目标检测算法——YOLOv5结合CA注意力机制

关注”PandaCVer“公众号
深度学习Tricks,第一时间送达
论文题目:《Coordinate Attention for Efficient Mobile NetWork Design》
论文地址: https://arxiv.org/pdf/2103.02907.pdf
本文中,作者通过将位置信息嵌入到通道注意力中提出了一种新颖的移动网络注意力机制,将其称为“Coordinate Attention”。与通过2维全局池化将特征张量转换为单个特征向量的通道注意力不同,Coordinate注意力将通道注意力分解为两个1维特征编码过程,分别沿2个空间方向聚合特征。这样,可以沿一个空间方向捕获远程依赖关系,同时可以沿另一空间方向保留精确的位置信息。然后将生成的特征图分别编码为一对方向感知和位置敏感的attention map,可以将其互补地应用于输入特征图,以增强关注对象的表示。
小海带将CA注意力模块嵌入到YOLOv5网络中,可进一步强化YOLOv5网络对方向和位置等信息的敏感度,并涨点明显。近期较忙,想要代码的小伙伴请私信~
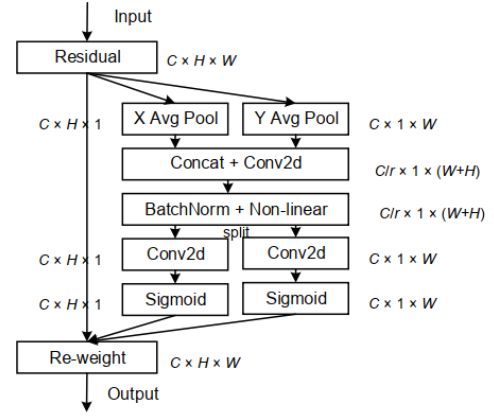
1.网络结构图
2.CA模块代码
不同于通道注意力将输入通过2D全局池化转化为单个特征向量,CoordAttention将通道注意力分解为两个沿着不同方向聚合特征的1D特征编码过程。这样的好处是可以沿着一个空间方向捕获长程依赖,沿着另一个空间方向保留精确的位置信息。然后,将生成的特征图分别编码,形成一对方向感知和位置敏感的特征图,它们可以互补地应用到输入特征图来增强感兴趣的目标的表示。
CA模块通过精确的位置信息对通道关系和长程依赖进行编码,类似SE模块,也分为两个步骤:坐标信息嵌入(coordinate information embedding)和坐标注意力生成(coordinate attention generation),它的具体结构如下图。
class h_sigmoid(nn.Module):
def __init__(self, inplace=True):
super(h_sigmoid, self).__init__()
self.relu = nn.ReLU6(inplace=inplace)
def forward(self, x):
return self.relu(x + 3) / 6
class h_swish(nn.Module):
def __init__(self, inplace=True):
super(h_swish, self).__init__()
self.sigmoid = h_sigmoid(inplace=inplace)
def forward(self, x):
return x * self.sigmoid(x)
class CoordAtt(nn.Module):
def __init__(self, inp, oup, reduction=32):
super(CoordAtt, self).__init__()
self.pool_h = nn.AdaptiveAvgPool2d((None, 1))
self.pool_w = nn.AdaptiveAvgPool2d((1, None))
mip = max(8, inp // reduction)
self.conv1 = nn.Conv2d(inp, mip, kernel_size=1, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(mip)
self.act = h_swish()
self.conv_h = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
self.conv_w = nn.Conv2d(mip, oup, kernel_size=1, stride=1, padding=0)
def forward(self, x):
identity = x
x_h = self.pool_h(x)
x_w = self.pool_w(x).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.conv1(y)
y = self.bn1(y)
y = self.act(y)
x_h, x_w = torch.split(y, [h, w], dim=2)
x_w = x_w.permute(0, 1, 3, 2)
a_h = self.conv_h(x_h).sigmoid()
a_w = self.conv_w(x_w).sigmoid()
out = identity * a_w * a_h
return out如何嵌入YOLOv5网络,各位小伙伴请参考上一篇博文~