【论文笔记】提高超高分辨率图像的语义分割准确性的两种方法:MagNet(CVPR2021)与FCtL(ICCV2021)
目前对于分辨率超过2000*2000的超高分辨率大图,难以直接输入到模型当中。目前最通用的做法就是将大图resize或者crop成小图,实现精度与计算资源的trade-off。resize和crop的做法各自都有着自身固有的缺点,因此在MagNet与FCtl中从crop的缺点出发提出了各自的解决方案,实现超高分辨率大图的语义分割。
一、背景简介
对于分辨率超过2000*2000的超高分辨率大图,直接将其输入到模型中进行训练以及测试会导致显存爆炸,是不现实的。因此,目前有两种常用的方法来应对这种情况:
Resize:即,将大图下采样到分辨率比较小,比如512*512的小图,再送入模型中进行训练。测试的时候,再将模型预测结果上采样到大图分辨率大小。
Crop:即,将大图通过滑动窗口裁剪成很多个小的,比如512*512的patch。再送入模型中进行训练。测试的时候,将模型预测的小图的结果再merge成一张大图。
但是,以上的两种方式都存在各自的缺点。Resize的方式在下采样中会损失掉图像中的很多细节信息,而crop的方式会使得模型能够利用的上下文信息局限在当前的patch之内。二者都是使得语义分割模型的性能出现下降。

因此MagNet与FCtl从crop的缺点出发,提出了各自的解决方案。MagNet与FCtl虽做法不同,但思想上却有共通之处。
二、MagNet,CVPR 2021

题目:Progressive Semantic Segmentation
paper:https://arxiv.org/pdf/2104.03778v1.pdf
code:GitHub - VinAIResearch/MagNet: Progressive Semantic Segmentation (CVPR-2021)
解读:【MagNet】《Progressive Semantic Segmentation》_bryant_meng的博客-CSDN博客
模型总框架: MagNet
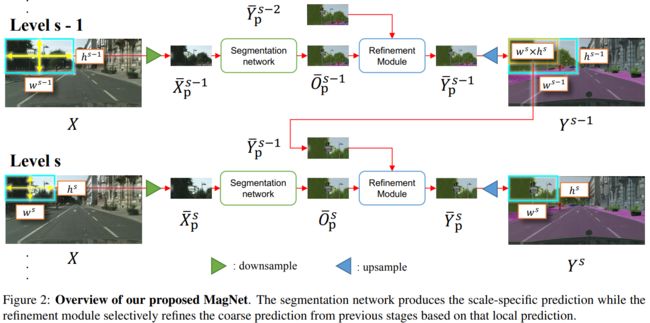
MagNet,一个多尺度的框架,通过在多个放大级别上观察图像来解决局部的模糊性。MagNet有多个处理阶段,其中每个阶段对应于一个放大级别,而一个阶段的输出被送入下一个阶段,进行粗到细的信息传播。每一阶段都以比前一阶段更高的分辨率分析图像,恢复先前由于降采样步骤而丢失的细节,并且分割输出通过各处理阶段逐步完善。

从图上就可以看出MagNet的思想就在于:用上一阶段中size稍大的细节信息稍许损失、上下文信息范围更大的patch中获取的分割结果来,与当前阶段size稍小的细节信息丰富、上下文信息范围更小的patch获取的分割结果来相互优化。
具体来说,整个模型包含主要的两个模块:分割网络与refinement module(以下简称RM)。分割网络可以使用任何能够语义分割框架,比如FPN、PSPNet、FCN等。
refinement module(RM)
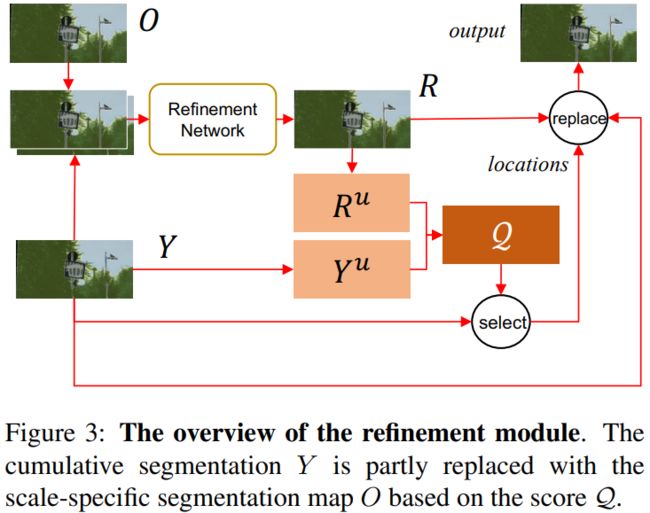
RM:用来在每个处理阶段完善分割图的单个patch。管道的每个处理阶段对分割图的各个块进行细化。该模块的输入是两个大小为h×w×C的分割图:来自以前所有比例的累积分割图Y和来自当前比例的比例特定分割图O。该模块的输出是更新的标度累积分割图。 它包含以下步骤:
- 使用一个小型网络,以Y和O作为输入,我们得到一个初始的组合分割图R。
- 计算预测不确定性图。具体来说,对于Y的每个像素,在这个位置的预测置信度被定义为最高概率值与第二高概率值之间的绝对差值(在C类的C个概率值中)。
- 根据置信度得分计算出不确定性得分,使这两个分数必须加起来为1。
- 同样地,我们可以计算R的预测不确定性图。Yu和Ru表示Y和R的不确定性图。
- 接下来,

- R map 某个 location 分类的越好,softmax 拉的越开,那么 prediction confidence 越大,1-R 越小,就表示不用去 refine 该区域。
- R RR map 某个 location 分类的越差,softmax 拉不开,那么 prediction confidence 越小,1-R 越大,就表示要着重去 refine 该区域。
其中的refinement network如下所示,扮演的角色是利用concat起来的分割结果重新产生一份优化后的分割结果R。
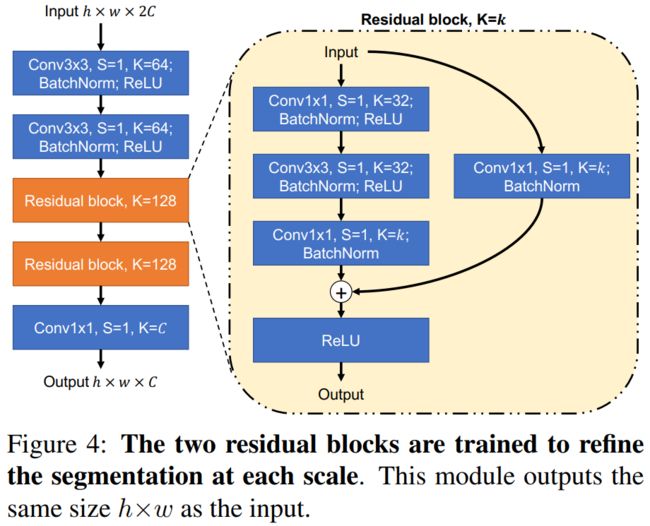
核心代码
R^u与Y^u的产生方法,是计算分割结果上每个像素点的不确定程度。具体做法在于使用当前像素点上模型对每一个类的预测概率中,最大的概率减去第二的概率。显然,值越小,模型的预测越不确定(这种做法与计算熵值类似)。核心代码如下:
def calculate_certainty(seg_probs):
"""Calculate the uncertainty of segmentation probability
"""
top2_scores = torch.topk(seg_probs, k=2, dim=1)[0]
res = (top2_scores[:, 0] - top2_scores[:, 1]).unsqueeze(1)
return res计算完不确定程度,分别产生了R^u与Y^u。然后使用
![]()
确定每个像素点是否分割准确。其中F代表median blurring中值滤波,主要作用在于考虑周围像素的信息。核心代码如下:
uncertainty_score = 1.0 - calculate_certainty(crop_preds)
certainty_score = calculate_certainty(fine_pred)
error_score = certainty_score * uncertainty_score
# error_score就是公式中的 Q然后选取Q中中的top K个像素进行replace操作,以refine分割结果。repalce操作核心代码如下:
error_point_indices, error_point_coords = get_uncertain_point_coords_on_grid(error_score, n_points)
error_point_indices = error_point_indices.unsqueeze(1).expand(-1, opt.num_classes, -1)
alter_pred = point_sample(logits.softmax(1), error_point_coords, align_corners=False)
aggre_pred = (
crop_preds.reshape(b, c, h * w).scatter_(2, error_point_indices, alter_pred).view(b, c, h, w)
)实际上就是将R中的预测不准的像素用Y中的预测值代替。这样,就将细节信息与上下文信息互相利用了起来。
实验结果
DeepGlobe数据集上: 本文方法最优。

refine过程:scale设置4效果最好;refine顺序为:256->512->1024->2048效果最好。

Y^u和R^u的组合方式:2^16 = 65536

不同backbone用本文的方法:本文方法最好。

三、FCtL,ICCV2021

题目:From Contexts to Locality: Ultra-high Resolution Image Segmentation via Locality-aware Contextual Correlation
paper:https://arxiv.org/abs/2109.02580v1
code:https://github.com/liqiokkk/FCtL/
解读:【图像分割】从上下文到局部性:基于局部性感知的上下文相关性超高分辨率图像分割 - 知乎 (zhihu.com)
方法主要流程
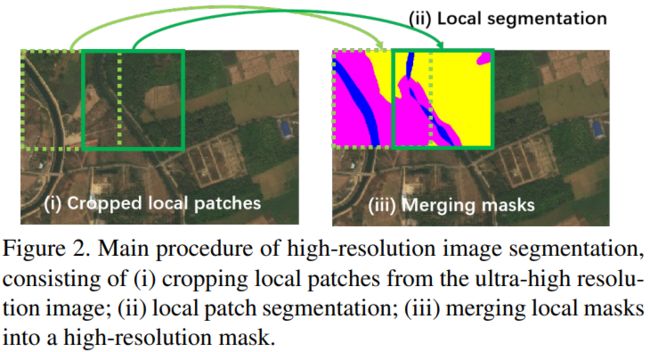
- 给定一个高分辨率图像,均匀地分成多个图像块;
- 预测每一个局部图像块的分割结果;
- 最后把局部分割结果融合为最终的整体图像分割结果。
模型总框架:FCtL
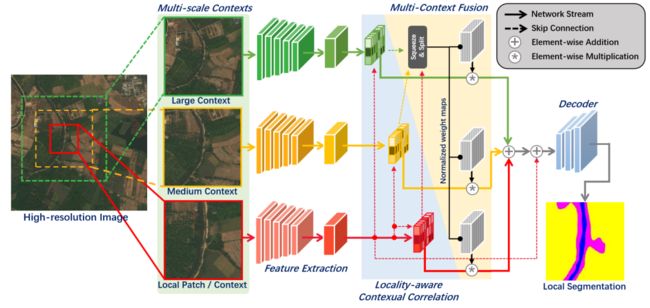
![]()
从上图中可以看出FCtl与MagNet同样的思想,就是用更大size的patch与小size的patch信息互补。模型分为特征提取,Locality-aware Contextual Correlation(LCC),Multi-context Fusion Module(EST),Decoder四个部分。其中最为关键的模块在于LCC与EST两个模块。

每个局部patch只覆盖超高分辨率图像的一个有限区域,往往包含不同尺度的区域或被截断的目标,往往传递的信息不完整,容易造成错误的语义分割。为了解决这个问题,论文提出了一个基于位置感知的上下文关联分割模型来处理每个局部patch。如上图所示,本文的局部分割模型基于multi-stream的编解码器架构,由特征提取模块(即编码器)、位置感知上下文相关模块、多上下文融合模块和解码器组成。具体来说,将带有不同尺度上下文的局部patch输入网络进行特征提取,并将其缩放成相同大小以减少计算开销。然后,通过位置感知上下文相关模块将上下文特征与局部patch特征分别关联,并进行自适应融合。最后对特征进行上采样,得到局部分割掩码。
Context of Local Patch

Locality-aware Contextual Correlation

Multi-context Fusion Module
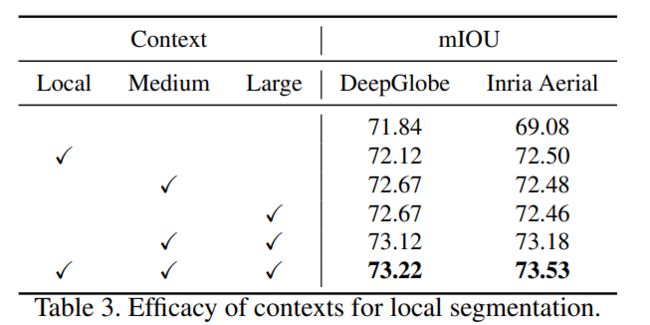
对于超高分辨率的地理空间图像,往往包含大量大小变化较大的目标,不同尺度的上下文可能对不同粒度目标的分割有不同的贡献。因此,适当地结合不同的上下文信息可以互补提取语义分割的精度。

核心代码
做法思想:计算出三个分支在每个像素点上每个值对应的权重然后进行加权求和以实现更大size的patch与小size的patch信息互补。
class _FCtL(nn.Module):
def __init__(self, inplanes, planes, lr_mult, weight_init_scale):
conv_nd = nn.Conv2d
bn_nd = nn.BatchNorm2d
super(_FCtL, self).__init__()
self.conv_value = conv_nd(inplanes, inplanes, kernel_size=1, bias=False)
self.conv_value_1 = conv_nd(inplanes, inplanes, kernel_size=1, bias=False)
self.conv_value_2 = conv_nd(inplanes, inplanes, kernel_size=1, bias=False)
self.conv_out = None
self.conv_query = conv_nd(inplanes, planes, kernel_size=1)
self.conv_key = conv_nd(inplanes, planes, kernel_size=1)
self.conv_query_1 = conv_nd(inplanes, planes, kernel_size=1)
self.conv_key_1 = conv_nd(inplanes, planes, kernel_size=1)
self.conv_query_2 = conv_nd(inplanes, planes, kernel_size=1)
self.conv_key_2 = conv_nd(inplanes, planes, kernel_size=1)
self.in_1 = conv_nd(512, 512, kernel_size=1)
self.in_2 = conv_nd(512, 512, kernel_size=1)
self.in_3 = conv_nd(512, 512, kernel_size=1)
self.trans = conv_nd(512*3, 512*3, kernel_size=1)
self.out_1 = conv_nd(512, 512, kernel_size=1)
self.out_2 = conv_nd(512, 512, kernel_size=1)
self.out_3 = conv_nd(512, 512, kernel_size=1)
self.softmax = nn.Softmax(dim=2)
self.softmax_H = nn.Softmax(dim=0)
self.gamma = nn.Parameter(torch.zeros(1))
self.gamma_1 = nn.Parameter(torch.zeros(1))
self.gamma_2 = nn.Parameter(torch.zeros(1))
self.weight_init_scale = weight_init_scale
self.reset_parameters()
self.reset_lr_mult(lr_mult)
self.reset_weight_and_weight_decay()
def reset_parameters(self):
for m in self.modules():
if isinstance(m, nn.Conv3d) or isinstance(m, nn.Conv2d) or isinstance(m, nn.Conv1d):
init.normal_(m.weight, 0, 0.01)
if m.bias is not None:
init.zeros_(m.bias)
m.inited = True
def reset_lr_mult(self, lr_mult):
if lr_mult is not None:
for m in self.modules():
m.lr_mult = lr_mult
else:
print('not change lr_mult')
def reset_weight_and_weight_decay(self):
init.normal_(self.conv_query.weight, 0, 0.01*self.weight_init_scale)
init.normal_(self.conv_key.weight, 0, 0.01*self.weight_init_scale)
self.conv_query.weight.wd=0.0
self.conv_query.bias.wd=0.0
self.conv_key.weight.wd=0.0
self.conv_key.bias.wd=0.0
def forward(self, x, y=None, z=None):
residual = x
value = self.conv_value(y)
value = value.view(value.size(0), value.size(1), -1)
out_sim = None
if z is not None:
value_1 = self.conv_value_1(z)
value_1 = value_1.view(value_1.size(0), value_1.size(1), -1)
out_sim_1 = None
value_2 = self.conv_value_2(x)
value_2 = value_2.view(value_2.size(0), value_2.size(1), -1)
out_sim_2 = None
query = self.conv_query(x)
key = self.conv_key(y)
query = query.view(query.size(0), query.size(1), -1)
key = key.view(key.size(0), key.size(1), -1)
if z is not None:
query_1 = self.conv_query_1(x)
key_1 = self.conv_key_1(z)
query_1 = query_1.view(query_1.size(0), query_1.size(1), -1)
key_1 = key_1.view(key_1.size(0), key_1.size(1), -1)
query_2 = self.conv_query_2(x)
key_2 = self.conv_key_2(x)
query_2 = query_2.view(query_2.size(0), query_2.size(1), -1)
key_2 = key_2.view(key_2.size(0), key_2.size(1), -1)
sim_map = torch.bmm(query.transpose(1, 2), key)
sim_map = self.softmax(sim_map)
out_sim = torch.bmm(sim_map, value.transpose(1, 2))
out_sim = out_sim.transpose(1, 2)
out_sim = out_sim.view(out_sim.size(0), out_sim.size(1), *x.size()[2:])
out_sim = self.gamma * out_sim
if z is not None:
sim_map_1 = torch.bmm(query_1.transpose(1, 2), key_1)
sim_map_1 = self.softmax(sim_map_1)
out_sim_1 = torch.bmm(sim_map_1, value_1.transpose(1, 2))
out_sim_1 = out_sim_1.transpose(1, 2)
out_sim_1 = out_sim_1.view(out_sim_1.size(0), out_sim_1.size(1), *x.size()[2:])
out_sim_1 = self.gamma_1 * out_sim_1
sim_map_2 = torch.bmm(query_2.transpose(1, 2), key_2)
sim_map_2 = self.softmax(sim_map_2)
out_sim_2 = torch.bmm(sim_map_2, value_2.transpose(1, 2))
out_sim_2 = out_sim_2.transpose(1, 2)
out_sim_2 = out_sim_2.view(out_sim_2.size(0), out_sim_2.size(1), *x.size()[2:])
out_sim_2 = self.gamma_2 * out_sim_2
if z is not None:
H_1 = self.in_1(out_sim)
H_2 = self.in_2(out_sim_1)
H_3 = self.in_3(out_sim_2)
H_cat = torch.cat((H_1, H_2, H_3), 1)
H_tra = self.trans(H_cat)
H_spl = torch.split(H_tra, 512, dim=1)
H_4 = torch.sigmoid(self.out_1(H_spl[0]))
H_5 = torch.sigmoid(self.out_2(H_spl[1]))
H_6 = torch.sigmoid(self.out_3(H_spl[2]))
H_st = torch.stack((H_4, H_5, H_6), 0)
H_all = self.softmax_H(H_st)
if z is not None:
out = residual + H_all[0] * out_sim + H_all[1] * out_sim_1 + H_all[2] * out_sim_2
else:
out = residual + out_sim
return outContextual Semantics Refinement Network
上下文语义细化网络: 利用上下文语义掩码来细化局部分割掩码。 结构如下:

通过之前的操作可以得到一个粗略的分割结果(local mask),通过上图中的网络结果对local mask 进行优化,网络结构采用U-Net 结构的变体。通过输入将一个局部掩码及其上下文掩码输入到一个双分支网络中以细化局部掩码。网络中的localcontext relevance结构用于度量context mask 和local mask 之间的相关性,通过Context mask 来优化local mask(local context relevance结构和 locality-aware correlation 结构类似)。
实验结果
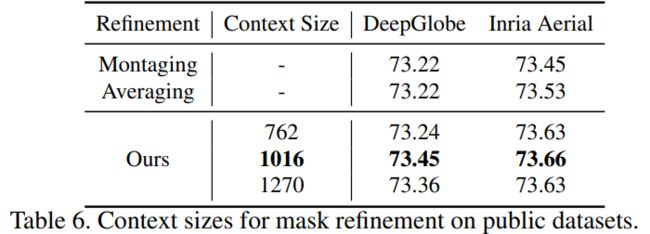
DeepGlobe数据集:效果最好。(注:MagNet为72.96,本方法更高)


参考博客
CVPR2021-MagNet与ICCV2021-FCtl:如何提高超高分辨率图像的语义分割准确性
【图像分割】从上下文到局部性:基于局部性感知的上下文相关性超高分辨率图像分割 - 知乎 (zhihu.com)
【MagNet】《Progressive Semantic Segmentation》_bryant_meng的博客-CSDN博客