涌来时,灌水、可复现性、工作真实的意义这些概念也伴随着 Paper 的洪水进入了人们的视野。谈及科研,我们总是站在以往研究的基础上,寻找些“新”的东西把某些理论方法技术的延申在未有人涉足的地方啃一啃,诚然站在巨人的肩膀上,但伴随着论文漫天飞研究追新打快的现状,似乎也有前人工作地基不稳之嫌。
两年前,一位名为 ContributionSecure14 的 Reddit 用户发了这样一个帖子:

谈及自己曾花了一周时间复现一篇论文却根本没法得到正确的结果,而上网一搜却发现不止是自己,也有其他人在网上反映无法复现这篇论文。这种经历让他萌生出一个想法,如果网上有一个专门的清单,列出那些无法复现的论文,是否会大大节省其他人的时间和精力呢?在这种想法的驱动下,一个看起来有一点古怪的网站 Paper Without Code 应运而生:

这个网站的界面极其简单,它只提供这样几个功能,首先,我们可以通过简单的表单提交我们尝试过但无法复现的论文:
Paper Without Code 网站在收到提交的内容后,会向这篇无法复现的论文的第一作者发送一封邮件,并且“Give a chance to respond”,这个回应的响应期是一周,超过一周的文章将光荣上榜:
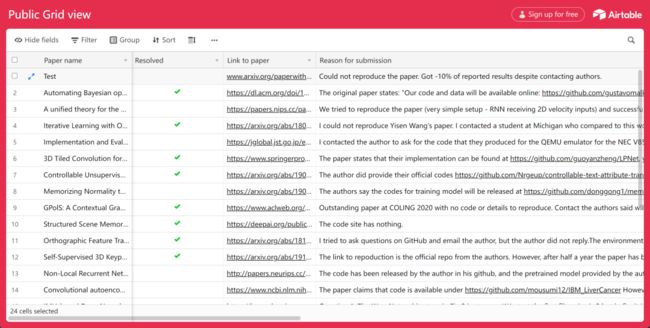
在表格里,可以看到指出论文无法复现的研究者被要求给出论文的地址链接、无法复现的理由、复现的项目代码地址以及复现所花费的时间。而表格会记录发出邮件的时间以及作者是否回复与回复的内容。可以看到,还是有相当多的作者看到了邮件并提交了代码:
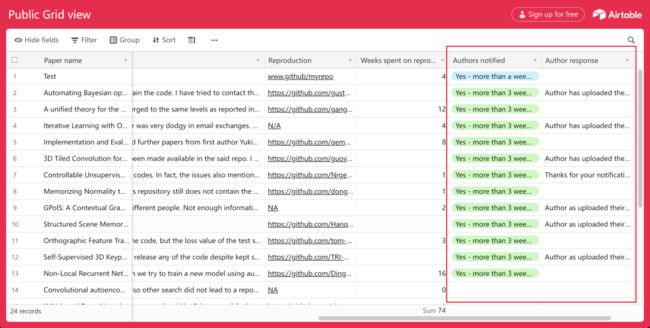
有些作者做出了认真的回复:

当然,也有的作者直言不讳的表达了不满,认为这是具有冒犯性的:

事实上,从总数上来看,参与这项类似于“将无法复现论文钉在十字架上”的活动的人数并不多,迄今为止也只要 24 篇论文在上榜,但是,这项“社会试验”以更有趣的方式在 Reddit 上被更充分的进行了讨论:
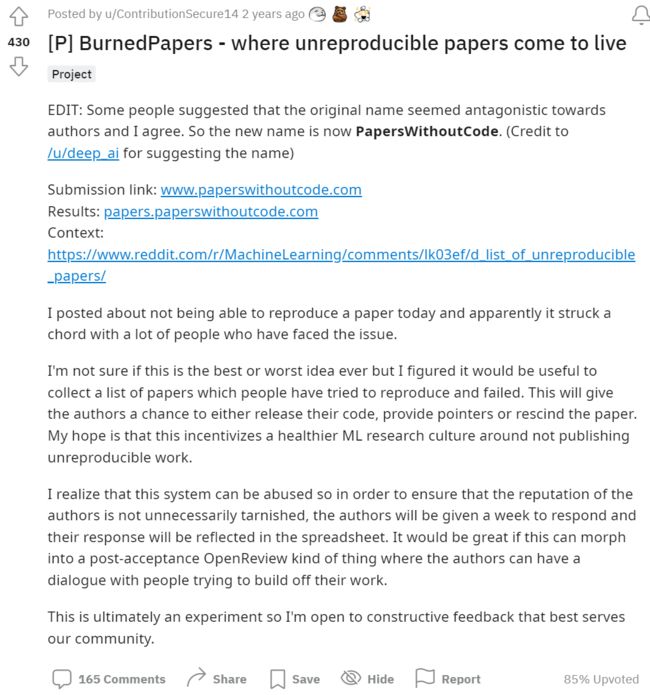
如项目作者 ContributionSecure14 介绍的这样,他创建了一个网站去公布这些“无法复现的论文”,有趣的是,ContributionSecure14 使用了一个“BurnedPapers”的词指代这些上榜的文章,免不了让人浮想联翩,ContributionSecure14 说他并不知道这究竟是一个“最好的想法”,还是一个“最糟糕的想法”,但是他的初衷是促成一种更健康的 ML 的研究文化。
显然,这个项目的支持者的理由简单直接,发 Paper ,做研究应该是件严肃认真的事,研究者要负起对这项研究的责任,而不能论文一发万事大吉。并且,这种社区间的监察,通过“社死”的形式也多少可以遏制一下论文灌水的势头:
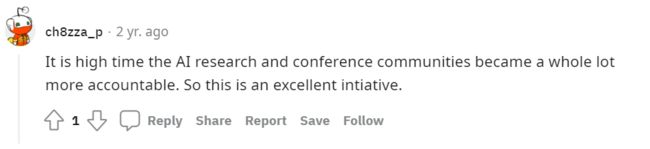
然而,意外的是,有非常多的人批评了这一做法,非常多的人指出列出一个耻辱柱式的“不可复现的论文列表”并非是解决问题的最佳机制设计。譬如,它无法保证无法复现这篇论文究竟是“论文本身的问题”还是复现者的“能力不足”,在表格中也可以看到,还是有相当一部分的认为论文无法复现的人并没有提交自己复现论文的项目地址:
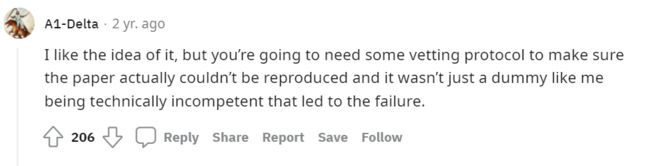
同时,也有人谈到一篇论文不公开代码无法被复现,也有可能是他们使用的数据有一些关涉隐私、政治敏感等问题的考量,也有可能是他们的架构有一些商业因素的考虑而不愿意披露自己的业务模型,一篇论文有价值与否与是否公开代码与数据并无直接关系,但是,判断这些不公开的数据与架构是否会影响到这篇论文的学术性也应成为同行评审的一部分:

并且,这种“不公布代码就让你社死”式的做法还会给科研工作者带来不必要的工作负担,这一点在道德上还处于一个模糊的地带,就是科研人员是否必要(而非应该)承担起让读者不仅读懂论文还要读懂代码以及实践上的设计(这对科研人员而言可能是共同知识)的责任。
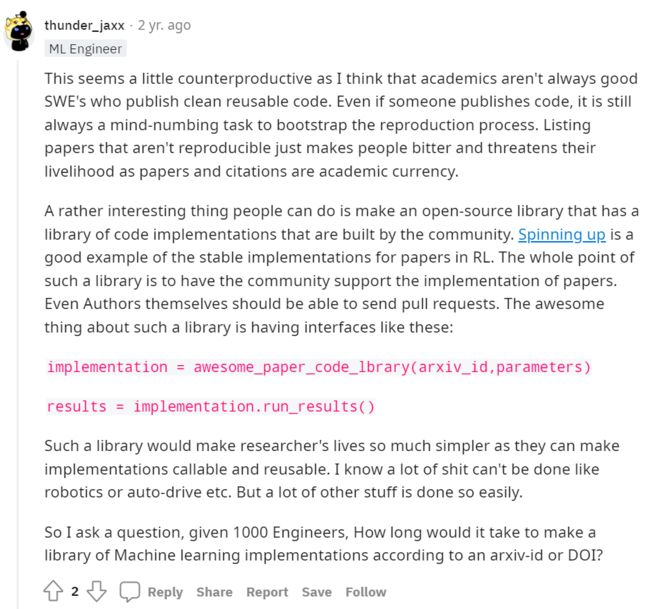
还有许多人认为或许这种想法本身是好的,但是却采取了一种“太过粗糙的”方式去实现这种想法,将一周不回应的论文直接作为“BurnedPapers”其实更有点民粹政治的味道。套用政治上保守主义的观点,这种问题更应该是被“改良”着解决的,譬如有很多人提出为促进论文的可复现性,更应该做的可能是一个记录“我做了哪些复现,哪一步出了问题使我无法继续复现的”的列表,从而使得至少复现者本身的问题可以被解决:
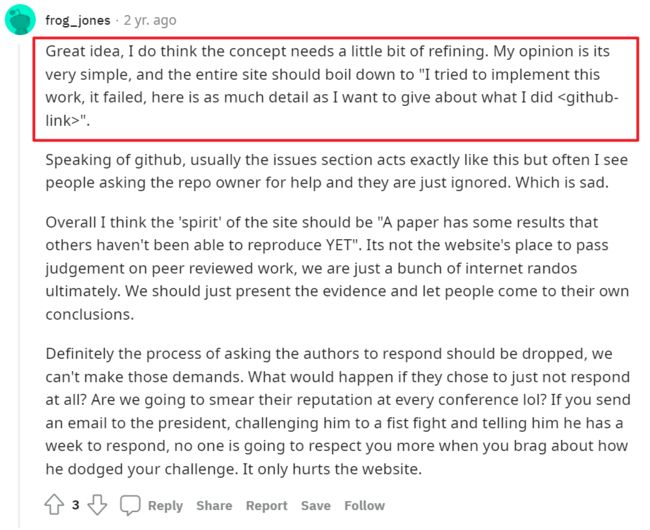
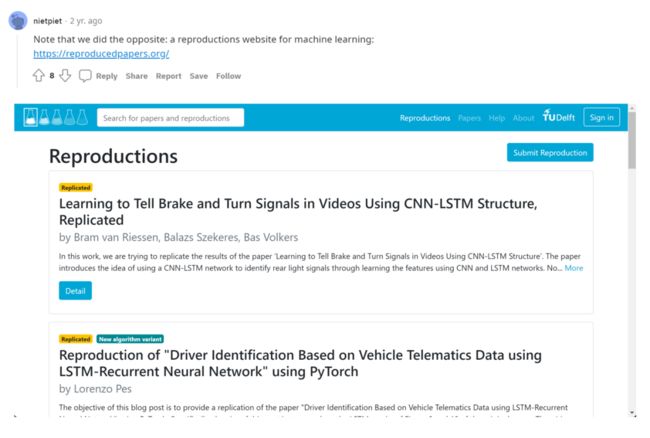
或者是一个归纳“可以复现的论文的列表”,并给出代码与细节(这个想法已经被人实现了):
在众多的批评声中也有答主强调了这个项目精神内涵的正确,许多批判者看到了这个项目“暴民”的一面,却也低估了甄别处理那些糟糕的工作对科研所造成的伤害。如果将无法复现的论文比作内存泄露,计算机没有释放掉不再使用的内存,而人类的信息处理能力是有限的,科研界确实需要一个“垃圾回收机制”去释放掉不再需要的内存,清理掉一些“不合格”的工作。

随着讨论的深入,其实问题的核心也逐渐发生了转移,这个仅只针对于这样一个“实验项目”的是否曲直的评价转向了更为宏观的涉及论文出版监察机制的研讨。
显然,我们知道论文的“可复现性”是相当重要的,也诚然论文灌水实验造假恶意隐瞒代码的现象及其危害的存在,那么我们如何找到一个更好的方式去使得我们一方面认可我们论文作为背景工作的那些研究具有扎实的基础,另一方面又能避免霰弹炮式的漫天开火,对论文作者带来一些不必要的负担与伤害呢?
回到之前提到在评审论文时也应该加入对不公开数据之余论文价值重要性意见的答主的答案,在他做出了如是的构想后,马上有人反驳,如果只是寄希望于同行评审时,那么这一策略已经失败了,并引用了一篇讲述心理学的可复现性危机的文章佐证只靠同行评审似乎并不能挽救“拿弱数据得到强理论的研究范式”,并且强调,科学应该是去中心化的。
文章题目:
What has happened down here is the winds have changed
文章链接:
https://statmodeling.stat.columbia.edu/2016/09/21/what-has-happened-down-here-is-the-winds-have-changed/
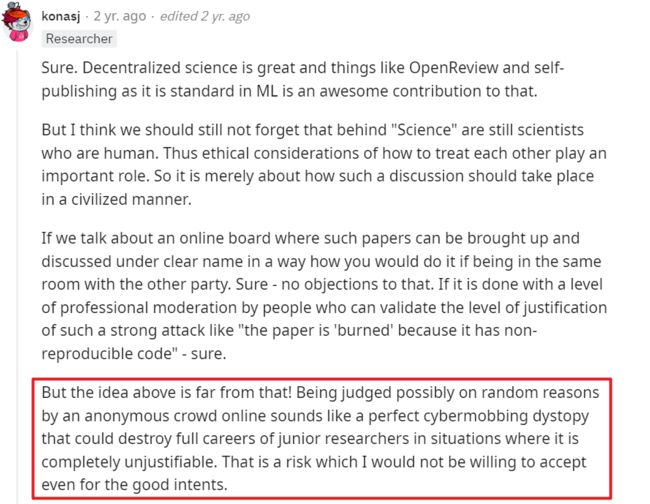
而关于这个问题的讨论则更加有意思,这似乎是一个恒久的“改良”还是“革命”的问题在一个似乎与政治毫不相干的领域内的复活,被反驳的答主仍然坚持“科学”这个词背后站着的是活生生的“科学家”,网上随机的人的匿名评判,哪怕出于“好的出发点”,也有可能赋予这些人权力毁掉一个年轻的研究者全部的职业生涯,哪怕可能这个研究者犯的可能只是一些小错误。因此正确的做法仍然应该是由一个足够专业的机构或有职业规范与操守的同行研究者通过细致的审查与专业的评判完成对一篇论文是否有错误存在的判断,因为只要在很少的情况一篇无法复现的论文是完全无效与造假的,更多的情况是问题不是很严重,只是需要削弱一些结论或增加几个假设。
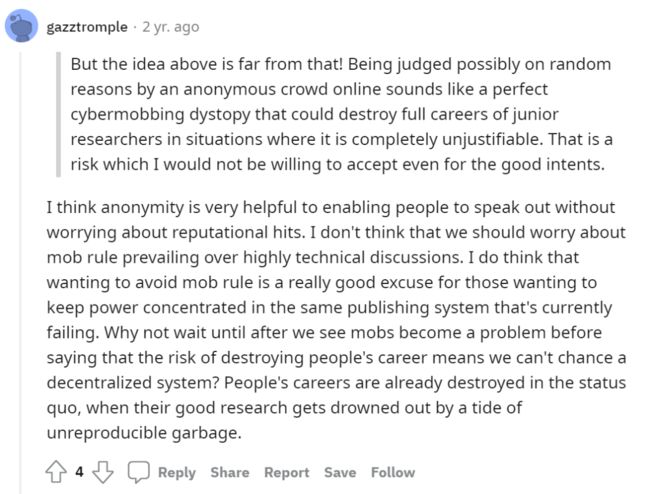
而针锋相对的意见在于,避免“暴民”统治可能是一个高度集权的规则制定者的惯用话术,担心那个虚构出来的年轻研究者被毁掉的未来的职业生涯,不如更加关心一下现实中已经被垃圾工作淹没而岌岌可危的研究者们的职业生涯。
讨论至此,似乎已经陷入了一个僵局,面对这样的一个问题,我们应该做的究竟是自上而下的做一些流程上的改进,譬如增加【可复现/难以复现/无法复现】的标签为研究者做出区分以选择合适的工作,还是更应该鼓励一种“民间”自下而上的学术监察,以 Paper Without Code 这样的网站为例将无法复现的论文作为靶子反向激励论文作者不敢随意造假?
其实回答这个问题还是更应该溯本追源,问问为什么会有这些“不可复现”的工作存在?
其实在几年前,人工智能的“可复现性危机”就被提上了舞台并进行讨论,而在更早的时候,对生物学、心理学的可复现性的质疑便已经开始此起彼伏,如果我们认可做研究是为了追求人类的知识的增加,那么追求普遍性则是知识的内在倾向,而实验的可重复性则是达到普遍性知识的重要手段。
而实验的不可重复一种是技术上的,散见 AI 领域诸如谷歌这些大厂发表的许多论文,普通研究者根本没有预算去重复与复现这些实验过程,对这些工作只能望洋兴叹,而大厂则因为其财力避免了监察获得了论文的独家权力。而另一种则影响更加深远,或许与实验心理学存在着相同的问题,AI 本质上讲还是弱理论的,区别于物理学的实验先经由理论推导认可理论后再进行实验进行验证,AI 领域由于缺少一套真正严谨完备的理论体系,因此在实验上往往是盲目的。也正是因为理论的缺乏,导致一些研究者反而获得了一种“解释权”,可以将自己在某些特定组合与条件下才能成立的结论放大,将“数据泄露”的结果归于普遍,把数据集的准确率认作真实世界的准确率,从而造成论文的不可复现。

而再回到关于“科学社区”,“科研监察”等话题的讨论中来,我们可以发现,对于以促成更加健康的 ML 社区文化为初衷的 Paper Without Code 对于没有钱没有财力复现的论文,即使公布代码 Paper Without Code 也无法解决复现的问题,而对于由于缺少理论指导导致的“强结论”,Paper Without Code 也没有真正的能力去解决这个问题,而只能退化为对文章本身的攻击。而对于作为一个论文好坏的信号发射器的 Paper without Code 而言,以复现者无法复现到要求作者回复不回复即上耻辱柱的逻辑链条与这篇论文本身的可复现性与好坏其实并不具有强相关的关系,复现者无法复现有多种原因很难必然指向论文错误,而作者不回复也有很多原因也难以指向作者心虚,显然作者回复并公布代码我们可以视作一种论文可靠的信号,但是作者不公布代码我们也无法推得这篇论文必然是糟糕甚至造假的论文,也因此,Paper Without Code 的生存空间便被进一步压窄。
当然这并不是说我们应该取缔这种社区的监察机制,我们需要去中心化的讨论与监察对现存的不合理的流程与僵硬的组织进行冲击,对从这个制度下生产出的论文进行审查与监管,但是真正的问题永远不是去否定与批判一两篇特定的论文,监察的目的是如何让这套体制能够真正产出让我们放心引用与在他们的研究基础上放手去干的“好”的成果,实现这种监察,需要的是引导与组织管理这种去中心化的监察的力量,而这种力量,唯有制度化与流程化才能办到,也即是将这种外在的监察内化到制度当中去。而在这个道路上,可能就不再是一个 Paer With Code 或者 Paper Without Code 就可以解决的问题了。
卖萌屋作者:小戏
边学语言学边学NLP~
作品推荐
千呼万唤始出来——GPT-3终于开源!
NLP哪个细分方向最具社会价值?
吴恩达发起新型竞赛范式!模型固定,只调数据?!
仅仅因为方法 Too Simple 就被拒稿,合理吗?
算法工程师的三观测试
后台回复关键词【入群】
加入卖萌屋NLP、CV、搜推广与求职讨论群