Hive系列 (四):自定义函数UDF UDTF UDAF
文章目录
-
- Hive系列文章
- 简介
- 常见自定义函数
- 创建自定义函数步骤
- 自定义函数的实现
-
- udf格式
-
- 在idea中创建项目
- 导入hadoop和hive jar包
- 修改pom.xlm文件
- 自定义函数案例
- 命令加载
- 启动参数加载
- 配置文件加载
- UDTF格式
-
- 实现方法
- 执行流程
- 测试案例
- 测试代码
- 函数测试
- UDAF格式
-
- 实现方法
- 函数作用
- 测试案例
- 函数测试
Hive系列文章
Hadoop完全分布式搭建(腾讯云服务器+阿里云服务器)
Hive系列 (一):Hive搭建
Hive系列 (二):Hive基础知识
Hive系列 (三):开窗函数详解
Hive系列 (四):自定义函数UDF UDTF UDAF
Hive系列 (五):Hive数据类型
Hive系列 (六):Hive数据类型转换
Hive系列 (七):Hive常用函数
Hive系列 (八):Hive中的explode 与 lateral view
Hive系列 (九):Hive数据存储
Hive系列 (十):Hive调优
简介
用户自定义函数(UDF)是一个允许用户扩展HQL的强大的功能。
开发自定义UDF函数有两种方式,一个是继承org.apache.hadoop.hive.ql.exec.UDF,另一个是继承org.apache.hadoop.hive.ql.udf.generic.GenericUDF;
常见自定义函数
UDF:User-Defined-Function,用户自定义函数,一对一的输入输出。(最常用的)。
UDTF:User-Defined Table-Generating Functions,用户自定义表生成函数。一对多的输入输出,比如 lateral view explore()
UDAF:User-Defined Aggregation Function,用户自定义聚合函数,多进一出,比如 count/max/min。
创建自定义函数步骤
- 编写自定义函数
- 编译部署
- 在hive中注册自定义函数
- 使用自定义函数
- 销毁自定义函数
自定义函数的实现
udf格式
在idea中创建项目
在idea中新建maven项目,注意java版本要和hive环境保持一致。

点击下一步,输入项目名称

导入hadoop和hive jar包
hadoop包所在位置:

hive jar所在位置:

导入到项目中,这里我将hadoop和hive包放在本地两个文件夹中:


修改pom.xlm文件
上述包导入成功后,该问价做如下修改后,不会报错,则配置成功。
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0modelVersion>
<groupId>org.examplegroupId>
<artifactId>hive_udfartifactId>
<version>1.0-SNAPSHOTversion>
<properties>
<maven.compiler.source>8maven.compiler.source>
<maven.compiler.target>8maven.compiler.target>
properties>
<dependencies>
<dependency>
<groupId>org.apache.hadoopgroupId>
<artifactId>hadoop-clientartifactId>
<version>3.3.1version>
dependency>
<dependency>
<groupId>org.apache.hivegroupId>
<artifactId>hive-execartifactId>
<version>3.1.2version>
dependency>
dependencies>
project>
定义UDF函数要注意下面几点:
- 继承
org.apache.hadoop.hive.ql.exec.UDF - 重写
evaluate(),这个方法不是由接口定义的,因为它可接受的参数的个数,数据类型都是不确定的。Hive会检查UDF,看能否找到和函数调用相匹配的evaluate()方法
自定义函数案例
在java目录下新建包:hive_udf

在hive_udf包中新建类:TolowerOrUpperCase
package hive_udf;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.hive.ql.exec.UDF;
/**
* 转换小写或者大写
*
* @author ericray
*
*/
public class TolowerOrUpperCase extends UDF {
public String evaluate(String val, int i) {
if (StringUtils.isBlank(val)) {
return "";
}
else if (i == 0) {
return val.toUpperCase();
}
else {
return val.toLowerCase();
}
}
//调试自定义函数
public static void main(String[] args){
System.out.println(new TolowerOrUpperCase().evaluate("ericray",0));
}
}
打包:

执行成功后,可以在target中看到jar包

上传到hive服务器
[hadoop@master udf_jar]$ pwd
/opt/export/udf_jar
[hadoop@master udf_jar]$ ll
total 4
-rw-rw-r-- 1 hadoop hadoop 2221 Aug 9 14:02 hive_udf-1.0-SNAPSHOT.jar
命令加载
这种加载只对本session有效
# 将jar包添加到hive classpath中
# 进入hive客户端,执行下面命令
0: jdbc:hive2://master:10000> add jar /opt/export/udf_jar/hive_udf-1.0-SNAPSHOT.jar;
# 创建一个临时函数,注意函数名:包名.class类名
0: jdbc:hive2://master:10000> create temporary function my_case as 'hive_udf.TolowerOrUpperCase';
OK
No rows affected (0.033 seconds)
# 测试功能:
0: jdbc:hive2://master:10000> select my_case('abac',0);
OK
+-------+
| _c0 |
+-------+
| ABAC |
+-------+
# 在表中应用
0: jdbc:hive2://master:10000> select my_case(name,0) as upper_name from employee;
OK
+-------------+
| upper_name |
+-------------+
| STFF |
| JOE |
| RUBY |
| BETTY |
+-------------+
4 rows selected (3.771 seconds)
启动参数加载
也是在本session有效,临时函数
# 将编写的udf的jar包上传到服务器上
[hadoop@master udf_jar]$ pwd
/opt/export/udf_jar
[hadoop@master udf_jar]$ ll
total 4
-rw-rw-r-- 1 hadoop hadoop 2221 Aug 9 14:02 hive_udf-1.0-SNAPSHOT.jar
# 创建配置文件
[hadoop@master bin]$ pwd
/opt/hive/bin
[hadoop@master bin]$ vim hive-init
# 添加以下内容
# temporary 关键字定义临时函数,不声明则是永久函数
add jar /opt/export/udf_jar/hive_udf-1.0-SNAPSHOT.jar;
create temporary function my_case as 'hive_udf.TolowerOrUpperCase';
# 3、启动hive的时候带上初始化文件:
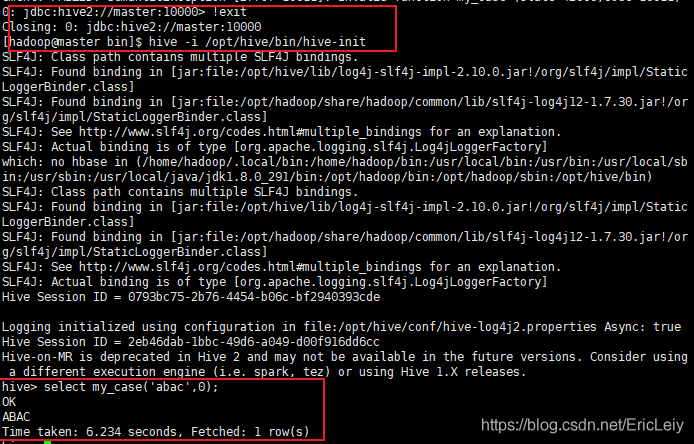
配置文件加载
通过配置文件方式这种只要用hive命令行启动都会加载函数。
# 将编写的udf的jar包上传到服务器上
[hadoop@master udf_jar]$ pwd
/opt/export/udf_jar
[hadoop@master udf_jar]$ ll
total 4
-rw-rw-r-- 1 hadoop hadoop 2221 Aug 9 14:02 hive_udf-1.0-SNAPSHOT.jar
#在hive的安装目录的bin目录下创建一个配置文件,文件名:.hiverc
vi ./bin/.hiverc
add jar /hivedata/udf.jar;
create temporary function my_case as 'hive_udf.TolowerOrUpperCase';
3、启动hive
[hadoop@master bin]$ hive
hive> select my_case('abac',0);
OK
ABAC
Time taken: 7.489 seconds, Fetched: 1 row(s)
UDTF格式
UDTF是一对多的输入输出。
实现方法
继承org.apache.hadoop.hive.ql.udf.generic.GenericUDF,
重写initlizer()、getdisplay()、evaluate()
执行流程
UDTF首先会调用initialize方法,此方法返回UDTF的返回行的信息(返回个数,类型)。
初始化完成后,会调用process方法,真正的处理过程在process函数中,在process中,每一次forward()调用产生一行;如果产生多列可以将多个列的值放在一个数组中,然后将该数组传入到forward()函数。
最后close()方法调用,对需要清理的方法进行清理。
测试案例
把"k1:v1;k2:v2;k3:v3"类似的的字符串解析成每一行多行,每一行按照key:value格式输出
测试代码
package com.udf.hive; //这里我新建了一个包
import org.apache.hadoop.hive.ql.exec.UDFArgumentException;
import org.apache.hadoop.hive.ql.exec.UDFArgumentLengthException;
import org.apache.hadoop.hive.ql.metadata.HiveException;
import org.apache.hadoop.hive.ql.udf.generic.GenericUDTF;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.ObjectInspectorFactory;
import org.apache.hadoop.hive.serde2.objectinspector.StructObjectInspector;
import org.apache.hadoop.hive.serde2.objectinspector.primitive.PrimitiveObjectInspectorFactory;
import java.util.ArrayList;
public class ParseMapUDTF extends GenericUDTF {
@Override
public void close() throws HiveException {
}
@Override
public StructObjectInspector initialize(ObjectInspector[] args)
throws UDFArgumentException {
if (args.length != 1) {
throw new UDFArgumentLengthException(" 只能传入一个参数");
}
ArrayList<String> fieldNameList = new ArrayList<String>();
ArrayList<ObjectInspector> fieldOIs = new ArrayList<ObjectInspector>();
fieldNameList.add("map");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
fieldNameList.add("key");
fieldOIs.add(PrimitiveObjectInspectorFactory.javaStringObjectInspector);
return ObjectInspectorFactory.getStandardStructObjectInspector(fieldNameList,fieldOIs);
}
@Override
public void process(Object[] args) throws HiveException {
String input = args[0].toString();
String[] paramString = input.split(";");
for(int i=0; i<paramString.length; i++) {
try {
String[] result = paramString[i].split(":");
forward(result);
} catch (Exception e) {
continue;
}
}
}
}
按照udf的方式进行打包,上传到hive服务器,重启hive客户端
函数测试
加载自定义函数
0: jdbc:hive2://master:10000> add jar /opt/export/udf_jar/hive_udf-1.0-SNAPSHOT.jar;
Added [/opt/export/udf_jar/hive_udf-1.0-SNAPSHOT.jar] to class path
dded resources: [/opt/export/udf_jar/hive_udf-1.0-SNAPSHOT.jar]
No rows affected (0.021 seconds)
0: jdbc:hive2://master:10000>
创建临时函数
0: jdbc:hive2://master:10000> create temporary function parseMap as 'com.udf.hive.ParseMapUDTF';
OK
No rows affected (0.036 seconds)
0: jdbc:hive2://master:10000>
调用函数
0: jdbc:hive2://master:10000> select parseMap("name:eric;age:18;address:suzhou");
OK
+----------+---------+
| map | key |
+----------+---------+
| name | eric |
| age | 18 |
| address | suzhou |
+----------+---------+
3 rows selected (6.93 seconds)
0: jdbc:hive2://master:10000>
UDAF格式
实现方法
用户自定义聚合函数。user defined aggregate function。多对一的输入输出 count sum max。定义一个UDAF需要如下步骤:
1、UDF自定义函数必须是org.apache.hadoop.hive.ql.exec.UDAF的子类,并且包含一个或多个嵌套的的实现了org.apache.hadoop.hive.ql.exec.UDAFEvaluator的静态类。
2、函数类需要继承UDAF类,内部类Evaluator实UDAFEvaluator接口。
3、Evaluator需要实现 init、iterate、terminatePartial、merge、terminate这几个函
函数作用
init实现接口UDAFEvaluator的init函数iterate每次对一个新值进行聚集计算都会调用,
计算函数要根据计算的结果更新其内部状态terminatePartial无参数,其为iterate函数轮转结束后,
返回轮转数据merge接收terminatePartial的返回结果,进行数据merge操作,
其返回类型为boolean。terminate返回最终的聚集函数结果。
UDAF类已经过时弃用了,现在是实现GenericUDAFResolver2接口,暂时没搞懂,后续会更新
测试案例
计算一组数据的最大值。
package com.udf.hive;
import org.apache.hadoop.hive.ql.exec.UDAF;
import org.apache.hadoop.hive.ql.exec.UDAFEvaluator;
import org.apache.hadoop.io.IntWritable;
// UDAF类已经过时弃用了,现在是实现GenericUDAFResolver2接口
@Deprecated
public class MaxValueUDAF extends UDAF {
public static class MaximumIntUDAFEvaluator implements UDAFEvaluator {
private IntWritable result;
public void init() {
result = null;
}
public boolean iterate(IntWritable value) {
if (value == null) {
return true;
}
if (result == null) {
result = new IntWritable( value.get() );
} else {
result.set( Math.max( result.get(), value.get() ) );
}
return true;
}
public IntWritable terminatePartial() {
return result;
}
public boolean merge(IntWritable other) {
return iterate( other );
}
public IntWritable terminate() {
return result;
}
}
}
函数测试
按照udf的方式进行打包,上传到hive服务器,重启hive客户端
创建临时函数:
0: jdbc:hive2://master:10000> add jar /opt/export/udf_jar/hive_udf-1.0-SNAPSHOT.jar;
Added [/opt/export/udf_jar/hive_udf-1.0-SNAPSHOT.jar] to class path
Added resources: [/opt/export/udf_jar/hive_udf-1.0-SNAPSHOT.jar]
No rows affected (0.012 seconds)
0: jdbc:hive2://master:10000> create temporary function maxTest as 'com.udf.hive.MaxValueUDAF';
OK
No rows affected (0.054 seconds)
0: jdbc:hive2://master:10000>
测试:
0: jdbc:hive2://master:10000> select maxTest(chinese) as chinese from myhive.stu_scores;
OK
+----------+
| chinese |
+----------+
| 100 |
+----------+