ECCV2020 Flow-edge Guided Video Completion20论文翻译
ECCV2020 Flow-edge Guided Video Completion20论文翻译
-
-
- 摘要
- 1.介绍
- 2.相关工作
- 3.方法
-
- 3.1 综述
- 3.2 Edge-guided Flow Completion边缘引导的光流补全
- 3.3 Local and Non-local Temporal Neighbors局部和非局部邻域
- 3.4 Fusing Temporal Neighbors融合时间邻域
- 3.5 Iterative Completion迭代补全
- 4 实验结果
-
- 4.1 实验设置
- 4.2 定量的评估
- 4.3 定量的评估
- 4.4 消融研究
- 4.5 局限性
- 4.6 负面的结果
- 参考文献
-
光流边缘引导的视频补全算法
论文地址: Flow-edge Guided Video Completion20

摘要
我们提出了一个新的基于光流的视频修复算法。之前的光流修复算法通常无法保持运动边界的锐度。我们的方法首先提取并完成运动边缘,然后利用运动边缘来引导具有锐边的分段光滑流补全。现有的方法在相邻帧之间的局部光流连接之间传播色彩。然而,并不是视频中所有缺失的区域都可以用这种方法进行恢复,因为运动的边界形成了不可逾越的障碍。我们的方法通过相隔较远的帧之间的全局光流(non-local flow)连接减轻了这个问题,允许在运动边界上传播视频内容。我们在DAVIS数据集验证了我们的方法,视觉和定量结果都表明,我们的方法优于最先进的算法。
1.介绍
视频修复是用新合成的内容填充一个给定时空区域的任务。有着广泛的应用,包括修复(去除划痕), 视频编辑和特效(删除不需要的对象),水印和logo的去除,和视频稳定化(在移除晃动后填充外部,而不是剪切)。新合成的内容应该无缝嵌入到视频中,这种变化也应该是尽可能难以察觉的。这是具有挑战性的,因为我们需要确保结果在时间上是一致的(不会闪烁),并且涉及到动态摄像机运动以及视频中复杂的物体运动。
直到几年前,大多数方法使用基于块的合成技术[14,26,39]。这些方法通常比较慢并且合成新内容的能力也有限,因为他们只能重新混合视频中已有的块。最近的基于学习的技术实现了更合理的合成[5, 38],但由于视频的内存要求很高,采用三维时空核的方法存在分辨率问题。迄今为止最成功的方法[14,42]是基于流光流的。它们共同合成色彩和光流,沿光流轨迹传播色彩以提高时间的连贯,这种方式减缓了内存问题并允许高分辨率输出。我们的方法也遵循这种普遍的方法。
基于光流的方法实现良好结果的关键在于准确的光流修复,特别的是沿物体边界合成锐化的光流边缘。然而,上述所提到的方法不能够合成锐化的光流边缘并且通常会产生过度平滑的结果。当移除平面背景前的整个对象时,这种方法仍然有效,但在一些复杂的情况下就不起作用了。比如说,现有的方法很难很好地完成部分可见的动态对象(图1b-c)。值得注意的是,这种情况在完成静态屏幕空间masks时非常普遍,比如说logo和水印。在我们的工作里,我们通过明确的合成光流边缘来提升光流的合成效果。我们然后使用合成的光流边缘来引导光流的合成,使得光流分段平滑,有着锐化的边缘 (图1d)。
以往基于光流的方法的另一个局限性是相邻帧之间的串联光流向量只能形成连续的时间约束。这阻止了对视频的多个部分进行约束和传播。比如说,考虑到行走的人的周期性的腿部运动的场景:这里,背景在两腿之间反复可见,但是横扫运动阻止了形成持续的光流轨迹来获得(并填充)这些区域。我们通过向一组non-local(时间距离)帧引入额外的光流约束缓解了这个问题。这就创造了跨越光流障碍的捷径,并将色彩传播到视频的更多部分。
最后,前面的基于光流的方法直接传播色彩值,然而在视频中,由于光线变化,阴影,镜头晕光,自动曝光和白平衡等效果,颜色往往会随着时间而微妙变化,这些效果会导致从不同帧传播的颜色组合在一起时出现明显可见的颜色接缝。我们的方法通过在Gradient-domain中操作来减少这个问题。
总的来说,我们的方法缓解了现存的基于光流的视频修复算法的局限性:
- Flow edges光流边缘:通过显式地合成光流的边缘,我们获得了分段平滑光流的合成。
- Non-local flow非局部光流:我们利用非局部光流处理不能通过传递光流处理的区域(例如,周期运动,如步行)。
- Seamless blending无缝融合:我们通过操作Gradient-domain来避免在结果中出现明显的接缝。
- Memory efficiency内存效率:我们的方法处理高达4K分辨率的视频,而其他方法失败,因为过度的GPU内存要求。
2.相关工作
图像修复: 目的是用合理合成的内容填充图像中缺失的区域。Example-based方法利用了自然图像中的冗余并且将图片块从已知区域转换到未知(缺失)区域[7, 9]。这些方法通过 patch-based基于块的合成[1,39]或通过用graph cuts图像切割来解决标记问题[12,32]找到内容转换的联系。除了只使用逐字复制的patch之外,还有几种方法通过几何和光度变换增强patch搜索来提高补全质量[8,13,15,24]。Learning-based方法在图像修复已经展现了有前途的结果,主要是他们能够合成一些原始图像中没有的新内容 [16, 29, 43, 45]。一些改进的网络设计被提出来处理 free-form holes[23,40,44],并利用预测的结构(如边缘)来引导内容 [25, 33, 41],我们的工作利用一个pretrained 图像修复模型 [45]来填充没有通过时间传播填充的像素。
视频修复: 继承了图像补全问题带来的挑战,并由于时间维度的增加引入了新的挑战。下面,我们只讨论与我们的工作最相关的视频修复方法。我们请读者参阅调查[17]以获得该领域的完整地图。
Patch-based合成技术以3D(时空)patches作为合成单元应用于视频补全修复[26,39]。然而,用 3D patches处理动态视频(用手持相机拍摄)很有挑战性,因为它们不能适应摄像机运动引起的变形。因为这个原因,一些方法选择2D空间patches来填充空洞并且使用 homography-based registration增强时间一致性[10,或显式的光流约束[14,34,36]。特别的是,Huang et al. [14]提出了一种在光流估计和flow-guided patch-based的合成之间交替的优化公式。虽然已有令人印象深刻的结果,但该方法的计算成本较高。近期研究[3,28]展示速度也可以有大幅提升,通过 (1)将光流合成步骤与颜色合成步骤解耦和 (2)移除patch-based合成(即仅依赖于基于光流的颜色传播)。这些 flow-based方法,不能够得到缺失区域的锐化光流边缘并且很难合成动态对象边界。我们的方法专注于克服 flow-based方法的局限性。
由于learning-based的视觉合成方法的成功,最近的努力集中在开发基于cnn的视频合成方法上。一些方法采用3D CNN结构来提取特征并且学习修复缺失的内容[5, 38]。然而,由于内存的限制,3D CNNs的使用极大地限制了视频处理的空间(和时间)分辨率。为了缓解这个问题, [20, 22, 27]中的方法抽取少量邻近帧作为参考。然而,这些方法由于使用了固定的时间窗,不能传输时间上的遥远的内容。 受flow-based方法[3, 14, 28]的启发, Xu等人[42]明确地预测和完善了稠密光流场,以便于传播潜在的较远帧的内容来填补缺失的区域。我们的方法建立在floow-based的视频合成公式并且做了一些技术贡献来大幅提高合成的视觉质量,包括合成保持边缘(edge-preserving)的光流场,利用非局部光流和Gradient-domain处理来获得无缝的结果。
Gradient-domain处理: 技术是各种应用中不可缺少的工具,包括图像编辑 [2,31],基于图像的渲染 [21],混合缝合全景[37],和在视频中无缝插入运动目标[6]。在视频修复的情况下,泊松融合可以作为一个后处理操作来将合成的内容和原始图片进行融合并且隐藏沿孔边界的接缝。但是,这种方法是不够的,因为从多个帧传播的内容可能在孔内引入可见的接缝,不能通过泊松融合去除。我们的方法通过在flow-based传播过程中传播梯度(而不是色彩)来缓解这个问题。
3.方法

3.1 综述
我们的视频补全方法的输入是一个彩色视频和一个显示需要合成的部分的二值掩模视频 (Figure 2a)。我们将掩码像素当作缺失的区域,其他的区域称为已知区域。我们的方法由以下三个主要步骤组成:
- Flow completion光流补全:我们首先计算相邻帧以及一组非相邻 (“non-local”)帧的前向光流和反向光流,然后补全这些光流场中缺失的区域 (Section 3.2)。由于边缘通常是光流映射中最显著的特征,我们首先提取并补全它们。然后,我们使用补全的边缘,以产生分段平滑光流的完成补全 (Figure 2b)。
- Temporal propagation: 接下来,我们沿着光流轨迹为每个缺失的像素传播一组候选像素 (Section 3.3)。通过串联正向光流向量和反向光流向量,得到两组候选像素,直到得到一个已知的像素。利用非局部流向量,通过对三个时间距离帧的检验,得到了另外三组候选像素。对于每组候选像素,我们估计一个置信度分数和一个二进制有效性指标 (Figure 2c)。
- Fusion融合:我们使用置信度加权平均值将每个缺失像素的候选像素与至少一个有效候选像素融合 (Section 3.4)。我们在gradient domain中进行融合以避免可见的颜色接缝(Figure 2d)。
如果在此过程后仍有缺失像素,这意味着它们不能通过时间传播被填充(例如,在整个视频中被遮挡)。为了处理这些像素,我们选择一个关键帧(剩下的大部分缺失像素),并使用单图像补全技术(Section 3.5)填充补全它。我们使用这个结果作为上面描述的相同流程的另一个迭代的输入。空间补全步骤保证我们在每次迭代中都有进展,并且它的结果将被传播到视频的剩余部分,以便在下一个迭代中增强时间一致性。在下面的部分中,我们将提供关于这些步骤的更多细节。
3.2 Edge-guided Flow Completion边缘引导的光流补全
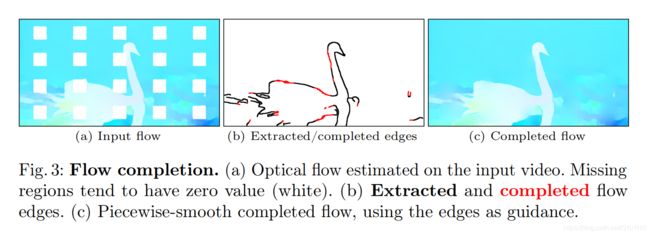
我们算法的第一步是计算相邻帧和一些非局部帧的光流(我们会在Section 3.3解释我们怎样选择一组非局部连接)并以边缘导向的方式补全光流场中缺失区域。
Flow computation光流估计: Ii和Mi分别为第i帧的色彩和掩码(如果从上下文可以清楚地看出我们就去掉下标i),如果像素p缺失,M(p) = 1, 否则等于0。
我们使用pretrained FlowNet2 [18]网络F来计算相邻帧i和j的光流:
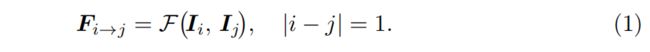
我们发现光流估计在幅度较大的运动中有很明显的退化甚至是失败,这在非局部帧中频繁的发生。为了缓解这个问题,在估计光流之前,我们使用单应变换Hj→i来补偿帧i和帧j之间的大运动(例如,从相机旋转):
![]()
因为我们感兴趣的不是经过单应变换帧之间的光流而是原始帧之间的光流,我们把反单应变换的光流场Hi→j加回来,也就是将每个光流向量映射回未对齐帧j中的原始像素位置。我们使用RANSAC对ORB特征匹配[35]估计对齐单应性。这个操作大约占用总计算时间的3%。
Flow edge completion光流边缘补全: 在估计了光流场之后,我们下一个目标是合理的补全缺失的内容。我们注意到缺失区域的影响稍微扩展到掩码之外(参见Figure 3a中白色区域的凸起)。因此,我们为了光流补全将掩码扩大了15个像素。在这篇论文中可以看到很多例子,光流场通常是分段平滑的,也就是说它们的梯度很小,除了沿着明显的运动边界,明显的运动边界也是这些图中最显著的特征。然而,我们观察到许多先前基于光流的视频补全方法都不能保持清晰的边界。为了提升这方面,我们首先提取和完善的光流边缘,然后使用它们作为一个分段平滑补全的光流值的引导。
我们使用Canny边缘检测[4]来提取一个光流边缘映射Ei→j(Figure 3b,黑线)。值得注意的是我们使用掩码移除了缺失区域的边缘。我们遵循EdgeConnect [25]并训练一个光流边缘补全网络(具体细节查看Section 4.1)。在前向推理时,该网络预测一个补全边缘映射 E˜i→j (Figure 3b, 红线)。
Flow completion光流补全: 现在我们已经在缺失区域产生了光流边缘,我们已经准备好完成实际的光流值。因为除了边缘部分,我们感兴趣的是平滑补全,我们的解决方案是最小化所有地方的梯度(除了边缘)。我们通过解决下面的问题来获得补全光流F˜:

Δx和Δy分别表示水平和垂直的有限前向差分算子。这个总和覆盖了所有的非边缘像素,边界条件确保了掩码外的光流的平滑延续。方程3的解是一组稀疏线性方程,我们使用标准线性最小二乘求解器来求解。Figure 3c显示了一个流光流补全的示例。
3.3 Local and Non-local Temporal Neighbors局部和非局部邻域
现在我们可以使用补全的光流场来指导彩色视频的完成。这个过程分为两个步骤:对于每一个缺失的像素,我们
- 找到一组已知的时间邻域像素(this section)
- 通过加权平均融合候选像素来解决颜色(Section 3.4)。
光流场在帧之间建立相关像素之间的连接,通过沿着光流轨迹将已知像素的颜色通过缺失区域传播,从而引导补全。与将颜色push传播到缺失的区域(并遭受重复重采样的痛苦)相比,更可取的做法是,对于给定的缺失像素,可过渡地跟踪正向和反向光流链接,直到获得已知的像素,并pull它们的颜色。
我们通过测量前后循环一致性误差来检查流程的有效性,当发现误差大于5像素时,停止跟踪。

我们称这种方式可以到达的已知像素为局部时间邻域,因为它们是通过链接相邻帧之间的光流向量来计算的。
有时,我们可能无法到达一个局部已知像素,因为缺失的区域会一直延伸到视频的末尾,因为无效的光流或者是因为遇到了flow barrier。flow barrier发生在每一个主要的运动边界,因为闭塞/反闭塞打破了前向/后向循环的一致性。 Figure 4显示了一个典型的示例。Barriers可以导致大面积的孤立像素,没有局部的时间邻域。以前的方法依靠幻想在这些区域产生内容。然而,幻想更倾向于虚构,而不是传播。

特别的是,即使合成的内容是可信的,它很可能与跨barrier可见的实际内容不同,这将导致暂时不一致的结果。
我们通过引入非局部时态邻域来缓解这个问题,也就是说,计算光流到一组时间上遥远的帧中,这些帧跨越了光流barriers,从而显著减少孤立像素的数量和幻像的需求。对于每一帧,我们计算了三个额外的非局部光流使用单应性对齐方法的帧(等式2)。为了简单起见,我们始终选择视频的第一帧、中间帧和最后一帧作为非局部邻域。Figure 5显示了一个示例。
讨论: 我们对非局部邻域选择的自适应方案进行了实验,但是我们发现增加的复杂性对于本文中的较短的视频序列很难被证明是合理的,对于较长的视频,也许有必要采取更复杂的计划,比如常量帧偏移,可能还会添加额外的非局部帧。

3.4 Fusing Temporal Neighbors融合时间邻域
现在我们已经为缺失的像素计算了时间邻域,我们已经准备好融合它们来合成完成的颜色值。对于一个给定的缺失像素p,使 k ∈ N(p)作为一组有效的局部和非局部时间邻域(我们拒绝光流量误差过大的邻域,并将在 Section 3.5中解释如何处理没有邻域的像素),我们计算候选颜色ck的加权平均值作为补全的颜色,

权重wk由光流循环一致性误差计算:

dk是非局部邻域的一致性误差D˜i→j(p),并将这些误差的最大值沿光流连接向量的局部邻域计算。我们设置T = 0.1来对光流量误差大的邻域进行重估。

Gradient-domain processing梯度域处理: 我们观察到,直接传播的颜色值经常产生可见的接缝,甚至光流是正确的也是如此。这是因为在输入视频中有细微的颜色变化(Figure 6a)。这些影响经常发生,如灯光变化,阴影,镜头晕光,自动曝光,和白平衡等。我们通过改变方程5来计算颜色梯度的加权平均值,而不是颜色值来解决这个问题。
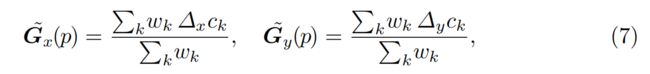
并且通过求解泊松重建问题得到最终图像。该问题可以用标准线性最小二乘法来解决。

通过在梯度域中操作(Figure 6b),颜色接缝被抑制了(Figure 6c)。
3.5 Iterative Completion迭代补全
在每次迭代中,我们传播颜色梯度然后获得最多5个候选梯度。然后我们融合所有的候选梯度并通过求解泊松重建问题(方程式8)。这将填补所有具有有效时间邻域的缺失像素。一些缺失的像素或许没有任何有效时间邻域,即使是非局部光流,例如,当像素被所有非局部帧遮挡,或当光流被错误估计时发生这种情况。与过去的工作相似[14],我们把这个问题当作一个单图像补全任务,然后通过 Deepfill [45]解决它。然而,如果我们用这种单图像方法在所有帧中补全剩余的缺失区域,其结果在时间上是不一致的。相反,我们只选择剩下的缺失像素最多的一帧然后用单图像方法进行补全。然后,我们将不全的结果作为输入输送到我们整个流水线的另一个迭代当中(光流计算是一个值得注意的例外,它不需要重新计算)。在这之后的迭代,单图像方法修复的帧数被当做是已知的区域,并且它的颜色梯度被连贯的传播到周围的帧。
当没有缺失的像素的时候就停止迭代。在实践中,我们的算法需要大概5次迭代来填充我们尝试的视频序列中全部缺失的像素。我们在补充材料中包含了伪代码,它总结了整个流水线。
4 实验结果
4.1 实验设置
场景: 我们考虑了两种视频不全的场景:
- 屏幕空间的掩码修复
- 目标移除
对于修复设置,我们生成了一个固定的掩码,其网格为5×4个正方形方块(见Figure 7中的示例)。该设置模拟了水印或字幕删除的任务。从这样的缺失中恢复内容是特别具有挑战性的,因为它经常需要在其背景上合成部分可见的动态对象。对于目标移除的设置,我们的目的是从一个覆盖整个前景目标的动态移动掩码中恢复丢失的内容。这个任务相对来说简单一些,因为通常主要的动态对象会被完全删除。目标移除设置中的结果,因为掩码对象背后的真实内容的确实,所以很难去比较和评估。因为这个,我们进一步引入了一个合成对象掩码的修复任务。具体地说,我们收集一组自由形状的目标掩码,并随机地将它们与其他视频配对,假装有一个目标遮挡了场景。
评估指标: 对于有真实标签的任务(固定掩码修复和对象掩码修复),我们使用PSNR、SSIM和LPIPS[46]来量化完整视频的质量。对于LPIPS,我们采用默认的设置;我们使用Alexnet作为骨干网络,然后我们在中间特征的基础上增加了一个线性校准。
数据集: 我们在DAVIS数据集[30]上评估我们的方法,这个数据集包含150个视频序列。遵循[42]中的评估方案,我们使用2017-test-dev和2017-test-challenge的60个序列,用于训练我们的光流边缘补全网络。我们使用2017-train和2017-val中的90个序列来测试固定掩码的修复任务。对于目标移除任务,我们对Huang等人提供的[14]精细掩码的90个序列中的29个进行了测试(这些掩码包括前景对象投射的阴影)。对于目标掩码修复任务,我们随机将这29个视频序列与同一组具有相同或更长持续时间的掩码序列配对。我们通过[0.8,1]的均匀随机因子来调整目标掩码的大小,并修剪它们以匹配帧数。我们设置所有序列的大小为960x512。
实现细节: 我们在公开可用的官方实现的EdgeConnect[25]的基础上建立了光流边缘修复网络。对于Canny边缘检测器[4],我们使用以下参数: Gaussian σ = 1,低阈值为0.1,高阈值为0.2。我们在光流图像上运行Canny边缘检测器。除了掩码和边缘图像,EdgeConnect采取了一个
“灰度”图像作为附加输入;我们使用光流图像代替他。我们加载在Places2数据集[47]上预训练的权重,然后在DAVIS 2017-test-dev和2017-test-challenge的60个序列上微调了3个轮次。我们采用来自英伟达不规则掩码数据集的掩码测试拆分。在训练过程中,我们首先将边缘图像和对应的光流图像裁剪为256×256个patch。然后我们用一个随机选择的且大小调整为256×256的掩码覆盖它们。我们使用学习率为0.001的adam优化器,花费了12个小时在一张英伟达P100 GPU上训练我们的网络。
4.2 定量的评估
我们在table1中报告了固定掩码和对象掩码的修复设置下的定量结果。由于内存的限制,不是所有方法都可以处理完整的960×512分辨率,我们将所有场景缩小到720×384,并报告了两种分辨率下的数字。在三个指标上,我们的方法相比SOTA算法[14,20,22,26,27,42]大大提高了性能。根据[14],我们还在补充材料中展示了我们的方法的运行时间的详细分析。我们在目标移除设置下,对“CAMEL”视频序列报告我们方法的每个组件的时间。我们的方法以每分钟7.2帧的速度运行。

4.3 定量的评估
Figure 7显示了一组不同序列的示例修复结果。在这些所有情况下,我们的方法产生的内容在时间上是一致的,在视觉上是可信的。与table 1中列出的方法进行广泛的定性比较,请参考补充视频结果。
4.4 消融研究
在本节中,我们将验证我们的设计选择的有效性。
Gradient domain processing梯度域处理: 我们比较了梯度传播过程与颜色传播(用于[14,42]), Figure 6 显示了一个视觉上的比较。当直接使用颜色传播填充缺失的区域,由于不同帧的颜色不同,可以看到明显的的接缝((Figure 6a),梯度域操作可以将其移除 (Figure 6c)。 Table 2(a)定量的分析了梯度传播的贡献。
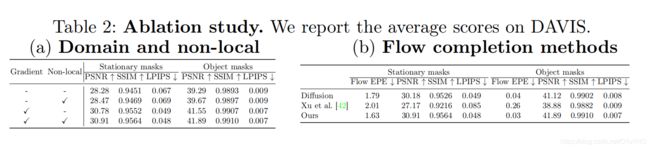
Non-local temporal neighbors非局部时间邻域: 我们研究了非局部时间邻域的有效性, Table 2(a)展示了定量的比较。总体数量上的改善有些微妙,因为在大多数样本情景中,前向/反向光流邻域足以传播正确的内容。在具有挑战性的情况下,当前向和后向(传递连接)光流邻域由于阻塞或不可用时不正确时,使用非局部领域能够极大地减少错误。 Figure 9展示了一个例子,使用非局部邻域允许我们从较远的帧传播正确得内容。

Edge-guided flow completion边缘引导的光流补全: 我们评估了用不同方法补全光流场的性能。在Figure 8,我们展示了两个使用扩散的光流补全结果示例(实际上方程3没有边缘引导),一个训练的光流补全网络[42],和我们提出的边缘引导的光流补全。基于扩散的方法在光流场的每个地方最大化平滑,因此不能创建运动边界。基于学习的光流补全网络[42]不能预测光滑的流场和尖锐的流边。相比之下,我们提出的边缘引导光流补全方法将缺失区域填充为分段平滑光流,且沿孔边界没有可见的接缝。Table 2(b)报告了假真光流之间的端点错误endpoint error(EPE)(即,使用FlowNet2从原始的、未损坏的视频计算光流)和补全的光流。结果展示我们提出的光流补全相比于扩散和训练的光流补全网络[42],很明显的实现了更低的EPE错误。因此,我们提出的边缘引导的光流补全方法有助于提高定量结果。

4.5 局限性
失败的结果: 视频修复仍然是一个具有挑战性的问题。我们在Figure 10中展示并解释了几个失败案例。
处理速度: 我们的方法运行速度为0.12 fps,与其他基于光流的方法相当。端到端模型相对的更快一些,Lee等人的[22]运行在0.405 fps,但是有着更糟糕的表现。我们承认稍微慢一点的运行时间是一个弱点。
4.6 负面的结果
我们探索了几个备选方案,以提高我们的视频修复结果的质量。不幸的是,这些变化要么导致性能下降,要么没有产生明显的改进。
Flow completion network光流修复网络: 许多基于cnn的方法在图像补全方面都取得了良好的效果,对于光流补全来说,使用CNN看似为一个很自然的方法。我们改进并实验了一些图像修复结构,包括partial conv[23]和EdgeConnect [25]来学习修复缺失的光流(通过在一个较大的视频数据集上的光流场训练[19])。然而,我们发现在两种情况下,网络都不能推广到成不可见的视频序列并且在孔洞的边缘产生可见的接缝。
Learning-based fusion基于学习的融合: 我们探索过使用基于U-Net的模型来学习融合候选像素的权重(Section 3.4)。我们的模型采用前后一致性误差映射和有效性掩码作为输入,并预测融合权重,使融合的梯度尽可能地接近真实的梯度。然而,我们在这个基于学习的融合方法上没有得到相比于手调的权重很明显的提升。
参考文献
- Barnes, C., Shechtman, E., Finkelstein, A., Goldman, D.B.: Patchmatch: A randomized correspondence algorithm for structural image editing. In: ACM TOG
(Proc. SIGGRAPH). vol. 28, p. 24 (2009) - Bhat, P., Zitnick, C.L., Cohen, M.F., Curless, B.: Gradientshop: A gradient-domain
optimization framework for image and video filtering. ACM TOG (Proc. SIGGRAPH) 29(2), 10–1 (2010) - Bokov, A., Vatolin, D.: 100+ times faster video completion by optical-flow-guided
variational refinement. In: ICIP (2018) - Canny, J.: A computational approach to edge detection. IEEE Trans. Pattern Anal.
Mach. Intell. pp. 679–698 (1986) - Chang, Y.L., Liu, Z.Y., Hsu, W.: Free-form video inpainting with 3d gated convolution and temporal patchgan. In: ICCV (2019)
- Chen, T., Zhu, J.Y., Shamir, A., Hu, S.M.: Motion-aware gradient domain video
composition. TIP 22(7), 2532–2544 (2013) - Criminisi, A., Perez, P., Toyama, K.: Object removal by exemplar-based inpainting.
In: CVPR (2003) - Darabi, S., Shechtman, E., Barnes, C., Goldman, D.B., Sen, P.: Image melding:
Combining inconsistent images using patch-based synthesis. ACM TOG (Proc.
SIGGRAPH) 31(4), 82–1 (2012) - Drori, I., Cohen-Or, D., Yeshurun, H.: Fragment-based image completion. In: ACM
TOG (Proc. SIGGRAPH). vol. 22, pp. 303–312 (2003) - Gao, C., Moore, B.E., Nadakuditi, R.R.: Augmented robust pca for foregroundbackground separation on noisy, moving camera video. In: 2017 IEEE Global
Conference on Signal and Information Processing (GlobalSIP) (2017) - Granados, M., Kim, K.I., Tompkin, J., Kautz, J., Theobalt, C.: Background inpainting for videos with dynamic objects and a free-moving camera. In: ECCV
(2012) - He, K., Sun, J.: Image completion approaches using the statistics of similar patches.
TPAMI 36(12), 2423–2435 (2014) - Huang, J.B., Kang, S.B., Ahuja, N., Kopf, J.: Image completion using planar
structure guidance. ACM TOG (Proc. SIGGRAPH) 33(4), 129 (2014) - Huang, J.B., Kang, S.B., Ahuja, N., Kopf, J.: Temporally coherent completion of
dynamic video. ACM Transactions on Graphics (TOG) (2016) - Huang, J.B., Kopf, J., Ahuja, N., Kang, S.B.: Transformation guided image completion. In: ICCP (2013)
- Iizuka, S., Simo-Serra, E., Ishikawa, H.: Globally and locally consistent image
completion. ACM TOG (Proc. SIGGRAPH) 36(4), 107 (2017) - Ilan, S., Shamir, A.: A survey on data-driven video completion. In: Computer
Graphics Forum. vol. 34, pp. 60–85 (2015) - Ilg, E., Mayer, N., Saikia, T., Keuper, M., Dosovitskiy, A., Brox, T.: Flownet 2.0:
Evolution of optical flow estimation with deep networks. In: CVPR (2017) - Kay, W., Carreira, J., Simonyan, K., Zhang, B., Hillier, C., Vijayanarasimhan, S.,
Viola, F., Green, T., Back, T., Natsev, P., et al.: The kinetics human action video
dataset. arXiv preprint arXiv:1705.06950 (2017) - Kim, D., Woo, S., Lee, J.Y., Kweon, I.S.: Deep video inpainting. In: CVPR (2019)
- Kopf, J., Langguth, F., Scharstein, D., Szeliski, R., Goesele, M.: Image-based
rendering in the gradient domain. ACM TOG (Proc. SIGGRAPH) 32(6), 199
(2013) - Lee, S., Oh, S.W., Won, D., Kim, S.J.: Copy-and-paste networks for deep video
inpainting. In: ICCV (2019) - Liu, G., Reda, F.A., Shih, K.J., Wang, T.C., Tao, A., Catanzaro, B.: Image
inpainting for irregular holes using partial convolutions. In: ECCV (2018) - Mansfield, A., Prasad, M., Rother, C., Sharp, T., Kohli, P., Van Gool, L.J.: Transforming image completion. In: BMVC (2011)
- Nazeri, K., Ng, E., Joseph, T., Qureshi, F., Ebrahimi, M.: Edgeconnect: Generative
image inpainting with adversarial edge learning. In: ICCVW (2019) - Newson, A., Almansa, A., Fradet, M., Gousseau, Y., Pérez, P.: Video inpainting of
complex scenes. SIAM Journal on Imaging Sciences (2014) - Oh, S.W., Lee, S., Lee, J.Y., Kim, S.J.: Onion-peel networks for deep video completion. In: ICCV (2019)
- Okabe, M., Noda, K., Dobashi, Y., Anjyo, K.: Interactive video completion. IEEE
computer graphics and applications (2019) - Pathak, D., Krahenbuhl, P., Donahue, J., Darrell, T., Efros, A.A.: Context encoders:
Feature learning by inpainting. In: CVPR (2016) - Perazzi, F., Pont-Tuset, J., McWilliams, B., Van Gool, L., Gross, M., SorkineHornung, A.: A benchmark dataset and evaluation methodology for video object
segmentation. In: CVPR (2016) - Pérez, P., Gangnet, M., Blake, A.: Poisson image editing. ACM TOG (Proc. SIGGRAPH) 22(3), 313–318 (2003)
- Pritch, Y., Kav-Venaki, E., Peleg, S.: Shift-map image editing. In: ICCV (2009)
- Ren, Y., Yu, X., Zhang, R., Li, T.H., Liu, S., Li, G.: Structureflow: Image inpainting
via structure-aware appearance flow. In: CVPR. pp. 181–190 (2019) - Roxas, M., Shiratori, T., Ikeuchi, K.: Video completion via spatio-temporally consistent motion inpainting. IPSJ Transactions on Computer Vision and Applications
(2014) - Rublee, E., Rabaud, V., Konolige, K., Bradski, G.: Orb: An efficient alternative to
sift or surf. In: ICCV (2011) - Strobel, M., Diebold, J., Cremers, D.: Flow and color inpainting for video completion.
In: German Conference on Pattern Recognition (2014) - Szeliski, R., Uyttendaele, M., Steedly, D.: Fast poisson blending using multi-splines.
In: ICCP. pp. 1–8 (2011) - Wang, C., Huang, H., Han, X., Wang, J.: Video inpainting by jointly learning
temporal structure and spatial details. In: AAAI (2019) - Wexler, Y., Shechtman, E., Irani, M.: Space-time completion of video. TPAMI (3),
463–476 (2007) - Xie, C., Liu, S., Li, C., Cheng, M.M., Zuo, W., Liu, X., Wen, S., Ding, E.: Image
inpainting with learnable bidirectional attention maps. In: ICCV (2019) - Xiong, W., Yu, J., Lin, Z., Yang, J., Lu, X., Barnes, C., Luo, J.: Foreground-aware
image inpainting. In: CVPR (2019) - Xu, R., Li, X., Zhou, B., Loy, C.C.: Deep flow-guided video inpainting. In: CVPR
(2019) - Yan, Z., Li, X., Li, M., Zuo, W., Shan, S.: Shift-net: Image inpainting via deep
feature rearrangement. In: ECCV (2018) - Yu, J., Lin, Z., Yang, J., Shen, X., Lu, X., Huang, T.S.: Free-form image inpainting
with gated convolution. arXiv preprint arXiv:1806.03589 (2018) - Yu, J., Lin, Z., Yang, J., Shen, X., Lu, X., Huang, T.S.: Generative image inpainting
with contextual attention. In: CVPR (2018) - Zhang, R., Isola, P., Efros, A.A., Shechtman, E., Wang, O.: The unreasonable
effectiveness of deep features as a perceptual metric. In: CVPR (2018) - Zhou, B., Lapedriza, A., Khosla, A., Oliva, A., Torralba, A.: Places: A 10 million
image database for scene recognition. IEEE transactions on pattern analysis and
machine intelligence 40(6), 1452–1464 (2017)