科研训练第三周:关于《Learn from Syntax: Improving Pair-wise Aspect and Opinion Terms Extraction with Ric》的论文阅读
上周查完了关于aspect-opinion抽取的2021相关工作,
这周是精读其中一篇然后下周一(也就是明天)汇报,不过好像被推迟到下下周啦,所以我今天才开始读没啥问题叭
默默吐槽国庆放假三天但是zn专业一堆实验、大作业外加两门课设要肝
前天下午写完RRT寻路算法(花了好大时间画图)
昨天完成了图形学OpenGL的一个小Demo以及一个数独的简单解法(多解还没有做完555~)
另外编译原理好难啊啊啊,写了三个上午的作业还是没写完嘤嘤嘤
Abstract
原文
In this paper, we propose to enhance the pair-wise
aspect and opinion terms extraction (PAOTE) task
by incorporating rich syntactic knowledge. We first
build a syntax fusion encoder for encoding syntactic features, including a label-aware graph convolutional network (LAGCN) for modeling the dependency edges and labels, as well as the POS tags uni-
fiedly, and a local-attention module encoding POS
tags for better term boundary detection. During pairing, we then adopt Biaffine and Triaffine scoring
for high-order aspect-opinion term pairing, in the
meantime re-harnessing the syntax-enriched representations in LAGCN for syntactic-aware scoring.
Experimental results on four benchmark datasets
demonstrate that our model outperforms current
state-of-the-art baselines, meanwhile yielding explainable predictions with syntactic knowledge.
在本文中,作者主要解决的问题是PAOTE,主要创新点在于引入丰富的句法知识进行改进
- 首先,构建句法融合编码器(包含用于统一建模依赖边和标签的以及词性标签的标签感知图卷积网络LAGCN,以及用于更好的检测术语边界的编码词性标签的局部注意模块)
- 接着,采用了双仿射和三仿射评分对高阶方面意见术语进行aspect-opinion配对,同时再次利用LAGCN来做语法感知评分
Motivation
本文的模型致力于解决下述两个问题:
- 现有的ABSA工作仅仅用了句法依存边缘特征而没有考虑句法依存标签特征
- 如何有效地对于重叠结构的建模是目前没有被探索的
Model模型
虽然不太理解,但是这个实验除了加了参数之外很像是搭积木(改进已有的模型为主)
另外感觉Bert一用时间复杂度马上就上去了
虽然BERT它其实……没有跑,直接用的官方参数
这边先挖个坑哈,感觉今天来不及看完所有的理论啦~
结束了,初步的阅读

首先底层BERT,如果你对BERT不理解,戳这里
悄咪咪,其实BERT模型的目标是利用大规模无标注语料训练、获得文本的包含丰富语义信息的Representation

模型概览如上图
解释一下这个图哈~
自底向上的编程思想,计网yyds 顺序:
- 第一步输入:模型以经过BERT编码的上下文单词表示作为输入

v i v_i vi是单词 w i w_i wi的经过BERT上下文编码后的向量化表示 - 第二步输入:将依存边、标签以及词性标记注入到句法融合编码器
- 第三步:术语的分类与过滤
- 第四步AO配对:计算词组间配对的得分(high-order scores 高阶分数 syntactic-aware scores句法分数)
下面结合每一层(步骤)来试着解剖一下公式:
- 第一层Input:输入句子
- 第二层BERT:套用的BERT训练好的参数,这一步没有公式(实际上和直接套用Glove应该差距不大叭,就是BERT的基于上下文的编码更靠谱)
- 第三层Syntax Fusion Encoder:本文的重点啦,使用到的句法知识有依存边、标签以及词性标签。他们给这层起了一个名字:SynFue(有L层,包含了对于词性标签的local attention——是局部注意力机制的意思嘛,我的理解是没有把整句话的pos输入,只输入了标记了的词的pos标签?以及针对每一层上所有语法输入的标签感知GCN)

关于本文提出的融合语言知识的SynFue模型如上图
局部对于pos编码的注意力机制
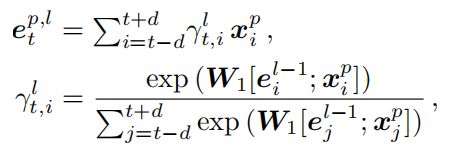
其中 e t p , l e_t^{p,l} etp,l是需要输出的表示, W 1 W_1 W1是需要训练的参数, x i p x_i^p xip是单词 w i w_i wi的pos标签的Embedding, d d d是窗口大小,具体除了限制时间复杂度外我确实不太理解窗口的作用,对一个按窗口大小挨个扫描
对于丰富句法知识具有标签感知的GCN(LAGCN)
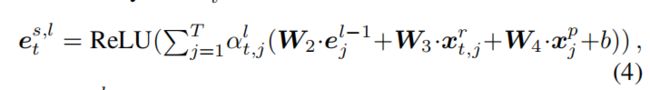
其中 e t s , l e_t^{s,l} ets,l表示单词 w t w_t wt在LAGCN的第l层的表示; a t , j l a_{t,j}^l at,jl是具有语法感知能力的邻居连接强度分布,计算公式如下

(5)(6)中的 b t , j b_{t,j} bt,j表示窗口当中的每一对单词的关系的邻接矩阵(举个栗子,如果单词apple 和 good具有ao关系,则相应的邻接矩阵参数置为1否设置为0); r t , j r_{t,j} rt,j表示单词 w i w_i wi和 w j w_j wj之间的依存关系, x t , j x_{t,j} xt,j则是一村标签的embedding
最终显式地将局部注意力的pos编码与LAGCN的第L层的表示连接为整体的令牌表示
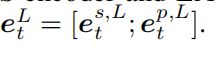
- 第四层:词组的生成与过滤

首先将BERT生成的单词表示和SynFue生成的单词表示粘在一起(兼顾上下文语意以及语法的知识的融合)
下图是根据token表示来做的 span 表示

其中 h h e a d h_{head} hhead和 h t a i l h_{tail} htail是每一个词组的开始、结束的边界表示, h s h_s hs是从Bert编码的完整句子的表示, h p o o l h_{pool} hpool是最大池化操作这里不太懂,是和窗口大小有关的参数么 h s i z e h_{size} hsize是词组的宽度的embedding。FFN表示的是feed for ward layers(前向,喂数据),Dropout是用来缓解过拟合问题。 - 第五层:词组配对
High-order scoring:以往经典的做法是Biaffine scorer,但是它只对于每对之间的二元关系进行建模,但是对于前文提到的三元关系的建模不够,于是提出了High-order scoring(就是一开始的模型的图)
首先Biaffine得到的参数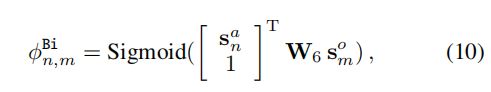
W 6 W_6 W6是要学习的参数, d s d_s ds是词组表示的维度, W 6 W_6 W6形状如下:
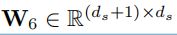
至于 s n a s_n^a sna是对于aspect term的表示的定义;
文中采用了另一种三元组的仿射机制Triaffine scorer(为了同时解决两个重叠的a-o对的问题,形如:
![]()
)
计算公式如下,需要解释的参数 s k ∗ s_k^* sk∗是一个可能是观点aspect 的词组也可能是opinion的词组,这里存疑的地方是,这种建模并没有完全解决重叠的问题吖,比如(apple like good not bad……)这种多个重叠的问题好像文中依旧没有解决:
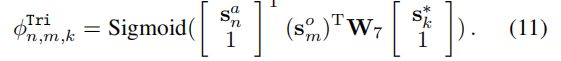
Syntactic-aware scoring:

这里用了cross-attention 对每个 s n , m p s_{n,m}^p sn,mp进行操作【这个在模型整体架构图里面画了,但是还是有点?】


计算所有得分的加和
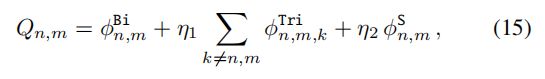
![]()
最后用softmax进行线性处理,拟定一个阈值,评分大于这个阈值的a-o对可以视为合法输出
Experiment实验
训练
首先,定义了一个关于术语识别以及观点对发现的联合损失(17)
![]()

需要提的是,采用了负采样
数据集特征

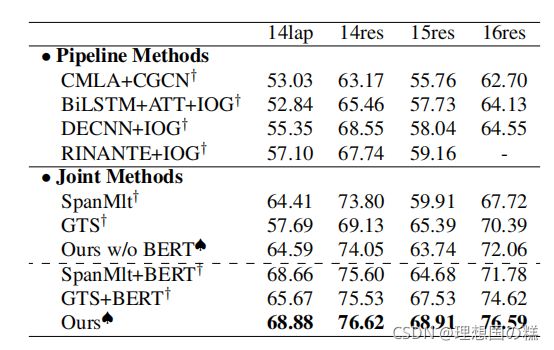
主要实验的结果
P1:数据集以及相关资源
- 语料:14lap, 14res,15res and 16res
- 使用Stanford CoreNLP Toolkit工具来获得依存的词组以及词性标签
- 使用了BERT官方训练好的参数
P2:参数设定
- BERT的向量以及词组表示向量的维度均为768
- 句法标签和词性标签大小分别为100-d,跨度宽度嵌入为25-d
- 优化器:Adam optimizer
- 学习率4e-5
- batch-size:16
- F1 作为评分
*注意的是,在不同的数据集上,参数有微调
P3:Baselines
1、pipline方法:CMLA+CGCN、BiLSTM+ATT+IOG、BiLSTM+ATT+IOG、RINANTE+IOG
2、联合抽取:SpanMlt、GTS
P4:消融实验
实验结果
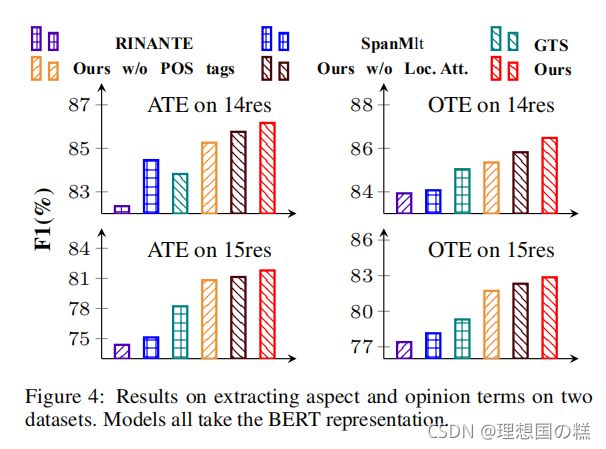

F5是改变了Tri评分和S评分权重的结果,进一步说明了Syntactic-aware scoring评分的重要性,至于Tri评分,由于数据集本身重叠部分占比并没有很多,所以文中认为限制了Tri评分的效果(我觉得是Tri本身建模不太合理?)
- pos标签影响有限
- 负采样策略对于结果影响比较大
- 依存标签的特征对于模型影响比较大
- syntactic-aware scores对于配对作用比较大
- 去除 cross-attention mechanism会影响syntactic-aware scores的有效性
其他
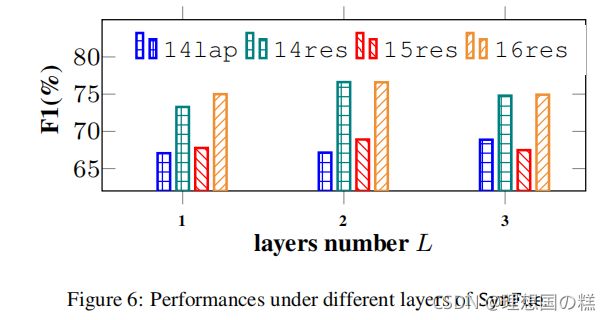
关于 L L L层数的影响,如图6:2层最佳,多了的话,训练集效果会变好,测试集会降低(过拟合)
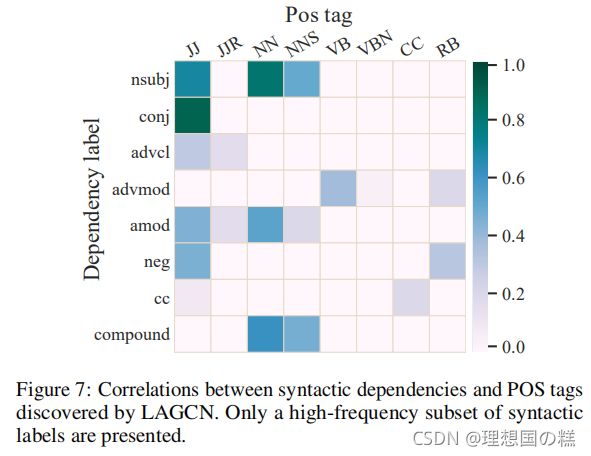
语法相关性,LAGCN可以很好的去捕捉句法依存关系标签与pos标签的关系,图7可见~
10.7终于更新结束,接下来是撸代码啦,555自己算法课设写得LOUVAIN算法正确率低于0.5已经开始怀疑人生稍微辛苦一点叭,zn的大三真的卷麻了
结论
在本研究中,我们研究了一种新的联合模型的两两方面和意见术语提取(PAOTE)。我们提出的语法融合编码器包含了丰富的语法特征,包括依赖边和标签,以及POS标签。在配对过程中,我们同时考虑了方面-意见术语对的高阶评分和句法感知评分。在四个基准数据集上的实验结果表明,与目前最先进的模型相比,我们提出的语法丰富的模型具有更好的性能,证明了丰富的语法知识对这项任务的有效性。