python与机器学习
机器学习
数据挖掘、CV、NLP、语音识别、统计学习、模式识别
套路:1.数据收集处理;2.特征选择与模型构建;3.评估与预测
站点:kaggle github
python库
科学计算库numpy
pandas
线性回归
例子:工资x1、年龄x2、贷款额度y关系关系:;
预测一个值,这个值有区间。工资和年龄是特征;贷款额度是目标或者标签;
拟合一个面分割的过程;y= a+b*x1+c*x2;a偏置参数对结果影响小;bc权重参数,对结果影响大。
真实值y与预测值y'的误差 ;一万个样本一万个,这些误差满足:独立同分布,均值0方差为~的高斯分析。
;一万个样本一万个,这些误差满足:独立同分布,均值0方差为~的高斯分析。
独立即两个贷款人样本不相关。
同分布即都来同一个银行贷款。
高斯分布即贷款浮动满足正太分布,浮动不会大。

似然函数:乘积,用来根据样本数据估计参数值。

最大似然估计:似然函数越大越好----预测值成为真实值的可能性。

目标函数求偏导数=0,求极小值。
凸优化--凸函数
X即工资和年龄,Y是贷款额。

评估方法:R方

梯度下降策略
就是找山谷最低点,即目标函数的极值点。什么样的参数能使目标函数达到极值点。
按照一定方向、步伐更新参数。

批量梯度下降:速度慢。
随机梯度下降:不定收敛。
小批量梯度下降:常用。学习率,步长,小一点。批处理数量,32,64,128等。考虑内存和效率。

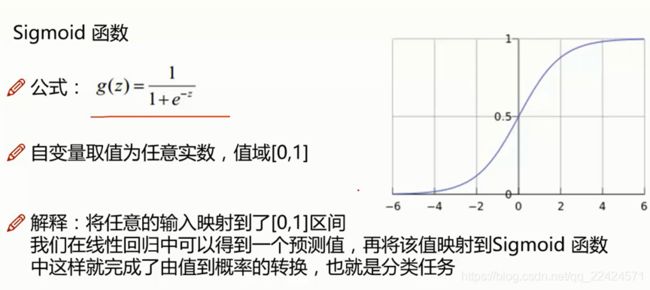
逻辑回归算法
做的是二分类任务。
机器学习算法一般先用逻辑回归简单算法,不行再复杂点的算法。
非线性即高阶函数。逻辑回归可以处理非线性问题。


例子:预测大学生是否被录取,大量申请人的历史数据作训练集。
损失函数就是上边的对数似然函数去负号再求平均。
求梯度;
定义停止策略;1.迭代次数;2.损失变化;3.根据梯度;
数据洗牌,提高泛化能力;np.random.shuffle(data)
实验对比过程:
1.调节停止策略;迭代次数;损失;梯度;
2.调节学习率;
3.使用mini-batch替代批量梯度下降;
4.数据标准化;
评估指标:精度;

案例:交易数据异常检测
1.背景
pandas读取csv数据;
第一行是已经提取好的特征;
0是正常;1是异常;本质是个分类任务;故使用使用逻辑回归二分类。
2.数据处理
正负样本比例统计-》样本不均衡的解决方法-》下采样与过采样方案;
sklearn库-》预处理模块,数据处理fit_transform()得到新的特征;
drop无用的特征;
正常的数据下采样到异常一样的数据;index;
交叉验证:
80%训练集-20%测试集,数据切分;80%的训练集又分出验证机集-》交叉验证求平均。
klearn.cross_validation
模型评估:recall召回率;
TP:true positive,预测对了,预测成了正样本;
FP,false positive;错误判断成正样本;存伪;
FN,false negative;错误判断成了负样本;
TN,true negative;预测对了,预测成了负样本;
recall = TP/(TP+FN)
混淆矩阵:
实际兼顾精度与召回;
正则化惩罚项:
loss后边加上L1/L2正则项;惩罚力度有个因子;
SMOTE数据上采样生成:
1.找出少数种类,计算欧氏距离得到k近邻排序;
2.采样倍率;
3.生成新数据;
![]()
决策树算法
分类树和回归树都可以。
从根节点到叶子节点,来决策,完成分类或者回归。
根节点是最重要的因素;
非叶子节点:中间过程;
叶子节点:决策结果;
增加一个节点相当于数据切一刀分开;
训练:构造决策树-》选择节点-》衡量标准-》熵值;
测试:数据走一遍即可;
熵值:随机变量的不确定性;混乱程度;熵值越高,越乱,越不稳定;
![]()
信息增益:表示特征X使得类别Y的熵值减小(不确定性减小)的程度。
即分类后,类内同类的多,即熵值小;
信息增益率:考虑自身熵值;
GINI系数:

越小则越 接近1,越确定,熵值越小;
决策树剪枝:防止过拟合;
预剪枝:边建立边剪枝;限制树深度,叶子节点个数,叶子节点样本数,信息增益等。
后剪枝:建立完再剪枝;一定的衡量标准来判定;
sklearn决策树参数:
内置数据集:
![]()


可视化graphviz包:
sklearn构建:
切分训练集与测试集;
参数选择:gridSearchCV模块;
集成算法
ensemble learning
bagging集成模型
并行训练多个分类器取平均;
随机森林:多个决策树并行放在一起;数据采样随机;特征选择随机;->提高泛化能力;
树模型个数并不是越多越好;达到一定量就不提高了;
特征重要性衡量:特征破坏看误差;作用:特征筛选;
boosting提升模型
adaboost: 根据前一次的分类效果调整数据权重;前边训练错了,后边权重则增加;
xgboost:后边;
stacking堆叠模型
聚合多个分类或回归模型;如KNN,SVM, RF;
第一阶段得出各自结果;第二阶段再用前一阶段的结果训练;
准确率提升,速度慢;
案例实战:泰坦尼克获救预测
船员数据分析:label;特征:性别,年龄,名字,老人和孩子数量,票编号,票价,站点;
数据预处理:
pandas读取csv;
缺失值处理:去掉列 or 缺失值填充:均值;
male与female替换成0和1;
构建算法模型:
线性回归:sklearn,交叉验证分割数据集;
逻辑回归:sklearn;
随机森林分类也可以:调参,树的个数;特征工程,加特征,造特征;
随机森林特征重要性分析:
贝叶斯算法
逆概问题;正向概率,逆向概率;
贝叶斯公式:

拼写纠正实例:
垃圾邮件过滤实例:
朴素贝叶斯问题假设特征之间独立,互不影响;
拼写检查器实例:
文本数据分析:新闻分类任务
停用词表;stop words;
Tf-idf:关键词提取;Term Frequency (TF)词频统计;
idf: 逆文档频率;