java zookeeper 主从热备_zookeeper 核心原理
zookeeper 核心原理
1、了解zookeeper的设计
2、zookeeper集群角色
3、深入分析ZAB协议
4、从源码层面分析leader选举的实现过程
5、关于zookeeper的数据存储
6、关于zookeeper数据存储
zookeeper 的由来
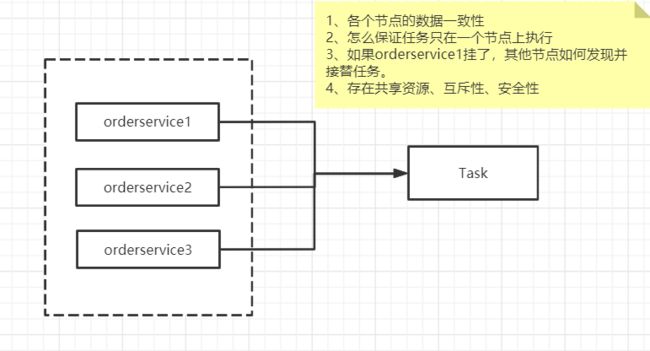
zookeeper的设计
防止单点故障
集群方案(leader、follower)、还能分担请求
每个节点的数据是一致的
leader、master、redis-cluster
leader挂了怎么办?数据如何恢复
选举机制
如何去保证数据一致性?(分布式事务)
2PC
结论:
zab来实现选举:集群内选举leader来调度简化集群的复杂度,
为什么要做集群:保证zookeeper协调工具的高性能和高可用(热备,同步)
2pc做数据一致性:引入了协调者(leader)和参与者(follower)的概念。
zookeeper 集群
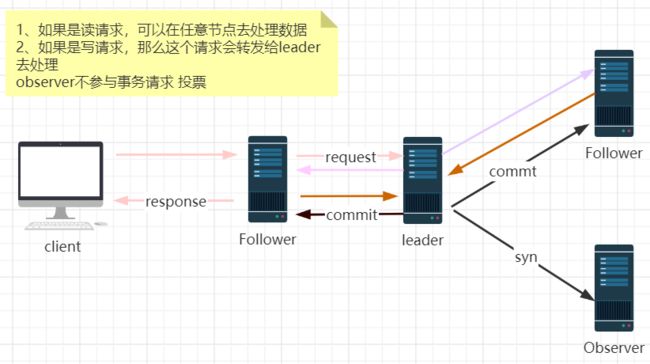
1. follower:处理读请求,转发写请求给leader
2. leader接收到事务请求后会转发提议给集群中的每一个节点(observer除外)
3. follwer节点收到提议后响应,返回ack
4. leader收到过半节点响应ack,便会提交事务(commit),给客户端一个response。反之会执行回滚。
5. 事务提交后会同步给Observer
3种角色特性:
leader:集群的核心,起到了主导整个集群的作用,事务请求的调度和处理。
follower:处理客户端的非事务请求,转发事务请求,参与事务的投票过程,参与leader选举投票
observer:观察者角色,了解集群中的状态变化,进行状态同步。可以响应非事务请求。
备注:observer与follwer工作原理一致,区别是不参与事务请求的投票,投票会影响性能。
当引入更多节点提升性能时候,多投票,多网络请求,但observer可以在不投票不增加网络请求的情况下提升性能,所以引入了observer。
Zookeeper集群中服务器数量的增加,会影响集群中写数据的性能,因为集群中是使用2PC协议,索引当更新节点的时候,需要半数已经的机器的ack才会执行commit操作。机器的增加,势必会增加收集ack的时间。Observer在不影响集群中事务处理能力的前提下,扩展Zookeeper提高集群中的非事务的处理能力。
1、观察zk集群的服务器的状态,并将状态同步到observer服务器上。
2、处理客户端的非事务请求,转发事务请求给leader
3、不参与任何投票(与follow的区别)
节点数:2n+1节点,至少n+1个可用,满足投票机制过半机制的需要,所以是最少三个,奇数节点。
server.1=192.168.1.103:2888:3181
server.2=192.168.1.104:2888:3181
server.3=192.168.1.106:2888:3181
server.4=192.168.1.102:2888:3181
ZAB 协议
ZAB(zookeeper atomic Broadcast)协议是为分布式协调服务zookeeper专门设计的一种支持崩溃恢复的原子广播协议,主要用于实现分布式数据一致性,通过主备模式的系统架构来保持集群中各个副本之间的数据一致性。
支持崩溃恢复的原子广播协议、主要用于实现数据一致性,
ZAB协议的两个基本模式,也是zab核心:
崩溃恢复
原子广播
注意:
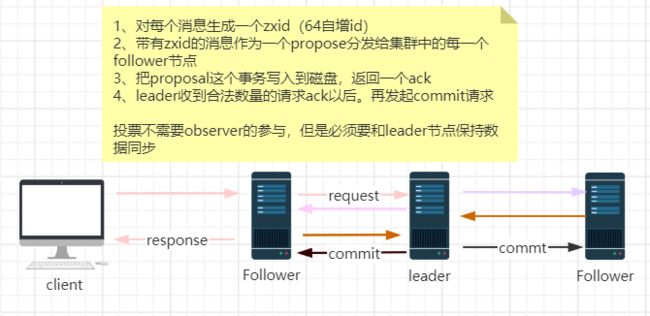
投票是所有节点参与的,leader自己也不例外
但所有投票过程不需要observer ,但observer必须要和leader节点保持数据同步,保证正确的处理非事务请求。
消息广播
改进版2PC
崩溃恢复(对数据层来说)
1、当leader失去了过半的follower节点的联系
2、当leader服务挂了
集群就会进入崩溃恢复阶段对于数据恢复来说
1、已经被处理的消息不能丢失
当leader收到合法数量的follower的ack以后,就会向各个follower广播消息(commit命令),同时自己也会commit这条事务消息,如果follower节点收到commit命令之前。leader挂了,会导致部分节点收到commit,部分节点没有收到,那么**zab协议需要保证已经被处理的消息不能丢失。**
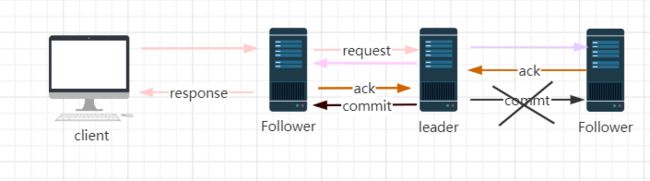
2、被丢弃的消息不能再次出现
当leader收到事务请求,并且还未发起事务投票之前,leader挂了;怎么办?
旧的leader带领的上个朝代没有提交的事务会被全部丢弃。
**此时zab协议要保证被丢弃的消息不能再出现。**
**zab 的设计思想**
为了满足上面的两个原则,zab做了如下的设计:
1. zxid(消息id)是最大的。(新选举的leader的zxid是最大的,保证当前节点的消息是最新的)。
比如leader挂了之后,follwer1收到了commit请求,follwer1的zxid就是最新的,最大的,follwer2没有收到commit请求,zxid不是最大的,选举时候依旧选举zxid是最大的那个节点作为leader,follwer1的提交之前的commit请求可以保证数据时最新的,不丢失,由此满足了上面的第一条原则。
2. epoch的概念,每产生一个leader,那么新的leader的epoch会+1,zxid是64位的数据,低32位表示消息计数器(自增),高32位(存储epoch编号)。tips:epoch概念可以联想各个朝代皇帝的年号。
tips:
新选举的leader的epoch会比上一轮leader的epoch高,这样保证上一轮leader再起来之后本一轮不会被选举成为leader,而变成了一个follwer,而且旧的leader的zxid会小于新leader的zxid,新的leader继任之后会把旧的leader所有没提交的事务清除,由此满足了上面的第二条原则。
疑问如下:
2. 临时节点使用场景:分布式锁;既然有持久化节点;
3. 为什么需要有临时节点存在; 提升集群性能、客户端断开连接临时节点会自动删除,减少网络开销
leader选举
基于fastleader选举:
1、选举指标
zxid 最大设置为leader 64位,
myid(服务器id,sid)【myid越大,在leader选举机制中权重越大】
2、选举阶段
启动时
运行时崩溃后
epoch (每一轮投票,epoch都会递增)
选举状态
graph LR
LOKING[LOKING]--> LEADING[LEADING] --> FOLLOWING[FOLLOWING] --> OBSERVING[OBSERVING]
启动的时候初始化
(myid,zxid,epoch)
检查zxid
myid
统计投票
判断epoch
zxid
再判断myid
QuorumPeer
Leader选举源码分析
看QuormPeerMain的 main.initializeAndRun(args)
1 protected void initializeAndRun(String[] args) throwsConfigException, IOException, AdminServerException {2 //用来保存全局配置
3 QuorumPeerConfig config = newQuorumPeerConfig();4 if (args.length == 1) {5 //args[0] -> zoo.cfg, 解析配置文件并保存到 QuorumPeerConfig
6 config.parse(args[0]);7 }8 //Start and schedule the the purge task9 //启动一个定时任务清理日志
10 DatadirCleanupManager purgeMgr = newDatadirCleanupManager(11 config.getDataDir(),12 config.getDataLogDir(),13 config.getSnapRetainCount(),14 config.getPurgeInterval());15 purgeMgr.start();16 //判断是否standalone模式,或是集群
17 if (args.length == 1 &&config.isDistributed()) {18 runFromConfig(config);19 } else{20 LOG.warn("Either no config or no quorum defined in config, running in standalone mode");21 //there is only server in the quorum -- run as standalone
22 ZooKeeperServerMain.main(args);23 }24 }
看runFromConfig 是怎么处理的
1 protected void initializeAndRun(String[] args) throwsConfigException, IOException, AdminServerException {2 //用来保存全局配置
3 QuorumPeerConfig config = newQuorumPeerConfig();4 if (args.length == 1) {5 //args[0] -> zoo.cfg, 解析配置文件并保存到 QuorumPeerConfig
6 config.parse(args[0]);7 }8 //Start and schedule the the purge task9 //启动一个定时任务清理日志
10 DatadirCleanupManager purgeMgr = newDatadirCleanupManager(11 config.getDataDir(),12 config.getDataLogDir(),13 config.getSnapRetainCount(),14 config.getPurgeInterval());15 purgeMgr.start();16 //判断是否standalone模式,或是集群
17 if (args.length == 1 &&config.isDistributed()) {18 runFromConfig(config);19 } else{20 LOG.warn("Either no config or no quorum defined in config, running in standalone mode");21 //there is only server in the quorum -- run as standalone
22 ZooKeeperServerMain.main(args);23 }24 }
看runFromConfig 是怎么处理的
1 public void runFromConfig(QuorumPeerConfig config) throwsIOException, AdminServerException {2 try{3 ManagedUtil.registerLog4jMBeans();4 } catch(JMException e) {5 LOG.warn("Unable to register log4j JMX control", e);6 }7
8 LOG.info("Starting quorum peer, myid=" +config.getServerId());9 MetricsProvider metricsProvider; //指标数据
10 try{11 metricsProvider =MetricsProviderBootstrap.startMetricsProvider(12 config.getMetricsProviderClassName(),13 config.getMetricsProviderConfiguration());14 } catch(MetricsProviderLifeCycleException error) {15 throw new IOException("Cannot boot MetricsProvider " +config.getMetricsProviderClassName(), error);16 }17 try{18 ServerMetrics.metricsProviderInitialized(metricsProvider);19 //这个和2181端口监听有关系20 //ClientCnxn(客户端和服务端进行网络交互的类)21 //ServerCnxn(服务端网络通信处理类)
22 ProviderRegistry.initialize();23 ServerCnxnFactory cnxnFactory = null;24 ServerCnxnFactory secureCnxnFactory = null;25 //为客户端提供读写的server,也就是2181这个端口的访问功能
26 if (config.getClientPortAddress() != null) {27 cnxnFactory =ServerCnxnFactory.createFactory();28 cnxnFactory.configure(config.getClientPortAddress(), config.getMaxClientCnxns(), config.getClientPortListenBacklog(), false);29 }30
31 if (config.getSecureClientPortAddress() != null) {32 secureCnxnFactory =ServerCnxnFactory.createFactory();33 secureCnxnFactory.configure(config.getSecureClientPortAddress(), config.getMaxClientCnxns(), config.getClientPortListenBacklog(), true);34 }35 //zk逻辑主线程、负责选举、投票
36 quorumPeer =getQuorumPeer();37 quorumPeer.setTxnFactory(newFileTxnSnapLog(config.getDataLogDir(), config.getDataDir()));38 quorumPeer.enableLocalSessions(config.areLocalSessionsEnabled());39 quorumPeer.enableLocalSessionsUpgrading(config.isLocalSessionsUpgradingEnabled());40 //quorumPeer.setQuorumPeers(config.getAllMembers());
41 quorumPeer.setElectionType(config.getElectionAlg()); //采用什么选举算法
42 quorumPeer.setMyid(config.getServerId()); //myId(sid,myid)
43 quorumPeer.setTickTime(config.getTickTime()); //心跳时间间隔(2000)
44 quorumPeer.setMinSessionTimeout(config.getMinSessionTimeout());45 quorumPeer.setMaxSessionTimeout(config.getMaxSessionTimeout());46 quorumPeer.setInitLimit(config.getInitLimit()); //数据初始化的时长
47 quorumPeer.setSyncLimit(config.getSyncLimit()); //数据同步时长
48 quorumPeer.setConnectToLearnerMasterLimit(config.getConnectToLearnerMasterLimit());49 quorumPeer.setObserverMasterPort(config.getObserverMasterPort());50 quorumPeer.setConfigFileName(config.getConfigFilename());51 quorumPeer.setClientPortListenBacklog(config.getClientPortListenBacklog());52 quorumPeer.setZKDatabase(newZKDatabase(quorumPeer.getTxnFactory()));53 quorumPeer.setQuorumVerifier(config.getQuorumVerifier(), false);54 if (config.getLastSeenQuorumVerifier() != null) {55 quorumPeer.setLastSeenQuorumVerifier(config.getLastSeenQuorumVerifier(), false);56 }57 quorumPeer.initConfigInZKDatabase(); //初始化内存数据库 ->磁盘持久化
58 quorumPeer.setCnxnFactory(cnxnFactory);59 quorumPeer.setSecureCnxnFactory(secureCnxnFactory);60 quorumPeer.setSslQuorum(config.isSslQuorum());61 quorumPeer.setUsePortUnification(config.shouldUsePortUnification());62 quorumPeer.setLearnerType(config.getPeerType());63 quorumPeer.setSyncEnabled(config.getSyncEnabled());64 quorumPeer.setQuorumListenOnAllIPs(config.getQuorumListenOnAllIPs());65 if(config.sslQuorumReloadCertFiles) {66 quorumPeer.getX509Util().enableCertFileReloading();67 }68 quorumPeer.setMultiAddressEnabled(config.isMultiAddressEnabled());69 quorumPeer.setMultiAddressReachabilityCheckEnabled(config.isMultiAddressReachabilityCheckEnabled());70 quorumPeer.setMultiAddressReachabilityCheckTimeoutMs(config.getMultiAddressReachabilityCheckTimeoutMs());71
72 //sets quorum sasl authentication configurations
73 quorumPeer.setQuorumSaslEnabled(config.quorumEnableSasl);74 if(quorumPeer.isQuorumSaslAuthEnabled()) {75 quorumPeer.setQuorumServerSaslRequired(config.quorumServerRequireSasl);76 quorumPeer.setQuorumLearnerSaslRequired(config.quorumLearnerRequireSasl);77 quorumPeer.setQuorumServicePrincipal(config.quorumServicePrincipal);78 quorumPeer.setQuorumServerLoginContext(config.quorumServerLoginContext);79 quorumPeer.setQuorumLearnerLoginContext(config.quorumLearnerLoginContext);80 }81 quorumPeer.setQuorumCnxnThreadsSize(config.quorumCnxnThreadsSize);82 quorumPeer.initialize();83
84 if(config.jvmPauseMonitorToRun) {85 quorumPeer.setJvmPauseMonitor(newJvmPauseMonitor(config));86 }87 //启动主线程
88 quorumPeer.start();89 ZKAuditProvider.addZKStartStopAuditLog();90 quorumPeer.join();91 } catch(InterruptedException e) {92 //warn, but generally this is ok
93 LOG.warn("Quorum Peer interrupted", e);94 } finally{95 if (metricsProvider != null) {96 try{97 metricsProvider.stop();98 } catch(Throwable error) {99 LOG.warn("Error while stopping metrics", error);100 }101 }102 }103 }
启动主线程,QuorumPeer 重写了 Thread.start 方法,我们接下来看start方法里面发生了什么?
调用 QUORUMPEER 的 START 方法
1 @Override2 public synchronized void start() { //重写线程start方法
3 if (!getView().containsKey(myid)) {4 throw new RuntimeException("My id " + myid + " not in the peer list");5 }6 loadDataBase(); //从磁盘加载数据
7 startServerCnxnFactory(); //这里来启动2181端口监听,ServerSocketChannel
8 try{9 adminServer.start();10 } catch(AdminServerException e) {11 LOG.warn("Problem starting AdminServer", e);12 System.out.println(e);13 }14 startLeaderElection(); //开启leader选举
15 startJvmPauseMonitor(); //启动监控
16 super.start(); //启动线程
17 }
loaddatabase, 主要是从本地文件中恢复数据,以及获取最新的 zxid
1 private voidloadDataBase() {2 try{3 zkDb.loadDataBase(); //从本地文件加载数据4
5 //load the epochs6 //从最新的zxid恢复epoch变量、zxid64位,前32位是epoch的值,后32位是zxid
7 long lastProcessedZxid =zkDb.getDataTree().lastProcessedZxid;8 long epochOfZxid =ZxidUtils.getEpochFromZxid(lastProcessedZxid);9 try{10 //从文件中读取当前的epoch
11 currentEpoch =readLongFromFile(CURRENT_EPOCH_FILENAME);12 } catch(FileNotFoundException e) {13 //pick a reasonable epoch number14 //this should only happen once when moving to a15 //new code version
16 currentEpoch =epochOfZxid;17 LOG.info(18 "{} not found! Creating with a reasonable default of {}. "
19 + "This should only happen when you are upgrading your installation",20 CURRENT_EPOCH_FILENAME,21 currentEpoch);22 writeLongToFile(CURRENT_EPOCH_FILENAME, currentEpoch);23 }24 if (epochOfZxid >currentEpoch) {25 throw new IOException("The current epoch, "
26 +ZxidUtils.zxidToString(currentEpoch)27 + ", is older than the last zxid, "
28 +lastProcessedZxid);29 }30 try{31 //从文件中读取接收的epoch
32 acceptedEpoch =readLongFromFile(ACCEPTED_EPOCH_FILENAME);33 } catch(FileNotFoundException e) {34 //pick a reasonable epoch number35 //this should only happen once when moving to a36 //new code version
37 acceptedEpoch =epochOfZxid;38 LOG.info(39 "{} not found! Creating with a reasonable default of {}. "
40 + "This should only happen when you are upgrading your installation",41 ACCEPTED_EPOCH_FILENAME,42 acceptedEpoch);43 writeLongToFile(ACCEPTED_EPOCH_FILENAME, acceptedEpoch);44 }45 if (acceptedEpoch
47 +ZxidUtils.zxidToString(acceptedEpoch)48 + " is less than the current epoch, "
49 +ZxidUtils.zxidToString(currentEpoch));50 }51 } catch(IOException ie) {52 LOG.error("Unable to load database on disk", ie);53 throw new RuntimeException("Unable to run quorum server ", ie);54 }55 }
退出loaddatabase,我们看初始化 LEADERELECTION
1 public synchronized voidstartLeaderElection() {2 try{3 //得到当前节点的状态,如果是 LOOKING
4 if (getPeerState() ==ServerState.LOOKING) {5 //构建一个Vote(myid、zxid、epoch)
6 currentVote = newVote(myid, getLastLoggedZxid(), getCurrentEpoch());7 }8 } catch(IOException e) {9 RuntimeException re = newRuntimeException(e.getMessage());10 re.setStackTrace(e.getStackTrace());11 throwre;12 }13 //根据electionType来创建选举算法
14 this.electionAlg =createElectionAlgorithm(electionType);15 }
配置选举算法,选举算法有 3 种,可以通过在 zoo.cfg 里面进行配置,默认是 fast 选举
1 protected Election createElectionAlgorithm(intelectionAlgorithm) {2 Election le = null;3
4 //TODO: use a factory rather than a switch
5 switch(electionAlgorithm) {6 case 1:7 throw new UnsupportedOperationException("Election Algorithm 1 is not supported.");8 case 2:9 throw new UnsupportedOperationException("Election Algorithm 2 is not supported.");10 case 3:11 //cnxn(和网络有关的一个类,ServerCnxn、ClientCnxn)12 //QuorumCnxManager 管理集群选举和投票相关的操作
13 QuorumCnxManager qcm =createCnxnManager();14 QuorumCnxManager oldQcm =qcmRef.getAndSet(qcm);15 if (oldQcm != null) { //判断是否已经开启选举
16 LOG.warn("Clobbering already-set QuorumCnxManager (restarting leader election?)");17 oldQcm.halt(); //种植掉当前的选举
18 }19 //监听集群中的票据
20 QuorumCnxManager.Listener listener =qcm.listener;21 if (listener != null) {22 listener.start();23 //初始化了FastLeaderElection
24 FastLeaderElection fle = new FastLeaderElection(this, qcm);25 fle.start(); //启动leader选举
26 le =fle;27 } else{28 LOG.error("Null listener when initializing cnx manager");29 }30 break;31 default:32 assert false;33 }34 returnle;35 }
启动leader选举
1 voidstart() {2 /**
3 * 启动两个线程4 * wsThread 业务层发送线程,将消息发送给IO负责类 QuorumCnxManger5 * 启动业务层接受线程,从IO负责类 QuorumCnxManger 接收消息6 */
7 this.wsThread.start();8 this.wrThread.start();9 }
投票过程
1、检查节点状态是looking时投票给自己、投票逻辑源码在FastLeaderElection类的lookforleader(),可以自己再细看源码
各个节点互相广播vode信息(myid,zxid,epoch)
先判断epoch,再判断zxid,再判断myid
胜出的投票会更新到当前的结果中。
继续广播,让其他节点知道自己现在的票据(告诉别人胜出的那个票据信息)。
epoch更新,进行下一轮选举
如果收到的消息epoch小于当前节点的epoch,则忽略这条消息(忽略旧的投票参数)
epoch相同时比较zxid,myid,如果胜出就更新自己的票据,并发出广播
投票的结果都蠢到本机的投票集合中,用来判断是不是超过半数
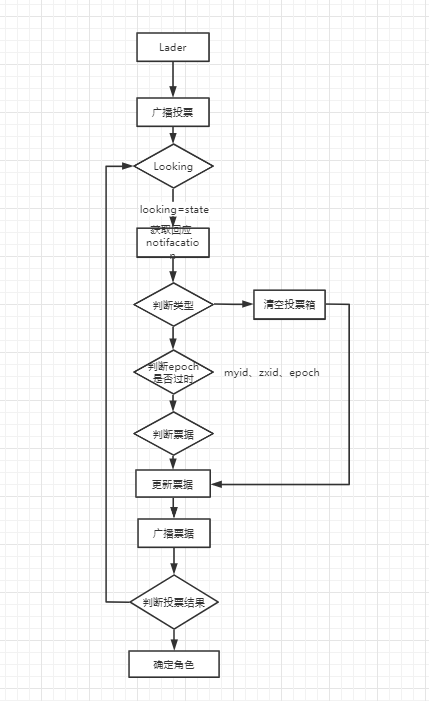
// 1、判断消息里的epoch是不是比当前的大,如果大则消息中id对应的服务器就是leader
// 2、如果epoch相等则判断zxid,如果消息里的zxid大,则消息中id对应的服务器就是leader
// 3、如果前面两个都相等那就比较服务器id,如果大,则其就是leader
return ((newEpoch > curEpoch)
|| ((newEpoch == curEpoch)
&& ((newZxid > curZxid)
|| ((newZxid == curZxid)
&& (newId > curId)))));