Python:自适应滤波器简介及其实现方法

Python:自适应滤波器概述及其实现方法
-
-
- 一、自适应滤波器简介
-
- 1.1 自适应滤波器原理、特点、分类及其作用
- 1.2 自适应滤波器的数学表示方法[^2]
- 二、不同类型自适应滤波器的代码实现[^3]
-
- 2.1 时域自适应滤波器算法的实现
-
- 2.1.1 LMS自适应滤波器算法的实现
- 2.2.2 NLMS自适应滤波器算法的实现
- 2.3.3 RLS自适应滤波器算法的实现
- 2.2 频域自适应滤波器NLMS算法的实现
-
- 实现自适应滤波器的 ✨ 最多的两个 Github 仓库:
- ✨ 回声消除自适应滤波器设计包:ewan-xu/pyaec: simple and efficient python implemention of a series of adaptive filters. including time domain adaptive filters(lms、nlms、rls、ap、kalman)、nonlinear adaptive filters(volterra filter、functional link adaptive filters)、frequency domain adaptive filters(frequency domain adaptive filter、frequency domain kalman filter) for acoustic echo cancellation.
- 另一个自适应滤波器(该包实现的自适应滤波器比较少,但是说明详细):Wramberg/adaptfilt: Adaptive filtering module for Python
✨ 注意:我写这篇博客的目的是学习,如果真感兴趣可以参考文章最后的参考文献11(大神写的)。
一、自适应滤波器简介
1.1 自适应滤波器原理、特点、分类及其作用
自适应滤波器是利用前一时刻滤波器参数,自动调整当前时刻滤波器参数,以适应信号随时间变化的统计特征,从而实现最优滤波,其原理如下图所示:
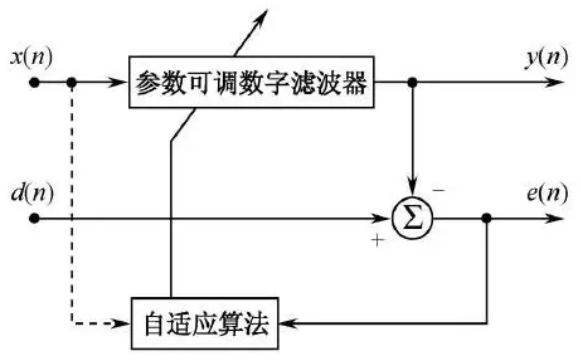
- x ( n ) x(n) x(n)为输入信号;
- d ( n ) d(n) d(n)为期望信号;
- y ( n ) y(n) y(n)为输入信号通过参数可调数字滤波器(自适应滤波器)的输出信号;
- e ( n ) e(n) e(n)为误差信号。
自适应滤波器的原理如下所示:
- 输入信号 x ( n ) x(n) x(n)通过参数通过自适应滤波器(Adaptive Filter)后产生输出信号 y ( n ) y(n) y(n),将其与期望信号 d ( n ) d(n) d(n)进行比较,形成误差信号 e ( n ) e(n) e(n),通过自适应算法对滤波器参数进行调节,最终使 e ( n ) e(n) e(n)的均方值最小。
- 自适应滤波可以利用前一时刻已知滤波器参数的结果,自动调节当前时刻的滤波器参数,以适应信号随时间变化的统计特性,从而实现最优滤波。
自适应滤波器的特点:
(1)无需提取信息的先验统计特性;
(2)直接利用观测数据,并依据某种判据在观测过程中不断递归更新;
(3)最优化。
自适应滤波器的分类:
(1)按结构分类:横向结构、格型结构;
(2)按算法分类:随机梯度、最小二乘法;
(3)按处理方式分类:成批处理、递归处理。
常用的两类自适应滤波器包括维纳滤波器与卡尔曼滤波器:
- 维纳滤波器: 其参数是固定的,适用于平稳随机过程;
- 卡尔曼滤波器: 其参数时变的,适用于非平稳过程。
- 自适应滤波器的作用:
自适应滤波器是应用于未知信号的滤波器,在实际应用中,困难在于信号模型是未知的,所以自适应滤波器的关键是寻找一种算法,使系数能以满足实际需求的精度与速度趋近于分段近似平稳滤波器的稳态权系数。
1.2 自适应滤波器的数学表示方法2
自适应滤波器的详细模型如下图(图片来源)所示:
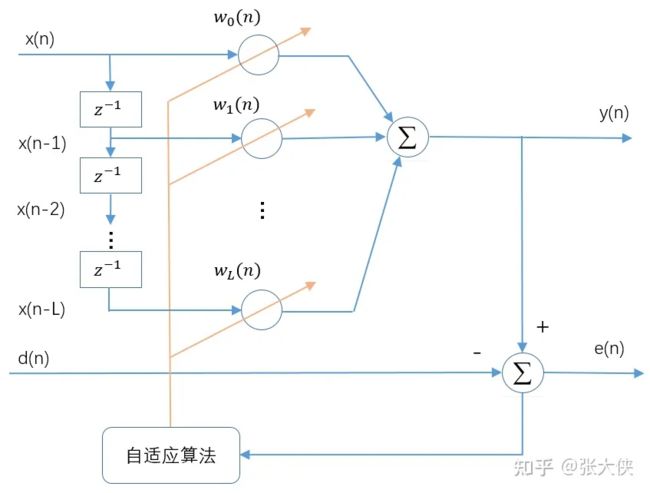
输入信号:
x ( n ) = [ x ( n ) , x ( n − 1 ) , . . . , x ( n − L ) ] T {\bm x}(n) = [x(n), x(n-1), ..., x(n-L)]^T x(n)=[x(n),x(n−1),...,x(n−L)]T
输出信号:
y ( n ) = ∑ k = 0 L w k ( n ) x ( n − k ) {\bm y}(n) = \sum_{k=0}^Lw_k(n)x(n-k) y(n)=k=0∑Lwk(n)x(n−k)
自适应线性组合器的 L + 1 L+1 L+1个权系数构成一个权重系数适量,称为权重适量,用 w ( n ) {\bm w}(n) w(n)表示:
w = [ w 0 ( n ) , w 1 ( n ) , . . . , w L ( n ) ] T {\bm w}=[w_0(n), w_1(n), ..., w_L(n)]^T w=[w0(n),w1(n),...,wL(n)]T
因此, y ( n ) y(n) y(n)可以表示为:
y ( n ) = x T ( n ) w ( n ) = w T ( n ) x ( n ) {\bm y}(n) = {\bm x}^T(n){\bm w}(n) = {\bm w}^T(n){\bm x}(n) y(n)=xT(n)w(n)=wT(n)x(n)
误差信号为:
e ( n ) = d ( n ) − y ( n ) = d ( n ) − x T ( n ) w ( n ) = d ( n ) − w T ( n ) x ( n ) e(n)=d(n)-y(n)=d(n)-x^T(n)w(n)=d(n)-{\bm w}^T(n){\bm x}(n) e(n)=d(n)−y(n)=d(n)−xT(n)w(n)=d(n)−wT(n)x(n)
自适应线性组合器采用误差信号 e ( n ) e(n) e(n)均方值最小的准则,即:
ξ ( n ) = E [ e 2 ( n ) ] = E [ d 2 ( n ) ] + w T ( n ) E [ x ( n ) x T ( n ) ] w ( n ) − 2 E [ d ( n ) x T ( n ) ] w ( n ) \xi(n) = E[e^2(n)]=E[d^2(n)]+{\bm w}^T(n)E[{\bm x}(n){\bm x}^T(n)]{\bm w}(n) \\ -2E[d(n){\bm x}^T(n)]{\bm w}(n) ξ(n)=E[e2(n)]=E[d2(n)]+wT(n)E[x(n)xT(n)]w(n)−2E[d(n)xT(n)]w(n)
输入信号 x ( n ) {\bm x}(n) x(n)的自相关矩阵 R \bf R R为:
R = E [ x ( n ) x T ( n ) ] = [ E [ x ( n ) x ( n ) ] , E [ x ( n ) x ( n − 1 ) ] , . . . , E [ x ( n ) x ( n − L ) ] E [ x ( n − 1 ) x ( n ) ] , E [ x ( n − 1 ) x ( n − 1 ) ] , . . . , E [ x ( n − 1 ) x ( n − L ) ] ⋮ E [ x ( n − L ) x ( n ) ] , E [ x ( n − L ) x ( n − 1 ) ] , . . . , E [ x ( n − L ) x ( n − L ) ] ] \begin{aligned}{\bf R} &= E[{\bm x}(n){\bm x}^T(n)] \\ &= \begin{bmatrix} E[x(n)x(n)], E[x(n)x(n-1)], ..., E[x(n)x(n-L)] \\ E[x(n-1)x(n)], E[x(n-1)x(n-1)], ..., E[x(n-1)x(n-L)] \\ \vdots \\ E[x(n-L)x(n)], E[x(n-L)x(n-1)], ..., E[x(n-L)x(n-L)] \end{bmatrix} \end{aligned} R=E[x(n)xT(n)]=⎣ ⎡E[x(n)x(n)],E[x(n)x(n−1)],...,E[x(n)x(n−L)]E[x(n−1)x(n)],E[x(n−1)x(n−1)],...,E[x(n−1)x(n−L)]⋮E[x(n−L)x(n)],E[x(n−L)x(n−1)],...,E[x(n−L)x(n−L)]⎦ ⎤
期望信号 d ( n ) d(n) d(n)与输入信号 x ( n ) {\bm x}(n) x(n)的互相关矩阵 P \bf P P为:
P = E [ d ( n ) x ( n ) ] = E [ d ( n ) x ( n ) , d ( n ) x ( n − 1 ) , . . . , d ( n ) x ( n − L ) ] \begin{aligned} {\bf P}&=E[d(n){\bm x}(n)] \\ &=E[d(n)x(n), d(n)x(n-1), ..., d(n)x(n-L)] \end{aligned} P=E[d(n)x(n)]=E[d(n)x(n),d(n)x(n−1),...,d(n)x(n−L)]
将自相关矩阵 R \bf R R与互相关矩阵 P \bf P P带入 ξ \xi ξ,得到均方误差的简单表达形式:
ξ ( n ) = E [ d 2 ( n ) ] + w T R w − 2 P T w \xi(n) = E[d^2(n)]+{\bm w}^T{\bf R}{\bm w} - 2{\bf P}^T{\bm w} ξ(n)=E[d2(n)]+wTRw−2PTw
由上式可以得出,在输入信号与参考响应都是平稳随机信号的前提下,均方误差是权重适量的各分量的二次函数。该函图像是一个 L + 2 L+2 L+2维空间中那个一个中间下凹的超抛物面,有唯一的最低点,该曲面称为均方误差性能曲面,简称性能曲面。
均方误差性能曲面 ξ \xi ξ的梯度为:
∇ = ∂ ξ ∂ w = 2 R w − 2 P \nabla = \frac{\partial \xi}{\partial w} = 2{\bf R}{\bm w} - 2{\bf P} ∇=∂w∂ξ=2Rw−2P
另, ∇ = 0 \nabla = 0 ∇=0,可以得到最小均方误差对应而最优权重适量 W ∗ \bm W^* W∗(也称为维纳解),即 w ∗ = R − 1 P {\bm w^*} = {\bf R^{-1}}{\bf P} w∗=R−1P。
虽然维纳解的表达式我们可以通过上面的数学推导得到,但是在实际应用存在如下问题:
- 需要知道自相关矩阵 R \bf R R与互相关矩阵 P \bf P P,但是由于输入信号 x ( n ) { \bm x}(n) x(n)是不确定的,所以无从获得 R \bf R R与 P \bf P P;
- 矩阵的逆计算量大: O ( n 3 ) O(n^3) O(n3);
- 如果信号非平稳,则 R \bf R R与 P \bf P P每次都不一样,需要重复计算。
这也是为什么要设计不同的自适应滤波器算法的原因。
二、不同类型自适应滤波器的代码实现3
对于自适应滤波器的算法可以分为时域与频域两类,本文展示如下两类自适应滤波器:
- 时域自适应滤波器:LMS、NLMS、RLS
- 频域自适应滤波器:NLMS
2.1 时域自适应滤波器算法的实现
2.1.1 LMS自适应滤波器算法的实现
LMS自适滤波器算法流程为:
y ( n ) = w T ( n ) x ( x ) e ( n ) = d ( n ) − y ( n ) w ( n + 1 ) = w ( n ) + 2 μ e ( n ) x ( n ) \begin{aligned} &{\bm y}(n) = {\bm w}^T(n){\bm x}(x) \\ &{\bm e}(n) = d(n) - y(n) \\ &{\bm w}(n+1) = {\bm w}(n) + 2\mu e(n){\bm x}(n) \end{aligned} y(n)=wT(n)x(x)e(n)=d(n)−y(n)w(n+1)=w(n)+2μe(n)x(n)
LMS自适滤波器实现代码如下所示:
import numpy as np
def lms(x, d, N=4, mu=0.1):
"""LMS (Least Mean Squares) 滤波器
Args:
x (_type_): 输入信号
d (_type_): 期望信号
N (int, optional): (个人理解)滤波器长度. Defaults to 4.
mu (float, optional): 迭代步长. Defaults to 0.1.
返回值:
e (_type_): 误差信号
"""
# LMS迭代步数
n_Iters = min(len(x), len(d)) - N
u = np.zeros(N) # 每次输入自适应滤波器的信号
w = np.zeros(N) # 滤波器权重系数
e = np.zeros(n_Iters) # 误差信号
for n in range(n_Iters):
# 下面两条指令将输入信号 u 转换为
# [当前信号, 前一个信号, 前两个信号, ..., 前N-1个信号]的格式
u[1:] = u[:-1]
u[0] = x[n]
# 根据LMS方法计算每次迭代的误差信号
e_n = d[n] - np.dot(u, x)
# 根据当前误差e、步长u、输入信号u更新滤波器权重w
w = w + mu * e_n * u
# 存储每次迭代误差e_n到误差向量e中
e[n] = e_n
return e
LMS的优点: 算法简单易于实现,算法复杂度低,能够抑制旁瓣效应。
LMS的缺点:
- (1) 收敛速度慢,由于LMS滤波器系数更新都是逐点进行的,每次采样点梯度估计对句真实梯度存在误差,导致滤波器系数的每次更新不会按照真实的梯度方向更新,从而导致收敛速度慢。
(2) 跟踪性能较差,并且随着滤波器阶数(步长参数)升高,系统的稳定性下降
(3) LMS要求不同时刻的输入向量 x ( n ) x(n) x(n)线性无关(LMS的独立性假设)。如果输入信号存在相关性,会导致前一次迭代产生的梯度噪声传播到下一次迭代,从而导致误差的反向传播,收敛速度变慢,跟踪性能差。
2.2.2 NLMS自适应滤波器算法的实现
- NLMS自适应滤波器算法对LMS算法输入信号做了归一化处理,并且可以采用变步长因子。与LMS相比,其收敛速度更快,而且计算量与LMS相当。
NLMS自适应滤波器算法流程为:
y ( n ) = w T ( n ) x ( x ) e ( n ) = d ( n ) − y ( n ) w ( n + 1 ) = w ( n ) + μ e ( n ) x ( n ) x H ( n ) x ( n ) \begin{aligned} &{\bm y}(n) = {\bm w}^T(n){\bm x}(x) \\ &{\bm e}(n) = d(n) - y(n) \\ &{\bm w}(n+1) = {\bm w}(n) + \frac{\mu e(n){\bm x}(n)}{{\bm x}^H(n){\bm x}(n)} \end{aligned} y(n)=wT(n)x(x)e(n)=d(n)−y(n)w(n+1)=w(n)+xH(n)x(n)μe(n)x(n)
NLMS自适应滤波器的实现代码如下所示:
import numpy as np
def nlms(x, d, N=4, mu=0.1):
"""NLMS (Normalized Least Mean Squares) 滤波器
Args:
x (_type_): 输入信号
d (_type_): 期望信号
N (int, optional): (个人理解)滤波器长度. Defaults to 4.
mu (float, optional): 迭代步长. Defaults to 0.1.
返回值:
e (_type_): 误差信号
"""
# NLMS迭代步数
n_Iters = min(len(x), len(d)) - N
u = np.zeros(N) # 每次输入自适应滤波器的信号
w = np.zeros(N) # 滤波器权重系数
e = np.zeros(n_Iters) # 误差信号
for n in range(n_Iters):
# 下面两条指令将输入信号 u 转换为
# [当前信号, 前一个信号, 前两个信号, ..., 前N-1个信号]的格式
u[1:] = u[:-1]
u[0] = x[n]
# 根据LMS方法计算每次迭代的误差信号
e_n = d[n] - np.dot(u, x)
# 根据当前误差e、步长u、输入信号u更新滤波器权重w
w = w + mu * e_n * u / (np.dot(u, u) + 1e-3)
# 存储每次迭代误差e_n到误差向量e中
e[n] = e_n
return e
2.3.3 RLS自适应滤波器算法的实现
- RLS (Recursive Least Square) 算法为递归最小二乘法,是最小二乘法的一类快速算法,递归最小二乘自适应滤波器相对于LMS自适应滤波器横向滤波器具有更好的性能。
RLS与LMS相比,RLS最大的缺点是计算量较大,但是其收敛速度非常快。当环境噪声为平稳随机信号时,LMS算法效果明显,但当环境噪声为非平稳随机噪声时,LMS算法难以自适应跟踪统计特性不断变化的外界噪声,收敛效果一般。RLS算法能够该缺点,在非平稳的环境下获得满意的效果。
一个 p p p-th阶的RLS自适应滤波器的算法步骤如下所示:
- 参数:
p = filter order λ = forgetting factor δ = value to initialize P (0) \begin{aligned} &{\bm p} = \text{filter order} \\ &{\bm \lambda} = \text{forgetting factor} \\ &{\bm \delta} = \text{value to initialize {\bf P}(0)} \end{aligned} p=filter orderλ=forgetting factorδ=value to initialize P(0)
- 初始化:
w ( n ) = 0 x ( k ) = 0 , k = − p , . . . , − 1 , d ( k ) = 0 , k = − p , . . . , − 1 P ( 0 ) = δ I , where I is the identity matrix of rank p + 1 \begin{aligned} &{\bf w}(n) = 0 \\ &x(k) = 0, k = -p, ..., -1, \\ &d(k) = 0, k = -p, ..., -1 \\ &{\bf P}(0) = \delta {\bm I}, \text{where } {\bm I} \ \text{is the identity matrix of rank} \ p+1 \end{aligned} w(n)=0x(k)=0,k=−p,...,−1,d(k)=0,k=−p,...,−1P(0)=δI,where I is the identity matrix of rank p+1
- 对于 n = 1 , 2 , . . . n =1, 2, ... n=1,2,...执行如下计算过程:
x ( n ) = [ x ( n ) x ( n − 1 ) ⋮ x ( n − p ) ] e ( n ) = d ( n ) − x T ( n ) w ( n − 1 ) , g ( n ) = P ( n − 1 ) x ( n ) { λ + x T ( n ) P ( n − 1 ) x ( n ) } − 1 P ( n ) = λ − 1 P ( n − 1 ) − g ( n ) x T ( n ) λ − 1 P ( n − 1 ) w ( n ) = w ( n − 1 ) + e ( n ) g ( n ) \begin{aligned} &{\bf x}(n) = \begin{bmatrix} x(n) \\ x(n-1) \\ \vdots \\ x(n-p) \end{bmatrix} \\ &e(n) = d(n) - {\bf x}^T(n){\bf w}(n-1), \\ &{\bf g}(n) = {\bf P}(n-1){\bf x}(n)\{ \lambda + {\bf x}^T(n){\bf P}(n-1){\bf x}(n) \}^{-1} \\ &{\bf P}(n) = \lambda^{-1}{\bf P}(n-1) - {\bf g}(n){\bf x}^T(n)\lambda^{-1}{\bf P}(n-1) \\ &{\bf w}(n) = {\bf w}(n-1) + e(n){\bf g}(n) \end{aligned} x(n)=⎣ ⎡x(n)x(n−1)⋮x(n−p)⎦ ⎤e(n)=d(n)−xT(n)w(n−1),g(n)=P(n−1)x(n){λ+xT(n)P(n−1)x(n)}−1P(n)=λ−1P(n−1)−g(n)xT(n)λ−1P(n−1)w(n)=w(n−1)+e(n)g(n)
RLS自适应滤波器的实现代码如下所示:
import numpy as np
def rls(x, d, N=4, lmbd=0.999, delta=0.01):
"""RLS (Recursive Least Squares) 滤波器
Args:
x (_type_): 输入信号
d (_type_): 期望信号
N (int, optional): 滤波器长度. Defaults to 4.
lmbd (float, optional): 遗忘因子 (Forgetting Factor). Defaults to 0.999.
delta (float, optional): 初始化 P[0] 的单位矩阵. Defaults to 0.01.
返回值:
e (_type_): 误差信号
"""
# RLS迭代步数
n_Iters = min(len(x), len(d)) - N
lmbd_inv = 1/ lmbd # 遗忘因子的倒数
u = np.zeros(N) # 每次输入自适应滤波器的信号
w = np.zeros(N) # 滤波器权重系数
P = np.eye(N) * delta # 目前不清楚其具体内涵,将其理解为当成中算法间变量
e = np.zeros(n_Iters) # 误差信号
for n in range(n_Iters):
# 下面两条指令将输入信号 u 转换为
# [当前信号, 前一个信号, 前两个信号, ..., 前N-1个信号]的格式
u[1:] = u[:-1]
u[0] = x[n]
# 计算每次迭代的误差信号
e_n = d[n] - np.dot(u, x)
# 计算上面RLS算法中的g(n)
r = np.dot(P, u)
g = r / (lmbd + np.dot(u, r))
# 更新滤波器参数w与P
w = w + e_n * g
P = lmbd_inv * (P - np.outer(g, np.dot(u, P)))
# 存储每次迭代误差e_n到误差向量e中
e[n] = e_n
return e
2.2 频域自适应滤波器NLMS算法的实现
上面的三种自适应滤波器都是在时域中实现的,我们还可以通过通过OLS (Ordinary Least Square) 进行分段FFT计算卷积,以实现在频域中实现自适应滤波器。下面以NLMS算法为出发点,实现一种 Block NLMS 自适应滤波器,其算法流程如下所示:
u B , n = col u ( n B + B − 1 ) , . . . , u ( n B + 1 ) , u ( n B ) u 2 B , n ′ = F [ u B , n u B , n − 1 ] ≜ clo { u k ′ ( n ) , k = 0 , 1 , . . . , 2 B − 1 } λ k ( n ) = β λ k ( n − 1 ) + ( 1 − β ) ∣ u k ′ ( n ) ∣ 2 , k = 0 , 1 , . . . , 2 B − 1 u k , n ′ = [ u k ′ ( n ) … u k ′ ( n − M B + 1 ) ] , k = 0 , 1 , . . . , 2 B − 1 y k ′ ( n ) = u k , n ′ l k , n − 1 ′ , k = 0 , 1 , . . . , 2 B − 1 d ^ B , n = [ I B 0 B × B ] F ∗ col { y 0 ′ ( n ) , . . . , y 2 B − 1 ′ ( n ) } e B , n = d B , n − d ^ B , n e 2 B , n ′ = F [ I B 0 B × B ] e B , n ≜ col { e k ′ ( n ) , k = 0 , 1 , . . . , 2 B − 1 } l k , n = l k , n − 1 + μ λ k ( n ) u k , n ′ ∗ d k ( n ) ′ , k = 0 , 1 , . . . , 2 B − 1 [ l 0 , n c ⊺ l 1 , n c ⊺ ⋮ l 2 B − 1 , n c ⊺ ] = 1 2 B F ∗ [ I B 0 B × B ] F [ l 0 , n ⊺ l 1 , n ⊺ ⋮ l 2 B − 1 , n ⊺ ] \begin{aligned} &u_{B,n} = \text{col}{u(nB + B -1), ..., u(nB+1), u(nB)} \\ &u_{2B, n}' = F \begin{bmatrix} u_{B,n} \\ u_{B, n-1} \end{bmatrix} \triangleq \text{clo} \{ u_k'(n), k = 0, 1, ..., 2B-1 \} \\ & \\ \\ &\lambda_k(n) = \beta \lambda_k(n-1) + (1 - \beta)| u_k'(n) |^2, \ \ k = 0, 1, ..., 2B-1 \\ &u_{k, n}' = \big[ u_k'(n) \ \ \dots \ \ u_k'(n-\tfrac{M}{B}+1) \big], \ \ k = 0, 1, ..., 2B-1 \\ & y_k'(n) = u_{k,n}' l_{k, n-1}', \ \ k = 0, 1, ..., 2B-1 \\ \\ &\hat{d}_{B,n} = \big[ {\bf I}_B 0_{B \times B} \big] F^* \text{col} \{ y_0'(n), ..., y_{2B-1}'(n) \} \\ &e_{B,n} = d_{B, n} - \hat{d}_{B,n} \\ &e_{2B,n}' = F \begin{bmatrix} {\bf I}_B \\ 0_{B \times B} \end{bmatrix} e_{B,n} \triangleq \text{col} \{ e_k'(n), \ \ k = 0, 1, ..., 2B - 1 \} \\ \\ &l_{k, n} = l_{k, n-1} + \frac{\mu}{\lambda_k(n)}u_{k,n}'^* d_k(n)', \ \ k = 0, 1, ..., 2B-1 \\ &\begin{bmatrix} l_{0,n}^{c\intercal} \\ l_{1,n}^{c\intercal} \\ \vdots \\ l_{2B-1,n}^{c\intercal} \end{bmatrix} = \frac{1}{2B} F^* \begin{bmatrix} {\bf I}_B & \\ & 0_{B \times B} \end{bmatrix} F \begin{bmatrix} l_{0, n}^{\intercal} \\ l_{1,n}^{\intercal} \\ \vdots \\ l_{2B-1, n}^{\intercal} \end{bmatrix} \end{aligned} uB,n=colu(nB+B−1),...,u(nB+1),u(nB)u2B,n′=F[uB,nuB,n−1]≜clo{uk′(n),k=0,1,...,2B−1}λk(n)=βλk(n−1)+(1−β)∣uk′(n)∣2, k=0,1,...,2B−1uk,n′=[uk′(n) … uk′(n−BM+1)], k=0,1,...,2B−1yk′(n)=uk,n′lk,n−1′, k=0,1,...,2B−1d^B,n=[IB0B×B]F∗col{y0′(n),...,y2B−1′(n)}eB,n=dB,n−d^B,ne2B,n′=F[IB0B×B]eB,n≜col{ek′(n), k=0,1,...,2B−1}lk,n=lk,n−1+λk(n)μuk,n′∗dk(n)′, k=0,1,...,2B−1⎣ ⎡l0,nc⊺l1,nc⊺⋮l2B−1,nc⊺⎦ ⎤=2B1F∗[IB0B×B]F⎣ ⎡l0,n⊺l1,n⊺⋮l2B−1,n⊺⎦ ⎤
对于每个块 n n n, { d ^ B , e B , n } \{ \hat{d}_B, e_{B,n} \} {d^B,eB,n}可以表示为:
d ^ B , n = col { d ^ ( n B + B − 1 ) , . . . , d ^ ( n B + 1 ) , d ^ ( n B ) } e B , n = col { e ( n B + B − 1 ) , . . . , e ( n B + 1 ) , e ( n B ) } \hat{d}_{B,n} = \text{col} \{ \hat{d}(nB+B-1), ..., \hat{d}(nB+1), \hat{d}(nB) \} \\ e_{B,n} = \text{col} \{ e(nB+B-1), ..., e(nB+1), e(nB) \} d^B,n=col{d^(nB+B−1),...,d^(nB+1),d^(nB)}eB,n=col{e(nB+B−1),...,e(nB+1),e(nB)}
Block NLMS 自适应滤波器的实现代码如下所示:
import numpy as np
from numpy.fft import rfft as fft
from numpy.fft import irfft as ifft
def fdaf(x, d, M, mu=0.05, beta=0.9):
"""频域自适应滤波器: Block NLMS 自适应滤波器
Args:
x (_type_): 输入信号
d (_type_): 期望信号
M (_type_): FFT窗口尺寸
mu (float, optional): 迭代步长. Defaults to 0.05.
beta (float, optional): 正则化系数. Defaults to 0.9.
"""
# 滤波器权重系数
H = np.zeros(M+1, dtype=np.complex)
# 正则化系数
norm = np.full(M+1, 1e-8)
# 窗口
window = np.hanning(M)
x_old = np.zeros(M)
# 窗口块的个数
num_block = min(len(x), len(d)) // M
# 信号误差
e = np.zeros(num_block * M)
# 下面对每个块进行迭代
for n in range(num_block):
x_n = np.concatenate([x_old, x[n*M:(n+1)*M]])
d_n = d[n*M:(n+1)*M]
x_old = x[n*M:(n+1)*M]
# 将每个窗口数据进行FFT变换,在频域与滤波器权重系数H相乘(对应于时域的卷积)
X_n = fft(x_n)
y_n = ifft(H*X_n)[M:]
# 在时域得到每个窗口的信号误差
e_n = d_n - y_n
e[n*M:(n+1)*M] = e_n
# 计算频域的误差信号
e_fft = np.concatenate([np.zeros(M), e_n*window])
E_n = fft(e_fft)
# 计算频域的自适应滤波器权重系数
norm = beta*norm + (1-beta)*np.abs(X_n)**2
G = mu*E_n / (norm+1e-3)
H = H + X_n.conj()*G
# 计算时域的自适应滤波器权重
h = ifft(H)
h[M:] = 0
H = fft(h)
return e
参考文献
自适应滤波器算法综述以及代码实现 - 凌逆战 - 博客园 ↩︎
自适应滤波器(一)LMS自适应滤波器 - 知乎 ↩︎
(74条消息) python实现LMS、NLMS、RLS、KALMAN等自适应滤波器_ewan_xu的博客-CSDN博客_python实现lms算法 ↩︎