【python爬虫】scrapy框架案例实现数据保存入MySQL
文章目录
- 前言
-
- 往期知识点
- 学习宝典
- 最终效果
- 开发准备
-
- 基本开发环境
- scrapy项目的搭建
- 页面分析
- scrapy实现代码部分
-
- settings部分
- starts部分
- items部分
- spider主要部分
- pipelines部分
- 总结
前言
本章用scrapy框架进行岗位信息的保存,相信对于每个上班族来说,总要经历找工作,如何在网上挑到心仪的工作?如何提前为心仪工作的面试做准备?今天我们来保存招聘信息,助你能找到心仪的工作!
往期知识点
往期内容回顾
【python爬虫】纵横中文网python实战
【python教程】保姆版教使用pymysql模块连接MySQL实现增删改查
selenium自动化测试实战案例哔哩哔哩信息至Excel
舍友打一把游戏的时间,我实现了一个selenium自动化测试并把数据保存到MySQL

学习宝典
对于项目实战来说,那必定是需要一定的 Scrapy 的基础的,因此在编写项目之前再次推荐下 Scrapy 框架的中文官网:
https://www.osgeo.cn/scrapy/intro/tutorial.html
有需要的随时可以回去看看。。。下面我们正式开始今天的话题:使用 Scrapy 实现工作信息存储。

最终效果
还是老样子,先看一下最终的实现效果吧,保存到了csv和MySQL数据库中
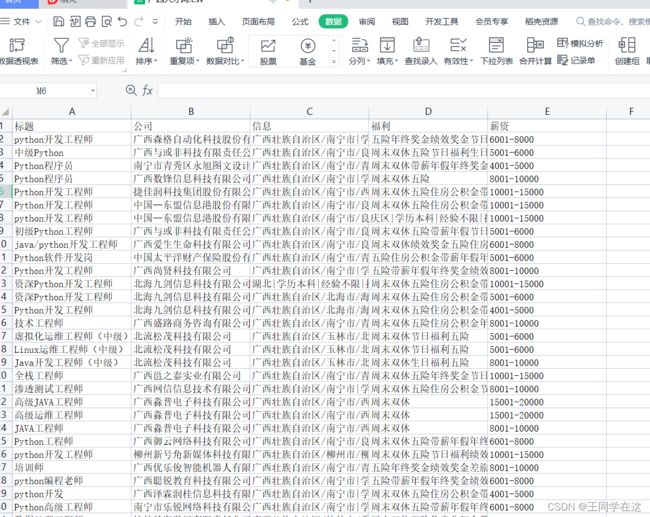
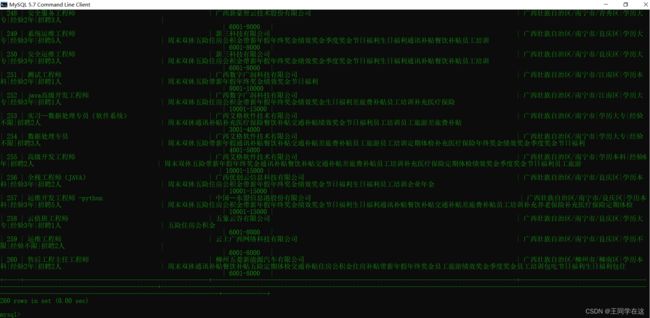
开发准备
基本开发环境
- pycharm
- Python 3.8
scrapy项目的搭建
1.创建项目:
scrapy startproject 项目名
2.然后cd 项目名称,进入项目
cd 项目名字
3.创建一个文件:
scrapy genspider 名称 域名
页面分析
打开网址搜索需要查看的岗位信息(这里我已pytho岗位为例)。

需求信息,标题,公司,薪资,基本要求,这些信息都存储在页面源码div的li标签中,到时候解析数据找到全部div后遍历li提取信息即可。
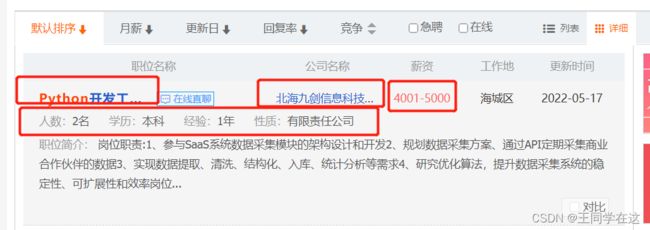
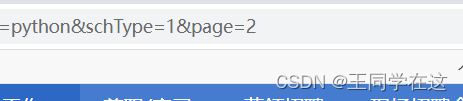
翻页不难发现page代表的是页数
规律
page=2
page=3
page=4
一直往下

接下来进行代码实战
scrapy实现代码部分
settings部分
设置机器人协议为False,增加一个管道类进行MySQL的存储,等相关主要操作
# 让终端显示指定类型的日志信息,只输出错误类型信息
LOG_LEVEL = 'ERROR'
# Crawl responsibly by identifying yourself (and your website) on the user-agent
USER_AGENT = 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/101.0.4951.54 Safari/537.36'
# Obey robots.txt rules
ROBOTSTXT_OBEY = False # 机器人协议
# 俩个管道类,一个存储csv,一个存储MySQL
ITEM_PIPELINES = {
'gxrc.pipelines.GxrcPipeline': 300,
'gxrc.pipelines.mysqlPipeline': 301,
}
starts部分
在项目中自己新建一个py来进行项目的运行,不用在终端一直打命令
from scrapy import cmdline
#开启爬虫
cmdline.execute('scrapy crawl spider'.split(" "))
items部分
把需要提取的数据放进item中
import scrapy
class GxrcItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field()
company = scrapy.Field()
momey = scrapy.Field()
company_text = scrapy.Field()
wafir = scrapy.Field()
spider主要部分
在spider.py中主要进行的是数据提取并把结果交给管道。
import scrapy
from ..items import GxrcItem
import copy
class SpiderSpider(scrapy.Spider):
name = 'spider'
# allowed_domains = ['www.baidu.com'] # 域名
start_urls = ['https://s.gxrc.com/sJob?keyword=python&schType=1&PosType=']
page_num = 2
# 解析
def parse(self, response):
# 列表
all_data = []
# 全部标签
all_li = response.xpath('//*[@id="posList"]/div')
# 遍历
for i in all_li:
items = GxrcItem() # items
items['title'] = i.xpath('string(./ul[1]/li[1]/h3/a)').extract_first()
items['company'] = i.xpath('./ul[1]/li[2]/a/text()').extract_first()
# 详情页
details_url = 'https:' + i.xpath('./ul[1]/li[1]/h3/a/@href')[0].extract()
# 发送请求详情页
yield scrapy.Request(url=details_url,dont_filter=True,callback=self.get_details,meta={"items":copy.deepcopy(items)})
# 详情页提取方法
def get_details(self,response):
# 获取item
items = response.meta['items']
# 提取信息
items['momey'] = response.xpath('//*[@id="content"]/div/div[1]/div/div[1]/div[1]/div[2]/text()').extract()[0].replace(' ','').replace('\n','').replace('\r','')
items['company_text'] = response.xpath('string(//*[@class="detail"])').extract()[0].replace('\n','')
items['wafir'] = response.xpath('string(//*[@class="welfare-con con"]/ul)').extract()[0].replace(' ','').replace('\n','').replace('\r','')
print(items)
yield items # 提交管道
# 翻页
if self.page_num <= 14:
url = f'https://s.gxrc.com/sJob?schType=1&pageSize=20&orderType=0&listValue=1&keyword=python&page={self.page_num}'
self.page_num += 1
# 请求新的url,回调
yield scrapy.Request(url,callback=self.parse)
pipelines部分
注意:在连接MySQL那里先创建好一个数据库,我这的数据库是(gxrc)。
这里本来有一个管道类,然后进行其他存储的方式就多定义多了一个管道类用来把数据存储到MySQL数据库中,随后在setting中添加新的管道类即可。
import csv
import pymysql
# csv存储
class GxrcPipeline:
def __init__(self):
self.filt = open('招聘信息.csv','w',newline='',encoding='utf-8')
self.csv = csv.writer(self.filt)
self.csv.writerow(['标题','公司','信息','福利','薪资'])
def process_item(self,item, spider):
# 保存csv
self.csv.writerow([item['title'],item['company'],item['company_text'],item['wafir'],item['momey']])
return item
def close_csv(self,spider):
self.filt.close()
# 管道文件中一个管道类对应将一组数据存储到一个平台或者载体中
class mysqlPipeline(object):
mysql = None
cursor = None
def open_spider(self,spider):
self.mysql = pymysql.Connect(host='localhost',user='root',password='111111',port=3306,charset='utf8',database='gxrc')
self.cursor = self.mysql.cursor() # 创建游标对象
def process_item(self,item,spider):
# 创建表
table = 'create table if not exists job(' \
'id int not null primary key auto_increment' \
',标题 varchar(250)' \
',公司 varchar(1050)' \
',信息 varchar(1000)' \
',福利 varchar(250)' \
',薪资 varchar(250)' \
');'
insert = 'insert into job(标题,公司,信息,福利,薪资) values("%s","%s","%s","%s","%s")'%(item['title'],item['company'],item['company_text'],item['wafir'],item['momey'])
try:
# 创建表
self.cursor.execute(table)
# 插入数据
self.cursor.execute(insert)
self.mysql.commit()
except Exception as e:
print('===============插入数据失败===============',e)
self.mysql.rollback()
return item # 传递给下一个即将被执行的管道类
# 关闭MySQL连接
def close_spider(self,spider):
self.cursor.close()
self.mysql.close()
这样我们就完成了对信息的存储过程。
总结
如果本文对你学习有所帮助-可以点赞+ 关注!将持续更新更多新的文章。