task_2异常检测方法—统计学习方法
一、基于统计学方法的异常检测
主要原理是:学习一个拟合给定数据集的生成模型,然后识别该模型低概率区域中的对象,把它们作为异常点。也就是说,包括两个步骤,第一,给出概率模型,第二,考虑对象有多大可能符合该模型。
根据如何指定和学习模型,异常检测的统计学方法可以划分为两个主要类型:参数方法和非参数方法。
- 参数方法:假定正常的数据对象被一个以 Θ \Theta Θ为参数的参数分布产生。该参数分布的概率密度函数 f ( x , Θ ) f(x,\Theta) f(x,Θ)给出对象 x x x被该分布产生的概率。该值越小, x x x越可能是异常点。(也就是给出f,然后把每个x代入,算f(x))
- 非参数方法:并不假定先验统计模型,而是试图从输入数据确定模型。非参数方法通常假定参数的个数和性质都是灵活的,不预先确定(所以非参数方法并不是说模型是完全无参的,完全无参的情况下从数据学习模型是不可能的)。
二、参数方法
主要介绍高斯分布的,因为不管任何分布,都可以用一组高斯分布和的形式近似。
2.1 基于正态分布的一元异常点检测
仅涉及一个属性或变量的数据称为一元数据。我们假定数据由正态分布产生,然后可以由输入数据学习正态分布的参数,并把低概率的点识别为异常点。
根据输入数据,其平均值和方差作为正太分布模型的期望和方差。再根据概率密度函数的公式,算出数据的概率。如果低于阈值,就可认为该数据点为异常点。
一般使用3sigma原则。如果数据点超过范围 ( μ − 3 σ , μ + 3 σ ) (\mu-3\sigma, \mu+3\sigma) (μ−3σ,μ+3σ),那么这些点很有可能是异常点。
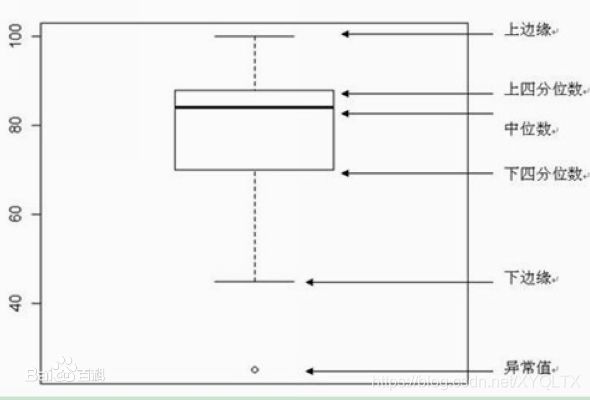
在Q3+1.5IQR和Q1-1.5IQR处画两条与中位线一样的线段,这两条线段为异常值截断点,称其为内限;在Q3+3IQR和Q1-3IQR处画两条线段,称其为外限。处于内限以外位置的点表示的数据都是异常值,其中在内限与外限之间的异常值为温和的异常值(mild outliers),在外限以外的为极端的异常值(extreme outliers)。四分位距IQR=Q3-Q1。
用Python画一个简单的箱线图:
import numpy as np
import seaborn as sns#seaborn就是在matplotlib基础上面的封装,方便直接传参数调用
import matplotlib.pyplot as plt
data = np.random.randn(50000)*20+20
sns.boxplot(data=data)
2.2 多元异常点检测
涉及两个或多个属性或变量的数据称为多元数据。许多一元异常点检测方法都可以扩充,用来处理多元数据。其核心思想是把多元异常点检测任务转换成一元异常点检测问题。例如在各个维度的特征之间相互独立的情况下。基于正态分布的一元异常点检测扩充到多元情形时,可以求出每一维度的均值和标准差。最后的模型也就是联合概率分布模型。
如果特征之间有相关性,一般是先将其去相关,也叫归化。假设变量经过投影后得到一个新变量,即 X ′ = U T X \mathbf{{X}'}={{\mathbf{U}}^{T}}\mathbf{X} X′=UTX ,映射之后的协方差为:
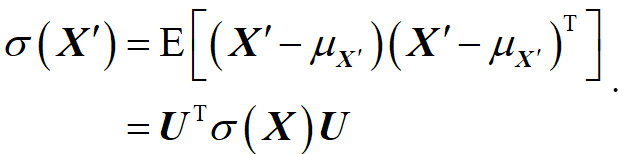
再代入高斯分布的公式即可。
三、非参数方法
在异常检测的非参数方法中,“正常数据”的模型从输入数据学习,而不是假定一个先验。通常,非参数方法对数据做较少假定,因而在更多情况下都可以使用。
3.1 使用直方图检测异常点
步骤1:构造直方图。使用输入数据(训练数据)构造一个直方图。该直方图可以是一元的,或者多元的(如果输入数据是多维的)。超过三维的要怎么画呢
尽管非参数方法并不假定任何先验统计模型,但是通常确实要求用户提供参数,以便由数据学习。例如,用户必须指定直方图的类型(等宽的或等深的)和其他参数(直方图中的箱数或每个箱的大小等)。与参数方法不同,这些参数并不指定数据分布的类型。
步骤2:检测异常点。为了确定一个对象是否是异常点,可以对照直方图检查它。在最简单的方法中,如果该对象落入直方图的一个箱中,
3.2 HBOS
HBOS全名为:Histogram-based Outlier Score,意为基于直方图的离群值得分。是一种单变量方法的组合,基本假设是数据集的每个维度相互独立。然后对每个维度进行区间(bin)划分,区间的密度越高,异常评分越低。感觉是这样一种想法,就是越脱离集体越是异常点的可能性大。
它包括两种设置直方图的方法:
-
静态宽度直方图:标准的直方图构建方法,在值范围内使用k个等宽箱。样本落入每个桶的频率(相对数量)作为密度(箱子高度)的估计。时间复杂度: O ( n ) O(n) O(n),每个样本算一次,所以一共也就是N次
-
动态宽度直方图:首先对所有值进行排序,然后固定数量的 N k \frac{N}{k} kN个连续值装进一个箱里,其 中N是总实例数,k是箱个数;直方图中的箱面积表示实例数。因为箱的宽度是由箱中第一个值和最后一个值决定的,所有箱的面积都一样,因此每一个箱的高度都是可计算的。这意味着跨度大的箱的高度低,即密度小,只有一种情况例外,超过k个数相等,此时允许在同一个箱里超过 N k \frac{N}{k} kN值。时间复杂度: O ( n × l o g ( n ) ) O(n\times log(n)) O(n×log(n))。
假设样本p第 i 个特征的概率密度为 p i ( p ) p_i(p) pi(p) ,则p的概率密度可以计算为: P ( p ) = P 1 ( p ) P 2 ( p ) ⋯ P d ( p ) P(p)=P_{1}(p) P_{2}(p) \cdots P_{d}(p) P(p)=P1(p)P2(p)⋯Pd(p) 两边取对数: log ( P ( p ) ) = log ( P 1 ( p ) P 2 ( p ) ⋯ P d ( p ) ) = ∑ i = 1 d log ( P i ( p ) ) \begin{aligned} \log (P(p)) &=\log \left(P_{1}(p) P_{2}(p) \cdots P_{d}(p)\right) =\sum_{i=1}^{d} \log \left(P_{i}(p)\right) \end{aligned} log(P(p))=log(P1(p)P2(p)⋯Pd(p))=i=1∑dlog(Pi(p)) 概率密度越大,异常评分越小,为了方便评分,两边乘以“-1”: − log ( P ( p ) ) = − 1 ∑ i = 1 d log ( P t ( p ) ) = ∑ i = 1 d 1 log ( P i ( p ) ) -\log (P(p))=-1 \sum_{i=1}^{d} \log \left(P_{t}(p)\right)=\sum_{i=1}^{d} \frac{1}{\log \left(P_{i}(p)\right)} −log(P(p))=−1i=1∑dlog(Pt(p))=i=1∑dlog(Pi(p))1 最后可得计算公式为: H B O S ( p ) = − log ( P ( p ) ) = ∑ i = 1 d 1 log ( P i ( p ) ) H B O S(p)=-\log (P(p))=\sum_{i=1}^{d} \frac{1}{\log \left(P_{i}(p)\right)} HBOS(p)=−log(P(p))=i=1∑dlog(Pi(p))1
也就是频率越大,异常频分越小,为异常点的可能性越小。
对于连续型数据计算其概率密度,最简单的方法是对连续数据进行离散化。离散化的基本思想是设置“断点”,将数据分割成若干个区间。其中,“断点”的设置可以是静态的,也可以是动态的。
对于样本集D,设置合适的“断点”集合,将特征的取值分割成若干个区间。统计区间的样本数,可以构建一个频数直方图H。假设第 i 个特征分割成m 个区间,每个区间统计的样本个数分别为:
h 1 h 2 . . . h m h_1h_2...h_m h1h2...hm
对于第i个区间,其频率取值为 h i / s u m ( h 1 . . . h m ) h_i/sum(h_1...h_m) hi/sum(h1...hm)
四、练习
使用PyOD库生成toy example并调用HBOS
根据pyod官方文档,用于生成toy数据的方法主要是:
- pyod.utils.data.generate_data(),其作用是合成数据生成;正态数据由多元高斯分布生成,异常值由均匀分布生成。
- pyod.utils.data.generate_data_clusters(),其作用是集群中综合数据生成;可以使用多个集群创建更复杂的数据模式。
下面给出两个函数的具体参数和用法。
4.1 pyod.utils.data.generate_data()
合成数据生成;正态数据由多元高斯分布生成,异常值由均匀分布生成。
import pyod
pyod.utils.data.generate_data(n_train=1000,
n_test=500,
n_features=2,
contamination=0.1,
train_only=False,
offset=10,
behaviour='old',
random_state=None,)
#输出为:训练数据,训练结果(0,1),测试数据,测试结果(0,1)
#函数解释:
Docstring:
Utility function to generate synthesized data.
Normal data is generated by a multivariate Gaussian distribution and
outliers are generated by a uniform distribution.
Parameters
----------
n_train : int, (default=1000)
The number of training points to generate.
n_test : int, (default=500)
The number of test points to generate.
n_features : int, optional (default=2)
The number of features (dimensions).
contamination : float in (0., 0.5), optional (default=0.1)
The amount of contamination of the data set, i.e.
the proportion of outliers in the data set. Used when fitting to
define the threshold on the decision function.
train_only : bool, optional (default=False)
If true, generate train data only.
offset : int, optional (default=10)
Adjust the value range of Gaussian and Uniform.
behaviour : str, default='old'
Behaviour of the returned datasets which can be either 'old' or
'new'. Passing ``behaviour='new'`` returns
"X_train, y_train, X_test, y_test", while passing ``behaviour='old'``
returns "X_train, X_test, y_train, y_test".
.. versionadded:: 0.7.0
``behaviour`` is added in 0.7.0 for back-compatibility purpose.
.. deprecated:: 0.7.0
``behaviour='old'`` is deprecated in 0.20 and will not be possible
in 0.7.2.
.. deprecated:: 0.7.2.
``behaviour`` parameter will be deprecated in 0.7.2 and removed in
0.8.0.
random_state : int, RandomState instance or None, optional (default=None)
If int, random_state is the seed used by the random number generator;
If RandomState instance, random_state is the random number generator;
If None, the random number generator is the RandomState instance used
by `np.random`.
Returns
-------
X_train : numpy array of shape (n_train, n_features)
Training data.
y_train : numpy array of shape (n_train,)
Training ground truth.
X_test : numpy array of shape (n_test, n_features)
Test data.
y_test : numpy array of shape (n_test,)
Test ground truth.
File: c:\users\15745\anaconda3\lib\site-packages\pyod\utils\data.py
Type: function
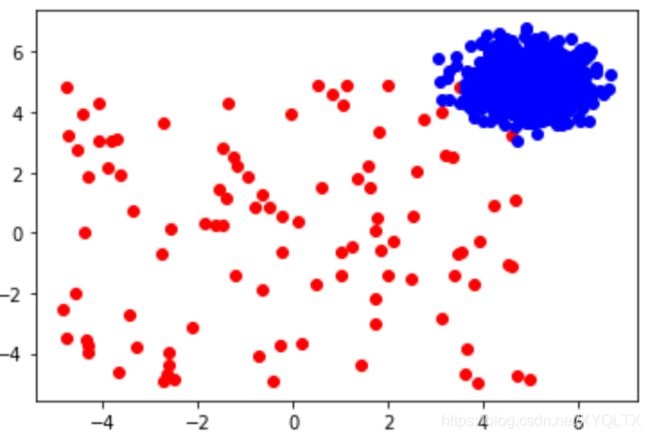
使用默认参数生成数据,并画图展示
import matplotlib.pyplot as plt
import pyod
a = pyod.utils.data.generate_data(n_train=1000,
n_test=500,
n_features=2,
contamination=0.1,
train_only=False,
offset=10,
behaviour='old',
random_state=None,)
fig = plt.figure()
data1 = a[0][a[1]==1,:]
data2 = a[0][a[1]==0,:]
plt.scatter(data1[:,0], data1[:,1],c = 'r',marker = 'o')
plt.scatter(data2[:,0], data2[:,1],c = 'b',marker = 'o')
fig.show()
4.2 pyod.utils.data.generate_data_clusters()
集群中综合数据生成;可以使用多个集群创建更复杂的数据模式。
pyod.utils.data.generate_data_clusters(n_train=1000,
n_test=500,
n_clusters=2,
n_features=2,
contamination=0.1,
size='same',
density='same',
dist=0.25,
random_state=None,
return_in_clusters=False,)
#输出为:训练数据,训练结果(0,1),测试数据,测试结果(0,1)
#函数解释
Docstring:
Utility function to generate synthesized data in clusters.
Generated data can involve the low density pattern problem and global
outliers which are considered as difficult tasks for outliers detection
algorithms.
Parameters
----------
n_train : int, (default=1000)
The number of training points to generate.
n_test : int, (default=500)
The number of test points to generate.
n_clusters : int, optional (default=2)
The number of centers (i.e. clusters) to generate.
n_features : int, optional (default=2)
The number of features for each sample.
contamination : float in (0., 0.5), optional (default=0.1)
The amount of contamination of the data set, i.e.
the proportion of outliers in the data set.
size : str, optional (default='same')
Size of each cluster: 'same' generates clusters with same size,
'different' generate clusters with different sizes.
density : str, optional (default='same')
Density of each cluster: 'same' generates clusters with same density,
'different' generate clusters with different densities.
dist: float, optional (default=0.25)
Distance between clusters. Should be between 0. and 1.0
It is used to avoid clusters overlapping as much as possible.
However, if number of samples and number of clusters are too high,
it is unlikely to separate them fully even if ``dist`` set to 1.0
random_state : int, RandomState instance or None, optional (default=None)
If int, random_state is the seed used by the random number generator;
If RandomState instance, random_state is the random number generator;
If None, the random number generator is the RandomState instance used
by `np.random`.
return_in_clusters : bool, optional (default=False)
If True, the function returns x_train, y_train, x_test, y_test each as
a list of numpy arrays where each index represents a cluster.
If False, it returns x_train, y_train, x_test, y_test each as numpy
array after joining the sequence of clusters arrays,
Returns
-------
X_train : numpy array of shape (n_train, n_features)
Training data.
y_train : numpy array of shape (n_train,)
Training ground truth.
X_test : numpy array of shape (n_test, n_features)
Test data.
y_test : numpy array of shape (n_test,)
Test ground truth.
File: c:\users\15745\anaconda3\lib\site-packages\pyod\utils\data.py
Type: function
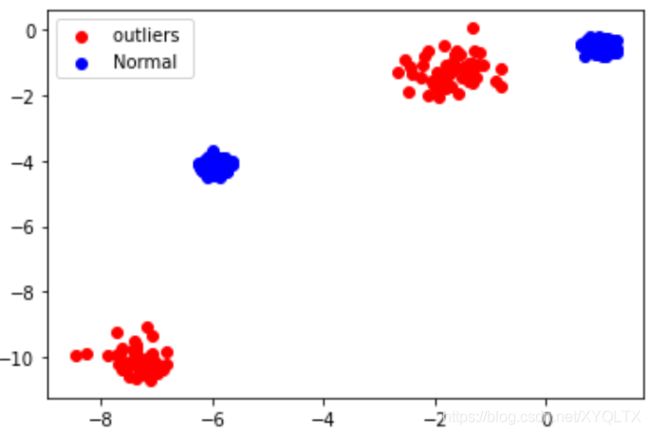
使用默认参数生成数据,并画图展示
import matplotlib.pyplot as plt
import pyod
a = pyod.utils.data.generate_data_clusters(n_train=1000,
n_test=500,
n_clusters=2,
n_features=2,
contamination=0.1,
size='same',
density='same',
dist=0.25,
random_state=None,
return_in_clusters=False,)
fig = plt.figure()
data1 = a[0][a[2]==1,:]
data2 = a[0][a[2]==0,:]
plt.scatter(data1[:,0], data1[:,1],c = 'r',marker = 'o')
plt.scatter(data2[:,0], data2[:,1],c = 'b',marker = 'o')
plt.legend(['outliers ', 'Normal'])
fig.show()
将生成的数据调用HBOS
from pyod.models.hbos import HBOS
#pyod.models.hbos.HBOS(alpha=0.1, contamination=0.1, n_bins=10, tol=0.5)
import sklearn
import pyod
import numpy as np
# 训练一个HBOS检测器
clf_name = 'HBOS'
clf = HBOS() # 初始化检测器clf
# 通过pyod.utils.data.generate_data创建一个toy数据
data = pyod.utils.data.generate_data(n_train=100,
n_test=50,
n_features=2,
contamination=0.1,
train_only=False,
offset=10,
behaviour='old',
random_state=None,)
X1 = data[0]
X2 = data[2]
X_train = np.r_[X1,X2]
clf.fit(X_train) # 使用X_train训练检测器clf
# 返回训练数据X_train上的异常标签和异常分值
y_train_pred = clf.labels_ # 返回训练数据上的分类标签 (0: 正常值, 1: 异常值)
y_train_scores = clf.decision_scores_ # 返回训练数据上的异常值 (分值越大越异常)
y_train_pred
#array([0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 1, 1, 1, 0, 1, 1, 1, 1, 1, 1, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0,
# 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 1, 0, 1, 1, 1])
HBOS函数的主要参数:
n_bins (int, optional (default=10)) - bin的数量
alpha (float in (0, 1), optional (default=0.1)) 用于防止溢出的正则。
tol (float in (0, 1), optional (default=0.1)) 该参数决定的灵活性,同时处理落入箱之外的样本。