【数学建模】华为杯学习——特征选择(Python代码实现)
目录
1 问题回顾
2 数据集介绍及建模目标
3 问题刨析
4 Python代码实现——方法1
5 Python代码实现——方案2
1 问题回顾
问题有点长,可以直接看题目解析。
乳腺癌是目前世界上最常见,致死率较高的癌症之一。乳腺癌的发展与雌激素受体密切相关,有研究发现,雌激素受体α亚型(Estrogen receptors alpha, ERα)在不超过10%的正常乳腺上皮细胞中表达,但大约在50%-80%的乳腺肿瘤细胞中表达;而对ERα基因缺失小鼠的实验结果表明,ERα确实在乳腺发育过程中扮演了十分重要的角色。目前,抗激素治疗常用于ERα表达的乳腺癌患者,其通过调节雌激素受体活性来控制体内雌激素水平。因此,ERα被认为是治疗乳腺癌的重要靶标,能够拮抗ERα活性的化合物可能是治疗乳腺癌的候选药物。比如,临床治疗乳腺癌的经典药物他莫昔芬和雷诺昔芬就是ERα拮抗剂。
目前,在药物研发中,为了节约时间和成本,通常采用建立化合物活性预测模型的方法来筛选潜在活性化合物。具体做法是:针对与疾病相关的某个靶标(此处为ERα),收集一系列作用于该靶标的化合物及其生物活性数据,然后以一系列分子结构描述符作为自变量,化合物的生物活性值作为因变量,构建化合物的定量结构-活性关系(Quantitative Structure-Activity Relationship, QSAR)模型,然后使用该模型预测具有更好生物活性的新化合物分子,或者指导已有活性化合物的结构优化。
一个化合物想要成为候选药物,除了需要具备良好的生物活性(此处指抗乳腺癌活性)外,还需要在人体内具备良好的药代动力学性质和安全性,合称为ADMET(Absorption吸收、Distribution分布、Metabolism代谢、Excretion排泄、Toxicity毒性)性质。其中,ADME主要指化合物的药代动力学性质,描述了化合物在生物体内的浓度随时间变化的规律,T主要指化合物可能在人体内产生的毒副作用。一个化合物的活性再好,如果其ADMET性质不佳,比如很难被人体吸收,或者体内代谢速度太快,或者具有某种毒性,那么其仍然难以成为药物,因而还需要进行ADMET性质优化。为了方便建模,本试题仅考虑化合物的5种ADMET性质,分别是:1)小肠上皮细胞渗透性(Caco-2),可度量化合物被人体吸收的能力;2)细胞色素P450酶(Cytochrome P450, CYP)3A4亚型(CYP3A4),这是人体内的主要代谢酶,可度量化合物的代谢稳定性;3)化合物心脏安全性评价(human Ether-a-go-go Related Gene, hERG),可度量化合物的心脏毒性;4)人体口服生物利用度(Human Oral Bioavailability, HOB),可度量药物进入人体后被吸收进入人体血液循环的药量比例;5)微核试验(Micronucleus,MN),是检测化合物是否具有遗传毒性的一种方法。
2 数据集介绍及建模目标
本试题针对乳腺癌治疗靶标ERα,首先提供了1974个化合物对ERα的生物活性数据。这些数据包含在文件“ERα_activity.xlsx”的training表(训练集)中。training表包含3列,第一列提供了1974个化合物的结构式,用一维线性表达式SMILES(Simplified Molecular Input Line Entry System)表示;第二列是化合物对ERα的生物活性值(用IC50表示,为实验测定值,单位是nM,值越小代表生物活性越大,对抑制ERα活性越有效);第三列是将第二列IC50值转化而得的pIC50(即IC50值的负对数,该值通常与生物活性具有正相关性,即pIC50值越大表明生物活性越高;实际QSAR建模中,一般采用pIC50来表示生物活性值)。该文件另有一个test表(测试集),里面提供有50个化合物的SMILES式。
其次,在文件“Molecular_Descriptor.xlsx”的training表(训练集)中,给出了上述1974个化合物的729个分子描述符信息(即自变量)。其中第一列也是化合物的SMILES式(编号顺序与上表一样),其后共有729列,每列代表化合物的一个分子描述符(即一个自变量)。化合物的分子描述符是一系列用于描述化合物的结构和性质特征的参数,包括物理化学性质(如分子量,LogP等),拓扑结构特征(如氢键供体数量,氢键受体数量等),等等。关于每个分子描述符的具体含义,请参见文件“分子描述符含义解释.xlsx”。同样地,该文件也有一个test表,里面给出了上述50个测试集化合物的729个分子描述符。
最后,在关注化合物生物活性的同时,还需要考虑其ADMET性质。因此,在文件“ADMET.xlsx”的training表(训练集)中,提供了上述1974个化合物的5种ADMET性质的数据。其中第一列也是表示化合物结构的SMILES式(编号顺序与前面一样),其后5列分别对应每个化合物的ADMET性质,采用二分类法提供相应的取值。Caco-2:‘1’代表该化合物的小肠上皮细胞渗透性较好,‘0’代表该化合物的小肠上皮细胞渗透性较差;CYP3A4:‘1’代表该化合物能够被CYP3A4代谢,‘0’代表该化合物不能被CYP3A4代谢;hERG:‘1’代表该化合物具有心脏毒性,‘0’代表该化合物不具有心脏毒性;HOB:‘1’代表该化合物的口服生物利用度较好,‘0’代表该化合物的口服生物利用度较差;MN:‘1’代表该化合物具有遗传毒性,‘0’代表该化合物不具有遗传毒性。同样地,该文件也有一个test表,里面提供有上述50个化合物的SMILES式(编号顺序同上)。
建模目标:根据提供的ERα拮抗剂信息(1974个化合物样本,每个样本都有729个分子描述符变量,1个生物活性数据,5个ADMET性质数据),构建化合物生物活性的定量预测模型和ADMET性质的分类预测模型,从而为同时优化ERα拮抗剂的生物活性和ADMET性质提供预测服务。
3 问题刨析
根据文件“Molecular_Descriptor.xlsx”和“ERα_activity.xlsx”提供的数据,针对1974个化合物的729个分子描述符进行变量选择,根据变量对生物活性影响的重要性进行排序,并给出前20个对生物活性最具有显著影响的分子描述符(即变量),并请详细说明分子描述符筛选过程及其合理性。
简化描述问题:根据特征对IC50值和pIC50值影响的重要性进行排序,并给出前20个对IC50值和pIC50值最具有显著影响的特征
方案:特征选择。
4 Python代码实现——方法1
'''导入相关库'''
import pandas as pd
from sklearn.model_selection import train_test_split #拆分数据集
from sklearn.ensemble import RandomForestRegressor #随机森林
from sklearn.metrics import r2_score #评估模型
import seaborn as sns
import matplotlib
import matplotlib.pyplot as plt
plt.rcParams['font.sans-serif']=['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.rcParams['font.sans-serif'] = ['SimHei'] # 中文字体设置-黑体
plt.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
sns.set(font='SimHei',font_scale=1.5) # 解决Seaborn中文显示问题并调整字体大小
'''读取数据'''
data=pd.read_excel('ERα_activity.xlsx')
data2=pd.read_excel('Molecular_Descriptor.xlsx')
#====两个数据集做列合并==========
data_ER_X = data.drop(["SMILES"], axis=1) # 删除重复特征
data3 = pd.concat([data,data2], axis=1) # 列合并
#res=data3
#res.to_excel('合并数据.xlsx')
#data3=pd.read_excel('合并数据.xlsx')
'''数据处理'''
#===(1)提取特征和目标:============
X = data3.drop(['SMILES','IC50_nM','pIC50'],axis=1) # 特征
y = data3.loc[:, ['IC50_nM','pIC50']] # 目标
#===(2)拆分数据集==============
X_train,X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=100)
#====(3)分别提取两个特征的训练和测试数据:===========
y_IC50_train = y_train.loc[:,"IC50_nM"]
y_pIC50_train = y_train.loc[:,"pIC50"]
y_IC50_test = y_test.loc[:,"IC50_nM"]
y_pIC50_test = y_test.loc[:,"pIC50"]
'''构建模型'''
#使用随机森林构建先预测IC50_nM
#使用随机森林的方法构建模型
rf_model = RandomForestRegressor(n_estimators=100)
rf_model.fit(X_train,y_pIC50_train) # 预测IC50_nM的模型训练
# 评估模型
predict = rf_model.predict(X_train)
print("训练准确度为::",r2_score(y_pIC50_train,predict))
predict = rf_model.predict(X_test)
print("测试准确度为:",r2_score(y_pIC50_test,predict))
'''获取重要性排名:'''
features = X.columns # 读取列命
feature_importances = rf_model.feature_importances_ # 获取每个特征重要性
features_df = pd.DataFrame({'特征':features,'重要性':feature_importances}) #
features_df.sort_values('重要性',inplace=True,ascending=False) # 排序
print(features_df)
#获取重要性最高的前20名:
print(features_df[:20])
'''可视化重要性排名'''
sns.set(rc={"figure.figsize":(23,9)}) # 设置大小
sns.barplot(features_df['特征'][:20],features_df['重要性'][:20]) # 柱形图
plt.ylabel('Importants') # 纵轴标签
plt.xlabel('Features')
sns.despine(bottom=True)
plt.show()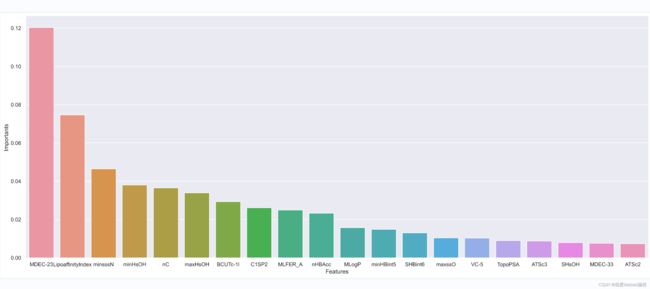
5 Python代码实现——方案2
import xgboost
import pandas as pd
from sklearn.model_selection import train_test_split
from sklearn.metrics import r2_score
from xgboost import XGBRegressor
import numpy as np
from imblearn.metrics import geometric_mean_score
'''读取文件内容'''
input = pd.read_excel(r"Molecular_Descriptor.xlsx", sheet_name="training")
output = pd.read_excel(r'ERα_activity.xlsx',sheet_name='training')
# 区分自变量(X)和因变量(Y)
independentCol = input.columns[1:-1]
dependentCol = output.columns[-1]
X = input[independentCol]
Y = output[dependentCol]
# 修改自变量名称为正整数,为后面的训练做准备
numForCol = [i for i in range(0, len(independentCol), 1)]
colReplace = dict(zip(independentCol, numForCol))
X = X.rename(columns=colReplace)
'''随机获得训练集和测试集'''
x_train, x_test, y_train, y_test = train_test_split(X, Y, test_size=0.8, shuffle=True)
'''初始化 gmean(0) 和 指标组合(空)'''
gmean = 0
feaFinal = set()
# 不断简化指标组合,以获得最优指标集
while (1):
# 按步骤二随机抽取80%样本,进行只保留重要性大于0的指标
x_1, _, y_1, _ = train_test_split(x_train, y_train, test_size=0.8, shuffle=True)
m1 = xgboost.XGBRegressor(use_label_encoder=False)
m1.fit(x_1, y_1) # 讲样本放入XGBoost
f1 = dict(zip(x_1.columns, m1.feature_importances_)) # 讲指标序号和重要性分数进行对应
f1 = {k: v for (k, v) in f1.items() if v > 0} # 保留重要性分数大于0的指标
f1 = set(f1.keys()) # 讲指标序号以set形式存放
# 步骤三,与步骤二相似,获得另一组指标
x_2, _, y_2, _ = train_test_split(x_train, y_train, test_size=0.8, shuffle=True)
m2 = xgboost.XGBRegressor(use_label_encoder=False)
m2.fit(x_2, y_2)
f2 = dict(zip(x_2.columns, m2.feature_importances_))
f2 = {k: v for (k, v) in f2.items() if v > 0}
f2 = set(f2.keys())
# 取两个指标组的交集,并将该交集放入XGBoost
featureUnion = f1.union(f2)
x_train = x_train[featureUnion]
x_test = x_test[featureUnion]
model = xgboost.XGBRegressor(use_label_encoder=False)
model.fit(x_train, y_train)
y_pred = model.predict(x_test) # 进行预测
# 利用预测结果和y_test, 计算gmean
gmean_new = r2_score(y_test, y_pred)
# 若新计算的gmean上次小或一样,则优化结束
if gmean_new <= gmean:
break
# 否则,更新最佳的gmean和指标选择
else:
gmean = gmean_new
feaFinal = featureUnion
# print("Update: " + str(gmean_new))
# print("Update: " + str(feaFinal))
findName = {v: k for k, v in colReplace.items()}
feaFinal = sorted(feaFinal)
SelectedFeatures = [findName[i] for i in feaFinal]
# print("指标集最优解:" + str(SelectedFeatures))
# print("最后G-mean: " + str(gmean))
col_im = str(SelectedFeatures)
import pandas as pd
from xgboost import XGBClassifier,XGBRegressor
import numpy as np
from sklearn.model_selection import train_test_split
from sklearn.ensemble import RandomForestRegressor
file_label_act = r'ERα_activity.xlsx'
file_feature = r'Molecular_Descriptor.xlsx'
data_label_activity = pd.read_excel(file_label_act,sheet_name='training')
data_feature = pd.read_excel(file_feature,sheet_name='training')
x = np.array(data_feature.iloc[:,1:])
y = np.array(data_label_activity.iloc[:,-1])
x_train,x_val,y_train,y_val = train_test_split(x,y,test_size=0.1)
#随机森林
# cls = XGBRegressor()
cls = RandomForestRegressor()
cls.fit(x_train,y_train)
f = cls.feature_importances_
f_l = data_feature.columns.tolist()
# print('集成学习筛选特征前模型的得分效果:',cls.score(x_val,y_val))
dic_ = {j:i for i,j in zip(f,f_l)}
d_order=sorted(dic_.items(),key=lambda x:x[1],reverse=True) # 按字典集合中,每一个元组的第二个元素排列。 # x相当于字典集合中遍历出来的一个元组。
col_rf = [i[0] for i in d_order[:30]]
#Xgboost
cls = XGBRegressor()
cls.fit(x_train,y_train)
f = cls.feature_importances_
f_l = data_feature.columns.tolist()
# print('集成学习筛选特征前模型的得分效果:',cls.score(x_val,y_val))
dic_ = {j:i for i,j in zip(f,f_l)}
d_order=sorted(dic_.items(),key=lambda x:x[1],reverse=True) # 按字典集合中,每一个元组的第二个元素排列。 # x相当于字典集合中遍历出来的一个元组。
col_xg = [i[0] for i in d_order[:30]]
print('rf:',len(col_rf),'xg:',len(col_xg),'im:',len(col_im))
col_xg_ = []
for i in col_rf:
if i in col_xg:
col_xg_.append(i)
print('xg:',len(col_xg_),col_xg_)
col_im_ = []
for i in col_rf:
if i in col_im:
col_im_.append(i)
print('im:',len(col_im_),col_im_)
col_xg_im = []
for i in col_rf:
if i in col_im or i in col_xg:
col_xg_im.append(i)
print('xg or im:',len(col_xg_im),col_xg_im)
col_xg_im_and = []
for i in col_rf:
if i in col_im and i in col_xg:
col_xg_im_and.append(i)
print('xg and im:',len(col_xg_im_and),col_xg_im_and)
col_ = col_xg_im_and.copy()
x = np.array(data_feature[col_])
y = np.array(data_label_activity.iloc[:,-1])
x_train,x_val,y_train,y_val = train_test_split(x,y,test_size=0.1)
cls = RandomForestRegressor()
cls.fit(x_train,y_train)
print('集成学习筛选特征前模型的得分效果:',cls.score(x_val,y_val))
for i in col_xg_:
if i not in col_:
col_.append(i)
for i in col_im_:
if i not in col_:
col_.append(i)
col_ = col_[:20]