大数据关键技术:自然语言处理入门篇
分词与词向量#
自然语言处理简介#
自然语言处理概况#
什么是自然语言处理?
自然语言处理( Natural Language Processing, NLP)是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法。自然语言处理是一门融语言学、计算机科学、数学于一体的科学。
自然语言处理主要应用于机器翻译、舆情监测、自动摘要、观点提取、文本分类、问题回答、文本语义对比、语音识别、中文OCR等方面。
(1) 计算机将自然语言作为输入或输出:
- 输入对应的是自然语言理解;
- 输出对应的是自然语言生成;
(2) 关于NLP的多种观点:
- A、人类语言处理的计算模型:
- ——程序内部按人类行为方式操作
- B、 人类交流的计算模型:
- ——程序像人类一样交互
- C、有效处理文本和语音的计算系统
(3) NLP的应用:
A、机器翻译(Machine Translation)…….
B、MIT翻译系统(MIT Translation System)……
C、文本摘要(Text Summarization)……
D、对话系统(Dialogue Systems)……
E、其他应用(Other NLP Applications):
——语法检查(Grammar Checking)
——情绪分类(Sentiment Classification)
——ETS作文评分(ETS Essay Scoring)
自然语言处理相关问题#
为什么自然语言处理比较难?
(1) 歧义
“At last, a computer that understands you like your mother”
对于这句话的理解:
A、 它理解你就像你的母亲理解你一样;
B、 它理解你喜欢你的母亲;
C、 它理解你就像理解你的母亲一样
D、 我们来看看Google的翻译:终于有了一台像妈妈一样懂你的电脑(看上去Google的理解更像选项A)。
A到C这三种理解好还是不好呢?
(2) 不同层次的歧义
A、 声音层次的歧义——语音识别:
——“ ... a computer that understands you like your mother”
——“ ... a computer that understands you lie cured mother”
B、语义(意义)层次的歧义:
Two definitions of “mother”:
——a woman who has given birth to a child
——a stringy slimy substance consisting of yeast cells and bacteria; is added to cider or wine to produce vinegar
C、话语(多语)层次的歧义、句法层次的歧义:
NLP的知识瓶颈
我们需要:
——有关语言的知识;
——有关世界的知识;
可能的解决方案:
——符号方法 or 象征手法:将所有需要的信息在计算机里编码;
——统计方法:从语言样本中推断语言特性;
(1)例子研究:限定词位置
任务:在文本中自动地放置限定词
样本:Scientists in United States have found way of turning lazy monkeys into workaholics using gene therapy. Usually monkeys work hard only when they know reward is coming, but animals given this treatment did their best all time. Researchers at National Institute of Mental Health near Washington DC, led by Dr Barry Richmond, have now developed genetic treatment which changes their work ethic markedly. ”Monkeys under influence of treatment don’t procrastinate,” Dr Richmond says. Treatment consists of anti-sense DNA - mirror image of piece of one of our genes - and basically prevents that gene from working. But for rest of us, day when such treatments fall into hands of our bosses may be one we would prefer to put off.
(2)相关语法规则
a) 限定词位置很大程度上由以下几项决定:
i. 名词类型-可数,不可数;
ii. 照应-特指,类指;
iii. 信息价值-已有,新知
iv. 数词-单数,复数
b) 然而,许多例外和特殊情况也扮演着一定的角色,如:
i. 定冠词用在报纸名称的前面,但是零冠词用在杂志和期刊名称前面
(3) 符号方法方案
a) 我们需要哪些类别的知识:
i. 语言知识:
-静态知识:数词,可数性,…
-上下文相关知识:共指关系
ii. 世界知识:
- 引用的唯一性(美国现任总统),名词的类型(报纸与杂志),名词之间的情境关联性(足球比赛的得分),......
iii. 这些信息很难人工编码!
(4)统计方法方案
a) 朴素方法:
i. 收集和你的领域相关的大量的文本
ii. 对于其中的每个名词,计算它和特定的限定词一起出现的概率
iii. 对于一个新名词,依据训练语料库中最高似然估计选择一个限定词
b) 实现:
i. 语料:训练——华尔街日报(WSJ)前21节语料,测试——第23节
ii. 预测准确率:71.5%
c) 结论:
i. 结果并不是很好,但是对于这样简单的方法结果还是令人吃惊
ii. 这个语料库中的很大一部分名词总是和同样的限定词一起出现,如:
-“the FBI”,“the defendant”, ...
(5)作为分类问题的限定词位置
a) 预测:
b) 代表性的问题:
i. 复数?(是,否)
ii. 第一次在文本中出现?
iii. 名词(词汇集的成员)
c) 图表例子略
d) 目标:学习分类函数以预测未知例子
(6)分类方法
a) 学习X->Y的映射函数
b) 假设已存在一些分布D(X,Y)
c) 尝试建立分布D(X,Y)和D(X|Y)的模型
(7)分类之外
a) 许多NLP应用领域可以被看作是从一个复杂的集合到另一个集合的映射:
i. 句法分析: 串到树
ii. 机器翻译: 串到串
iii. 自然语言生成:数据词条到串
b) 注意,分类框架并不适合这些情况!
自然语言处理:单词计数#
语料库及其性质#
(1) 什么是语料库(Corpora)
i. 一个语料库就是一份自然发生的语言文本的载体,以机器可读形式存储;
(2) 单词计数(Word Counts)
i. 在文本中最常见的单词是哪些?
ii. 在文本中有多少个单词?
iii. 在大规模语料库中单词分布的特点是什么?
(3) 我们以马克吐温的《汤姆索耶历险记》为例:
单词(word) 频率(Freq) 用法(Use)
the 3332 determiner (article)
and 2972 conjunction
a 1775 determiner
to 1725 preposition, inf. marker
of 1440 preposition
was 1161 auxiliary verb
it 1027 pronoun
in 906 preposition
that 877 complementizer
Tom 678 proper name
虚词占了大多数
(4) 这个例句里有多少个单词:
They picnicked by the pool, then lay back on the grass and looked at the stars.
i. “型”(Type) ——语料库中不同单词的数目,词典容量
ii. “例”(Token) — 语料中总的单词数目
iii. 注:以上定义参考自《自然语言处理综论》
iv. 汤姆索耶历险记(Tom Sawyer)中有:
1. 词型— 8, 018
2. 词例— 71, 370
3. 平均频率— 9(注:词例/词型)
(5) 词频的频率:
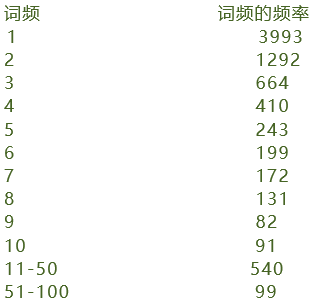
大多数词在语料库中仅出现一次!
自然语言处理的一般步骤#
(1) 文本预处理(分词、去除停用词、词干化)
(2) 统计词频
(3) 文本向量化
分词相关知识#
(1) Tokenization
i. 目标:将文本切分成单词序列
ii. 单词指的是一串连续的字母数字并且其两端有空格;可能包含连字符和撇号但是没有其它标点符号
iii. Tokenizatioan 容易吗?
(2) 什么是词?
i. English:
1. “Wash. vs wash”
2. “won’t”, “John’s”
3. “pro-Arab”, “the idea of a child-as-required-yuppie-possession must be motivating them”, “85-year-old grandmother”
ii. 东亚语言:
词之间没有空格
(3) 分词(Word Segmentation)
i. 基于规则的方法: 基于词典和语法知识的形态分析
ii. 基于语料库的方法: 从语料中学习(Ando&Lee, 2000))
iii. 需要考虑的问题: 覆盖面,歧义,准确性
1.基于词典:基于字典、词库匹配的分词方法;(字符串匹配、机械分词法)
2.基于统计:基于词频度统计的分词方法;
3.基于规则:基于知识理解的分词方法。
中文分词——jieba分词#
中文分词是中文文本处理的一个基础步骤,也是中文人机自然语言交互的基础模块,在进行中文自然语言处理时,通常需要先进行分词。
中文在基本文法上有其特殊性,具体表现在:
1.与英文为代表的拉丁语系语言相比,英文以空格作为天然的分隔符,而中文由于继承自古代汉语的传统,词语之间没有分隔。 古代汉语中除了连绵词和人名地名等,词通常就是单个汉字,所以当时没有分词书写的必要。而现代汉语中双字或多字词居多,一个字不再等同于一个词。
2.在中文里,“词”和“词组”边界模糊
现代汉语的基本表达单元虽然为“词”,且以双字或者多字词居多,但由于人们认识水平的不同,对词和短语的边界很难去区分。
例如:“对随地吐痰者给予处罚”,“随地吐痰者”本身是一个词还是一个短语,不同的人会有不同的标准,同样的“海上”“酒厂”等等,即使是同一个人也可能做出不同判断,如果汉语真的要分词书写,必然会出现混乱,难度很大。
jieba分词算法使用了基于前缀词典实现高效的词图扫描,生成句子中汉字所有可能生成词情况所构成的有向无环图(DAG), 再采用了动态规划查找最大概率路径,找出基于词频的最大切分组合,对于未登录词,采用了基于汉字成词能力的HMM模型,使用了Viterbi算法。
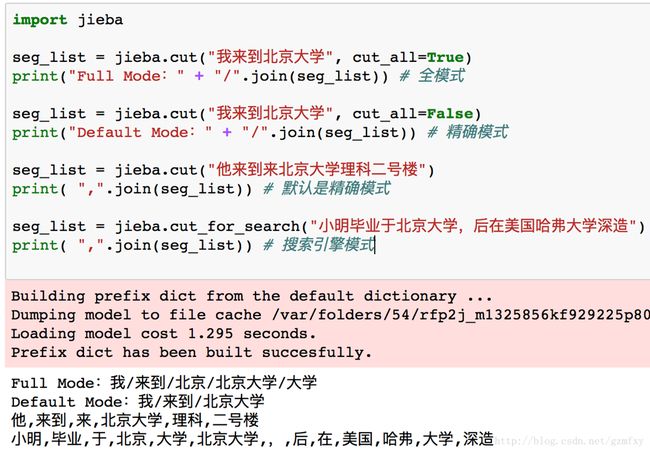
jieba分词支持三种分词模式:
-
精确模式, 试图将句子最精确地切开,适合文本分析:
-
全模式,把句子中所有的可以成词的词语都扫描出来,速度非常快,但是不能解决歧义;
-
搜索引擎模式,在精确模式的基础上,对长词再词切分,提高召回率,适合用于搜索引擎分词。
jieba分词还支持繁体分词和支持自定义分词。
jieba分词器安装#
在python2.x和python3.x均兼容,有以下三种:
-
全自动安装:easy_install jieba 或者 pip install jieba / pip3 install jieba
-
半自动安装: 先下载,网址为: http://pypi.python.org/pypi/jieba, 解压后运行: python setup.py install
-
手动安装: 将jieba目录放置于当前目录或者site-packages目录,
jieba分词可以通过import jieba 来引用
jieba分词主要功能#
先介绍主要的使用功能,再展示代码输出。jieba分词的主要功能有如下几种:
-
jieba.cut:该方法接受三个输入参数:需要分词的字符串; cut_all 参数用来控制是否采用全模式;HMM参数用来控制是否适用HMM模型
-
jieba.cut_for_search:该方法接受两个参数:需要分词的字符串;是否使用HMM模型,该方法适用于搜索引擎构建倒排索引的分词,粒度比较细。
-
待分词的字符串可以是unicode或者UTF-8字符串,GBK字符串。注意不建议直接输入GBK字符串,可能无法预料的误解码成UTF-8,
-
jieba.cut 以及jieba.cut_for_search返回的结构都是可以得到的generator(生成器), 可以使用for循环来获取分词后得到的每一个词语或者使用
-
jieb.lcut 以及 jieba.lcut_for_search 直接返回list
-
jieba.Tokenizer(dictionary=DEFUALT_DICT) 新建自定义分词器,可用于同时使用不同字典,jieba.dt为默认分词器,所有全局分词相关函数都是该分词器的映射。
jieba分词器添加自定义词典#
jieba分词器还有一个方便的地方是开发者可以指定自己的自定义词典,以便包含词库中没有的词,虽然jieba分词有新词识别能力,但是自行添加新词可以保证更高的正确率。
使用命令:
jieba.load_userdict(filename) # filename为自定义词典的路径
在使用的时候,词典的格式和jieba分词器本身的分词器中的词典格式必须保持一致,一个词占一行,每一行分成三部分,一部分为词语,一部分为词频,最后为词性(可以省略),用空格隔开。下面其中userdict.txt中的内容为小修添加的词典,而第二部分为小修没有添加字典之后对text文档进行分词得到的结果,第三部分为小修添加字典之后分词的效果。

这里介绍基于TF-IDF算法的关键词抽取, 只有关键词抽取并且进行词向量化之后,才好进行下一步的文本分析,可以说这一步是自然语言处理技术中文本处理最基础的一步。
jieba分词中含有analyse模块,在进行关键词提取时可以使用下列代码
import jieba.analyse
jieba.analyse.extrac_tags(sentence,topK=20,withweight=False,allowPos=())
#sentence为待提取的文本,
#toPK为返回几个TF/tDF权重最大的关键词,默认值为20
#withweight为是否一并返回关键词权重值,默认值为False
#a11 owPOS仅包含指定词性的词,默认值为空,既不筛选
jieba.analyse.TFIDF(idf_path=None)#新建rF-IDF实例,idf path为IDF频率文件
jieba.analyse.textrank(sentence,topK=20,withweight=False,allowPOS=('ns','n','vn','v'))
#直接使用,接口相同,注意磨人过滤词性
jieba.analyse.TextRank()
#新建自定义TextRank.实例
基本思想:
1、将待抽取关键词的文本进行分词
2、以固定窗口大小(默认为5,通过span属性调整),词之间的共现关系,构建图计算图中节点的PageRank,注意是无向带权图
利用jieba进行关键词抽取#
一个例子:分别使用两种方法对同一文本进行关键词抽取,并且显示相应的权重值。

jieba分词的词性标注#
jieba分词还可以进行词性标注,标注句子分词后每个词的词性,采用和ictclas兼容的标记法,这里知识简单的句一个列子。

#jieba.posseg.POSTokenizer(tokenizer=None)
#新建自定义分词器,tokenizer参数可以指定内部使用的
#jieba.Tokenizer分词器,jieba.posseg.dt为默认词性标注分词器
import jieba.posseg as pseg
words=pseg.cut("我爱北京大学")
for word,flag in words:
print('%s %s' %(word,flag))
文本向量化表示#
文本表示是自然语言处理中的基础工作,文本表示的好坏直接影响到整个自然语言处理系统的性能。文本向量化就是将文本表示成一系列能够表达文本语义的向量,是文本表示的一种重要方式。目前对文本向量化大部分的研究都是通过词向量化实现的,也有一部分研究者将句子作为文本处理的基本单元,于是产生了doc2vec和str2vec技术。
词袋模型#
词袋模型和表示方法
从书店图书管理员谈起。假设书店有3排书架,分别摆放“文学艺术”、“教育考试”、“烹饪美食”3种主题的书籍,现在新到了3本书分别是《唐诗三百首》、《英语词汇》《中式面点》,你是一名图书管理员,要怎样将这些书摆放到合适的书架上呢?实际上你摆放图书的过程就是分类的过程。如下图所示:
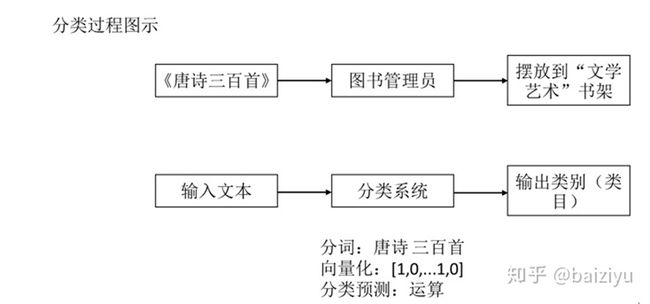
文本向量化表示就是用数值向量来表示文本的语义。文本分类领域使用了信息检索领域的词袋模型,词袋模型在部分保留文本语义的前提下对文本进行向量化表示。

One-Hot表示法
One-Hot表示法的数值计算规则为:词语序列中出现的词语其数值为1,词语序列中未出现的词语其数值为0。用数学式子表达为:
文本含有词项文本不含词项wj={1, 文本含有词项 j0, 文本不含词项 j.
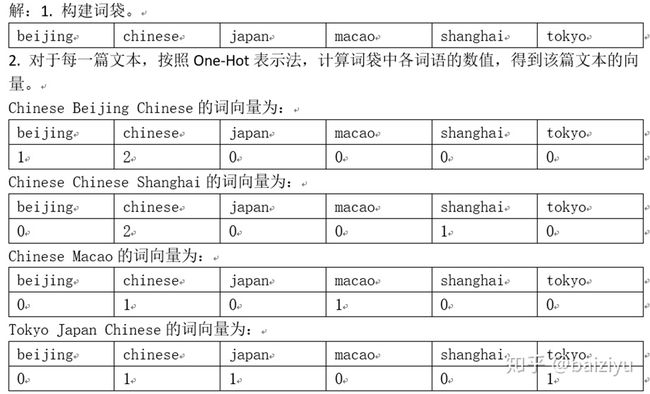
例1 已知有下边的几篇英文文本,请用词袋模型One-Hot法向量化表示每篇文本。

从以上介绍可以看到,词袋模型的One-Hot表示法考虑了都有哪些词在文本中出现,用出现的词语来表示文本的语义。

TF表示法
TF表示法的数值计算规则为:词语序列中出现的词语其数值为词语在所在文本中的频次,词语序列中未出现的词语其数值为0。用数学式子表达为:
文本含有词项文本不含词项wj={count(tj), 文本含有词项 j0, 文本不含词项 j
其中,t表示词语j,count(t)表示词语j在所在文本出现的次数。
从以上介绍可以看到,词袋模型的TF表示法除了考虑都有哪些词在文本中出现外,还考虑了词语出现的频次,用出现词语的频次来突出文本主题进而表示文本的语义。
TF-IDF表示法
TF-IDF表示法的数值计算规则为:词语序列中出现的词语其数值为词语在所在文本中的频次乘以词语的逆文档频率,词语序列中未出现的词语其数值为0。用数学式子表达为:
文本含有词项文本不含词项wj={count(tj)×idf(tj), 文本含有词项 j0, 文本不含词项 j

例2 已知有下边的几篇英文文本,请用词袋模型TF法向量化表示每篇文本。文本同例1

IDF值计算过程

非词袋模型#
词袋(Bag Of Word)模型是最早的以词语为基础处理单元的文本项量化方法。该模型产生的向量与原来文本中单词出现的顺序没有关系,而是词典中每个单词在文本中出现的频率。该方法虽然简单易行,但是存在如下三个方面的问题:维度灾难,无法保留词序信息,存在语义鸿沟。
神经网络语言模型(Neural Network Language Model,NNLM)与传统方法估算的不同在于直接通过一个神经网络结构对n元条件概率进行估计。
由于NNLM模型使用低维紧凑的词向量对上下文进行表示,解决了词袋模型带来的数据稀疏、语义鸿沟等问题。
另一方面,在相似的上下文语境中,NNLM模型可以预测出相似的目标词,而传统模型无法做到这一点。
例如,如果在语料中A=“小狗在院子里趴着”出现1000次,B=“小猫在院子里趴着”出现1次。A和B的唯一区别就是狗和猫,两个词无论在语义还是语法上都相似。根据频率来估算概率P(A)>>P(B),这显然不合理。如果采用NNLM计算P(A)~P(B),因为NNLM模型采用低维的向量表示词语,假定相似的词其词向量也相似。
Word2Vec是从大量文本语料中以无监督的方式学习语义知识的一种模型,它被大量地用在自然语言处理(NLP)中。
Word2Vec模型中,主要有Skip-Gram和CBOW两种模型,从直观上理解,Skip-Gram是给定input word来预测上下文。而CBOW是给定上下文,来预测input word。

Word2Vec模型实际上分为了两个部分,第一部分为建立模型,第二部分是通过模型获取嵌入词向量。Word2Vec的整个建模过程实际上与自编码器(auto-encoder)的思想很相似,即先基于训练数据构建一个神经网络,当这个模型训练好以后,我们并不会用这个训练好的模型处理新的任务,我们真正需要的是这个模型通过训练数据所学得的参数,例如隐层的权重矩阵。
模型的输出概率代表着到我们词典中每个词有多大可能性跟input word同时出现。举个例子,如果我们向神经网络模型中输入一个单词“Soviet“,那么最终模型的输出概率中,像“Union”, ”Russia“这种相关词的概率将远高于像”watermelon“,”kangaroo“非相关词的概率。因为”Union“,”Russia“在文本中更大可能在”Soviet“的窗口中出现。

我们的模型将会从每对单词出现的次数中习得统计结果。例如,我们的神经网络可能会得到更多类似(“Soviet“,”Union“)这样的训练样本对,而对于(”Soviet“,”Sasquatch“)这样的组合却看到的很少。因此,当我们的模型完成训练后,给定一个单词”Soviet“作为输入,输出的结果中”Union“或者”Russia“要比”Sasquatch“被赋予更高的概率。
如果两个不同的单词有着非常相似的“上下文”(也就是窗口单词很相似,比如“Kitty climbed the tree”和“Cat climbed the tree”),那么通过我们的模型训练,这两个单词的嵌入向量将非常相似。
那么两个单词拥有相似的“上下文”到底是什么含义呢?
比如对于同义词“intelligent”和“smart”,我们觉得这两个单词应该拥有相同的“上下文”。而例如”engine“和”transmission“这样相关的词语,可能也拥有着相似的上下文。
实际上,这种方法实际上也可以帮助你进行词干化(stemming),例如,神经网络对”ant“和”ants”两个单词会习得相似的词向量。
词干化(stemming)就是去除词缀得到词根的过程。
主题挖掘#
LDA主题模型基本知识#
文本挖掘背景知识#
什么是文本挖掘?
- 计算机通过高级数据挖掘和自然语言处理,对非结构化的文字进行机器学习。
- 文本数据挖掘包含但不局限以下几点:
- 主题挖掘
- 文本分类
- 文本聚类
- 语义库的搭建
在机器学习和自然语言处理等领域,主题挖掘是寻找是主题模型,主题模型是用来在一系列文档中发现抽象主题的一种统计模型。
如果一篇文章有一个中心思想,那么一些特定词语会更频繁的出现。简单而言,主题挖掘就是要找到表达文章中心思想的主题词。
从大量文字中找到主题是一个高度复杂的工作,不仅因为人的自然语言具有多层面特性,而且很难找到准确体现资料核心思想的词语。
主题挖掘的现有方案如下:
- TF-IDF(Term Frequency–Inverse Document Frequency)
- 共现关系(co-occurrence)
- LDA(隐含狄利克雷分布Latent Dirichlet allocation)
但是这些算法也存在一定的局限性:要么是无法做到只提炼出重要主题,要么是不具高度扩展性和高效性。
TF-IDF
TF-IDF(term frequency–inverse document frequency,词频-逆向文件频率)是一种用于信息检索(information retrieval)与文本挖掘(text mining)的常用加权技术。
TF-IDF是一种统计方法,用以评估一字词对于一个文件集或一个语料库中的其中一份文件的重要程度。字词的重要性随着它在文件中出现的次数成正比增加,但同时会随着它在语料库中出现的频率成反比下降。
TF-IDF的主要思想是:如果某个单词在一篇文章中出现的频率TF高,并且在其他文章中很少出现,则认为此词或者短语具有很好的类别区分能力,适合用来分类。
- TF是词频(Term Frequency)
词频(TF)表示词条(关键字)在文本中出现的频率。
这个数字通常会被归一化(一般是词频除以文章总词数), 以防止它偏向长的文件。

- IDF是逆向文件频率(Inverse Document Frequency)
逆向文件频率 (IDF) :某一特定词语的IDF,可以由总文件数目除以包含该词语的文件的数目,再将得到的商取对数得到。
如果包含词条t的文档越少, IDF越大,则说明词条具有很好的类别区分能力。

- TF-IDF实际上是:TF * IDF
某一特定文件内的高词语频率,以及该词语在整个文件集合中的低文件频率,可以产生出高权重的TF-IDF。因此,TF-IDF倾向于过滤掉常见的词语,保留重要的词语。
- TF-IDF应用
(1)搜索引擎;
(2)关键词提取;
(3)文本相似性;
(4)文本摘要
Python如何实现TF-IDF算法: NLTK、 Sklearn、 Jieba
Co-occurrence(共现关系)
共词关系分析方法在网络研究中应用普遍,通常利用单元(如词汇、人物和机构等)之间的共现关系构建共现矩阵,进而映射为共现关系网络并可视化,从而来揭示某领域的热点与趋势、结构与演化等。
在大规模语料中,若两个词经常共同出现(共现)在截取的同一单元(如一定词语间隔/一句话/一篇文档等)中,则认为这两个词在语义上是相互关联的,而且,共现的频率越高,其相互间的关联越紧密。
两个词共同出现的次数越多,网络图中两个词语节点连线越粗,也就是共现的次数为边上的权值
其次,单个词出现的次数越多,在网络图中节点越大,若一个词与许多词均有联系,则这个词会在网络图的中心区域。
在文本挖掘中,有共现矩阵的概念,如下
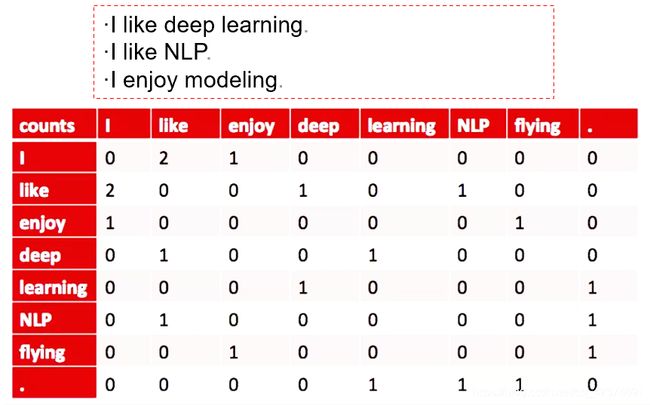
案例:
利用Python构建共现关系分析大江大河2弹幕数据

导入Gephi 制作网络图
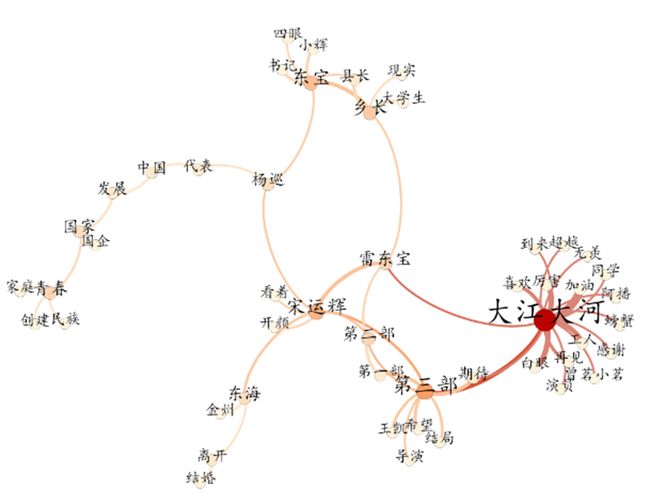
案例:利用共现关系分析微生物群落中菌群之间的生态学关系
什么是LDA主题模型#
介绍#
- 关于LDA有两种含义,一种是线性判别分析(Linear Discriminant Analysis),一种是概率主题模型:隐含狄利克雷分布(Latent Dirichlet Allocation,简称LDA),我们讲后者。
- 按照wiki上的介绍,LDA由Blei, David M.、Ng, Andrew Y.、Jordan于2003年提出,是一种在PLSA基础上改进的主题模型,它可以将文档集中每篇文档的主题以概率分布的形式给出,从而通过分析一些文档抽取出它们的主题(分布)出来后,便可以根据主题(分布)进行主题聚类或文本分类。同时,它是一种典型的词袋模型,即一篇文档是由一组词构成,词与词之间没有先后顺序的关系。
- 研表究明,汉字的序顺并不定一能影阅响读。比如当你看完这句话后,才发这现里的字,全是都乱的。
- 此外,一篇文档可以包含多个主题,文档中每一个词都由其中的一个主题生成。
人类是怎么生成文档的呢?LDA的这三位作者在原始论文中给了一个简单的例子。比如假设事先给定了这几个主题:Arts、Budgets、Children、Education,然后通过学习训练,获取每个主题Topic对应的词语。如下图所示:

然后以一定的概率选取上述某个主题,再以一定的概率选取那个主题下的某个单词,不断的重复这两步,最终生成如下图所示的一篇文章(其中不同颜色的词语分别对应上图中不同主题下的词):

当我们看到一篇文章后,往往喜欢推测这篇文章是如何生成的,我们可能会认为作者先确定这篇文章的几个主题,然后围绕这几个主题遣词造句,表达成文。
LDA就是要干这事:根据给定的一篇文档,推测其主题分布。
通俗来说,可以假定认为人类是根据上述文档生成过程写成了各种各样的文章,现在某小撮人想让计算机利用LDA干一件事:你计算机给我推测分析网络上各篇文章分别都写了些什么主题,且各篇文章中各个主题出现的概率大小(主题分布)是什么。
数学背景知识#
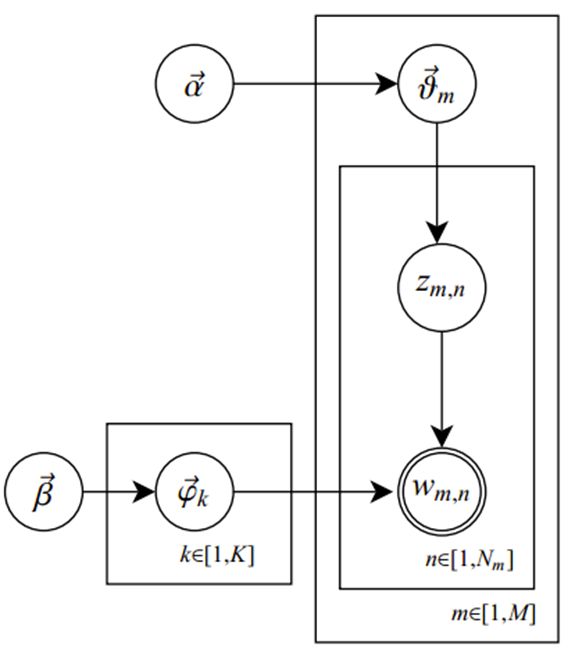
在LDA模型中,一篇文档生成的方式如下:
- 从狄利克雷分布中取样生成文档 i 的主题分布
- 从主题的多项式分布中取样生成文档i第 j 个词的主题
- 从狄利克雷分布中取样生成主题对应的词语分布
- 从词语的多项式分布中采样最终生成词语
其中,类似Beta分布是二项式分布的共轭先验概率分布,而狄利克雷分布(Dirichlet分布)是多项式分布的共轭先验概率分布。
这里先简单解释下二项分布、多项分布、beta分布、Dirichlet 分布这4个分布。
- 二项分布(Binomial distribution),是从伯努利分布推进的。伯努利分布,又称两点分布或0-1分布,是一个离散型的随机分布,其中的随机变量只有两类取值,非正即负{+,-}。
- 多项分布,是二项分布扩展到多维的情况。单次试验中的随机变量的取值不再是0-1的,而是有多种离散值可能(1,2,3...,k)。比如投掷6个面的骰子实验,N次实验结果服从K=6的多项分布。
- Beta分布,二项分布的共轭先验分布。给定参数和,取值范围为[0,1]的随机变量 x 的概率密度函数。
- Dirichlet分布,是beta分布在高维度上的推广,其密度函数形式跟beta分布的密度函数如出一辙。
贝叶斯派思考问题的固定模式:
先验分布π(θ) + 样本信息χ ⇒后验分布π(θ|x)
上述思考模式意味着,新观察到的样本信息将修正人们以前对事物的认知。换言之,在得到新的样本信息之前,人们对的认知是先验π(θ)分布,在得到新的样本信息χ后,人们对θ的认知为 π(θ|x)。
所观测到的数据符合二项分布,参数的先验分布和后验分布都是Beta分布的情况,就是Beta-Binomial共轭。换言之,Beta分布是二项式分布的共轭先验概率分布。
在贝叶斯概率理论中,如果后验概率P(θ|x)和先验概率p(θ)满足同样的分布律,那么,先验分布和后验分布被叫做共轭分布,同时,先验分布叫做似然函数的共轭先验分布。
所观测到的数据符合多项分布,参数的先验分布和后验分布都是Dirichlet 分布的情况,就是Dirichlet-Multinomial 共轭。换言之,至此已经证明了Dirichlet分布的确就是多项式分布的共轭先验概率分布。
实现#
为了方便描述,首先定义一些变量:

图模型为(图中被涂色的w表示可观测变量,N表示一篇文档中总共N个单词,M表示M篇文档)
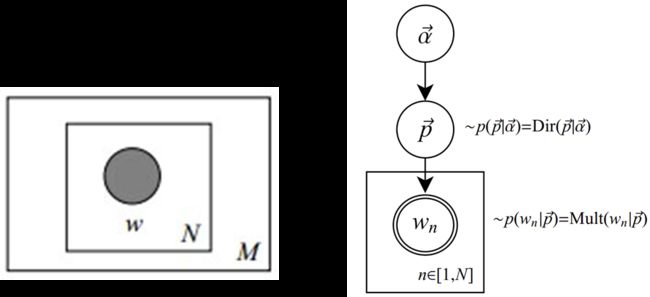
主题模型下生成文档

PLSA中,主题分布和词分布是唯一确定的,能明确的指出主题分布可能就是{教育:0.5,经济:0.3,交通:0.2},词分布可能就是{大学:0.5,老师:0.3,课程:0.2}。
但在LDA中,主题分布和词分布不再唯一确定不变,即无法确切给出。例如主题分布可能是{教育:0.5,经济:0.3,交通:0.2},也可能是{教育:0.6,经济:0.2,交通:0.2},到底是哪个我们不再确定(即不知道),因为它是随机的可变化的。但再怎么变化,也依然服从一定的分布,即主题分布跟词分布由Dirichlet先验随机确定。
PLSA和LDA生成模型的比较#
LDA生成文档的过程中,先从dirichlet先验中“随机”抽取出主题分布,然后从主题分布中“随机”抽取出主题,最后从确定后的主题对应的词分布中“随机”抽取出词。

形式化LDA#

对于语料库中的每篇文档,LDA定义了如下生成过程(generative process):
(1)对每一篇文档,从主题分布中抽取一个主题。
(2)从上述被抽到的主题所对应的单词分布中抽取一个单词。
(3)重复上述过程直至遍历文档中的每一个单词。
LDA认为每篇文章是由多个主题混合而成的,而每个主题可以由多个词的概率表征。所以整个程序的输入和输出如下表所示。

每个主题规则文件.twords如下格式所示

案例分析#
“埃航空难”的主题图谱构建及分析#
王晰巍,张柳,黄博,韦雅楠.基于LDA的微博用户主题图谱构建及实证研究——以“埃航空难”为例[J].数据分析与知识发现,2020,4(10):47-57.
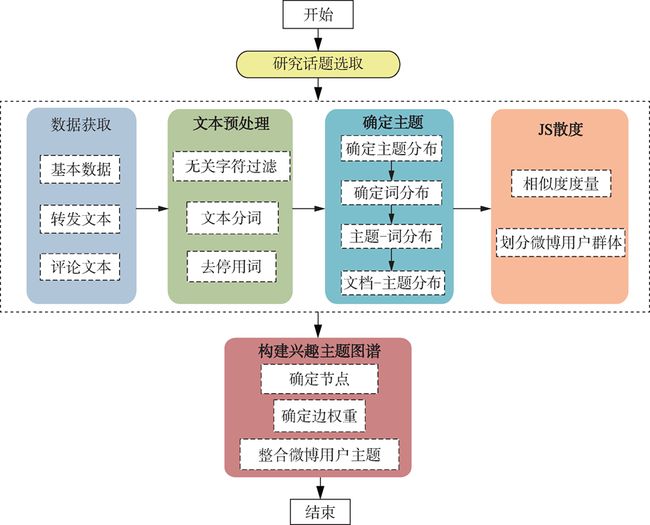
数据获取与文本预处理
第一步,采用网络爬虫方式采集用户数据,获取字 段包括用户 ID、用户名、用户个人资料相关字段、转发评论文本及时间等信息。
数据采集时间段参考百度指数,如图 2 所示,“埃航空难”的活跃期以 2019 年 3 月 10 日为起始 点、2019 年 6 月 20 日为终结点,从而最大限度地保证 数据的有效性,最终获得微博数据 34 325 条。