论文解读:跨模态/多光谱/多模态检测 Cross-Modality Fusion Transformer for Multispectral Object Detection
(可见图像和热成像)
右侧的热图像可以在光照不足的情况下捕捉到更清晰的行人轮廓。 此外,热图像还捕捉到被柱子遮挡的行人。在光线充足的白天,视觉图像比热图像具有更多的细节,例如边缘、纹理和颜色。有了这些细节,我们可以很容易地找到隐藏在机动三轮车中的司机,而这在热图像中是很难找到的。
1.瓶颈问题:
现实世界中环境是不断变化的,比如雨天,雾天,晴天,阴天等等,算法很难在仅仅用可见传感器数据(如相机拍下来的图像),在动态的环境变化中检测目标。因此,多光谱成像技术正逐渐被采用,因为它能够提供来自多光谱相机的组合信息,例如可见光和热成像。并且通过融合不同模态的互补性,可以进一步提高检测算法的可感知性、可靠性和鲁棒性。
然而,多光谱数据的引入将产生新的问题:
a.如何整合表示以充分利用不同模态之间的内在互补性?
b.以及如何设计一种有效的跨模态融合机制以实现最大性能形成增益?
使用卷积网络将它们扩展到跨模态融合或模态交互以充分利用固有的互补性并非易事。由于卷积算子具有非全局感受野,因此信息仅在局部区域内融合。
2.本文贡献:
(1) 引入了一种新的强大的双流backbone,在Transformer方案的基础上从另一种模态中增强了一种模态。
(2) 我们提出了一个简单而有效的CFT模块,并对其进行了理论分析,表明CFT模块同时融合了模态内和模态间特征。
(3) 实验结果在三个公共数据集上实现了最先进的性能,这证实了所提出方法的有效性。
3.解决方案:
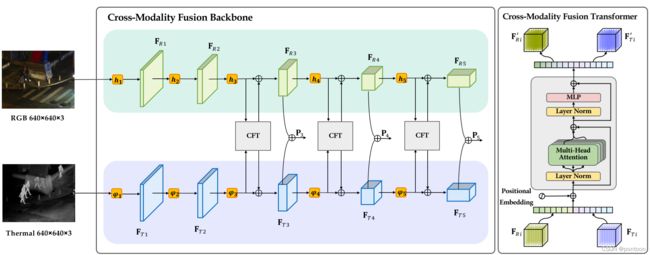
-
在yolov5的基本网络框架下进行更改
-
其输入为不同模态的图像对,backbone改为双流网络,并且将CFT(Cross-Modality Fusion Transformer)嵌入其中
-
将两个模态图像经过卷积后的特征图拉平并concat在一起(记为I,(2HW * C)),添加位置编码组成CFT的输入
将I复制三份分别与相应W(C*C)相乘得到QKV。
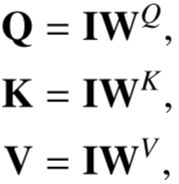
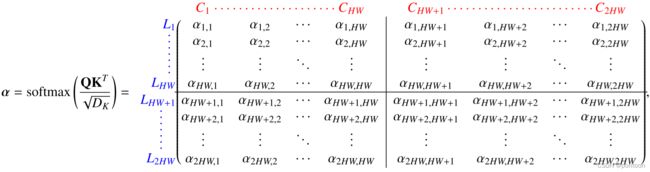

Transformer机制能够使不同模态的特征进行交互。
因此,不需要仔细设计模态融合模块。 我们只需要简单地将多模态特征拼接成一个序列,然后Transformer就可以自动同时进行模态内和模态间信息融合,并鲁棒地捕捉RGB和Ther-之间的潜在交互。
-
实验:
在三个公开数据集上进行实验(FILP. LLVIP. VEDAI.)
训练参数:
We use SGD optimizer with an initial learning rate of 1e-2, a momentum of 0.937, and a weight decay of 0.0005. As for data augmentation, we use the Mosaic method which mixes four training images in one image.
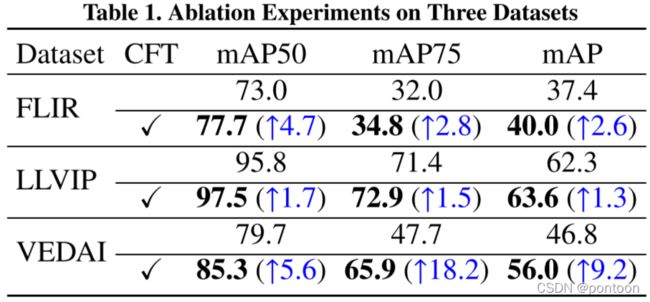
在yolov5上做了消融实验:
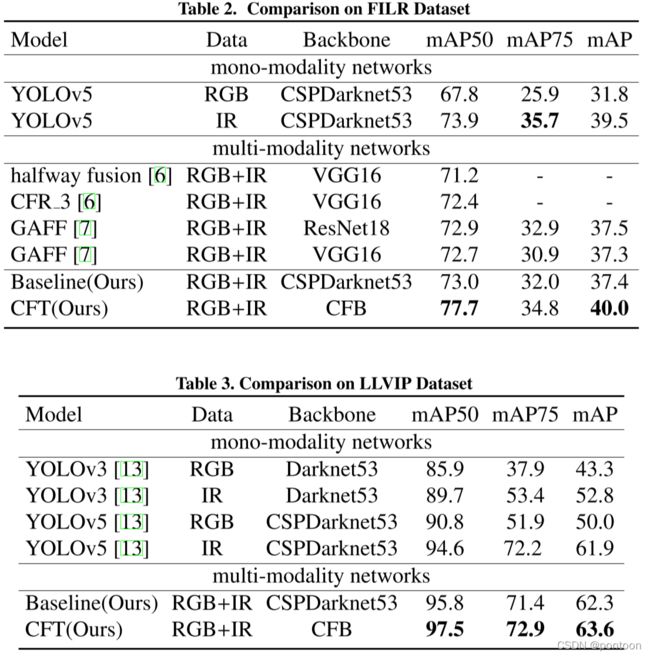
在FILP.数据集上的实验结果对比:(红色箭头为漏检)
第一行:真实标签
第二行:未加CFT的检测网络
第三行:加了CFT的检测网络
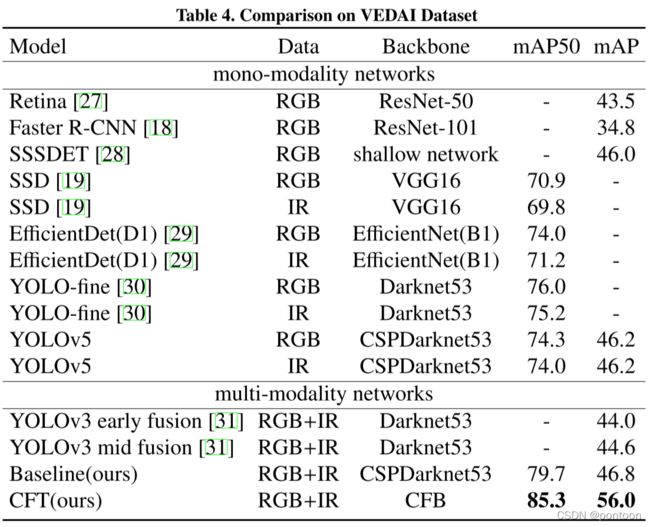
在LLVIP.数据集上的实验结果对比:(红色箭头为漏检)
第一行:真实标签
第二行:未加CFT的检测网络
第三行:加了CFT的检测网络
在VEDAI.数据集上的实验结果对比:(红色箭头为漏检,蓝色箭头为过检)
第一行:真实标签
第二行:未加CFT的检测网络
第三行:加了CFT的检测网络
在三个不同数据集上的实验指标,证明提出的方法最优: