多交个朋友?罗永浩跳槽淘宝直播间;5分钟搞懂XGBoost算法;CUDA C++最佳实践指南;手写字体的倾斜校正;前沿论文 | ShowMeAI资讯日报

日报合辑 | 电子月刊 | 公众号下载资料 | @韩信子
淘宝斩获罗永浩、俞敏洪,双11主播争夺战一触即发!
『交个朋友』直播间已入驻天猫,主播罗永浩也会在10月24日首播,参与天猫双11的预热。在店铺首页宣传视频中,老罗表示特意为不常购物的男性朋友准备了手机、电脑、显卡、运动鞋服等品类。
新东方、东方甄选创始人俞敏洪也正积极为双11备课,并将在10月31日晚现身『新东方迅程教育专营店』淘宝直播间。去年双11期间,俞敏洪首次在淘宝直播带课,分享大学学习、职业路径规划等。
工具&框架
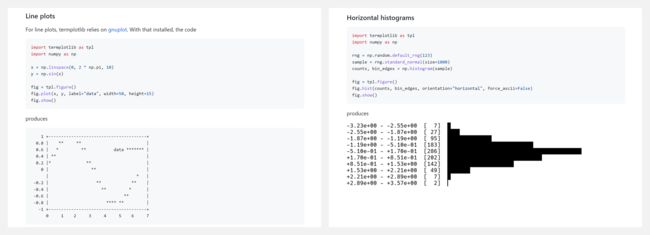
『termplotlib』Python 命令行绘图库
https://github.com/nschloe/termplotlib
termplotlib 是一个 Python 库,支持使用终端命令行绘图。你可以像 matplotlib 一样使用它,如下是线型图(Line plots)和水平直方图(Horizontal histograms)的绘制示例。
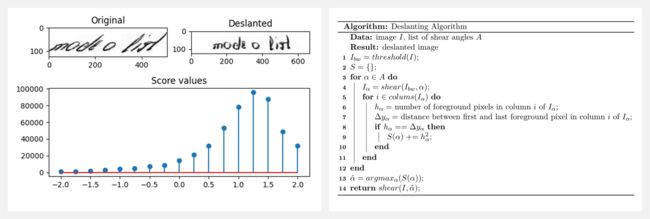
『Deslanting Algorithm』手写体倾斜校正
https://github.com/githubharald/DeslantImg
这个项目实现了一个算法,将图像中的手写文本进行倾斜校正,即去除草书风格。人们可以把它作为手写文本识别的一个预处理步骤。它提供了三种实现方式(Python、C++、OpenCL)。
『Transformer Engine』在NVIDIA GPU上加速Transformer模型
https://github.com/NVIDIA/TransformerEngine
https://docs.nvidia.com/deeplearning/transformer-engine/user-guide/index.html
Transformer Engine(TE)是一个用于在 NVIDIA GPU 上加速 Transformer 模型的库,包括在Hopper GPU 上使用 8 位浮点(FP8)精度,以在训练和推理中提供更好的性能和更低的内存利用率。
TE 为流行的 Transformer 架构提供了一系列高度优化的构建模块,并提供了类似于混合精度的自动API,可以与你的 PyTorch 代码无缝连接。TE 还包括一个与框架无关的 C++ API,可以与其他深度学习库集成,以实现对变形器的 FP8 支持。

『obs-websocket』基于 WebSocket 的 OBS 远程控制工具
https://github.com/obsproject/obs-websocket
obs-websocket 是一个基于 WebSocket 的 OBS 远程控制工具,可用于下述场景:
- 从同一本地网络的手机或平板电脑上远程控制 OBS
- 根据当前场景改变你的流媒体 overlay/graphics
- 用第三方程序自动切换场景(例如:自动驾驶等)

『NerfAcc』PyTorch 通用 NeRF 加速工具包
https://github.com/KAIR-BAIR/nerfacc
https://www.nerfacc.com/en/latest/
NerfAcc 是一个小的 PyTorch 工具箱,用于使用 PyTorch CUDA 扩展加速 NeRF 训练和渲染。对于大多数的 NeRFs 适配,即插即用。

博文&分享
『XGBoost Algorithm Explained in Less Than 5 Minutes』5分钟解析 XGBoost 算法
https://medium.com/@techynilesh/xgboost-algorithm-explained-in-less-than-5-minutes-b561dcc1ccee
XGBoost 是许多数据科学家的首选算法,最初是由陈天奇开发,工作原理是将多个『弱学习器』组合成一个『强学习器』,通过训练许多决策树来工作——每棵树都在数据的一个子集上进行训练,然后将每棵树的预测组合起来形成最终的预测。
XGBoost 的设计目标是高效、灵活、便携,在分类、回归和排名等各种任务中的表现优于其他机器学习算法。作为对 GBM 算法的改进,XGBoost 使用的正则化模型有助于防止过拟合,也有许多可调整的参数能提高算法的性能:
max_depth:决策树的最大深度eta:学习率gamma:进行拆分所需的最小损失减少subsample:用于训练每棵树的训练数据的一部分

『CUDA C++ Best Practices Guide』CUDA C++ 最佳实践指南
https://docs.nvidia.com/cuda/cuda-c-best-practices-guide/index.html
这是一份帮助开发人员从 NVIDIA® CUDA® GPU 获得最佳性能的手册,介绍了应用程序的评估、并行化、优化、部署(APOD)设计周期,帮助快速识别最易从GPU加速中受益的代码。此外,指南针对 CUDA C++ 代码的设计和实现提出了具体建议,并解释了可以简化编程的编码隐喻和习语。

建议新读者按顺序阅读本指南,这将大大提高对有效编程实践的理解。指南使用 C++ 编程语言,因此要求一定的 C++ 语言基础。指南包含以下章节:
- Assessing Your Application(评估申请)
- Heterogeneous Computing(异构计算)
- Application Profiling(应用程序分析)
- Parallelizing Your Application(应用程序并行化)
- Getting Started(开始)
- Getting the Right Answer(得到正确的答案)
- Optimizing CUDA Applications(优化CUDA应用程序)
- Performance Metrics(性能指标)
- Memory Optimizations(内存优化)
- Execution Configuration Optimizations(执行配置优化)
- Instruction Optimization(指令优化)
- Control Flow(控制流)
- Deploying CUDA Applications(部署CUDA应用程序)
- Understanding the Programming Environment(了解编程环境)
- CUDA Compatibility Developer’s Guide(CUDA兼容性开发者指南)
- Preparing for Deployment(准备部署)
- Deployment Infrastructure Tools(部署基础设施工具)

数据&资源
『Awesome Vision-and-Language Pre-Training』视觉-语言预训练相关资源大列表
https://github.com/zhjohnchan/awesome-vision-and-language-pretraining

研究&论文

可以点击 这里 回复关键字 日报,免费获取整理好的论文合辑。
科研进展
- 2022.10.02 『神经渲染』 IntrinsicNeRF: Learning Intrinsic Neural Radiance Fields for Editable Novel View Synthesis
- CVPR 2022 『图像补全』 High-Resolution Image Synthesis with Latent Diffusion Models
- 2022.09.21 『图像分类』 Mega: Moving Average Equipped Gated Attention
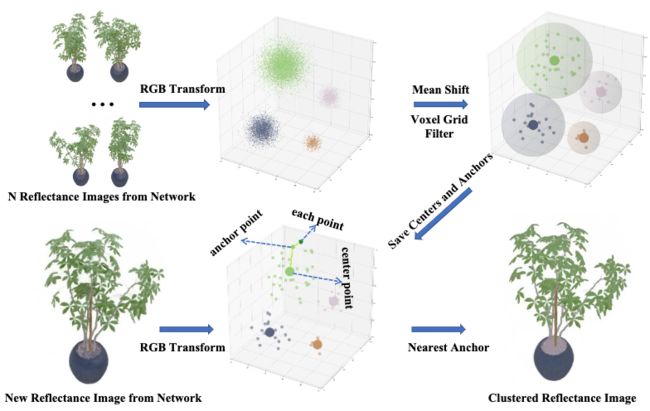
⚡ 论文:IntrinsicNeRF: Learning Intrinsic Neural Radiance Fields for Editable Novel View Synthesis
论文时间:2 Oct 2022
领域任务:Neural Rendering, Novel View Synthesis,神经渲染,多视角同步
论文地址:https://arxiv.org/abs/2210.00647
代码实现:https://github.com/zju3dv/intrinsicnerf
论文作者:Weicai Ye, Shuo Chen, Chong Bao, Hujun Bao, Marc Pollefeys, Zhaopeng Cui, Guofeng Zhang
论文简介:Given that intrinsic decomposition is a fundamentally ambiguous and under-constrained inverse problem, we propose a novel distance-aware point sampling and adaptive reflectance iterative clustering optimization method that enables IntrinsicNeRF with traditional intrinsic decomposition constraints to be trained in an unsupervised manner, resulting in temporally consistent intrinsic decomposition results./鉴于本征分解是一个根本性的模糊和约束不足的逆向问题,我们提出了一种新颖的距离感知点采样和自适应反射率迭代聚类优化方法,使具有传统本征分解约束的IntrinsicNeRF能够以无监督的方式进行训练,从而得到时间上一致的本征分解结果。
论文摘要:我们提出了被称为IntrinsicNeRF的内在神经辐射场,它将内在分解引入到基于NeRF的~神经渲染方法中,并能在房间规模的场景中进行可编辑的新颖视图合成,而现有的逆向渲染结合神经渲染方法只能在特定物体场景中工作。鉴于本征分解是一个根本性的模糊和约束不足的逆向问题,我们提出了一种新颖的距离感知的点采样和自适应反射率迭代聚类优化方法,使具有传统本征分解约束的IntrinsicNeRF能够以无监督的方式进行训练,从而得到时间上一致的本征分解结果。为了应对场景中反射率相似的不同相邻实例被错误地聚在一起的问题,我们进一步提出了一种从粗到细优化的分层聚类方法,以获得快速的分层索引表示。它可以实现引人注目的实时增强现实应用,如场景重新着色、材料编辑和光照变化。在Blender Object和Replica Scene上进行的大量实验表明,即使对于具有挑战性的序列,我们也能获得高质量的、一致的内在分解结果和高保真的新颖视图合成。代码和数据可在项目的网页上找到 https://zju3dv.github.io/intrinsic_nerf/



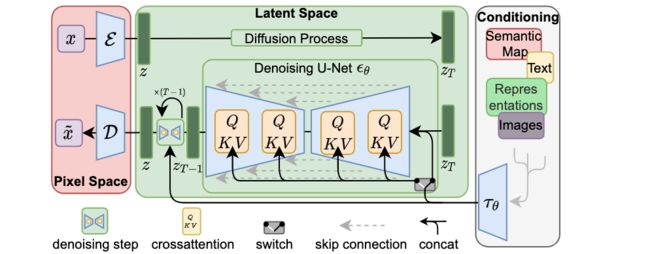
⚡ 论文:High-Resolution Image Synthesis with Latent Diffusion Models
论文时间:CVPR 2022
领域任务:Denoising, Image Inpainting, 降噪,图像补全
论文地址:https://arxiv.org/abs/2112.10752
代码实现:https://github.com/compvis/latent-diffusion , https://github.com/compvis/stable-diffusion , https://github.com/labmlai/annotated_deep_learning_paper_implementations , https://github.com/divamgupta/stable-diffusion-tensorflow , https://github.com/keras-team/keras-cv
论文作者:Robin Rombach, Andreas Blattmann, Dominik Lorenz, Patrick Esser, Björn Ommer
论文简介:By decomposing the image formation process into a sequential application of denoising autoencoders, diffusion models (DMs) achieve state-of-the-art synthesis results on image data and beyond./通过将图像形成过程分解为去噪自动编码器的连续应用,扩散模型(DMs)在图像数据和其他方面取得了最先进的合成结果。
论文摘要:通过将图像形成过程分解为去噪自动编码器的连续应用,扩散模型(DMs)在图像数据和其他方面取得了最先进的合成结果。此外,它们的表述可以由一个指导机制来控制图像生成过程,而无需重新训练。然而,由于这些模型通常直接在像素空间中运行,强大的DMs的优化往往需要消耗数百个GPU天,并且由于顺序评估,推理的成本很高。为了使DM在有限的计算资源上进行训练,同时保留其质量和灵活性,我们在强大的预训练自动编码器的潜在空间中应用它们。与以前的工作相比,在这样的表征上训练扩散模型首次允许在降低复杂性和保留细节之间达到一个接近最佳的点,极大地提高了视觉保真度。通过在模型结构中引入交叉注意力层,我们把扩散模型变成了强大而灵活的生成器,用于一般的调节输入,如文本或边界框,并且高分辨率合成以卷积的方式成为可能。我们的潜伏扩散模型(LDMs)在图像绘制方面达到了新的技术水平,并在各种任务上取得了极具竞争力的性能,包括无约束的图像生成、语义场景合成和超分辨率,同时与基于像素的DMs相比大大降低了计算要求。代码可在 https://github.com/CompVis/latent-diffusion 获取。
⚡ 论文:Mega: Moving Average Equipped Gated Attention
论文时间:21 Sep 2022
领域任务:Image Classification, 图像分类
论文地址:https://arxiv.org/abs/2209.10655
代码实现:https://github.com/facebookresearch/mega
论文作者:Xuezhe Ma, Chunting Zhou, Xiang Kong, Junxian He, Liangke Gui, Graham Neubig, Jonathan May, Luke Zettlemoyer
论文简介:The design choices in the Transformer attention mechanism, including weak inductive bias and quadratic computational complexity, have limited its application for modeling long sequences./transformer注意力机制中的设计选择,包括弱的感应偏差和二次计算复杂性,限制了其对长序列建模的应用。
论文摘要:Transformer注意力机制中的设计选择,包括弱的感应偏差和二次计算的复杂性,限制了其在长序列建模中的应用。在本文中,我们介绍了Mega,一个简单的、有理论基础的、配备了(指数)移动平均数的单头门控注意力机制,以将位置感知的局部依赖性的感应偏差纳入位置无关的注意力机制。我们进一步提出了Mega的一个变体,它提供了线性的时间和空间复杂性,但只产生最小的质量损失,通过有效地将整个序列分割成具有固定长度的多个块状。在广泛的序列建模基准上进行的广泛实验,包括Long Range Arena、神经机器翻译、自动回归语言建模以及图像和语音分类,表明Mega比其他序列模型,包括Transformers的变体和最近的状态空间模型,都有显著的改进。
我们是 ShowMeAI,致力于传播AI优质内容,分享行业解决方案,用知识加速每一次技术成长!
◉ 点击 日报合辑,在公众号内订阅话题 #ShowMeAI资讯日报,可接收每日最新推送。
◉ 点击 电子月刊,快速浏览月度合辑。
◉ 点击 这里 ,回复关键字 日报 免费获取AI电子月刊与论文 / 电子书等资料包。
