全国数据分析亚军教你0基础开展一个机器学习项目
我是一名0基础靠机器学习拿1.5万奖金的文科本科生
跟您一样,我的学习刚开始走过很多弯路:
硬啃周志华老师的《机器学习》西瓜书,一周才读了1页 看吴恩达老师的《机器学习入门课》,看完连“线性回归”是什么都不知道
分不清机器学习算法和算法的区别,甚至把《算法导论》当做机器学习入门书
我身边连会python的都少之又少,更没有任何一个人研究机器学习了,但就是在这样的背景下,我没有报班,没有求助他人,完全靠自学夺得了【2020届全国Datathon数据分析大赛社会组亚军】。

这里并不是想宣传什么课程或者是培训班,亦不会做什么书籍推荐,我学会这些的秘诀其实就只有1个字:
练!
是的。
刚开始学习一门新技能,最重要的并不是掌握基础知识,而是培养成就感和兴趣。
接下来我为您准备了一个比较完备且上手简单的机器学习项目,照着项目的代码一段一段进行尝试,
遇到不能理解的代码您可以直接复制,相信您也能够走出自己的机器学习之路,加油!
项目:【线性回归】法国玺镇4年内的家庭用电情况分析
数据源地址:http://archive.ics.uci.edu/ml/datasets/Individual+household+electric+power+consumption

点击上面的【Data Folder】即可下载数据集
1、了解数据和数据集:
这里就不带大家分析了,详见上方提供的网页链接
2、导入相关库、读取数据:
首先先导入常用的pip库(#后的注释内容如果在下没表述清楚,您可不看):
%matplotlib inline
#这行是为了方便jupyter画图,非jupyter环境可以删除这句
import matplotlib.pyplot as plt #这次不在python内画图,因此可以不用导入该库,此行展示仅供参考
import numpy as np
from sklearn.linear_model import LinearRegression
import pandas as pd #个人比较喜欢用modin库,据说会快一些,代码如下:import modin.pandas as pd
import sqldf #如果不太熟悉pandas语法的朋友可以导入这个库,可以用这个pip库来实现通过SQL语法更改dataframe
读取数据要用到这个指令:
df = pd.read_csv('household_power_consumption.txt',sep=';') #该代码不会自动拆分txt,不加分隔符(sep=';')必出问题,如果报错,请在括号内添加Low memory=False
3、特征处理
特征处理可以说是机器学习最重要的一步,这里我们对特征的处理主要还是【数据清洗】:
1、空值处理 2、数据类型转换 3、单位转换 4、特征缩放 5、异常值处理
……
并非所有的数据都要经历以上N个步骤,我们要根据数据的实际情况进行取舍。
首先看看整个数据长啥样,最常用的指令无非就是下面2个:
df.info() #查看数据概况
df.describe() #对数据型特征进行描述统计
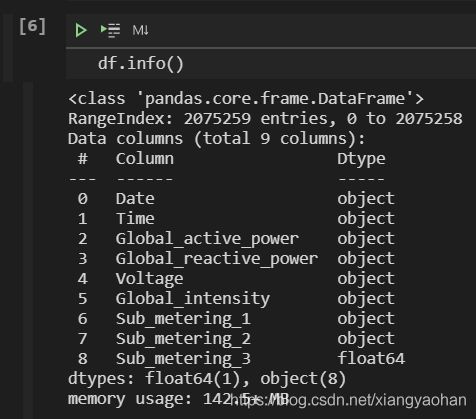
注意,【object】代表“对象”这一数据类型,然而根据我们第一部分对【数据描述】的阅读,除了Date和Time代表时间以外,其他的数据类型都应该是数据型。
另外,我们可以看到,在【df.describe()】运行之后,只有一列结果,也就是说:
除了Sub_metering_3是数据型特征以外,其他的本应该是数据型特征的特征的数据类型不对。
这里就能够确定【数据类型转换】是我们一定要做的数据清洗步骤了,不过在这之前,我们先进行【空值处理】,这里推荐一段缺失值可视化代码:
import missingno as msno
msno.matrix(df)
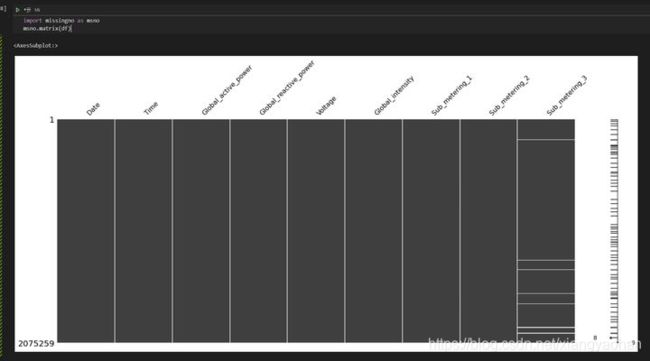
特征Sub_metering_3的空行就是缺失值,这里我们来看看这些缺失值长啥样,根据缺失值的实际情况决定处理方案:
df[df.isnull().values==True] #限制值为缺失值的列全部显示出来
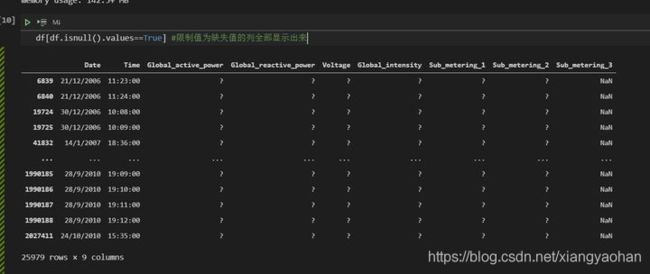
可以看出,特征Sub_metering_3中缺失值所对应的列有很大一部分都是“?”,正是因为非法字符的存在,因此许多特征的数据类型才并非【数据描述】中提到的【数值型】,而全部都是object。
我们这里将异常字符“?”全部替换为缺失值nan然后再统一删除
#将?替换成缺失值
df = df.replace(to_replace='?',value = np.nan)
#丢弃带有缺失值的数据
df = df.dropna()
删除掉缺失值和异常值之后,我们再对所有的特征进行【数值类型转换】:
df=df.apply(pd.to_numeric, errors='ignore') #首先将能转换成数值类型的全部特征转换为数据类型
执行完上述代码后,再执行:
df['Time'] = pd.to_datetime(df['Time'],format="%H:%M:%S")
df['Date'] = pd.to_datetime(df['Date'],format="%d/%m/%Y") #将2个时间特征转换成对应的时间格式
最后我们再来看看现在的数据类型:
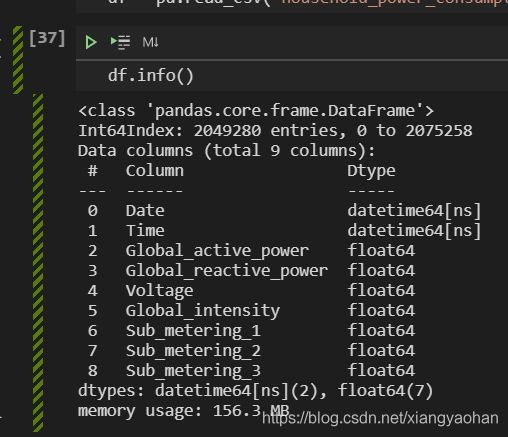
很棒,到现在您已经完成了一半的工作!接下来的部分可能要求一点点机器学习基础,您可以查阅周志华老师的《机器学习》第二章 2.1 经验误差与过拟合 来补足一些基本概念。
4、划分训练集和测试集
接下来让我们给模型要验证的X变量和Y变量赋值:
X = df[['Sub_metering_1','Sub_metering_2','Sub_metering_3']]
Y = df['Global_active_power']
赋值完成后,划分训练集和测试集,方便对模型进行检验:
from sklearn.model_selection import train_test_split
X_train,X_test,Y_train,Y_test = train_test_split(X, Y, test_size=0.3, random_state=10) # 测试集为30%
5、特征值标准化
在原始的资料中,各变数的范围大不相同。对于某些机器学习的算法,若没有做过标准化,目标函数会无法适当的运作。
举例来说,多数的分类器利用两点间的距离计算两点的差异,若其中一个特征具有非常广的范围,那两点间的差异就会被该特征左右,因此,我们这里要对模型进行标准化。
from sklearn.preprocessing import StandardScaler #通过去除均值并缩放到单位方差来标准化特征
scaler = StandardScaler()
X_train = scaler.fit_transform(X_train) # 必须先fit才能使用标准化,因此我们这里对模型训练并转换
X_test = scaler.transform(X_test) # 直接使用在模型构建数据上进行一个数据标准化操作,对剩余的数据(testData)使用同样的均值、方差、最大最小值等指标进行转换,transform(testData),从而保证train、test处理方式相同:
6、模型训练
可能有很多朋友会认为模型构建是最难的,其实不然,前辈们已经为我们准备好了非常多完善的封装函数,只要学会不同函数的应用场景和参数调整,并调用即可,这里用到的是最经典的线性回归:
# 模型训练(线性模型)
lr = LinearRegression()
lr.fit(X_train, Y_train) # 训练模型
y_predict = lr.predict(X_test) # 预测
7、模型检验
接下来就是见证奇迹的时刻了!我们已经构建好了模型,可以在这一步查看模型的整体效果如何,这里面的一些概念需要一些《计量经济学》基础,这方面您可自行补足。
print ("R方:",lr.score(X_test, Y_test)) #可以用不同的模型来输出R方,R方的含义是,预测值解释了y变量的方差的多大比例,该统计参数是预测数据和原始数据对应点误差的平方和的均值
mse = np.average((y_predict-np.array(Y_test))**2) #它是“误差”的平方的期望值,误差就是估计值与被估计量的差
rmse = np.sqrt(mse) #该统计参数,也叫回归系统的拟合标准差,是MSE的平方根
print ("MSE:" ,mse)
print ("RMSE:",rmse)
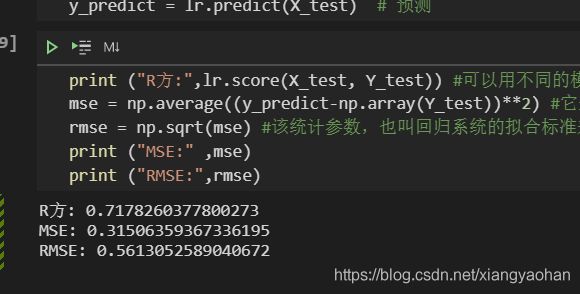
R方有0.717,从统计学意义上来讲还是非常不错的,如果有一些基础的同学,可以通过以下的代码计算调整后的R方:
y = Y_test
yhat = y_predict
SS_Residual = sum((y-yhat)**2)
SS_Total = sum((y-np.mean(y))**2)
r_squared = 1 - (float(SS_Residual))/SS_Total
adjusted_r_squared = 1 - (1-r_squared)*(len(y)-1)/(len(y)-X.shape[1]-1)
print(r_squared, adjusted_r_squared)
好了,以上就是您的第一个机器学习项目了,如果我有没表述清楚的地方,您可以关注我的公众号【向瑶函】,或者添加我的个人微信:a112901528(请备注【机器学习】)详细了解。