Resnet 介绍
转载自https://www.jianshu.com/p/93990a641066
Resnet
介绍
终于可以说一下Resnet分类网络了,它差不多是当前应用最为广泛的CNN特征提取网络。它的提出始于2015年,作者中间有大名鼎鼎的三位人物He-Kaiming, Ren-Shaoqing, Sun-Jian。绝对是华人学者的骄傲啊。
VGG网络试着探寻了一下深度学习网络的深度究竟可以深几许以能持续地提高分类准确率。我们的一般印象当中,深度学习愈是深(复杂,参数多)愈是有着更强的表达能力。凭着这一基本准则CNN分类网络自Alexnet的7层发展到了VGG的16乃至19层,后来更有了Googlenet的22层。可后来我们发现深度CNN网络达到一定深度后再一味地增加层数并不能带来进一步地分类性能提高,反而会招致网络收敛变得更慢,test dataset的分类准确率也变得更差。排除数据集过小带来的模型过拟合等问题后,我们发现过深的网络仍然还会使分类准确度下降(相对于较浅些的网络而言)。
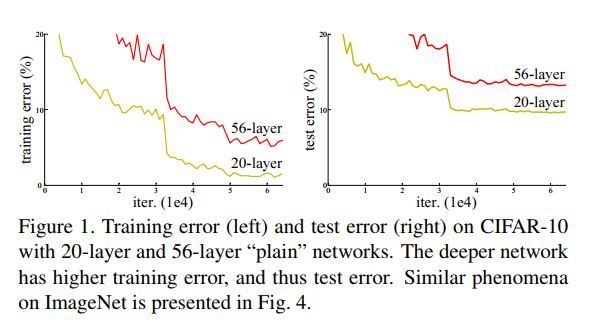
常规CNN网络后期层数增加带来的分类准确率的降低
正是受制于此不清不楚的问题,VGG网络达到19层后再增加层数就开始导致分类性能的下降。而Resnet网络作者则想到了常规计算机视觉领域常用的residual representation的概念,并进一步将它应用在了CNN模型的构建当中,于是就有了基本的residual learning的block。它通过使用多个有参层来学习输入输出之间的残差表示,而非像一般CNN网络(如Alexnet/VGG等)那样使用有参层来直接尝试学习输入、输出之间的映射。实验表明使用一般意义上的有参层来直接学习残差比直接学习输入、输出间映射要容易得多(收敛速度更快),也有效得多(可通过使用更多的层来达到更高的分类精度)。
当下Resnet已经代替VGG成为一般计算机视觉领域问题中的基础特征提取网络。当下Facebook乍提出的可有效生成多尺度特征表达的FPN网络也可通过将Resnet作为其发挥能力的基础网络从而得到一张图片最优的CNN特征组合集合。
深度残差学习(Deep Residual learning)
残差学习
若将输入设为X,将某一有参网络层设为H,那么以X为输入的此层的输出将为H(X)。一般的CNN网络如Alexnet/VGG等会直接通过训练学习出参数函数H的表达,从而直接学习X -> H(X)。
而残差学习则是致力于使用多个有参网络层来学习输入、输出之间的参差即H(X) - X即学习X -> (H(X) - X) + X。其中X这一部分为直接的identity mapping,而H(X) - X则为有参网络层要学习的输入输出间残差。
下图为残差学习这一思想的基本表示。
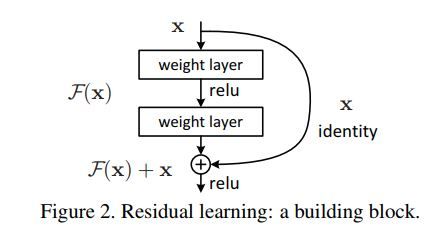
残差学习的基本单元
Identity mapping
上小节中,我们知道残差学习单元通过Identity mapping的引入在输入、输出之间建立了一条直接的关联通道,从而使得强大的有参层集中精力学习输入、输出之间的残差。一般我们用F(X, Wi)来表示残差映射,那么输出即为:Y = F(X, Wi) + X。当输入、输出通道数相同时,我们自然可以如此直接使用X进行相加。而当它们之间的通道数目不同时,我们就需要考虑建立一种有效的identity mapping函数从而可以使得处理后的输入X与输出Y的通道数目相同即Y = F(X, Wi) + Ws*X。
当X与Y通道数目不同时,作者尝试了两种identity mapping的方式。一种即简单地将X相对Y缺失的通道直接补零从而使其能够相对齐的方式,另一种则是通过使用1x1的conv来表示Ws映射从而使得最终输入与输出的通道达到一致的方式。
实验比较所用到的残差网络结构与朴素网络结构

残差网络与朴素网络结构之间的对比
作者为了表明残差网络的有效性,共使用了三种网络进行实验。其一为VGG19网络(这是VGG paper中最深的亦是最有效的一种网络结构),另外则是顺着VGG网络思维继续加深其层次而形成的一种VGG朴素网络,它共有34个含参层。最后则是与上述34层朴素网络相对应的Resnet网络,它主要由上节中所介绍的残差单元来构成。
在具体实现残差网络时,对于其中的输入、输出通道数目不同的情况作者使用了两种可能的选择。A)shortcut直接使用identity mapping,不足的通道通同补零来对齐;B)使用1x1的Conv来表示Ws映射,从而使得输入、输出通道数目相同。
自下面两表中,我们可看出残差网络能够在深度增加的情况下维持强劲的准确率增长,有效地避免了VGG网络中层数增加到一定程度,模型准确度不升反降的问题。
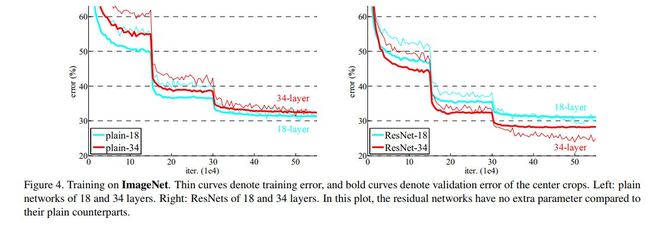
不同深度的朴素网络与残差网络在Imagenet上的性能表现
不同深度的朴素网络与残差网络在Imagenet上的性能表现其二
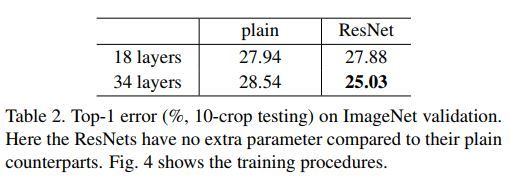
然后自下表中,我们可以看到常规Resnet网络与其它网络如VGG/Googlenet等在Imagenet validation dataset上的性能比较。
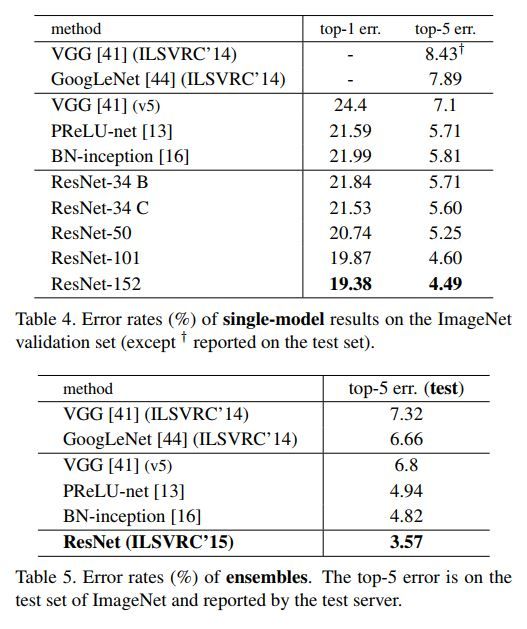
Resnet常规网络与其它模型之间的性能比较
bottleneck构建模块
为了实际计算的考虑,作者提出了一种bottleneck的结构块来代替常规的Resedual block,它像Inception网络那样通过使用1x1 conv来巧妙地缩减或扩张feature map维度从而使得我们的3x3 conv的filters数目不受外界即上一层输入的影响,自然它的输出也不会影响到下一层module。
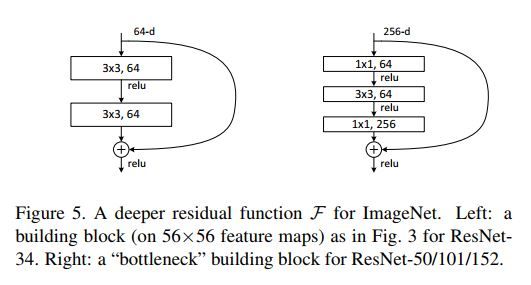
Bottleneck模块
不过它纯是为了节省计算时间进而缩小整个模型训练所需的时间而设计的,对最终的模型精度并无影响。
CIFAR10上更深的Resnet网络
作者进一步在小的CIFAR10数据集上尝试了更深的Resnet网络,其深度最多达到了1202层。不过却发现分类性能终于开始有了一定下降。作者分析认为可能是层数过多,导致模型过于复杂,而CIFAR-10较小的数据集造成了它的过拟合吧。
如下表为其疯狂的实验结果。
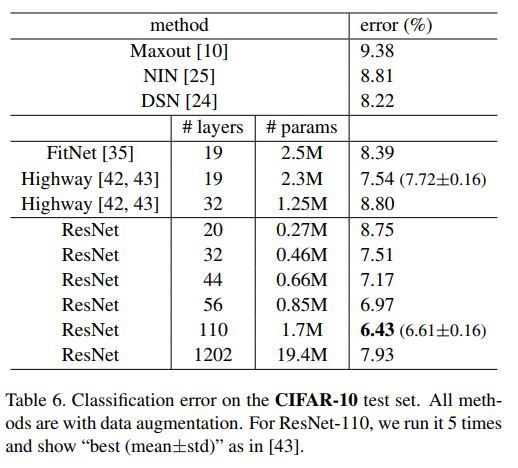
CIFAR-10上更深的Resnet网络的应用
代码实例
数据输入层
name: "ResNet-50"
layer {
name: "data"
type: "Data"
top: "data"
top: "label"
include {
phase: TRAIN
}
transform_param {
mirror: true
crop_size: 224
mean_file: "data/ilsvrc12/imagenet_mean.binaryproto"
}
data_param {
source: "examples/imagenet/ilsvrc12_train_lmdb"
batch_size: 50
backend: LMDB
prefetch: 2
}
}
如下为构成Resnet网络的一个residual block表示。注意它这里的identity mapping中包含了一个1x1 conv表示的Ws。而网络中其它的若干模块则可能直接使用的identity mapping,而不含任何有参层。
layer {
bottom: "pool1"
top: "res2a_branch1"
name: "res2a_branch1"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
bottom: "res2a_branch1"
top: "res2a_branch1"
name: "bn2a_branch1"
type: "BatchNorm"
batch_norm_param {
}
}
layer {
bottom: "res2a_branch1"
top: "res2a_branch1"
name: "scale2a_branch1"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "pool1"
top: "res2a_branch2a"
name: "res2a_branch2a"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 1
pad: 0
stride: 1
bias_term: false
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2a"
name: "bn2a_branch2a"
type: "BatchNorm"
batch_norm_param {
}
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2a"
name: "scale2a_branch2a"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2a"
name: "res2a_branch2a_relu"
type: "ReLU"
relu_param {
}
}
layer {
bottom: "res2a_branch2a"
top: "res2a_branch2b"
name: "res2a_branch2b"
type: "Convolution"
convolution_param {
num_output: 64
kernel_size: 3
pad: 1
stride: 1
bias_term: false
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2b"
name: "bn2a_branch2b"
type: "BatchNorm"
batch_norm_param {
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2b"
name: "scale2a_branch2b"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2b"
name: "res2a_branch2b_relu"
type: "ReLU"
relu_param {
}
}
layer {
bottom: "res2a_branch2b"
top: "res2a_branch2c"
name: "res2a_branch2c"
type: "Convolution"
convolution_param {
num_output: 256
kernel_size: 1
pad: 0
stride: 1
bias_term: false
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0.2
}
}
}
layer {
bottom: "res2a_branch2c"
top: "res2a_branch2c"
name: "bn2a_branch2c"
type: "BatchNorm"
batch_norm_param {
}
}
layer {
bottom: "res2a_branch2c"
top: "res2a_branch2c"
name: "scale2a_branch2c"
type: "Scale"
scale_param {
bias_term: true
}
}
layer {
bottom: "res2a_branch1"
bottom: "res2a_branch2c"
top: "res2a"
name: "res2a"
type: "Eltwise"
eltwise_param {
}
}
layer {
bottom: "res2a"
top: "res2a"
name: "res2a_relu"
type: "ReLU"
relu_param {
}
}
Resnet网络的最后若干层。与其它VGG/Alexnet或者Googlenet并无不同。
layer {
bottom: "res5c"
top: "pool5"
name: "pool5"
type: "Pooling"
pooling_param {
kernel_size: 7
stride: 1
pool: AVE
}
}
layer {
bottom: "pool5"
top: "fc1000"
name: "fc1000"
type: "InnerProduct"
inner_product_param {
num_output: 1000
weight_filler {
type: "xavier"
}
bias_filler {
type: "constant"
value: 0
}
}
}
layer {
bottom: "fc1000"
bottom: "label"
top: "prob"
name: "prob"
type: "SoftmaxWithLoss"
include {
phase: TRAIN
}
}
layer {
name: "probt"
type: "Softmax"
bottom: "fc1000"
top: "probt"
include {
phase: TEST
}
}
layer {
name: "accuracy/top-1"
type: "Accuracy"
bottom: "fc1000"
bottom: "label"
top: "accuracy/top-1"
accuracy_param
{
top_k: 1
}
include {
phase: TEST
}
}
layer {
name: "accuracy/top-5"
type: "Accuracy"
bottom: "fc1000"
bottom: "label"
top: "accuracy/top-5"
accuracy_param
{
top_k: 5
}
include {
phase: TEST
}
}
参考文献
- Deep Residual Learning for Image Recognition, He-Kaiming, 2015
- https://github.com/intel/caffe