K8S 学习四(POD详解)
POD结构
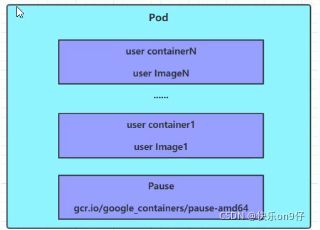
每个pod中都可以包含一个或者多个容器,这些容器可以分为两类:
1) 用户程序所在的容器,数量可多可少(上图的第一、第二层)
2) Pause容器,这是每个pod都会有的一个根容器,它的作用有两个 :
2.1)可以以它为依据,评估整个Pod的健康状态
2.2) 可以在根容器上设置IP地址,其他容器都以此IP(Pod ip),以实现POD内部的网路通信
这里POD内部的通讯,POD之间的通讯采用虚拟二层网络技术来实现,我们当前用的环境是Flannel.
定义Pod
下面是pod的资源清单:
#下面是Pod的资源清单
apiVersion: v1 #必选版本号,例如v1
kind: Pod #必选,资源类型,例如Pod
metadata: #必选,元数据
name: string #必须,Pod名称
namespace: string #Pod所属的命名空间,默认为:default
labels: #自定义标签列表
- name: string
spec: #必选,Pod中容器的详细定义
containers: #必选,Pod中容器列表
- name: string #必选,容器名称
image: string #必选,容器的镜像名称
imagePullPolicy: [ Always|Never|IfNotPresent ] #获取镜像的策略
command: [string] #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args: [string] #容器启动命令参数列表
workingDir: string #容器的工作目录
volumeMounts: #挂载到容器 内部的储存卷配置
- name: string #应用pod定义的共享储存卷的名称,需要volumens[]部门定义的卷名
mountPath: string #存储卷在容器内mount的绝对路径,应该少于512字符
readOnly: boolean #是否为制度模式
ports: #需要暴露的端口库列表
- name: string #端口名称
containerPort: int #容器需要监听的端口号
hostPort: int #容器所在主机需要监听的端口号,默认与Container相同
protocol: string #端口协议支持TCP和UDP,默认TCP
env: #容器运行钱需要设置的环境变量列表
- name: string #环境变量名称
value: string #环境变量的值
resources: #资源限制和请求的设置
limits: #支援限制的设置
cpu: string #CPu的限制,单位为core数,将用于docker run --cpu-shares参数
memory: string #内存限制,单位可以为mib、gib,将用于dockeer run --momory参数
requests: #资源请求的设置
cpu: string #Cpu请求,容器启动的初始可用数量
memory: string #内存请求,容器启动的出师可用数量
lifecycle: #生命周期钩子
postStart: #容器启动后立即执行此钩子,如果执行失败,会根据重启策略进行重启
preStop: #容器终止前执行此钩子,无论结果如何,容器都会终止
livenessProbe: #对Pod内各个容器健康检查的设置,当探测无响应几次之后会自动重启该容器
exec: #对Pod容器内检查方式设为exec方式
command: [string] #exec方式需要定制的命令或脚本
httpGet: #对piod内个容器健康检查方法设置为HttpGet,需要定制path。port
path: string
port: number
host: string清单中有这么多字段,怎么记呢? 可以使用以下命令查看:
#在这里,可以通过命令来查看每种资源的可配置项
#kubectl explain 资源类型。 (查看某种资源可以配置的1级属性字段)
#kubectl explain 资源类型.属性。 查看属性的子属性(一定要Object)
例如:
[root@master ~]# kubectl explain pod
KIND : POD
VERSION: v1
FIELDS:
apiVersion
kind
metadata K8s清单属性解说
查看pod以yaml的形式展示:
kubectl get pods 【podname】 -n dev -o yaml

K8s资源清单 一级属性都是一样的,主要包含5个部分:
· apVersion
· kind
· metadata
` spec
· status
在上面的属性中,spec是接下来研究的重点,继续看他常见的子属性
· containers <[]Object> 容器列表,用于定义容器的详细信息
·nodeName
· nodeSelector
· hostNetwork
· volumes <[]Object> 存储卷,用于定义Pod上面挂载的存储信息
· restartPolicy
Pod配置
本小节主要用来研究pod.spec.containers属性,这也是pod配置中最为关键的一项配置
[root@master ~]# kubectl explain pod.spec.containers
KIND : POD
VERSION : v1
RESOURCE: containers<[]Object> #数组,代表可以有多个容器
FIELDS:
name #容器名称
image #容器需要构建的镜像地址
imagePullPolicy #镜像拉取策略(镜像是使用本地的还是远程仓库的)
command <[]string> #容器的启动命令列表,如不指定,使用打包时使用的启动命令
args <[]string> #容器启动命令需要的参数列表
env <[]Object> #容器环境变量配置
ports #容器需要暴露的端口列表
resources Pod基本配置--name和image
创建pod-base.yaml文件内容如下:
apiVersion: v1
kind: Pod
metadata:
name: pod-base
namespace: dev
labls:
user: alenTest
spec:
containers:
- name: nginx
image: nginx:1.17.1 #这个镜像从何而来?在搭建集群的时候,在安装docker的时候已经通过配置文件已经指向了阿里的镜像仓库。 具体可以看回第一章,安装集群docker篇
- name: busybox
image: buybox:1.30上面定义了一个比较简单的Pod的配置,里面有两个容器:
1)nginx:用1.17.1版本的nginx镜像创建,(nginx是一个轻量级的web容器)
2)busybox:用1.30版本的busybox镜像创造,(busybox是一个小巧的linux命令集合包)

上图有一个容器不断尝试restart都重启不起来,可以通过以下命令去查看:
kubectl discribe pods [podname] -n dev [-n namespace name]
查看容器启动日志:
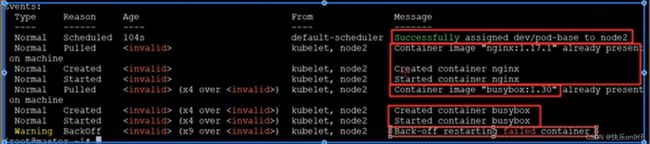
日志中显示,创建busybox的时候,容器有问题了.. 这里先忽略
Pod基本配置--镜像拉取策略imagePullPolicy
来看下面例子
apiVersion: v1
kind: Pod
metadata:
name: pod-base
namespace: dev
labls:
user: alenTest
spec:
containers:
- name: nginx
image: nginx:1.17.1
imagePullPolicy: Always #用于设置镜像拉取策略
- name: busybox
image: buybox:1.30imagePullPolicy, 用于设置镜像拉取策略,K8S支持配置三种拉取策略:
1) Always:总说从远程仓库拉取镜像(一直用远程的)
2)ifNotPresent:本地有几句用本地镜像,本地无就用远程的
3)Never:一直使用本地镜像
imagePullPolicy默认值说明:
如果镜像tag为具体版本号,默认策略识ifNotPersent
如果镜像tag为latest(最终版本),默认策略识always
POD基本配置--启动命令
在上面遇到一个问题一直没有解决,就是busybox容器,一直没有运行.到底是什么原因呢咁?
原来busybox不是一个程序,而是类似一个工具类的集合,K8s集群启动管理后,它会自动关闭,解决办法就是让其一直云效,这就用到了command配置。
创建pod-command.yaml文件,内容如下:
appVersion: v1
kind: Pod
metadata:
name: pod-command
namespace: dev
spec:
containers:
-name: nginx
image: nginx:1.17.1
-name: buybox
image: buybox:1.30
command: ["/bin/sh'","-c","touch /tem/hello.txt;while true;do /bin/echo $(data +%T) >> /tmp/hello.txt; sleep 3; done;"]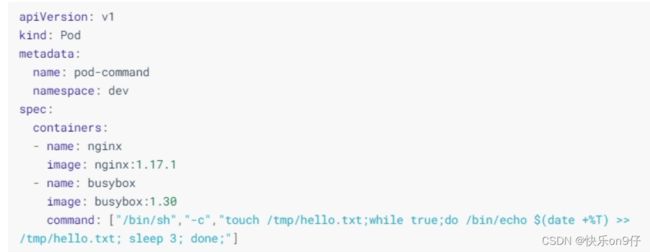 command,用于在pod中的容器初始化完毕之后运行的一个命令。
command,用于在pod中的容器初始化完毕之后运行的一个命令。
稍微解析上面命令的意思:
"/bin/sh","-c", 使用sh命令执行
touch /tep/hello.txt 创建一个 /temp/hello.txt文件
while true;do /bin/echo ${data + %T)>> /tmp/hello.txt; sleep 3; done
每个三秒向文件中写入当前时间#按照上面的脚本,创建一份yaml
vim pod-cammand.yaml
#根据yaml创建一个pod
kubectl create -f pod-ammand.yaml
#查看现在容器是否有运行两个
kubectl get pods -n dev看看效果试试
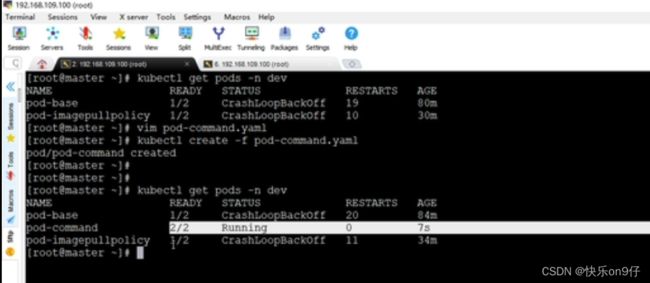
#进入pod中busybox容器,查看文件内容
#补充一个命令:kubectl exec pod名称 -n 命名空间 -it -c 容器名称 /bin/sh 在容器内部执行命令
#使用这个命令就可以进入容器内部,然后进行相关操作
#比如查看txt文件内容
kubectl exec pod-command -n dev -it -c busybox /bin/sh
/#
/# #已经入容器了..
/# tail -f /tmp/hello.txt
13:00:01
13:00:02
13:00:03
#特别说明:
通过上面发现command已经可以完成启动命令和传递参数的功能,为什么这里还要提供一个armgs选项,用于传递参数呢?这其实和docker有点关系,k8s中的command和args两项其实是实现覆盖dockerfile中ENTRYPOINT
1:如果command和args都没有写,那么就用dockerfile的配置
2:如果command写了,但args没有写,那么dockerfile默认的配置会被忽略,执行输入的command
3;如果command没有写,但args写了,那么dockerfile中配置的ENTRYPOINT命令会被执行,使用当前args的参数
4:如果command和args都写了,那么dockerfille的配置会被忽略,执行command并追加args参数POD配置-环境变量
本小节主要来研究pod.spec.containers属性,这也是pod配置中最为关键的一项配置。
kubectl explain pod.spec.containers
KIND: pod
VERSION: v1
RESOURCE: containers <[]object> #数组,可以代表多个容器
FIELDS:
name #容器名称
image #容器需要的镜像地址
imagePullPolicy #镜像拉取策略
command <[]string> #容器的启动命令列表,如不指定,使用打包时候的使用的启动命令
args <[]string> #容器的启动命令需要的参数
env <[]Object> #容器环境变量配置
ports #容器需要暴露的端口列表
resources 环境变量:

接下来用以上的yaml来试试创建pod,
1:创建yaml文件
2: 创建pod
3:查看pod是否创建成功
4:kubectl exec -it进入容器内部(注意,pod只有一个容器在云效的时候,可以忽略-c 指定容器名称)
5:echo $username --> 输出环境变量名为username的值。 可以看得到容器的环境变量值是正确的,退出。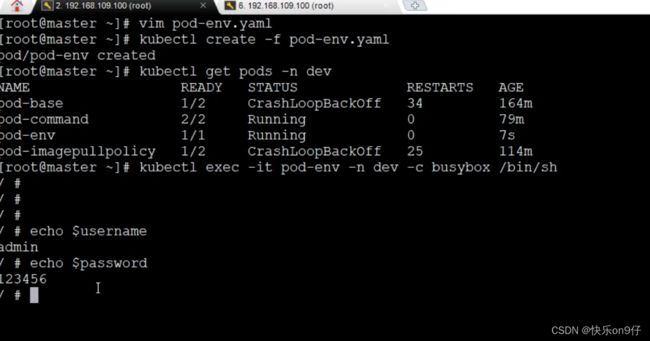
这种方式不是很推荐,我们推荐的是将这些配置文件单独存储在配置文件中。这种方式后面再介绍。
pod基本配置 端口设置--容器需要暴露的端口,
首先看一下ports支持的子选项:
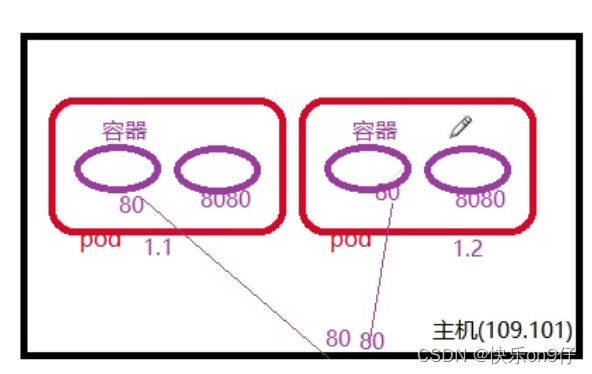
 这里解析一下containerPort(容器IP)和hostPort的意思:
这里解析一下containerPort(容器IP)和hostPort的意思:
如下图,假设主机资源内有两个pod, 其中一个container的port是80,另外一个是8080,那么containerPort==80了, hostPort意思是将容器的端口到去这台主机资源的端口上去,即是容器端口=机器端口, 因为外部访问是通过 容器端口+主机IP 就是一个访问套接字了. 所以! 如果设置hostport,主机上只能运行容器的一个服务。 不然就会占用端口了。
来创建个pod试试:
 用上面写的yaml操作下图:
用上面写的yaml操作下图:
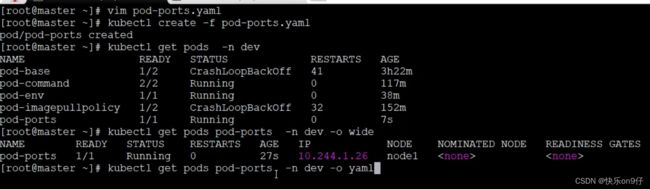
Kubectl get pods -o wide==没有看到port,直接用yaml展示查看。、
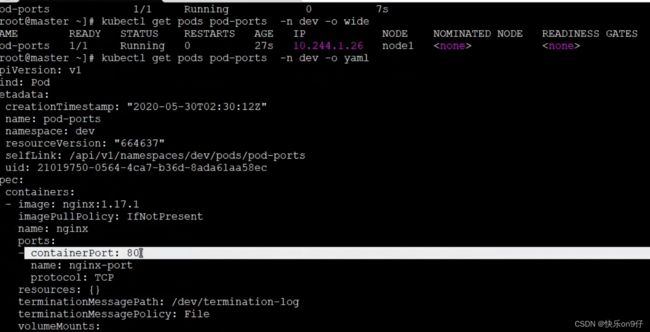
或者用 describe命令来查看容器的端口。
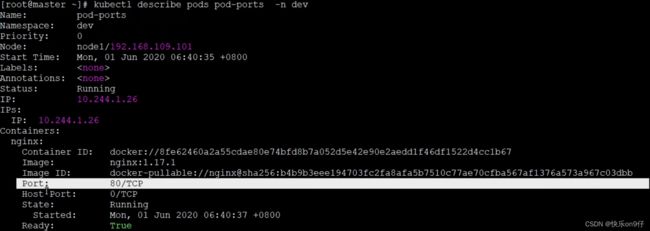
访问容器中的程序需要使用的是:
PODIP:contaniner port
POD配置-资源配额
容器中的程序要运行,肯定要占用一定资源的,比如cpu和内存等,如果不对某个内容的资源做限制,那么它就可能吃掉大量资源,导致其他容器无法运行,针对这种情况,k8s提供了对内存和cpu的资源进行配额的机制..如下图所示:
这里比如Pod里面有ABCDEFG这么多个容器, 要知道节点的内存是固定的,如果A容器发疯突然吃大量的内存,会导致其他容器内存不足。 于是就有个方法,比如限制A最多只能吃500M的内存,超过500M就会重启这个容器。
这种机制主要通过resources选项实现,他有两个子选项:
1. limits: 用于限制运行时容器的最大占用资源,当容器占用资源超过limites时会被种植,并进行重启
2,requests:用于设置容器需要的最小资源,如果环境资源不够,容器将无法启动
可以通过上面两个选项设置资源的上下限。接下来,编写一个测试案例,创建
pod-resouces.yaml
apiVersion: v1
kind: Pod
metadata:
name: pod-resources
namespace: dev
spec:
containers:
- name: nginx
image: nginx:1.17.1
resouces: #资源配额
limits: #限制资源(上限)
cpu: "2" #CPU选址,单位是core数
memory: "10Gi" #内存限制
requests: #请求资源(下限)
cpu: "1"
memory: "10Mi"在这里对cpu和memory的单位做一个说明
cpu: core数,可以为整数或小数
memory:内存大小,可以使用Gi,Mi,G,M等形式
第二个案例:将下限修改成10个G
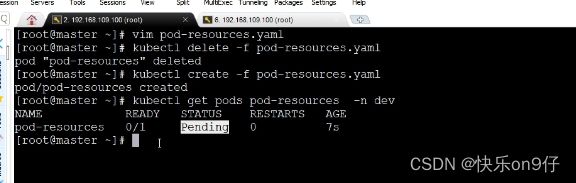
查看后,发现每个节点都内存不足
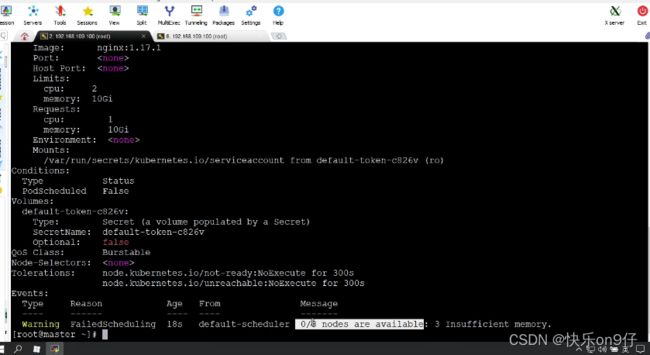
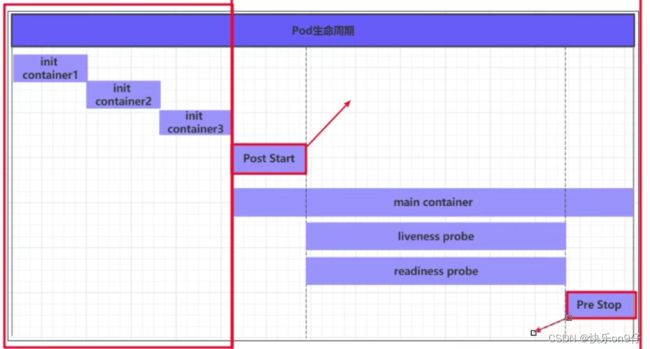
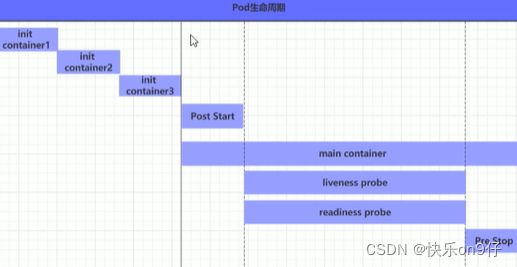
Pod生命周期
我们一般将pod对象从创建至终止的时间范围,它主要包含下面的过程:
1-pod创建过程
2-运行初始化容器(int container) 过程
3-运行主容器(main container)过程
3.1 容器启动后钩子(post start)、容器终止前钩子(per stop)
3.2 容器的存活性探测(llveness probe)\就绪性探测(readiness probe)
4. pod终止过程
下图中,主容器的开始前, 或结束前,都可以传递参数进行操作容器;
在整个生命周期中,pod会出现五种状态(相位),分别如下:
1--挂起(pending): apiserver已经创建了pod资源,但它未被调度完成或处于下载镜像过程中
2:运行中(Runing):pod已经调度到某个节点,并所有容器都已经被Kubelet创建完成
3:成功(Succeeded):pod中所有容器都已经成功终止并不会被重启
4:失败(Failed):所有容器都已经终止,但至少有一个容器终止失败,即容器返回了非0值的推出状态
5: 未知(Unknown):apiserver无法正常获取到pod对象的状态信息,通常由网络通信失败导致
pod创建和终止
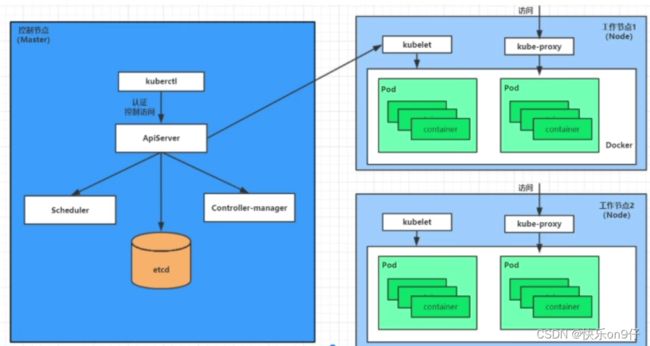
pod的创建过程
1、用户通过kubectl或其他api客户端提交需要创建的pod的信息给apiServer
2、apiServer开始生成pod对象信息,并将信息存入etcd,然后返回确认信息至客户端
3、apiServer开始反映etcd中pod对象的变化,其他组件使用watch机制来跟踪检查apiServer的变动
4、scheduler发现有新的pod对象要创建,开始为pod分配主机并将结果信息更新到apiserver
5、node节点上的kubelet发现有pod调度过来,尝试调用docker启动容器,并将结果返回到apiserver
6、apiserver将接受到的pod状态存入etcd中。
Pod的终止过程
1. 用户向apiServer发送删除pod对象命令
2. apiServer中的pod对象信息会随着时间的推移而更新,在宽限期内(30s默认),pod被视为dead
3.将pod标记为terminating状态
4,kubeclet在监控到pod对象转为terminating状态的同时启动pod关闭过程
5, 端点控制器监控到pod对象的关闭行为时将其从所有匹配到此端点的server资源的端点列表中移除
6,如果当前pd对象定义了preStop钩子处理器,则在其标记为terminating后即会以同步的方式启动执行
7,pod对象中的容器进程收到停止信号
8,宽限期结束后,若pod中还存在仍在运行的进程,那么pod对象会收到立刻终止的信号
9,kubelet请求apiServer将此pod资源的宽限期设置为0从而完成删除操作,此时pod对于用户已不可见
pod的初始化容器
初始化容器是在POD的主容器启动之前要运行的容器,主要是做一些主容器的前置工作,它具有两大特征:
1、初始化容器必须运行完成直至结束,若某个初始化容器运行失败,那么K8S需要重启它知道成功完成。
2、初始化容器必须按照定义的顺序执行,当且仅当前一个成功之后,后面的一个才能运行
(比如运行ngxin,这个ngxin要有前提链接mysql和redis的)
初始化容器有很多应用场景,下面列出的是最常见的几个:
·提供著容器环境中不具备的工具程序或自定义代码
·初始化容器要先于应用容器串行启动并运行完成,因此可用于延后应用容器的启动直至其以来的条件得到满足。
接下来做一个案例,模拟下面这个星球:
假设要以著容器来运行nginx,但是要求在运行ngxin之前先要能够链接上mysql和redis所在的服务器,为了简化测试,实现规定好mysql(192.168.109.201)和redis(192.168.109.202)服务器的地址。 创建pod-initcontalner.yaml内容如下:
下图的initContainers 就是初始化容器的属性了,实际和containers是一样的
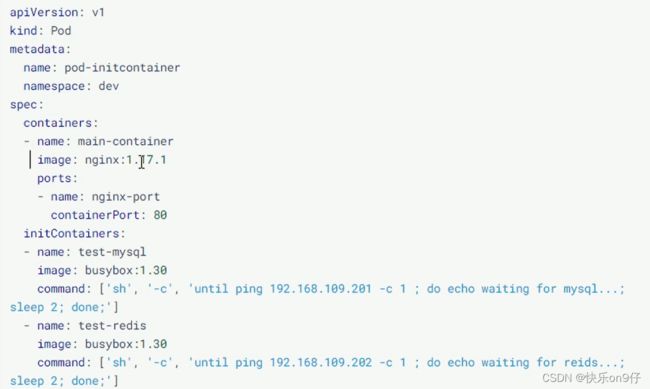
接下来,可以试试看,上面的nginx创建的时机(初始化容器要比真正的容器早创建)
并且是串行的哟!!ABC三个容器,如果B初始化容器创建不成功,K8S会一直循环创建B而卡着C的: 下面IP是不通的 ,所以创建不成功
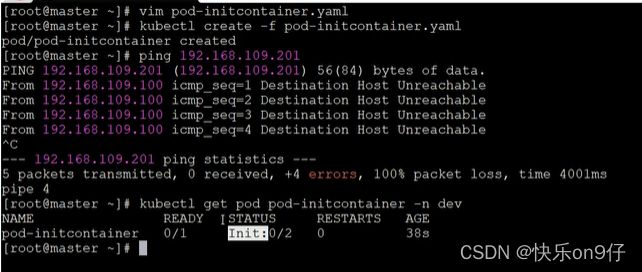
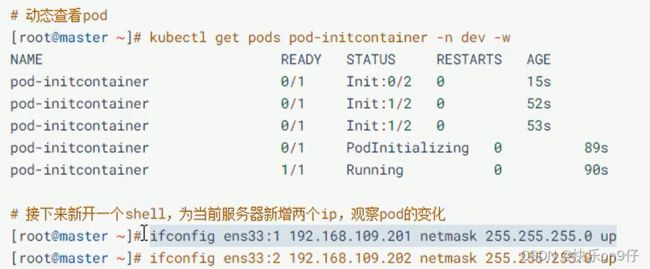
在原来的窗口加上-w动态监听
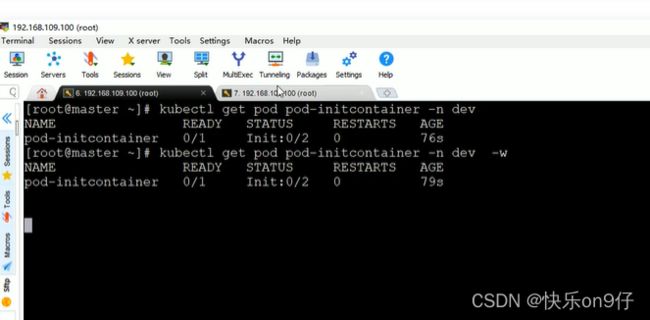
此时新开一个窗口, 添加一下201这个地址。
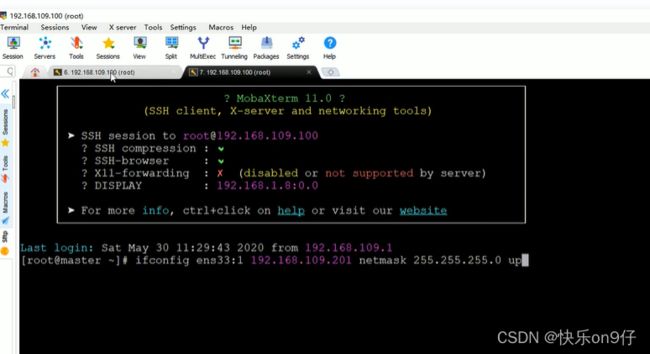
再回来看, 第一个容器,已经起来了。 第二个还是没有跑, 由于初始化容器没完成跑完
这个容器其实海没有跑起来的
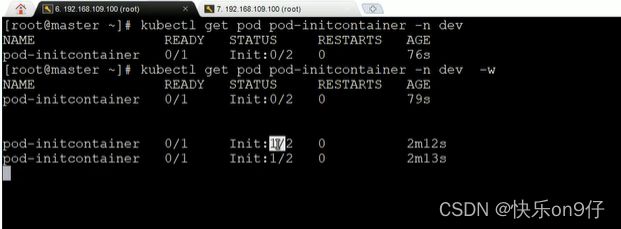
于是,我们又重复上面的步骤,把第二个IP也加进来,ping通它。于是,容器就起来了
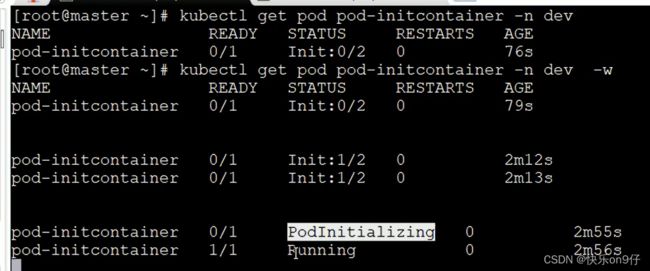
上面的命令:

POD--主容器之钩子函数
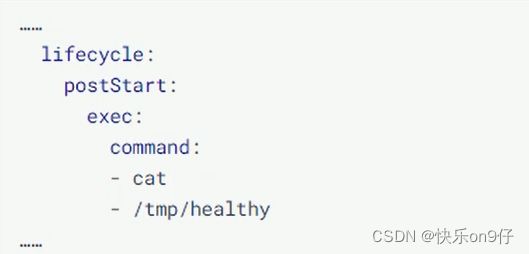
什么是钩子函数呢? 其实钩子函数是K8S给我预留的点, 它允许我们在这些点上去定义一些用户自己的行为代码,当我们的POD运行到这些点的时候,K8S会帮我们调用定义在上面的用户代码,来完成一些指定的功能,这就是钩子函数的作用。
主容器中K8S为我们预留的点分为下面两种:
1、容器启动后钩子(post start)-->如果代码执行成功,容器启动,否则重启容器
2、容器终止前钩子(per stop) -->容器删除时调用,如果代码执行成功,容器会删除,否则会阻塞
K8S有三种方式定义我们的行为代码:
1、Exec命令:在容器内执行一次命令
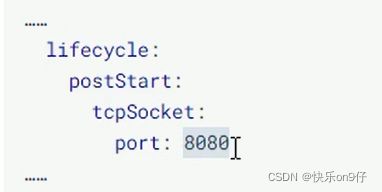
2、TCPSocket:在当前容器尝试访问指定的Socket
也就是说,容器启动后,尝试连接8080,链接成功,容器启动,否则失败
 、
、
HttpGet:在当前容器中向某url发起http请求
下面好像很多,其实就是 http://192.168.109.100:80/
其实就是在容器启动后,向上面的url发送一个get请求。发送成功,容器启动

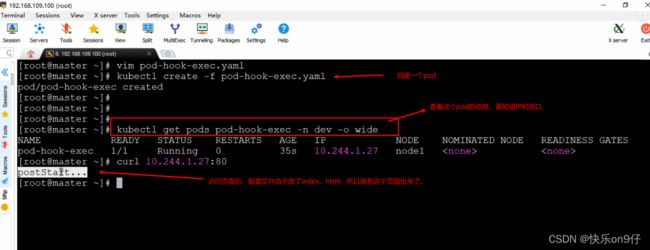
接下来,以exec方式为例,演示一下钩子函数的使用,创建
pod-hook-exec.yaml文件,内容如下:

接下来,试试就上面的yaml,进行一个pod
再次提醒一下,查找yaml的属性,可以用以下命令:
kubectl explain pod.spec--->一个一个找就行了

![]()
Pod容器探测
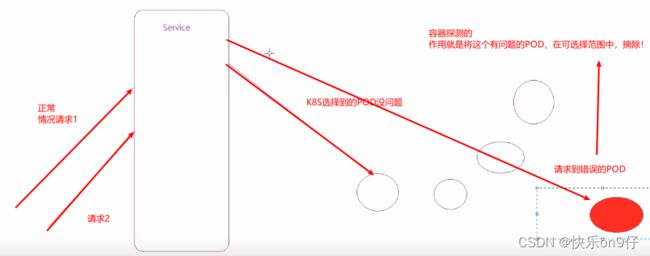
容器探测用于检测容器中的应用实例是否正常工作,是保障业务可用性的一种传统机制,如果经过探测,实例的状态不符合预期,那么K8S就会把该问题实例“摘除”,不承担业务流量,K8S提供了两种探针来实现容器探测的,分别是:
1、liveness probes: 存活性探针,用于检测应用实例当前是否处于正常运行状态,如果不是,k8s会重启容器。
2、readiness probes:就绪型探针,用于检测应用是来当前是否接受请求,如果不能,K8S不会转发流量。
livenessProbe 决定是否重启容器,readinessProbe 决定是否将请求转发给容器
意思大概如下图:
上面两种探针目前均之策三种探测方式:
1、Exec命令:在容器内执行一次命令,如果命令的退出码为0,则认为程序正常,否则不正常

2、TCPSocket:将会尝试访问一个用户容器你的端口,如果能够简历这条连接,则认为程序正常,否则不正常。

3、HttpGet:调用容器内web应用的URL,如果返回的状态在200到399之间正常,否则不正常:

演示:
方式一:Exec
创建pod-liveness-exec.yaml

创建pod,观察效果

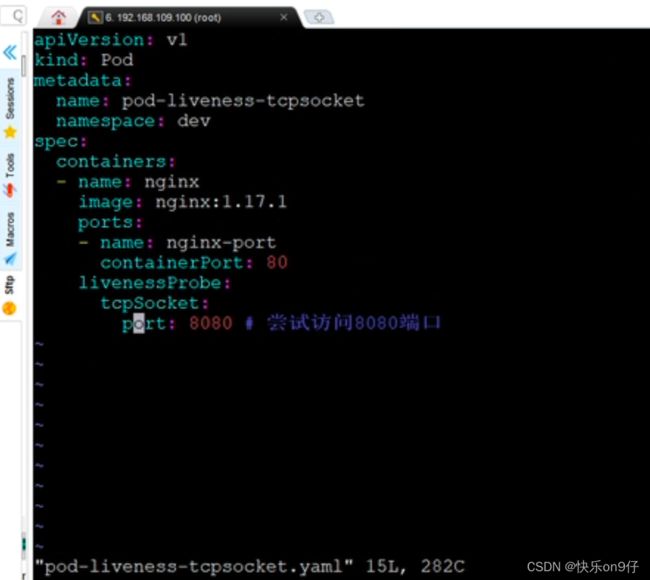
方式二:
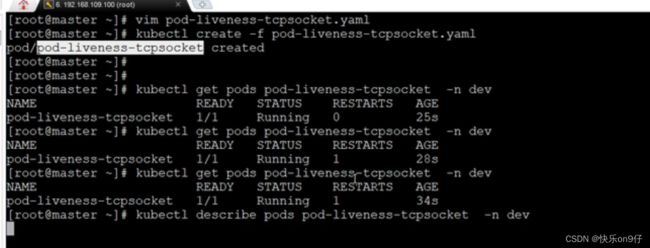
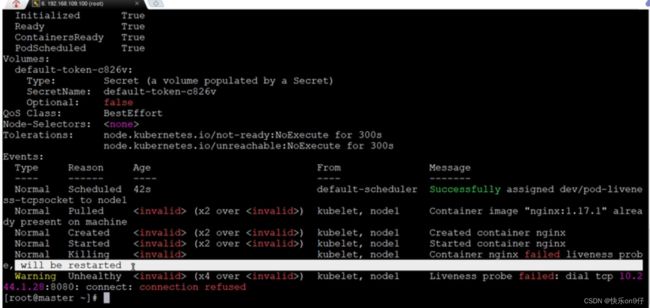
用kubectl describe pods pod-liveness-tcpsocket -n dev 来查看肯定是有问题呃
下图:存活探针探出问题,连接8080链接杯拒绝了:
下面改成80端口就可以了
再用这个配置文件创建pod,检查后,探针没有报错了。
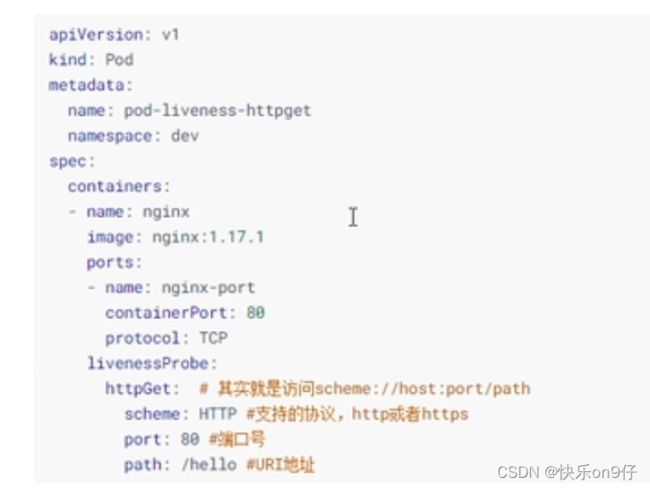
方式三:HttpGet
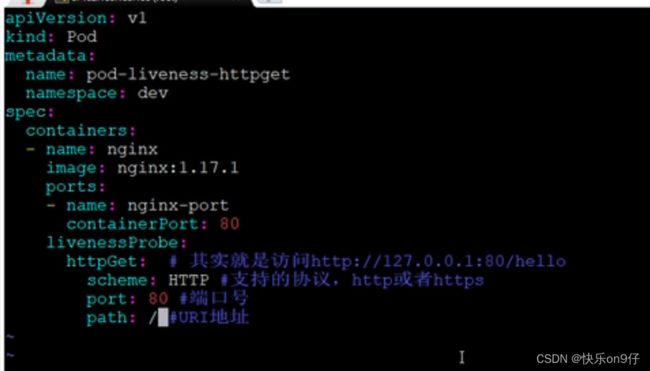
创建pod-liveness-httpget.yaml(相当于是访问本机的http://127.0.0.1:80/hello)
nginx肯定是没有hello的,所以大概会报错
创建pod,观察效果:
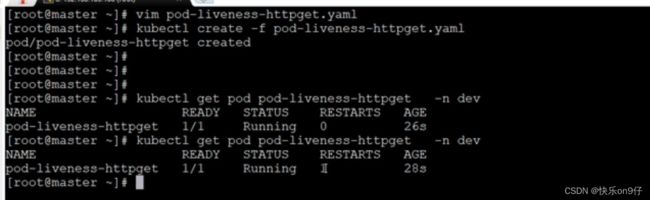
存活性探针失败:404的原因:
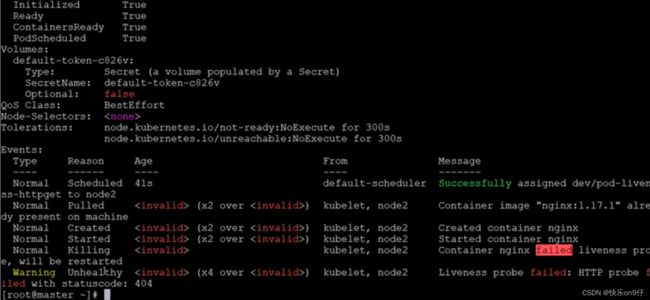 改成正常,就delete掉上面的pod,然后编辑一下把path改成/ 就可以了;
改成正常,就delete掉上面的pod,然后编辑一下把path改成/ 就可以了;
再重新create后,再get一下看看有没有重启就可以了;
Pod容器探测补充
至此已经使用了liveness Probe演示了三种探测方式,但是查看livenessProbe的子属性时发现,除了这三种方式,还有一些其他配置,在这里解析一下:

下面给一个例子:
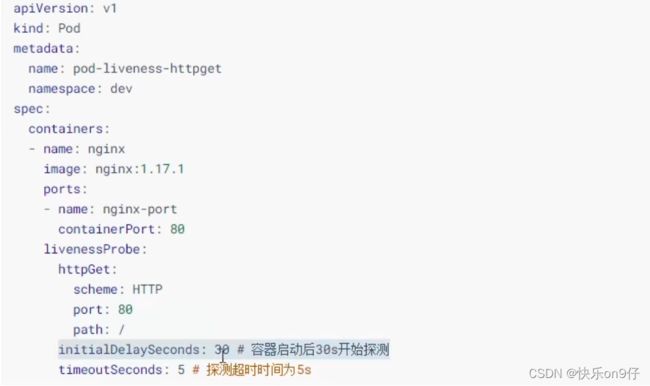
POD详解一已结束