Python 接口并发测试详解
一、接口并发测试简介
1、性能测试简介
性能测试是通过自动化测试工具模拟多种正常、峰值及异常负载条件对系统的各项性能指标进行的测试。负载测试和压力测试都属于性能测试,两者可以结合进行。通过负载测试,确定在各种工作负载下系统的性能,目标是测试当负载逐渐增加时,系统各项性能指标的变化情况。压力测试是通过确定一个系统的瓶颈或者不能接受的性能点,来获得系统能提供的最大服务级别的测试。
性能测试的重点是测试在并发条件下服务或系统的瓶颈所在,从而优化相关功能,可能涉及软件及硬件的多方面改进。由此可见,性能测试对整个产品非常重要,甚至可以决定一个产品是否能长久发展。
构建一个性能测试环境需要做一些准备,如图所示:
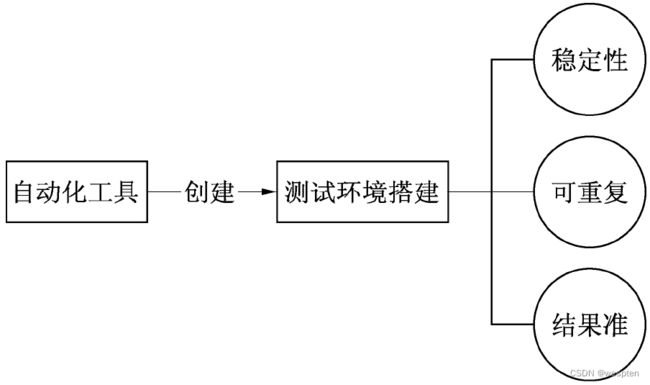
一般情况下都是使用自动化测试工具来构建性能测试环境,需要必要的服务器、软件和客户端等软硬件的支持。
一个良好的性能测试环境需要满足以下条件:
- 稳定、可重复的测试环境,能够保证测试结果的准确性。
- 保证达到测试执行的技术需求。
- 保证得到正确、可重复及易理解的测试结果。
有时候找到测试的基线(基本功能版本的产品线),能够更快地定义问题所在。通过不断地加压,测试服务或系统的最大承压能力。
根据不同的目的,可以把性能测试分成以下两个方面。
- 负载测试(Load Testing):在负载状态下对服务器系统的性能进行测试,目标是测试当前负载逐渐增加时,系统组成部分的相应输出项,如正常请求的接收数、响应时间、CPU负载、内存使用等,从而判断系统的性能。
- 压力测试(Stress Testing):通过确定一个系统的瓶颈或者不能接受的性能点,获得系统能提供的最大服务级别的测试行为。
关于压力测试,可以用一个具体的例子来理解。
例如,现在有600个用户可以在13s内完成支付交易,而650个用户完成支付交易的时间却超过了13s,则说明该支付服务已经不能再接收更多的业务请求了,从而估算出该项支付服务的最大承受范围是600个用户左右。所谓最大承受的压力点,就是通常意义上的瓶颈点。
后续会介绍一些热门的自动化性能测试工具,以便更准确地找到系统和服务性能的瓶颈点。这种性能测试在一些情况下能给团队和公司产生巨大的价值,包括商业价值。
2、并发测试简介
提到并发测试,测试人员总是会直接想到性能测试。除了在单元测试中会涉及一部分并发情况,测试人员可以根据开发模式及项目需求针对具体功能提取响应时间作为性能指标的参考。测试行业中的大多数人都认为性能测试包括并发测试、压力测试等,但并发测试一定是性能测试。所以并发测试与性能测试是包含于的关系。
其实测试人员的这种想法是错的,并发测试不等同于性能测试,性能测试也只是并发测试中的一小类而已。并发测试中除了耳熟能详的性能测试外,另一个与测试人员更密切相关的问题。
随着技术时代的发展,由于性能导致的问题项目组可以通过扩容、分布式缓存等方式有效地解决。并且从项目成本的角度看,虚拟服务器的发展已经让扩容不再需要很大的人力及物力,甚至由于解决性能问题导致的成本代价要远远小于因为执行大型性能测试而产生的成本代价。在这样的大形势下,除了真正有业务需求的公司,大多数大中小公司对于专职性能测试工程师的需求量会下降。他们真正需要的已不是系统测试完成后上线前的大型性能测试,而是并发测试。
接口并发测试是以并发为手段的接口测试行为,通过测试行为发现接口在并发场景下导致的功能问题就是接口并发测试最主要的目的。测试人员所做的功能测试真的完美了吗?没有!由于并发而导致的功能缺陷已然成为了项目上线后的主要遗留缺陷。
二、常见的性能问题
当下流行一种时尚的软件设计理念“微服务”,把复杂功能组合拆分成若干个独立的服务进行开发,然后有选择地组合执行各服务。微服务开发框架更有利于并发测试设计,每个服务都是测试切入口,可以单独执行。测试切入口越多,越有利于测试场景的设计,有效地执行并发用例。
测试切入口从三个方面查找统计:客户端操作、系统间接口调用、内置的定时任务。
客户端可以使用工具捕获提交到服务器的请求,分析链接、参数进行测试。
系统接口可以查相关接口文档,开发并模拟其他系统功能进行测试。
定时任务视开发框架,可能需要二次开发,以接口形式进行测试。
并发测出的问题是一种综合症,往往由多种错误交织在一起,切不可头痛医头脚痛医脚。
解决这类问题通常分为以下5个步骤:
- 通过并发测试找到故障点。
- 以故障点的现象分析问题原因。
- 确定产生原因后讨论解决方案。
- 根据解决方案实施修复。
- 通过并发测试验证修复情况。
在团队内进行专业的分析讨论,得出结论,是一种硬实力。除了开发以外,希望测试人员也要多多参与技术讨论,提升自身发现定位问题的能力。
接下来先了解下因为容易被忽视而导致的常见并发问题。
1、事务并发的问题
由于事务处理而导致的并发问题,测试人员需要先理解事务是什么意思。举个例子来阐述事务的概念。
故事场景:开心用手机通过定电影票系统购买电影票,找到自己喜欢的电影,选择自己想坐的位置,确认后点击下方的“确认选座”,进入订单支付画面。随后开心进入了订单支付画面,勾上了满减活动、现金抵用券,选择使用支付宝去支付,支付成功后收到平台短信。
结合以上场景,先讨论下系统内部的事务控制。事务的控制好坏往往取决于程序员们的开发技术能力、业务理解能力、专注程度,由于这类错误而导致的bug是非常低级且严重的。
将故事场景进行以下切分。
故事场景的上半部分:开心用手机购买电影票,找到自己喜欢的电影,选择自己想坐的位置,确认后点击下方的“确认选座”,进入订单支付画面。
“确认选座”与“生成订单”对于定电影票系统是内部接口。
将“确认选座”与“生成订单”定义为一个事务,有以下四个特性。
- 原子性的操作:要么都做,要么都不做。
- 状态保持一致性:系统锁定座位时必须生成订单,取消订单时必须解锁座位。
- 与其他事务互相隔离,不被干扰:座位被其他人选定、操作日志记录失败、断网等。
- 事务提交后永久存在,不会受到任何故障影响。只能另起一个新事务去修改已存在的数据。
这个例子的事务比较简单,想象下违反这些特性可能出现的问题。而这些问题就是测试人员在对“确认选座”与“生成订单”接口进行并发测试时,所需要考虑的测试用例覆盖点。
- 一个座位被多个账号同时锁定,生成了订单。
- 座位锁定成功,但是订单没生成。
- 订单取消成功,座位解锁失败。
- 生成重复的订单号。
- 操作日志没有完整地记录所有行为。
故事场景的下半部分:开心进入了订单支付画面,勾上了满减活动、现金抵用券,选择使用支付宝去支付,支付成功后收到平台短信。
“支付成功”对于定电影票系统是外部接口。对于外部接口的事务控制,就需要考虑两个系统的设计。在这里我们假设支付机构接口是成熟、稳定、无问题的。考虑针对订电影票系统的支付接口的事务控制就是外部接口测试的重点。
对支付接口进行并发接口测试,要考虑的事务问题如下:
- 同一笔订单,不能同时选择多种方式,不能进行多次支付。
- 重复通知商城支付结果(支付成功、支付超时),只能处理一次订单。
- 日志记录完整记录发送、接受的支付信息,与测试用例内容相匹配。
2、极限值并发的问题
由于极限值而导致的并发问题,先举个例子来阐述极限值的概念。
故事场景:最近开心测试团队接到一个周年庆营销活动项目的测试任务。营销活动的具体安排为每日9:00-21:00给予每个用户一份惊喜。每人每日可获得两次抽奖机会,会员可通过转发抽奖活动至朋友圈额外获得一次抽奖机会。已经获得一等奖或二等奖的用户不可再获得三四等奖;中奖概率按预估概率进行设定,如果已中奖数量达到每日设定奖品数量上限,该奖项停止。
周年庆营销活动的具体安排就是测试需求,开心将营销活动的具体安排进行拆分,得出并发测试场景。
- 每日9:00-21:00给予每个用户一份惊喜。
- 每人每日可获得两次抽奖机会,
- 会员可通过转发抽奖活动至朋友圈额外获得一次抽奖机会。
- 已经获得一等奖或二等奖的用户不可再获得三四等奖。
- 中奖概率按预估概率进行设定。
- 已中数量达到每日设定奖品数量上限,该奖项停止。
这个场景中处处都是极限值,让我们一起来字字品味,理清测试的切入口。
在这个场景中,先分析测试对象分别有:活动时间、抽奖次数、中奖概率、奖品数量上限、中奖规则。
针对这些对象结合测试场景,分析这些测试对象如果“越界”可能导致的问题作为并发测试的用例覆盖点。
- 测试活动:不在活动时间范围内,也能参与抽奖。
- 抽奖次数:活动分享至朋友圈,抽奖机会增加次数超过一次。
- 抽奖次数:每日抽奖次数超过上限。
- 中奖概率:中奖概率分配不足100%,或超过100%。
- 中奖概率:设置中奖概率有效的小数位数。
- 奖品数量上限:奖项数量上限控制。
- 中奖规则:已中一等奖或二等奖的用户,是否还能中奖。
3、压力并发的问题
由于压力负载而导致的并发问题,此类问题可以归类于性能问题。
在此类中,并发测试等同于性能测试,通常被称为压力测试,它是为了了解系统能提供的最大服务级别,获知系统响应时间、错误率等指标。通过增加并发数实现压力并发的测试行为,除了能发现系统中的性能问题,更是为了能发现系统功能上的缺陷。
关于此类并发测试需考虑的测试点,希望测试人员要明白数据处理的本质。我从数据库对于事务处理的角度进行分析,需要测试人员先掌握数据库事务隔离级别的知识。
事务的概念在事务并发问题中已经说明。在理解事务含义的基础上,再看数据库事务的隔离级别。
数据库事务的隔离级别有4个,由低到高依次如下:
1)Read uncommitted(未授权读取、读未提交)
如果一个事务已经开始写数据,则另外一个事务不允许同时进行写操作,但允许其他事务读此行数据。该隔离级别可以通过“排他写锁”实现。
该隔离级别避免了更新丢失,却可能出现脏读,也就是说事务B读取到了事务A未提交的数据。
2)Read committed(授权读取、读提交)
读取数据的事务允许其他事务继续访问该行数据,但是未提交的写事务将会禁止其他事务访问该行。
该隔离级别避免了脏读,但是却可能出现不可重复读。事务A事先读取了数据,事务B紧接着更新了数据,并提交了事务,而事务A再次读取该数据时,数据已经发生了改变。
3)Repeatable read(可重复读取)
读取数据的事务将会禁止写事务(但允许读事务),写事务则禁止任何其他事务。
该隔离级别避免了不可重复读取和脏读,但是有时可能出现幻读。这可以通过“共享读锁”和“排他写锁”实现。
4)Serializable(序列化)
提供严格的事务隔离。它要求事务序列化执行,事务只能一个接着一个地执行,但不能并发执行。如果仅仅通过“行级锁”是无法实现事务序列化的,必须通过其他机制保证新插入的数据不会被刚执行查询操作的事务访问到。
序列化是最高的事务隔离级别,同时代价也花费最高,性能很低,一般很少使用。在该级别下,事务顺序执行,不仅可以避免脏读、不可重复读,还避免了幻像读。
这 4 个级别可以逐个解决脏读、不可重复读、幻读这 3 类问题。
以下解释这 3 类情况的含义:
- 脏读
一个事务读取到了另一个事务未提交的数据操作结果。
- 更新丢失
更新丢失包括以下两种情况。
(1)回滚丢失
当2个事务更新相同的数据源时,如果第一个事务被提交,而另外一个事务却被撤销,那么会连同第一个事务所做的更新也被撤销,也就是说第一个事务做的更新丢失了。
(2)覆盖丢失
当2个或多个事务查询同样的记录然后各自基于最初的查询结果更新该行时,会造成覆盖丢失,因为每个事务都不知道其他事务的存在,最后一个事务对记录做的修改将覆盖其他事务对该记录做的已提交的更新。
- 不可重复读(Non-repeatable Reads)
一个事务对同一行数据重复读取两次,但是却得到了不同的结果,包括以下情况。
(1)虚读:事务T1读取某一数据后,事务T2对其做了修改,当事务T1再次读该数据时得到与前一次不同的值。
(2)幻读:事务在操作过程中进行两次查询,第二次查询的结果包含了第一次查询中未出现的数据或者缺少了第一次查询中出现的数据(这里并不要求两次查询的SQL语句相同)。这是由在两次查询过程中有另外一个事务插入数据造成的。
通常数据库设置默认隔离级别为Read committed(授权读取、读提交),仅支持使用事务并防止脏读。隔离级别越高,越能保证数据的完整性和一致性,但同时对并发性能的影响也会非常越大。当项目需求对系统性能有要求时,程序员就不能通过提高数据库设置级别保证并发事务处理的正确性。如果事务处理不正确,会直接导致功能出错,如资金计算错误等。提高隔离级别导致数据库访问效率急剧下降,为了保证系统性能不受影响,大部分的业务隔离将由程序逻辑进行处理。
下面以故事的形式,介绍测试人员在处理该并发测试需求时要关注的测试用例覆盖点。
最常见的覆盖点就是第二类更新丢失(覆盖丢失)产生的问题。
故事场景如下:
开心在网上开店卖鞋子,每时每刻库存都发生着变化:开心上架补货,开心下架撤货,买家下单买鞋,买家撤单取消。
考虑库存情况,可以根据以上场景建立一个基础公式,来校验测试结果是否正确。
- 剩余鞋子数量=上架数量−下架数量−成功下单数量
再进一步,建立公式二:
- 剩余鞋子数量=上架的数量−下架数量−下单数量+撤单数量
这些相互对立、交叉的操作都会影响到商品库存,任意两种组合或几种组合,可能打破公式平衡。例如,两个用户同时买一款鞋子,两个都下单成功。但第二个用户突然发现另一款鞋子更适合,她要求退款处理(减1后加1操作)。这样就导致与退款处理同时产生的事务计算出现问题,计算剩余鞋子数量与实际剩余鞋子数量不符,引发资金对账不平等情况。这种情况测试人员可以通过直接读取数据库值,再通过计算公式验证测试结果是否满足预期结果。
其次,在剩余鞋子数量发生变化的同时,测试人员要确定客户看到的情况是否与事务处理结果相符。此类问题可以通过校验买卖过程中的异常情况进行测试。例如,测试场景为:用户在客户端买了鞋子,但前端反馈由于网络问题购买失败,测试人员需要通过检查请求成功或失败的结果数量判定是否与预期结果相符。
同时通过公式记录每次请求后的商品数量变化,将其与前端显示的相关数量作对比。
- 下架数量 = 下架请求总数量 – 下架请求失败数量
说到测试人员判定请求是否成功,要提到另外一个概念:同步请求与异步请求。这两者的区别会造成测试人员判定请求状态与实际请求状态有差异,以至测试结果出错。
举个例子说明什么是同步请求和异步请求。
上班日中午天气太热,开心不想出办公室,让同事帮忙买一下比目鱼盖饭。同事塞着耳机没反应,开心拍拍他继续说,同事听到后不答应。于是开心提出请同事吃比目鱼盖饭,同事欢快地答应出门了。结果比目鱼餐厅今天不营业,同事空手而归。
这个例子有3次请求失败情况,同步请求失败2次,异步请求失败1次。
- 同步请求:由于同事塞着耳机,环境太吵,根本没听到开心的请求。(网络异常,没收到)
- 同步请求:同事听到了请求,但是没答应。(参数异常,条件不对,拒绝执行)
- 异步请求:同事没买到饭空手而归。(执行过程中发现资源冲突,执行失败)
同步请求:开心等待同事的回答,期间未做其他事情一直是等待回应状态。
异步请求:开心得到同事的第一次回答,过了一段时间后得到第二次回答。此期间开心可以做其他事情。
如果是异步请求,可能会出现两种情况:
- 即使测试人员在第一次得到“好的”的状态,也不能说明这个请求是成功的。因为“好的”并不说明“饭真的买回来”了。
- 即使测试人员在第一次得到“失败”的状态,也不能说明这个请求是失败的。因为“失败”可能是由于网络异常造成的没收到回复,实际同事“已经买到了比目鱼饭!”开心可以欢快地吃饭了。
说完以上内容,总结一下测试人员在处理此类并发测试时需要重点考虑以下几点:
- 先确定请求是同步,还是异步。
- 测试场景中的异常结果前后端处理数据是否相符。
- 并发产生的数据运算是否正确。
4、异常数据干扰并发的问题
异常数据导致的并发问题,除了并发测试外,测试人员可以通过另一种测试发现问题。对于此类情况的异常数据测试也可以称为系统健壮性测试。此类测试的重点是要根据业务逻辑或系统相关的配置情况构建能够造成异常的测试数据,要求这些数据不能被当作正常数据处理,也不能影响其他正常数据。
例如,测试人员构建测试场景为不断触发定时批处理任务,如果程序员在代码中忽视对异常数据逻辑处理,就会造成数据库连接池爆满、内存溢出、遇到异常数据直接报错中断(待执行任务队列越积越多)等问题。
此类并发测试关注点不是同步并发,而是逐步加压的并发数量,需要测试人员对系统架构配置及数据流逻辑具有非常清晰的认识,才能构建符合测试需求的异常测试场景。
三、性能问题解决方案
1、程序三高
1. 高并发
高并发(High Concurrency)是互联网分布式系统架构设计中必须考虑的因素之一。当多个进程或线程同时(或着说在同一段时间内)访问同一资源时会产生并发问题,因此需要通过专门的设计来保证系统能够同时(并发)正确处理多个请求。
2. 高性能
简单地说,高性能(High Performance)就是指程序处理速度快、耗能少。与性能相关的一些指标如下:
- 响应时间:系统对请求做出响应的时间。例如系统处理一个 HTTP 请求需要 200ms,这个 200ms 就是系统的响应时间。
- 吞吐量:单位时间内处理的请求数量。
- TPS:每秒响应事务数。
- 并发用户数:同时承载能正常使用系统功能的用户数量。
高并发和高性能是紧密相关的,提高应用的性能,可以提高系统的并发能力。
应用性能优化时,对于计算密集型和 I/O 密集型还是有很大差别,需要分开来考虑。
水平扩展(Scale Out):只要增加服务器数量,就能线性扩充系统性能。通常增加服务器资源(CPU、内存、服务器数量),大部分时候是可以提高应用的并发能力和性能 (前提是应用能够支持多任务并行计算和多服务器分布式计算才行)。但水平扩展对系统架构设计是有要求的,难点在于:如何在架构各层进行可水平扩展的设计。
3. 高可用
高可用性(High Availability)指一个系统经过专门的设计,从而减少停工时间,保证服务的持续可用。
如高可用集群就是保证业务连续性的有效解决方案。
2、三高解决方案
主要粗浅地介绍了一些系统设计、系统优化的套路和最佳实践。
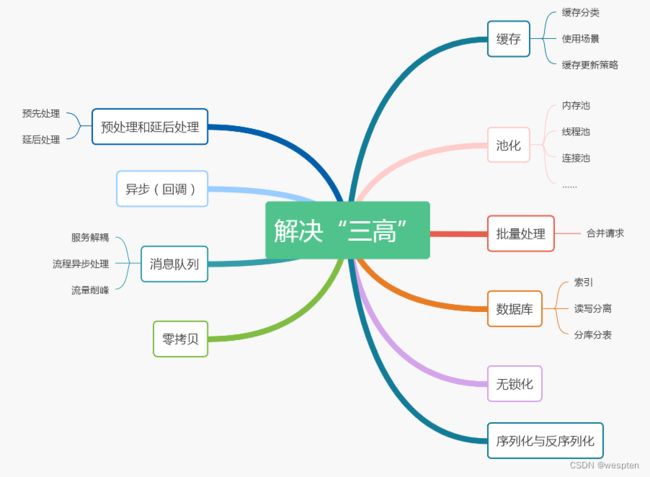
其实从缓存、消息队列到 CAS……很多看起来很牛逼的架构设计其实都来源于操作系统、体系结构。
这些底层的基础知识,看似古老的技术,却是经过时间洗礼留下来的好东西。现在很多的新技术、框架看似非常厉害,实则不少都是新瓶装旧酒,每几年又会被淘汰一批。
1. 缓存
1)什么是缓存
在计算机中,缓存是存储数据的硬件或软件组件,以便可以更快地满足将来对该数据的请求。存储在缓存中的数据可能是之前计算结果,也可能是存储在其他位置的数据副本。 ——维基百科
缓存本质来说是用空间换时间的思想,它在计算机世界中无处不在, 比如 CPU 就自带 L1、L2、L3 Cache,这在一般应用开发中关注较少,但在一些实时系统、大规模计算模拟、图像处理等追求极致性能的领域,就特别注重编写缓存友好的代码。
2)什么是缓存友好
简单来说,就是代码在访问数据的时候,尽量使用缓存命中率高的方式。
3)缓存为什么有效
缓存之所以能够大幅提高系统的性能,关键在于数据的访问具有局部性,也就是二八定律:「80% 的数据访问集中在 20% 的数据上」。这部分数据也被叫做热点数据。
缓存一般使用内存作为存储,内存读写速度快于磁盘,但容量有限,十分宝贵,不可能将所有数据都缓存起来。
如果应用访问数据没有热点,不遵循二八定律,即大部分数据访问并没有集中在小部分数据上,那么缓存就没有意义,因为大部分数据还没有被再次访问就已经被挤出缓存了。每次访问都会回源到数据库查询,那么反而会降低数据访问效率。
4)缓存分类
- 本地缓存
使用进程内成员变量或者静态变量,适合简单的场景,不需要考虑缓存一致性、过期时间、清空策略等问题。
可以直接使用语言标准库内的容器来做存储。
- 分布式缓存
当缓存的数据量增大以后,单机不足以承载缓存服务时,就要考虑对缓存服务做水平扩展,引入缓存集群。
将数据分片后分散存储在不同机器中,如何决定每个数据分片存放在哪台机器呢?一般是采用一致性 Hash 算法,它能够保证在缓存集群动态调整,在不断增加或者减少机器时,客户端访问时依然能够根据 key 访问到数据。
常用的中间件有 Memcache、 Redis Cluster 等。也可以在 Redis 的基础上,提供分布式存储的解决方案。
5)适合缓存的场景
- 读多写少
比如电商里的商品详情页面,访问频率很高,但是一般写入只在店家上架商品和修改信息的时候发生。如果把热点商品的信息缓存起来,这将拦截掉很多对数据库的访问,提高系统整体的吞吐量。
因为一般数据库的 QPS 由于有「ACID」约束、并且数据是持久化在硬盘的,所以比 Redis 这类基于内存的 NoSQL 的效率低不少,这常常是一个系统的瓶颈,如果我们把大部分的查询都在 Redis 缓存中命中了,那么系统整体的 QPS 也就上去了。
- 计算耗时大,且实时性不高
比如王者荣耀里的全区排行榜,一般一周更新一次,并且计算的数据量也比较大,所以计算后缓存起来,请求排行榜直接从缓存中取出,就不用实时计算了。
6)不适合缓存的场景
- 写多读少,频繁更新。
- 对数据一致性要求严格: 因为缓存会有更新策略,所以很难做到和数据库实时同步。
- 数据访问完全随机: 因为这样会导致缓存的命中率极低。
7)缓存更新的策略
如何更新缓存其实已经有总结得非常好的「最佳实践」,我们按照套路来,大概率不会犯错。策略主要分为两类:
- Cache-Aside
- Cache-As-SoR:SoR(System Of Record,记录系统)表示数据源,一般就是指数据库。
- Cache-Aside

这应该是最容易想到的模式了,获取数据时先从缓存读,如果 cache hit(缓存命中)则直接返回,若没命中就从数据源获取,然后更新缓存。
写数据的时候则先更新数据源,然后设置缓存失效,那么下一次获取数据的时候必然 cache miss,然后触发回源。
可以看出这种方式对于缓存的使用者是不透明的,需要使用者手动维护缓存。
- Cache-As-SoR
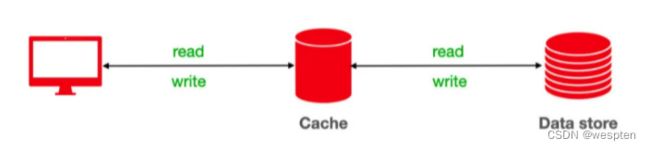
从字面上来看,就是把 Cache 当作 SoR,也就是数据源,所以一切读写操作都是针对 Cache 的,由 Cache 内部自己维护和数据源的一致性。这样对于使用者来说就和直接操作 SoR 没有区别了,完全感知不到 Cache 的存在。
CPU 内部的 L1、L2、L3 Cache 就是这种方式,作为数据的使用方(应用程序),是完全感知不到在内存和我们之间还存在几层的 Cache,但是我们之前又提到编写 “缓存友好”的代码。这种策略不是透明的吗?这是不是冲突呢?
其实不然,缓存友好是指我们通过学习了解缓存内部实现、更新策略之后,通过调整数据访问顺序提高缓存的命中率。
Cache-As-SoR 又分为以下三种方式:
- Read Through:这种方式和 Cache-Aside 非常相似,都是在查询时发生 cache miss 去更新缓存,但是区别在于 Cache-Aside 需要调用方手动更新缓存,而 Cache-As-SoR 则是由缓存内部实现自己负责,对应用层透明。
- Write Through:直写式,就是在将数据写入缓存的同时,缓存也去更新后面的数据源,并且必须等到数据源被更新成功后才可返回。这样保证了缓存和数据库里的数据一致性。
- Write Back:回写式,数据写入缓存即可返回,缓存内部会异步的去更新数据源,这样好处是写操作特别快,因为只需要更新缓存。并且缓存内部可以合并对相同数据项的多次更新,但是带来的问题就是数据不一致,可能发生写丢失。
2. 预处理与延后处理
预先延后,这其实是一个事物的两面,两者的核心思想都是将本来该在实时链路上处理的事情剥离,要么提前处理、要么延后处理,以降低实时链路的路径长度, 这样能有效提高系统性能。
1)预处理
案例:
前段时间支付宝联合杭州市政府发放消费劵,但是要求只有杭州市常驻居民才能领取,那么需要在抢卷请求进入后台的时候就判断一下用户是否是杭州常驻居民。
而判断用户是否是常驻居民这个是另外一个微服务接口,如果直接实时的去调用那个接口,短时的高并发很有可能把这个服务也拖挂,最终导致整个系统不可用,并且 RPC 本身也是比较耗时的,所以就考虑在这里进行优化。
解决思路:
那么该怎么做呢?很简单的一个思路,提前将杭州所有常驻居民的 user_id 存到缓存中, 比如可以直接存到 Redis,大概就是千万量级。这样,当请求到来的时候我们直接通过缓存可以快速判断是否来自杭州常驻居民,如果不是则直接在这里返回前端。
这里通过预先处理减少了实时链路上的 RPC 调用,既减少了系统的外部依赖,也极大地提高了系统的吞吐量。
预处理在 CPU 和操作系统中也广泛使用,比如 CPU 基于历史访存信息,将内存中的指令和数据预取到 Cache 中,这样可以大大提高 Cache 命中率。 还比如在 Linux 文件系统中,预读算法会预测即将访问的 page,然后批量加载比当前读请求更多的数据缓存在 page cache 中,这样当下次读请求到来时可以直接从 cache 中返回,大大减少了访问磁盘的时间。
2)延后处理
还是支付宝的案例:

这是支付宝春节集五福活动开奖当晚。大家发现没有,这类活动中奖奖金一般会显示 「稍后到账」,为什么呢?那当然是到账这个操作不简单!
到账即转账,等于 A 账户给 B 账户转钱,A 减钱时,B 就必须要同时加上钱。也就是说不能 A 减了钱但 B 没有加上,这就会导致资金损失。资金安全是支付业务的生命线,这可不行。
这两个动作必须一起成功或是一起都不成功,不能只成功一半,这是保证数据一致性,保证两个操作同时成功或者失败就需要用到事务。
如果去实时的做到账,那么大概率数据库的 TPS(每秒处理的事务数) 会是瓶颈。通过产品提示,将到账操作延后处理,解决了数据库 TPS 瓶颈。
延后处理还有一个非常著名的例子,COW(Copy On Write,写时复制)。如 Linux 创建进程时调用 fork,fork 产生的子进程只会创建虚拟地址空间,而不会分配真正的物理内存,子进程共享父进程的物理空间,只有当某个进程需要写入的时候,才会真正分配物理页,拷贝该物理页,通过 COW 减少了很多不必要的数据拷贝。
3. 池化
后台开发过程中你一定离不开各种 「池子」: 内存池、连接池、线程池、对象池……
内存、连接、线程这些都是资源,创建线程、分配内存、数据库连接这些操作都有一个特征, 那就是创建和销毁过程都会涉及到很多系统调用或者网络 I/O,每次都在请求中去申请创建这些资源,就会增加请求处理耗时。如果我们用一个“容器(池)”把它们保存起来,下次需要的时候,直接拿出来使用,就可以避免重复创建和销毁所浪费的时间。
1)内存池
在 C/C++ 中经常会使用 malloc、new 等 API 动态申请内存。由于申请的内存块大小不一,如果频繁的申请、释放会导致大量的内存碎片,并且这些 API 底层依赖系统调用,会有额外的开销。
内存池就是在使用内存前,先向系统申请一块空间留做备用,使用者需要内池时则向内存池申请,用完后还回来。
内存池的思想非常简单,实现却不简单,难点在于以下几点:
- 如何快速分配内存
- 降低内存碎片率
- 维护内存池所需的额外空间尽量少
如果不考虑效率,我们完全可以将内存分为不同大小的块,然后用链表连接起来,分配的时候找到大小最合适的返回,释放的时候直接添加进链表。如:

当然这只是玩具级别的实现,业界有性能非常好的实现了,我们可以直接拿来学习和使用。
比如 Google 的“tcmalloc”和 Facebook 的“jemalloc”,如果感兴趣可以搜来看看,也推荐去看看被誉为神书的 CSAPP(《深入理解计算机系统》)那里也讲到了动态内存分配算法。
2)线程池
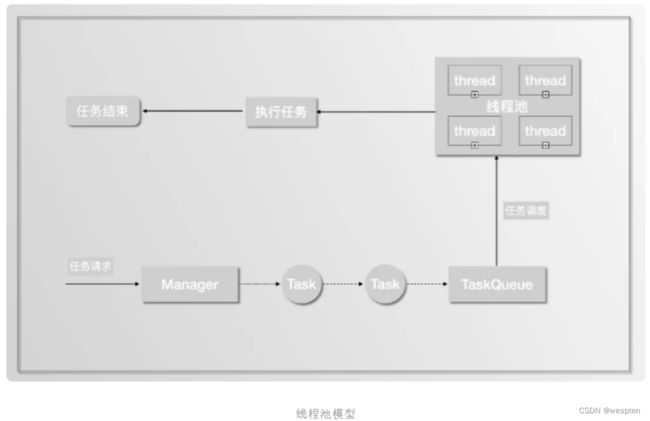
线程是干嘛的?线程就是我们程序执行的实体。在服务器开发领域,我们经常会为每个请求分配一个线程去处理,但是线程的创建销毁、调度都会带来额外的开销,线程过多也会导致系统整体性能下降。在这种场景下,我们通常会提前创建若干个线程,通过线程池来进行管理。当请求到来时,只需从线程池选一个线程去执行处理任务即可。
线程池常常和队列一起使用来实现任务调度,主线程收到请求后将创建对应的任务,然后放到队列里,线程池中的工作线程等待队列里的任务。
线程池实现上一般有四个核心组成部分:
- 管理器(Manager): 用于创建并管理线程池。
- 工作线程(Worker): 执行任务的线程。
- 任务接口(Task): 每个具体的任务必须实现任务接口,工作线程将调用该接口来完成具体的任务。
- 任务队列(TaskQueue): 存放还未执行的任务。
3)连接池
顾名思义,连接池是创建和管理连接的。
大家最熟悉的莫过于数据库连接池,这里我们简单分析下如果不用数据库连接池,一次 SQL 查询请求会经过哪些步骤:
- 和 MySQL server 建立 TCP 连接:三次握手
- MySQL 权限认证:
- Server 向 Client 发送密钥
- Client 使用密钥加密用户名、密码等信息,将加密后的报文发送给 Server
- Server 根据 Client 请求包,验证是否是合法用户,然后给 Client 发送认证结果
- Client 发送 SQL 语句
- Server 返回语句执行结果
- MySQL 关闭
- TCP 连接断开:四次挥手
可以看出不使用连接池的话,为了执行一条 SQL,会花很多时间在安全认证、网络 I/O 上。
如果使用连接池,执行一条 SQL 就省去了建立连接和断开连接所需的额外开销。
还能想起哪里用到了连接池的思想吗?HTTP 长链接也算一个变相的链接池,虽然它本质上只有一个连接,但是思想却和连接池不谋而合,都是为了复用同一个连接发送多个 HTTP 请求,避免建立和断开连接的开销。
池化实际上也是预处理和延后处理的一种应用场景,通过池子将各类资源的创建提前和销毁延后。
4. 异步(回调)
对于处理耗时的任务,如果采用同步的方式,会增加任务耗时,降低系统并发度。此时可以通过将同步任务变为异步进行优化。
- 同步:比如我们去 KFC 点餐,遇到排队的人很多,当点完餐后,大多情况下我们会隔几分钟就去问好了没,反复去问了好几次才拿到,在这期间我们也没法干活了,这个就叫同步轮循, 这样效率显然太低了。
- 异步:服务员被问烦了,就在点完餐后给我们一个号码牌,每次准备好了就会在服务台叫号,这样我们就可以在被叫到的时候再去取餐,中途可以继续干自己的事。
在很多编程语言中有异步编程的库,比如 C++ 的 std::future、Python 的 asyncio 等,但是异步编程往往需要回调函数(Callback function),如果回调函数的层级太深,这就是回调地狱(Callback hell)。回调地狱如何优化又是一个庞大的话题……
这个例子相当于函数调用的异步化,还有的情况是处理流程异步化,这个会在接下来消息队列中讲到。
5. 消息队列
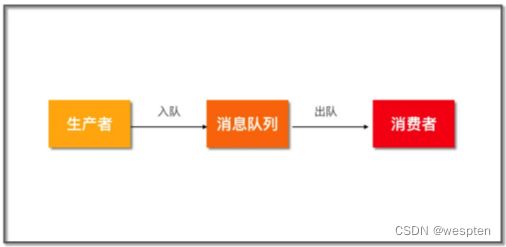
这是一个非常简化的消息队列模型,上游生产者将消息通过队列发送给下游消费者。在这之间,消息队列可以发挥很多作用,比如:
1)服务解耦
有些服务被其它很多服务依赖,比如一个论坛网站,当用户成功发布一条帖子后,系统会有一系列的流程要做,有积分服务计算积分、推送服务向发布者的粉丝推送一条消息等,对于这类需求,常见的实现方式是直接调用:

但是如果此时需要新增一个数据分析的服务,那么又得改动发布服务,这违背了依赖倒置原则,即上层服务不应该依赖下层服务,那么怎么办呢?

引入消息队列作为中间层,当帖子发布完成后,发送一个事件到消息队列里,而关心帖子发布成功这件事的下游服务就可以订阅这个事件,这样即使后续继续增加新的下游服务,只需要订阅该事件即可,完全不用改动发布服务,完成系统解耦。
2)异步处理
有些业务涉及到的处理流程非常多,但是很多步骤并不要求实时性,那么我们就可以通过消息队列异步处理。
比如淘宝下单,一般包括了风控、锁库存、生成订单、短信/邮件通知等步骤,但是核心的就风控和锁库存,只要风控和扣减库存成功,那么就可以返回结果通知用户成功下单了。后续的生成订单,短信通知都可以通过消息队列发送给下游服务异步处理,这样可以大大提高系统响应速度。
这就是处理流程异步化。
3)流量削峰
一般像秒杀、抽奖、抢卷这种活动都会伴随短时间内海量的请求, 一般都超过后端的处理能力,那么我们就可以在接入层将请求放到消息队列里,后端根据自己的处理能力不断从队列里取出请求进行业务处理,起到平均流量的作用。
就像长江汛期,上游短时间大量的洪水汇聚直奔下游,但是通过三峡大坝将这些水缓存起来,然后匀速的向下游释放,起到了很好的削峰作用。
消息队列的核心思想就是把同步的操作变成异步处理,而异步处理会带来相应的好处,比如:
- 服务解耦。
- 提高系统的并发度,将非核心操作异步处理,这样不会阻塞主流程。
但是软件开发没有银弹,所有的方案选择都是一种 trade-off(权衡、取舍)。 同样,异步处理也不全是好处,也会导致一些问题:
- 降低了数据一致性,从强一致性变为最终一致性。
- 有消息丢失的风险,比如宕机,需要有容灾机制。
6. 批量处理
在涉及到网络连接、I/O 等情况时,将操作批量进行处理能够有效提高系统的传输速率和吞吐量。
在前后端通信中,通过合并一些频繁请求的小资源可以获得更快的加载速度。
比如我们后台 RPC 框架,经常有更新数据的需求,而有的数据更新的接口往往只接受一项,这个时候我们往往会优化下更新接口,使其能够接受批量更新的请求,这样可以将批量的数据一次性发送,大大缩短网络 RPC 调用耗时。
7. 数据库
我们常把后台开发调侃为“CRUD”(增删改查),可见数据库在整个应用开发过程中的重要性不言而喻。
而且很多时候系统的瓶颈也往往处在数据库这里,慢的原因也有很多,比如没用索引、没用对索引、读写锁冲突等等。
那么如何使用数据才能又快又好呢?下面这几点需要重点关注:
1)索引
索引可能是我们平时在使用数据库过程中接触得最多的优化方式。索引好比图书馆里的书籍索引号,想象一下,如果我让你去一个没有书籍索引号的图书馆找《人生》这本书,你是什么样的感受?当然是怀疑人生,同理,你应该可以理解当你查询数据却不用索引的时候,数据库该有多崩溃了吧。
数据库表的索引就像图书馆里的书籍索引号一样,可以提高我们检索数据的效率。索引能提高查找效率,可是你有没有想过为什么呢?这是因为索引一般而言是一个排序列表,排序意味着可以基于二分思想进行查找,将查询时间复杂度做到 O(logn),从而快速地支持等值查询和范围查询。
二叉搜索树的查询效率无疑是最高的,因为平均来说每次比较都能缩小一半的搜索范围,但是一般在数据库索引的实现上却会选择 B 树或 B+ 树而不用二叉搜索树,为什么呢?
这就涉及到数据库的存储介质了,数据库的数据和索引都是存放在磁盘,并且是 InnoDB 引擎是以页为基本单位管理磁盘的,一页一般为 16 KB。AVL 或红黑树的搜索效率虽然非常高,但是同样的数据项,它也会比 B、B+ 树(高度)更高,高就意味着平均来说会访问更多的节点,即磁盘 I/O 次数!
所以表面上来看我们使用 B、B+ 树没有二叉查找树效率高,但是实际上由于 B、B+ 树降低了树高,减少了磁盘 I/O 次数,反而大大提升了速度。
这也告诉我们,没有绝对的快和慢,系统分析要抓主要矛盾,先分析出决定系统瓶颈的到底是什么,然后才是针对瓶颈的优化。
下面是索引必知必会的知识,大家可以查漏补缺:
- 主键索引和普通索引,以及它们之间的区别
- 最左前缀匹配原则
- 索引下推
- 覆盖索引、联合索引
2)读写分离
一般业务刚上线的时候,直接使用单机数据库就够了,但是随着用户量上来之后,系统就面临着大量的写操作和读操作,单机数据库处理能力有限,容易成为系统瓶颈。
由于存在读写锁冲突,并且很多大型互联网业务往往读多写少,读操作会首先成为数据库瓶颈,我们希望消除读写锁冲突从而提升数据库整体的读写能力。
那么就需要采用读写分离的数据库集群方式,如一主多从,主库会同步数据到从库,写操作都到主库,读操作都去从库。
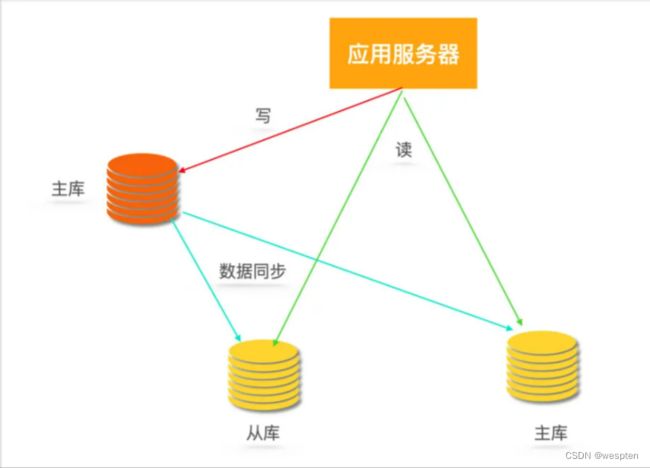
读写分离之后就避免了读写锁争用,这里解释一下,什么叫读写锁争用:
MySQL 中有两种锁:
- 排它锁(X 锁): 事务 T 对数据 A 加上 X 锁时,只允许事务 T 读取和修改数据 A。
- 共享锁(S 锁): 事务 T 对数据 A 加上 S 锁时,其他事务只能再对数据 A 加 S 锁,而不能加 X 锁,直到 T 释放 A 上的 S 锁。
读写分离解决问题的同时也会带来新问题,比如主库和从库数据不一致。
MySQL 的主从同步依赖于 binlog,binlog(二进制日志)是 MySQL Server 层维护的一种二进制日志,是独立于具体的存储引擎。它主要存储对数据库更新(insert、delete、update)的 SQL 语句,由于记录了完整的 SQL 更新信息,所以 binlog 是可以用来数据恢复和主从同步复制的。
从库从主库拉取 binlog 然后依次执行其中的 SQL 即可达到复制主库的目的,由于从库拉取 binlog 存在网络延迟等,所以主从数据同步存在延迟问题。
那么这里就要看业务是否允许短时间内的数据不一致,如果不能容忍,那么可以通过如果读从库没获取到数据就去主库读一次来解决。
3)分库分表
如果用户越来越多,写请求暴涨,对于上面的单 Master 节点肯定扛不住,那么该怎么办呢?多加几个 Master?不行,这样会带来更多的数据不一致的问题,且增加系统的复杂度。那该怎么办?就只能对库表进行拆分了。
常见的拆分类型有垂直拆分和水平拆分。
以拼夕夕电商系统为例,一般有订单表、用户表、支付表、商品表、商家表等,最初这些表都在一个数据库里。后来随着砍一刀带来的海量用户,拼夕夕后台扛不住了!于是紧急从阿狸粑粑那里挖来了几个 P8、P9 大佬对系统进行重构。
- P9 大佬第一步先对数据库进行垂直分库,根据业务关联性强弱,将它们分到不同的数据库,比如订单库,商家库、支付库、用户库。
- 第二步是对一些大表进行垂直分表,将一个表按照字段分成多表,每个表存储其中一部分字段。比如商品详情表可能最初包含了几十个字段,但是往往最多访问的是商品名称、价格、产地、图片、介绍等信息,所以我们将不常访问的字段单独拆成一个表。
由于垂直分库已经按照业务关联切分到了最小粒度,但数据量仍然非常大,于是 P9 大佬开始水平分库,比如可以把订单库分为订单 1 库、订单 2 库、订单 3 库……那么如何决定某个订单放在哪个订单库呢?可以考虑对主键通过哈希算法计算放在哪个库。
分完库,单表数据量任然很大,查询起来非常慢,P9 大佬决定按日或者按月将订单分表,叫做日表、月表。
分库分表同时会带来一些问题,比如平时单库单表使用的主键自增特性将作废,因为某个分区库表生成的主键无法保证全局唯一,这就需要引入全局 UUID 服务了。
经过一番大刀阔斧的重构,拼夕夕恢复了往日的活力,大家又可以愉快的在上面互相砍一刀了。
(分库分表会引入很多问题,并没有一一介绍,这里只是为了讲解什么是分库分表。)
8. 零拷贝
高性能的服务器应当避免不必要数据复制,特别是在用户空间和内核空间之间的数据复制。 比如 HTTP 静态服务器发送静态文件的时候,一般我们会这样写:
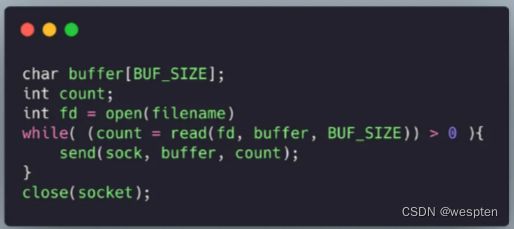
如果了解 Linux I/O 的话就知道这个过程包含了内核空间和用户空间之间的多次拷贝:
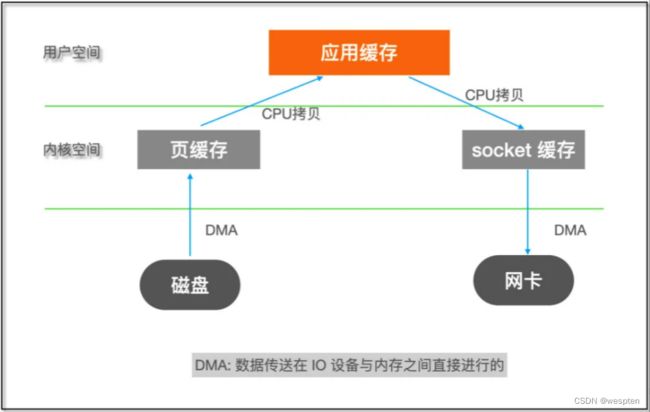
内核空间和用户空间之间数据拷贝需要 CPU 亲自完成,但是对于这类数据不需要在用户空间进行处理的程序来说,这样的两次拷贝显然是浪费。什么叫“不需要在用户空间进行处理”?
比如 FTP 或者 HTTP 静态服务器,它们的作用只是将文件从磁盘发送到网络,不需要在中途对数据进行编解码之类的计算操作。
如果能够直接将数据在内核缓存之间移动,那么除了减少拷贝次数以外,还能避免内核态和用户态之间的上下文切换。
而这正是零拷贝(Zero copy)干的事,主要就是利用各种零拷贝技术,减少不必要的数据拷贝,将 CPU 从数据拷贝这样简单的任务解脱出来,让 CPU 专注于别的任务。
常用的零拷贝技术
1)mmap
mmap 通过内存映射,将文件映射到内核缓冲区,同时,用户空间可以共享内核空间的数据。这样,在进行网络传输时,就可以减少内核空间到用户空间的拷贝次数。
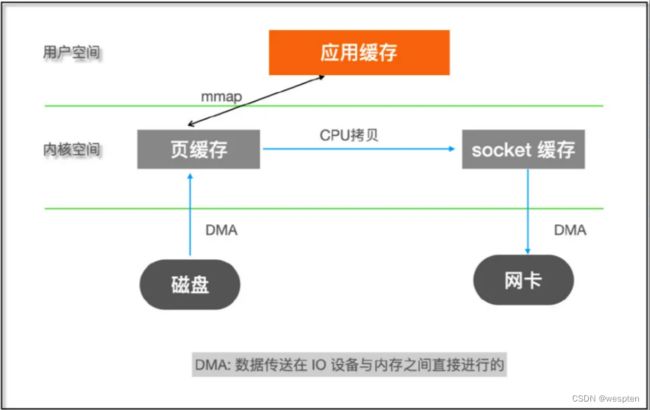
2)sendfile
sendfile 是 Linux 2.1 版本提供的,数据不经过用户态,直接从页缓存拷贝到 socket 缓存,同时由于和用户态完全无关,就减少了一次上下文切换。
在 Linux 2.4 版本,对 sendfile 进行了优化,直接通过 DMA 将磁盘文件数据读取到 socket 缓存,真正实现了“0”拷贝。前面 mmap 和 2.1 版本的 sendfile 实际上只是消除了用户空间和内核空间之间拷贝,而页缓存和 socket 缓存之间的拷贝依然存在。
9. 无锁化
在多线程环境下,为了避免竞态条件(race condition),我们通常会采用加锁来进行并发控制。锁的代价也是比较高的,锁会导致上下文切换,甚至被挂起直到锁被释放。
基于硬件提供的原子操作“CAS(Compare And Swap)”实现了一些高性能无锁的数据结构,比如无锁队列,可以在保证并发安全的情况下,提供更高的性能。
首先需要理解什么是 CAS,CAS 有三个操作数,内存里当前值 M、预期值 E、修改的新值 N,CAS 的语义就是:
如果当前值等于预期值,则将内存修改为新值,否则不做任何操作。
用 C 语言来表达就是:
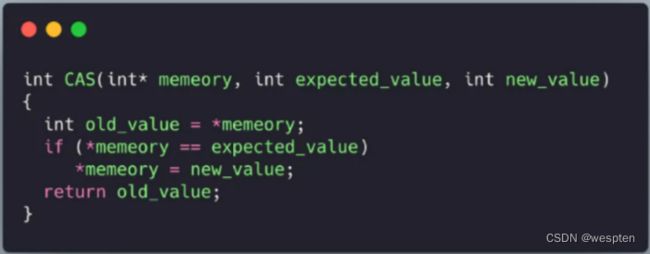
注意,上面的 CAS 函数实际上是一条原子指令,那么该如何使用呢?
假设我需要实现这样一个功能:对一个全局变量 global 在两个不同线程分别对它加 100 次,这里多线程访问一个全局变量存在 race condition,所以我们需要采用线程同步操作,下面分别用锁和 CAS 的方法来实现这个功能。
CAS 和锁示范:

通过使用原子操作大大降低了锁冲突的可能性,提高了程序的性能。
除了 CAS,还有一些硬件原子指令:
- Fetch-And-Add:对变量原子性 + 1。
- Test-And-Set:这是各种锁算法的核心,在 AT&T/GNU 汇编语法下,叫 xchg 指令。
10. 序列化与反序列化
所有的编程一定是围绕数据展开的,而数据呈现形式往往是结构化的,比如结构体(Struct)、类(Class)。 但是当我们通过网络、磁盘等传输、存储数据的时候却要求是二进制流。 比如 TCP 连接,它提供给上层应用的是面向连接的可靠字节流服务。那么如何将这些结构体和类转化为可存储和可传输的字节流呢?这就是序列化要干的事情,反之,从字节流如何恢复为结构化的数据就是反序列化。
序列化解决了对象持久化和跨网络数据交换的问题。
序列化一般按照序列化后的结果是否可读,而分为以下两类:
1)文本类型
如 JSON、XML,这些类型可读性非常好,语义是自解释的。也常常用在前后端数据交互上,如接口调试时可读性高,非常方便。但是缺点就是信息密度低,序列化后占用空间大。
2)二进制类型
如 Protocol Buffer、Thrift 等,这些类型采用二进制编码,数据组织得更加紧凑,信息密度高,占用空间小,但是带来的问题就是基本不可读。
像 Java、Python 便内置了序列化方法,比如在 Java 里实现了 Serializable 接口即表示该对象可序列化。
四、性能测试流程设计
1、性能测试理论
1. 性能测试概念
性能:就是软件质量属性中的“效率”特性。
效率的特性:
-
时间特性:指系统处理用户请求的响应时间。
-
资源特性:指系统在运行过程中,系统资源的消耗情况。
- CPU 使用率
- 内存使用率
- 磁盘 I/O
- 网络带宽使用率
- ...
什么是性能测试?
性能测试是指通过自动化测试工具模拟正常、峰值以及异常的负载条件,来对系统的各项性能指标进行测试和评估的过程。
- 后台程序的处理性能(代码性能)
- 中间件、数据库、架构设计等是否存在瓶颈
- 服务器资源消耗(CPU、内存、磁盘、网络)
- ...
2. 性能测试目的
-
评估当前系统能力。
- 例如:验收第三方提供的软件。
- 例如:获取关键的性能指标,与其他类似产品进行比较。
-
基于性能需求目标的测试验证。
-
精准容量规划,并验证系统容量的可扩展性。
- 根据各模块的承载量进行适当地收缩,来让出更多的可用资源
3. 性能测试策略
主要分为:
- 基准测试
- 负载测试
- 稳定性测试
- 其他:并发测试、压力测试、容量测试等
1)基准测试
狭义:也就是单用户测试。在测试环境确定以后,对业务模型中的重要业务做单独的测试,获取单用户运行时的各项性能指标,以进行基础的数据采集。
- 如:一个用户迭代 100 次,关注响应时间(事务成功率需 100%)。
广义:是一种测量和评估软件性能指标的活动。你可以在某个时刻通过基准测试建立一个已知的性能水平(称为基准线),当系统的软硬件环境发生变化之后再进行一次基准测试以确定那些变化对性能的影响。
- 如:先在 V1.0 版本的生产环境上进行性能测试收集所有的性能指标作为基准测试。
- 再在 V1.1 的开发版本上,使用与 V1.0 基准测试时相同的环境、配置、用户量等进行性能测试,再收集性能指标。
- 查看 V1.1 版本的性能是否比 V1.0 有所提升。
基准测试数据的用途:
- 为多用户并发测试和综合场景测试等性能分析提供参考依据。
- 识别系统或环境的配置变更对性能响应带来的影响。
- 为系统优化前后的性能提升/下降提供参考指标。
2)负载测试
含义:负载测试是指获取各个事务在不同负载条件下的性能表现。通过逐步增加系统负载量,测试系统性能的变化,并最终确定在满足系统的性能指标情况下,系统所能够承受的最大负载量的测试。
- 负载:指向服务器发送的请求数量。请求越多,负载越高。
- 负载测试关注的重点是逐步增加压力。如:分别用 10、20、30、...个并发用户跑 10 分钟。
- 通过负载测试,一般能找到系统的最优负载和最大负载。
示例:健身举哑铃
- 10斤哑铃,举起10个,需要15s
- 20斤哑铃,举起10个,需要15s
- 30斤哑铃,举起10个,需要15s —— 最优负载
- 40斤哑铃,举起10个,需要20s —— 最优负载
- 50斤哑铃,举起10个,需要40s
- 60斤哑铃,举起10个,需要100s —— 最大负载
- 70斤哑铃,举不起来
3)稳定性测试
含义:稳定性测试是指在服务器稳定运行(用户正常的业务负载下)的情况下进行长时间测试,并最终保证服务器能满足线上业务需求。时长一般为一天、一周等。
4)其他类型
并发测试:
-
广义:在极短的时间内发送多个请求,来验证服务器对并发的处理能力。如:抢红包、抢购、秒杀活动等。
-
狭义:模拟多用户在同一时间访问同一应用(进行同一具体操作)的测试,用于发现并发问题,例如线程锁、资源争用、数据库死锁等。
容量测试:
关注软件在极限压力下的各个参数值。例如:最大 TPS、最大连接数、最大并发数、最大数据条数等。
压力测试:
压力测试是在强负载(大数据量、大量并发用户等)下的测试,查看应用系统在峰值使用情况下操作行为,从而有效地发现系统的某项功能隐患、系统是否具有良好的容错能力和可恢复能力。
压力测试分为高负载下的长时间(如 24 小时以上)的稳定性压力测试,和极限负载情况下导致系统崩溃的破坏性压力测试。
-
稳定性压力测试:在系统高负载的情况下(下图中接近 C 点),长时间运行(24 小时),查看系统的处理能力。
-
破坏性压力测试:在系统极限负载的情况下(下图中 C-D 点),对系统进行压力测试,查看系统容错能力和错误恢复能力。

4. 性能测试指标
性能指标:在性能测试的过程中,记录一系列的测试数据值,用这些实际记录的数据值与需求中的性能要求做对比,达标则表示性能测试通过;未达标则可能是性能 Bug。
不同人群关注的性能指标各有侧重。前台服务接口的调用者一般只关心吞吐量、响应时间等外部指标。后台服务的所有者则不仅仅关注外部指标,还会关注 CPU、内存、负载等内部指标。
拿某打车平台来说,用户所关心的是智能提示服务的外部指标能不能抗住因大波优惠所导致的流量激增;而对于智能提示服务的开发、运维、测试人员,不仅仅关注外部指标,还会关注 CPU、内存、IO 等内部指标,以及部署方式、服务器软硬件配置等运维相关事项。
常见的性能指标:响应时间、并发数、吞吐量、错误率、点击数、PV/UV、系统资源利用率等。
-
3 个关键的业务指标:
- 响应时间
- 并发数
- TPS/QPS(吞吐量)
-
系统资源指标:
- CPU
- 内存
- 磁盘 I/O
- 网络带宽使用率
1)响应时间
含义:系统处理一个请求或一个事务的耗时(客户端从发起请求到获取响应)。
响应时间是终端用户对系统性能的最直观印象,包括了系统响应时间和前端展现时间。
- 系统响应时间:反应的是系统能力,又可以进一步细分为应用系统处理时间、数据库处理时间和网络传输时间等。
- 前端展现时间:取决于客户端收到服务器返回的数据后渲染页面所消耗的时间。
因此,性能测试又分为后端(服务器端)的性能测试和前端(通常是浏览器端)的性能测试。
系统响应时间 = 应用程序处理时间(A1+A2+A3) + 网络传输时间(N1+N2+N3+N4)

响应时间的指标取决于具体的服务类型。
- 如智能提示一类的服务,返回的数据有效周期短(用户多输入一个字母就需要重新请求),且对实时性要求比较高,则响应时间的上限一般在 100ms 以内。
- 而导航一类的服务,由于返回结果的使用周期比较长(整个导航过程中),响应时间的上限一般在 2-5s。
对于响应时间的统计,应从均值、.90、.99 等多个分布的角度统计,而不仅仅是给出均值。
50 th(60/70/80/90/95 th):如果把响应时间从小到大顺序排序,那么 50% 的请求的响应时间在这个范围之内。后面的 60/70/80/90/95 th 也是同样的含义。
常见瓶颈:同一请求/事务的响应时间忽大忽小。
在正常吞吐量下发生此问题,可能的原因有两方面:
- 服务对资源的加锁逻辑有问题,导致处理某些请求过程中花了大量的时间等待资源解锁。
- 硬件服务器本身分配给服务的资源有限,某些请求需要等待其他请求释放资源后才能继续执行。
2)并发数
含义:在同一时刻与服务器正常进行交互的用户数量。
- 系统用户数:系统注册的总用户数。
- 在线用户数:某段时间内访问系统的用户数,这些用户并不一定同时向系统提交请求。
- 并发用户数:某一物理时刻同时向系统提交请求的用户数。
3)吞吐量
含义:吞吐量(Throughput)是指在单位时间内,系统处理客户端请求的数量。
吞吐量 = 并发数 / 响应时间
从不同维度来描述:
- “Bytes/Second”和“Pages/Second”表示的吞吐量,主要受网络设置、服务器架构、应用服务器制约。
- “Requests/Second”和“Transactions/Second”表示的吞吐量,主要受应用服务器和应用本身实现的制约。
吞吐量是衡量服务器性能好坏的直接指标,通常表现如下:
-
在系统处于轻压力区(未饱和)时,并发用户数上升,平均响应时间(基本不变),系统吞吐量(上升)。
-
在系统处于重压力区(基本饱和)时,并发用户数上升,平均响应时间(上升),系统吞吐量(基本不变)。
-
在系统处于崩溃区(压力过载)时,并发用户数上升,平均响应时间(上升),系统吞吐量(下降)。
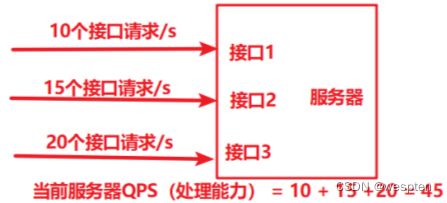
QPS
含义:服务器每秒钟处理的接口请求数量(一个服务器中有多个接口,QPS 指的是所有接口在同一个单位时间内的被处理数量之和)。
TPS
含义:服务器每秒钟处理的事务请求数量。
一个事务通常指的是界面上的一个业务场景操作。一个事务可以包含一个或者多个接口请求。
一个业务请求发送给服务器后,最终会定位到服务器对应的业务请求的代码,既有可能是一段代码也有可能是多段代码。
示例:
- 登录操作:发送一个登录请求 —— 则登录事务对应 1 个接口请求
- 支付操作:查询用户余额请求 + 支付安全校验请求 + 支付请求 —— 则支付事务对应 3 个接口请求
结论:
- 对于登录事务而言,当 TPS 为 10 时,服务器的 QPS 也是 10。
- 对于支付事务而言,当 TPS 为 10 时,服务器的 QPS 就是 30。
吞吐量计算方法:
- 均值计算
TPS = 总的请求数 / 总的时间
问题:对于同一天的时间内,不同的时间段,请求速率会有波动,这样计算会被平均掉,法测试负载高的情况。
- 二八原则
含义:80% 的请求数会集中在 20% 的时间内完成。
TPS = 总的请求数 * 80% / 总的时间 * 20%
通常二八原则的计算方法会比平均的计算方式更具代表性和准确。
- 按照每天的具体业务数据进行计算(稳定性测试 TPS)
当获取每天的具体业务统计数据时,就可以统计出业务请求集中的时间段作为有效业务时间;并统计有效业务时间内的总请求数
TPS = 有效业务时间的总请求数 * 80% / 有效业务时间 * 20%
- 模拟用户峰值业务操作的并发量:(压力测试 TPS)
获取每天的交易峰值的时间段,及这个时间段内的所有请求的数量。
TPS = 峰值时间内的请求数 / 峰值时间段 * 系数(倍数)
系数可以是 2、3、6、10,根据要达成的性能指标而定。
5. 案例
某购物商城,经过运营统计,正常一天成交额为 100 亿,客单价平均为 300 元,交易时间主要为 10:00-14:00 以及 17:00-24:00,其中 19:00-20:00 的成交量最大,大约成交 20 亿。
现升级系统,需要进行性能测试,保证软件在上线后能稳定运行。
请计算出系统稳定性测试时的并发(负载)量,及保证系统峰值业务时的并发(负载)量。
稳定性分析:
- 有效的交易时间为 10:00-14:00、17:00-24:00,一共为 7 个小时
- 有效的请求数:100e / 300
- 稳定性 TPS = 100e / 300 * 80% / (7 * 3600 * 20%)
压力分析:
- 峰值的交易时间为 19:00-20:00,一共为 1 个小时
- 有效的请求数:20e / 300
- 峰值 TPS = 20e / 300 / 3600 * 系数
6. 系统资源利用率
含义:指系统各种资源的使用情况。一般用“资源的使用量/总的资源可用量×100%”形成资源利用率的数据。
建议:没有特殊需求时,通常要求如下:
- CPU 不高于 80%(±5)
- 内存不高于 80%
- 磁盘不高于 90%
- 网络不高于 80%
7. 其他指标
1)点击数
点击数是衡量 Web 服务器处理能力的一个重要指标。
- 点击数不是通常一般人认为的访问一个页面就是 1 次点击数,而是指该页面包含的元素(图片、链接、框架等)向 Web 服务器发出的请求数量。
- 通常我们也用每秒点击次数(Hits per Second)指标来衡量 Web 服务器的处理能力。
- 注意:只有 Web 项目才有此指标。
2)错误率
含义:指系统在负载情况下,失败业务(取决于断言结果)的占比。
错误率=(失败业务数/业务总数)*100%
- 不同系统对错误率要求不同,但一般不超过千分之五。
- 稳定性较好的系统,其错误率应该由超时引起,即为超时率。
2、性能需求分析
性能需求分析是整个性能测试工作开展的基础,性能需求分析做的好不好直接影响到性能测试的结果。
性能需求分析通常包含的内容如下:
-
熟悉被测系统
- 熟悉系统的业务功能
- 熟悉系统的技术架构
-
确定性能测试指标
- 有需求:按照需求进行测试
- 没有需求:查找相关资料、与同类型软件对比、对未来数据进行预估等
-
明确性能测试内容
- 从业务角度,挑选核心业务进行测试
- 从技术角度,挑选逻辑复杂度高、数据量大的业务进行测试
-
确定性能测试策略
- 负载测试、稳定性测试等
1. 测试指标
性能测试指标要可测量,如定量指标给出具体数值,定性指标要给出具体描述。
- 吞吐量(TPS/QPS)
- 事务响应时间
- 用户并发数
- 数据库的数据量
- 系统的稳定运行时间要求
- 是否需要考虑系统支持水平扩展
- 考虑系统的最大容量
性能测试指标的来源一般如下:
1)需求文档
-
客户明确需求:通常情况,客户有明确的需求,提出一些性能测试指标。例如:每秒登录用户量多少,用户在线总量多少等。
-
客户隐形需求:基于客户明确指标下,会有一些隐性指标,例:100 万在线用户的查询在 5 秒响应,我们也许纳入性能测试指标内。
-
用户模型确定:有了上述性能测试指标后,就可以创建我们的用户模型了。如下:
- 用户指标:用户登录 TPS 需达到 50;
- 用户总量:总用户量 100 万;
- 用户模型:系统每天用户在线量在 100 万左右,平均在早晨 08:00-11:00 期间登录,其中登录与查询的比例为 1:5。
2)运营数据
根据历史运营数据收集、分析业务数据,如:
- 注册用户数、日活、月活等?计算用户的增长速度
- 每月、每周、每天的峰值业务量是多少?
- 用户频繁使用的功能模块、业务场景是哪些?
2. 测试内容
测试范围:
- 哪些接口要进行性能测试和稳定性测试。
- 哪些页面业务逻辑要进行性能测试和稳定性测试。
关注重点:
-
针对新增或重构模块:进行全面的测试,优先覆盖典型场景。典型场景如下示例:
- 核心业务功能
- 用户频繁使用的业务功能
- 特殊交易日或峰值交易的业务功能
- 发生过性能问题的业务功能
- 资源占用高的业务功能
- 代码优化过的业务功能
- ...
-
针对继承模块:进行回归验证即可,不做探索性的性能测试。
3. 测试策略
分析步骤:
- 根据上述性能测试内容的提取方法,整理出需要进行性能测试的测试点。
- 根据性能指标计算方法,得到每个测试点要满足的性能。
案例:
- 针对每个核心的业务功能(接口)都要达到对应的性能指标要求。
- 基于业务流程(多个接口的组合)来测试是否达到性能指标的要求。
- 模拟用户真实的业务场景,进行长时间的稳定性测试。
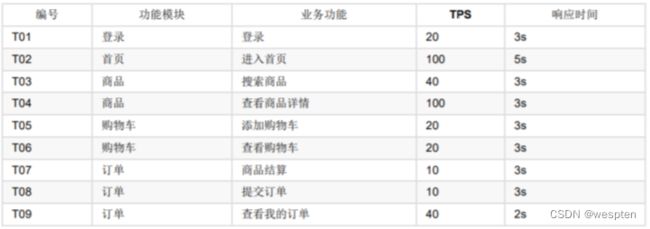
期望的 TPS 和最大响应时间,如下:
3、性能测试计划
在实际工作中,通常有性能测试的计划模板,对照模板进行编写即可。
通常包含内容如下:
- 测试背景 —— 背景介绍
- 测试目的 —— 需求分析阶段确定的项目需要达成的性能目标
- 测试范围 —— 需求分析阶段确定的性能测试点
- 测试策略 —— 结合前面的测试范围,考虑使用什么样的方式来进行性能测试,可以达成对应的测试目标
- 风险控制 —— 管理型分析(从技术、人员、时间、进度各个方面考虑可能会出现的问题及如何解决这些问题)
- 进度与分工 —— 说明性能测试工作要分为哪几个步骤进行,每个步骤的开始/结束时间,及对应的负责人
- 交付清单 —— 对应进度安排中每个阶段的阶段产物
案例如下:
1. 测试背景
轻商城是公司新开发的一个电商项目,为了保证项目上线后能够稳定的运行,且在后期推广中能够承受用户的增长,需要对项目进行性能测试。
2. 测试目的
对新电商项目进行性能测试的核心目的包括:
- 确定核心业务功能的 TPS。
- 对业务流程(多接口组合)进行压测。
- 系统能在实际系统运行压力的情况下,稳定的运行 24 小时。
3. 测试范围
通过对性能测试需求的调研和分析,确定被测系统的测试范围如下:
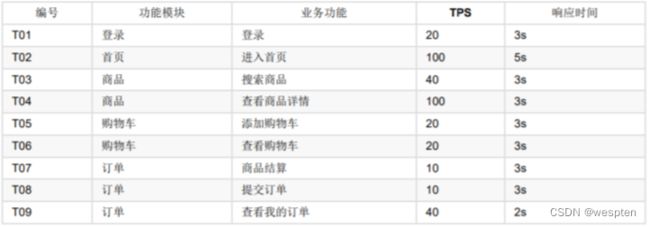
4. 测试策略
1. 基准测试
- 先做基准测试,确定估算的标准。
2. 负载测试
-
通过逐步增加系统负载,测试系统性能的变化,并最终确定在满足系统的性能指标情况下,系统所能够承受的最大负载量的测试。
-
分别模拟 5、10、30、50、100 个用户对系统进行负载测试,查看不同并发时系统软件各项指标是否符合需求。
3. 稳定性测试
-
用 200 个用户对系统进行 7*24 小时不间断的稳定性测试,验证系统在长时间的正常负载下的表现是否正常。
- 是否发生内存、句柄、连接等泄露;
- 是否正常触发 fullgc(JVM 调优就是为了减少 fullgc 频率);
- 数据库的容量问题;
- ...
5. 风险控制
| 风险类型 | 风险描述 | 风险级别 | 应对方案 |
|---|---|---|---|
| 环境风险 | 找不到合适的软硬件等资源 | 高 | 测试前期阶段识别,并使用相近配置进行验证,后期需在测试报告中提出 |
| 环境风险 | 部署出现问题,联调进度缓慢 | 高 | 更换环境;增加资源配置 |
| 人力风险 | 测试周期紧张,需要多名测试人员同时进行测试,但具备性能测试能力的人员不足 | 高 | 延长测试周期,或在前期培训相应人员 |
| 数据风险 | 构造测试数据时间较长 | 高 | 开发人员协助 |
| 交付风险 | 发现比较严重的 Bug | 高 | 延长测试时间,增加对应人员 |
6. 交付清单
性能测试计划、性能测试脚本、性能缺陷统计和性能测试报告等。
7. 进度与分工

4、性能测试用例设计
可参考如下性能测试用例的模板来编写:
- 对于单个业务功能(接口)的性能测试,每个测试点编写一个测试用例(如果多个接口有强关联,可以将多个接口放入同一个用例)。
- 对于多个业务功能的组合测试,需按照用户实际的业务场景,挑选出有代表性的业务流程编写测试用例。
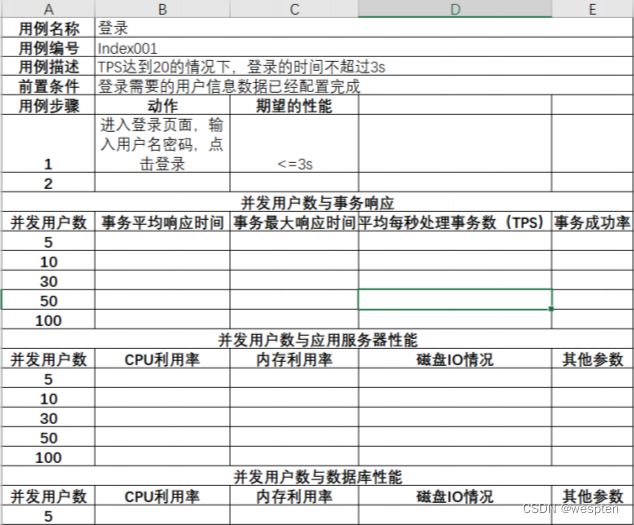
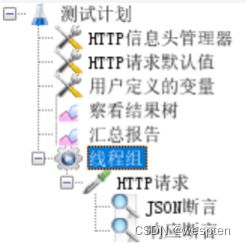
5、性能测试脚本开发
示例:使用 JMeter 编写测试脚本并调试,常用测试元件如下:
- 取样器 —— HTTP 请求
- 配置元件 —— HTTP 请求默认值
- 配置元件 —— 用户定义的变量
- 后置处理器 —— JSON 提取器
- 断言 —— 响应断言
- 断言 —— JSON 断言
- 监听器 —— 察看结果树
- 监听器 —— 聚合报告
基础结构如下:
6、性能测试资源准备
1. 测试环境
在进行性能则试之前,需要先完成性能测试环境的搭建工作,测试环境一般包括硬件环境、软件环境及网络环境。
性能测试环境的特点:
- 性能测试对测试环境的独立性要求更高,更为严格。
- 如果某环境下运行多个系统,就很难判断其中的某个环境对资源的占用情况。
尽量保持性能测试环境与真实生产环境的一致性:
- 硬件环境
- 包括服务器环境、网络环境等
- 软件环境
- 版本一致性:包括操作系统、数据库、被测应用程序、第三方软件等
- 配置一致性:包括操作系统、数据库、被测应用程序、第三方软件等
- 使用场景的一致性
- 基础业务数据的一致性:尽量模拟真实场景下的业务数据使用情况
- 业务操作模式的一致性:尽量模拟真实场景下用户的业务功能使用情况
2. 性能测试环境的建模
主要分为网络拓扑图、硬件、软件、参数配置、测试数据等。描述清楚几个要点:
- 有几台测试服务器?
- 每台服务都有什么服务?(前台 Web 服务、Redis、数据库等)
- 各服务器间的连接关系?

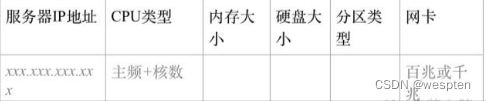
3. 建模思路
- 分析系统真实运行的网络拓扑环境;
- 明确公司可对性能测试进行投入的软硬件资源;
- 最好的性能测试环境就是待发布的生产环境;
- 次好的性能测试环境就是 1:1 复制的生产环境;
- 对于软硬件资源不足情况下,同比例缩小系统每一层结构中的机器数量。注意:系统中的每一层必须要有机器(至少可验证分库、分布式的处理正确性);
- 测试环境的搭建最好让运维人员负责,即使硬件不同,但在软件版本和配置上也可以尽可能跟生产环境保持一致。
思考:低配测试环境的性能测试意义。
即使测试环境较 low,但性能测试还是能起到意义的,至少能够:
- 验证业务流程的处理正确性。
- 验证程序没有明显的性能问题。
- 验证单台机器的处理能力。
4. 测试数据
构造方法:
压测环境中的数据量尽量与生产环境中的数据量一致。为了快速创建大量数据,通常使用如下方法:
- 通过接口构造
- 通过数据库构造
数据量:
数据库中该有多少测试数据才是合理的呢?
-
需要考虑、中长期系统运营的数据出现的可能性
-
和性能测试干系人讨论,讨论得出数据
-
需要考虑数据库配置文件、缓存参数的设置情况
-
明确 Cache 预 load 的数据说明
缓存数据:
-
业务正确性:如 HTTP 请求中的 cookies 贯穿整个业务交互过程,在测试脚本中应该缓存 cookies,保证业务正常,同时考虑后台对 cookies 的存取方式,保证大并发下不会出现 cookies 丢失或者写满的情况。
-
性能表现:关注冷启动和热启动这两种场景下的性能表现。
-
现象:
- 很多时候,在我们搭建完性能测试的基准环境,开始执行性能基准测试的时候,往往会发现系统刚开始运行时业务处理的响应时间都会相对比较长,只有当性能测试执行了一段时间后,系统的各项指标以及事务的响应时间才逐渐趋于正常。
- 另外,在做前端性能测试的时候,我们对于一个页面的打开时间通常会去统计两个指标,一个是首次打开时间,另一个是多次打开的时间。而且,通常来讲首次打开时间会远大于后面再次打开的时间。
-
原因:
- 服务器端会对“热点”数据进行缓存,而不是每次访问都直接从数据库中获取数据。那么,系统刚开始运行时,由于没有任何之前的访问记录,所有数据都需要访问数据库,所以前期的事务响应时间都会比较长。但是,随着缓存的建立,后续的访问就会比较快了。这个前期对系统的“预热”过程其实是在“预热”缓存。
- 浏览器端也会缓存从服务器端拿到的各种静态资源,在第一次访问时这些资源都需要从服务器端获取,而后面再访问时,这些静态资源已经在浏览器的缓存中了,所以访问速度会大大加快。
-
为此,在做性能基准测试的时候,有经验的工程师通常都会先用性能场景对系统进行一下“预热”,然后再真正开始测试。
5. 测试工具和监控工具
- Loadrunner
- Jmeter
- Siege
- Apache Bench
- 自写工具
6. 测试桩
测试桩作用:用于性能瓶颈定位时,规避测试中一些非主要的流程,通常由研发人员提供。
-
模块之间的测试桩:流程中包含 AB 模块,性能定位 AB 模块性能瓶颈时,需在 AB 模块之间做桩,让其支持单压 A,或者单压 B 模块。
-
辅助测试桩:测试流程中的一些非主要流程,且测试脚本不易实现。例:登录时安全校验输入验证,可适当地让研发人员进行前段安全校验的屏蔽。
7、性能测试脚本执行
先保证脚本调试通过之后,才能进入正式压测阶段。
正式执行性能测试前,需要根据要模拟的业务负载量来选择适当的测试机。
1. 压测机
通常会选择 Windows 或者 Linux 环境来执行脚本:
- Windows 环境:操作界面化、直观、易上手,但是软件占用机器资源较多,导致资源可使用率不高,降低了可支持并发数。
- Linux 环境:命令行操作,结果查看不太方便,但资源可使用率相对较高,可支持较高并发。
2. 分布式执行
如果单台压测机的并发量不能够满足负载要求,则可以通过分布式压测来提高并发量。如 JMeter 工具支持分布式压测,即多台机器同时执行同一个脚本,然后统计结果。
注意事项:
-
性能测试环境一定要是干净的:后台服务器除了自己没有其他人在用;测试元素不能有其他;本机一切影响网络的都要关掉。
-
如果是在生产环境压测,则注意是否有脏数据,以及测试后的数据清理机制。
-
最好每轮性能测试都重启机器,这样垃圾回收和缓存的影响能降到最小。
8、性能测试监控
1. 监控指标
-
业务指标:并发数、响应时间、吞吐量等
-
系统资源指标:
- CPU:CPU 使用率、CPU 使用类型(用户态、内核态)
- 内存利用率:实际内存、虚拟内存
- 磁盘:I/O 速度、磁盘等待队列
- 网络:带宽使用率
-
Java 应用:JVM 监控、JVM 内存(堆区)、Full GC 频率等
-
数据库:慢查询、连接数、锁、缓存命中率
-
压测机资源:CPU 使用率、内存使用率、磁盘空间使用率(测试日志的产生)、网络带宽使用率
一般情况下,测试人员只需要关注 1、2、5,来判断系统是否存在性能问题。
而开发人员要定位性能问题时,一般会再次复现场景,并监控所有的性能指标,来进行分析并调优。
2. 监控工具
要对性能测试指标进行监控,可以使用系统自带的监控工具,也可以使用第三方监控工具或者监控平台。
-
业务指标
- 通过性能测试工具(如 LoadRunner、JMeter 等)以图形化方式监控。
-
系统资源指标
- 使用 Jmeter 插件 PerfMon 进行服务器的系统资源监控。
- 使用 Linux 命令监控:top、free、vmstat、sar、iostat 等。
- 使用 Nmon 工具:全面监控 linux 系统资源使用情况,包括 CPU、内存、I/O 等,可独立于应用进行监控。
-
Java 应用
- jvisualvm
-
数据库
- SQL 查询
- SQL 日志
-
压测机资源
- Windows 自带“任务管理器”
- Linux 命令
3. 使用 Jmeter 客户端监控业务及系统资源指标
- 如使用 JMeter“聚合报告”组件监控业务指标。
- 如使用 JMeter 性能监控插件“PerfMon Metrics Collector”监控服务器资源指标。
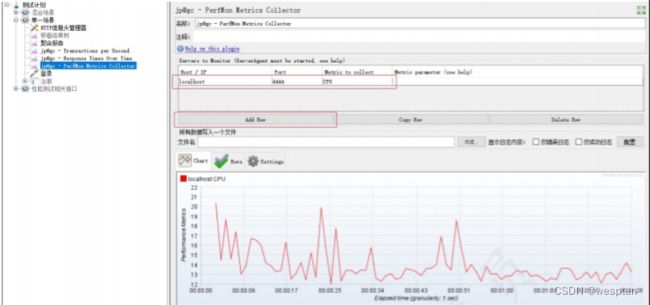
4. 使用 nmon 监控系统资源指标
nmon 是一款快速获取 linux 系统资源的小工具。
下载与安装:
- 下载 rpm 包:http://mirror.ghettoforge.org/distributions/gf/el/6/gf/x86_64/nmon-14i-1.gf.el6.x86_64.rpm
- 安装 rpm 包:rpm -ivh nmon-14i-1.gf.el6.x86_64.rpm
- 执行 ./nmon 即可运行

前台运行使用
键入“c”查看系统 CPU 使用情况:

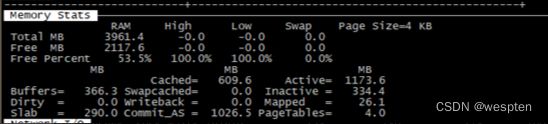
键入“m”查看系统内存使用情况:
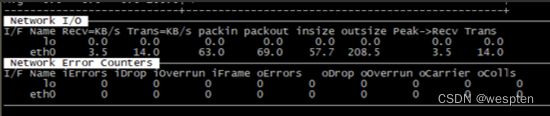
键入“n”查看网络使用情况使用情况:
5. JVM 监控
1)JVM dump
很多情况下,都会出现 dump 这个字眼,jvm 中也不例外,其中主要包括内存 dump、线程 dump。
首先,内存dump是指通过 jmap -dump
-
当发现应用内存溢出或长时间使用内存很高的情况下,通过内存 dump 进行分析可找到原因。
-
当发现 cpu 使用率很高时,通过线程 dump 定位具体哪个线程在做哪个工作占用了过多的资源。
2)jvisualvm
使用本地 jvisualvm 远程监控服务器的步骤如下:
(1)修改 Tomcat 的启动脚本(catalina.sh 或 catalina.bat),并启动 Tomcat 服务
-Dcom.sun.management.jmxremote
-Djava.rmi.server.hostname=182.92.91.137
-Dcom.sun.management.jmxremote.port=10086
-Dcom.sun.management.jmxremote.ssl=false
-Dcom.sun.management.jmxremote.authenticate=false(2)进入本地 jdk 安装目录的 bin 目录,找到 jvisualvm.exe 并启动
(3)右键“远程”选择“添加远程主机”,并输入步骤 1 配置的远程服务器 IP

(4)点击刚刚添加的主机,右键点击“添加JMX连接”,填写端口号(步骤 1 配置的端口号)

(5)点击 JMX 连接,选择监控,看 JVM 对应的监控指标。(重点关注:CPU 使用、堆的内存使用)

9、性能测试瓶颈调优
性能调优的步骤:
-
确定问题:根据性能监控的数据和性能分析的结果,确定性能存在的问题。
-
确定原因:确定问题之后,对问题进行分析,找出问题的原因。
-
确定解决方案(改服务器参数配置/增加硬件资源配置/修改代码)。
-
验证解决方案,分析调优结果。
注意:性能测试调优并不是一次完成的过程,针对同一个性能问题,上面的步骤可能要经过多次循环才能最终完成性能调优的目标(即:测试发现问题 -> 找原因 -> 调整 -> 验证 -> 分析 -> 再测试 ...)
10、输出性能测试报告
按照测试报告模板来进行编写。通常包含内容如下:
- 测试目标
- 测试结论(通过/不通过)
- 性能测试的过程记录:如测试范围、指标数据、发现的问题、调优结果等
- 性能测试过程中的风险,当前是否还存在风险
- 本次性能测试的复盘总结
五、常用压测工具
压力测试工具很多,如Locust工具、AB工具、webbench工具和http_load工具等,它们各有特色和最适合的场景。
1、轻量级http_load工具的使用
http_load是一款基于Linux平台的Web服务器性能测试工具,用于测试Web服务器的吞吐量与负载,以及Web页面的性能。对于Windows用户,官方没有提供exe版本用于直接安装,一些爱好者提供了一种通过Cygwin移植到Windows系统上的方法。
http_load工具的安装方式十分简单,在网站acme.com上下载tar.gz包,然后使用make和make install命令进行安装即可。到目前为止,最新的tar包为http_load-09Mar2016.tar。
在安装的过程中,使用make install命令时可能遇到的报错如下:
make install
rm -f /usr/local/bin/http_load
cp http_load /usr/local/bin
rm -f /usr/local/man/man1/http_load.1
cp http_load.1 /usr/local/man/man1
cp: /usr/local/man/man1: No such file or directory处理方式是先创建/usr/local/man文件夹,然后再重新运行make install命令。
完整的命令如下:
sudo mkdir -p /usr/local/man
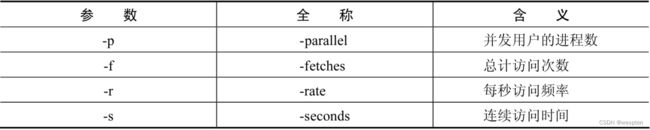
make install使用http_load做压力测试的方法简单、直接,语法如下:
http_load -p user_process_number -s second_number url_file其中的参数介绍如下表所示:
另外,url_file为要设置测试的网址文件,需要提前创建好,如在当前目录下创建以下内容的文件urls:
http://soso.com执行命令后的输出结果如下:
~/install_soft/http_load-09Mar2016/http_load -rate 5 -seconds 10 urls
45 fetches, 5 max parallel, 261720 bytes, in 10.004 seconds
5816 mean bytes/connection
4.49818 fetches/sec, 26161.4 bytes/sec
msecs/connect: 365.563 mean, 388.459 max, 361.376 min
msecs/first-response: 518.561 mean, 557.724 max, 504.79 min
HTTP response codes:
code 200 -- 45对结果进行分析:这是执行了一个持续时间为10s的测试,频率为每秒5个用户;最终结果有45个请求,最大并发数为5个进程,总计传输的数据是261 720字节;最后一行也很关键,它表示打开响应页面的类型,200是正常的HTTP状态码,如果是403比较多或者有50X,那么说明服务存在一定的问题,系统可能遇到了瓶颈。
下面总结使用http_load时的常见错误:
- byte count wrong:http_load在处理时会关注每次访问同一个URL的返回结果(即字节数)是否一致,若不一致就会抛出该错误。
- Too many open files:系统限制的open files太小,通过ulimit -n修改open files值即可。
- 无法发送最大请求(请求长度大于600个字符):可以将默认接收请求的buf值调整为更大的值。
- Cannot assign requested address:客户端频繁地连服务器,由于每次连接都在很短的时间内结束,导致出现很多的TIME_WAIT,以致用尽了可用的端口号,使新的连接没有办法绑定端口,所以要修改客户端机器的配置。
可以在sysctl.conf中添加以下配置:
- net.ipv4.tcp_tw_reuse = 1:表示开启重用,允许将TIME-WAIT sockets重新用于新的TCP连接,默认为0,表示关闭。
- net.ipv4.tcp_timestamps=1:表示开启对TCP时间戳的支持,若该项设置为0,则下面一项设置不起作用。
- net.ipv4.tcp_tw_recycle=1:表示开启TCP连接中对TIME-WAIT sockets的快速回收。
2、webbench工具的使用
除了Locust之外,另外一款流行的Web性能测试工具是webbench,它是轻量级的网站测压工具,最多可以对网站进行3万并发量的模拟请求测试。webbench可以控制持续时间、是否使用缓存、是否等待服务器响应等参数,对中小型网站的测试有明显的效果,可以很容易测试出网站的承压极限。但webbench对于大型网站的测试效果不是很明显,因为这种网站(如百度)的承压能力非常强。
webbench工具最重要的两个测试指标是每秒响应的请求数和每秒传输的数据量。
webbench的安装方式和http_load类似,可以到官方网上下载对应的tar.gz包,然后使用命令make和make install进行安装即可。到目前为止,webbench工具已经很久没有更新了,最新版本为webbench 1.5。
例如,CentOS系统上进行安装,安装命令如下:
wget http://www.ha97.com/code/webbench-1.5.tar.gz
tar xf webbench-1.5.tar.gz
yum install gcc* ctags* -y
make && make installwebbench的使用方式很简单,语法如下:
webbench -c [并发数] -t [运行时间] [访问的URL]下面使用webbench测试之前的tinyBBS项目。先启动该项目服务,然后执行如下命令:
webbench -c 300 -t 10 http://127.0.0.1:5000/
Webbench - Simple Web Benchmark 1.5
Copyright (c) Radim Kolar 1997-2004, GPL Open Source Software.
Benchmarking: GET http://127.0.0.1:5000/
300 clients, running 10 sec.使用webbench工具进行压力测试时应注意:
- 压力测试会对服务器性能产生一些影响,如会消耗CPU和内存资源,因此为了测试的准确性,应尽量找一个相对稳定的服务器进行测试。
- 压力测试应该逐步增加。例如,在并发数量增加到50的时候看看负载情况,增加到100的时候再观察一下情况,然后再进一步增加到200并发、300并发等,最后测出网站变慢甚至打不开网页时的负载量。
- 针对一些访问量大的页面进行压力测试效果更佳,因此应有的放矢,对重要的页面和功能接口进行压力测试。
3、AB工具的使用
比起webbench,开发者更熟悉AB工具。
AB工具是Apache超文本传输协议(HTTP)的性能测试工具。它的设计意图是描绘当前所安装的Apache的执行性能,显示用户安装的Apache每秒可以处理多少个请求。它是和Apche服务一起捆绑安装的,有Apache服务就有AB工具。
AB工具的安装很简单,只需要到Apache官网上下载对应操作系统的安装包即可,这个工具针对Windows也有专门的版本,并且在不断维护和更新中。如果之前已经在计算机上安装过Apache服务,可以在执行文件的相同目录下找到AB工具的可执行exe文件。
1. Windows系统的安装方式
1)Apache下载

选择一个版本,点击Download:

点击File For Microsoft Windows:
由于Apache HTTP Server官方不提供二进制(可执行)的发行版,所以我们选择一些贡献者编译完成的版本,我们选择第一个Apache Haus。
点击ApacheHaus,进入下载页:

选择其中一个版本,如果你的Windows还没安装对应的VC环境的话,选择对应的VCRedistribute版本下载安装。我选择Apache 2.4VC9版,因为我的电脑中已经安装了VC9的环境。
点击JumpLinks下第一行的某一个版本,下载对应压缩包。
2)配置Apache
解压后进入里面Apache22(最后两位数字可能不同)文件夹,使用文本编辑器(推荐ultraedit)打开conf文件夹中的httpd.conf配置文件
找到ServerRoot选项,设置Apache目录,大约在35行左右,将其改成你的Apache程序的文件夹,例:
ServerRoot "C:/Users/myPC/Downloads/httpd-2.2.31-x86-r3/Apache22"找到Listen选项,设置端口,大约46行,一般不修改,使用默认80,在开启服务器前请保证80端口未被占用
找到DocumentRoot选项,修改服务器根目录,例:
DocumentRoot "F:/"请保证此目录存在,否则服务器无法正常启动。
修改Directory,保证其与服务器根目录相同,只修改下面的第一行中引号部分:
#
# Possible values for the Options directive are "None", "All",
# or any combination of:
# Indexes Includes FollowSymLinks SymLinksifOwnerMatch ExecCGI MultiViews
#
# Note that "MultiViews" must be named *explicitly* --- "Options All"
# doesn't give it to you.
#
# The Options directive is both complicated and important. Please see
# http://httpd.apache.org/docs/2.2/mod/core.html#options
# for more information.
#
Options Indexes FollowSymLinks
#
# AllowOverride controls what directives may be placed in .htaccess files.
# It can be "All", "None", or any combination of the keywords:
# Options FileInfo AuthConfig Limit
#
AllowOverride None
#
# Controls who can get stuff from this server.
#
Order allow,deny
Allow from all
找到ScriptAlias选项,设置服务器脚本目录,大约326行,一般将其设置为Apache目录下的cgi-bin文件夹:
ScriptAlias /cgi-bin/ "C:/Users/myPC/Downloads/httpd-2.2.31-x86-r3/Apache22/cgi-bin"找到随后的Directory选项,设置脚本目录,大约342行,需要将其设置为和前面的ScriptAlias目录相同:
AllowOverride None
Options None
Order allow,deny
Allow from all
3)ssl配置
如果你这使启动服务,一般会出现下面的消息对话框:

提示:
Windows不能在本地计算机启动Apache2.2。有关更多信息,查阅系统日志文件。如果这是非Microsoft服务,请与厂商联系,并参考特定服务器错误代码1。
确定此问题的原因:
右键 计算机,点击管理->Windows日志->应用程序,显示如下

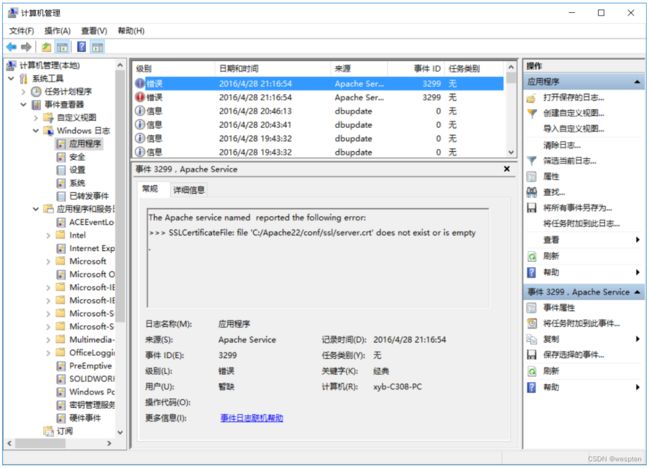
这是由于SSL配置不正确所产生的,下面说一下解决办法。
打开Apache程序目录下的conf/extra/httpd-ahssl.conf文件,配置VirtualHost选项,有三处名为VirtualHost的选项,均需修改。
第一个在107行左右。
在110行左右,将其中的SSLCertificateFile改为:Apache所在目录/conf/ssl/server.crt
在111行左右,将SSLCertificateKeyFile改为:Apache所在目录/conf/ssl/server.key
在112行左右,将DocumentRoot改为你的服务器根目录
在126行左右,将CustomLog改为:Apache所在目录/logs/ssl_request.log,这个不改的话也会错。一般会出现如下错误:

Apache2.2服务由于下列服务特定错误而终止:函数不正确。
改成的效果:
SSLEngine on
ServerName localhost:443
SSLCertificateFile C:/Users/myPC/Downloads/httpd-2.2.31-x86-r3/Apache22/conf/ssl/server.crt
SSLCertificateKeyFile C:/Users/myPC/Downloads/httpd-2.2.31-x86-r3/Apache22/conf/ssl/server.key
DocumentRoot F:/
# openssl req -new > server.csr
# openssl rsa -in privkey.pem -out server.key
# openssl x509 -in server.csr -out server.crt -req -signkey server.key -days 2048
SSLOptions +StdEnvVars
SSLOptions +StdEnvVars
BrowserMatch "MSIE [2-5]"
nokeepalive ssl-unclean-shutdown
downgrade-1.0 force-response-1.0
CustomLog "C:/Users/myPC/Downloads/httpd-2.2.31-x86-r3/Apache22/logs/ssl_request.log"
"%t %h %{SSL_PROTOCOL}x %{SSL_CIPHER}x "%r" %b"
主要改上文四处地方。
在130行和152行还有另外两个VirtualHost,均需修改上述的四个选项。
例:
130行
SSLEngine on
ServerName serverone.tld:443
SSLCertificateFile C:/Users/myPC/Downloads/httpd-2.2.31-x86-r3/Apache22/conf/ssl/serverone.crt
SSLCertificateKeyFile C:/Users/myPC/Downloads/httpd-2.2.31-x86-r3/Apache22/conf/ssl/serverone.key
DocumentRoot F:/
# openssl req -new > serverone.csr
# openssl rsa -in privkey.pem -out serverone.key
# openssl x509 -in serverone.csr -out serverone.crt -req -signkey serverone.key -days 2048
SSLOptions +StdEnvVars
SSLOptions +StdEnvVars
BrowserMatch "MSIE [2-5]"
nokeepalive ssl-unclean-shutdown
downgrade-1.0 force-response-1.0
CustomLog "C:/Users/myPC/Downloads/httpd-2.2.31-x86-r3/Apache22/logs/ssl_request.log"
"%t %h %{SSL_PROTOCOL}x %{SSL_CIPHER}x "%r" %b" env=HTTPS
第152行:
SSLEngine on
ServerName servertwo.tld:443
SSLCertificateFile C:/Users/myPC/Downloads/httpd-2.2.31-x86-r3/Apache22/conf/ssl/servertwo.crt
SSLCertificateKeyFile C:/Users/myPC/Downloads/httpd-2.2.31-x86-r3/Apache22/conf/ssl/servertwo.key
DocumentRoot F:/
# openssl req -new > servertwo.csr
# openssl rsa -in privkey.pem -out servertwo.key
# openssl x509 -in servertwo.csr -out servertwo.crt -req -signkey servertwo.key -days 2048
SSLOptions +StdEnvVars
SSLOptions +StdEnvVars
BrowserMatch "MSIE [2-5]"
nokeepalive ssl-unclean-shutdown
downgrade-1.0 force-response-1.0
CustomLog "C:/Users/myPC/Downloads/httpd-2.2.31-x86-r3/Apache22/ssl_request.log"
"%t %h %{SSL_PROTOCOL}x %{SSL_CIPHER}x "%r" %b"
上述的两个VirtualHost均需修改四处
这样,Apache就算配置完了,如果还有问题,可能还需配置./conf/extra/httpd-ssl.conf,配置方法和配置VirtualHost的相似
4)启动Apache HTTP Server
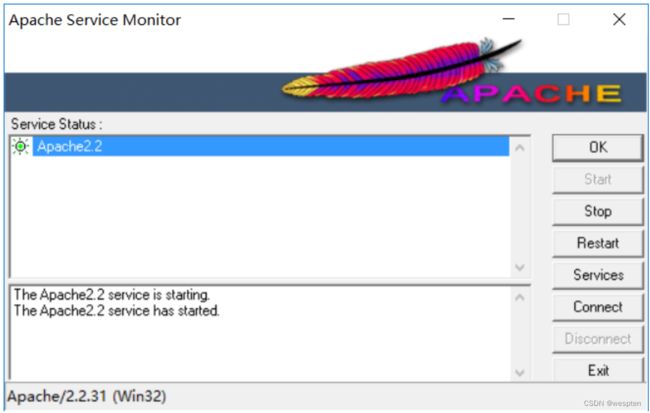
使用Windows命令行以管理员身份进入Apache程序的文件夹下的bin文件夹,输入httpd -k install,完成Apache服务的安装。
然后双击bin目录下的ApacheMonitor.exe,点击右边的start启动服务器,如果正常,如下图:
测试一下:

2. Mac OS系统的安装与使用
同样也是在官网上找到对应的版本,选择httpd-2.4.41.tar.gz包即可(版本为2.4.41),如图所示。然后再通过“编译三板斧”(即预配置、编译、编译安装3个步骤)来安装,对应的命令为:
./configure
make
make install安装好后,在终端中输入ab,输出信息如下:
ab: wrong number of arguments
Usage: ab [options] [http[s]://]hostname[:port]/path
Options are:
-n requests Number of requests to perform
-c concurrency Number of multiple requests to make at a time
-t timelimit Seconds to max. to spend on benchmarking
This implies -n 50000
-s timeout Seconds to max. wait for each response
Default is 30 seconds
-b windowsize Size of TCP send/receive buffer, in bytes
-B address Address to bind to when making outgoing connections
-p postfile File containing data to POST. Remember also to set -T
-u putfile File containing data to PUT. Remember also to set -T
-T content-type Content-type header to use for POST/PUT data, eg.
'application/x-www-form-urlencoded'
Default is 'text/plain'
-v verbosity How much troubleshooting info to print
-w Print out results in HTML tables
-i Use HEAD instead of GET
-x attributes String to insert as table attributes
-y attributes String to insert as tr attributes
-z attributes String to insert as td or th attributes
-C attribute Add cookie, eg. 'Apache=1234'. (repeatable)
-H attribute Add Arbitrary header line, eg. 'Accept-Encoding: gzip'
Inserted after all normal header lines. (repeatable)
-A attribute Add Basic WWW Authentication, the attributes
are a colon separated username and password.
-P attribute Add Basic Proxy Authentication, the attributes
are a colon separated username and password.
-X proxy:port Proxyserver and port number to use
-V Print version number and exit
-k Use HTTP KeepAlive feature
-d Do not show percentiles served table.
-S Do not show confidence estimators and warnings.
-q Do not show progress when doing more than 150 requests
-l Accept variable document length (use this for dynamic
pages)
-g filename Output collected data to gnuplot format file.
-e filename Output CSV file with percentages served
-r Don't exit on socket receive errors.
-m method Method name
-h Display usage information (this message)
-I Disable TLS Server Name Indication (SNI) extension
-Z ciphersuite Specify SSL/TLS cipher suite (See openssl ciphers)
-f protocol Specify SSL/TLS protocol
(TLS1, TLS1.1, TLS1.2 or ALL)例如,要对百度首页进行并发测试,命令如下:
ab -n 5 -c 2 https://www.baidu.com/其中,-n表示选择多少个请求,-c表示并发数。执行命令后,输出结果如下:
This is ApacheBench, Version 2.3 <$Revision: 1826891 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking www.baidu.com (be patient).....done
Server Software: BWS/1.1
Server Hostname: www.baidu.com
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES128-GCM-SHA256,2048,128
TLS Server Name: www.baidu.com
Document Path: /
Document Length: 166943 bytes
Concurrency Level: 2
Time taken for tests: 6.506 seconds
Complete requests: 5
Failed requests: 4
(Connect: 0, Receive: 0, Length: 4, Exceptions: 0)
Total transferred: 839184 bytes
HTML transferred: 833016 bytes
Requests per second: 0.77 [#/sec] (mean)
Time per request: 2602.435 [ms] (mean)
Time per request: 1301.218 [ms] (mean, across all concurrent requests)
Transfer rate: 125.96 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 621 703 58.1 723 775
Processing: 1241 1448 246.4 1485 1775
Waiting: 372 425 93.9 392 592
Total: 1916 2151 233.5 2183 2493
Percentage of the requests served within a certain time (ms)
50% 2096
66% 2270
75% 2270
80% 2493
90% 2493
95% 2493
98% 2493
99% 2493
100% 2493 (longest request)其中比较重要的参数如下。
- ·Requests per second:吞吐率
公式为:吞吐率=总完成请求数量/测试消耗时间
- Concurrency Level:并发数。
- Time per request:用户平均请求等待时间。
公式为:用户平均请求等待时间=处理完成请求的总时间/并发用户数
- Time per request:服务器平均请求等待时间。
公式为:服务器平均请求等待时间=处理完所有请求所用时间/总请求数
AB工具还可以将post数据存储在JSON文件中,具体命令如下:
ab -c 10 -n 200 -t 5 -p ./post.json -T 'application/json' http://httpbin.org/post其中,post.json文件的内容也很简单,就是JSON格式的数据,具体如下:
{
'key1':'value',
'key2':'value2'
}3. 利用Python操作AB工具
有时候会觉得AB工具不够灵活,需要在它的基础上根据实际需求进行封装。下面我们就尝试编写一个Python脚本来操作AB工具。
#-*- coding: utf-8 -*-
import os
import json
class AbTool(object):
def __init__(self, url, child_process, request_num):
self.url = url
self.child_process = child_process
self.request_num = request_num
def set_url(self, url):
self.url = url
def set_child_process(self, child_process):
self.child_process = child_process
def set_request_num(self, request_num):
self.request_num = request_num
def set_time(self, seconds):
self.seconds = seconds
def runAndStore(self):
cmd = "ab -n " + str(self.request_num) + " -c " + str(self.child_process) + " -t 5 " + self.url
print(cmd)
os.system(cmd)
tool = AbTool('https://www.soso.com/', 2, 100)
tool.runAndStore()其实ab命令的参数设置非常不“智能”,基本都是硬编码,当参数需要调整的时候,要在脚本里修改相应代码,因此可以考虑把参数写入一个配置文件中,通过读取配置文件来设置参数。配置文件的格式有很多种,如传统的ini和XML,也有比较流行的YAML。这里推荐使用YAML格式的配置文件,因其可读性更高。
下面介绍一下YAML方面的知识。
YAML是一种用来表达数据序列化的格式,具有较高的可读性。YAML参考了其他多种语言,包括C语言、Python和Perl,并从XML和电子邮件的数据格式(RFC 2822)中获得灵感。目前已经有数种编程语言和脚本语言支持(或者说解析)YAML。
YAML的数据结构类似于大纲的缩进方式,例如:
items:
prod_id: ST002321
price: 37.00
rank: 4
service:
service_name: nginx
port: 8081
pid: 555345Python中也有用于解析YAML格式数据的包,安装方式如下:
pip install yaml下面编写一个测试脚本,代码如下:
# coding:utf-8
import yaml
file_path = './test.yaml'
with open(file_path, 'rb') as f:
data = yaml.load(f)
print(data)test.yaml文件的内容如下:
stock:
code_no: 000977
name: lcxx
price: 44.38
market: SZ执行命令python test_yml.py,输出结果如下:
python test_yml.py
test_yml.py:6: YAMLLoadWarning: calling yaml.load() without Loader=... is
deprecated, as the default Loader is unsafe. Please read https://msg.pyyaml.
org/load for full details.
data = yaml.load(f)
{'stock': {'code_no': '000977', 'name': 'lcxx', 'price': 44.38, 'market':
'SZ'}}可以看出,yaml包将YAML文件内容解析成可读性更强的字典结构,后续就可以像普通字典一样进行操作。下面将之前的ab_tool.py(代码6.3)改编为解析YAML文件的ab_tool2.py,代码如下:
# -*- coding: utf-8 -*-
import os
import yaml
class AbTool(object):
def __init__(self):
config_data = self.load_config()
self.url = config_data['config']['url']
self.child_process = config_data['config']['child_process']
self.request_num = config_data['config']['request_num']
# 执行持续的时间
self.running_time = config_data['config']['running_time']
# 从YAML文件中获取config
def load_config(self):
config_data = {}
file_path = './ab_config.yaml'
with open(file_path, 'rb') as f:
config_data = yaml.load(f)
return config_data
def set_url(self, url):
self.url = url
def set_child_process(self, child_process):
self.child_process = child_process
def set_request_num(self, request_num):
self.request_num = request_num
def set_time(self, seconds):
self.seconds = seconds
def runAndStore(self):
cmd = "ab -n " + str(self.request_num) + " -c " + str(self.child_
process) + " -t " + str(self.running_time) + "" + self.url
print(cmd)
os.system(cmd)
tool = AbTool()
tool.runAndStore()在与代码同级目录下的ab_config.yaml文件是配置文件,其内容如下:
config:
url: https://soso.com/
child_process: 3
request_num: 100
running_time: 5执行python ab_tool2.py,输出结果如下:
ab -n 100 -c 3 -t 5 https://soso.com/
This is ApacheBench, Version 2.3 <$Revision: 1826891 $>
Copyright 1996 Adam Twiss, Zeus Technology Ltd, http://www.zeustech.net/
Licensed to The Apache Software Foundation, http://www.apache.org/
Benchmarking soso.com (be patient)
Finished 65 requests
Server Software: nginx
Server Hostname: soso.com
Server Port: 443
SSL/TLS Protocol: TLSv1.2,ECDHE-RSA-AES256-GCM-SHA384,2048,256
TLS Server Name: soso.com
Document Path: /
Document Length: 5816 bytes
Concurrency Level: 3
Time taken for tests: 5.020 seconds
Complete requests: 65
Failed requests: 0
Total transferred: 427895 bytes
HTML transferred: 378040 bytes
Requests per second: 12.95 [#/sec] (mean)
Time per request: 231.686 [ms] (mean)
Time per request: 77.229 [ms] (mean, across all concurrent requests)
Transfer rate: 83.24 [Kbytes/sec] received
Connection Times (ms)
min mean[+/-sd] median max
Connect: 125 154 22.2 156 260
Processing: 44 55 7.8 56 83
Waiting: 43 54 7.7 55 82
Total: 170 209 25.9 213 304
Percentage of the requests served within a certain time (ms)
50% 212
66% 220
75% 224
80% 229
90% 243
95% 249
98% 252
99% 304
100% 304 (longest request)4、Locust工具的使用
性能测试的工具非常多,有针对Web服务的并发工具,也有针对客户端的工具,还有针对数据库读写I/O的检测工具。这里介绍Python技术栈下的性能测试工具——Locust,并用它进行实践。
Locust是使用Python语言编写的开源性能测试工具,其简洁、轻量、高效的并发机制基于Gevent协程,可以实现单机模拟生成较高的并发压力。使用该工具可以节省实际的物理机资源,通过单机达到并发的效果,从而进行压力测试,找到最大的承压点。Locust用于对网站(或其他系统)进行负载测试,并确定系统可以处理多少个并发用户。
Locust的主要优点如下:
- 测试人员可以使用普通的Python脚本进行用户场景测试,而无须具备其他编程语言和技能。
- 具有分布式和可扩展的特性,支持上万个用户。
- 使用者可以基于Web的用户界面实时监控脚本运行的状态,可视化地进行分析,以方便使用和管理。
- 几乎可以测试任何类型的系统,除了常规的Web HTTP接口外,还可自定义客户端,测试其他类型的系统。
1. 环境搭建
Locust目前支持Python 2.7/3.4/3.5/3.6及以上版本,安装也十分方便,可以使用pip命令进行安装:
pip install locustio在安装的过程中可能出现超时下载并导致失败的情况,这是因为部分依赖包资源在国外的网站上,有条件的朋友可以访问外网进行安装,或者使用豆瓣网的镜像库在国内网络环境下安装。
安装完毕后可以检查一下安装的版本,命令如下:
pip show locustio在计算机上执行该命令后输出结果如下:
Name: locustio
Version: 0.14.4
Summary: Website load testing framework
Home-page: https://locust.io/
Author: Jonatan Heyman, Carl Bystrom, Joakim Hamrén, Hugo Heyman
Author-email:
License: MIT
Location: /Library/Frameworks/Python.framework/Versions/3.7/lib/python3.7/
site-packages
Requires: flask, gevent, msgpack-python, psutil, ConfigArgParse, pyzmq,
geventhttpclient-wheels, requests, six
Required-by:想了解更多的Locust命令,可以输入locust --help命令,输出结果如下:
usage: locust [-h] [-H HOST] [--web-host WEB_HOST] [-P PORT] [-f LOCUSTFILE]
[--csv CSVFILEBASE] [--csv-full-history] [--master] [--slave]
[--master-host MASTER_HOST] [--master-port MASTER_PORT]
[--master-bind-host MASTER_BIND_HOST]
[--master-bind-port MASTER_BIND_PORT]
[--heartbeat-liveness HEARTBEAT_LIVENESS]
[--heartbeat-interval HEARTBEAT_INTERVAL]
[--expect-slaves EXPECT_SLAVES] [--no-web] [-c NUM_CLIENTS]
[-r HATCH_RATE] [-t RUN_TIME] [--skip-log-setup] [--step-load]
[--step-clients STEP_CLIENTS] [--step-time STEP_TIME]
[--loglevel LOGLEVEL] [--logfile LOGFILE] [--print-stats]
[--only-summary] [--no-reset-stats] [--reset-stats] [-l]
[--show-task-ratio] [--show-task-ratio-json] [-V]
[--exit-code-on-error EXIT_CODE_ON_ERROR] [-s STOP_TIMEOUT]
[LocustClass [LocustClass ...]]
Args that start with '--' (eg. -H) can also be set in a config file
(~/.locust.conf or locust.conf). Config file syntax allows: key=value,
flag=true, stuff=[a,b,c] (for details, see syntax at https://goo.gl/R74nmi).
If an arg is specified in more than one place, then commandline values
override config file values which override defaults.
positional arguments:
LocustClass
optional arguments:
-h, --help show this help message and exit
-H HOST, --host HOST Host to load test in the following format:
http://10.21.32.33
--web-host WEB_HOST Host to bind the web interface to. Defaults to '' (all
interfaces)
-P PORT, --port PORT, --web-port PORT
Port on which to run web host
-f LOCUSTFILE, --locustfile LOCUSTFILE
Python module file to import, e.g. '../other.py'.
Default: locustfile
--csv CSVFILEBASE, --csv-base-name CSVFILEBASE
Store current request stats to files in CSV format.
--csv-full-history Store each stats entry in CSV format to
_stats_history.csv file
--master Set locust to run in distributed mode with this
process as master
--slave Set locust to run in distributed mode with this
process as slave
--master-host MASTER_HOST
Host or IP address of locust master for distributed
load testing. Only used when running with --slave.
Defaults to 127.0.0.1.
--master-port MASTER_PORT
The port to connect to that is used by the locust
master for distributed load testing. Only used when
running with --slave. Defaults to 5557. Note that
slaves will also connect to the master node on this
port + 1.
--master-bind-host MASTER_BIND_HOST
Interfaces (hostname, ip) that locust master should
bind to. Only used when running with --master.
Defaults to * (all available interfaces).
--master-bind-port MASTER_BIND_PORT
Port that locust master should bind to. Only used when
running with --master. Defaults to 5557. Note that
Locust will also use this port + 1, so by default the
master node will bind to 5557 and 5558.
--heartbeat-liveness HEARTBEAT_LIVENESS
set number of seconds before failed heartbeat from
slave
--heartbeat-interval HEARTBEAT_INTERVAL
set number of seconds delay between slave heartbeats
to master
--expect-slaves EXPECT_SLAVES
How many slaves master should expect to connect before
starting the test (only when --no-web used).
--no-web Disable the web interface, and instead start running
the test immediately. Requires -c and -t to be
specified.
-c NUM_CLIENTS, --clients NUM_CLIENTS
Number of concurrent Locust users. Only used together
with --no-web
-r HATCH_RATE, --hatch-rate HATCH_RATE
The rate per second in which clients are spawned. Only
used together with --no-web
-t RUN_TIME, --run-time RUN_TIME
Stop after the specified amount of time, e.g. (300s,
20m, 3h, 1h30m, etc.). Only used together with --no-
web
--skip-log-setup Disable Locust's logging setup. Instead, the
configuration is provided by the Locust test or Python
defaults.
--step-load Enable Step Load mode to monitor how performance
metrics varies when user load increases. Requires
--step-clients and --step-time to be specified.
--step-clients STEP_CLIENTS
Client count to increase by step in Step Load mode.
Only used together with --step-load
--step-time STEP_TIME
Step duration in Step Load mode, e.g. (300s, 20m, 3h,
1h30m, etc.). Only used together with --step-load
--loglevel LOGLEVEL, -L LOGLEVEL
Choose between DEBUG/INFO/WARNING/ERROR/CRITICAL.
Default is INFO.
--logfile LOGFILE Path to log file. If not set, log will go to
stdout/stderr
--print-stats Print stats in the console
--only-summary Only print the summary stats
--no-reset-stats [DEPRECATED] Do not reset statistics once hatching has
been completed. This is now the default behavior. See
--reset-stats to disable
--reset-stats Reset statistics once hatching has been completed.
Should be set on both master and slaves when running
in distributed mode
-l, --list Show list of possible locust classes and exit
--show-task-ratio print table of the locust classes' task execution
ratio
--show-task-ratio-json
print json data of the locust classes' task execution
ratio
-V, --version show program's version number and exit
--exit-code-on-error EXIT_CODE_ON_ERROR
sets the exit code to post on error
-s STOP_TIMEOUT, --stop-timeout STOP_TIMEOUT
Number of seconds to wait for a simulated user to
complete any executing task before exiting. Default is
to terminate immediately. This parameter only needs to
be specified for the master process when running
Locust distributed.Locust主要由下面几个库构成:
- gevent:一种基于协程的Python网络库,它用到了Greenlet提供的封装了libevent事件循环的高层同步API。
- Flask:使用Python编写的轻量级Web应用框架。
- requests:Python HTTP库。
- msgpack-python:MessagePack是一种快速、紧凑的二进制序列化格式,适用于类似于JSON的数据格式。msgpack-python主要提供MessagePack数据序列化及反序列化的方法。
- six:Python 2和Python 3的兼容库,用来封装Python 2和Python 3之间的差异性。
- pyzmq:是zeromq(一种通信队列)的Python绑定,主要用来实现Locust的分布式运行。
Locust的官方网站上有一个最简单的用例,其代码如下:
#coding:utf-8
from locust import HttpLocust, TaskSet, task
class UserBehavior(TaskSet):
def on_start(self):
""" on_start is called when a Locust start before any task is scheduled """
self.login()
def login(self):
self.client.post("/login", {"username":"ellen_key", "password":
"education"})
@task(2)
def index(self):
self.client.get("/")
@task(1)
def profile(self):
self.client.get("/profile")
class WebsiteUser(HttpLocust):
task_set = UserBehavior
host='http://example.com'
min_wait = 5000
max_wait = 9000上述程序对网站example.com进行测试,先模拟用户登录系统,然后随机访问index(/)和profile页面(/profile),请求比例为2∶1,两次请求之间的时间间隔随机,介于5s~9s。
运行上述脚本很简单,先通过cd命令跳转到该脚本所在的目录,然后执行如下命令:
locust如果locust脚本不在当前目录下,那么需要使用-f指定文件,并使用--host指定测试主机地址,具体命令如下:
locust -f /path/to/file_name.py --host=http://example.com如果要运行分布在多个进程上的locust脚本,则需要使用--master启动主进程,具体命令如下:
locust -f /path/to/file_name.py --master --host=http://example.com然后再使用--slave启动任意数量的从进程,具体命令如下:
locust -f /path/to/file_name.py --slave --host=http://example.com如果要在多台机器上分布式运行locust脚本,需要执行以下命令:
locust -f /path/to/file_name.py --slave --master-host=192.168.1.24 --host=
http://example.com2. Locust快速入门
Locust可以先在Web界面进行设置,然后可以很方便地进行性能测试。默认使用Web模式,访问http://localhost:8089即可,如图所示。在该页面中可以设置模拟的用户数量、需要持续执行的时间及需要测试的网页地址等。

当单击Start swarming按钮后,Locust会执行脚本程序中的代码,随机访问设置的路由地址(URL),并形成结果写入CSV文件中,执行结果如图示。
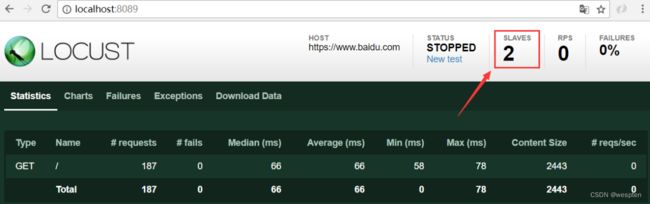
整个操作非常人性化,可视化界面让人耳目一新,能方便地统计失败的情况和异常的捕获。同时,Locust也提供柱状图形式的统计,如每秒总请求数的变化统计、返回延迟时间统计和用户数量统计等,从多个维度全方位地展示测试结果。
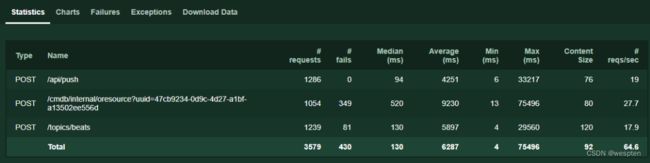
图中的报表中各字段含义如下:
- Type:请求类型;
- Name:请求路径;
- Requests:当前请求的数量;
- Fails:当前请求失败的数量;
- Median:中间值,单位是ms,一半服务器的响应时间低于该值,而另一半服务器的响应时间高于该值;
- Average:所有请求的平均响应时间,单位为ms;
- Min:请求的最小服务器响应时间,单位为ms;
- Max:请求的最大服务器响应时间,单位为ms;
- Content Size:单个请求的大小,单位是字节;
- reqs/sec:每秒请求的个数;
在上图中,RPS和平均响应时间这两个指标显示的值都是根据最近2秒请求响应数据计算得到的统计值,我们也可以理解为瞬时值。
如果想看性能指标数据的走势,就可以在Charts栏查看。在这里,可以查看到RPS和平均响应时间在整个运行过程中的波动情况。

除了以上数据,Locust还提供了整个运行过程数据的百分比统计值,例如我们常用的90%响应时间、响应时间中位值;平均响应时间和错误数的统计,该数据可以通过Download response time distribution CSV和Download request statistics CSV获得,数据展示效果如下所示。


除此之外,Locust也可以使用no-web模式进行性能测试,命令如下:
locust -f /path/to/file_name.py --no-web - csv=locust -c10 -r2 --run-time 2h30m其中,--no-web表示使用no-web模式运行,--csv表示执行结果文件名,-c表示并发用户数,-r表示每秒请求数,--run_time表示运行时间。
3. 编写接口压测脚本文件
Locust类的client属性是一种需要被调用者初始化的属性。在使用Locust时,需要先继承Locust类,然后在子类的client属性中绑定客户端的实现类。
对于常见的HTTP或HTTPS,Locust已经实现了HttpLocust类,其client属性绑定了HttpSession类,而HttpSession又继承自requests.Session,因此在测试HTTP(S)的Locust脚本中,可以通过client属性调用Python requests库的所有方法,包括GET、POST、HEAD、PUT、DELETE和PATCH等,调用方式与requests完全一致。另外,由于使用了requests. Session,因此client方法的调用过程就自动具有了状态记忆的功能。常见的场景是当登录系统后可以维持登录状态的Session,从而使后续的HTTP请求操作都能带上登录状态。
对于HTTP或HTTPS以外的协议,同样可以使用Locust进行测试,只是需要我们自行实现客户端。在客户端的具体实现上,首先可通过注册事件的方式,在请求成功时触发events.request_success,在请求失败时触发events.request_failure即可。然后创建一个继承自Locust类的类,对其设置一个client属性并与我们实现的客户端进行绑定。
这样就可以像使用HttpLocust类一样测试其他协议类型的系统了。
在Locust类中,除了client属性,还需要关注以下几个属性:
- task_set:指向一个TaskSet类,该类定义了用户的任务信息。该属性为必填项。
- max_wait/min_wait:每个用户执行两个任务间隔时间的上下限(单位是ms),具体数值在上下限中随机取值,若不指定则默认间隔时间固定为1s。
- host:被测系统的主机IP地址(host),当在终端中启动Locust的过程中没有指定--host参数时才会用到。
- weight:同时运行多个Locust类时会用到,用于控制不同类型任务的执行权重。
测试开始后,每个虚拟用户(Locust实例)的运行逻辑都会遵循如下规律:
- 执行WebsiteTasks中的on_start(只执行一次),进行初始化。
- 从WebsiteTasks中随机挑选一个任务执行,如果定义了任务间的权重关系,那么就按照权重关系随机挑选。
- 在Locust类中的min_wait和max_wait定义的间隔时间范围(如果TaskSet类中也定义了min_wait或者max_wait,以TaskSet中的优先)内随机取一个值,休眠等待。
- 重复(2)~(3)步,直至测试任务终止。
在上面介绍的属性和类中,建议先学习TaskSet类,该类实现了虚拟用户所执行任务的调度算法,包括规划任务执行顺序(schedule_task)、挑选下一个任务(execute_next_task)、执行任务(execute_task)、休眠等待(wait)及中断控制(interrupt)等。
在此基础上的TaskSet子类可以顺利完成需要的操作,具体代码如下:
from locust import TaskSet, task
class UserBehavior(TaskSet):
@task(1)
def test_job1(self):
self.client.get('/job1')
@task(2)
def test_job2(self):
self.client.get('/job2')采用tasks属性定义任务信息时,编写代码如下:
from locust import TaskSet
def test_job1(obj):
obj.client.get('/job1')
def test_job2(obj):
obj.client.get('/job2')
class UserBehavior(TaskSet):
tasks = {test_job1:1, test_job2:2}
# tasks = [(test_job1,1), (test_job1,2)]下面编写一个接口压力测试的程序,具体代码如下:
from locust import HttpLocust, TaskSet, task
class UserBehavior(TaskSet):
def setup(self):
print('task has been setup')
def teardown(self):
print('task has been teardown')
def on_start(self):
# 虚拟用户启动任务时运行
print('starting')
def on_stop(self):
# 虚拟用户结束任务时运行
print('ending')
@task(2)
def index(self):
self.client.get("/")
@task(1)
def profile(self):
self.client.get("/profile")
class WebsiteUser(HttpLocust):
def setup(self):
print('locust setup')
def teardown(self):
print('locust teardown')
host = ‘http: // XXXXX.com’
task_set = UserBehavior
min_wait = 4000
max_wait = 8000
if __name__ == '__main__':
pass一般来说,Locust用于HTTP类型的服务测试,但是也可以自定义客户端来测试其他类型的服务,如App等。只需要编写一个触发request_success和request_failure事件的自定义客户端即可,并且官网上已经提供了一个完整的用例,代码如下:
import time
from locust import Locust, TaskSet, events, task
import requests
class TestHttpbin(object):
def status(self):
try:
r = requests.get('http://httpbin.org/status/200')
status_code = r.status_code
print status_code
assert status_code == 200, 'Test Index Error: {0}'.format(status_
code)
except Exception as e:
print e
class CustomClient(object):
def test_custom(self):
start_time = time.time()
try:
# 添加测试方法
TestHttpbin().status()
name = TestHttpbin().status.__name__
except Exception as e:
total_time = int((time.time() - start_time) * 1000)
events.request_failure.fire(request_type="Custom",name=name,
response_time=total_time, exception=e)
else:
total_time = int((time.time() - start_time) * 1000)
events.request_success.fire(request_type="Custom",name=name,
response_time=total_time, response_length=0)
class CustomLocust(Locust):
def __init__(self, *args, **kwargs):
super(CustomLocust, self).__init__(*args, **kwargs)
self.client = CustomClient()
class ApiUser(CustomLocust):
min_wait = 100
max_wait = 1000
class task_set(TaskSet):
@task(1)
def test_custom(self):
self.client.test_custom()在上述代码中,自定义了一个测试类TestHttpbin,其中,status()方法用于校验接口返回码。因此只需要在CustomClient类的test_custom()方法中添加需要的测试方法TestHttp-bin().status(),然后再利用注解的功能就可以使用Locust对该方法进行负载测试。
下面讲解一个登录GitHub的具体案例,代码如下:
# -*- coding: utf-8 -*-
from locust import HttpLocust, TaskSet, task
# 继承TaskSet类
class WebsiteTasks(TaskSet):
def on_start(self): # 初始化工作
payload = {
"username": "test_me",
"password": "123456",
}
header = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/
537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36"
}
self.client.post("/login", data=payload,headers=header)
@task(5)
def index(self):
self.client.get("/")
@task(1)
def about(self):
self.client.get("/about/")
class WebsiteUser(HttpLocust):
host = https://github.com/ # 提供给--host的参数
task_set = WebsiteTasks # TaskSet类
# 每个用户的间隔时间,单位是ms,是在max和min之间的随机时间
min_wait = 5000
max_wait = 15000 # 最大间隔时间4. Locust运行模式
运行Locust时,通常会使用到两种运行模式:单进程运行和多进程分布式运行。
1)单进程运行模式
Locust所有的虚拟并发用户均运行在单个Python进程中,具体从使用形式上,又分为no_web和web两种形式。该种模式由于单进程的原因,并不能完全发挥压力机所有处理器的能力,因此主要用于调试脚本和小并发压测的情况。
当并发压力要求较高时,就需要用到Locust的多进程分布式运行模式。从字面意思上看,大家可能第一反应就是多台压力机同时运行,每台压力机分担负载一部分的压力生成。的确,Locust支持任意多台压力机(一主多从)的分布式运行模式,但这里说到的多进程分布式运行模式还有另外一种情况,就是在同一台压力机上开启多个slave的情况。
这是因为当前阶段大多数计算机的CPU都是多处理器(multiple processor cores),单进程运行模式下只能用到一个处理器的能力,而通过在一台压力机上运行多个slave,就能调用多个处理器的能力了。比较好的做法是,如果一台压力机有N个处理器内核,那么就在这台压力机上启动一个master,N个slave。当然,我们也可以启动N的倍数个slave,但是根据我的试验数据,效果跟N个差不多,因此只需要启动N个slave即可。
no_web形式启动locust:
如果采用no_web形式,则需使用--no-web参数,并会用到如下几个参数。
-c, --clients:指定并发用户数;-n, --num-request:指定总执行测试次数;-r, --hatch-rate:指定并发加压速率,默认值位1。
示例:
$ locust -f locustfile.py --host = xxxxx.com --no-web -c 1 -n 2在此基础上,当我们想要调试Locust脚本时,就可以在脚本中需要调试的地方通过print打印日志,然后将并发数和总执行次数都指定为1
$ locust -f locustfile.py --host = xxxxx.com --no-web -c 1 -n 1执行测试
通过这种方式,我们就能很方便地对Locust脚本进行调试了。
Locust脚本调试通过后,就算是完成了所有准备工作,可以开始进行压力测试了。
web形式启动locust:
如果采用web形式,,则通常情况下无需指定其它额外参数,Locust默认采用8089端口启动web;如果要使用其它端口,就可以使用如下参数进行指定。
-P, --port:指定web端口,默认为8089.- 终端中--->进入到代码目录: locust -f locustfile.py --host = xxxxx.com
- -f 指定性能测试脚本文件
- -host 被测试应用的URL地址【如果不填写,读取继承(HttpLocust)类中定义的host】
- 如果
Locust运行在本机,在浏览器中访问http://localhost:8089即可进入Locust的Web管理页面;如果Locust运行在其它机器上,那么在浏览器中访问http://locust_machine_ip:8089即可。
2)多进程分布式运行
不管是单机多进程,还是多机负载模式,运行方式都是一样的,都是先运行一个master,再启动多个slave。
启动master时,需要使用--master参数;同样的,如果要使用8089以外的端口,还需要使用-P, --port参数。
D:workSpacesApiAutoTestTestCasesOpsUltraAPITestMonitorAPITest>locust -f monitorAgent.py --master --port=8089
[2018-06-05 15:36:30,654] dengshihuang/INFO/locust.main: Starting web monitor at *:8089
[2018-06-05 15:36:30,684] dengshihuang/INFO/locust.main: Starting Locust 0.8.1启动slave时需要使用--slave参数;在slave中,就不需要再指定端口了。master启动后,还需要启动slave才能执行测试任务。
D:workSpacesApiAutoTestTestCasesOpsUltraAPITestMonitorAPITest>locust -f monitorAgent.py --slave
[2018-06-05 15:36:30,654] dengshihuang/INFO/locust.main: Starting web monitor at *:8089
[2018-06-05 15:36:30,684] dengshihuang/INFO/locust.main: Starting Locust 0.8.1D:workSpacesApiAutoTestTestCasesOpsUltraAPITestMonitorAPITest>locust -f monitorAgent.py --slave --master-host=
master和slave都启动完毕后,就可以在浏览器中通过http://locust_machine_ip:8089进入Locust的Web管理页面了。使用方式跟单进程web形式完全相同,只是此时是通过多进程负载来生成并发压力,在web管理界面中也能看到实际的slave数量。
如果slave与master不在同一台机器上,还需要通过--master-host参数再指定master的IP地址。
Number of users to simulate:虚拟用户数,对应中no_web模式的-c, --clients参数;
Hatch rate(users spawned/second):每秒产生(启动)的虚拟用户数 , 对应着no_web模式的-r, --hatch-rate参数,默认为1。点击Start swarming 按钮,开始运行性能测试;
5. Locust类高级用法
locustfile.py:
1 from locust import HttpLocust, TaskSet, task
2
3 class ScriptTasks(TaskSet):
4 def on_start(self):
5 self.client.post("/login", {
6 "username": "test",
7 "password": "123456"
8 })
9
10 @task(2)
11 def index(self):
12 self.client.get("/")
13
14 @task(1)
15 def about(self):
16 self.client.get("/about/")
17
18 @task(1)
19 def demo(self):
20 payload={}
21 headers={}
22 self.client.post("/demo/",data=payload, headers=headers)
23
24 class WebsiteUser(HttpLocust):
25 task_set = ScriptTasks
26 host = "http://example.com"
27 min_wait = 1000
28 max_wait = 5000脚本解读:
1、创建ScriptTasks()类继承TaskSet类: 用于定义测试业务。
2、创建index()、about()、demo()方法分别表示一个行为,访问http://example.com。用@task() 装饰该方法为一个任务。1、2表示一个Locust实例被挑选执行的权重,数值越大,执行频率越高。在当前ScriptTasks()行为下的三个方法得执行比例为2:1:1
3、WebsiteUser()类: 用于定义模拟用户。
4、task_set : 指向一个定义了的用户行为类。
5、host: 指定被测试应用的URL的地址
6、min_wait : 用户执行任务之间等待时间的下界,单位:毫秒。
7、max_wait : 用户执行任务之间等待时间的上界,单位:毫秒。脚本使用场景解读:
在这个示例中,定义了针对http://example.com网站的测试场景:先模拟用户登录系统,然后随机地访问首页(/)和关于页面(/about/),请求比例为2:1,demo方法主要用来阐述client对post接口的处理方式;并且,在测试过程中,两次请求的间隔时间为1->5秒间的随机值。
从脚本中可以看出,脚本主要包含两个类,一个是WebsiteUser(继承自HttpLocust,而HttpLocust继承自Locust),另一个是ScriptTasks(继承自TaskSet)。事实上,在Locust的测试脚本中,所有业务测试场景都是在Locust和TaskSet两个类的继承子类中进行描的。
那如何理解Locust和TaskSet这两个类呢?简单地说,Locust类就好比是一群蝗虫,而每一只蝗虫就是一个类的实例。相应的,TaskSet类就好比是蝗虫的大脑,控制着蝗虫的具体行为,即实际业务场景测试对应的任务集。
1)伪代码
from locust import HttpLocust, TaskSet, task
class WebsiteTasks(TaskSet):
def on_start(self): #进行初始化的工作,每个Locust用户开始做的第一件事
payload = {
"username": "test_user",
"password": "123456",
}
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
}
self.client.post("/login",data=payload,headers=header)#self.client属性使用Python request库的所有方法,调用和使用方法和requests完全一致;
@task(5) #通过@task()装饰的方法为一个事务,方法的参数用于指定该行为的执行权重,参数越大每次被虚拟用户执行的概率越高,默认为1
def index(self):
self.client.get("/")
@task(1)
def about(self):
self.client.get("/about/")
class WebsiteUser(HttpLocust):
host = "https://github.com/" #被测系统的host,在终端中启动locust时没有指定--host参数时才会用到
task_set = WebsiteTasks #TaskSet类,该类定义用户任务信息,必填。这里就是:WebsiteTasks类名,因为该类继承TaskSet;
min_wait = 5000 #每个用户执行两个任务间隔时间的上下限(毫秒),具体数值在上下限中随机取值,若不指定默认间隔时间固定为1秒
max_wait = 15000伪代码中对https://github.com/网站的测试场景,先模拟用户登录系统,然后随机访问首页/和/about/,请求比例5:1,并且在测试过程中,两次请求的间隔时间1-5秒的随机值;
on_start方法,在正式执行测试前执行一次,主要用于完成一些初始化的工作,例如登录操作;
WebsiteTasks类中如何去调用 WebsiteUser(HttpLocust)类中定义的字段和方法呢?
通过在WebsiteTasks类中self.locust.xxoo xxoo就是我们在WebsiteUser类中定义的字段或方法;
伪代码:
from locust import HttpLocust, TaskSet, task
import hashlib
import queue
class WebsiteTasks(TaskSet):
@task(5)
def index(self):
data = self.locust.user_data_queue #获取WebsiteUser里面定义的ser_data_queue队列
md5_data=self.locust.md5_encryption() #获取WebsiteUser里面定义的md5_encryption()方法
self.client.get("/")
class WebsiteUser(HttpLocust):
host = "https://github.com/"
task_set = WebsiteTasks
min_wait = 5000
max_wait = 15000
user_data_queue = queue.Queue()
def md5_encryption(self,star):
'''md5加密方法'''
obj = hashlib.md5()
obj.update(bytes(star,encoding="utf-8"))
result = obj.hexdigest()
return result伪代码中测试场景如何表达?
代码主要包含两个类:
- WebsiteUser继承(HttpLocust,而HttpLocust继承自Locust)
- WebsiteTasks继承(TaskSet)
在Locust测试脚本中,所有业务测试场景都是在Locust和TaskSet两个类的继承子类中进行描述;
简单说:Locust类就类似一群蝗虫,而每只蝗虫就是一个类的实例。TaskSet类就类似蝗虫的大脑,控制蝗虫的具体行为,即实际业务场景测试对应的任务集;
源码中:class Locust(object)和class HttpLocust(Locust)
1 class Locust(object):
2 """
3 Represents a "user" which is to be hatched and attack the system that is to be load tested.
4
5 The behaviour of this user is defined by the task_set attribute, which should point to a
6 :py:class:`TaskSet ` class.
7
8 This class should usually be subclassed by a class that defines some kind of client. For
9 example when load testing an HTTP system, you probably want to use the
10 :py:class:`HttpLocust ` class.
11 """
12
13 host = None
14 """Base hostname to swarm. i.e: http://127.0.0.1:1234"""
15
16 min_wait = 1000
17 """Minimum waiting time between the execution of locust tasks"""
18
19 max_wait = 1000
20 """Maximum waiting time between the execution of locust tasks"""
21
22 task_set = None
23 """TaskSet class that defines the execution behaviour of this locust"""
24
25 stop_timeout = None
26 """Number of seconds after which the Locust will die. If None it won't timeout."""
27
28 weight = 10
29 """Probability of locust being chosen. The higher the weight, the greater is the chance of it being chosen."""
30
31 client = NoClientWarningRaiser()
32 _catch_exceptions = True
33
34 def __init__(self):
35 super(Locust, self).__init__()
36
37 def run(self):
38 try:
39 self.task_set(self).run()
40 except StopLocust:
41 pass
42 except (RescheduleTask, RescheduleTaskImmediately) as e:
43
44 class HttpLocust(Locust):
45 """
46 Represents an HTTP "user" which is to be hatched and attack the system that is to be load tested.
47
48 The behaviour of this user is defined by the task_set attribute, which should point to a
49 :py:class:`TaskSet ` class.
50
51 This class creates a *client* attribute on instantiation which is an HTTP client with support
52 for keeping a user session between requests.
53 """
54
55 client = None
56 """
57 Instance of HttpSession that is created upon instantiation of Locust.
58 The client support cookies, and therefore keeps the session between HTTP requests.
59 """
60 def __init__(self):
61 super(HttpLocust, self).__init__()
62 if self.host is None:
63 raise LocustError("You must specify the base host. Either in the host attribute in the Locust class, or on the command line using the --host option.")
64 self.client = HttpSession(base_url=self.host) 在Locust类中,静态字段client即客户端的请求方法,这里的client字段没有绑定客户端请求方法,因此在使用Locust时,需要先继承Locust类class HttpLocust(Locust),然后在self.client =HttpSession(base_url=self.host)绑定客户端请求方法;
对于常见的HTTP(s)协议,Locust已经实现了HttpLocust类,其self.client=HttpSession(base_url=self.host),而HttpSession继承自requests.Session。因此在测试HTTP(s)的Locust脚本中,可以通过client属性来使用Python requests库的所 有方法,调用方式与 reqeusts完全一致。另外,由于requests.Session的使用,client的方法调用之间就自动具有了状态记忆功能。常见的场景就是,在登录系统后可以维持登录状态的Session,从而后续HTTP请求操作都能带上登录状态;
Locust类中,除了client属性,还有几个属性需要关注:
- task_set ---> 指向一个TaskSet类,TaskSet类定义了用户的任务信息,该静态字段为必填;
- max_wait/min_wait ---> 每个用户执行两个任务间隔的上下限(毫秒),具体数值在上下限中随机取值,若不指定则默认间隔时间为1秒;
- host --->被测试系统的host,当在终端中启动locust时没有指定--host参数时才会用到;
- weight--->同时运行多个Locust类时,用于控制不同类型的任务执行权重;
Locust流程,测试开始后,每个虚拟用户(Locust实例)运行逻辑都会遵守如下规律:
- 先执行WebsiteTasks中的on_start(只执行一次),作为初始化;
- 从WebsiteTasks中随机挑选(如果定义了任务间的权重关系,那么就按照权重关系随机挑选)一个任务执行;
- 根据Locust类中min_wait和max_wait定义的间隔时间范围(如果TaskSet类中也定义了min_wait或者max_wait,以TaskSet中的优先),在时间范围中随机取一个值,休眠等待;
- 重复2~3步骤,直到测试任务终止;
2)class TaskSet
TaskSet类实现了虚拟用户所执行任务的调度算法,包括规划任务执行顺序(schedule_task)、挑选下一个任务(execute_next_task)、执行任务(execute_task)、休眠等待(wait)、中断控制(interrupt)等待。在此基础上,就可以在TaskSet子类中采用非常简洁的方式来描述虚拟用户的业务测试场景,对虚拟用户的所有行为进行组织和描述,并可以对不同任务的权重进行配置。
@task:
通过@task()装饰的方法为一个事务。方法的参数用于指定该行为的执行权重。参数越大每次被虚拟用户执行的概率越高。如果不设置默认为1。
TaskSet子类中定义任务信息时,采取两种方式:@task装饰器和tasks属性。
采用@task装饰器定义任务信息时:
from locust import TaskSet, task
class UserBehavior(TaskSet):
@task(1)
def test_job1(self):
self.client.get('/test1')
@task(3)
def test_job2(self):
self.client.get('/test2')采用tasks属性定义任务信息时:
from locust import TaskSet
def test_job1(obj):
obj.client.get('/test1')
def test_job2(obj):
obj.client.get('/test2')
class UserBehavior(TaskSet):
tasks = {test_job1:1, test_job2:3}
# tasks = [(test_job1,1), (test_job1,3)] # 两种方式等价上面两种定义任务信息方式中,均设置了权重属性,即执行test_job2的频率是test_job1的两倍。
若不指定,默认比例为1:1。
3)关联
在某些请求中,需要携带之前response中提取的参数,常见场景就是session_id。Python中可用通过re正则匹配,对于返回的html页面,可用采用lxml库来定位获取需要的参数。
from locust import HttpLocust, TaskSet, task
from lxml import etree
class WebsiteTasks(TaskSet):
def get_session(self,html): #关联例子
tages = etree.HTML(html)
return tages.xpath("//div[@class='btnbox']/input[@name='session']/@value")[0]
def on_start(self):
html = self.client.get('/index')
session = self.get_session(html.text)
payload = {
"username": "test_user",
"password": "123456",
'session' : session
}
header = {
"User-Agent":"Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/58.0.3029.110 Safari/537.36",
}
self.client.post("/login",data=payload,headers=header)
@task(5)
def index(self):
self.client.get("/")
assert response['ErrorCode']==0 #断言
@task(1)
def about(self):
self.client.get("/about/")
class WebsiteUser(HttpLocust):
host = "https://github.com/"
task_set = WebsiteTasks
min_wait = 5000
max_wait = 150004)参数化
作用:循环取数据,数据可重复使用。
例如:模拟3个用户并发请求网页,共有100个URL地址,每个虚拟用户都会依次循环加载100个URL地址。
from locust import TaskSet, task, HttpLocust
class UserBehavior(TaskSet):
def on_start(self):
self.index = 0
@task
def test_visit(self):
url = self.locust.share_data[self.index]
print('visit url: %s' % url)
self.index = (self.index + 1) % len(self.locust.share_data)
self.client.get(url)
class WebsiteUser(HttpLocust):
host = 'http://debugtalk.com'
task_set = UserBehavior
share_data = ['url1', 'url2', 'url3', 'url4', 'url5']
min_wait = 1000
max_wait = 3000(1)保证并发测试数据唯一性,不循环取数据
所有并发虚拟用户共享同一份测试数据,并且保证虚拟用户使用的数据不重复;
例如:模拟3用户并发注册账号,共有9个账号,要求注册账号不重复,注册完毕后结束测试:
采用队列:
from locust import TaskSet, task, HttpLocust
import queue
class UserBehavior(TaskSet):
@task
def test_register(self):
try:
data = self.locust.user_data_queue.get()
except queue.Empty:
print('account data run out, test ended.')
exit(0)
print('register with user: {}, pwd: {}'
.format(data['username'], data['password']))
payload = {
'username': data['username'],
'password': data['password']
}
self.client.post('/register', data=payload)
class WebsiteUser(HttpLocust):
host = 'http://debugtalk.com'
task_set = UserBehavior
user_data_queue = queue.Queue()
for index in range(100):
data = {
"username": "test%04d" % index,
"password": "pwd%04d" % index,
"email": "test%[email protected]" % index,
"phone": "186%08d" % index,
}
user_data_queue.put_nowait(data)
min_wait = 1000
max_wait = 3000(2)保证并发测试数据唯一性,循环取数据
所有并发虚拟用户共享同一份测试数据,保证并发虚拟用户使用的数据不重复,并且数据可循环重复使用;
例如:模拟3个用户并发登录账号,总共有9个账号,要求并发登录账号不相同,但数据可循环使用;

from locust import TaskSet, task, HttpLocust
import queue
class UserBehavior(TaskSet):
@task
def test_register(self):
try:
data = self.locust.user_data_queue.get()
except queue.Empty:
print('account data run out, test ended')
exit(0)
print('register with user: {0}, pwd: {1}' .format(data['username'], data['password']))
payload = {
'username': data['username'],
'password': data['password']
}
self.client.post('/register', data=payload)
self.locust.user_data_queue.put_nowait(data)
class WebsiteUser(HttpLocust):
host = 'http://debugtalk.com'
task_set = UserBehavior
user_data_queue = queue.Queue()
for index in range(100):
data = {
"username": "test%04d" % index,
"password": "pwd%04d" % index,
"email": "test%[email protected]" % index,
"phone": "186%08d" % index,
}
user_data_queue.put_nowait(data)
min_wait = 1000
max_wait = 30005)断言(即检查点)
性能测试也需要设置断言么? 某些情况下是需要,比如你在请求一个页面时,就可以通过状态来判断返回的 HTTP 状态码是不是 200。
通过with self.client.get("url地址",catch_response=True) as response的形式;
response.status_code获取http响应码进行判断,失败后会加到统计错误表中;
python自带的断言assert失败后代码就不会向下走,且失败后不会被Locust报表统计进去;
默认不写参数catch_response=False断言无效,将catch_response=True才生效;
下面例子中:
首先使用python断言对接口返回值进行判断(python断言不通过,代码就不向下执行,get请求数为0),通过后对该接口的http响应是否为200进行判断。
@task
def all_interface(self):
#豆瓣图书api为例子
with self.client.get("https://api.douban.com/v2/book/1220562",name="/LhcActivity/GetActConfig",catch_response=True) as response:
assert response.json()['rating']['max']==10 #python断言对接口返回值中的max字段进行断言
if response.status_code ==200: #对http响应码是否200进行判断
response.success()
else:
response.failure("GetActConfig[Failed!]")6. Locust和其他工具集成
Locust作为一款强大的性能测试框架,还可以搭配其他工具进行集成。例如,和MySQL进行对接,将Locust的结果写入MySQL中做持久化存储等,也可以配合Jmeter进行其他方面的测试,如代码覆盖测试。
持久化的运行逻辑如下:
- 执行Locust命令生成CSV文件。
- 读取CSV文件内容,然后写入MySQL中。
- 完成后续分析。
其中,步骤(2)要使用MySQL,因此需要安装MySQL服务和Python对MySQL支持的驱动模块。
安装MySQL的方法很简单,前往MySQL官网下载对应操作系统的MySQL安装包进行安装即可。安装完毕后即可启动MySQL服务。需要注意的是,在Windows下可在进程管理中将MySQL设置为自启动模式。
在Python中安装对应的驱动也很简便,命令如下:
pip install mysql-connector例如,编写一个简单的连接MySQL的脚本,代码如下:
# 引入MySQL驱动
import mysql.connector
# 创造连接对象
conn = mysql.connector.connect(user='root', password='root', database=
'test')
# 创造游标对象
cursor = conn.cursor()
# 执行查询语句
data = cursor.execute("SELECT * FROM my_test")如果是针对Locust服务进行性能采集分析,完全可以把Locust服务当作一个普通的网络服务进行定时访问,从而获得需要统计的数据。
相关代码如下:
def get_locust_stats_by_web_api():
print("get_locust_stats")
try:
start_url = f'http://localhost:8089/stats/requests'
print(start_url)
return requests.get(start_url).json()
except Exception as e:
print(e)但这样的脚本也存在一定的缺陷,例如需要人为开启服务和定时任务进行监控,不符合自动化测试的要求。
更好的办法是把这段采集程序集成到Locust脚本中,这样就能做到采集监控和Locust服务同时启动或同时停止。而no-web模式下的性能数据采集和Web模式类似,这里不再赘述,更多的业务处理是在持续化存储方面,也就是对数据入库的处理。
注意:
locust虽然使用方便,但是加压性能和响应时间上面还是有差距的,如果项目有非常大的并发加压请求,可以选择wrk
对比方法与结果:
可以准备两台服务器,服务器A作为施压方,服务器B作为承压方
服务器B上简单的运行一个nginx服务就行了
服务器A上可以安装一些常用的压测工具,比如locust、ab、wrk
我当时测下来,施压能力上 wrk > golang >> ab > locust
因为locust一个进程只使用一核CPU,所以用locust压测时,必须使用主从分布式(zeromq通讯)模式,并根据服务器CPU核数来起slave节点数
wrk约为55K QPS;
golang net/http 约 45K QPS;
ab 大约 15K QPS;
locust 最差,而且response time明显比较长;
蝗虫比Jmeter好的一点就是高并发,但是相对的不好的地方也有,就是需要另外的工具去监控服务器,而且需要去编写代码。
六、JMeter安装配置
1、JMeter简介
- JMeter 是轻量级的接口性能测试工具,同时具备一定程度的接口自动化测试能力。
- JMeter 支持多协议,其中较适合测试使用公有协议(如 HTTP、JDBC 等)的服务或模块,特别适合 B/S 结构的后台性能系统。
- JMeter 有大量第三方插件,也可以比较方便的编写适合自己使用的插件。
- Java 应用(依赖 JDK),可以运行在任何 Java 支持的系统上。
- 对比 LoadRunner,JMeter 有开源、免费、使用简单、安装简便的特点。虽然功能不如 LR 完善,但是也足够支撑性能测试工作。
- 支持脚本。
- 支持分布式部署。
- 图形化展示结果。
Jmeter 与 Loadrunner 的对比:
Loadrunner
- 优点
- 多用户(支持数量单位:万)
- 详细分析报表
- 支持 IP 欺骗
- 缺点
- 收费
- 体积庞大(单位 GB)
- 无法定制功能
Jmeter
- 优点
- 免费、开源
- 小巧
- 丰富学习资料及扩展组件
- 应用广泛
- 易上手
- 缺点
- 不支持 IP 欺骗
- 分析和报表能力相对于 LR 欠缺精度
2、基本原理
录制的原理:Jmeter 作为浏览器与 web 服务器之间的代理网关,可以捕获浏览器的请求和 web 服务器的响应,通过线程来模拟真实用户对 web 服务器的访问压力。
并发压测原理:Jmeter 内部建立一个线程池,多线程运行取样器产生大量负载,在运行过程中通过断言来验证结果的正确性,可以通过监听来记录测试结果。
3、基本概念
测试计划(Test Plan):
- JMeter 测试计划是一系列配置元件、线程组,控制器, Sampler,断言,监听器、定时器组成的集合。
- JMeter 的各种部件以树形目录结构在工程中被组织起来,根节点下属器件类型一般是配置器、线程组,监听器。
- JMeter 运行时会首先运行配置器,然后启动线程组,全部线程组中 Sampler 的执行结果会在配置的监听器中出现。
- 虽然从界面上可以在测试计划根节点上添加监听器、断言,但是绝大多数情况下,不需要在根节点配置这两类器件。
线程组(Thread Group):
- 线程组是一组器件,是一系列配置器、控制器、定时器、 Sampler,断言和监听器的集合。
- 线程组的线程数量、执行次数、启动时间都可以配置。
- 线程启动后会顺序执行下属的配置器、控制器、定时器、 Sampler、断言和监听器,实现一系列包含测试逻辑的操作。
取样器(Sampler):
- Sampler 中文翻译为取样器,可以理解为对被测目标的一次请求或调用。
- JMeter 原生携带了很多常用的 Sampler,如 http、bsf、jsr223、 jdbc 等。
- 一般情况下,进行 web 后端测试使用 http、bsf、jsr223 三个类型的 Sampler,加上对应的控制器已可以满足需要了。
- 偶尔可能会用到 jdbc,有些系统会使用 websocket 等第三方插件。
逻辑控制器(Logic Contoller):
- Logic Contoller 中文名叫逻辑控制器。这一类器件用于控制线程组内部的采样器的执行逻辑。
- 以 http 采样器为例, 可以通过 loop 控制器定义某个或某几个采样器的执行次数、通过 if 控制器定义某个采样器执行后,接下来执行哪个采样器。
- 逻辑控制器的作用和各种语言中的逻辑控制语句非常相似,所以使用过任何语言的同学应该可以很好理解。
- 想顺利使用 Jmeter,掌握一门这个工具支持的计算机语言是必须的,对于没有使用过计算机语言的同学,推荐可以从 javascript 学起。
定时器(Timer):
- Timer 中文翻译为定时器。定时器一般只在线程组中被使用,作用实际上是让线程等待一段时间。
- Jmeter 提供很多类型的定时器有很多类型,可以根据自己的需要选择合适的。
断言(Assertion):
- 断言是条件判断器件。断言为真时, Jmeter 认为采样器的执行结果为成功,反之亦然。
- 断言一般情况添加在采样器上,采样器执行完毕, Jmeter 会调用采样器上的断言,根据断言中的配置或代码判断执行结果为成功还是失败。
- 以 Response Assertion 为例,选择包含,并填写字符串后,若采样器返回包含字符串的即为成功,反之为失败。
监听器(Listener):
- 监听器用于收集 Jmeter 的运行结果并展示给用户。
- JMeter 提供的大部分监听器为统计报告。能够提供 Sampler 执行结果展示的的只有 view result tree。
- 最常用的监听器是 Aggregate Report 和 View Result Tree。
4、Jmeter 安装
- 本机安装 JDK1.8+ 版本;
- 下载 Jmeter 的安装包:http://jmeter.apache.org/download_jmeter.cgi;
- 下载完成后直接解压缩即可,无须安装;
- 点击 bin 目录下的 jmeter.bat 文件即可启动 jmeter;
5、Jmeter 启动方式
JMeter 启动有多种方式, 进入 JMeter 安装目录下的 bin 目录:
- 双击 jmeter.bat;
- 双击 ApacheJMeter.jar 选择使用 java 程序打开;
- 命令行输入:java -jar ApacheJMeter.jar;
6、JMeter 文件目录介绍
bin 目录:
存放可执行文件和配置文件。
- jmeter.bat:Windows 的启动文件
- jmeter.log:日志文件
- jmeter.sh:Linux 的启动文件
- jmeter.properties:系统配置文件
- jmeter-server.bat:Windows 分布式测试要用到的服务器配置
- jmeter-serve:Linux 分布式测试要用到的服务器配置
docs 目录:
docs 是 JMeter 的 api 文档, 可打开 api/index.html 页面来查看。
rintable_docs 目录:
printable_docs 的 usermanual 子目录下的内容是 JMeter 的用户手册文档
usermanual 下 component_reference.html 是最常用到的核心元件帮助文档。
提示:printable_docs 的 demos 子目录下有一些常用的 JMeter 脚本案例, 可以作为参考。
lib 目录:
该目录用来存放 JMeter 依赖的 jar 包和用户扩展所依赖的 jar 包。
7、Jmeter 修改默认配置
汉化配置:
实现 JMeter 界面的汉化包含两种方式:
1)临时性
- 启动JMeter -> 选择菜单“Options” -> Choose Language -> Chinese (Simplified)
2)永久性
- 找到 Jmeter 安装目录下的 bin 目录;
- 打开 jmeter.properties 文件, 把第 37 行修改为“language=zh_CN”;
- 重启 JMeter 即可。
修改主题:
JMeter 默认主题是黑色的, 可以通过以下步骤修改:
- 启动 JMeter -> 选择菜单“选项” -> 外观 -> Windows(选择自己喜欢的主题即可)
七、JMeter工具使用
1、Jmeter元件简介
常见元件类型:
- 取样器
- 逻辑控制器
- 前置处理器
- 后置处理器
- 断言
- 定时器
- 测试片段
- 配置元件
- 监听器
元件作用域:
在 JMeter 中,元件的作用域是靠测试计划的树形结构中元件的父子关系来确定的。
提示:核心是取样器,其他组件都是以取样器为核心运行的。组件添加的位置不同,生效的取样器也不同。
作用域的原则:
- 取样器:元件不和其他元件相互作用, 因此不存在作用域的问题。
- 逻辑控制器:元件只对其子节点中的取样器和逻辑控制器作用。
- 其他六大元件:除取样器和逻辑控制器元件外,如果是某个取样器的子节点,则该元件对其父子节点起作用。
- 如果其父节点不是取样器,则其作用域是该元件父节点下的其他所有后代节点(包括子节点、子节点的子节点等)。
元件执行顺序:
- 配置元件(config elements)
- 前置处理程序(Per-processors)
- 定时器(timers)
- 取样器(Sampler)
- 后置处理程序(Post-processors)
- 断言(Assertions)
- 监听器(Listeners)
提示:
- 前置处理器、后置处理器、断言等元件功能对取样器起作用(如果在它们的作用域内没有任何取样器,则不会被执行)。
- 如果在同一作用域范围内有多个同一类型的元件,则这些元件按照它们在测试计划中的上下顺序依次执行。
2、测试计划
JMeter 的测试计划是一系列配置器、线程组、控制器、Sampler、检查器、监听器组成的集合。
- Jmeter 的各种部件以目录树的形式在工程中被组织起来,根节点下属器件类型一般是配置元件、线程组、监听器。
- Jmeter 运行时会首先运行配置元件,然后启动线程组,线程组中全部 Sampler 的执行结果会在配置的监听器中出现。
- Jmeter 测试以测试计划为单位执行,测试计划一般至少应该包含一个线程组、一个 Sampler 和一个监听器。
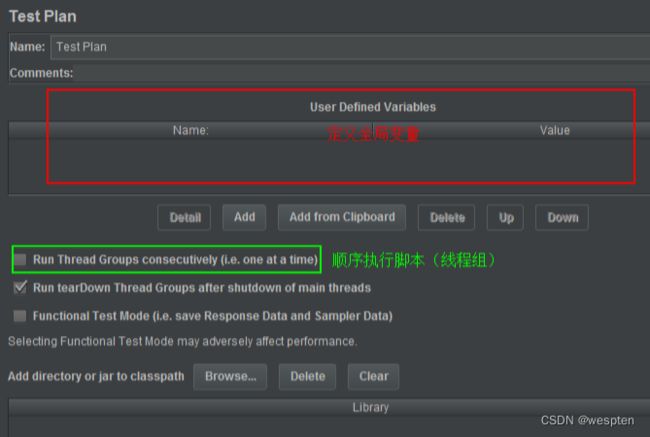
注意:Jmeter 默认多个线程组之间是并行执行关系。如果希望一个线程组执行完毕后,再按序执行下一个线程组下的请求,则需要在测试计划下勾选“Run Thread Groups consecutively”。
3、线程组
JMeter 中 Thread Group 和 Load Runner 中 user 的概念十分接近,可以通过添加采样器、控制器、定时器等单元模拟用户行为,可以通过修改实例数量模拟多用户操作。
在测试执行时,Thread Group 中的每一实例都是一个独立的线程,实例数量和每个实例的循环次数可以设定。
线程组的特点:
- 模拟多人操作。
- 线程组可以添加多个, 多个线程组可以并行或串行。
- 取样器(请求)和逻辑控制器必须依赖线程组才能使用。
线程组分类:
- 线程组:普通的、常用的线程组,可以看做一个虚拟用户组,线程组中的每一个线程都可以理解为一个虚拟用户。
- setUp 线程组:一种特殊类型的线程组, 可用于执行预测试操作。
- tearDown 线程组:一种特殊类型的线程组, 可用于执行测试后工作。
- 一般我们可以将初始化数据的脚本放入 setup 线程组中,将清除测试数据的脚本放入到 teardown 线程组中,来保证脚本始终在开始和最后执行,而无需额外考虑线程组的执行顺序。
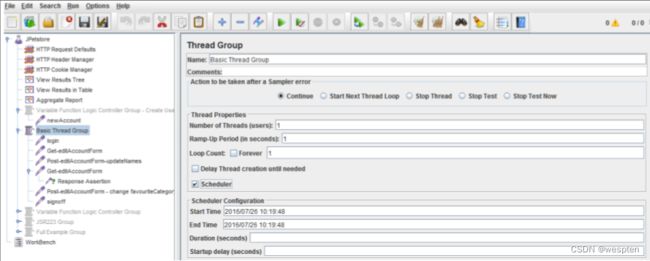
配置项介绍:
Name:线程组名称,用在 UI 上显示时区分不同的线程组。可以同名但是尽量不要使用相同的名字。
Comments:线程组说明,可以用来写一些注释。
Action to be take after sampler error:这一组配置项用于定义线程组内 sampler 发生 error 时,线程组的行为。常用选项为 continue 和 stop test now。进行测试时一般选择 continue,进行调试时一般选择 stop test now。
- Continue:继续执行当前线程。
- Start next thread loop:结束当前线程,启动新的线程重新执行该线程的测试。
- Stop Thread:停止当前线程,并且不再启动新的线程。
- Stop test:停止整个测试。
- Stop test now:强制停止整个测试(stop test 和 stop test now 的区别类似于 kill 和 kill -9)。
Thread Properites:
- Number of Thread(users):线程数量。测试开始执行后 Jmeter 会根据这个配置配启动对应的线程数量。例如配置 10 个线程,则可以模拟 10 个用户。
- Ram-up Period(in seconds):线程启动时间间隔。Jmeter 会根据这个配置,间隔性的启动线程。例如配置 10 线程,延迟为 100 秒,那么 Jmeter 会每个 10 秒启动一个线程。
- Loop Count:每个线程的执行次数。线程组内的全部 Sampler 执行完毕后,再次执行该线程组,直至达到配置次数。
- Delay Thread creation until needed:这个选项在 Ram-up Period(in seconds)配置时生效。如果不选,Jmeter 会先创建完全部实例再逐个启动;如果选择,Jmeter 会在上一个线程启动后,再创建下一个线程。
示例:一个线程组中设置了 2 个线程,每个线程分别执行 3 个请求,那么:
- 线程 1 顺序执行请求 1-3;线程 2 顺序执行请求 1-3。
- 线程 1 和线程 2 则是并发执行。
4、配置元件
Jmeter 中的配置元件主要用于管理 Sampler 的参数或变量。
- 点击选中配置元件,然后点击 JMeter UI 上的蓝色问号,可以查看配置元件对应的文档。
- 一般情况下, HTTP 相关的配置元件添加于根目录。添加于根目录时, Test Plan 的全部 http sampler 会使用根目录的配置。如有特殊情况,可以在某个 thread group 或 sampler 上添加下配置元件,覆盖默认配置。
- HTTP 测试常用的配置元件是 HTTP Request Defaults、HTTP Header Manager 和 HTTP CookieManager。
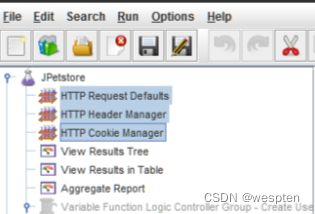
1. HTTP Request Defaults
HTTP Request Defaults 配置元件用于配置 http sampler 的默认参数,一般配置在根节点上。配置在根节点后,整个 Test Plan 里面了所有 http sampler 都会默认使用 HTTP Request Defaults 的配置。
最常用的选项为服务器的 IP、Port、Implementation:
- IP、PORT:分别为服务器的IP和端口。其他选项的用途见文档。
- Implementation:指定使用哪个 http 版本实现(一般选择 HttpClient4),选择后 Jmeter 会使用 ApacheHttpClient4.X 版本处理 http 请求。
2. HTTP Cookie Manager
- HTTP Cookie Manager 配置元件用于配置 http sampler 使用的 cookie,使用 cookie 的请求必须添加这个配置元件,不使用 cookie 的可以不添加。
- 一般情况下,添加后使用默认配置即可。如默认配置和服务器端实现不同时,可以从开发人员处了解实现细节修改对应配置。
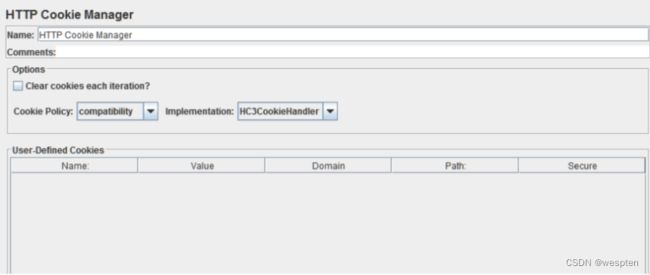
3. HTTP Header Manager
- HTTP Header Manager 配置元件用于配置 http sampler 请求的 header。对于 header 没有特殊要求的 http 接口,可以不添加。
- HTTP Header manager 中的配置和接口定义有关,可以通过浏览器抓取请求查看,或者翻阅开发文档获取信息。
5、取样器
1. HTTP Request(Sampler)
HTTP Request Sampler 用于发送 HTTP 请求并接收响应结果。
- HTTP Request Sampler 的大部分选项对应 HTTP 协议的参数。
- 如果同级或上级目录有 HTTP Request Defaults,不填写时会使用 HTTP Request Defaults 的配置,填写后会覆盖 HTTP Request Defaults 的配置。
- HTTP Sampler 会校验请求的 Response Code。Response Code != 200 的请求, HTTP Sampler 默认会认为请求失败。这里的返回码指的是 HTTP 协议中定义的 Response Code 而不是 Response Body 中的内容。
配置项介绍:
- 协议:向目标服务器发送 HTTP 请求时的协议, 可以是 http 或者是 https ,默认值为 http 。
- 服务器名称或 IP :HTTP 请求发送的目标服务器名称或 IP 地址。
- 端口号:目标服务器的端口号, 默认值为 80 。
- 方法:发送 HTTP 请求的方法, 可用方法包括 GET、POST、HEAD、PUT、OPTIONS、TRACE、DELETE 等。
- 路径:目标 URL 路径(不包括服务器地址和端口)。
- Content encoding:内容的编码方式, 默认值为 iso8859。
- 请求重定向行为:一般使用默认即可。需要对 HTTP 的重定向有一定了解才能修改这项配置,如果重定向出现问题又不知道该怎么配置请找对应的开发人员去求助。
- 同请求一起发送参数:GET 请求时 URL 中附带参数可以通过此方式添加。
- 消息体数据:POST/PUT 请求的 JSON/XML 数据存放地。
注意:
- 如果 GET 请求 URL 中的参数含中文,则建议将参数放到下面“参数”中填写,并将中文参数的“编码?”勾上。
- 如果发送的请求体格式为多种请求体格式(Content-Type)时,需要勾选“multipart/form-data” 。
2. JDBC Request(Sampler)
JDBC Request 用于连接数据库并执行 SQL。
使用步骤 1:添加 MySQL 驱动 jar 包
在测试计划面板点击“浏览…”按钮,将所需的 JDBC 驱动添加进来。
步骤 2:配置 JDBC Connection Configuration
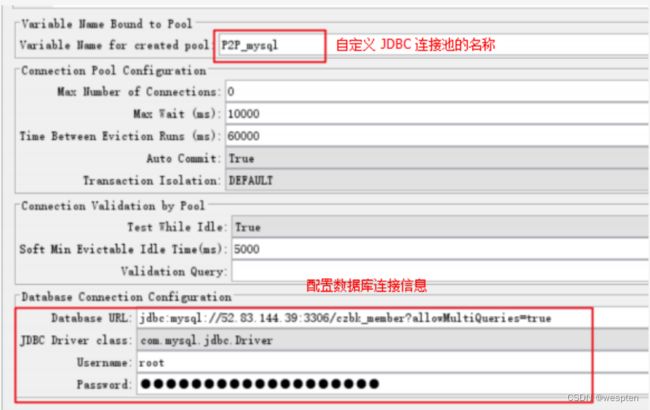
- Variable Name: MySQL 数据库连接池名称(后续 JDBC 请求时要引用)。
- Database URL: jdbc:mysql://localhost:3306/czbk_member(allowMultiQueries=true:添加该参数后,在后面的 JDBC Request 请求中可以批量执行多条 SQL 语句;如果没加该参数,那么在执行完第一条 SQL 后就会报错)。
- jdbc:mysql:MySQL 固定格式
- //127.0.0.1:数据库 IP 地址
- 3306:MySQL 端口
- czbk_member:要连接的数据库名称
- JDBC DRIVER class: com.mysql.jdbc.Driver(MySQL 驱动包位置固定格式)。
- Username:数据库用户名。
- Password:数据库密码(如果密码为空则不写)。
步骤 3:配置 JDBC Request
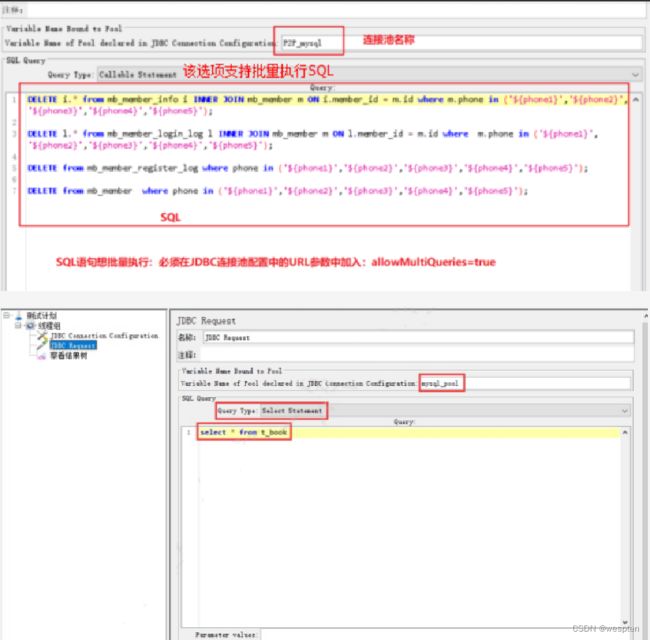
主要参数:
- Variable Name:数据库连接池的名字,需要与 JDBC Connection Configuration 的 Variable Name Bound Pool 名字保持一致。
- Query:非批量执行时,填写的 sql 语句未尾不要加分号。
- Parameter values:参数值。
- Parameter types:参数类型。
- Variable names:保存 sql 语句返回结果的变量名。
- Result variable name:创建一个对象变量, 保存所有返回的结果。
- Query timeout:查询超时时间。
- Handle result set:定义如何处理由 callable statements 语句返回的结果。
运行结果示例:
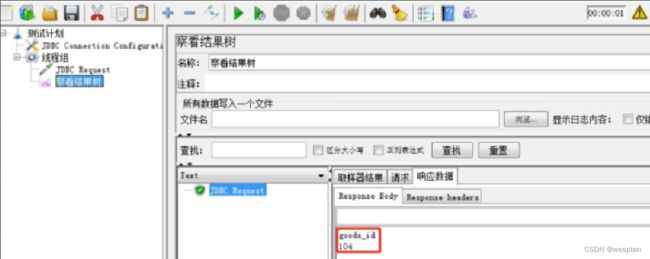
6、参数化
Jmeter 参数化常用方式:
- 用户定义变量(User Defined Variables)
- 用户参数(User Parameters)
- CSV 文件(CSV Data Set Config)
- 函数
1. 用户定义变量(User Defined Variables)
注意:用户定义变量的作用域针对的是测试计划,即无论用户定义的变量组件放在哪里, 他都会针对整个测试计划生效。
添加方式: 测试计划 --> 线程组--> 配置元件 --> 用户定义变量
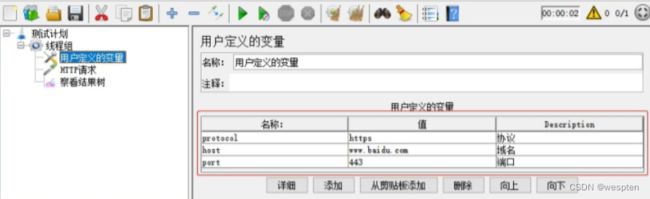

2. 用户参数
添加方式: 测试计划 --> 线程组--> 前置处理器 --> 用户参数
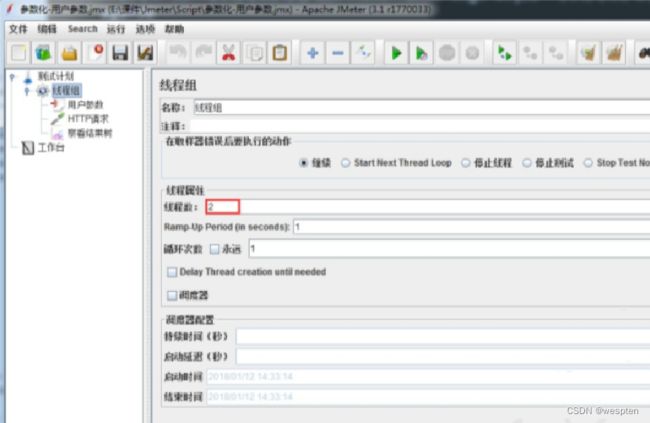


3. CSV 文件
CSV 的作用域是针对线程的, 只有两种情况:
- 对所有线程组中的线程生效:父节点是测试计划,并且线程共享模式是“所有线程”时,对所有线程组中的线程生效。
- 对当前线程组中的线程生效:父节点是某个线程组时,只会对当前线程组生效。
添加方式:测试计划 --> 线程组 --> 配置元件 --> CSV 数据文件设置
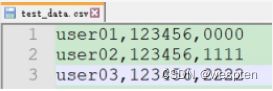
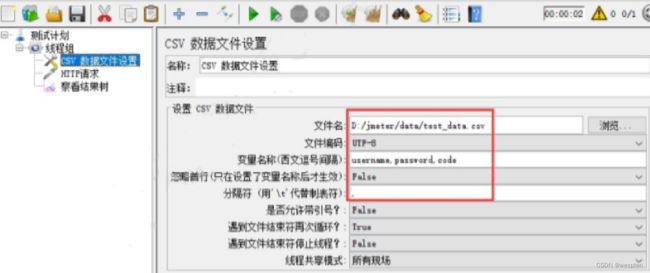
- 文件名:CSV 文件路径。
- 文件编码:文件编译字符编码,一般设置 UTF-8。
- 变量名称:多个变量时,使用英文逗号分隔。
- 忽略首行:True 为忽略,False 为不忽略,默认值 False 。
- 分隔符:如文件中使用的是逗号分隔,则填写逗号;如使用的是制表符,则填写 \t,
- 是否允许带引号:CSV 文件中的内容是否允许带引号
- 遇到文件结束符再次循环:当读取文件到结尾时,是否再从头读取文件。False 表示当读取文件到结尾时,停止读取文件。
- 遇到文件结束符停止线程:True 表示当读取文件到结尾时,停止进程。
- 线程共享模式:共享模式一般默认即可。
- 所有线程:该文件在所有线程之间共享,所有线程循环取值,线程 1 取第一行,线程 2 取下一行。
- 当前线程组:各个线程组分别循环取值。
- 当前线程:每个文件分别为每个线程打开。
4. 函数
JMeter 中内置了大量函数,可以使用这些函数帮助我们完成数据驱动,实现相对复杂的测试逻辑。
函数助手
JMeter 支持的全部函数可以从 GUI 上的函数助手中查到。
![]()
使用步骤:
- 在 JMeter UI 上点击函数助手图标打开函数助手;
- 点击函数助手最上面的下拉菜单可以选择要使用的函数;
- 选择函数后,点击 help,可以打开函数对应的帮助文档;
- 根据函数的文档说明和自己的需要,填写 Function Parameter 中的参数;
- 点击 Gennerate 按键,生成函数字符串。

1)${__Random}
__Random 函数的功能是产生随机整数。可以在使用某种资源时在资源名称字符串上使用这个函数,这样可以创建名称+随机数的不同名资源。
以 PetStore 户登录为例,可以在用户名称后添加 ${__Random(1,10,user)},这样线程每次循环会使用不同的名称。
参数说明:
- The minimum value allowed for a range of values:随机数取值范围的最小值。
- The maximum value allowed for a range of values:随机数取值范围的最大值。
- Name of variable in which to store the result (optional):存储本次调用生成随机数的变量名称。
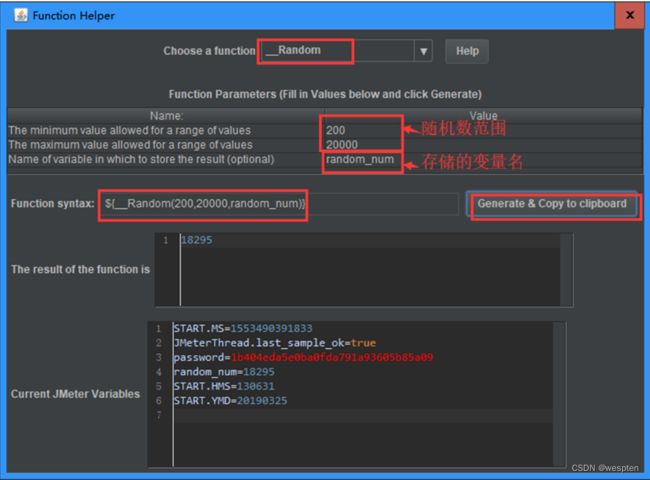
2) ${__RandomString(,,)}
如 ${__RandomString(10,abcdefghijiklmnopq,)} 表示取 10 个表示从“abcdefghijiklmnopq”中随机取10个字符串。
3)${____javaScript}
__javaScript 函数的功能是运行一段 JavaScript 代码,并返回执行结果。
下面这个应用,每次返回的结果并不固定,但是有大约 40% 的概率返回真,这段代码结合 IF 控制器,可以实现保持一定概率,并随机进行某个操作流程。
${__javaScript(${__Random(1, 10, )} > 6, )}
参数说明:
- JavaScript expression to evaluate:需要执行的 JavaScript 表达式。
- Name of variable in which to store the result (optional):存储本次调用生成随机数的变量名称。
4)${__counter(,)}
__counter 函数的功能是计数。
参数说明:
- TRUE:线程组中每个线程使用自己的 counter。
- Name of variable in which to store the result (optional):存储 __counter 返回值的变量名。

__counter 可以用于生成用户,图例是使用 counter 创建 50 个用户,用户名和密码依次为 test1、test1 至 test50、test50。
7、断言
一般添加于采样器上,用于验证 Sampler 的结果或收集 Sampler 性能数据。
- 虽然 HTTP Sampler 会自动验证 Response Code,但是很多时候我们需要对其返回内容进行验证,这时我们一般需要使用 Assertion。
- HTTP 测试常用断言为 Response Assertion、JSON Assertion、Duration Assertion。
- JR223 Assertion 有时也会用到,这个断言可以通过代码实现复杂的结果检查。
1. Response Assertion(响应断言)
Response Assertion 可以检查 http 请求返中 body 的值。

配置项详解
Apply to(适用范围):
- Mainsampleandsub-samples:作用于父节点取样器及对应子节点取样器
- Mainsampleonly :仅作用于父节点取样器
- Sub-samplesonly :仅作用于子节点取样器
- JMeterVariable :作用于 jmeter 变量(输入框内可输入 jmeter 的变量名称)
测试字段(要检查的项):
- 响应文本:来自服务器的响应文本,即主体,不包括任何 HTTP 头
- 响应代码:响应的状态码,例如:200
- 响应信息:响应的信息,例如:OK
- ResponseHeaders :响应头部
- RequestHeaders :请求头部
- RequestData :请求数据
- URL 样本:响应的 URL
- Document(text):响应的整个文档
- 忽略状态:忽略返回的响应状态码
模式匹配规则:
- 包括:文本包含指定的正则表达式。
- 匹配:整个文本匹配指定的正则表达式。
- Equals:整个返回结果的文本等于指定的字符串(区分大小写)。
- Substring:返回结果的文本包含指定字符串(区分大小写)。
- 否:取反。
- 或者:如果存在多个测试模式,勾选代表逻辑或(只要有一个模式匹配,则断言就是 OK ),不勾选代表逻辑与(所有都必须匹配,断言才是 OK)。
测试模式:即填写你指定的结果(可填写多个),按钮【添加】、【删除】 是进行指定内容的管理。
注意:当要断言非 200 的响应状态码时,注意要勾选“忽略状态(ignore status)”,否则 Jmeter 会默认将非 200 的响应视为失败。
2. JSON Assertion(JSON 断言)
该组件用来对 JSON 文档进行验证, 验证步骤如下:
- 首先解析JSON数据, 如果数据不是 JSON, 则验证失败。
- 使用 Jayway JsonPath 1.2.0 中的语法搜索指定的路径。 如果找不到路径, 就会失败。
- 如果在文档中找到 JSON 路径, 并且要求对期望值进行验证, 那么它将执行验证操作。
添加方式: 测试计划 --> 线程组--> HTTP请求 --> (右键添加) 断言 --> JSON 断言
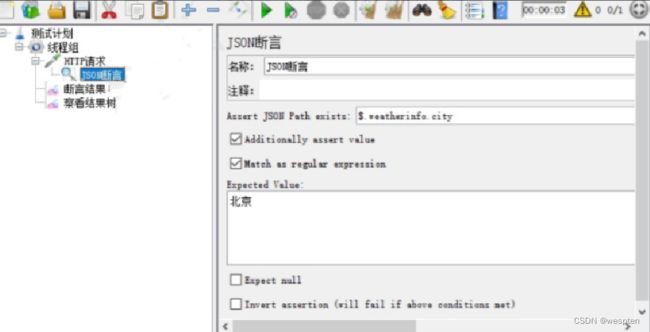
参数详解:
- Assert JSON Path exists:用于断言的 JSON 元素的路径。
- Additionally assert value:如果您想要用某个值生成断言,请选择复选框。
- Match as regular expression:如果需要使用正则表达式,请选择复选框。
- Expected Value:期望值,用于断言的值或用于匹配的正则表达式的值。
- Expect null:如果希望为空,请选择复选框。
- Invert assertion (will fail if above conditions met):反转断言(如果满足以上条件则失败)。
JsonPath 语法参考文档:https://github.com/json-path/JsonPath
3. Duration Assertion(持续时间断言)
Duration Assertion 可以检查 HTTP 请求返回所需的时间,大于配置值的请求会被标记为失败。
配置项介绍:
- 这个断言的主要配置项为 Duration in milliseconds,用于配置请求失败时间。
- Apply to 选项可以保留默认值。如果有特殊需要,可以根据文档说明配置。
8、监听器
Listener 译为监听器,一般用于对测试结果进行统计。Jmeter 提供的监听器绝大部分监听器是用于性能统计的:
- 能够获取请求/响应详细信息的只有 View Results Tree。
- 统计类型的监听器最常使用的是 Aggregate Graph(比 Aggregate Report 和 Summary Report 多了图表展示)。
监听器会监听同级或下级目录中的 Sampler,例如:
- 监听器在根目录时,监听全部 Sampler。
- 监听器在线程组根目录时,监听线程组全部 Sampler。
- 监听器在某个 Sampler 上,仅监听这个 Sampler。
View Results Tree、Aggregate Graph 这两个监听器几乎在每个 Jmeter 测试中都会用到。
1. View Results Tree
用于监听 Sampler 的详细信息。这个 Listener 常用于 debug,实际进行性能或负载测试时一般会关闭这个监听器或选择仅监听失败的 Sampler。

这里绿色的就说明请求是通过的,返回值是 200,如果出现红色的 × 就说明请求失败,这时候可以通过右边的取样器结果和响应数据来查看结果。
配置项说明:
FileName:选项配置后,可以把请求存储到一个文件中。
Log / Display only:选项可以过滤成功或失败的请求。
左下方会列出执行的 samplers,选中 samplers,右下方会列出 Sampler 这次执行的详细信息。以 Http Sampler 为例:
- Request:页签内会显示请求的具体信息,包括请求类型、URL、data 和全部 headers。
- Sampler Result:页签内会显示请求开始是时间,加载时间等以及 Http 请求的一些信息。如 header、response code 等。
- Thread Name:线程组名称
- Sample Start: 启动开始时间
- Load time:加载时长
- Latency:等待时长
- Size in bytes:发送的数据总大小
- Headers size in bytes:发送数据的其余部分大小
- Sample Count:发送统计
- Error Count:交互错误统计
- Response code:返回码
- Response message:返回信息
- Response headers:返回的头部信息
2. Aggregate Report
Aggregate Report 用于监听 Sampler 响应,并针对 Sampler 的性能结果进行汇总统计,统计内容包括:
- 每个 Sampler 执行的次数,以及全部 Sampler 执行的次数。
- 每个 Sampler 以及全部 Sampler 的最大/最小/平均/90% 的响应时间、失败率、吞吐量。

重点关心的性能指标:
- 响应时间:观察当前的最大最小值的波动范围。
- 如果波动范围不大,以平均响应时间作为最终的性能响应时间结果。
- 如果波动范围很大,以 90%(经验)的响应时间作为最终性能响应时间结果。
- 错误率:事务的失败率。
- 吞吐量:
- 吞吐量以“requests/second、requests/minute、 requests/hour”来衡量。当时间单位已经被选取为 second,所以显示速率至少是 1.0,即每秒 1 个请求。
- 当吞吐量被保存到 CSV 文件时,采用的是 requests/minute,所以 30.0 requests/second 在 CSV 中被保存为 0.5。
例:200 个用户在 10 秒中同时访问百度的页面,平均响应时间是 85 毫秒,最大的响应时间 841 毫秒,最小的响应时间是 37 毫秒,错误率为 0%,说明百度网页的性能还是不错的,每个页面都能很快的得到响应,不用 1 秒钟。
9、控制器
控制器用于在线程组内通过 Sampler 实现各种测试逻辑,可以定义 Sampler 执行的条件,可以让 Sampler 循环执行等。
- 使用 Jmeter 提供的线程组、控制器、Sampler,可以在线程内实现包含测试逻辑的用例。
- 常用控制器包括 Simple Controller、 If Controller、Loop Controller 等。

1. If Controller
If Controller 的作用类似于各种计算机语言中的 if 语句,条件为真时执行下属的 Sampler。
示例:使用“用户定义的变量”定义一个变量 name,name 的值可以是‘baidu’或‘itcast’,根据 name 的变量值实现对应网站的访问。
第一种配置方法:
第二种配置方法:
勾选上“Interpret Condition as Variable Expression”,判断条件需用使用 jexl3 函数。(使用这个函数来进行判定时,Jmeter 自身的执行效果要高一些)。

注意:当勾选“interpret condition as variable expression”时,这时 conditon 中不能直接填写条件表达式,而需要借助函数将条件表达式计算为 true/false,可以借助的函数有 _jexl2、jexl3、_groovy,例如直接填写 ${modelId}==5 时是不能识别的。
2. Loop Controller
- Loop Controller 循环执行下属的 Sampler,循环次数可以配置为整数常量,也可以配置为变量。
- 图例中的 Loop Controller 实现了用户登录后,浏览了 4 次鱼相关的内容。
- 若当前线程组的线程数为 2、loop count为 3,而 loop controller 设置为 4,则每个线程的运行次数为 3*4 = 12。

思考:线程组属性可以控制循环次数, 那么循环控制器有什么用?
答:线程组属性控制组内所有取样器的执行次数,而循环控制器可以控制组内部分取样器的循环次数,后者控制精度更高。
3. ForEach 控制器
ForEach 控制器一般和用户自定义变量或者正则表达式提取器一起使用,其在用户自定义变量或者从正则表达式提取器的返回结果中读取一系列相关的变量。 该控制器下的取样器都会被执行一次或多次, 每次读取不同的变量值。

示例 1:与用户定义的变量配合使用

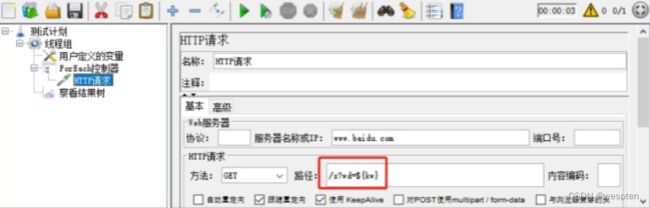
示例 2:与正则表达式配合使用

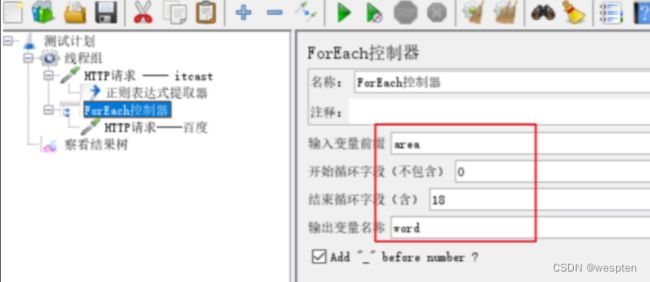
接着在 ForEach 控制器下添加一个 HTTP 请求,引用 ForEach 控制器中定义的变量 ${word},作为参数。
4. Transaction Controller(事务控制器)
事务控制器会额外产生一个采样器,用来统计该控制器下所有子节点的耗时。
事务控制器用于将 Test Plan 中的特定部分组织成一个事务。JMeter 中 Transaction 的作用在于,可以针对 Transaction 统计其响应时间、吞吐量等。比如说,一个用户操作可能需要多个 Sampler 来模拟,此时使用Transaction Controller 则可以更准确地得到该用户操作的性能指标,如响应时间等。这个时间包含了该控制器范围内的所有组件的处理时间,而不仅仅是采样器的。
如果事务控制器下的取样器有多个,只有当所有的取样器都运行成功,整个事务控制器定义的事物才算成功。

参数说明:
- Name:名称。
- Comments:注释。
- generate parent sample:选择是否生成一个父取样器。(选中这个参数结果展示如下图红框,否则显示为下图蓝框)
- include duration of timer and pre-post processors in generated samle:是否包含定时器,选择将在取样器前与后加上延时。(建议不勾选,否则统计就比较麻烦了,还需要扣除延时)

5. Simple Controller
- Simple Controller 常用于打包一组 Sampler,这样可以让线程组看起来更简洁、直观。
- Simple Controller 打包的一组 Sampler 可以在 Module Controller 中使用。
6. Module Controller
- 先将测试逻辑模块化,再指定模块进行执行,方便调试。
10、定时器
1. 同步定时器(Synchronizing Timer)[集合点]
提示:在 Jmeter 中叫做同步定时器, 在其他软件中又叫集合点。
思考:
- 如何模拟多个用户同时抢一个红包?
- 如何测试电商网站中的抢购活动、秒杀活动?
SyncTimer 的目的是阻塞线程,直到阻塞了 n 个线程, 然后立即释放它们。
同步定时器相当于一个储蓄池,累积一定的请求,当在规定的时间内达到一定的线程数量,这些线程会在同一个时间点一起并发,所以可以用来做大数据量的绝对并发请求。
添加方式:测试计划 --> 线程组 --> HTTP请求 -->(右键添加)定时器 --> Synchronizing Timer
操作示例:
- 添加线程组,设置线程数=100
- 添加 HTTP 请求
- 添加同步定时器
- 添加查看结果树
- 添加监听器-聚合报告


注意事项:当用户数不能整除集合点组件的一组用户数属性时,如果超时时间是 0,会导致程序挂起,那么该怎么避免挂起?
实现:
- 方案 1:点击 stop 强行终止。(不建议)
- 方案 2:修改一组用户数,能够做到整除。(治标不治本)
- 方案 3:修改超时时间,不设置为 0,即便一组用户数填充不满,只要超时,也会执行。(建议)
2. constant timer(常量定时器)
固定延迟几秒。

3. 常数吞吐定时器(Constant Throughput Timer)
常数吞吐量定时器可以让 JMeter 以指定数字的吞吐量(以每分钟的样本数为单位,而不是每秒)执行。吞吐量计算的范围可以为指定为当前线程、当前线程组、所有线程组。

注意:常数吞吐量定时器只是帮忙达到性能测试的负载(压力)要求,本身不代表性能有 bug 还是无 bug,对于 bug 的分析需要通过响应时间来判断。
案例:
一个用户以 20 QPS (20 次/s) 的频率访问百度首页,持续一段时间,统计运行情况。
操作步骤:
- 添加线程组, 循环次数设置成永远
- 添加 HTTP 请求
- 添加常数吞吐定时器
- 添加查看结果树
- 添加监听器-聚合报告
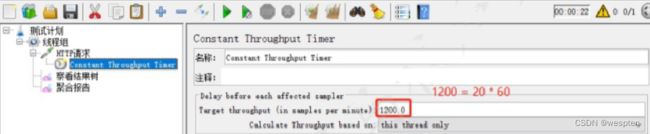
查看聚合报告的 Throughput 字段, 实际值围绕设置的 QPS 值上下波动。
4. throughput shaping timer
设定在某一个时间段内,最多发起多少请求,以控制服务端的 TPS。
11、关联
当请求之间有依赖关系,比如一个请求的入参是另一个请求返回的数据,这时候就需要用到关联处理。JMeter 可以通过“后置处理器”中的一些组件来处理关联。
常用的关联方法:
- 正则提取器
- XPath 提取器
- JSON 提取器
- 跨线程组关联
1. 正则提取器(Regular Expression Extractor)
作用:例如把登录响应报文中的 token 取出来,存到一个 Jmeter 变量中,用在其他接口的请求参数。
使用步骤 1:在结果树中测试正则表达式
步骤 2:在采样器下新建正则提取器,匹配响应数据中的正则表达式(注意:引号需要转义)
HTTP Request 右键 --> Add --> Post Processors --> Regular Expression Extractor

参数介绍:
- Name(引用名称):下一个请求要引用的参数名称,如填写 title,则后续元件可用 ${title} 引用该提取出来的值。
- Regular Expression(正则表达式)
- ():括起来的部分就是要提取的。
- .:匹配任何字符串。
- +:一次或多次。
- ?:零或一次;非贪婪模式,在找到第一个匹配项后停止。
- 模板:用$$引用起来, 如果在正则表达式中有多个正则表达式, 则可以是 $2$$3$ 等等, 表示解析到的第几个值给 title。如 $1$ 表示解析到的第 1 个值。
- 匹配数字:0 代表随机取值;-1 代表全部取值;1 代表取第一个值。
- 缺省值:如果参数没有取得到值, 那默认给一个值让它取。
步骤 3:添加 Debug Post Processor,查看调试过程中的全部变量
HTTP Request 右键-->Add-->Post Processors-->Debug Post Processor
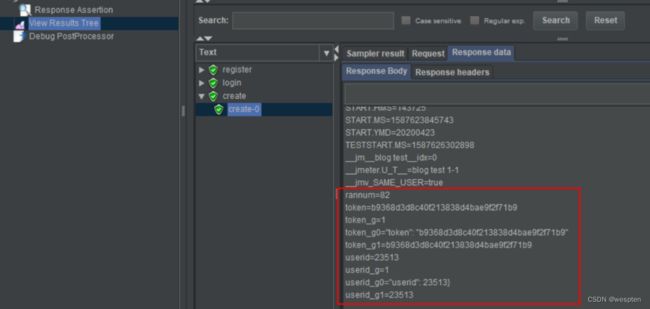
2. XPath 提取器
添加方式:测试计划 --> 线程组 --> HTTP请求 -->(右键添加)后置处理器 --> XPath 提取器
参数介绍:
- Use Tidy(tolerantparser):如果勾选此项,则使用 Tidy 将 HTML 响应解析为 XHTML。当需要处理的页面是 HTML 格式时,必须选中该选项,当需要处理的页面是 XML 或 XHTML 格式(例如 RSS 返回)时,取消选中该选项。
- 引用名称:存放提取出的值的参数。
- XPath Query:用于提取值的 XPath 表达式。
- 匹配数字:如果 XPath 路径查询导致许多结果,则可以选择提取哪个作为变量。
- 0:表示随机。
- -1:表示提取所有结果(默认值),它们将被命名为<变量名>_N(其中 N 从 1 到结果的个数)。
- X:表示提取第 X 个结果。如果这个 X 大于匹配项的数量,则不返回任何内容,将使用默认值。
- 缺省值:参数的默认值。
3. JSON 提取器
添加方式:测试计划 --> 线程组 --> HTTP请求 -->(右键添加)后置处理器 --> JSON 提取器
- Names of created variables:存放提取出的值的参数。
- JSON Path Expressions:JSON 路径表达式。
4. 跨线程组关联
当有依赖关系的两个请求(一个请求的入参是另一个请求返回的数据),放入到不同的线程组中时,就不能使用提取器保存的变量来传递参数值,而是要使用 Jmeter 属性来传递。
Jmeter 属性的配置方法可以用函数实现:
- __setProperty 函数: 将值保存成 Jmeter 属性
- __property 函数: 在其他线程组中使用 property 函数读取属性
备注:setProperty 函数需要通过 BeanShell 取样器来执行(BeanShell 取样器作用: 执行函数和脚本)
操作步骤示例:
- 添加线程组 1
- 添加HTTP请求-天气
- 添加 JSON 提取器
- 添加 BeanShell 取样器(将JSON提取器提取的值保存为 Jmeter 属性)
- 添加线程组 2
- 添加 HTTP 请求-百度(读取 Jmeter 属性)
- 添加查看结果树
12、计数器
计数器 Counter 可以让各线程使用递增的数字变量,避免使用了重复数据。
在 Config Element 下 添加 Counter,其配置页面及参数含义:

- start value:起始值。
- increment:递增值。
- maximum value:最大值,若达到了则会从 start value 重新开始取数。
- Number format:数字格式(默认整数)。
- exported variable name:生成的数据所用变量名。
- track count independently for each user:每个线程的 Counter 是否相互独立,互不影响。
- 勾上:开启2个线程示例:线程1取1,线程2取1,线程1取2,线程2取2...
- 不勾:开启2个线程示例:线程1取1,线程2取2,线程1取3,线程2取4...
- reset counter on each thread group iteration:勾上则变量的值不会变化。(一般不用)
13、可编程Sampler
Jmeter 支持可编程 Sampler,系统内部预置了一些常用的变量。通过使用可编程 Sampler 结合之前介绍的变量、逻辑控制器、http Sampler 等,Jmeter 基本上可以完成任何 B/S 性能、压力测试任务。
Jmeter 中的支持编程的 Sampler 有 Bean Shell Sampler、BSF Sampler 和 JSR223 Sampler。
- Bean Shell Sampler:Jmeter 最早支持的可编程采样器,支持标准 Java 语句和表达式,另外包括一些脚本命令和语法。
- BSF:继 Bean Shell 后支持的可编程采样器,支持 JavaScript、 Groovy 等多种语言。
- JSR223:继 BSF 后支持的可编程采样器,支持 JavaScript、 Groovy 等多种语言。
一般情况下我们采用 JSR223 Sampler,语言我们一般选择 JavaScrip 和 Groovy。
- JavaScript:当前 B/S 开发必然会使用到语言,学习资料非常多,而且遇到问题可以找前端开发帮忙解决,比较方便。
- Groovy:完全兼容 java,有时可以用 JSR223 代替编写 Java 插件使用。
预置变量
Jmeter 的三种可编程 Sampler 都支持几个预置变量,常用的变量有 vars、 log 和 SamplerResult。
vars:
- vars 用于存、取线程组内部共享变量。
- vars 支持持 put 和 get 方法,在所支持的任何语言使用方式都相同。
- vars.put("key", "value") 定义一个变量,定义后可以通过 ${key} 和 vars.get("key") 获取 "value"(注意,vars.put 的数据仅支持字符串类型)。
log:
用于在脚本中记录日志。可以使用的方法有:
- log.info("message")
- log.error("message")
SamplerResult:
用于设置 Sampler 的结果。
setSuccessful(boolean success) 设置为 true 时,Sampler 的结果为成功;false 时为失败。

14、Jmeter 命令行压测
通常 Jmeter 的 GUI 模式仅用于调试,在实际的压测项目中,为了让压测机有更好的性能,多用 Jmeter 命令行来进行压测。
官方:Jmeter 最佳实践
同时,JMeter 也支持生成 HTML 测试报告, 以便从测试计划中获得图表和统计信息。

以上定义的文件路径可以是相对路径,也可以是绝对路径。
使用案例:
步骤 1:jmeter -n -t test.jmx -l result.jtl -e -o ./report
- 执行 test.jmx 文件。
- 在当前目录下生成 result.jtl 测试结果数据。
- 在当前目录下生成 report 目录并存放生成的 HTML 测试报告。
如下图所示,成功执行并生成报告:
注意事项:定义的测试结果数据(.jtl 文件)及报告存放目录需不存在或为空,如果在执行命令时 .jtl 文件和 HTML 报告已存在,则必须先删除,否则在运行命令时就会报错。如下图所示:


步骤 2:打开报告目录下的 index.html 查看执行结果报告:
可以看到页面左侧有三个菜单:
- Dashboard(仪表盘):测试结果汇总。
- Charts(图表):详细的性能测试图表。包括 Over Time(时间变化)、Throughput(吞吐量)、Response Times(响应时间)
- Customs Grahps(自定义图表)
以下介绍 Dashboard 参数含义
Test and Report informations:
- Source file:生成报告的源文件
- Start Time:开始时间
- End Time:结束时间
APDEX(应用性能指标):
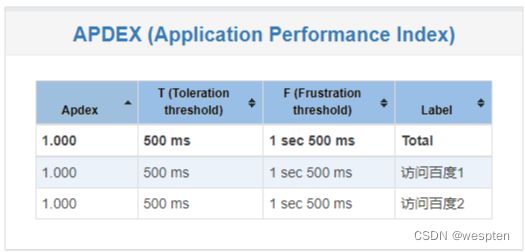
- 计算每笔交易 APDEX 的容忍和满足阈值基于可配置的值。范围在 0-1 之间:1 表示达到所有用户均满意。
- T(Toleration threshold):容忍或满意阈值。
- F(Frustration threshold):失败阈值。
Requests Summary(请求总结):

成功与失败的请求占比,KO 指失败率,OK 指成功率。
Statistics、Errors、Top 5 Errors by sampler
具体的测试结果数据统计,可检查哪些脚本执行失败。

15、分布式测试
在使用 JMeter 进行性能测试时,如果并发数比较大(比如项目需要支持 10000 并发),单台电脑(CPU 和内存)可能无法支持, 这时可以使用 JMeter 提供的分布式测试的功能,使用多台测试机一起来模拟以达到要求的负载量。
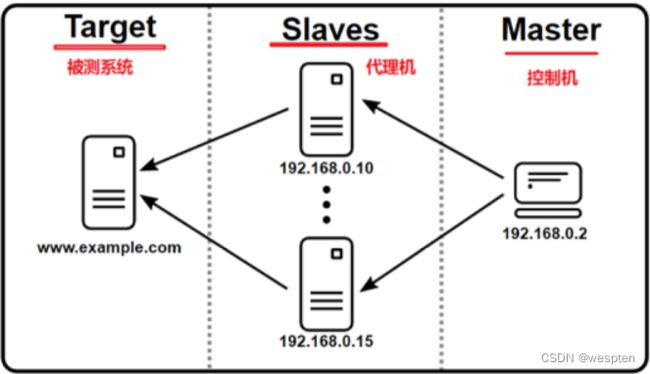
- 分布式测试时通常由 1 台控制机(Controller)和 N 台代理机(Agent)。
- 控制机(Controller):负责给代理机分发测试任务,接收代理机返回的测试结果数据,做汇总展示。
- 代理机(Agent):通过命令行模式执行控制机发送过来的脚本(不需要启动 Jmeter 界面),执行完成后将测试结果回传给控制机。
1. 代理机(Agent)配置
步骤如下:
-
Agent 机上需要安装 JMeter
-
修改服务端口
注意:该步骤非必须。如果是在同一台机器上演示需要使用不同的端口,则可以不修改。
打开 bin/jmeter.properties 文件, 修改server_port,比如:server_port=2001
- 将 RMI SSL 设置为禁用
打开 bin/jmeter.properties 文件, 修改为:server.rmi.ssl.disable=true
- 运行 Agent 上的 jmeter-server.bat 文件, 启动 JMeter
2. 控制机(Controller)配置
-
修改 JMeter 的 bin 目录下 jmeter.properties 配置文件中的
remote_hosts配置项- 示例:remote_hosts=192.168.182.100:1099,192.168.182.101:1099
- IP 和 Port 指的是 Agent 机的,多台 Agent 之间用逗号隔开
-
将 RMI SSL 设置为禁用:打开 bin/jmeter.properties 文件, 修改为:
server.rmi.ssl.disable=true -
启动 JMeter
-
选择菜单:运行 ——> 远程启动/远程全部启动

案例:
一台控制机和两台执行机,做分布式。要求控制机启动,两台执行机执行,并反馈结果。实现步骤如下:
- 配置代理机一,并启动
- 配置代理机二,并启动
- 配置控制机,并启动
- 添加线程组
- 添加 HTTP 请求
- 添加聚合报告
备注:
-
测试机上所有的防火墙关闭。
-
所有的控制机、代理机、被测系统都在同一个子网中。
-
修改完端口要重启 JMeter。
-
控制机和代理机最好分开,由于控制机需要发送信息给代理机并且会接受代理机回传的测试数据,所以控制机自身会有消耗。
-
参数文件:如果使用 csv 进行参数化,那么需要把参数文件在每台 slave 上拷一份且路径需要设置成一样的。
-
每台机器上安装的 JMeter 版本和插件最好都一致,否则容易出现一些意外问题。
16、Jenkins 配置
1. 构建触发器
选择定时任务:如下图所示为每 5 分钟执行该项目。

2. 构建命令

3. 构建后操作
Publish HTML reports:构造后的报告结果路径。

4. Editable Email Notification:构建后的报告结果邮件配置
选择右下角 Advanced Settings,添加发送邮件的时机和对象:

构建示例:
17、常用图表
1. 插件安装
步骤 1:安装插件管理器
- 在 Jmeter 官网上下载插件管理器 Plugins-manager-1.3.jar
- 将 jar 包放入到 lib\ext 目录下
- 重启 Jmeter,可以在选项下看到 Plugins Manager 选项

步骤 2:安装指定的插件
- 打开 Plugins Manager 插件管理器
- 选择 Available Plugins(当前可用的插件)
- 选择需要下载的插件(等待右方文本内容展示出来):3 Basic Graphs、PerfMon、Custom Thread Groups、5 Additional
- 下载右下角的下载按钮,自动的完成下载,Jmeter 会自动重启

2. Concurrency Thread Group(并发线程组)

指标监听器:

如下图所示:运行过程中的 TPS 统计。
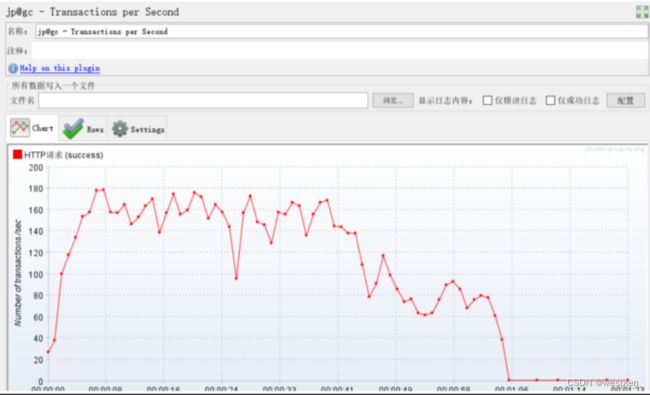
如下图所示:Bytes Through Over Time(运行过程中的传输速率)。
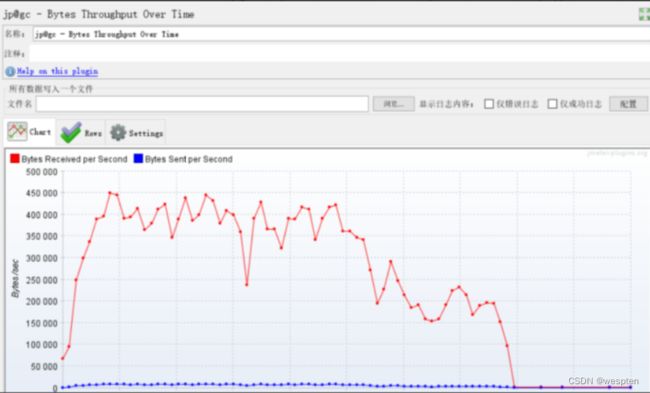
3. 服务器资源监控
以下介绍基于 Jmeter 客户端来监控服务器的硬件资源指标。
使用步骤如下:
- 下载安装包 ServerAgent-2.2.3.zip
- 解压缩安装包
- 启动安装包中的执行文件:并在服务器端启动(如在 windows 上启动 startAgent.bat;在 Linux 上则启动 startAgent.sh)
- Jmeter 中添加组件(监听器中的 perForm 组件),并进行如下配置:

运行性能脚本,该组件会自动监控。
性能脚本运行完毕后,可在该组件下方的图表区域,右键保存为 CSV 性能结果数据。
18、JMeter实战
回顾JMeter元件:

1. 案例 1:博客网站后端测试
测试目标:
- 测试博客网站后端的常用 HTTP 接口的访问方法。
- 展示 HTTP 请求的各类使用方法。
- 展示提取 JSON 数据。
- 展示随机生成测试数据,并通过可编程 Sampler 连接各个请求,组成一个完整的用场景。
接口一:通过接口自动创建(注册)用户

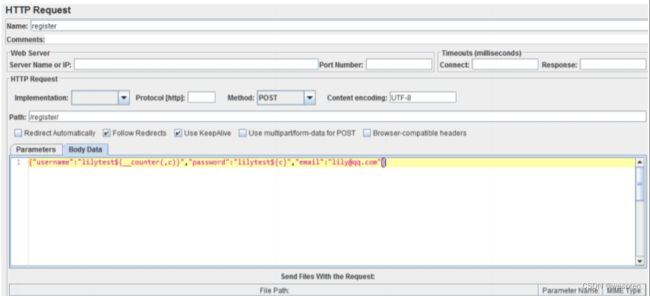
接口二:登陆并获取 Token 和 userid



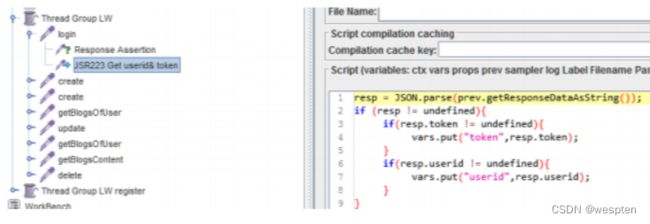
接口三:创建博文


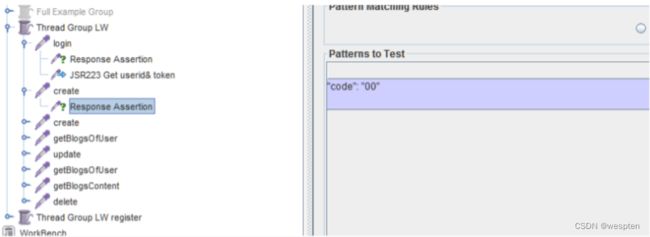
接口四:获取用户博文


接口五:更新博文

2. 案例2:JPetStore 应用
图例中的测试流程为:
- 所有用户随进对商品进行10次浏览。每次浏览随机选择要浏览的对象;
- 80%的用户选择登陆系统,把比较便宜的鱼加入购物车;
- 在上面的80%用户中,有40%的用户,有把贵的于加入了购物车;
- 把鱼加入购物车的用户全部进入了结算流程。但是最终40%的用户确认了结算。
19、常见问题处理
工作中用 jmeter 请求一个接口对谈得上会 jmeter 的人似乎都是可以做出来的,但是实际难点是参数化,结果的断言,结果的汇总等。本文将针对结果过滤有效性的情况展开分析。
示例场景:一个接口需要对入参1000多个数据做测试,且需要对结果中断言失败的情况处理。
1)在察看结果树中只看失败情况
查看结果树的数据刷的哗哗的,其实真正测试中可能失败的比较少,刷刷的难以抓住,而且这个树似乎放不上1000多个数据,所以等执行完再看势必会少数据。
2)如何把日志放入文件查看
你发现问题总不能给研发数据的时候只有截图吧,要不然就去服务端日志里遨游。
3)cvs 文件遇到中文的尴尬
读取 cvs 的中文都是乱码。
4)失败请求数据的采集
断言失败如何把入参保存下来。
5)结果树响应数据中文乱码解决办法
1. 结果处理常见问题
1)在察看结果树中只看失败情况
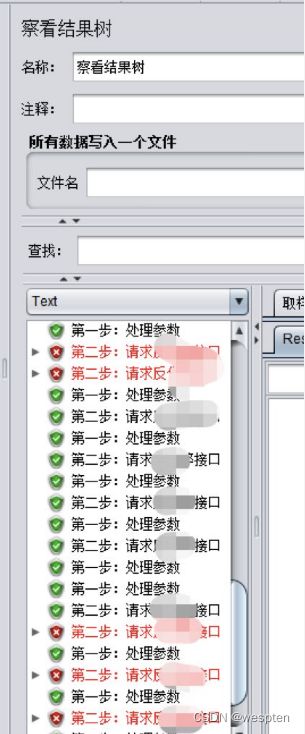
简单的解决就是把绿色的部分都给屏蔽掉,如下图所示:
2)如何把日志放入文件查看

如果有下图提示,忽略即可。

下面是日志文件的样子:

日志内容受到断言的控制,当然也和日志级别有关系。

3)cvs 文件中文读取乱码
不管是从哪里拿到的测试数据,当保存为 cvs 时要保存为 utf-8 的数据,可以先以 txt 文件写入数据,保存的时候再去修改。
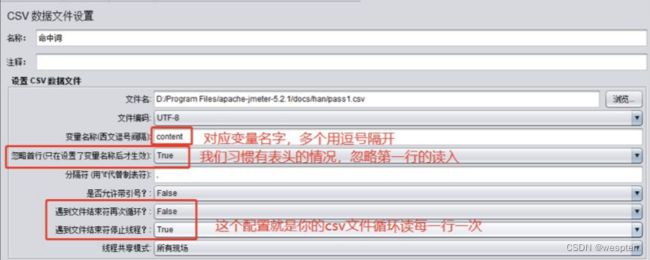
在对应的线程组上配置循环为永远,利用 cvs 遇到结束符停止的功能。

在请求中就可以参数化引用了,想在哪里用都行,就是不能跑出去这个线程组。

可以检查下中文的展示了:
4)失败请求数据的采集
以下示例是通过在断言失败时写入文件来达到目的。如果测试的数据特别多也需要对数量做统计,也是可以处理的。
注意点:jmeter 中接入的 python2 版本,jmeter 中赋值参数一定要是 u"参数值" 的 unicode 值,不然也会有编码的很多问题,所以存文件的时候要将其解码为 byte 的。
示例代码:

5)结果树响应数据中文乱码解决办法
jmeter 安装目录的 bin 目录下的 jmeter.properties 文件:
#sampleresult.default.encoding=ISO-8859-1
改为:
sampleresult.default.encoding=utf-8
之后重启 JMeter。
八、JMeter接口测试实战
搭建好JDK环境后,解压下载的文件,执行bin目录下的jmeter.bat,JMeter启动成功就会显示 GUI界面,但是,此时 GUI界面是英文的,切换到中文界面的操作为:点击 Options 下的Choose Language,选择 Chinese(Simplified),GUI界面就会以中文显示,但是关闭 JMeter 后再次启动时,界面依然显示英文。
为了使其启动即显示中文界面,可在bin 目录下,编辑 jmeter.properties 文件,把language=en修改为 language=zh_CN,保存该文件,下次启动 JMeter后,默认显示的就是中文了。
在实际应用中,会遇到某些功能需要为 JMeter 单独安装插件,安装插件的方式为下载jmeter-plugins-manager-1.3.jar文件,把该文件放到JMeter的lib/ext目录下。再次启动JMeter后,点击菜单栏的“选项”,可以看到“Plugins Manager”选项,点击“Plugins Manager”会弹出一个新的界面,如图所示。
点击“Available Plugins”,选择要安装的插件,这里主要选择JSON Plugins,PerfMon,XML Plugins,WebSocket 等插件,选中要安装的插件后,点击右下角的“Apply Changes and Restart JMeter”,就会自动下载插件并且安装,安装成功后系统自动重新启动JMeter。
1、WebServices的请求
在JMeter中创建计划和线程组,线程组名称是“WebServices的请求”,用鼠标右键点击线程组名称,在配置元件中选择HTTP信息头管理器,在HTTP信息头管理器中添加消息头,消息头为Content-Type:text/xml; charset=utf-8。
这里请求的接口是查询电话号码,接口名称是 getMobileCodeInfo,请求参数和相应内容如下:
POST /WebServices/MobileCodeWS.asmx HTTP/1.1
Host:ws.webxml.com.cn
Content-Type: text/xml; charset=utf-8
Content-Length: length
SOAPAction: "http://WebXml.com.cn/getMobileCodeInfo"
string
string
HTTP/1.1 200 OK
Content-Type: text/xml; charset=utf-8
Content-Length: length
string
用鼠标右键点击线程组,点击添加中的Sampler,新建 HTTP请求,方法选择POST,路径填写:
http://ws.webxml.com.cn/WebServices/MobileCodeWS.asmx?op=getMobileCodeInfo。
在Body Data中填写如下内容:
134****5195
在线程组中新增监听器中的查看结果树,完善后的脚本如图所示。
点击导航栏,在结果树中可查看到服务端响应回复的内容:
13484545187∶陕西西安陕西移动动感地带
100卡
2、HTTP的请求
下面来看使用 JMeter 进行针对 HTTP 请求的接口测试。这里以“抽屉新热榜”产品为例。在登录中输入账号和错误的密码,然后点击“登录”按钮。打开Chrome浏览器调试功能的Network查看请求的信息,获取的请求信息为。
General:
Request URL:https://dig.chouti.com/login
Request Method:POST
Status Code:200
Remote Address:117.34.34.233:443
Referrer Policy:no-referrer-when-downgrade
Response Headers:
cache-control:no-cache
content-length:76
content-type:text/plain;charset=utf-8
date:Fri,01 Feb 2019 07:16:29 GMT
eagleid:752222cf15490053896208101e
server:Tengine
status:200
timing-allow-origin:*
vary:Accept-Encoding
via:cache30.12nul6-1[63,0],cache7.cn451[199,0]
Request Headers:
:authority:dig.chouti.com
:method:POST
:path:/login
:scheme:https a
ccept:*/*
accept-encoding:gzip,deflate,br
accept-language:zh-CN,zh;q=0.9
content-length:49
content-type:application/x-www-form-urlencoded; charset=UTF-8 cookie:gpsd=698471c95aff035be8d4869235bc6225;
gpid=ac6249d0fb574589acc5def913eb8753; 9755xjdesxxd =32;YD0000098090586993AWM TID=IdnDYQ01DnBARERRVVY9kBbtc%2BfqlyID;JSESSIONID=aaa0swU604MOfek-heeIw;
gdxidpyhxdE=fvfRMKOt682Fqb73%2B60kGP8whPfMvT9WY9Dx4%5CwOH6zhcHb%5C4PJLCW IghJe82KW1XmpKx0tUrZAUdwfxd9dG7c82F4oPfqhGbQy41qEcjrMqxYW82Brxnr1MkSBpmu Aldouulk8pQeBXsriLolAd779U6hQW8pEMSxwq2h9JwxJ11Q82Bitfqi2L83A15490060556 76;YD000098090586983AWM_NI=sgSK4Xe2vULaUu4jLidE5YSyNag7zQiZ9zFmcQDWboE8
ecfba2f46da8b3faaed53e82bab7d7d764f2b8fdaced669ca69bb6ee37e2a3 dnt:1
origin:https://dig.chouti.com
referer:https://dig.chouti.com/
user-agent:Mozilla/5.0 (Windows NT 6.1;Win64;x64)AppleWebKit/537.36 (KHTML, like Gecko) Chrome/72.0.3626.81 Safari/537.36
x-requested-with:XMLHttpRequest
Form Data为:
phone:86134****5195
password:asdfghjkl
oneMonth:1
查看以上请求信息,可以得出如下结论:
- 请求方法:POST
- 请求URL:https://dig.chouti.com/login
- 请求参数:
- phone:86134****5195
- password:asdfghjkl
- oneMonth:1
- 请求Headres为:
- Content-Type:application/x-www-form-urlencoded;charset=UTF-8
确定如上信息后,在JMeter 中再次创建一个新的线程组和新的HTTP 请求,HTTP信息头管理器如图所示。

HTTP请求的接口信息如图所示:

点击执行后,在“察看结果树”中可看到执行的结果如图所示。
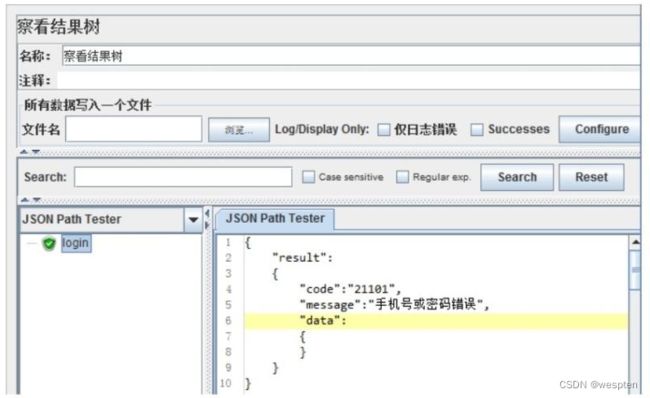
3、JMeter断言实战
在接口测试中断言非常重要,一个没有断言的接口测试用例是无效的。用例中一个断言有三个层面,分别是HTTP状态码的断言:业务状态码的断言和某一接口请求后服务端响应数据的断言。在JMeter 中增加断言的方式是,右键点击测试用例,在“添加”中选择“断言”。
在断言中点击响应断言,在响应断言中,要测试的模式填写内容:HTTP/1.1200 OK,要测试的响应字段选择 Response Headers,模式匹配规则选择 Substring,把该响应断言命名为 HttpCodeStatus,并且把该响应断言放在全局的位置,如图所示。
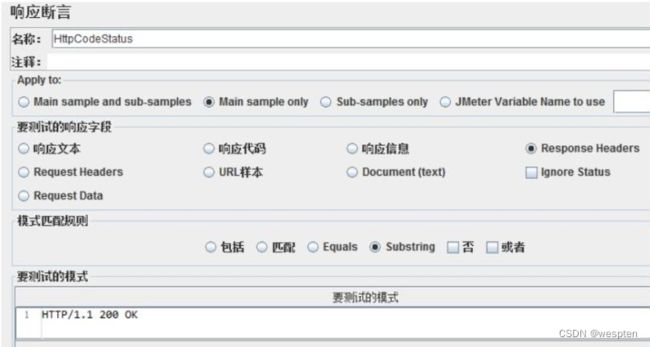
接下来添加业务状态码。在接口 login 中服务端响应数据中返回的业务状态码是21101,用鼠标右键点击login接口用例,在断言中选择JSON Assertion,在Assert JSON Path exists中编写获取到业务状态码的脚本,在Expected Value中编写期望的结果,完善后的内容如图所示。
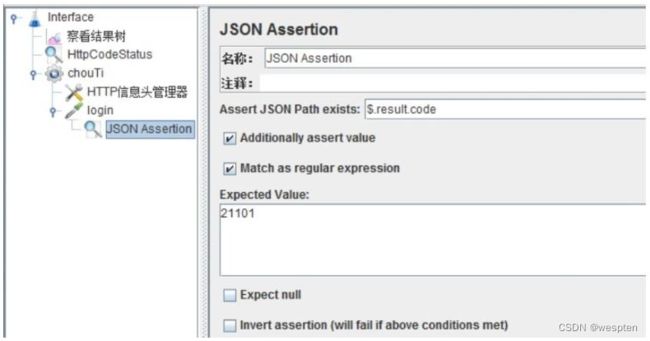
由于login接口用例无返回的data数据,所以就不做断言。对接口进行断言后,在监视器中新增断言结果,再次执行断言的结果如图所示。
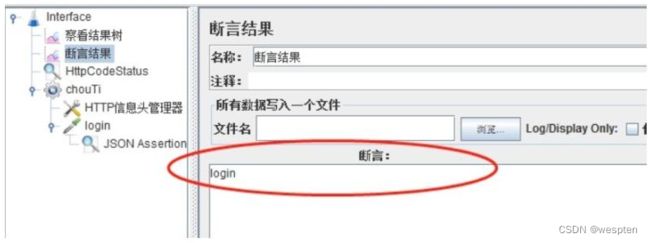
注解:如果断言失败,则会显示详细的失败信息。
4、HTTP请求默认值
login 的接口路径中直接填写着请求地址,但实际应用中,请求地址会发生改变,特别是在接口测试用例的情况下,如果请求地址或者端口发生了变化,每个接口用例都需要在路径中修改,这样维护的成本很高。在自动化测试思维体系中,无论是什么形式的自动化方式,维护方便都是必须要考虑的因素之一。
是否可以把请求地址和端口单独分离出来放到一个地方,让所有接口用例都可以继承使用,这样,即使修改请求地址和端口,只需要维护一个地方即可,而无须修改每个接口测试用例。这里使用 JMeter 的HTTP 请求默认值,它可以把请求地址和端口分离出来并被所有的接口用例应用。
用鼠标右键点击线程组,在配置元件中选择 HTTP请求默认值,在协议中填写 HTTPS,在服务器名称或者 IP中填写请求的地址 dig.chouti.com,在端口号中默认为空,因为HTTP请求的默认值是针对所有接口用例的,所以位置移动到线程组下面,填写的内容和位置如图所示。

接下来修改接口用例。在接口用例的路径中不再需要填写请求地址和端口,只填写具体的接口名称,如原来 login的路径为 https://dig.chouti.com/login,现在只需要填写/login即可,修改后的内容如图所示。
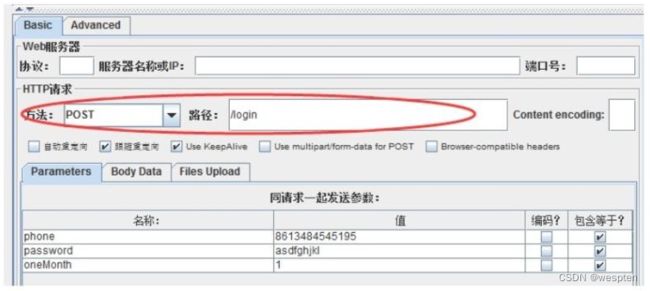
再次执行接口用例查看结果是否正确(之所以再次执行,是因为系统进行了修改,查看是否因为修改导致错误)。
5、用户定义的变量
为降低测试维护成本,通过以上HTTP请求默认值把请求地址等公共数据进行了分离,公共数据主要涉及请求地址、登录系统的用户名和密码等数据,其他的数据可通过 JMeter 测试工具自己生成并使用生成之后的数据,使接口测试的数据形成一个闭环。
在JMeter 中新增用户定义的变量,新增的步骤为右键点击线程组,在配置元件中点击用户定义的变量,在用户定义的变量中新增公共数据请求地址、端口号、用户名和密码,用户定义的变量是全局的,移动到线程组下面,用户定义变量的公共数据和用户定义变量的位置如图所示。

在图中可以看到,在用户定义的变量中增加了URL、PHONE和PASSWORD 变量,公共数据使用时只需要调用这几个变量。这里把请求地址放在了变量URL中。修改HTTP请求默认值,在服务器名称或IP中直接填写URL变量。在JMeter中调用变量的方式是${变量名},在服务器名称或IP地址中填写${URL},修改后如图所示。
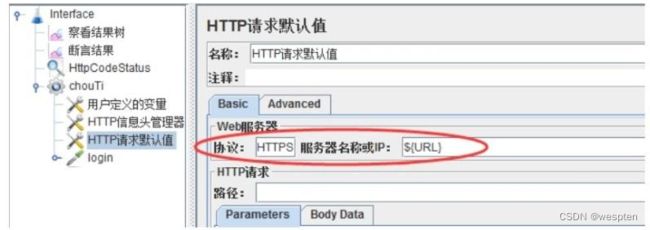
再次执行login的接口用例,执行结果通过,说明分离公共数据是正确的。
新增登录成功的接口用例,对用户名和密码使用调用变量的形式,登录成功的接口用例如图所示。
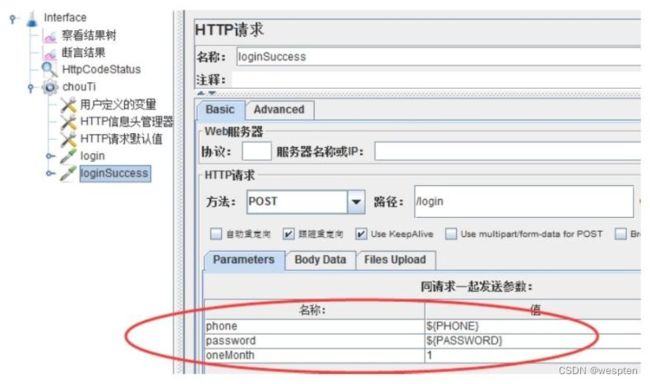
再次执行所有的用例,执行成功的信息,如图所示。

6、Token的获取实战
在PostMan中介绍到登录系统成功后,服务端返回给客户端的响应数据中返回了Token,在后面接口的请求中请求参数Token与登录成功后返回的Token一致。那么,在JMeter 中如何获取这个Token 呢?获取的方式有两种,一种方式是使用 JMeter 中后置处理器的正则表达式提取器获取,另外一种方式是使用后置处理器的JSON Path Extractor获取。
在JMeter的测试计划中创建“token实战”的线程组,在该线程组中新增登录成功的接口用例,如图所示。
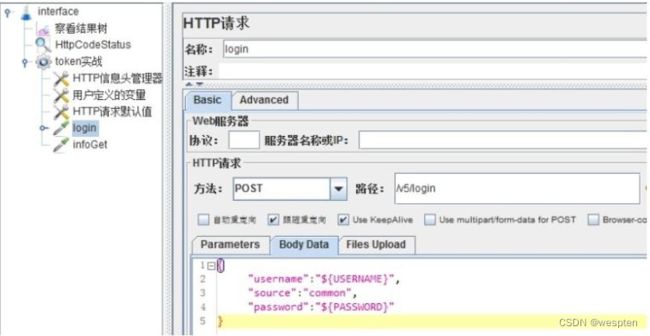
用鼠标右键点击 login 接口,在后置处理器中点击“正则表达式提取器”,填写获取Token的正则表达式,如图所示。
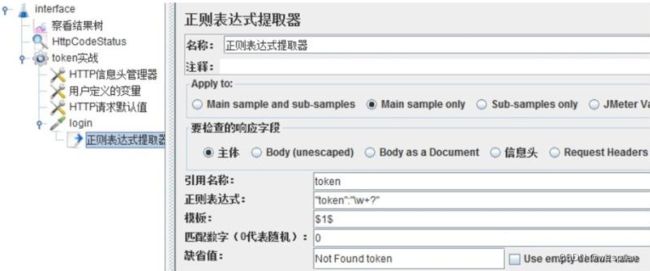
注解:这里变量名称为 token,模板和匹配数字默认,在正则表达式中匹配获取到登录成功后的token内容,默认编写Not Found token,是指如果获取token失败,调用变量token的时候,会显示Not Found Token的信息。
在实际应用中,如需获取 Token 或者动态的参数,建议使用 JSON Path Extractor,这种获取方式更加简单。用鼠标右键点击 login 接口,在后置处理器中点击“JSON Path Extractor”,在JSON Path Extractor中填写获取token的内容,如图所示。
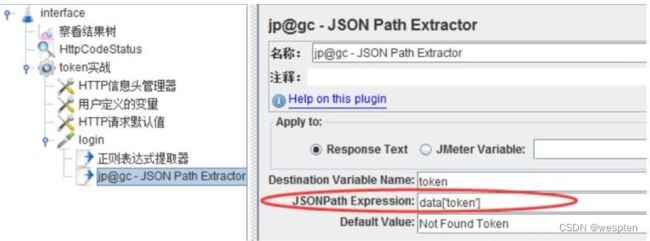
注解:在Destination Variable Name 中定义要获取的变量名称 token,在JSONPath Expression中填写获取token的节点。由于token是在data下,所以填写data[‘token'],在Default Value中填写当获取token失败,返回默认值信息。
这里使用了两种获取 token的方式,如果确认使用JSON Path Extractor方法,那么就需要禁用正则表达式提取器,禁用的方式是在正则表达式提取器中用鼠标右键点击禁用,禁用后的效果如图所示。

获取了登录成功后的token之后,下面再新增登录成功后的接口用例来应用定义的变量 token。新增接口 infoGet,它的请求参数是{"token":"ma5TnNKAquu0dgX9vf41525330567364"},请求参数中 token是登录成功响应数据中的token,在新增的infoGet接口中直接调用token的变量,infoGet的接口内容如图所示。

再次执行接口用例,infoGet接口的请求参数如图所示:
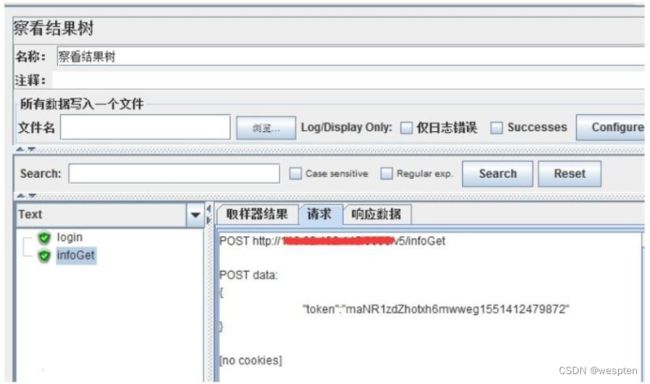
7、HTTP Cookie管理器实战
HTTP 是一个无状态的协议,在12.9小节中介绍过,登录成功后返回了token,获取token等于拿到了令牌,用户就可以在系统执行相关业务。并不是所有的产品都采用 Token 签发令牌这样的方式,以人人网为例,来看 JMeter 测试工具中“HTTP Cookie 管理器”的应用。登录系统时用 Charles 抓包工具抓到的响应数据,如图所示。

在图中我们看到,登录成功后返回的响应数据中并没有 Token,查看个人主页请求地址 http://www.renren.com/967004081/profile 发送请求如何保证是在登录成功后的操作呢?查看个人主页Request 的请求内容,如图所示。

图中可以看到,个人主页地址 http://www.renren.com/967004081/profile1在向服务端发送请求时带有 Cookie信息,返回的内容是“无涯”个人主页的信息。在JMeter 中创建线程组“人人网”,新增登录和个人主页的接口用例,如图所示。

点击“启动”按钮执行接口用例后,个人主页接口用例返回的内容并不是“无涯”个人主页的内容,而是重定向到登录的内容,如图所示。

用鼠标右键点击线程组,在配置元件中点击“HTTP Cookie管理器”,移动到查看结果树下面,如图所示。
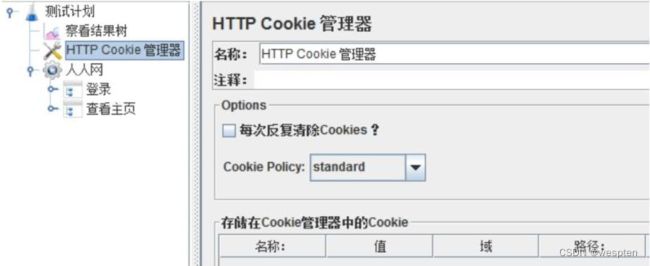
注解:添加HTTP Cookie管理器后,JMeter会自动记录并保存服务端返回的cookie信息,并且在后面所有请求中自动添加cookie,而且每个线程的cookie都是独立的。
执行以上接口用例,查看个人主页接口用例在请求时是否带了登录成功后的标识,如图所示。
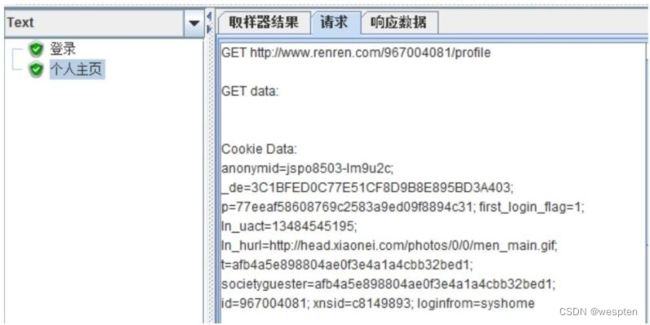
个人主页返回的响应数据会显示“无涯”个人主页的信息,如图所示。
注解:在以上请求中可以看到,“个人主页”的接口用例在请求中自动带了登录成功后的标识,会返回用户个人主页的信息。
8、生成测试报告实战
虽然在JMeter 的结果树中可以看到接口用例执行的结果,但是这样的结果看起来很不直观,下面,结合 Ant 工具生成基于HTML 的测试报告。在https://ant.apache.org/bindownload.cgi下载Ant,把apache-ant-1.10.1-bin.tar.gz下载后解压,把 Ant所在的文件路径名填加到 path的环境变量中,打开 cmd命令提示符输入ant,出现图中显示的信息,表示Ant环境配置成功。

生成测试报告的步骤具体为:
(1)修改bin目录下的jmeter.properties,把jmeter.save.saveservice.output_format=csv修改为jmeter.save.saveservice.output_format=xml,修改后的内容为:
# legitimate values: xml, csv, db. Only xml and csv are currently supported.
#jmeter.save.saveservice.output format=csv
jmeter.save.saveservice.output_format=xml
(2)把 JMeter的extras目录中的ant-jmeter-1.1.1.jar文件复制到 Ant的lib目录下。
(3)在JMeter的目录下创建 testSuite目录,在testSuite目录下创建 report目录和script的目录。report目录用以存储生成的测试报告,在report目录下创建html目录,用以存储生成的基于HTML的测试报告,在report目录下创建 jtl目录,用以存储生成的后缀为jtl的文件。Script目录用以存储测试脚本(目前,测试脚本都在bin 目录下,把测试脚本全部从 bin 命令中迁移到该目录下统一管理),在testSuite目录下创建build.xml文件,如图所示。
(4)编写build.xml文件,Ant执行的时候会用到该文件,build.xml的内容为:
执行接口自动化测试
生成接口自动测试报告
注解:在以上配置文件中,jmeterPath 指的是 jmeter 的目录(这个目录依据自己本地目录填写即可),jmeter.result.jtl.dir指的是后缀为 jtl的文件存储目录,jmeter.result.html.dir 指的是生成 html 测试报告的存储目录,jmeter.result.jtlName指的是生成后缀为 jtl文件的名称,jmeter.result.htmlName指的是生成 html测试报告的文件名称。
在target 为 run 中,先执行测试脚本,也就是
(5)到 build.xml目录下执行 ant,运行测试脚本和生成测试报告,执行的过程如图所示。


在图中可以看到执行成功,在report目录下的html目录下存在collapse.png,expand.png和生成的HTML的测试报告。打开该 HTML文件,基于HTML的测试报告内容如图所示。
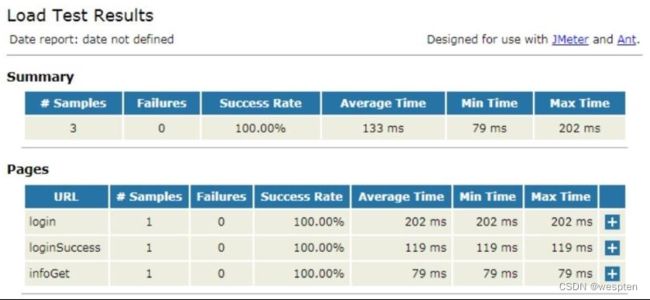
注解:在图12-11-5的测试报告中,可以看到接口用例总数、失败数、成功率及执行的时间。
9、自动发送邮件实战
如果生成测试报告后自动发送给具体的人,用户体验就会非常好。接下来实现执行接口用例,生成测试报告并自动发送邮件。使用 Ant 发送邮件需要下载mail.jar,activation.jar,commons-email-1.2.jar文件,并且放在Ant目录下的lib子目录下。
再次编辑 build.xml 文件,以实现执行完成后自动发送邮件的功能,编辑后的build.xml文件代码如下:
执行接口自动化测试用例
生成接口自动化测试报告
发送自动化测试报告
$(message)
注解:在自动发送邮件中,一定要填写正确的邮箱账号和密码,以及邮件服务器的端口和smtp 服务器的地址。执行的顺序是先执行测试脚本,然后生成测试报告,最后自动发送邮件。
再次ant执行,执行的步骤如图所示。
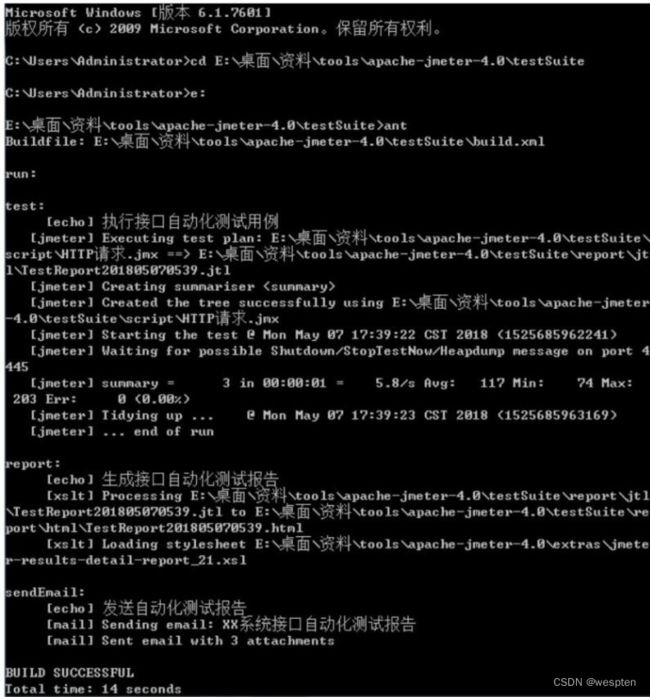
注解:在图12-12-1中可以看到,执行的流程是先执行测试脚本,再生成基于HTML的测试报告,最后发送邮件给相关的人。
打开QQ邮箱,可以看到测试系统发送过来的邮件,如图所示。
收件人可下载或者在线查看到系统的测试结果。
10、引入CI
到JMeter的testSuite目录下执行ant命令,可自动地执行接口用例和生成基于HTML的测试报告,这些工作还可以通过 Jenkins来完成,直接在CI平台中选择“立即构建”选项,就可以自动地完成,而不需要每次到 testSuite目录下执行ant命令,同时生成的测试报告也可以在Jenkins平台中查看。
首先在Jenkins 中配置 Ant 的路径,点击“系统管理”按钮,再点击“Global Tool Configuration”按钮,在打开的页面中,配置 Ant的ANT_HOME,配置界面如图所示。

注解:在Name中填写本地搭建的ant版本号,在ANT_HOME中填写 ant在本地的路径,同时在插件中安装ant。
在Jenkins中新建项目,名称为 Jmeter4.0,选择构建自由风格的软件项目,点击 OK 按钮后,在“增加构建”页面中选择“Invoke Ant”选项,点击“高级”按钮,在Build File中填写build.xml的路径,如图所示。

增加构建后选择“Publish HTML reports”选项,点击“增加”按钮,在HTML directory to archive文本框中填写 HTML的路径,在Index page[s]中填写HTML的测试报告,填写内容如图所示。
注解:使用正则表达式*.html,就可以获取所有基于HTML的测试报告。
点击“保存”按钮,跳转到项目 Jmeter 4.0的详情界面,选择“立即构建”选项。
在项目 Jmeter 4.0详情界面中可以看到生成的HTML Report,如图所示。

点击“HTML Report”按钮,会出现 HTML 测试报告界面,点击最新的测试报告,显示内容如图所示。
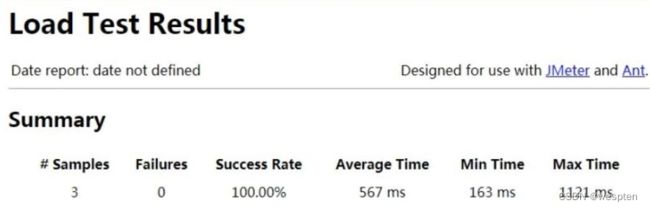
11、JMeter接口测试
前面详细地介绍了JMeter在接口测试中的应用,包括 cookie的处理,token的获取,JMeter 与 Ant 结合后测试报告的生成,自动发送邮件功能以及 Ant 与Jenkins 的整合。本节将结合这些知识点使用 JMeter 测试工具进行一次接口测试的实战。
该业务内容要求首先成功登录系统,创建用户后查询用户、冻结用户(创建的用户默认状态是激活)、激活用户,最后删除用户。
在这样的一个业务中,接口测试主要包括三个维度,第一个是接口可用性的测试,主要用于验证一个接口请求是否正常,例如,登录的接口 login,执行成功只能说该接口请求正常,但是这还无法保证登录业务是成功的,因为在一个登录业务中不仅仅请求了login 接口,还有其他的接口;第二个就是接口的校验,用于请求字段空值和边界值等校验;第三个就是通过接口测试技术来测试产品的业务。在接口用例执行成功后,接口用例执行结果全部通过,那么可以说明这个业务功能质量是合格的。本实例演示第三个维度,也就是通过接口测试来测试产品的业务。
启动 JMeter,在测试计划中创建新的线程组 userManage。在线程组创建用户定义的变量,HTTP 请求默认值和HTTP 消息头管理器,在线程组中创建登录、创建用户、查询用户、冻结用户、激活用户和删除用户的简单控制器,如图所示。

把请求地址、端口、用户名以及密码放在用户定义的变量中,如图所示。
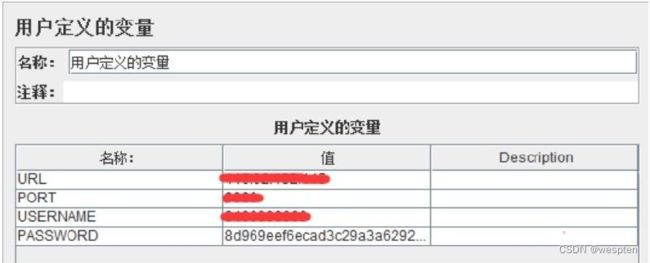
在HTTP信息头管理器中填写客户端发送请求到服务端所带的headers信息,如图所示。

在HTTP请求默认值中填写请求的地址和端口,直接调用用户定义的变量,如图所示。
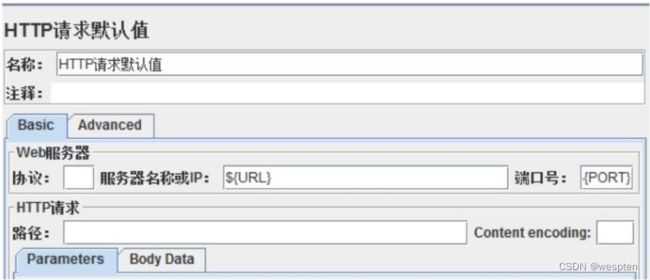
接下来完善登录业务的接口用例,主要有login和infoGet,完善后的登录业务的接口如图所示。

注解:在图中,执行 login接口成功后获取登录成功后的token,以及对login进行断言验证name是否正确,校验name部分如图所示。
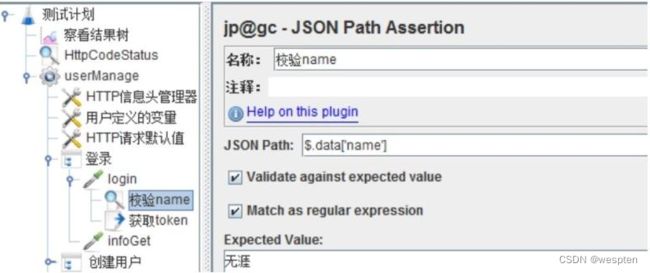
接着执行 infoGet接口用例。infoGet接口用例中请求参数 token与登录成功后返回的token必须一致,因此在infoGet请求参数中 token值调用 login接口用例后置处理器中定义的token变量,如图所示。

不管是login接口还是infoGet接口在请求成功后,响应数据中都包含了业务状态码,在线程组 userManage 中新增业务状态码断言,放在接口用例的上面对所有的接口用例生效,业务状态码的断言如图所示。

继续完善用户管理业务的接口用例,分别是创建用户,查询用户,冻结用户,激活用户和删除用户,如图所示。
注解:在以上的用例中,可以看到用户业务执行的流程,即先创建用户然后对业务进行操作,这里特别说明,用户创建成功后默认状态是激活的,所以冻结用户用例应在激活用例前,而不能激活用例在冻结用例前。因为用户创建成功状态默认是激活的,再次执行激活的接口用例是有没意义的。
在以上执行图中可以看到,其他接口都有断言验证,而冻结用户、激活用户及删除用户只验证了HTTP 协议状态码、业务状态码,但是没有断言响应数据。这样导致的问题是添加用户成功后,冻结了用户,用户的状态是否为冻结状态无法确定,但是在冻结用户、激活用户和删除用户中服务端返回的响应数据是{"status":0,"msg":"","data":{}},那么如何证明冻结用户接口执行成功后用户的状态就是冻结的?可以调用查询用户接口来查看该用户的状态字段是否是冻结状态,如果是,证明冻结接口执行成功后用户确实已被冻结,激活用户同理。在冻结用户和激活用户用例后面添加查询用户接口用例,验证用户的状态。
冻结用户和激活用户后,增加查询用户的接口验证用户状态的用例,如图所示。
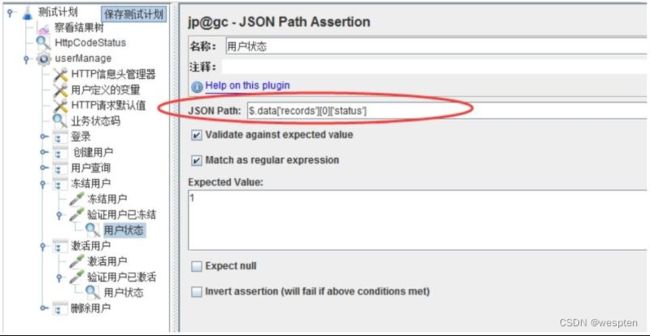
在图中可以看到,删除接口用例同样缺少数据断言。如何在接口用例中通过断言证明用户已被删除?可以在删除接口用例后,增加用户查询的接口用例,依据用户名称查看该用户是否存在,如果返回的数据是0,那么该用户已删除,否则说明删除接口用例存在问题,完善后的接口用例如图所示。

至此,用户业务的接口用例才比较完善了。用户业务如果使用手工的方式进行测试,至少需要5分钟以上的时间,而且每次环境更新,每次迭代这个业务都需要重新测试。通过使用 JMeter 测试工具来实现该业务的接口用例,只需要几秒钟时间,就可以测试出该业务功能是否正常。
为了确保接口XX模块的业务接口用例是正常、合理的,必须做到断言合理,也就是说断言应包含HTTP协议状态码验证、业务状态码和业务数据验证。另外还需要确保接口用例执行流程业务合理,例如,冻结用户用例时,需要明确地告诉我们冻结用户功能是否存在问题,也就是必须验证冻结用户后用户的状态,这里添加了查询用户的接口用例来验证用户的状态。假设冻结用户后没有执行用户查询接口和验证用户状态,是无法确定用户状态是否为冻结的。在自动化测试中,答案只有两种,一是成功,表明业务正确;二是失败,表明业务存在问题。
在build.xml 文件中将 HTTP 请求.jmx 修改为 shop.jmx,在Jenkins 中执行Jmeter 4.0的项目,执行后的结果如图所示。

九、JMeter对Selenium自动化代码进行压测
JMeter是Apache组织开发的基于Java的压力测试工具,用于对软件进行压力测试,最初被用于Web应用测试,后来扩展到其他测试领域。JMeter可以用于测试静态和动态资源,如静态文件、Java小服务程序、CGI脚本、Java对象、数据库、FTP服务器等。JMeter可以模拟服务器、网络或对象产生的巨大负载,从不同压力类别下测试它们的强度,分析整体性能。另外,JMeter能够对应用程序进行功能/回归测试,通过创建带有断言的脚本来验证程序是否返回期望的结果。为了能最大限度地灵活使用,JMeter允许使用正则表达式创建断言。下面介绍JMeter的安装方法。
登录JMeter官网,根据自己的计算机操作系统选择适合的安装文件。
使用的版本是JMeter 5.2.1,需要Java 1.8及以上的版本支持。要安装JMeter,必须先安装JDK,还要进行相应的环境配置。
/bin目录下的常用文件和目录如下:
- examples:该目录下包含JMeter使用实例。
- ApacheJMeter.jar:JMeter源码包。
- jmeter.bat:在Windows系统中的启动文件。
- jmeter.sh:在Linux系统中的启动文件。
- jmeter.log:JMeter运行日志文件。
- jmeter.properties:JMeter配置文件。
- jmeter-server.bat:在Windows系统中启动负载生成器服务的文件。
- jmeter-server:在Linux系统中启动负载生成器的文件。
其他目录如下:
- /docs:JMeter帮助文档。
- /extras:提供对Ant的支持文件,可也用于持续集成。
- /lib:存放JMeter依赖的jar包,同时安装插件也存放于此目录下。
- /licenses:软件许可文件。
- /printable_docs:JMeter用户手册。
其中,在bin目录下的jmeter.sh(在Windows系统中是jmeter.bat)文件就是可执行文件。运行或者双击该文件后,可以看到如图所示的GUI操作界面。
JMeter和Selenium结合使用,可以实现对网站页面的自动化性能的测试。下面介绍具体的实现方法。
1. 下载WebDriver驱动
下载WebDriver插件(包含Google浏览器驱动和Firefox浏览器驱动),安装好之后需要重启JMeter。
注意,需要把解压的lib目录下的所有jar文件放到JMeter安装目录的lib文件夹下,再把解压的lib/ext文件夹下的jmeterplugins-webdriver.jar文件复制到JMeter安装目录的lib/ext文件夹里。
通过Meter Plugins Manager(JMeter插件管理器)安装Webdriver:
安装好之后需重启jmeter。
2. 添加Chrome Driver
添加Chrome Driver的配置项,设置方式如图所示:

配置浏览器驱动地址:

3. 添加jp@gc - WebDriver Sampler
新增一个WebDriver Sampier配置,如图所示。
4. 编写Selenium代码实现自动化测试
代码编写好后就可以执行了:
WDS.sampleResult.sampleStart()
WDS.browser.get("https://www.google.com/");
var searchBox = WDS.browser.findElement(org.openqa.selenium.By.name("q"));
searchBox.click();
searchBox.sendKeys('Test');
searchBox.sendKeys(org.openqa.selenium.Keys.ENTER);
WDS.sampleResult.sampleEnd()由于可能存在跨线程,需要设置全局变量,直接调用变量即可看到效果。
5. 跨线程,需要设置全局变量

直接调用变量:
十、多线程并发处理实现
通过前面的压力测试可以看出,并发量是考核服务性能的一个关键指标。如果在高并发下能承受更大的流量和请求,则这样的服务会更加稳定、强大。
一般情况下,如果可以对一些大访问量的接口或者服务提供多线程的处理方式,那么会大幅度减少请求压力。因此可以利用服务器的多核特性,让服务器能更好地处理海量请求。
实现多线程并发处理,可以从以下几个方面去考虑:
- 服务器部署。
- Web服务器配置,如负载均衡。
- Web Service或框架自身调优。
- 代码多线程化。
- 中间件。
1. 服务器部署
Python常见的部署方式有以下几种:
- fcgi:使用spawn-fcgi或者框架自带的工具对各个项目分别生成监听进程,然后被HTTP Web服务器调用。但是Python项目很少直接使用fcgi,更多的是选择使用WSGI方式部署。
- WSGI:利用HTTP服务的mod_wsgi模块来运行各个项目。它用于规范Server端和application端的交互。
- uWSGI:实现了WSGI协议,在WSGI基础上进一步开发,使用C语言编写,执行效率高,性能非常好。uWSGI协议是专门供uWSGI服务器使用的。根据大量试验验证,uWSGI协议的效率大约是fcgi协议的10倍。
在Web服务器中,一般选择Apache即可。Apache支持解析WSGI协议,提供了mod_wsgi模块。但uWSGI的性能更好,内存占用低,可以多App管理,拥有详尽的日志功能且高度可定制。
2. Web服务器配置
针对uWSGI协议,可以在Nginx中配置该协议,其中,nginx.conf的配置方法如下:
location / {
include uwsgi_params;
uwsgi_pass 127.0.0.1:9090
}对应上面的配置来启动Web服务,具体命令如下:
uwsgi -s :9090 -w my_app -M -p 4该命令的含义是使用一个主进程管理并发出4个线程来运行Web服务,占用的端口是9090。也可以使用Nginx对多个应用进行部署,nginx.conf配置如下:
server {
listen 80;
server_name app1.mydomain.com;
location / {
include uwsgi_params;
uwsgi_pass 127.0.0.1:9090;
uwsgi_param UWSGI_PYHOME /var/www/myenv;
uwsgi_param UWSGI_SCRIPT myapp1;
uwsgi_param UWSGI_CHDIR /var/www/myappdir1;
}
}
server {
listen 80;
server_name app2.mydomain.com;
location / {
include uwsgi_params;
uwsgi_pass 127.0.0.1:9090;
uwsgi_param UWSGI_PYHOME /var/www/myenv;
uwsgi_param UWSGI_SCRIPT myapp2;
uwsgi_param UWSGI_CHDIR /var/www/myappdir2;
}
}重启Nginx服务后即可生效,这样就配置两个应用共用一个uWSGI服务来运行。
除此之外还可以配置负载均衡来分流请求,达到减少并发压力的效果。在相关配置文件中的具体配置方法如下:
#定义负载代理服务器组
upstream my_proxy {
server 127.0.0.1:8885;
server 127.0.0.1:8886;
server 127.0.0.1:8887;
server 127.0.0.1:8888;
}
server{
listen 80;
server_name message.test.com;
keepalive_timeout 65; #
proxy_read_timeout 2000; #
sendfile on;
tcp_nopush on;
tcp_nodelay on;
location / {
proxy_pass_header Server;
proxy_set_header Host $http_host;
proxy_redirect off;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Scheme $scheme;
proxy_pass http://my_proxy; # 通过多个代理去负载
}
}其中,每一个代理的ip+port都是一个后端服务,例如一个Django Web项目。
3. Web Service调优
不同的编程语言实现的Web Service的调优方式不同,这里只对Python的常用Web框架进行讲解,具体包括Django、Flask和Tornado。
其中,Django没有单独设置并发的配置,一般还是利用uWSGI+Nginx来实现,具体方法已经在前面介绍过。如果要设置使用守护进程来运行Web服务,启动命令如下:
uwsgi -s :9090 -w my_app -M -p 4 -t 30 --limit-as 128 -R 10000 -d runing.log其中,-d指明使用守护进程来运行Web服务,--limit-as通过使用POSIX/UNIX的setrlimit()函数来限制每个uWSGI进程的虚拟内存占用量,这里设置最大不超过128MB。
Tornado是一款高性能的Web框架,它的特性是异步非阻塞,可以使用回调和协程来实现高性能接口响应。Tornado可以扩展出成千上万个开放的连接,非常适合长时间轮询,WebSocket需要与每个用户建立长期连接的其他应用程序。
在Tornado框架的官网上提供了一个最简化版的脚本,代码如下:
import tornado.ioloop
import tornado.web
class MainHandler(tornado.web.RequestHandler):
def get(self):
self.write("Hello, world")
def make_app():
return tornado.web.Application([
(r"/", MainHandler),
])
if __name__ == "__main__":
app = make_app()
app.listen(8888)
tornado.ioloop.IOLoop.current().start()4. 代码多线程化
对于某些业务,如需要批量下载多个文件,如果是单一进程去完成则耗费的时间比较长,如果使用多线程去处理则会非常高效。
假设要下载3个PDF文件,代码如下:
# -*- coding: utf-8 -*-
from threading import Thread
from time import time,sleep
class DownFile(Thread):
def __init__(self, file_name, cost_time):
Super().__init__()
self.__name = file_name
self.__time = cost_time
def run(self):
print('Start to download %s.....' % self.__name)
sleep(self.__time) # 模拟消耗时间
print('%s finish download' % self.__name)
start = time()
task1 = DownFile('Python机器学习.pdf', 3)
task1.start()
task2 = DownFile('Golang编程指南.pdf', 4)
task2.start()
task3 = DownFile('细说PHP.pdf', 3)
task3.start()
task1.join()
task2.join()
task3.join()
end = time()
print("三个文件下载完成一共耗时:%.2f秒" % (end - start))
执行该脚本,输出如下:
python threading01.py
Start to download Python机器学习.pdf.....
Start to download Golang编程指南.pdf.....
Start to download 细说PHP.pdf.....
Python机器学习.pdf finish download
细说PHP.pdf finish download
Golang编程指南.pdf finish download
三个文件下载完成一共耗时:4.01秒由此可以看出,使用多线程使下载任务变成了并发执行,大大缩短了响应时间。
5. 消息中间件
消息中间件(MQ)是指支持与保障分布式应用程序之间同步或异步收发消息的中间件。它可以解决一些高并发的性能瓶颈,将消息队列中的任务分发给消息消费者,其架构图如图所示。

MQ具有异步、吞吐量大、延时低的特性,适合执行投递异步通知、限流及削峰平谷等任务。利用一些特性,可以做定时任务。
消息中间件的可选性很多,如RabbitMQ、RocketMQ及ZeroMQ,国内还有TubeMQ可以选择使用。
十一、接口并发测试实战
1、并发测试场景设计
1. 设计思路整理
1)需求分析
并发测试的需求分析分为以下几个部分。
- 业务需求分析
(1)首先要找到并发测试对象,了解需要测试的功能有哪些,可以按照业务功能整理,不必深入细节。
(2)其次描述测试对象的重要性,如要求严格质量的核心功能、高频使用的功能、占用系统资源较多的功能。
(3)最后进行测试对象拆分,比如购买商品可以拆分成:搜索商品、锁定库存、提交订单、发送支付指令、接受处理支付结果、业务流水、短信及站内信通知、微信推送结果等。
- 环境需求分析
明确重点测试对象,预先设置基础数据及大量历史数据,模拟真实环境。
- 性能需求指标分析
分析性能指标是否合理。可以从历史数据中的这几个方面考虑:TPS、页面访问量、并发请求数,从而判断需求指标是否恰当,安排优先级。
2)测试策略
在看懂一个功能完整的运行流程,包括请求顺序、请求之间互相调用关系、数据流向、有没有调用外部系统后,需要明确重点测试对象,预先设置基础数据及大量历史数据,模拟真实环境。这些都属于并发测试的准备工作。完成了准备工作,测试人员就需要按照测试策略执行测试。
一般并发测试会涉及以下几个测试阶段,测试执行顺序也可以按照序列执行:
- 对于功能并发测试,要先进行单业务功能场景的测试,再进行混合业务功能场景的测试。
- 对于性能并发测试,通常是满足某些系统性能指标的前提下,让被测对象承担不同的工作量,以评估被测对象的最大处理能力及是否存在缺陷。
- 对于稳定性测试,判断测试系统的长期稳定运行的能力。该策略测试强度较小,一般趋向于客户现场日常状态下的压力强度,当然在通过时间不能保证稳定性的状态下,需要加大压力强度来测试,此时的压力强度则会高于正常值。
- 对于异常性测试,模拟系统在较差、异常资源配置下运行,如人为降低系统工作环境所需要的资源,网络带宽、系统内存、数据锁等,以评估被测对象在资源不足的情况下的工作状态。
对于不同的测试执行阶段,只是测试人员关注的测试目的不同而已。实际执行代码相同或者仅需修改少数代码(如添加性能指标)就能完成测试。对于测试人员来说,测试思想才是最关键的内容,而测试思想在复杂的业务功能测试中最能体现。所以在下一节,我会以功能并发测试为例,举两个实例,希望大家能掌握其中的测试思想。
2. 场景分析实例
1)账户资金场景
账户资金场景用于将账户展示给用户看。账户信息包括余额、交易流水,提供交易支付服务。
其中金额、流水分多种类型,测试人员需要根据账户体系的组成,先简单地画出需测试的数据库对象,如图所示。
当确定了测试对象后,测试人员需要掌握测试对象中的名字含义,即接口中参数的含义及相互的逻辑关系,并且明确测试对象的操作行为以及规则的含义。
用户账户资金类名词:总资金、可用资金、冻结资金、锁定资金、在途资金。
- 总资金=可用资金+冻结资金+锁定资金。
冻结资金:在竞价保证金、法院冻结、押金场景会将资金冻结。
锁定资金场景:申请提现锁定。
在途资金场景:银行卡充值代扣成功,暂未到账。
交易流水类名词:用户流水、可用资金流水、冻结资金流水、在途及销账资金流水。
用户流水:用户充值、提现、交易流水。
可用资金流水:记录可用资金发生的变化,如充值、提现、交易。
冻结资金流水:记录冻结资金发生的变化。
在途及销账资金流水:记录在途资金发生的变化,如实时充值、银行隔日兑付。
交易类型:实时支付、挂账支付、组合实时支付。每种支付方式,若实时接口网络颠簸出现异常值,都以查询回调交易信息为准。
直接支付:账户A划款至账户B,实时反馈支付成功、支付失败结果,异步再次反馈支付结果。
挂账支付:增加一个划款任务,账户A划款至账户B,实时反馈接受成功、失败,异步反馈支付成功、支付失败。
组合实时支付:一组实时支付指令,任意账户中出现余额不足,这组交易都将回退。
交易风控规则如下:
- 单笔最大交易额设置。
- 每日累计交易额度设置。
- 提现规则控制:在途资金,当日充值金额。
- 大额交易时间设置。
日结、实时对账,资金不平的账户立即封存,等待处理完成再解封。
日结:每个账户每日分别计算各类资金期初余额。
- 总资金=可用资金+冻结资金+锁定资金
- 期末金额 - 期初金额 = 对账交易流水的汇总
2)整理业务场景
当完成基本的测试需求分析后,测试人员需要将测试需求点按照测试思想重新组装,形成独立的测试场景,这个过程也可以被称为分拆合成再分拆优化的过程。
入金相关充值场景如图示。
- 通道代扣入金:由本人授权第三方支付机构、银行,根据本人的确认充值金额,从绑定的银行卡账户直接扣款。
- 支付机构余额入金:根据本人的确认交易金额,从第三方支付机构余额扣款。
- 银行卡转账:由本人通过网银、银行柜面、ATM机,发起向企业转账,转入电商平台指定账号。
- 第三方支付机构与资金系统,对实际到账资金进行核销。

- 直接支付、组合支付:实时支付并反馈结果。
- 当网络颠簸收到异常信息时,不能判定为支付失败。需要等待异步支付通知,或主动查询支付结果。挂账支付:资金系统实时反馈接受结果。待账户资金足够后,按序支付并进行异步通知。
3)测试方案设计、分配计划
最后,测试人员可以根据测试需求分析以及场景构建结果,参考项目组分工开发模式,设计测试方案以及测试计划。
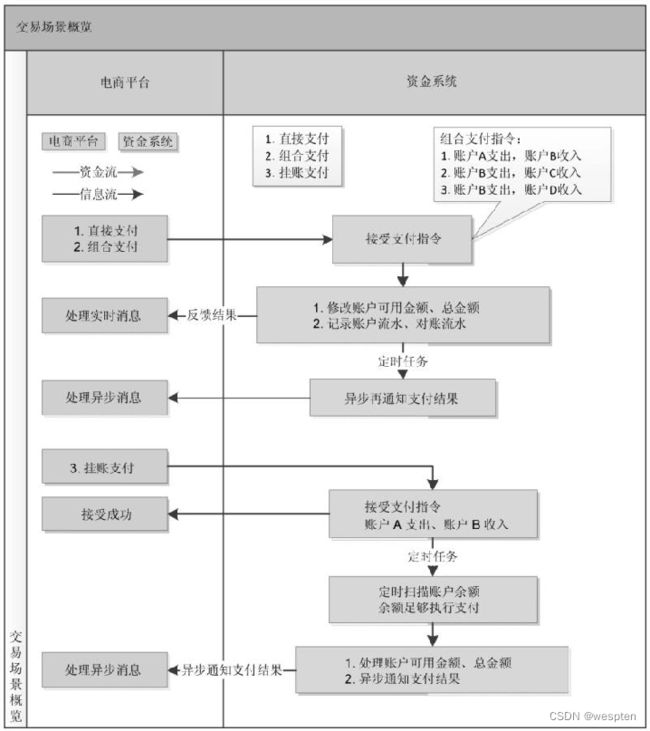
举例如下:
第一轮测试,以接口文档驱动测试,测试步骤及要点如下:
- 编写接口测试代码,核对每个接口传入参数控制:长度限制、格式、必填限制、正常值范围限制等。同时,确认报错提示信息是否准确、到位。
- 异常账户数据测试,将账户冻结、交易金额置为负数、数据库锁表、网络断开等情况,对入金、交易类接口测试,检查数据是否出现异常。
- 逐个接口进行并发事务测试,检查账户金额、用户流水、对账流水数据。核对账户收支金额、流水是否与用例调用结果一致。
- 复合接口并发测试,将各种方式充值、交易类型的接口按照一定的顺序进行并发。同样核对账户收支金额、流水是否与用例结果一致。
第二轮测试,以业务场景驱动测试,测试步骤及要点如下:
- 同一动作并发:相同订单并发支付、并发退款。
- 电商平台混合交易场景:秒杀抢购、集中退货、到货确认。
- 绕过页面操作,通过抓包、POST工具,抛送异常值进行交易测试。
3. 场景分析实例2
1)线上抽奖推广活动场景
某电商网站三周年庆,策划一轮面向所有会员的营销活动,活动详情如下:
- 活动时间:5月18日~5月25日,每天9:00~21:00。
- 参与方式:登录微信公众号或者手机APP。
- 参与资格:所有会员每日有三次机会,分享活动到朋友圈增加一次机会,当日消费最多可增加三次机会。
- 奖项设定:一等奖5000元现金、二等奖100元支付红包、三等奖10元支付红包、四等奖3元支付红包、五等奖谢谢参与,支付红包有效期为1周。
- 奖项概率:一等奖0.008%,二等奖0.05%,三等奖20%,四等奖50%,五等奖29.942%。
- 中奖规则:每日限定一等奖1名、二等奖20名、三等奖100名、四等奖2000名;已获得一等奖、二等奖的会员,只能抽中五等奖。
- 条件触发情况:若截至 15:00 仍未出现一等奖,提高一等奖中奖概率至 0.04%,同时主办方视活动实时详情增加奖品个数。
- 公正性保障方案:公司员工账号排除在中奖范围内,不予中任何奖项。
2)业务需求分析
测试人员根据业务需求,设计测试对象如图所示。
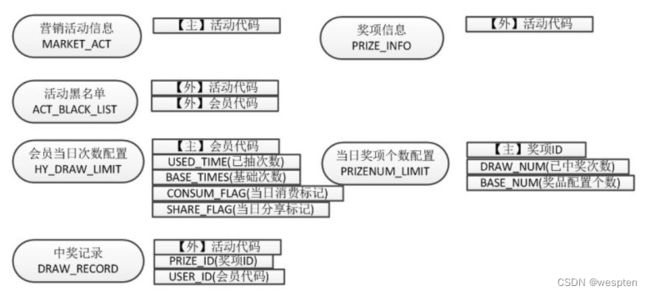
由于抽奖活动的业务复杂度相对简单,测试对象中的名字含义以及操作行为规则简洁易懂,此处不需要额外的测试分析。
3)测试方案设计
根据营销活动的规则,我们由表及里,逐一验证各种业务场景下功能的准确性。
- 验证抽奖次数
测试目标:已注册用户的抽奖次数,每日活动结束后初始化是否有效。
当日新注册用户,是否获得抽奖次数。
并发测试分享、消费场景,新增次数是否准确。
- 验证用户抽奖次数、黑名单功能
测试目标:挑选拥有不同次数的账号10个,每个账号进行30个以上的并发测试。分别统计每个账号、每种抽奖结果,是否与期望值一致。
- 验证抽奖概率
测试目标:进行10轮并发,每轮1万个请求,验证3位小数的中奖概率是否有效,中奖个数是否符合预期。
由于一等奖中奖概率为十万分之八,故使用单个账号测试中奖概率,需要做以下配置准备。
按业务场景配置中奖概率,概率需支持三位小数;调整奖品个数各10万个。
屏蔽单个账号抽奖次数限制,屏蔽单个账号只能中一次一等奖、二等奖限制。
- 验证奖品数量限制
测试目标:至少进行3轮并发,每轮100次抽奖请求,验证一等奖、二等奖中奖个数是否会超过限制。
在中奖概率极高的条件下,并发测试中奖的奖品数量是否会超过每日限制,需要做以下配置准备。
调高各等奖项中奖概率,依次为70%、20%、10%、5%、0%;调整各等奖项奖品个数,依次为2、4、6、8、10个;屏蔽单个账号只能中一次一等奖、二等奖限制;屏蔽单个账号抽奖次数限制。
- 验证中奖规则
测试目标:至少进行3轮并发,每轮100次抽奖请求,已获一、二等奖的用户只能抽中五等奖。
需要做以下配置准备。
调高各等奖项中奖概率,依次为70%、20%、10%、5%、0%;调整各等奖项奖品个数,依次为2、4、6、8、10个;屏蔽单个账号抽奖次数限制。
- 验证支付红包能否正常使用
测试目标:获取100元、10元、3元支付红包若干个,单个轮流使用、组合使用;支付红包过期后,是否会作废。
2、并发结果测试与结论
1. 账户资金并发bug实例及测试建议
测试人员根据测试方案执行测试后输出测试结果,提交bug以及记录在bug追踪过程中的关键信息。这个步骤可以优化测试方法,提高测试效率及更好地为项目组提供有效信息。
bug举例如下:
1)bug描述:由于资金系统问题,造成支付总额与实际扣除金额不符。
测试行为:账户金额1000元,支付两笔10元订单,结果账户还剩余990元。
此类问题原因分析如下:
- 资金系统先查询账户余额,再用程序进行计算减去支付金额,最后直接将990元更新到数据库。
- 资金系统没有判断更新结果,虽然减了两次10元,最终却只支付成功一次。
例如,账户总额为1000元,冻结金额为 985元。
资金平衡公式:总资金=可用资金+冻结资金+锁定资金
数据修改方式:UPDATE总资金=总资金−10,可用资金=可用资金−10 WHERE总资金−冻结资金−锁定资金−可用金额=0
数据更新结果:第一次1条,第二次0条。
系统若没有判断返回的结果,主动抛出异常回滚,就会造成资金异常。
2)bug描述:由于电商系统问题,造成支付总额与实际扣除金额不符。
测试行为:账户金额1000元,支付三笔10元订单,由于卖家原因退款一笔,结果账户只剩余960元。
此类问题原因分析如下:
- 电商平台生成的两笔订单的支付单据号可能相同,收到的两次支付结果实为一笔交易。
- 用户对某一笔订单,反复点击发起支付,产生多笔不同的支付单号且支付成功。
- 系统自动发起退款时,由于网络颠簸未收到支付结果,反复发起退款。
根据测试结果,测试人员向开发设计人员提出建议如下:
- 资金系统应通过数据库操作去运算、修改金额,且要判断更新结果。
- 资金系统必须使用技术手段,确保同一个支付单号只能接受并支付一次。
- 电商平台每笔订单生成时,必须对应唯一的付款支付单号、退款支付单号,付款或退款时不可再生成新的支付单号。
2. 抽奖营销活动并发bug实例及测试建议
测试人员根据测试方案执行测试后输出测试结果,提交bug以及记录在bug追踪过程中的关键信息。这个步骤可以优化测试方法,提高测试效率及更好地为项目组提供有效信息。
bug举例如下:
1)bug描述:意外获得了多次抽奖机会。
测试行为:一个用户同时分享、消费多次,用户获得了额外的抽奖次数。
此类原因分析:在功能设计上没有分别记录分享、消费得到的次数,使得系统在一瞬间认为该用户并未分享过,增加了多次抽奖机会。
2)bug描述:用户在消费抽奖次数、奖品个数超出预期。
测试行为:一个用户出现超出设置的额外抽奖次数,可以领取无限制奖品数。
此类原因分析:此类问题原因与上一节中的账户资金控制 bug 的原因相似,不再详细描述。
3)bug描述:主办方频繁调整奖品个数,导致抽奖功能崩溃。
测试行为:在主办方调整奖品个数的过程中,多个用户并发领奖。
此类原因分析:一些意外的修改、锁表,导致正在高负荷运行的系统崩溃。
根据测试结果,测试人员向开发设计人员提出建议如下:
- 用独立的属性记录分享、消费获得的抽奖机会。
- 通过数据库去修改抽奖次数,并判断修改结果。
- 可将高负荷查询的数据缓存起来,不必每次都去直接查询数据库。
- “当日奖项个数配置”“奖项信息”属于不同场景下修改的表,修改并发量大的表尽量独立出来,以便技术升级改造,提高性能。
3、多线程并发
1. 单线程执行
Python 的内置模块提供了两个线程模块:thread 和 threading,thread 是原生模块,threading是扩展模块,在thread的基础上进行了封装及改进。所以只需要使用threading这个模块就能完成并发的测试。
先来介绍一下如何创建线程的语法:
变量 = threading.Thread(target = 执行函数)
变量.start()以一个单线程为例,实例代码:
1 import threading
2 def test():
3 print ("I am testing code!")
4 t = threading.Thread(target=test)
5 t.start()代码说明:
1 导入threading模块。
2~3自定义test()函数,并执行打印操作。
4用threading.Thread()方法创建一个线程,然后通过target参数把test()函数放到线程之中。
5启动线程执行线程中的函数test()。
其实单线程执行的结果和单独执行某一个或者某一组函数的结果是一样的,区别只在于用线程的方式执行函数,而线程是可以同时多个一起执行的,函数是不可以同时执行的。
2. 多线程执行
前面介绍了单个线程如何使用,多个线程只需要通过循环创建多个线程,并通过循环启动执行就可以了。
实例代码:
1 import threading
2 def test():
3 print ("I am testing code!")
4 def thd():
5 Threads = []
6 for i in range(10):
7 t = threading.Thread(target=test)
8 Threads.append(t)
9 for t in Threads:
10 t.start()
11 if __name__ == "__main__":
12 thd()代码说明:
4 自定义thd()函数用来创建并执行多个线程。
5 自定义一个空的threads数组,用来存放线程组。
6~8 通过循环10次来创建10个线程,并把每一次创建的线程t装到threads数组中。
9~10 对10个线程进行循环启动。
12 执行thd()函数进行多线程的并发。
这样就通过10个线程执行了10次test()函数,但需要注意的是Python的并发并非绝对意义上的同时处理,因为启动线程是通过循环启动的,还是有先后次序的,把test()函数改成打印当时的时间。
实例代码:
1 import threading
2 from datetime import *
3 def test():
4 print (datetime.now())
5 def thd():
6 Threads = []
7 for i in range(10):
8 t = threading.Thread(target=test)
9 Threads.append(t)
10 for t in Threads:
11 t.start()
12if __name__ == "__main__":
13 thd()代码说明:
4 打印当前时间。
通过运行结果可见还是有细微的时间差异的,只是可以小的忽略不计,当然如果线程较多,就会扩大这种差异,所以实际使用中并不推荐建立太多线程来执行并发。那么如何才能优化呢?
举个例子,如果需要并发执行500次test()函数,启动500个线程会非常慢,也非常消耗资源,那就可以把500的并发拆成25个线程,每个线程再循环20次执行test()函数,这样在启动下一个线程的时候,上一个线程已经在循环执行了,以此类推,当启动第25个线程的时候,可能已经执行了200次的test()函数,这样就可以大大减少并发的时间差异。下面通过对比来看执行时间的差异。
启动500个线程执行,实例代码就把循环次数改成500。
可以算出一共花了0.16秒的时间执行500个“并发”。
然后我们改一下代码,实例代码:
# -*- coding: utf8
1 import threading
2 from datetime import *
3 def test():
4 print (datetime.now())
5 def looptest():
6 for i in range (20):
7 test()
8 def thd():
9 Threads = []
10 for i in range(25):
11 t = threading.Thread(target=looptest)
12 Threads.append(t)
13 for t in Threads:
14 t.start()
15 if __name__ == "__main__":
16 thd()可以算出一共花了0.02秒的时间执行500个“并发”。
通过这 2种方法的对比可看出时间上快了8倍,如果函数执行时间需要以秒计的话,这个差异就是显著的,所以如果有大并发量的测试,建议使用后者,这样才会更接近于同时“并发”。
3. 守护线程
多线程还有一个重要的概念,就是守护线程。在理解守护线程之前先要知道主线程和子线程的区别,之前创建的线程只是main()线程的子线程,即先启动主线程main(),然后执行thd()启动子线程。
那么什么是守护线程呢?即当主线程执行完毕之后,所有的子线程也被关闭(无论子线程是否执行完成)。默认不设置的情况下是没有守护线程的,主线程执行完毕之后,会等待子线程全部执行完毕,才会关闭结束程序。
但这样会有一个弊端,当子线程死循环了或者一直处于等待之中,则程序将不会被关闭,会被无限挂起,改一下代码,把test()函数设置为无限循环。
实例代码:
1 import threading
2 from datetime import *
3 def test():
4 x = 0
5 while (x == 0):
6 print (datetime.now())
7 def thd():
8 Threads = []
9 for i in range(10):
10 t = threading.Thread(target=test)
11 Threads.append(t)
12 for t in Threads:
13 t.start()
14 if __name__ == "__main__":
15 thd()
16 print ("end")代码说明:
3~6无限循环打印当前时间。
16 打印end作为主线程的结束标志。
因为test()函数是一个死循环的函数,当主线程执行完成后打印了 end,然后程序继续等待子线程结束,而子线程一直不会结束,所以即便主线程执行完成了,但由于子线程还在执行,则程序是不会结束,这样就无法终止程序了。
这个时候就需要对子线程设置一个守护线程强行结束子线程,守护线程通过子线程的setDaemon()方法实现,默认情况下不设置,等同于 setDaemon(Flase),如果需要设置守护线程,则需要将其改成 setDaemon (True),改一下代码。
实例代码:
1 import threading
2 from datetime import *
3 def test():
4 sleep(1)
5 x = 0
6 while (x == 0):
7 print (datetime.now())
8 def thd():
9 Threads = []
10 for i in range(10):
11 t = threading.Thread(target=test)
12 Threads.append(t)
13 t.setDaemon(True)
14 for t in Threads:
17 t.start()
16 if __name__ == "__main__":
17 thd()
18 print ("end")代码说明:
4 在执行函数之前等待1秒钟,这是为了运行结果更清晰,主线程关闭后才会关闭子线程,中间会有时间差,会看到主线程执行完毕后还有部分子线程在执行,所以加上1秒的等待就可以等待子线程的关闭了。
13在每一个子线程中加上守护线程,必须加在start()之前才有效果。
通过结果可以发现,这就像程序执行到一半强制中断程序的执行一样,看似很暴力却很有用,如果子线程发送一个请求未收到返回的结果,那不可能永远等下去,这时候就需要强制关闭。所以守护线程的意义在于处理主线程和子线程的关闭工作。
4. 阻塞线程
上一节讲到守护线程的确有点不讲道理,那有没有更柔和的方式来处理呢?其实可以通过子线程join()方法阻塞线程,让主线程等待子线程完成之后再往下执行,等主线程执行完毕后再关闭所有子线程。
把上面的代码加上join(),实例代码:
1 import threading
2 from datetime import *
3 def test():
4 sleep(1)
5 x = 0
6 while (x == 0):
7 print (datetime.now())
8 def thd():
9 Threads = []
10 for i in range(10):
11 t = threading.Thread(target=test)
12 Threads.append(t)
13 t.setDaemon(True)
14 for t in Threads:
15 t.start()
16 for t in Thread:
17 t.join()
18 if __name__ == "__main__":
19 thd()
20 print ("end")代码说明:
16~17 循环对每个子线程加上join()阻塞,必须加在start()之后。
也许有人会觉得这和什么都不设置不是一样吗?其实还是有点不一样的。什么都不设置的情况下主线程是执行完成的,仅等待子线程执行完成,所以会打印 end;而两个都设置的情况下,主线程会因为等子线程结束而不往下执行,主线程无法执行完成,自然也无法关闭子线程,所以是不会打印end的。
对于死循环/一直等待的情况,也可以通过join()的timeout参数来控制,这样就可以完美解决相互等待的情况,子线程告诉主线程让其等待2秒,2秒之内子线程完成,主线程就继续往下执行,2秒之后如果子线程还未完成,主线程也会继续往下执行,执行完成后关闭子线程,继续改代码。
实例代码:
1 import threading
2 from datetime import *
3 def test():
4 sleep(1)
5 x = 0
6 while (x == 0):
7 print (datetime.now())
8 def thd():
9 Threads = []
10 for i in range(10):
11 t = threading.Thread(target=test)
12 Threads.append(t)
13 t.setDaemon(True)
14 for t in Threads:
15 t.start()
16 for t in Thread:
17 t.join(2)
18 if __name__ == "__main__":
19 thd()
20 print ("end")运行之后发现其实一共运行了20秒,不是只设置了2秒吗?这是超时机制决定的,完成第一个线程的超时之后才会开始计算第二个线程的超时,所以执行了10个线程超时时间就是20秒。
一般来说不推荐用 timeout 参数,最好的方式还是在函数内加上超时判断,如果超过设置时间就直接退出函数,这样也等于结束了子线程,那主线程会随着子线程的结束而继续执行了。阻塞线程的意义在于控制子线程与主线程的执行顺序。
5. 并发测试框架
了解了如何通过多线程进行并发,综合上述的功能可以编写一套多线程的框架用作并发测试,这样只需要套用不同的测试函数,修改不同的参数作为并发数即可,而不再需要改多线程并发的代码。
实例代码:
1 THREAD_NUM = 1
2 ONE_WORKER_NUM =1
3 def test():
测试代码
4 def working():
5 global ONE_WORKER_NUM
6 for i in range(0,ONE_WORKER_NUM):
7 test()
8 def t():
9 global THREAD_NUM
10 Threads = []
11 for i in range(THREAD_NUM):
12 t = threading.Thread(target=working, name="T"+str(i))
13 t.setDaemon(True)
14 Threads.append(t)
15 for t in Threads:
16 t.start()
17 for t in Threads:
18 t.join()
19if __name__ == "__main__":
20 t()代码说明:
1自定义全局变量需要执行的线程数。
2自定义全局变量每个线程循环执行的数量。
这个2个变量的乘积就是最终的并发数,可以自行配置,如果只需要用线程来并发,就可以把第二个参数设置成1就行了。
3自定义需要执行的test()函数,可以是一个,也可以是多个测试函数的集合,这个根据实际情况编写。
4~6引用全局变量作为循环执行的次数,嵌套执行指定循环次数的test()函数。
8自定义t()函数作为多线程并发的函数。
9~14引用全局变量作为创建的线程数,并将working()函数放入线程之中,这样每个线程都可以执行多次test()函数,然后给所有创建的子线程设置守护线程。
15~16循环启动线程组中的所有线程。
17~18循环对线程组中的每个线程设置阻塞线程。
19~20通过主线程启动t()中的子线程。
当所有子线程结束之后,可以执行其他代码,比如对文件写入结果等。
4、接口并发测试实例
1. 测试需求分析
业务需求
活动时间:5月18日~5月25日,每天9:00~21:00。
参与方式:登录微信公众号或者手机APP。
参与资格:所有会员每日有三次机会,分享活动到朋友圈增加一次机会,当日消费最多可增加三次机会。
奖项设定:一等奖5000元现金、二等奖100元支付红包、三等奖10元支付红包、四等奖3元支付红包、五等奖谢谢参与,支付红包有效期为1周。
奖项概率:一等奖0.008%,二等奖0.05%,三等奖20%,四等奖50%,五等奖29.942%。
中奖规则:每日限定一等奖1名、二等奖20名、三等奖100名、四等奖2000名;已获得一等奖、二等奖的会员,只能抽中五等奖。
条件触发情况:若截至 15:00 仍未出现一等奖,提高一等奖中奖概率至 0.04%,同时主办方视活动实时详情增加奖品个数。
公正性保障方案:公司员工账号排除在中奖范围内,不予中任何奖项。
测试场景需求
(1)验证抽奖次数统计是否正确。
(2)验证用户抽奖次数、黑名单功能。
(3)验证抽奖概率。
(4)验证奖品数量限制。
(5)验证中奖规则。
(6)验证支付红包能否正常使用。
2. 测试方案设定
测试用例一
测试需求:验证抽奖次数统计是否正确。
预置条件:
已注册用户的抽奖次数功能正确。
每日活动结束后抽奖次数初始化功能正确。
当日新注册用户获得抽奖次数功能正确。
输入数据:已注册用户账号、当日注册用户账号。
测试场景:并发测试分享、消费场景。
测试结果:判定实际新增次数与预期新增次数是否一致。
测试用例二
测试需求:验证用户抽奖次数、黑名单功能。
预置条件:构建拥有不同次数的账号10个(包括黑名单中的员工账号)。
输入数据:10个不同的账号。
测试场景:每个账号并发10次抽奖次数请求。
测试结果:分别统计每个账号的抽奖次数是否与期望值一致。
测试用例三
测试需求:验证抽奖概率。
预置条件:
由于一等奖中奖概率为十万分之八,故使用单个账号测试中奖概率,需要做以下配置准备。
按业务场景配置中奖概率,概率需支持三位小数。
调整奖品个数各10万个。
屏蔽单个账号抽奖次数限制。
屏蔽单个账号只能中一次一等奖、二等奖限制。
输入数据:单用户账号。
测试场景:进行10轮并发,每轮1万个请求。
测试结果:验证3位小数的中奖概率是否有效,中奖个数是否符合预期。
测试用例四
测试需求:
验证奖品数量限制。
在中奖概率极高的条件下,并发测试中奖的奖品数量是否会超过每日限制。
预置条件:
调高各等奖项中奖概率,依次为70%、20%、10%、5%、0%。
调整各等奖项奖品个数,依次为2、4、6、8、10个。
屏蔽单个账号只能中一次一等奖、二等奖限制。
屏蔽单个账号抽奖次数限制。
输入数据:单用户账号。
测试场景:进行3轮并发,每轮100次抽奖请求。
测试结果:验证一等奖、二等奖中奖个数是否符合预期。
测试用例五
测试需求:验证中奖规则。
预置条件:
调高各等奖项中奖概率,依次为70%、20%、10%、5%、0%。
调整各等奖项奖品个数,依次为2、4、6、8、10个。
屏蔽单个账号抽奖次数限制。
输入数据:已获得过一等奖的用户账号、已获得二等奖的用户账号。
测试场景:进行3轮并发,每轮100次抽奖请求。
测试结果:已获一、二等奖的用户是否只能抽中五等奖。
测试用例六
测试需求:验证支付红包能否正常使用。
预置条件:构建10个拥有100元、10元、3元支付红包的账户。
输入数据:10个拥有100元、10元、3元支付红包的账户。
测试场景:单个并发使用、组合使用及支付红包过期情况下每轮20次消费请求。
测试结果:消费红包次数是否正确,红包使用或过期后是否会作废。
3. 测试代码编写
就以测试方案二验证抽奖次数为例,例如测试抽奖接口代码,然后将其封装到测试函数之中,并通过循环读取抽奖的手机号来对10个抽奖手机号执行抽奖。
首先需要把手机号输入指定的phone.txt之中,以换行作为手机号的分隔,保存测试脚本在同一个目录下面。
接着就是封装抽奖接口测试函数:
1 def choujiang():
2 url = "http://www.xxx.com/management/winningrecord/newluckDraw/"
3 for phone in open("phone.txt”):
4 form ={"phone":phone, " activityGuid ":1001}
5 response = requests.post(url,data = form)
6 print (response.text)代码说明:
1自定义choujiang()函数。
3 循环读取测试数据文件,在txt之中输入需要测试的手机号。
5 把读取的手机号赋值到form之中用于抽奖请求需要发送的数据。
6 打印抽奖接口返回的数据。
对于接口测试代码的编写就完成了。
4. 实例完整代码
完成了测试函数的编写之后,将其套用到并发测试框架之中就行了。
import threading
import requests
THREAD_NUM = 10
ONE_WORKER_NUM =10
def choujiang():
global id
url = "http://www.xxx.com/management/winningrecord/newluckDraw/"
for phone in open("phone.txt”):
form ={"phone":phone, " activityGuid ":1001}
response = requests.post(url,data=form)
print (response.text)
def working():
global ONE_WORKER_NUM
for i in range(0,ONE_WORKER_NUM):
choujiang()
def t():
global THREAD_NUM
Threads = []
for i in range(THREAD_NUM):
t = threading.Thread(target=working, name="T"+str(i))
t.setDaemon(True)
Threads.append(t)
for t in Threads:
t.start()
for t in Threads:
t.join()
if __name__ == "__main__":
t()通过结果的手机号和剩余抽奖次数,可以人工分析各种账号的抽奖次数是否正确。
5. 测试结果分析
测试人员根据测试方案执行测试后输出测试结果,提交bug以及记录在bug追踪过程中的关键信息,这个步骤可以优化测试方法,提高测试效率及更好地为项目组提供有效信息。
bug举例如下:
bug描述:意外获得了多次抽奖机会。
测试行为:一个用户同时分享、消费多次,用户获得了额外的抽奖次数。
此类原因分析:在功能设计上没有分别记录分享、消费得到的次数,使得系统在一瞬间认为该用户并未分享过,增加了多次抽奖机会。
根据测试结果,测试人员给开发设计人员提出建议如下:
- 用独立的属性记录分享、消费获得的抽奖机会。
- 通过数据库去修改抽奖次数,并判断修改结果。
- 可将高负荷查询的数据缓存起来,不必每次都去直接查询数据库。
- “当日奖项个数配置”“奖项信息”属于不同场景下修改的表,修改并发量大的表尽量独立出来,以便升级改造,提高性能。
5、订单并发性能
1. 整理并发需求
中午和晚上是订餐的高峰期,所以会有很大的并发订单量。在高峰期订单的成功率、响应速度等因素直接影响用户体验,为了保证用户能够正常下单,项目组需要测试人员对高峰期订单并发量进行并发性能测试。
从代码及业务层面来说,针对订餐接口,多个用户订餐多个餐厅与一个用户同时定同一个餐厅本质是一样的。所以测试人员可以在设定测试方案时按照测试效率选择高效的方案即可。
并发性能测试对环境及基础数据有一定要求。
不过环境和数据对性能测试的结果有着很大影响,这里还是给出主要的三点建议:
- 性能测试环境需尽量与生产环境保持一致。
- 性能测试基础数据可以根据前几年的业务数据预估获得。
- 在确定某一测试场景后,对测试执行产生的数据要有预判,方便测试数据准备。
性能指标需求如下:
- 首页打开速度<3s,订单提交成功<5s。
- 订单成功率达到99.5%以上。
- 在100个并发用户的高峰期,订单处理能力至少达到900TPS。
2. 提取性能指标
当我们能够构建测试数据完成并发场景的模拟后,就要考虑如何获取想要的指标。
以用户同时预定100个外卖订单为例,需提取的并发指标如下。
- 并发订单数
- 成功订单数
- 成功订单的响应时间
- 订单成功率
- 成功订单的总响应时间
- 成功订单的平均响应时间
- Tps
根据上面需要提取的指标分析一下如何提取数据。
并发订单数就是自定义的并发数,因为请求的时间较长,所以可以分成10个线程,每个线程循环10次来达到100个并发。
成功订单数就是获取响应值为成功的请求,先定义一个全局变量 success_count 为 0,然后在请求响应结果之中通过断言判断响应数据是否为成功,成功的话执行+1,因为断言的机制是判断为失败时中断下面的程序执行,所以只有通过断言之后才会计数到成功数。
在请求之前获取一下时间,在断言判断为成功之后再获取一下时间,2者相减得到成功订单的响应时间。
订单成功率只需要把成功的success_count值除以初始化并发的值就可以了。
成功订单的总响应时间为每个成功订单的响应时间之和,也需要定义一个全局变量sum_time为0.00,把每次的成功响应时间加上去,就是总响应时间了。
成功订单的平均响应时间就是把成功订单的总响应时间除以成功订单数。
Tps按照公式算出来就行了,成功并发数/成功订单的平均响应时间。
3. 测试代码编写
分析完成之后接着可以进行代码的编写了。
先初始化几个全局变量:
1 THREAD_NUM = 10
2 ONE_WORKER_NUM = 10
3 sum_time = 0.00
4 success_count = 0然后编写订单的发送请求代码,其实只需要把前面自动化测试代码复制过来合并,然后把相应的地方做一下改动即可。
省略登录代码
1def order():
2 global c
3 global sum_time
4 global success_count
5 t1 = time()
省略订单提交测试代码
6 assert res == "success"
7 print ("订餐成功")
8 t2 = time()
9 res_time = t2-t1
10 result = open("G:\\python\\res.txt", "a")
11 result.write("成功订单响应时间:"+str(res_time)+"\n")
12 result.close()
13 sum_time = sum_time+res_time
14 success_count = success_count+1代码说明:
2 引用全局变量c,这是登录后获取的cookie,用于提交订单发送的cookie。
3~4 引用全局变量sum_time和success_count,用作成功订单总响应时间和成功订单数的累加计算。
5 获取执行发送订单请求前时间,为什么要用 time(),而不用 datetime.now()呢?因为datetime.now()的数据类型不是数值,虽然两个时间可以用来做减法运算,但得到时间差值依旧不是数值,不能用来做加法运算,所以计算总响应时间的时候因为类型的原因无法累加,有兴趣的话可以去试一下,这里不详细介绍了。
6 通过断言判断订单是否成功,如果失败的话就中断执行函数下面所有的程序,这个意义就在于不让失败的订单累加到成功订单数之中。
8 获取执行订单成功之后的时间。
9 通过运算算出发送订单请求到订单成功后的时间,即成功订单的响应时间,并赋值给变量res_time。
10~12 把响应时间写入res.txt文件。
13 把每次成功订单的响应时间累加到全局变量sum_time之中。
14 把每次成功订单数累加到全局变量success_count之中。
注意事项如下:
- 因为响应时间是数字,而写入文件的时候只能写字符串类型,所以需要把最后的数字通过str()函数进行转化。
- 因为写入的时候不会换行,所以每写入一行内容后需要加上"\n"换行符,这样就不会连在一起了。
主线程在子线程完成之后,再把需要的数据写入到rex.txt文件之中:
1 result = open("G:\\python\\res.txt", "a")
2 result.write("并发订单数:"+str(THREAD_NUM*ONE_WORKER_NUM)+"\n")
3 result.write("成功订单数:"+str(success_count)+"\n")
4 result.write("订单成功率:"+str(success_count/(THREAD_NUM*ONE_WORKER_NUM)*100)+"%"+"\n")
5 result.write("成功订单总响应时间:"+str(sum_time)+"\n")
6 result.write("成功平均响应时间:"+str(sum_time/success_count)+"\n")
7 result.write("tps:"+str((success_count)/(sum_time/success_count))+"\n")
8 result.close()这样就完成整个代码的编写了。
4. 实例完整代码
import hashlib
import threading
from time import *
from datetime import datetime
import requests
import json
THREAD_NUM = 10
ONE_WORKER_NUM = 10
sum_time = 0.00
success_count = 0
username = "13999999999"
password = hashlib.md5(b'123456').hexdigest()
url ="http://www.xxx.com/ajax/user_login/"
form_data = {"username":username,"password":password}
login_response = requests.post(url, data = form_data)
c = login_response.cookies
def order():
global c
global sum_time
global success_count
t1 = time()
url1 = "http://www.xxxx.com/ajax/create_order/"
form_data1 = {"restaurant_id":11196, "menu_items_total":"12.00",
"menu_items_data":" [{'id':1653196,'p':2, 'q':6 }]",
"delivery_fee":"3.00"}
make_response = requests.post(url, data = form_data1,cookies = c)
res = make_response.text
id=json.loads(res)["order_id"]
assert id!= ""
time = datetime.now()+timedelta(hours=1)
url2 = "http://www.xxxx.com/ajax/place_order/"
form_data2 = {"order_id":id,"customer_name":"xxxx",
"mobile_number":username, "delivery_address":"xxxxxxx",
"preorder":"yes", "preorder_time":time, "pay_type":"cash"}
place_response = requests.post(url2,data = form_data2,cookies = c)
res = place_response.text
assert res == "success"
print ("订餐成功")
t2 = time()
res_time = t2-t1
result = open("G:\\python\\res.txt", "a")
result.write("成功订单响应时间:"+str(res_time)+"\n")
result.close()
sum_time = sum_time+res_time
success_count = success_count+1
def working():
global ONE_WORKER_NUM
for i in range(0,ONE_WORKER_NUM):
order()
def main():
global THREAD_NUM
Threads = []
for i in range(THREAD_NUM):
t = threading.Thread(target=working, name="T"+str(i))
t.setDaemon(True)
Threads.append(t)
for t in Threads:
t.start()
for t in Threads:
t.join()
if __name__ == "__main__":
main()
result = open("G:\\python\\res.txt", "a")
result.write("并发订单数:"+str(THREAD_NUM*ONE_WORKER_NUM)+"\n")
result.write("成功订单数:"+str(success_count)+"\n")
result.write("订单成功率:"+str(success_count/(THREAD_NUM*ONE_WORKER_NUM)*100)
+"%"+"\n")
result.write("成功订单总响应时间:"+str(sum_time)+"\n")
result.write("成功平均响应时间:"+str(sum_time/success_count)+"\n")
result.write("tps:"+str((success_count)/(sum_time/success_count))+"\n")
result.close()
测试结果数据满足性能测试需求,故测试通过。
6、WebSocket并发
1. 整理并发需求
同样是外卖平台,除了用户请求的并发量大之外,对于餐厅老板的并发量也很大。而餐厅老板的订单通知则是通过WebSocket来发送的,获取订单通知之前需要建立WebSocket连接,所以需要通过并发来测试客户端对服务器的WebSocket并发的连接成功率。
2. 提取性能指标
这个案例的场景相对来说就没那么复杂了,仅仅是测试WebSocket并发连接的成功率。
以客户端向服务器发送100个并发的WebSocket请求为例,需提取的并发指标如下。
- 连接数
- 成功连接数
- 成功连接率
根据上面的需要提取指标分析一下如何提取数据。
连接数就是自定义的并发,因为请求简单而且执行得比较快,所以直接可以用 100 个线程并发,而不需要再加上循环来处理。
成功连接数就是获取WebSocket的响应数,先定义一个全局变量success_count为0,然后在线程之中只需要在获取响应之后执行+1,这样每成功连接一次success_count就会+1,最后就能获取到成功数。
成功连接率只需要把成功连接数除以初始化并发的连接数就可以了。
3. 测试代码编写
分析完成之后接着可以进行代码的编写了。
先初始化几个全局变量:
1 THREAD_NUM = 100
2 ONE_WORKER_NUM = 1
3 count = 0然后编写WebSocket的连接请求。
1 def websockettest():
2 global count
3 url = " ws://www.xxx.com/serv/push?channel=delivery "
4 ws=websocket.create_connection(url)
5 ws.send("{'type': 'heartbeat', 'username': '13111111111','message': 'ok'}\n")
6 msg = ws.recv()
7 success_count = success_count+1代码说明:
1 自定义websocket()函数。
2 引用全局变量count。
3~6 发送WebSocket的连接请求。
7 当收到请求的响应结果后,count成功数+1。
这里其实会有一个问题,WebSocket的响应是阻塞的,如果连接未成功,则会一直等待响应,那就无法往下执行了,所以这里需要用到阻塞线程的超时参数,当线程1秒内未结束,则继续执行主线程,主线程执行结束后关闭所有子线程,既关闭了子线程,count数也不会增加,这样就获取到实际连接成功的数量了。
最后就是套用并发的测试框架了,但有几个地方还需要改一下。
join()中的超时时间。
主线程在子线程完成之后,再把需要的数据写入res.txt文件之中。
1 result = open("G:\\python\\res.txt", "a")
2 result.write("发起连接数:"+str(THREAD_NUM)+"\n")
3 result.write("成功连接数:"+str(success_count)+"\n")
4 result.write("成功率:"+str(success_count/THREAD_NUM*100)+"%"+"\n")
5 result.close()这样就完成整个代码的编写了。
4. 实例完整代码
#coding=utf-8
import threading
import websocket
THREAD_NUM = 100
ONE_WORKER_NUM = 1
success_count = 0
def websockettest():
global success_count
url = " ws://staging.djlajfjkd.com:23461/serv/push?channel=delivery "
ws=websocket.create_connection(url)
ws.send("{'type': 'heartbeat', 'username': '13111111111','message': 'ok'}\n")
msg = ws.recv()
success_count = success_count+1
def working():
global ONE_WORKER_NUM
for i in range(0,ONE_WORKER_NUM):
websockettest()
def t():
Threads = []
for i in range(THREAD_NUM):
t = threading.Thread(target=working, name="T"+str(i))
t.setDaemon(True)
Threads.append(t)
for t in Threads:
t.start()
for t in Threads:
t.join(1)·
print("main thread end")
if __name__ == "__main__":
t()
result = open("G:\\python\\res.txt", "a")
result.write("发起连接数:"+str(THREAD_NUM)+"\n")
result.write("成功连接数:"+str(success_count)+"\n")
result.write("成功率:"+str(success_count/THREAD_NUM*100)+"%"+"\n")
result.close()运行完成后打开res.txt文件:

十二、性能监控
1、InfluxDB
1. InfluxDB简介
什么是 InfluxDB ?
-
InfluxDB 是一个由 InfluxData 开发的,开源的时序型数据库。它由 Go 语言写成,着力于高性能地查询与存储时序型数据。
-
InfluxDB 被广泛应用于存储系统的监控数据、IoT 行业的实时数据等场景。
-
可配合 Telegraf 服务(Telegraf 可以监控系统 CPU、内存、网络等数据)。
-
可配合 Grafana 服务(数据展现的图像界面,将 InfluxDB 中的数据可视化)。
-
InfluxDB 官网
什么是时序数据?
时间序列数据(TimeSeries Data):按照时间顺序记录系统、设备状态变化的数据被称为时序数据。其应用场景很多,如:
- 无人驾驶车辆运行中要记录的经度、纬度、速度、方向、旁边的距离等。
- 某一地区的各车辆的行驶轨迹数据。
- 传统证券行业实时交易数据。
- 实时运维监控数据等。
时序数据特点:
- 性能好:关系型数据库对于大规模数据的处理性能糟糕,而 NoSQL 可以比较好地处理大规模数据,但依然比不上时间序列数据库。
- 存储成本低:高效的压缩算法,节省存储空间,有效降低 I/O 。
2. 数据存储结构
与 MySQL 的基础概念对比:
| 概念 | MySQL | InfluxDB |
|---|---|---|
| 数据库(同) | database | database |
| 表(不同) | table | measurement |
| 列(不同) | column | tag(带索引的,非必须)、field(不带索引)、timestemp(唯一主键) |
-
tag set:不同的每组 tag key 和 tag value 的集合。
-
field set:每组 field key 和 field value 的集合。
-
retention policy:数据存储策略(默认策略为 autogen)InfluxDB 没有删除数据操作,规定数据的保留时间达到清除数据的目的。
-
series:共同 retention policy、measurement 和 tag set 的集合。
示例数据:
- census 是 measurement
- butterflies 和 honeybees 是 field key
- location 和 scientist 是 tag key
name: census
————————————
time butterflies honeybees location scientist
2015-08-18T00:00:00Z 12 23 1 langstroth
2015-08-18T00:00:00Z 1 30 1 perpetua
2015-08-18T00:06:00Z 11 28 1 langstroth
2015-08-18T00:06:00Z 11 28 2 langstroth注意点:
- tag 只能为字符串类型。
- field 类型无限制。
- 不支持 join。
- 支持连续查询操作(汇总统计数据):CONTINUOUS QUERY。
3. 部署
新建容器网络:
docker network create grafana运行容器:
docker run -d --name=influxdb --network grafana -p 8086:8086 -v ${PWD}/influxdb/:/var/lib/influxdb influxdb:1.7.10创建数据库:
- 第一种方式:
curl -i -XPOST http://localhost:8086/query --data-urlencode "q=CREATE DATABASE jmeter" - 第二种方式:
docker exec -it influxdb influx
简单使用:
create database jmeters;
use jmeter;
show measurements;
select * from jmeter limit 3;4. 常用InfluxQL
-- 查看所有的数据库
show databases;
-- 使用特定的数据库
use database_name;
-- 查看所有的 measurement
show measurements;
-- 查询 10 条数据
select * from measurement_name limit 10;
-- 数据中的时间字段默认显示的是一个纳秒时间戳,改成可读格式
precision rfc3339; -- 之后再查询,时间就是 rfc3339 标准格式
-- 或可以在连接数据库的时候,直接带该参数
influx -precision rfc3339
-- 查看一个 measurement 中所有的 tag key
show tag keys
-- 查看一个 measurement 中所有的 field key
show field keys
-- 查看一个 measurement 中所有的保存策略(可以有多个,一个标识为 default)
show retention policies;
2、Grfana
1. Grfana简介
Grafana(官网)是一个跨平台的、开源的度量分析和可视化工具,可以通过将采集的数据查询然后可视化的展示,并及时通知。
它主要有以下六大特点:
- 展示方式:快速灵活的客户端图表,面板插件有许多不同方式的可视化指标和日志,官方库中具有丰富的仪表盘插件,比如热图、折线图、图表等多种展示方式;
- 支持多种数据源:Graphite、InfluxDB、OpenTSDB、Prometheus、Elasticsearch、CloudWatch 和 KairosDB 等;
- 通知提醒:以可视方式定义最重要指标的警报规则,Grafana 将不断计算并发送通知,在数据达到阈值时通过 Slack、PagerDuty 等获得通知;
- 混合展示:在同一图表中混合使用不同的数据源,可以基于每个查询指定数据源,甚至自定义数据源;
- 注释:使用来自不同数据源的丰富事件注释图表,将鼠标悬停在事件上会显示完整的事件元数据和标记;
- 过滤器:Ad-hoc 过滤器允许动态创建新的键/值过滤器,这些过滤器会自动应用于使用该数据源的所有查询。
2. Grfana基础
1)Data Source
- Grafana 确切的说是一个前端展示工具,将数据以非常美观直接的图形展示出来。那么这些数据必须有一个来源吧,那么 Grafana 获取数据的地方就称为 Data Source。
- 官方文档上说 Grafana 支持以下数据源:Graphite、InfluxDB、OpenTSDB、Prometheus、Elasticsearch、CloudWatch。
- 在 Grafana 3.0+ 之后,不仅支持上面说的这些数据源,还支持一些其它的数据源,这些就称为 Grafana Plugins。Grafana 支持的插件非常多,只要做一些简单的插件安装配置,就能获取丰富的数据源。
如下所示,添加数据源:
2)DashBoard
- 就像汽车仪表盘一样可以展示很多信息,包括车速、水箱温度等。Grafana 的 DashBoard 就是以各种图形的方式来展示从 Datasource 拿到的数据。
- 添加仪表盘的示例步骤:
如搜索 jmeter 仪表盘:

选择对应的仪表盘 ID :
复制ID,填入导入界面(导入时需要选择用户组以及对应的数据库):

展示仪表盘(右上角可以选择数据展示的时间段和刷新频次):
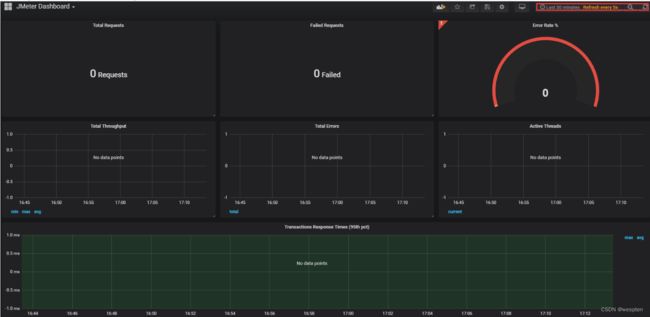
3)Row
- Row 是 DashBoard 的基本组成单元,一个 DashBoard 可以包含很多个 Row 。
- 一个 Row 可以展示一种信息或者多种信息的组合,比如系统内存使用率,CPU 五分钟及十分钟平均负载等。所以在一个 DashBoard 上可以集中展示很多内容。
4)Panel
- Panel(面板)实际上就是 Row 展示信息的方式,支持表格(table)、列表(alert list)、热图(Heatmap)等多种方式,具体可以去官网上查阅。
5)Query Editor
- 用来指定获取哪一部分数据,类似于 SQL 查询语句。比如要在某个 row 里面展示 test 这张表的数据,那么 Query Editor 里面就可以写成 select * from test。
- 这只是一种比方,实际上每个 DataSource 获取数据的方式都不一样,所以写法也不一样,比如像 zabbix 数据则是以指定某个监控项的方式来获取的。
6)Organization
- org 是一个很大的概念,每个用户可以拥有多个 org,grafana 有一个默认的 main org 。
- 用户登录后可以在不同的 org 之间切换,前提是该用户拥有多个 org 。
- 不同的 org 之间完全不一样,包括 datasource、dashboard 等都不一样。
- 创建一个 org 就相当于开了一个全新的视图,所有的 datasource、dashboard 等都要再重新开始创建。
7)User
- Grafana 里面用户有三种角色:admin、editor、viewer。
- admin 权限最高,可以执行任何操作,包括创建用户、新增 Datasource、创建 DashBoard 等。
- editor 角色不可以创建用户、不可以新增 Datasource、可以创建 DashBoard 。
- viewer 角色仅可以查看 DashBoard 。
- 在 2.1 版本及之后新增了一种角色 read only editor(只读编辑模式),这种模式允许用户修改 DashBoard,但是不允许保存。
- 每个 user 可以拥有多个 organization 。
3. 部署
运行容器:
docker run -d --name grafana --network grafana -p 3000:3000 grafana/grafana:6.6.2
默认登录账号密码为 admin/admin 。
3、Jmeter+InfluxDB压测结果采集
Jmeter 自带的监视器在 Windows 使用 GUI 模式运行时,其渲染和效果都不是太好,而在 linux 环境下又无法实时可视化。
因此如果有一个性能测试结果实时展示的页面,就可以提升我们对系统性能表现的掌握程度,另一方面也可以提升我们的测试效率。
Grafana 添加 InfluxDB 数据源:


配置项:
- URL:http://influxdb:8086:由于 grafana 和 influxdb 在在同个容器网络中,因此可直接填写【influxdb容器名:端口号】。
- Database:jmeter:在 influxdb 中创建的数据库名。
- Min time interval:5:每 5 秒刷新一次数据源(这里是与 jmeter backend listener 每 5 秒写入一次数据到 influxdb 保持同步)。

Grafana 创建 Jmeter 仪表盘:

导入 Grafana 官方 Jmeter 仪表盘:Apache JMeter Dashboard using Core InfluxdbBackendListenerClient | Grafana Labs

填写自定义配置:
仪表盘创建成功:

Jmeter 配置 Influxdb 监听器:

配置项说明:
- influxdbUrl:http://192.168.3.222:8086/write?db=jmeter:influxdb 服务器地址以及写入的数据库。
- application:app_1自定义应用名称,可在 grafana 仪表盘中筛选区分。
- measurement:jmeter:influxdb 表名,默认为 jmeter(写入数据时会自动创建该表)。
- summaryOnly:false:在 grafana 仪表盘中显示详细 Error 信息。
- testTitle:test_demo_1:在 influxdb 表数据中作区分。
查看写入的 Influxdb 表数据:
[root@localhost ~]# docker exec -it influxdb influx
Connected to http://localhost:8086 version 1.7.10
InfluxDB shell version: 1.7.10
> show measurements;
name: measurements
name
----
events
jmeter
>
> select * from jmeter limit 3;
name: jmeter
time application avg count countError endedT hit max maxAT meanAT min minAT pct90.0 pct95.0 pct99.0 rb responseCode responseMessage sb startedT statut transaction
---- ----------- --- ----- ---------- ------ --- --- ----- ------ --- ----- ------- ------- ------- -- ------------ --------------- -- -------- ------ -----------
1658844069082000000 app_1 0 0 0 0 1 internal
1658844074048000000 app_1 34.9375 16 42 30 41.3 42 42 39952 1872 all Single Request
1658844074050000000 app_1 34.9375 16 42 30 41.3 42 42 ok Single Request
>
> select * from events;
name: events
time application text title
---- ----------- ---- -----
1658844069036000000 app_1 test_demo_1 started ApacheJMeter
1658844215777000000 app_1 test_demo_1 ended ApacheJMeter
查看仪表盘展示:
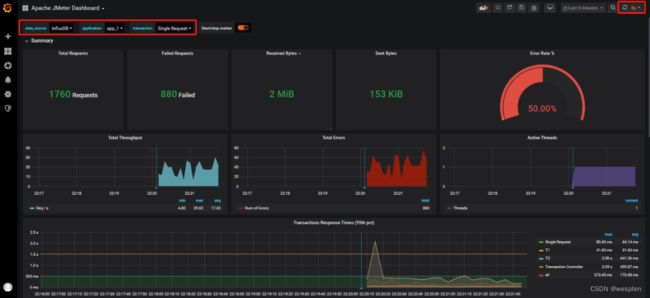
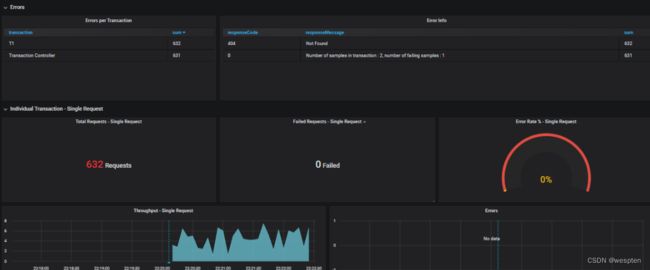
4、Prometheus
1. Prometheus简介
Prometheus(官网)是一套开源的监控&报警&时序数据库的组合,适合监控 Docker 容器。因为 Kubernetes 的流行带动了 Prometheus 的发展
Prometheus 是最初在 SoundCloud 上构建的开源系统监视和警报工具包,该项目拥有非常活跃的开发人员和用户社区。现在,它是一个独立的开源项目,并且独立于任何公司进行维护。为了强调这一点并阐明项目的治理结构,Prometheus 于 2016 年加入了 Cloud Native Computing Foundation,这是继 Kubernetes 之后的第二个托管项目。
Prometheus 优点:
- 非常少的外部依赖,安装使用超简单。
- 已经有非常多的系统集成,例如:docker、HAProxy、Nginx、JMX 等等。
- 服务自动化发现。
- 直接集成到代码。
- 设计思想是按照分布式、微服务架构来实现的。
Prometheus 特性:
- 多维度数据模型。
- 提供灵活的查询语言(PromQL)。
- 不依赖分布式存储,单个服务器节点是自主的。
- 以 HTTP 方式,通过 Pull 模型拉取时间序列数据。
- 也可以通过中间网关支持 Push 模型。
- 通过服务发现或者静态配置,来发现目标服务对象。
- 支持多种多样的图标和界面展示。
Prometheus 生态系统:
Prometheus 生态系统包含多个组件,其中许多是可选的。且大多数 Prometheus 组件都是用 Go 编写的,因此易于构建和部署为静态二进制文件。
- Prometheus server:它会抓取并存储时间序列数据。
- client libraries:用于检测应用程序代码。
- push gateway:一个支持短期工作的推送网关。
- 诸如 HAProxy、StatsD、Graphite 等服务的专用输出端。
- 一个 alertmanager 处理警报。
- 各种支持工具。
Prometheus 应用场景:
什么时候适合?
- Prometheus 可以很好地记录任何纯数字时间序列。它既适用于以机器为中心的监视,也适用于高度动态的面向服务的体系结构的监视。在微服务世界中,它对多维数据收集和查询的支持是一种特别的优势。
- Prometheus 的设计旨在提高可靠性,使其成为中断期间要使用的系统,以使你能够快速诊断问题。每个 Prometheus 服务器都是独立的,而不依赖于网络存储或其他远程服务。当基础结构的其他部分损坏时,你可以依靠它,并且无需设置广泛的基础结构即可使用它。
什么时候不适合?
- 普罗米修斯重视可靠性。即使在故障情况下也始终可以查看有关系统的可用统计信息。如果你需要 100% 的准确性(例如按请求计费),则 Prometheus 并不是一个好的选择,因为所收集的数据可能不够详细和完整。在这种情况下,最好使用其他系统来收集和分析数据以进行计费,并使用 Prometheus 进行其余的监视。
2. Prometheus 原理架构图
下图说明了 Prometheus 的体系结构及其某些生态系统组件。
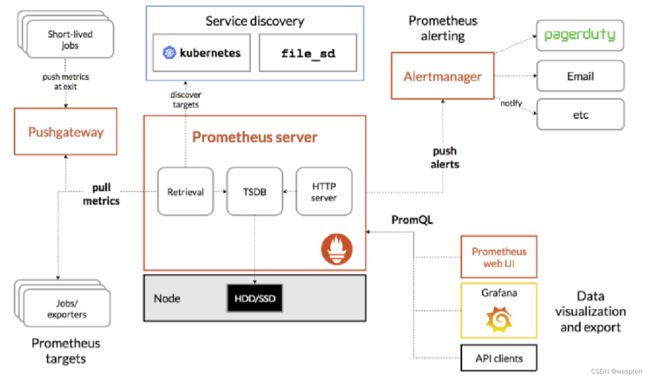
Prometheus 直接或通过中介推送网关从已检测作业中删除指标,以处理短暂的作业。它在本地存储所有报废的样本,并对这些数据运行规则,以汇总和记录现有数据中的新时间序列,或生成警报。Grafana 或其他 API 使用者可以用来可视化收集的数据。
3. 部署
配置文件:
https://github.com/prometheus/prometheus/blob/master/documentation/examples/prometheus.yml运行容器:
docker run -d --name prometheus --network grafana -p 9090:9090 -v ${PWD}/prometheus.yml:/etc/prometheus/prometheus.yml prom/prometheus:v2.16.0 --config.file=/etc/prometheus/prometheus.ymlWeb 访问 Prometheus:查看默认监控目标:
实时抓取监控数据,并存储在 Prometheus 数据库中:
5、Prometheus+Grfana主机性能采集
1. node_exporter
Prometheus 提供了各种监控 Agent,这里以主机性能监控【node_exporter】为例。
下载解压 node_exporter:

# 根据系统选择对应的下载包
[root@localhost prometheus]# wget https://github.com/prometheus/node_exporter/releases/download/v1.3.1/node_exporter-1.3.1.linux-amd64.tar.gz
[root@localhost prometheus]# tar -zxvf node_exporter-1.3.1.linux-amd64.tar.gz
node_exporter-1.3.1.linux-amd64/
node_exporter-1.3.1.linux-amd64/LICENSE
node_exporter-1.3.1.linux-amd64/NOTICE
node_exporter-1.3.1.linux-amd64/node_exporter
gzip: stdin: unexpected end of file
tar: Unexpected EOF in archive
tar: Unexpected EOF in archive
tar: Error is not recoverable: exiting now
[root@localhost prometheus]# ls
node_exporter-1.3.1.linux-amd64 node_exporter-1.3.1.linux-amd64.tar.gz prometheus.yml
[root@localhost prometheus]# cd node_exporter-1.3.1.linux-amd64/
[root@localhost node_exporter-1.3.1.linux-amd64]# ls
LICENSE node_exporter NOTICE
启动 node_exporter:
# 查看启动参数
[root@localhost prometheus]# ./node_exporter --help
# 自定义启动端口,且限定访问IP
[root@localhost prometheus]# nohup ./node_exporter --web.listen-address="192.168.3.222:9102" &
# 不限定访问IP
[root@localhost prometheus]# nohup ./node_exporter --web.listen-address=":9102" &修改 Prometheus 配置文件,添加 node_exporter 配置:

重启容器:
docker restart prometheus
监控添加成功:

Grafana 添加 Prometheus 数据源:

Grafana 导入 node_exporter 仪表盘:

导入 Grafana 官方 node_exporter 仪表盘:1 Node Exporter Dashboard 22/04/13 ConsulManager自动同步版 | Grafana Labs

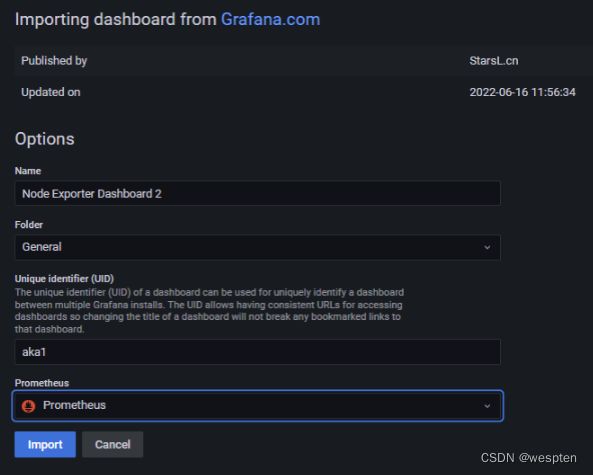
仪表盘导入成功:
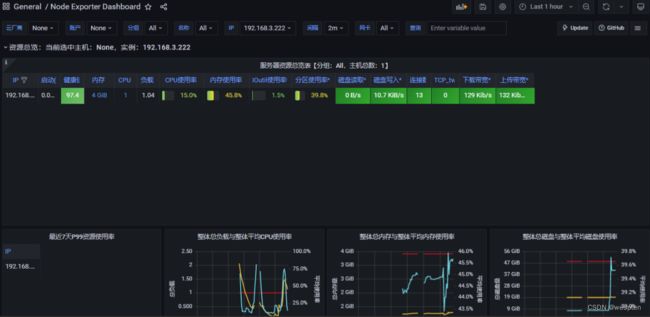
6、SkyWalking应用性能监控
1. SkyWalking简介
SkyWalking 是一款优秀的 APM 工具(Application Performance Monitoring,应用性能监控),专为微服务、云原生架构和基于容器(Docker、K8S、Mesos)的架构而设计,包含了分布式追踪、性能指标分析和服务依赖分析等功能。
更详细介绍
2. SkyWalking 搭建
1)平台后端(Backend)
官方:How to use the Docker images
docker run --name oap -d -p 1234:1234 -p 11800:11800 -p 12800:12800 apache/skywalking-oap-server
如下表示搭建成功:
2)平台前端(UI)
官方:UI(旧版)
# 新版 UI(Booster UI)暂无 docker 镜像,因此以旧版为示例
docker run --name oap-ui -d -p 10800:8080 --link oap:oap -e SW_OAP_ADDRESS=http://oap:12800 apache/skywalking-ui如下表示搭建成功:

3. Java Agent(Java 应用监控)
1)Java Agent 下载
官方:Setup java agent
curl -LO https://dlcdn.apache.org/skywalking/java-agent/8.11.0/apache-skywalking-java-agent-8.11.0.tgz
- 其他各类 Agent 下载
2)Java 演练项目
演练项目:GitHub - spring-projects/spring-petclinic: A sample Spring-based application
- 至少需要 Java11
[root@localhost skywalking]# cd spring-petclinic-main/
[root@localhost spring-petclinic-main]# ls
build.gradle gradle gradlew.bat mvnw pom.xml settings.gradle
docker-compose.yml gradlew LICENSE.txt mvnw.cmd readme.md src
[root@localhost spring-petclinic-main]# mvn clean package
启动项目并监控:
[root@localhost spring-petclinic-main]# pwd
/root/skywalking/spring-petclinic-main
[root@localhost spring-petclinic-main]# java -javaagent:/root/skywalking/skywalking-agent/skywalking-agent.jar -DSW_AGENT_NAME=petclinic_demo -DSW_AGENT_COLLECTOR_BACKEND_SERVICES=192.168.3.222:11800 -jar target/spring-petclinic-2.7.0-SNAPSHOT.jar访问演练项目:

4. SkyWalking 监控
成功加载应用监控数据:
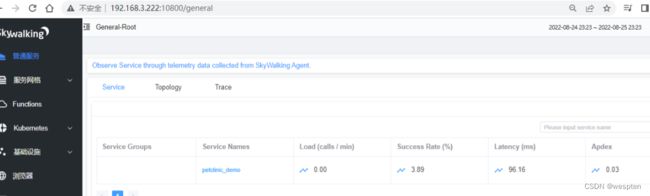
应用监控概览:
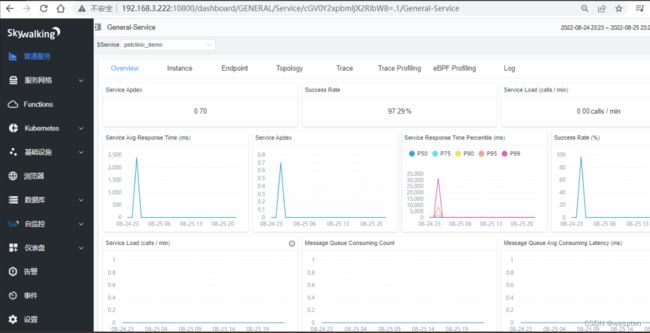
应用使用的链路追踪:

应用使用的相关 SQL:
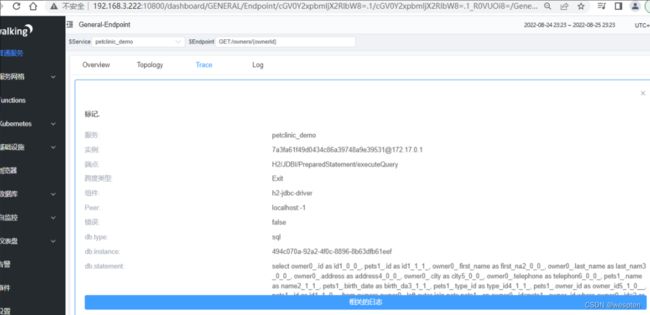
十三、性能调优
1、性能瓶颈概率分表
在实际的性能测试中,会遇到各种各样的问题,比如 TPS 压不上去等,导致这种现象的原因有很多,测试人员应配合开发人员进行分析,尽快找出瓶颈所在。
理想的性能测试指标结果可能不是很高,但一定是平缓的。
60%:数据库瓶颈
- 数据库服务器 CPU 使用率高(慢查询、SQL 过多、连接数过多)
- 抛出连接数过多(连接池设置太小,导致连接排队)
- 数据库出现死锁
25%:应用瓶颈
- 应用出现内存泄露
- 应用出现线程竞争/死锁
- 程序代码的算法复杂度
- 中间件、第三方应用出现异常
- 计算密集型任务引起 CPU 负载高
- I/O 密集型任务引起 I/O 负载高
10%:压测工具瓶颈
- JMeter 单机负载能力有限,如果需要模拟的用户请求数超过其负载极限,也会导致 TPS 压不上去
5%:Linux 机器出现异常
- Linux 可用内存无法回收(开销速率大于回收速率)
2、性能瓶颈调优步骤
-
确定问题:根据性能监控的数据和性能分析的结果,确定性能存在的问题。
-
确定原因:确定问题之后,对问题进行分析,找出问题的原因。
-
确定解决方案(改服务器参数配置/增加硬件资源配置/修改代码)。
-
验证解决方案,分析调优结果。
注意:性能测试调优并不是一次完成的过程,针对同一个性能问题,上述步骤可能要经过多次循环才能最终完成性能调优的目标,即:测试发现问题 -> 找原因 -> 调整 -> 验证 -> 分析 -> 再测试 ...
3、系统资源
-
CPU
- 监控内容:CPU 使用率、CPU 使用类型(用户进程、内核进程)
- 瓶颈分析:CPU已压满(接近 100%),需要再看其他指标的拐点所出现的时刻是否与 CPU 压满的时刻基本一致。
-
内存
- 监控内容:实际内存、虚拟内存
- 瓶颈分析:内存不足时,操作系统会使用虚拟内存,从虚拟内存读取数据,影响处理速度。
-
磁盘 I/O
- 监控内容:I/O 速度、磁盘等待队列
- 瓶颈分析:磁盘 I/O 成为瓶颈时,会出现磁盘I/O繁忙,导致交易执行时在 I/O 处等待。
-
网络
- 监控内容:网络流量(带宽使用率)、网络连接状态
- 瓶颈分析:如果接口传递的数据包过大,超过了带宽的传输能力,就会造成网络资源竞争, 导致 TPS 上不去。
发现了瓶颈后,只要对症下药就可以了。简单来说无论哪个地方出现瓶颈,只需要降低压力或者增加这部分瓶颈资源(应用软件没有瓶颈或优化空间之后),即可缓解症状。
- CPU 瓶颈:增加 CPU 资源。
- 内存瓶颈:增加内存、释放缓存。
- 磁盘 I/O 瓶颈:更换性能更高的磁盘(如固态 SSD)。
- 网络带宽瓶颈;增加网络带宽。
1. CPU
后台服务的所有指令和数据处理都是由 CPU 负责,服务对 CPU 的利用率对服务的性能起着决定性的作用。
top 参数详解:
下面以 top 命令的输出例,对 CPU 各项主要指标进行说明:

-
us(user):运行(未调整优先级的)用户进程所消耗的 CPU 时间的百分比。
-
像 shell 程序、各种语言的编译器、数据库应用、web 服务器和各种桌面应用都算是运行在用户地址空间的进程。
-
这些程序如果不是处于 idle 状态,那么绝大多数的 CPU 时间都是运行在用户态。
-
-
sy(system):运行内核进程所消耗的 CPU 时间的百分比。
-
所有进程要使用的系统资源都是由 Linux 内核处理的。当处于用户态(用户地址空间)的进程需要使用系统的资源时,比如需要分配一些内存、或是执行 I/O 操作、再或者是去创建一个子进程,此时就会进入内核态(内核地址空间)运行。事实上,决定进程在下一时刻是否会被运行的进程调度程序就运行在内核态。
-
对于操作系统的设计来说,消耗在内核态的时间应该是越少越好。通常 sy 比例过高意味着被测服务在用户态和系统态之间切换比较频繁,此时系统整体性能会有一定下降。
-
在实践中有一类典型的情况会使 sy 变大,那就是大量的 I/O 操作,因此在调查 I/O 相关的问题时需要着重关注它。 -
大部分后台服务使用的 CPU 时间片中 us 和 sy 的占用比例是最高的。同时这两个指标又是互相影响的,us 的比例高了,sy 的比例就低,反之亦然。 -
另外,在使用多核 CPU 的服务器上,CPU 0 负责 CPU 各核间的调度,CPU 0 上的使用率过高会导致其他 CPU 核心之间的调度效率变低。因此测试过程中需要重点关注 CPU 0。
-
-
ni(niced):用做 nice 加权的进程分配的用户态 CPU 时间百分比。
- 每个 Linux 进程都有个优先级,优先级高的进程有优先执行的权利,这个叫做 pri。进程除了优先级外,还有个优先级的修正值。这个修正值就叫做进程的 nice 值。
- 这里显示的 ni 表示调整过 nice 值的进程消耗掉的 CPU 时间。如果系统中没有进程被调整过 nice 值,那么 ni 就显示为 0。
- 一般来说,被测服务和服务器整体的 ni 值不会很高。如果测试过程中 ni 的值比较高,需要从服务器 Linux 系统配置、被测服务运行参数查找原因。
-
id(idle):空闲的 CPU 时间百分比。
-
一般情况下, us + ni + id 应该接近 100%。
-
线上服务运行过程中,需要保留一定的 id 冗余来应对突发的流量激增。
-
在性能测试过程中,如果 id 一直很低,吞吐量上不去,需要检查被测服务线程/进程配置、服务器系统配置等。
-
-
wa(I/O wait):CPU 等待 I/O 完成时间百分比。
-
和 CPU 的处理速度相比,磁盘 I/O 操作是非常慢的。有很多这样的操作,比如:CPU 在启动一个磁盘读写操作后,需要等待磁盘读写操作的结果。在磁盘读写操作完成前,CPU 只能处于空闲状态。
-
Linux 系统在计算系统平均负载时会把 CPU 等待 I/O 操作的时间也计算进去,所以在我们看到系统平均负载过高时,可以通过 wa 来判断系统的性能瓶颈是不是过多的 I/O 操作造成的。 -
磁盘、网络等 I/O 操作会导致 CPU 的 wa 指标提高。通常情况下,网络 I/O 占用的 wa 资源不会很高,而频繁的磁盘读写会导致 wa 激增。 -
如果被测服务不是 I/O 密集型的服务,那需要检查被测服务的日志量、数据载入频率等。
-
如果 wa 高于 10% 则系统开始出现卡顿;若高于 20% 则系统几乎动不了;若高于 50% 则很可能磁盘出现故障。
-
-
hi:硬中断消耗时间百分比。
-
si:软中断消耗时间百分比。
- 硬中断是外设对 CPU 的中断,即外围硬件发给 CPU 或者内存的异步信号就是硬中断信号;软中断由软件本身发给操作系统内核的中断信号。
- 通常是由硬中断处理程序或进程调度程序对操作系统内核的中断,也就是我们常说的系统调用(System Call)。
- 在性能测试过程中,hi 会有一定的 CPU 占用率,但不会太高。对于 I/O 密集型的服务,si 的 CPU 占用率会高一些。
-
st:虚拟机等待 CPU 资源的时间。
- 只有 Linux 在作为虚拟机运行时 st 才是有意义的。它表示虚机等待 CPU 资源的时间(虚机分到的是虚拟 CPU,当需要真实的 CPU 时,可能真实的 CPU 正在运行其它虚机的任务,所以需要等待)。
案例分析
现象:wa 与 id:
-
wa(IO wait)的值过高,表示硬盘存在 I/O 瓶颈。
-
id(idle)值高,表示 CPU 较空闲。
-
如果 id 值高但系统响应慢时,有可能是 CPU 等待分配内存,此时应加大内存容量。
-
如果 id 值持续低于 10,那么系统的 CPU 处理能力相对较低,表明系统中最需要解决的资源是 CPU。
-
现象:CPU 的 us 和 sy 不高,但 wa 很高:
如果被测服务是磁盘 I/O 密集型服务,wa 高属于正常现象。但如果不是此类服务,最可能导致 wa 高的原因有两个:
-
服务对磁盘读写的业务逻辑有问题,读写频率过高,写入数据量过大,如不合理的数据载入策略、log 过多等,都有可能导致这种问题。
-
服务器内存不足,服务在 swap 分区不停的换入换出。
现象:CPU 与吞吐量:
-
CPU 占用不高,吞吐量较低,可能是服务端线程池启动太少。
-
CPU 占用很高,吞吐量较低,服务端处理慢,可能操作数据库慢。
-
CPU 占用很高,吞吐量很高:
- 服务端处理能力强,需要调整线程数降低 CPU 使用率。
- 数据库连接数、慢 SQL、文件句柄优化。
- 提升物理设备。
2. LOAD
Linux 的系统负载指在特定时间间隔内(一个 CPU 周期)运行队列中的平均进程数。
(注意:Linux 中的 Load 体现的是整体系统负载,即 CPU 负载 + 磁盘负载 + 网络负载 + 其余外设负载,并不能完全等同于 CPU 使用率。而在其余系统如 Unix,Load 还是只代表 CPU 负载。)
从服务器负载的定义可以看出,服务器运行最理想的状态是所有 CPU 核心的运行队列都为 1,即所有活动进程都在运行,没有等待。这种状态下服务器运行在负载阈值下。
通常情况下,按照经验值,服务器的负载应位于阈值的 70%~80%,这样既能利用服务器大部分性能,又留有一定的性能冗余应对流量增长。
查看系统负载阈值的命令如下:

Linux 提供了很多查看系统负载的命令,最常用的是 top 和 uptime。
top 和 uptime 针对负载的输出内容相同,都是系统最近 1 分钟、5 分钟、15 分钟的负载均值:
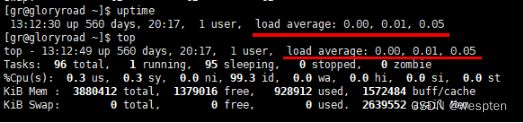
这三个数值的使用方法和 CPU 核数相关,首先确认 CPU 物理总核数:
-
/proc/cpuinfo 中的 processors 的最大值不一定是 CPU 的核数,有可能该 CPU 支持超线程技术,从而 processors 是物理核数的 2 倍。
-
这里我们需要准确的核数,具体方法为:找到 /proc/cpuinfo 文件中所有的 physical id 后的数值,取得最大的数值,加一后就是实际的 CPU 个数。然后查找任意一个 processors 下的 cpu cores,即是该颗 CPU 的核数,实际 CPU 个数乘以核数即为 CPU 的物理总核数。
示例:
[root@localhost home]# cat /proc/cpuinfo |grep "physical id"
physical id : 0
physical id : 0
[root@localhost home]# cat /proc/cpuinfo |grep "cpu cores"
cpu cores : 2
cpu cores : 2
物理 CPU 个数为 0+1=1 个,每个 CPU 的核数为 2 个,所以总的物理核数为 2x1=2。
计算结果说明该机器的在单位时间内可以处理的进程数是 2 个,如果单位时间内进程数超过 2 个,就会出现拥堵的情况,load 就会持续增高,增高到一定程度,就会出现系统崩溃等异常情况。
在性能测试过程中,系统负载是评价整个系统运行状况最重要的指标之一。通常情况下:
-
负载测试时:系统负载应接近但不能超过阈值。
-
并发测试时:系统负载最高不能超过阈值的 80%。
-
稳定性测试时:系统负载应在阈值的 50% 左右。
机器针对突发情况的处理:
-
如果 1 分钟 load 很高,5 分钟 load 较高,15 分钟 load 起伏不大的情况下,说明该次高 load 为突发情况,可以容忍。
-
如果高 load 持续,导致 5 分钟和 15 分钟 load 都已经超过报警值,这时候需要考虑进行处理。
-
如果 15 分钟 load 高于 1 分钟 load,说明高 load 情况已经得到缓解。
3. 内存
性能测试过程中对内存监控的主要目的是检查被测服务所占用内存的波动情况。
top 参数详解:
在 Linux 系统中有多个命令可以获取指定进程的内存使用情况,最常用的是 top 命令,如下图所示:

-
VIRT:进程所使用的虚拟内存的总数。它包括所有的代码,数据和共享库,加上已换出的页面,所有已申请的总内存空间。
-
RES:进程正在使用的没有交换的物理内存(栈、堆)。申请内存后该内存段已被重新赋值。
-
SHR:进程使用共享内存的总数。该数值只是反映可能与其它进程共享的内存,不代表这段内存当前正被其他进程使用。
-
SWAP:进程使用的虚拟内存中被换出的大小。交换的是已经申请但没有使用的空间(包括栈、堆、共享内存)。
-
DATA:进程除可执行代码以外的物理内存总量,即进程栈、堆申请的总空间。
从上面的解释可以看出,测试过程中主要监控 RES 和 VIRT。对于使用了共享内存的多进程架构服务,还需要监控 SHR。
free 参数详解:
free 命令显示系统内存的使用情况,包括物理内存、交换内存(swap)和内核缓冲区内存。如果加上 -h 选项(控制显示单位),输出的结果会友好很多:

有时我们需要持续的观察内存的状况,此时可以使用 -s 选项并指定间隔的秒数:如 free -h -s 3 表示每隔 3 秒输出一次内存的使用情况,直到按下 ctrl + c。
-
Mem 行:物理内存的使用情况。
-
Swap 行:交换空间的使用情况。
-
swap space 是磁盘上的一块区域,可以是一个分区,也可以是一个文件,所以具体的实现可以是 swap 分区也可以是 swap 文件。当系统物理内存吃紧时,Linux 会将内存中不常访问的数据保存到 swap 上,这样系统就有更多的物理内存为各个进程服务,而当系统需要访问 swap 上存储的内容时,再将 swap 上的数据加载到内存中,这就是常说的换出和换入。
-
交换空间可以在一定程度上缓解内存不足的情况,但是它需要读写磁盘数据,所以性能不是很高。因此
当交换空间内存开始使用,则表明内存严重不足。 -
如果系统内存充足或是做性能压测的机器,可以使用 swapoff -a 关闭交换空间,或在 /etc/sysctl.conf 文件中设置 swappiness 值。如果系统内存不富余,则需要根据物理内存的大小来设置交换空间的大小,具体的策略网上有很丰富的资料。
-
-
total 列:系统总的可用物理内存和交换空间大小。
-
used 列:已经被使用的物理内存和交换空间大小。
-
free 列:还有多少物理内存和交换空间可用使用(真正尚未被使用的物理内存数量)。
在吞吐量固定的前提下,如果内存持续上涨,那么很有可能是被测服务存在明显的内存泄漏,需要使用 valgrind 等内存检查工具进行定位。
-
shared 列:被共享使用的物理内存大小。
-
buffer/cache 列:被 buffer 和 cache 使用了的物理内存大小。
-
Linux 内核为了提升磁盘操作的性能,会消耗一部分空闲内存去缓存磁盘数据,就是 buffer 和 cache。 -
如果给所有应用分配足够内存后,物理内存还有剩余,linux 会尽量再利用这些空闲内存,以提高整体 I/O 效率,其方法是把这部分剩余内存再划分为 cache 及 buffer 两部分加以利用。
-
所以,
空闲物理内存不多,不一定表示系统运行状态很差,因为内存的 cache 及 buffer 部分可以随时被重用,在某种意义上,这两部分内存也可以看作是额外的空闲内存。
-
-
available 列:还可以被应用程序使用的物理内存大小。
- 从应用程序的角度来说,
available = free + buffer + cache。请注意,这只是一个很理想的计算方式,实际中的数据往往有较大的误差。
- 从应用程序的角度来说,
释放缓存内存
方式一:手动释放缓存内存
snyc
echo 3 > /proc/sys/vm/drop_caches
free -m方式二:修改 linux 配置自动释放
/proc/sys/vm/drop_caches 这个值的 0 改为 1
4. 磁盘 I/O
性能测试过程中,如果被测服务对磁盘读写过于频繁,会导致大量请求处于 I/O 等待的状态,系统负载升高,响应时间变长,吞吐量下降。
性能监控时的关注点:
-
I/O 使用率:磁盘实际 I/O 是否已接近最大值,接近则有问题。
-
I/O 队列:如果当前 I/O 队列长度一直不为 0,则有问题。
固态硬盘:500M/s
机械硬盘:不超过 200M/siostat 参数详解:
Linux 下可以用 iostat 命令来监控磁盘状态。
iostat -d 2 10 表示每 2 秒统计一次基础数据,统计 10 次:

-
tps:该设备每秒的传输次数。“一次传输”意思是“一次 I/O 请求”。多个逻辑请求可能会被合并为“一次 I/O 请求”。“一次传输”请求的大小是未知的。
-
kB_read/s:每秒从设备(driveexpressed)读取的数据量,单位为 Kilobytes。
-
kB_wrtn/s:每秒向设备(driveexpressed)写入的数据量,单位为 Kilobytes。
-
kB_read:读取的总数据量,单位为 Kilobytes。
-
kB_wrtn:写入的总数量数据量,单位为 Kilobytes。
从 iostat -d 的输出中,能够获得系统运行最基本的统计数据。但对于性能测试来说,这些数据不能提供更多的信息。需要加上 -x 参数。
iostat -x 参数详解:
如 iostat -x 2 10 表示每 2 秒统计一次更详细数据,统计 10 次:
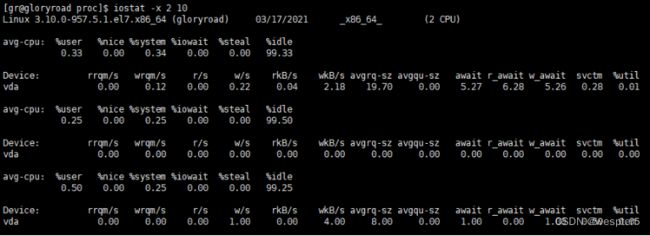
-
rrqm/s:每秒这个设备相关的读取请求有多少被 Merge 了。
- 当系统调用需要读取数据的时候,VFS 将请求发到各个 FS,如果 FS 发现不同的读取请求读取的是相同 Block 的数据,FS 会将这个请求合并 Merge。
-
wrqm/s:每秒这个设备相关的写入请求有多少被 Merge 了。
-
await:每一个 I/O 请求的处理的平均时间(单位:毫秒)。
-
await 的大小一般取决于服务时间(svtcm)以及 I/O 队列的长度和 I/O 请求的发出模式。假设 svtcm 比较接近 await,说明 I/O 差点没有等待时间。
-
假设 await 远大于 svctm(如大于 5),就要考虑 I/O 有压力瓶颈,说明 I/O 队列太长,应用得到的响应时间变慢。假设响应时间超过了用户能够容许的范围,这时可以考虑更换更快的磁盘。
-
-
svctm:I/O 平均服务时间。
-
%util:在统计时间内有百分之多少用于 I/O 操作。
-
例如,如果统计间隔 1 秒,该设备有 0.8 秒在处理 I/O,而 0.2 秒闲置,那么该设备的 %util = 0.8/1 = 80%,该参数暗示了设备的繁忙程度。
-
%util 接近100% 表明 I/O 请求太多,I/O 系统繁忙,磁盘可能存在瓶颈。
-
iostat -x 完整参数如下:
- rrqm/s: 每秒进行 merge 的读操作数目。即 delta(rerge)/s
- wrqm/s: 每秒进行 merge 的写操作数目。即 delta(wmerge)/s
- t/s: 每秒完成的读 I/O 设备次数。即 delta(rioVs
- w/s: 每秒完成的写 1/O 设备次数。即 delta(wio)/s
- rsec/s: 每秒读扇区数。即 delta(rsect)/s
- ws0c/s: 每秒写扇区数。即 deita(wsect)/s
- rkB/s: 每秒读 K 字节数。是 rsect/s 的一半,因为每扇区大小为 512 字节。(需要计算)
- wkB/s: 每秒写 K 字节数。是 wsect/s 的一半。(需要计算)
- avgrq+sz: 平均每次设备 I/O 操作的数据大小(扇区)。delta(rsect+wsect)/delta(rio+wio)
- avgqu-sz: 平均I/O队列长度,即delta(avea)/s/1000(因为 aveq 的单位为毫秒)。
- await: 平均每次设备 I/O 操作的等待时间(毫秒)。即 delta(ruse+wuse)/delta(rio+wio)
- svctm: 平均每次设备 I/O 操作的服务时间(毫秒)。即 delta(use)/delta(rio+wio)
- %util:一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。即 delta(use)/s/1000(因为 use 的单位为毫秒)5. 网络
性能测试中网络监控主要包括网络流量、网络连接状态的监控。
网络流量监控:
方法很多,网上有很多 shell 脚本。也可以使用 nethogs 命令。该命令与 top 类似,是一个实时交互的命令,运行界面如下:
在后台服务性能测试中,对于返回文本结果的服务,并不需要太多关注在流量方面。
理解带宽
针对一些特定的应用,比如直播或网盘(文件上传下载),带宽瓶颈也是一个出现频率较高的场景。
服务端的带宽分为上行(out)和下行(in)带宽(分别对应客户端的下载和上传)。
-
看视频看新闻使用带宽:客户端的下载、服务端的上行带宽。
-
服务端接收客户端的数据使用带宽:客户端的上传、服务端的下行带宽。
一个 Web 服务器如各类新闻网站通常需要更多的服务端上行(out)带宽;而邮件服务器、网盘服务器等则通常需要更多的服务端下行带宽(in)。
理解带宽速率公式
-
1 Mb/s 带宽速度为 128 KB/s(1024Kb / 8KB)
-
100 Mb/s 带宽速度为 12.5 Mb/s(考虑网络损耗通常按 10M/s 或 1280KB/s 算)
示例:5000 万像素手机拍一张照片,照片大小约 20MB,在下述带宽下需要耗时:
-
10M 带宽约 20 秒:耗时 = 流量 / 速率 = 20MB / (10Mb/8) = 20 / 1.25 = 16 秒(按 1MB/s=128KB/s 速度算即 20 秒)
-
100M 带宽约 2 秒:耗时 = 流量 / 速率 = 20MB / (100Mb/8) = 20 / 12.5 = 1.6 秒(按 10MB/s=128KB/s 速度算即 2 秒)
-
1000M 带宽约 0.2 秒:耗时 = 流量 / 速率 = 20MB / (1000Mb/8) = 20 / 125 = 0.16 秒(按 100MB/s=128KB/s 速度算即 0.2 秒)
案例分析
现象:从监控图表可以看出,当前的网络流量已经基本将网络带宽占满,因此网络存在瓶颈。
解决方案:
- 硬件解决:增加带宽(带宽便宜)。
- 软件解决:分析对应业务操作的数据传送内容是否可精简;是否可以异步传送。
网络连接状态监控
性能测试中对网络的监控主要是监控网络连接状态的变化和异常。
-
对于使用 TCP 协议的服务,需要监控服务已建立连接的变化情况(即 ESTABLISHED 状态的 TCP 连接)。
-
对于 HTTP 协议的服务,需要监控被测服务对应进程的
网络缓冲区的状态、TIME_WAIT 状态的连接数等。
Linux 自带的很多命令如 netstat、ss 都支持如上功能。
下图是 netstat 对指定 pid 进程的监控结果:

完整命令输出:
4、数据库
1. 慢查询
如 MySQL 资源出现瓶颈,首先找慢查询(超过自定义的执行时间阈值的 SQL)。
1)通过 SQL 语句定位到慢查询日志的所在目录,然后查看日志。
show variables like "slow%";
2)慢查询日志在查询结束以后才纪录,所以在应用反映执行效率出现问题时,查询慢查询日志并不能定位问题。这时可以使用show processlist命令查看当前 MySQL 正在进行的线程状态,可以实时地查看 SQL 的执行情况。
示例:
mysql -uroot -p123456 -h127.0.0.1 -p3307 -e "show full processlist" |grep dbname |grep -v NULL3)找到慢查询 SQL 后可以用执行计划(explain)进行分析(或反馈给 DBA 和开发处理)。推荐最简单的排查方式,步骤如下:
- 分析 SQL 是否加载了不必要的字段/数据。
- 分析 SQL 是否命中索引。
- 如果 SQL 很复杂,优化 SQL 结构。
- 如果表数据量太大,考虑分表。
- ……
2. 连接数
数据库连接池的使用率:
-
当数据库连接池被占满时,如果有新的 SQL 语句要执行,只能排队等待,等待连接池中的连接被释放(等待之前的 SQL 语句执行完成)。
-
如果监控发现数据库连接池的使用率过高,甚至是经常出现排队的情况,则需要进行调优。
查看/设置最大连接数:
-- 查看最大连接数
mysql> show variables like '%max_connection%';
+-----------------------+-------+
| Variable_name | Value |
+-----------------------+-------+
| extra_max_connections | |
| max_connections | 2512 |
+-----------------------+-------+
2 rows in set (0.00 sec)
-- 重新设置最大连接数
set global max_connections=1000;在/etc/my.cnf 里面设置数据库的最大连接数:
[mysqld]
max_connections = 1000查看当前连接数:
mysql> show status like 'Threads%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Threads_cached | 32 |
| Threads_connected | 10 |
| Threads_created | 50 |
| Threads_rejected | 0 |
| Threads_running | 1 |
+-------------------+-------+
5 rows in set (0.00 sec)-
Threads_connected:表示当前连接数。跟 show processlist 结果相同。准确的来说,Threads_running 代表的是当前并发数。
-
Threads_running:表示激活的连接数。一般远低于 connected 数值。
-
Threads_created:表示创建过的线程数。
-
如果我们在 MySQL 服务器配置文件中设置了 thread_cache_size,那么当客户端断开之后,服务器处理此客户的线程将会缓存起来以响应下一个客户而不是销毁(前提是缓存数未达上限)。
-
如果发现 Threads_created 值过大的话,表明 MySQL 服务器一直在创建线程,这也是比较耗资源,因此可以适当增加配置文件中 thread_cache_size 值。
-
查询服务器 thread_cache_size 的值:
mysql> show variables like 'thread_cache_size';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| thread_cache_size | 100 |
+-------------------+-------+
1 row in set (0.00 sec)3. 缓存命中率
-
通常,SQL 查询是从磁盘中的数据库文件中读取数据。
-
若当某一个 SQL 查询语句之前执行过,则该 SQL 语句及查询结果都会被缓存下来,下次再查询相同的 SQL 语句时,就会直接从数据库缓存中读取。(注意,MySQL 8 开始已废弃查询缓存功能。)
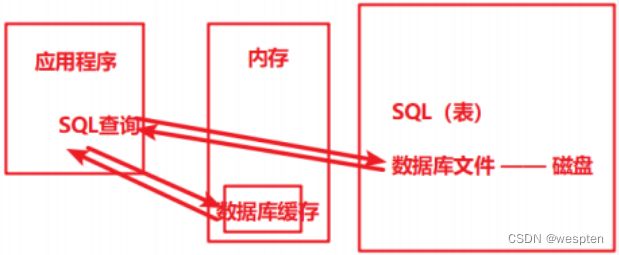
监控点:
-
业务执行过程中 SQL 查询时的缓存命中率(查询语句读取缓存的次数占总查询次数的比例)。
-
如果缓存命中率过低,需要优化对应的代码和 SQL 查询语句,以提高缓存命中率。
测试结果分析:
结论:从目前的测试结果来看(如下图所示),性能存在问题。
现象:并发数达到 50 时的 TPS 为 52,此时虽然响应时间为 4.4s(小于需求的 5s),但是数据库服务器的 CPU 使用率非常高(接近 100%),因此需要重点关注数据库的调优分析。

排查过程:
-
使用 top 命令观察,确定是 mysqld 导致还是其他原因。
- CPU 分为用户 CPU 和内核 CPU。综合其他的各项资源指标来分析,发现内存、磁盘IO、网络等指标无任何异常,因此判断此处不是内核 CPU 占用高,主要原因是用户进程占用的 CPU 高。
- 确认目前 CPU 占用高的为 mysqld 进程。
-
分析数据库服务器 CPU 高的可能原因:慢 SQL、SQL 语句过多、连接数过多等。
-
确认是否存在慢 SQL:
- 查看慢查询日志,看看是否有超过预期指标的 SQL 语句,并分析排查:看看执行计划是否准确、索引是否缺失、数据量是否太大等。
- 目前案例经过慢查询日志的分析,未存在慢查询。
-
确认是否 SQL 语句过多或连接数过多:
- 使用
show full processlist查看当前数据库中正在执行的 SQL 语句及连接池的状态,发现大量 SQL 在等待执行。 - 再结合操作过程中的系统日志进行分析,发现每进入一次商城首页,就需要在数据库中执行 19 条查询 SQL。
- 使用
-
解决方案:
- 硬件解决:增加 CPU。
- 软件解决:为减少一次性加载过多 SQL,可考虑使用分批次、异步加载的方式(展示到什么位置,就查询什么位置的数据)。
5、JAVA应用
1. JVM
JVM(JAVA Virtual Machine):虚拟出来的空间,专门供 JAVA 程序运行。
JAVA 应用运行机制:
JVM 体系结构介绍:
-
JVM 内存分为三个大区,young 区(年轻代),old 区(年老代)和 perm 区(持久代),其中 young 区又包含三个区:Edgn 区、S0 区(From 区)、S1 区(To 区)。
-
young 区和 old 区属于 heap(堆)区,占据堆内存;perm 区称为持久代,不占据堆内存。
-
PermSpace 主要是存放静态的类信息和方法信息、静态的方法和变量、final 标注的常量信息等。
JAVA 运行时内存划分:
重点关注:堆区(动态变化)。我们常说的性能调优,指的就是堆中的性能调优。
监控点:因此在测试时,需要关注堆区的空间是否持续上升而没有下降。
2. 垃圾回收机制
垃圾回收机制:
-
垃圾回收指将内存中已申请并使用完成的那部分内存空间回收,供新申请使用。
-
垃圾回收机制都是针对堆区的内存进行的。
监控点:
-
内存泄露:一个对象持有一个引用永远不释放,导致声明周期过长,这样持有的对象对了,内存就不够用了,这样就会频繁 GC。
-
系统在做垃圾回收时,不能够处理任何用户业务的。如果垃圾回收过于频繁,导致系统业务处理能力下降。
-
由于 Full GC 内存比较大,垃圾回收一次时间比较长,那么这段时间内都不能处理业务,对系统影响比较大,因此我们需要关注
Full GC 频率。
垃圾回收机制的运行步骤如下:

-
新程序执行时需要先申请内存空间,会先从年轻代中申请。
-
在年轻代满了以后,就会进行垃圾回收
Young GC(Minor GC)(所有的 Minor GC 都会触发“全世界的暂停(stop-the-world)”,停止应用程序的线程,但这段时间可以忽略不计)。 -
回收时检查年轻代中的内存,是否还在使用。还在使用的部分会移存到生存区 2 中;不使用的部分则释放,此时年轻代内存空间被清空。
-
新程序执行申请内存空间,再从年轻代申请。
-
年轻代又满了,就会进行垃圾回收
Young GC。还在使用的内存移存到生存区 1 中,并把生存区 2 中的内存也都存到生存区 1 中。此时就会清空年轻代和生存区 2。 -
循环上述 1-5 步。
-
如果部分内存在生存区中存活很久(内存在生存区中移动了 10 次左右),则将这部分内存放入到老年代中。
-
循环上述 1-7 步,直到老年代内存空间全部占满,此时就要进行垃圾回收
Full GC(Major GC)(Full Gc 会暂停所有正在执行的线程(Stop The World),来回收内存空间,这个时间需要重点考虑)。
3. JVM dump
在故障定位(尤其是 out of memory)和性能分析的时候,经常会用到一些文件来帮助我们排除代码问题。这些文件记录了 JVM 运行期间的内存占用、线程执行等情况,这就是我们常说的 dump 文件。
常用的有 heap dump 和 thread dump(也叫 javacore,或 java dump)。我们可以这么理解:heap dump 记录内存信息的,thread dump 是记录 CPU 信息的。
-
当发现应用内存溢出或长时间使用内存很高的情况下,通过内存 dump 进行分析可找到原因。
-
当发现 cpu 使用率很高时,通过线程 dump 定位具体哪个线程在做哪个工作占用了过多的资源。
-
heap dump
-
heap dump 文件是一个二进制文件,指定时刻的 Java 堆栈的快照,是一种镜像文件,它保存了某一时刻 JVM 堆中对象使用情况。
-
可以通过 Heap Analyzer工具分析 heap dump 文件,哪些对象占用了太多的堆栈空间,来发现导致内存泄露或者可能引起内存泄露的对象。
-
-
thread dump
-
thread dump 文件主要保存的是 java 应用中各线程在某一时刻的运行的位置,即执行到哪一个类的哪一个方法哪一个行上。
-
thread dump 是一个文本文件,打开后可以看到每一个线程的执行栈,以 stack trace 的方式显示。
-
通过对 thread dump 的分析可以得到应用是否“卡”在某一点上,即在某一点运行的时间太长,如数据库查询时长期得不到响应,最终导致系统崩溃。
-
单个的 thread dump 文件一般来说是没有什么用处的,因为它只是记录了某一个绝对时间点的情况。比较有用的是,线程在一个时间段内的执行情况。
-
thread dump 文件在分析时特别有效,困为它可以看出在先后两个时间点上,线程执行的位置。如果发现先后两组数据中同一线程都执行在同一位置,则说明此处可能有问题,因为程序运行是极快的,如果两次均在某一点上,说明这一点的耗时是很大的。通过对这两个文件进行分析,查出原因,进而解决问题。
-
4. 获取 dump 文件
可以利用 JDK 自带的工具获取 thread dump 文件和 heap dump 文件,即 JDK_HOME/bin/ 目录下的 jmap 和 jstack 这两个命令。
1)获取 heap dump 文件
./jmap -dump:format=b,file=heap.hprof 2576
这样就会在当前目录下生成 java 应用进程 pid 为 2576 的 heap.hprof 文件,这就是 heap dump 文件。
如果我们只需要将 dump 中存活的对象导出,那么可以使用 :live 参数:
jmap -dump:live,format=b,file=heapLive.hprof 2576
2)获取 thread dump 文件
./jstack 2576 > thread.txt
这样会将命令执行结果转储到 thread.txt,这就是 thread dump 文件。有了 dump 文件后,我们就能借助性能分析工具获取 dump 文件中的信息(使用 top -H -p
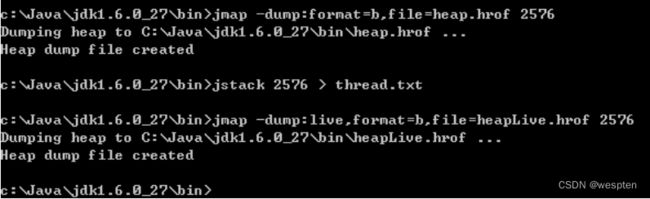
5. 打开 dump 文件
1)使用 JDK 自带的 jhat 命令
jhat 是用来分析 java 堆的命令,可以将堆中的对象以 html 的形式显示出来,包括对象的数量、大小等等,并支持对象查询语言。
jhat -port 5000 heap.hrof
当服务启动完成后,我们就可以在浏览器中,通过 http://localhost:5000/ 进行访问,如下所示:

2)使用 eclipse MAT 工具
一般来说,应用程序的 dump 文件都是很大的,jdk 自带命令难以分析这些大文件。在实际的生产环境下,我们必须要借助第三方工具,才能快速打开这些大文件,进行分析定位。
安装好 eclipse mat 分析工具后,将 dump 文件导入 eclipse,点击[Leak Suspects],找到跟公司有关的代码进行分析。

6. 分析 thread dump 文件
1)线程 dump 详解
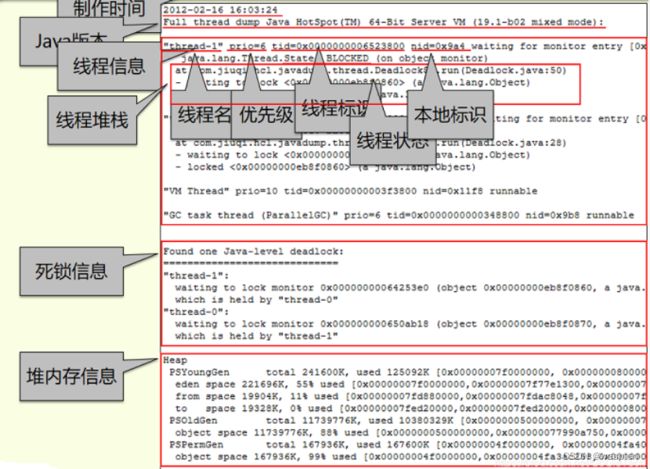
线程的状态:
- NEW:未启动,不会出现在 Dump 中。
- RUNNABLE:在虚拟机中执行的。
- BLOCKED:受阻塞并等待在监视器锁。
- WAITTING:无限期等待另一个线程执行特定的操作。
- TIMED_WAITTING:有时限的等候另一个线程执行特定的操作。
- TERMINATED:已退出。
监视器:

调用修饰:
- locked <地址> 目标:注意临界区对象锁可重入,线程状态为 RUNNABLE。
- waitting to lock <地址> 目标:还没有获得锁,进入区等待,线程状态为 BLOCKED
- waitting on <地址> 目标:获得锁了,等待区等待,线程状态为 WAITTING,TIMED_WAITTING。
- parking to wait for <地址> 目标:线程原语,随 current 包出现,与 synchronized 体系不同。
线程动作:
- runnable:线程状态为 RUNNABLE。
- in Object.wait():等待区等待,线程状态为 WAITTING 或 TIMED_WAITTING。
- waitting for monitor entry:进入区等待,线程状态为 BLOCKED。
- waitting on condition:等待区等待,被 park。
- sleeping:休眠的线程,调用了 Thread.sleep()。
2)分析线程 dump 的入手点
-
进入区等待:BLOCKED、waitting to lock、waitting for monitor entry,这些词表名代码层面已经存在冲突。
-
持续进行的 IO:一般来说被捕捉到的 runnable 的 IO 调用都是有问题的,如 runnable 中有 JDBC 链接的代码。
-
非线程调度的等待区等待:in Object.wait()(情况 1 可能会导致这个情况,造成大量线程堆积)。
-
“死锁”问题的解决办法
-
在最可能死锁的时间点制作 dump。
-
找出引起大量线程阻塞的线程。
-
找出该线程阻塞的原因。
-
阅读代码,遍历其他阻塞或等待的线程,以及它之前的调用是否会造成这个线程的等待。
-
-
注意:排除 GC 干扰,Full GC 时所有线程都会被阻塞住。
- 查看线程 dump 时,首先查看内存使用情况。
- 使用命令“-verbose:gc”,观察是否有 Full GC 字样。
3)分析 heap dump 文件
什么情况下需要分析堆 Dump?
内存不足、GC 异常、怀疑代码内存泄漏,这时需要制作堆 Dump,找出生命周期的错误关联对象以及相关代码。
JVM 内存模型:
- 年轻代(Young Generation,包括Eden space、From space、To space)
- 年老代(Old Generation)
- 永久代(PermGen space)
两种 GC:
- YoungGen GC:Minor GC
- Full GC:Major GC
常见错误:
- out of MemoryError:GC overhead limit exceed:回收时间占系统运行时间的 98% 以上,极有可能是内存泄漏导致的。
7. 案例分析:JVM 堆内存溢出
JVM 堆内存回收详细过程图解:从下图可以很清晰的看到,old 区空间占满后会进行一次 FGC(称为全量 GC),FGC 回收后如果 old 区空间还是不能容纳新生成对象,那么便会产生 java 堆内存溢出[JAVA HEAP OOM]。

性能问题发现过程:
查看服务器上报错日志,发现有如下报错信息[java.lang.OutOfMemoryError: Java heap space];根据报错信息确定是 jvm 堆内存空间不够导致,于是使用 jvm 命令查看(下图所示),发现此时 old 区内存空间已经被占满了。

同时使用 jvisualvm 监控工具也发现 old 区空间被占满(如下图所示,单位为百分比),整个 heap 区空间已经无法再容纳新对象进入。

建议:考虑大量数据一次性写入内存场景。
8. 案例分析:持久代内存溢出
PermSpace 主要是存放静态的类信息和方法信息、静态的方法和变量、final 标注的常量信息等。
现象:
压测某系统接口,压测前1分钟左右 TPS 400 多,之后 TPS 直降为零,后台报错日志:java.lang.OutOfMemoryError:PermGenspace,通过 jvm 监控工具查看持久代(perm区)空间被占满,而 Old 区空闲。

问题定位:
通过注释代码块定位问题,考虑到 perm 区溢出大部分跟类对象大量创建有关,故锁定问题在序列化框架使用可能有问题。
-
获取 JVM dump 文件。
-
安装 eclipse mat 分析工具。
-
将 dump 文件导入 eclipse,点击[Leak Suspects],找到跟公司有关的代码进行分析。

解决方案:
跟开发沟通后选择去掉 msgpack0.6 版本框架,采用 java 原生序列化框架。修改后系统 tps 稳定在 400 多,gc 情况正常。
修复前:

修复后:

类似问题如何避免:
- 去掉项目无用 jar 包。
- 避免大量使用类对象、大量使用反射。
9. 案例分析:频繁 FGC
现象:系统某接口频繁 FGC。
问题排查及解决方案:
先查 JVM 内存信息找可疑对象,命令为:jmap -histo

从内存对象实例信息中发现跟 mysql 连接有关,然后检测 mysql 配置信息:
发现系统采用的是 spring 框架的数据源,没有用连接池。
使用连接池的好处:连接复用,减少连接重复建立和销毁造成的大量资源消耗。
然后换做 hikaricp 连接池做对比测试:
压测半小时未出现 fgc,问题得到解决。
类似问题如何避免:
- 研发规范统一 DB 连接池,避免研发误用。
- 减少大对象、临时对象使用。
10. 案例分析:减少 mirror GC
现象:
假设,现在有亿级流量电商的抢购活动,活跃用户为 500 万,付费转化率为 10%。活跃时间在抢购的前几分钟,假设每秒产生 1000 单,而每台 Tomcat 的最高并发支持数为 500。现有三台服务器,均为 4 核 8g,每台服务器均部署 Tomcat,使用 nginx 做负载均衡。
有 300 单落在服务器 1 上,每单所在堆空间大小为 1Kb,每秒大约产生 300Kb 的堆对象。可以使用 lucene 来动态计算 javabean 所在堆空间的大小。下单还会产生其他对象,比如优惠券、库存、积分等,此时放大 20 倍,也就是每秒产生 6000Kb 的对象。假设还会有订单查询的操作,此时再放大 10 倍,也就是每秒产生约 58MB 的对象。
此时,堆初始值大小和最大值大小均为 3072MB,老年代大小为 2048MB,新生代大小为 1024MB,Eden 区大小为 819MB,s0 和 s1 区大小均为 102MB。819Mb / 58Mb = 14 秒,即大约 14 秒 Eden 区爆满,触发 mirror Gc,此时停止应用程序的线程。
优化:
因而,此时需要调整 JVM 的配置参数:老年代大小为 1024MB,新生代大小为 2048MB,Eden 区大小为 1638MB,s0 和 s1 区大小均为 204MB。1638Mb/ 58Mb = 28秒,这样能减少 mirror Gc,从而达到优化的效果。但更多的优化可根据实际线上 jvm 运行情况来看。
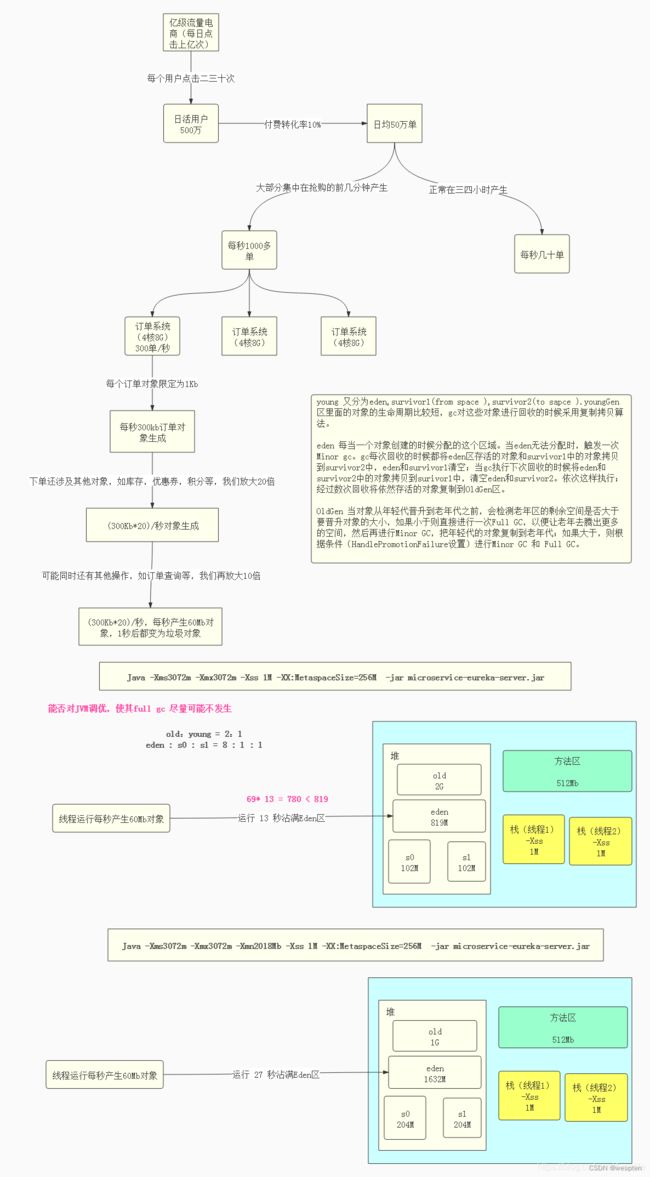
6、框架使用不当
1. 案例分析:错误使用框架提供的 API
某系统本身业务逻辑处理能力很快(研发本机自测 tps 可以到达 2w 多),但是接入到 framework 框架后,TPS 最高只能到达 300 左右,而且系统负载很低。
问题排查:
这种现象说明系统可能是堵在了某块方法上,根据这种情况一般采用线程 dump 的方式来查看系统具体哪些线程出现异常情况。
通过线程 dump 发现 [TIMED_WAITING]状态的业务线程占比很高。

线程的状态:
- NEW:未启动,不会出现在 Dump 中。
- RUNNABLE:在虚拟机中执行的。
- BLOCKED:受阻塞并等待在监视器锁。
- WAITTING:无限期等待另一个线程执行特定的操作。
- TIMED_WAITTING:有时限的等候另一个线程执行特定的操作。
- TERMINATED:已退出。

根据线程 dump 信息,找到公司包名开头的信息,然后从下往上查看线程 dump 信息,从信息中我们可以看到:
- framework.servlet.fServlet.doPost:框架 api 封装了 servletdopost 方法做了某些操作。
- framework.servlet.fServlet.execute:框架 api 执行 servelt。
- framework.process.fProcessor.process:框架 api 进行自身逻辑处理。
- framework.filter.impl.AuthFilter.before:框架使用过滤器进行用户权限过滤
- 。。。然后就是进行 http 请求操作。
由此判断,就是在框架进行权限校验这块堵住了。之后跟开发沟通这块的问题即可。
问题原因:
性能测试是验证 A 系统的处理能力,但是在压测程序里,A 系统却调用了权限校验系统,由于权限校验系统处理能力只有 300 左右,从而拖慢了整个系统处理能力。
因此,需要在压测过程中关闭对权限校验系统调用,只压 A 系统,这样才能压测出 A 真实的处理能力。
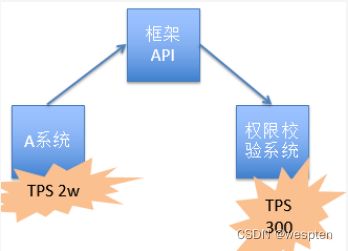
解决方案:
去掉对 B 系统调用,即去掉权限校验。
@Api(auth=true) 改为 @Api(auth=false)
2. 案例分析:日志框架使用不当
某系统添加 LOGBACK 日志框架输出日志(日志级别为 INFO)后,TPS 从 1000 降到 200 多:

从 JVISUALVM 工具看到有大量业务线程处于 BLOCKED 状态:
优化方案:
日志降级、将日志级别改为 warn,减少日志输出量。
后续建议:
-
合理设置日志级别、精简日志输出。
-
合理设置日志刷盘方式,同步 or 异步。
-
对于 DEBUG、INFO 日志打印、需要先判断日志级别:if(LOGGER.isDebugEnabled()){do log} 。
7、OS内存溢出
问题现象:
某系统线上故障,系统假死,无法提供服务,服务器 ssh 无法登录。
问题根因:
系统使用堆外内存,操作系统内核占用 cache 内存,当 cache 内存占满后,无法释放,导致物理内存 OOM(Out Of Memory)。

为什么会 OOM?
为什么会没有内存了呢?原因不外乎有两点:
-
分配的少了:比如虚拟机本身可使用的内存(一般通过启动时的 JVM 参数指定)太少。
-
应用用的太多,并且用完没释放,浪费了。此时就会造成内存泄露或者内存溢出。
优化方案:
通过优化 linux 操作系统内核参数:min_free_kbytes