机器学习基础-精确率和召回率
分类模型的评估
estimator.score():一般最常见使用的是准确率,即预测结果正确的百分比
混淆矩阵
在分类任务下,预测结果(Predicted Condition)与正确标记(True Condition)之间存在四种不同的组合,构成混淆矩阵(适用于多分类)
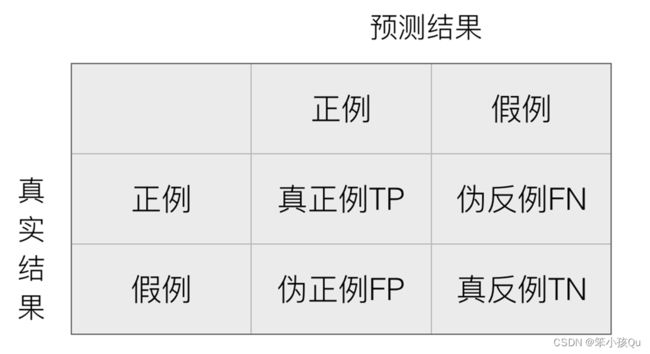
精确率(Precision)与召回率(Recall)

分类模型评估API

交叉验证与网格搜索
交叉验证定义:
为了让被评估的模型更加准确可信
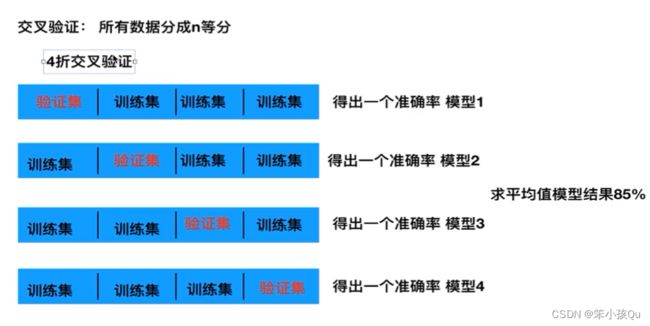
交叉验证过程:
将拿到的训练集数据,分为训练和验证集。以下图为例:将数据分成4份,其中一份作为验证集。然后经过4次(组)的测试,每次都更换不的验证集。即得到4组模型的结果,取平均值作为最终结果。又称4折交叉验证。
网格搜索-超参数搜索(调参数)
通常情况下,有很多参数是需要手动指定的(如k-近邻算法中的K值),这种叫超参数。但是手动过程繁杂,所以需要对模型预设几种超参数组合。每组超参数都采用交叉验证来进行评估。最后选出最优参数组合建立模型。
超参数搜索-网格搜索API
sklearn.model_selection.GridSearchCV

决策树与随机森林
决策树
决策树思想的来源非常朴素,程序设计中的条件分支结构就是if-then结构,最早的决策树就是利用这类结构分割数据的一种分类学习方法
信息熵

决策树的划分依据之一-信息增益
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:

注:信息增益表示得知特征X的信息而使得类Y的信息的不确定性减少的程度
信息增益的计算
信息熵的计算:

条件熵的计算:
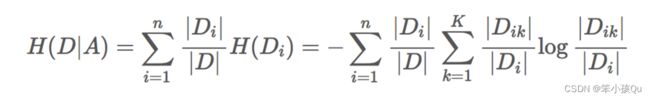
注:C_k 表示属于某个类别的样本数,

常见决策树使用的算法
信息增益 最大的准则
信息增益比 最大的准则
回归树: 平方误差 最小
分类树: 基尼系数 最小的准则 在sklearn中可以选择划分的原则
sklearn决策树API
class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
决策树的优缺点以及改进
优点:
缺点:
1. 决策树学习者可以创建不能很好地推广数据的过于复杂的树, 这被称为过拟合。
2.决策树可能不稳定,因为数据的小变化可能会导致完全不同的树被生成
改进:
减枝cart算法(决策树已有API实现)
随机森林
集成学习方法-随机森林
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做出预测。
随机森林定义:在机器学习中,随机森林是一个包含多个决策树的分类器,并且其输出的类别是由个别树输出的类别的众数而定。
学习算法
根据下列算法而建造每棵树:
如果不进行随机抽样,每棵树的训练集都一样,那么最终训练出的树分类结果也是完全一样的
如果不是有放回的抽样,那么每棵树的训练样本都是不同的,都是没有交集的,这样每棵树都是“有偏的”,都是绝对“片面的”(当然这样说可能不对),也就是说每棵树训练出来都是有很大的差异的;而随机森林最后分类取决于多棵树(弱分类器)的投票表决。
集成学习API
class sklearn.ensemble.RandomForestClassifier(n_estimators=10, criterion=’gini’, max_depth=None, bootstrap=True, random_state=None)

随机森林的优点
对于缺省值问题也能够获得很好得结果