kafka解释三的具体:发展Kafka应用
一个、整体外观Kafka
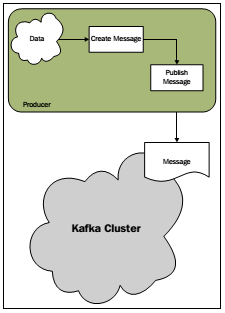
我们知道。Kafka系统有三大组件:Producer、Consumer、broker 。


producers 生产(produce)消息(message)并推(push)送给brokers,consumers从brokers把消息提取(pull)出来消费(consume)。
.png)

二、开发一个Producer应用
Producers用来生产消息并把产生的消息推送到Kafka的Broker。Producers能够是各种应用。比方web应用。server端应用,代理应用以及log系统等等。
当然。Producers如今有各种语言的实现比方Java、C、Python等。
我们先看一下Producer在Kafka中的角色:
2.1.kafka Producer 的 API
Kafka中和producer相关的API有三个类
- Producer:最基本的类。用来创建和推送消息
- KeyedMessage:定义要发送的消息对象,比方定义发送给哪个topic,partition key和发送的内容等。
- ProducerConfig:配置Producer。比方定义要连接的brokers、partition class、serializer class、partition key等
2.2以下我们就写一个最简单的Producer:产生一条消息并推送给broker
package bonree.producer; import java.util.Properties; import kafka.javaapi.producer.Producer; import kafka.producer.KeyedMessage; import kafka.producer.ProducerConfig; /******************************************************************************* * BidPlanStructForm.java Created on 2014-7-8 * Author: <a href=mailto:[email protected]>houda</a> * @Title: SimpleProducer.java * @Package bonree.producer * Description: * Version: 1.0 ******************************************************************************/ public class SimpleProducer { private static Producer<Integer,String> producer; private final Properties props=new Properties(); public SimpleProducer(){ //定义连接的broker list props.put("metadata.broker.list", "192.168.4.31:9092"); //定义序列化类(Java对象传输前要序列化) props.put("serializer.class", "kafka.serializer.StringEncoder"); producer = new Producer<Integer, String>(new ProducerConfig(props)); } public static void main(String[] args) { SimpleProducer sp=new SimpleProducer(); //定义topic String topic="mytopic"; //定义要发送给topic的消息 String messageStr = "send a message to broker "; //构建消息对象 KeyedMessage<Integer, String> data = new KeyedMessage<Integer, String>(topic, messageStr); //推送消息到broker producer.send(data); producer.close(); } }
三、开发一个consumer应用
Consumer是用来消费Producer产生的消息的,当然一个Consumer能够是各种应用。如能够是一个实时的分析系统。也能够是一个数据仓库或者是一个基于公布订阅模式的解决方式等。Consumer端相同有多种语言的实现,如Java、C、Python等。
我们看一下Consumer在Kafka中的角色:
3.1.kafka Producer 的 API
Kafka和Producer略微有些不同。它提供了两种类型的API
- high-level consumer API:提供了对底层API的抽象,使用起来比較简单
- simple consumer API:同意重写底层API的实现,提供了很多其它的控制权,当然使用起来也复杂一些
因为是第一个应用,我们这部分使用high-level API,它的特点每消费一个message自己主动移动offset值到下一个message。关于offset在后面的部分会单独介绍。与Producer类似,和Consumer相关的有三个基本的类:
- KafkaStream:这里面返回的就是Producer生产的消息
- ConsumerConfig:定义要连接zookeeper的一些配置信息(Kafka通过zookeeper均衡压力,详细请查阅见面几篇文章)。比方定义zookeeper的URL、group id、连接zookeeper过期时间等。
- ConsumerConnector:负责和zookeeper进行连接等工作
3.2以下我们就写一个最简单的Consumer:从broker中消费一个消息
package bonree.consumer; import java.util.HashMap; import java.util.List; import java.util.Map; import java.util.Properties; import kafka.consumer.Consumer; import kafka.consumer.ConsumerConfig; import kafka.consumer.ConsumerIterator; import kafka.consumer.KafkaStream; import kafka.javaapi.consumer.ConsumerConnector; /******************************************************************************* * Created on 2014-7-8 Author: <a * href=mailto:[email protected]>houda</a> * @Title: SimpleHLConsumer.java * @Package bonree.consumer Description: Version: 1.0 ******************************************************************************/ public class SimpleHLConsumer { private final ConsumerConnector consumer; private final String topic; public SimpleHLConsumer(String zookeeper, String groupId, String topic) { Properties props = new Properties(); //定义连接zookeeper信息 props.put("zookeeper.connect", zookeeper); //定义Consumer全部的groupID,关于groupID,后面会继续介绍 props.put("group.id", groupId); props.put("zookeeper.session.timeout.ms", "500"); props.put("zookeeper.sync.time.ms", "250"); props.put("auto.commit.interval.ms", "1000"); consumer = Consumer.createJavaConsumerConnector(new ConsumerConfig(props)); this.topic = topic; } public void testConsumer() { Map<String, Integer> topicCount = new HashMap<String, Integer>(); //定义订阅topic数量 topicCount.put(topic, new Integer(1)); //返回的是全部topic的Map Map<String, List<KafkaStream<byte[], byte[]>>> consumerStreams = consumer.createMessageStreams(topicCount); //取出我们要须要的topic中的消息流 List<KafkaStream<byte[], byte[]>> streams = consumerStreams.get(topic); for (final KafkaStream stream : streams) { ConsumerIterator<byte[], byte[]> consumerIte = stream.iterator(); while (consumerIte.hasNext()) System.out.println("Message from Single Topic :: " + new String(consumerIte.next().message())); } if (consumer != null) consumer.shutdown(); } public static void main(String[] args) { String topic = "mytopic"; SimpleHLConsumer simpleHLConsumer = new SimpleHLConsumer("192.168.4.32:2181", "testgroup", topic); simpleHLConsumer.testConsumer(); } }
四、执行查看结果
先启动server端相关进程:
- 执行zookeeper:[root@localhost kafka-0.8]# bin/zookeeper-server-start.sh config/zookeeper.properties
- 执行Kafkabroker:[root@localhost kafka-0.8]# bin/kafka-server-start.sh config/server.properties
再执行我们写的应用
- 执行刚才写的SimpleHLConsumer 类的main函数,等待生产者生产消息
- 执行SimpleProducer的main函数。生产消息并push到broker
结果:执行完SimpleProducer后在SimpleHLConsumer的控制台就可以看到生产者生产的消息:“send a message to broker”。
版权声明:本文博客原创文章。博客,未经同意,不得转载。