让陪伴机器人不再「直男」,读懂更多情绪 | 香港理工大学李嫣然
导读:现实对话中,「多喝热水」、「早点睡」等直男语录让人啼笑皆非。从某种意义上说,现有的对话系统就好比「直男」,对于情绪的感受力较弱。因其仅仅根据文本表面的意义进行分类,无法理解文本背后更深层的意思,无法与对方实现真正的「共情」。
如何提高陪伴机器人的共情能力,实现更专业、自然的情绪支持人机对话?香港理工大学李嫣然博士团队在这方面做了大量的工作。团队通过真人多轮情感支持对话中的中文语料数据挖掘语言背后的情绪流,进而针对AI的情绪探索和反馈能力等方面进行了有效地优化。
近日在由MLNLP(机器学习算法与自然语言处理)社区 和 中国中文信息学会青年工作委员会 联合举办的第九期 MLNLP 2022 学术研讨会上,李嫣然博士分享了题为「2022年了,陪伴对话机器人离我们还有多远?」的报告。同时,智源社区针对该项工作的灵感和初衷进行了独家访问。

李嫣然,博士毕业于香港理工大学,师从李文捷教授。其曾任小米人工智能实验室高级算法工程师、场景对话团队负责人,同时也兼任着北京大学心理与认知学院的行业导师。她在 ACL/EMNLP/ICLR/AAAI等国际顶级会议及期刊上发表论文二十余篇,涵盖情感计算、人机对话、自然语言生成等研究领域,累计引用次数超过1800次。同时她也担任了多年的NLP相关会议的领域主席及审稿人。个人主页:https://yanran.li/
采访&撰文:李梦佳、熊宇轩
基于陪伴机器人的愿景,解决现代社会的情绪问题
Q1:您所在团队这项研究的灵感来源于?
A:情感对话的一系列研究,都基于我们对于实现陪伴型机器人的愿景。为此,我们也学习了许多心理咨询、沟通交流相关的书籍和文献。经典的心理学书籍在此不列举了,对我个人影响最大的论文有《Dialogue Model
and Response Generation for Emotion Improvement Elicitation》和《ATOMIC: An Atlas of Machine Commonsense for If-Then Reasoning》。
Q2:多轮真人对话中文语料数据,这些数据来源于哪里?
A:多轮真人对话是研究团队出资进行的付费众包,我们提供特定的场景以及希望对话双方扮演的角色,参与众包的人员按照要求进行限定场景的多轮对话。在收集原始语料中,我们会尽心严格地筛选和清洗,最终得到了这份不涉及任何隐私、涵盖日常生活各种场景、具备真人交流的同理心和常识的中文对话数据。我们也将其开源希望回馈给学界,推动相关研究发展。
Q3:在人机交互中,我们往往遇到的问题是,AI在对话中仿佛理解了,但又没有真的理解。未来,想要真正实现有情绪的聊天,还有望采取哪些技术手段?目前的研究成果还有哪些不足之处?
A:现有的对话模型、大部分 NLP 甚至 AI 模型,基本都是数据驱动的,导致很多时候模型学到的都是数据之间的相关性,就会导致模型仿佛理解了又没有真的理解的情况。我个人认为常识对于我们的模型是必不可缺的。现在,我们虽然已经有了大规模的常识知识库,也有了一些可以进行常识推理、融合常识的模型,但都还有很多提升的空间。我也一直在关注这些方面的进展,比如如何从海量数据、超大规模语言模型中自动提取/蒸馏结构化的常识,如何通过人机交互、人机协作(如 human-in-the-loop)的方式,为模型学习常识提供更轻量化、精细化的监督信号等等。
Q4:未来这些工作将具体应用到哪些心理学领域?具体对于躁郁症等精神疾病的治疗有哪些帮助?
A:作为一个心理学业余爱好者,我了解到情绪问题和情绪疾病还是两个不同的层面。通常来说,现代社会的人们都或多或少会面临情绪问题,比如焦虑,这些是一种短期的、不稳定的负面状态。只有当情绪问题严重到一定程度才会被称为情绪疾病,比如抑郁,而情绪疾病的诊断就像其它生理疾病一样是有科学的标准的。目前我们的工作还主要是为了缓解人们生活中的情绪问题,比如疏导工作压力大的上班族,关怀独自在家的老年人,引导考前焦虑的学生等等。如果说到专业的情绪疾病诊断和治疗,前段时间发布的论文《D4: a Chinese Dialogue Dataset for Depression-Diagnosis-Oriented Chat》可能更相关一些。

在本次报告中,李嫣然博士首先介绍了构建情感支持陪伴对话机器人的研究背景,进而从「感知->认知」、「数据驱动->策略驱动」、「单模态->多模态」三个方面介绍了其团队的相关工作,最后对该领域未来 2-3 年内的发展方向进行了展望。

研究背景
目前,全球范围内有近 10 亿人患有精神障碍。据好心情发布的「数字化精神心理健康服务行业蓝皮书」统计,新冠疫情爆发后,全球抑郁症和焦虑障碍的患病人数显著增加,其中抑郁症患者激增 5,300 万、增幅达 27.6%;焦虑障碍患者激增 6,200 万,增幅达 20.8%。随着这一趋势的发展,人们对于情感治疗/疏导的需求日益增加。

然而,培养心理咨询师和社会志愿者的成本较高。相较于巨大的需求,发展中国家、低收入/中等收入国家向该领域投入的资源较为有限,有 76%-85% 的精神障碍患者得不到及时的治疗。因此,对于情感支持陪伴对话机器人的研究具有很强的现实意义。
研究方法
得益于深度学习、对话系统等技术的发展,自 2015-2016 年起,涌现出了一批有关情感支持陪伴对话机器人的研究工作,形成了新的研究方向。近年来,该领域的研究突飞猛进,每年大约有 5-10 篇相关的工作会发表在相关的顶级会议和学术期刊上。在 CCAC 2021 上,清华大学黄民烈教授也发表了题为「Emotional Intelligence in Dialogue Systems」的主题报告。

目前学界主要认为,情感对话领域的研究工作主要包含以下四个方向:(1)情绪理解(Emotion Understanding),即让机器理解来访者通过语言表达的情绪。(2)有情绪的聊天,即探究机器如何在回应中表达特定的情绪。(3)共情对话,即机器需要自主决定该表达怎样的情绪。(4)情感支持,即如何有策略地通过连续数轮的交互显著缓解来访者的情绪压力。其中,清华大学黄民烈老师也给出了(2)-(4)三个子任务之间的联系,如上图右上角所示。
感知->认知

如今,研究者们对情感对话的探索有逐渐从感知走向认知的趋势。如上图所示,许多已有的情绪理解工作会将该任务建模为一个分类问题,针对一段给定的对话输出一个情绪的标签。然而,由于人可能因为各种事件诱发产生某种情绪,这种单一的标签往往不能涵盖全面的信息。因此,2020 年末开始,一些工作展开了对全面、细粒度的情感认知的研究。

在 AAAI 2021 上,腾讯 AI Lab 发表了论文「Knowledge Bridging for Empathetic Dialogue Generation」,提出了模型 KEMP。作者认为,在对话过程中,说话人的请求和另一方的回复往往存在一定不对称的 Gap,回复中有时会出现一些请求中未涉及的新信息。我们需要将知识作为桥梁,从而对信息之间的关联建模。具体而言,该论文的作者采用情感词典提供外部知识,从而针对用户的陈述给出共情的回复,表达对于用户情绪状态的理解,实现从简单的情绪分类走向丰富的情绪认知。

在此基础上,清华大学团队在 AAAI 2022 上发表了论文「CEM:Commonsense-aware Empathetic Response Generation」,引入了目前最为先进的常识知识库「ATOMIC」、并采用了常识推理模型「COMET」生成与对话情境、说话人情绪等相关的常识知识。通过上述方式,我们可以针对某个事件进行多角度的推理。
如上图所示,如果一个人发现自己的电话出现了故障,根据图谱中反应推理「React」的边,机器可能会判断事件主体(用户)会产生沮丧的情绪;根据图谱中需求推理「Want」的边, 机器可能会判断该用户需要购买一个新的电话。通过这种多维度的推理,我们可以对事件的前因后果、可能引发的情绪、产生情绪的动机等要素建模,更加全面、立体地实现对事件背后情绪的认知。
基于 COMET 得到的常识,CEM 模型提出了「情感编码器」(Affective Encoder)和「认知编码器」(Cognitive Encoder),分别对感知和认知任务建模,进而生成最终的回复。

实验结果表明,尽管在引入认知图谱后取得了一定的性能提升,CEM 在涉及 32 类情绪的分类任务中的准确率仍然只有约 39%。可见,由于人们对于情绪的描述具有主观性和不确定性,不同人对于某件事产生的情绪可能有所差异,描述文本的差异也可能较大。因此,准确的情绪理解和认知仍然是一项困难的任务。
从某种意义上说,现有的对话系统就好比「直男」,对于情绪的感受力较弱。如果仅仅根据文本表面的意义进行分类,会造成很多尴尬的局面,无法与对方实现「共情」。我们认为,引入认知图谱会有助于改善「直男式」的回复。

为了实现从感知到认知的转变,我们仍然需要解决一系列难点,例如:(1)由于认知图谱存在一定的多样性,我们需要应对存在的歧义。如上图所示,在 ATOMIC 图谱中,三元组中的头「PersonX adopts a cat」发出的影响推理(Effect)边可能指向两个不同的尾——「发现对猫过敏」和「变得不那么孤独」,而这两个三元组代表了完全相反的情绪。因此,对尾实体的推理对于正确的情绪理解至关重要。(2)回复也需要考虑知识的多样性。在上述例子中,我们可能需要关注猫的来源(如猫舍或宠物救助站),如果不能对此上下文加以分辨,可能会导致回复中存在冲突和重复的现象,产生较差的用户体验。因此,我们需要在对话中获取到更准确的知识,提升情感理解和回复的性能。

为此,李嫣然博士团队于 ACL 2022 上发表了论文「C3KG:A Chinese Commonsense Conversation Knowledge Graph」,构建了面向中文的常识知识对话图谱,考虑了更丰富的上下文,更为全面地刻画了对话过程中的信息流(Flow)。具体而言,李嫣然博士团队从以下四个方面构建了常识对话图谱中的对话信息流,并使用三元组方式表示:
(1)情绪原因流,导致事件发生的情绪。
(2)事件流,事件之间的关联
(3)概念流,与事件流类似,粒度不同
(4)情绪意图流,某项陈述背后所表达的意图以及我们可能给出的回复。

为此,李嫣然博士团队通过众包方式,收集了大量的真人撰写的中文对话数据,构建了 CConv 数据集,并进行了说话人情绪和对应意图的标注。在此基础上,李嫣然博士团队基于数据增强、远程监督等方法挖掘了大量的对话流,从而构建了上文提到的4种对话信息流。

实验结果表明,通过上述方法挖掘的对话流具有非常强的通用性,其中 96% 的流也存在于另一个微信团队发布的对话数据中。通过使用该图谱,研究团队在情绪理解和意图识别任务上取得了显著的性能提升。
数据驱动->策略驱动

现有的大多数对话模型都由数据驱动。相较于策略驱动的方法,数据驱动方法对于数据标注的需求较低,完全依赖神经网络强大的学习能力提取知识。然而,数据驱动方法仍然存在一些弊端,例如:(1)回复内容过于通用(2)训练语料无法实现共情。
为此,研究者希望通过策略驱动的方式,在心理咨询、情绪疏导等对话任务中引入人类的先验知识。如上图所示,红色加粗的部分是我们在回复中使用的一些策略。例如,当来访者表示自己很沮丧时,机器可以首先通过询问了解发生了什么事。根据来访者陈述的事实,机器可以通过肯定和安慰的策略来表达对其遭遇的理解,从而实现共情。
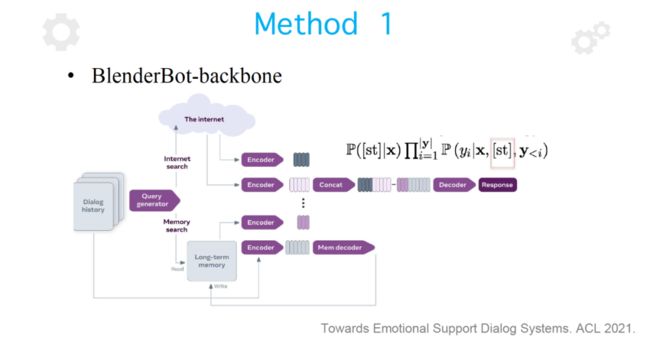
为了学习到这种策略,在 ACL 2021 上清华大学黄民烈教授团队发表的论文「Towards Emotional Support Dialog Systems」中,作者将策略作为特殊词例标签,拼接在生成模型中编码结果的最前端,初步实现了这一功能。

然而, 在实际情况下,咨询师在单轮回复中往往会用到多种策略,而这些策略又相互交叠。具体来说,多轮情感支持对话通常可以被划分为三个阶段:(1)探索(2)安慰(3)行动。其中,在探索情绪产生的原因时,我们可能会用到询问、复述、反映情感、自我表露等策略;在安慰阶段,我们可能会用到反映情感、自我表露、肯定与安慰等策略;在行动阶段,我们可能用到自我表露,肯定与安慰、提供建议、提供信息等策略。可见,对话过程中存在策略的交互和重叠,而论文「Towards Emotional Support Dialog Systems」中提出的模型无法实现这一功能,会产生标签一不一致的问题,无法学习到的真实数据分布。

针对上述问题,李嫣然博士团队在 ACL 2022 上发表了论文「MISC: A Mixed Strategy-Aware integrating COMET for Emotional Support Conversation」,尝试实现对多重策略的建模。由于现有的数据集大多只为每个回复赋予了一个标签,研究者需要考虑在缺乏完整标签信息的条件下进行多策略建模。
在本文中,李嫣然博士团队采用了 soft attention 的方式,并构造了策略编码表,即策略矩阵表示了 8 种策略,其中矩阵的每一行代表一种策略的表征。在获得上下文编码向量后,我们首先基于策略矩阵表征计算分布的注意力,注意力值的大小代表了当前上下文的权重,我们根据该权重来组合各种策略。通过将混合策略表征输入解码器,我们就可以得到考虑多重策略的回复。实验结果表明,该方法在 ACC、BLEU、PPL 等指标上都获得了显著的性能提升。

此外,该论文通过编码表注意力机制引入了一定的离散性,我们可以显式识别出在回复中使用到的策略。如上图所示,机器在对话中依次使用了红色、绿色、粉红色的策略。机器首先进行自我表露,表示自己也经历过分手;然后,机器说明自己的当时的反应,表达感同身受;最后,机器为来访者提供更多的信息和建议,表示生活还要继续。在回复生成过程中,随着解码的进行,数据的分布可能会产生一些变化,我们可以灵活、动态地计算当前需要使用的策略,提高用户的使用体验。
单模态->多模态

近年来,「视觉-语言」等多模态学习的研究工作受到了越来越多的关注。在情感陪伴对话的过程中,我们也可以基于对话式推荐技术,在安抚来访者的过程中推荐一些多模态物料的回复(例如,歌曲、电影、书籍)。在对话式推荐任务中,我们需要考虑多轮对话推荐的策略,通过动态生成的决策序列为用户提供更好的对话体验,提升推荐过程的效率。

为了实现上述目标,李嫣然博士团队在 SIGIR 2022 上发表了论文「Conversational Recommendation via Hierarchical Information Modeling」,通过利用对话历史和协同过滤来建模对话场景。
在协同过滤方面,研究者通过层次化的图构建了物料的层次化信息。从纵向看,研究者为每个用户构建了一个图,图与图之间通过用户之间的边来联通。从横向看,用户节点与一些属性节点相连,属性节点又与一些物料相关。通过对图的编码,我们可以计算用户之间的关联,整合各种信息,将序列化的图建模结果作为对话建模的输入。
在对话过程中,研究者利用了时序中的层次化的交互信息。我们不断发掘对用户有价值的、符合其喜好的物料,整个实现过程可以被看做通过多轮的询问和对话进行对图的剪枝。随着对话历史的推移,我们可以动态地得到当前的图表示,迭代式地将上一轮图表示作为下一轮学习的输入。

在此基础上,我们将序列化图建模的结果传递到动作空间中,得到更好的对动作的表征,最终通过深度强化学习模块完成对话式推荐。实验结果表明,该论文提出的方法在各类数据集上实现了显著的、普遍的性能提升。
对未来的思考
就陪伴对话机器人领域未来的发展而言,李嫣然博士认为以下 5 个方向具有很好的发展前景:
(1)更好的认知能力。引入更多、质量更高的知识图谱帮助常识推理,通过符号神经计算等方式更好地将知识引入到深度学习推理模型中。代表性的工作有论文「Moral Stories: Learning to Reason about Norms, Intent, Actions and their Consequences from Short Narratives」。他们提出了一个新的常识推理知识库,为学习添加了符合常理逻辑、社会规则、法律道德的约束。
(2)更好地适应多个域。结合情感支持、对话式推荐、面向任务的对话等任务,使用更加专业的数据集,实时地为不同人群提供更具有针对性的服务。代表性的工作有,「D4: a Chinese Dialogue Dataset for Depression-Diagnosis-Oriented Chat」、「AUGESC: Large-scale Data Augmentation for Emotional Support Conversation with Pre-trained Language Models」,前者尝试在心理咨询、心理诊疗等领域使用情感支持技术,后者利用自动化的数据增强技术缓解了训练数据不足的问题,使模型具有更好的泛化性能。
(3)更好地融合各种技能。机器在对话中需要具备各种子方向上的能力,具备一定的背景知识、社交属性,具有一定的人格。例如,情感对话任务中可能包含情绪理解、情感回复生成等子任务,使用的数据集、外部知识、甚至预训练框架可能是不同的。代表性的工作有「Emily: Developing An Emotional-Affective Open-Domain Chatbot with Knowledge Graph-based Persona」等。
(4)更好的统一学习架构。通过统一的框架解决一大类任务是目前比较流行的研究范式,这种做法在很多具体的任务中都取得了成功,在情感支持方向具有很大的研究潜力。代表性的工作有,邱锡鹏老师等人发表的论文「A Simple Language Model for Task-Oriented Dialogue」等。
(5)更合理地评价「共情」。BLEU、PPL 等指标难以真实反映机器的共情能力,我们需要针对共情回复构建更好的评价指标。代表性的工作有「Towards Facilitating Empathic Conversations in Online Mental Health Support: A Reinforcement Learning Approach」等。