Pandas数据的输入与输出:CSV文件
文章目录
-
- 简介
- 读取csv文件
- 写入csv文件
简介
Pandas支持多种格式的文件输入与输出,常用的有文本文件、excel文件,MySQL数据库。会分别讲解csv文件的读取和写入,excel文件的读取和写入,MySQL数据库表的读取和写入。
读取csv文件
使用read_csv()函数读取csv文件 ,语法如下:
pandas.read_csv(filepath_or_buffer, sep=NoDefault.no_default, delimiter=None, header='infer', names=NoDefault.no_default, index_col=None, usecols=None, squeeze=None, prefix=NoDefault.no_default, mangle_dupe_cols=True, dtype=None, engine=None, converters=None, true_values=None, false_values=None, skipinitialspace=False, skiprows=None, skipfooter=0, nrows=None, na_values=None, keep_default_na=True, na_filter=True, verbose=False, skip_blank_lines=True, parse_dates=None, infer_datetime_format=False, keep_date_col=False, date_parser=None, dayfirst=False, cache_dates=True, iterator=False, chunksize=None, compression='infer', thousands=None, decimal='.', lineterminator=None, quotechar='"', quoting=0, doublequote=True, escapechar=None, comment=None, encoding=None, encoding_errors='strict', dialect=None, error_bad_lines=None, warn_bad_lines=None, on_bad_lines=None, delim_whitespace=False, low_memory=True, memory_map=False, float_precision=None, storage_options=None)
部分常用参数说明:
- filepath_or_buffer:接收字符串或者路径对象,读取文件的路径和文件名。
- sep:接收字符串,分隔符,默认逗号。
- delimiter:接收字符串,分隔符的别名。
- header:接收整数或者整数构成的列表,默认值为infer。用作列名的行号,以及数据的开头。默认行为是推断列名:
- 如果names没有传递任何名称,则该行为与header=0相同,并且从文件的第一行推断列名;
- 如果显式传递列名,则该行为与header=None相同。显式传递header=0以替换现有名称。标题可以是整数列表,指定列上多索引的行位置,例如[0,1,3]。未指定的中间行将被跳过。请注意,如果skip_blank_lines=True,此参数将忽略注释行和空行,因此header=0表示数据的第一行,而不是文件的第一行。
- names:接收array-like,列名的列表,不能有重复值存在。
- index_col:接收整数,字符串,整数或者字符串构成的序列,使用哪一列作为行索引,可以设置复合行索引。
- usecols:接收list-like,返回列名的子集,选择使用哪些列。
返回值:
- DataFrame or TextParser
示例:
- 数据自带列名
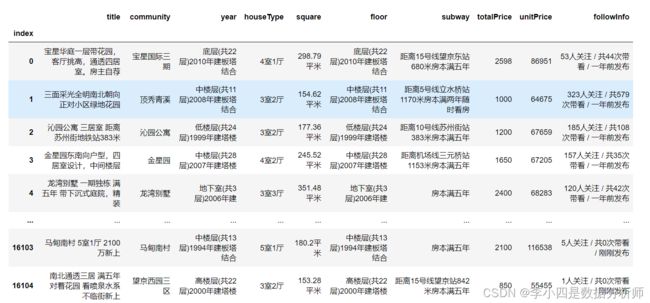
使用北京二手房数据作为示例,数据自带列名时可以直接导入,使用原数据中的index列作为行索引,代码如下:
house = pd.read_csv('house.csv', index_col='index')
# 如果未设置index_col参数,导入后的数据会显示系统给的隐式索引
导入的数据如图所示:
选择使用数据中的某些列:
# 创建列表,选择某些列,未使用floor列
usecol =['index','title','community','year','houseType','square','subway','totalPrice','unitPrice','followInfo']
house = pd.read_csv('house.csv', index_col='index', usecols=usecol)
导入的数据如图所示:
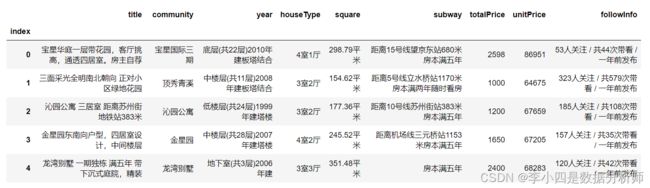
需要注意的是如果需要设置参数index_col为数据中的某一列,在参数usecols中必须有这一列存在,否则会报错。
- 数据未带列名
同样使用北京二手房数据,将数据中的列名删除,此时会将第一行的数据默认为列名,示例如下:
data = pd.read_csv('house_no_name.csv')
导入的数据如图所示:

以上这种方法肯定是有问题的,不能使用第一行数据作为数据的列名。只需要为names参数传入自己设置的列名即可,示例如下:
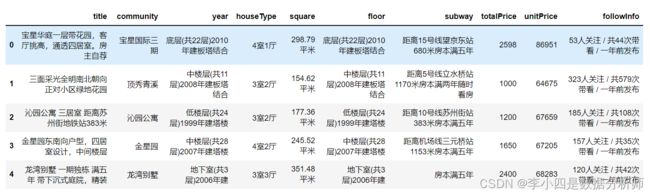
# 创建name_list
name_list = ['title','community','year','houseType','square','floor','subway','totalPrice','unitPrice','followInfo']
data = pd.read_csv('house_no_name.csv', names=name_list)
data.head()
导入的数据如图所示:
以上是读取csv文件的常用方法,如果数据中存在问题时也可以通过手动修改原数据,可以减少读取的代码。除此以外read_csv()函数中还有非常多的其他参数可以实现各种功能,可以对日期型列进行解析等,此处不详细介绍。
写入csv文件
同样可以使用to_csv()函数将整理好的数据写入到csv文件中,使用方法简单,具体语法如下:
DataFrame.to_csv(path_or_buf=None, sep=',', na_rep='', float_format=None, columns=None, header=True, index=True, index_label=None, mode='w', encoding=None, compression='infer', quoting=None, quotechar='"', line_terminator=None, chunksize=None, date_format=None, doublequote=True, escapechar=None, decimal='.', errors='strict', storage_options=None)
参数说明:
- path_or_buf:接收字符换或者路径对象,写入保存文件的路径和文件名。
- sep:接收字符串,默认为逗号。
- na_rep:接收字符串,默认为空字符串,空值的表现。
- columns:接收序列,要写入的列。
- header:接收布尔值或者字符串构成的列表,输出的列名。
- index:接收布尔值,默认为True,是否写入行索引。
- index_label:接收字符串或者序列,或者False,默认为None。
- mode:接收字符串,Python写入模式,默认’w’。
- encoding:接收字符串,编码格式,默认’utf-8’。
以上只介绍了常用参数,其他参数可以根据需要参考官方文档使用。
示例:
从sklearn库中下载加利福尼亚房屋数据,将数据整理成为DataFrame后存入到csv文件中。
# 导包
from sklearn.datasets import fetch_california_housing
housing = fetch_california_housing()
housing
读取后housing为一个字典,如图所示:

其中键’data’为数据,‘target’为数据标签,将’data’,‘target’,‘feature_names’,'target_names’提取出来,合并成为一个DataFrame。操作代码如下所示:
# 将数据赋值给变量x
x = housing['data']
# 将数据标签赋值给变量y
y = housing['target'].reshape(-1,1)
# 将feature_names和target_names合并到一个列表中
housing['feature_names'].extend(housing['target_names'])
# 为合并后的housing['feature_names']命名
column = housing['feature_names']
column
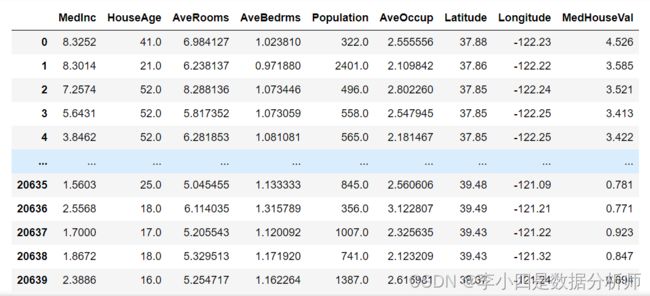
# 将数组x和y合并,并且创建DataFrame,将column列表作为df的列名
df1 = pd.DataFrame(np.concatenate((x,y),axis=1),columns=column)
df1
处理后的df1如图所示:
将df1保存为csv文件,代码如下:
df1.to_csv('california_housing.csv')
保存后的csv文件如图:
