petshop4.0 详解之二(数据访问层之数据库访问设计)
在系列一中,我从整体上分析了PetShop的架构设计,并提及了分层的概念。从本部分开始,我将依次对各层进行代码级的分析,以求获得更加细致而深入的理解。在PetShop 4.0中,由于引入了ASP.Net 2.0的一些新特色,所以数据层的内容也更加的广泛和复杂,包括:
数据库访问、Messaging、MemberShip、Profile四部分。在系列二中,我将介绍有关数据库访问的设计。 在PetShop中,系统需要处理的数据库对象分为两类:
一是数据实体,对应数据库中相应的数据表。它们没有行为,仅用于表现对象的数据。这些实体类都被放到
Model程序集中,例如数据表Order对应的实体类OrderInfo,其类图如下:
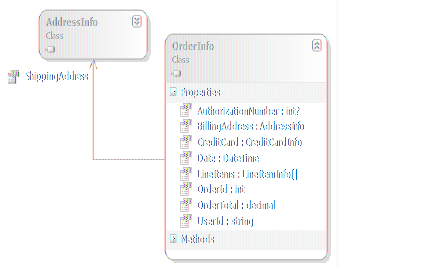 这些对象并不具有持久化的功能,简单地说,它们是作为数据的载体,便于业务逻辑针对相应数据表进行读/写操作。
虽然这些类的属性分别映射了数据表的列,而每一个对象实例也恰恰对应于数据表的每一行,但这些实体类却并不具备对应的数据库访问能力。 由于数据访问层和业务逻辑层都将对这些数据实体进行操作,因此程序集Model会被这两层的模块所引用。 第二类数据库对象则
是数据的业务逻辑对象。这里所指的业务逻辑,并非业务逻辑层意义上的领域(domain)业务逻辑(从这个意义上,我更倾向于将业务逻辑层称为“领域逻辑层”),一般意义上说,这些
业务逻辑即为基本的数据库操作,包括Select,Insert,Update和Delete。由于这些业务逻辑对象,仅具有行为而与数据无关,因此它们均被抽象为一个单独的接口模块IDAL,例如数据表Order对应的接口IOrder:
这些对象并不具有持久化的功能,简单地说,它们是作为数据的载体,便于业务逻辑针对相应数据表进行读/写操作。
虽然这些类的属性分别映射了数据表的列,而每一个对象实例也恰恰对应于数据表的每一行,但这些实体类却并不具备对应的数据库访问能力。 由于数据访问层和业务逻辑层都将对这些数据实体进行操作,因此程序集Model会被这两层的模块所引用。 第二类数据库对象则
是数据的业务逻辑对象。这里所指的业务逻辑,并非业务逻辑层意义上的领域(domain)业务逻辑(从这个意义上,我更倾向于将业务逻辑层称为“领域逻辑层”),一般意义上说,这些
业务逻辑即为基本的数据库操作,包括Select,Insert,Update和Delete。由于这些业务逻辑对象,仅具有行为而与数据无关,因此它们均被抽象为一个单独的接口模块IDAL,例如数据表Order对应的接口IOrder:
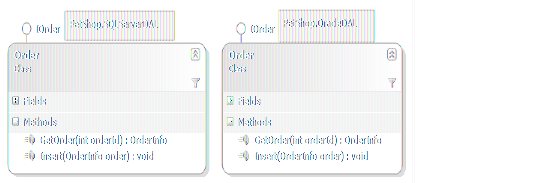
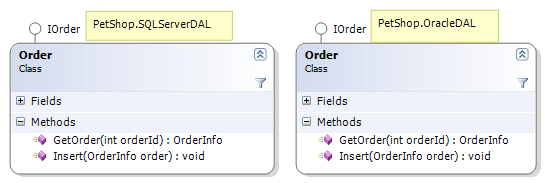
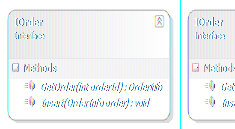 将数据实体与相关的数据库操作分离出来,符合面向对象的精神。首先,它体现了“职责分离”的原则。将数据实体与其行为分开,使得两者之间依赖减弱,当数据行为发生改变时,并不影响Model模块中的数据实体对象,避免了因一个类职责过多、过大,从而导致该类的引用者发生“灾难性”的影响。其次,它体现了“抽象”的精神,或者说是“面向接口编程”的最佳体现。抽象的接口模块IDAL,与具体的数据库访问实现完全隔离。这种与实现无关的设计,保证了系统的可扩展性,同时也保证了数据库的可移植性。在PetShop中,可以支持SQL Server和Oracle,那么它们具体的实现就分别放在两个不同的模块SQLServerDAL、OracleDAL中。 以Order为例,在SQLServerDAL、OracleDAL两个模块中,有不同的实现,但它们同时又都实现了IOrder接口,如图:
将数据实体与相关的数据库操作分离出来,符合面向对象的精神。首先,它体现了“职责分离”的原则。将数据实体与其行为分开,使得两者之间依赖减弱,当数据行为发生改变时,并不影响Model模块中的数据实体对象,避免了因一个类职责过多、过大,从而导致该类的引用者发生“灾难性”的影响。其次,它体现了“抽象”的精神,或者说是“面向接口编程”的最佳体现。抽象的接口模块IDAL,与具体的数据库访问实现完全隔离。这种与实现无关的设计,保证了系统的可扩展性,同时也保证了数据库的可移植性。在PetShop中,可以支持SQL Server和Oracle,那么它们具体的实现就分别放在两个不同的模块SQLServerDAL、OracleDAL中。 以Order为例,在SQLServerDAL、OracleDAL两个模块中,有不同的实现,但它们同时又都实现了IOrder接口,如图:
 从数据库的实现来看,PetShop体现出了没有ORM框架的臃肿与丑陋。由于要对数据表进行Insert和Select操作,以SQL Server为例,就使用了SqlCommand,SqlParameter,SqlDataReader等对象,以完成这些操作。尤其复杂的是Parameter的传递,在PetShop中,使用了大量的字符串常量来保存参数的名称。此外,PetShop还专门为SQL Server和Oracle提供了抽象的Helper类,包装了一些常用的操作,如ExecuteNonQuery、ExecuteReader等方法。 在
没有ORM的情况下,使用Helper类是一个比较好的策略,利用它来完成数据库基本操作的封装,可以减少很多和数据库操作有关的代码,这体现了对象复用的原则。PetShop将这些Helper类统一放到
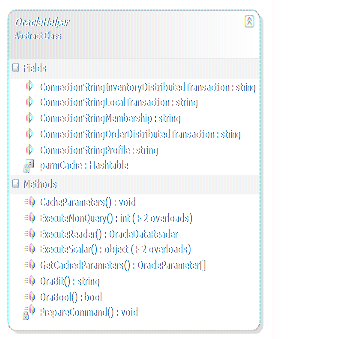
DBUtility模块中,不同数据库的Helper类暴露的方法基本相同,只除了一些特殊的要求,例如Oracle中处理bool类型的方式就和SQL Server不同,从而专门提供了OraBit和OraBool方法。此外,Helper类中的方法均为static方法,以利于调用。OracleHelper的类图如下:
从数据库的实现来看,PetShop体现出了没有ORM框架的臃肿与丑陋。由于要对数据表进行Insert和Select操作,以SQL Server为例,就使用了SqlCommand,SqlParameter,SqlDataReader等对象,以完成这些操作。尤其复杂的是Parameter的传递,在PetShop中,使用了大量的字符串常量来保存参数的名称。此外,PetShop还专门为SQL Server和Oracle提供了抽象的Helper类,包装了一些常用的操作,如ExecuteNonQuery、ExecuteReader等方法。 在
没有ORM的情况下,使用Helper类是一个比较好的策略,利用它来完成数据库基本操作的封装,可以减少很多和数据库操作有关的代码,这体现了对象复用的原则。PetShop将这些Helper类统一放到
DBUtility模块中,不同数据库的Helper类暴露的方法基本相同,只除了一些特殊的要求,例如Oracle中处理bool类型的方式就和SQL Server不同,从而专门提供了OraBit和OraBool方法。此外,Helper类中的方法均为static方法,以利于调用。OracleHelper的类图如下:
 对于数据访问层来说,最头疼的是SQL语句的处理。在早期的CS结构中,由于未采用三层式架构设计,数据访问层和业务逻辑层是紧密糅合在一起的,因此,SQL语句遍布与系统的每一个角落。这给程序的维护带来极大的困难。此外,由于
Oracle使用的是PL-SQL,而SQL Server和Sybase等使用的是T-SQL,两者虽然都遵循了标准SQL的语法,但在很多细节上仍有区别,如果将SQL语句大量的使用到程序中,无疑为可能的数据库移植也带来了困难。
最好的方法是采用存储过程。这种方法使得程序更加整洁,此外,由于存储过程可以以数据库脚本的形式存在,也便于移植和修改。但这种方式
仍然有缺陷。一是存储过程的测试相对困难。虽然有相应的调试工具,但比起对代码的调试而言,仍然比较复杂且不方便。
二是对系统的更新带来障碍。如果数据库访问是由程序完成,在.Net平台下,我们仅需要在修改程序后,将重新编译的程序集xcopy到部署的服务器上即可。如果使用了存储过程,出于安全的考虑,必须有专门的DBA重新运行存储过程的脚本,部署的方式受到了限制。 我曾经在一个项目中,利
用一个专门的表来存放SQL语句。
如要使用相关的SQL语句,就利用关键字搜索获得对应语句。这种做法
近似于存储过程的调用,但却避免了部署上的问题。然而这种方式却在性能上无法得到保证。它仅适合于SQL语句较少的场景。不过,利用良好的设计,我们可以为各种业务提供不同的表来存放SQL语句。同样的道理,这些SQL语句也可以存放到XML文件中,更有利于系统的扩展或修改。不过前提是,我们需要为它提供专门的SQL语句管理工具。 SQL语句的使用无法避免,如何更好的应用SQL语句也无定论,但有一个
原则值得我们遵守,就是“
应该尽量让SQL语句尽存在于数据访问层的具体实现中”。 当然,如果应用ORM,那么一切就变得不同了。因为ORM框架已经为数据访问提供了基本的Select,Insert,Update和Delete操作了。例如在NHibernate中,我们可以直接调用ISession对象的Save方法,来Insert(或者说是Create)一个数据实体对象: public void Insert(OrderInfo order) { ISession s = Sessions.GetSession(); ITransaction trans = null; try { trans = s.BeginTransaction(); s.Save( order); trans.Commit(); } finally { s.Close(); } } 没有SQL语句,也没有那些烦人的Parameters,甚至不需要专门去考虑事务。此外,这样的设计,也是与数据库无关的,NHibernate可以通过Dialect(方言)的机制支持不同的数据库。唯一要做的是,我们需要为OrderInfo定义hbm文件。 当然,ORM框架并非是万能的,面对纷繁复杂的业务逻辑,它并不能完全消灭SQL语句,以及替代复杂的数据库访问逻辑,但它却很好的体现了“80/20(或90/10)法则”(也被称为“帕累托法则”),也就是说:花比较少(10%-20%)的力气就可以解决大部分(80%-90%)的问题,而要解决剩下的少部分问题则需要多得多的努力。至少,那些在数据访问层中占据了绝大部分的CRUD操作,通过利用ORM框架,我们就仅需要付出极少数时间和精力来解决它们了。这无疑缩短了整个项目开发的周期。 还是回到对PetShop的讨论上来。现在我们已经有
了数据实体,数据对象的抽象接口和实现,可以说有关数据库访问的主体就已经完成了。留待我们的还有两个问题需要解决:
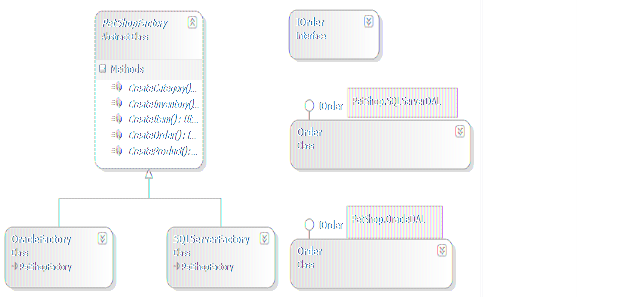
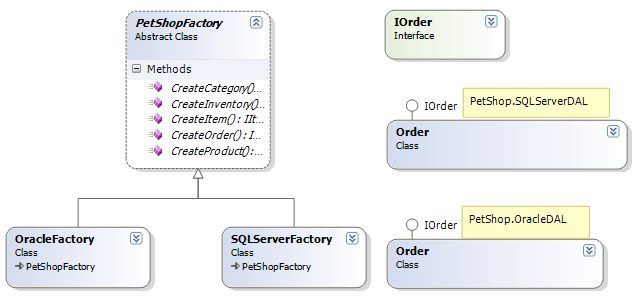
1、数据对象创建的管理 2、利于数据库的移植 在PetShop中,要创建的数据对象包括Order,Product,Category,Inventory,Item。在前面的设计中,这些对象已经被抽象为对应的接口,而其实现则根据数据库的不同而有所不同。也就是说,创建的对象有多种类别,而每种类别又有不同的实现,这是典型的抽象工厂模式的应用场景。而上面所述的两个问题,也都可以通过抽象工厂模式来解决。标准的抽象工厂模式类图如下:
对于数据访问层来说,最头疼的是SQL语句的处理。在早期的CS结构中,由于未采用三层式架构设计,数据访问层和业务逻辑层是紧密糅合在一起的,因此,SQL语句遍布与系统的每一个角落。这给程序的维护带来极大的困难。此外,由于
Oracle使用的是PL-SQL,而SQL Server和Sybase等使用的是T-SQL,两者虽然都遵循了标准SQL的语法,但在很多细节上仍有区别,如果将SQL语句大量的使用到程序中,无疑为可能的数据库移植也带来了困难。
最好的方法是采用存储过程。这种方法使得程序更加整洁,此外,由于存储过程可以以数据库脚本的形式存在,也便于移植和修改。但这种方式
仍然有缺陷。一是存储过程的测试相对困难。虽然有相应的调试工具,但比起对代码的调试而言,仍然比较复杂且不方便。
二是对系统的更新带来障碍。如果数据库访问是由程序完成,在.Net平台下,我们仅需要在修改程序后,将重新编译的程序集xcopy到部署的服务器上即可。如果使用了存储过程,出于安全的考虑,必须有专门的DBA重新运行存储过程的脚本,部署的方式受到了限制。 我曾经在一个项目中,利
用一个专门的表来存放SQL语句。
如要使用相关的SQL语句,就利用关键字搜索获得对应语句。这种做法
近似于存储过程的调用,但却避免了部署上的问题。然而这种方式却在性能上无法得到保证。它仅适合于SQL语句较少的场景。不过,利用良好的设计,我们可以为各种业务提供不同的表来存放SQL语句。同样的道理,这些SQL语句也可以存放到XML文件中,更有利于系统的扩展或修改。不过前提是,我们需要为它提供专门的SQL语句管理工具。 SQL语句的使用无法避免,如何更好的应用SQL语句也无定论,但有一个
原则值得我们遵守,就是“
应该尽量让SQL语句尽存在于数据访问层的具体实现中”。 当然,如果应用ORM,那么一切就变得不同了。因为ORM框架已经为数据访问提供了基本的Select,Insert,Update和Delete操作了。例如在NHibernate中,我们可以直接调用ISession对象的Save方法,来Insert(或者说是Create)一个数据实体对象: public void Insert(OrderInfo order) { ISession s = Sessions.GetSession(); ITransaction trans = null; try { trans = s.BeginTransaction(); s.Save( order); trans.Commit(); } finally { s.Close(); } } 没有SQL语句,也没有那些烦人的Parameters,甚至不需要专门去考虑事务。此外,这样的设计,也是与数据库无关的,NHibernate可以通过Dialect(方言)的机制支持不同的数据库。唯一要做的是,我们需要为OrderInfo定义hbm文件。 当然,ORM框架并非是万能的,面对纷繁复杂的业务逻辑,它并不能完全消灭SQL语句,以及替代复杂的数据库访问逻辑,但它却很好的体现了“80/20(或90/10)法则”(也被称为“帕累托法则”),也就是说:花比较少(10%-20%)的力气就可以解决大部分(80%-90%)的问题,而要解决剩下的少部分问题则需要多得多的努力。至少,那些在数据访问层中占据了绝大部分的CRUD操作,通过利用ORM框架,我们就仅需要付出极少数时间和精力来解决它们了。这无疑缩短了整个项目开发的周期。 还是回到对PetShop的讨论上来。现在我们已经有
了数据实体,数据对象的抽象接口和实现,可以说有关数据库访问的主体就已经完成了。留待我们的还有两个问题需要解决:
1、数据对象创建的管理 2、利于数据库的移植 在PetShop中,要创建的数据对象包括Order,Product,Category,Inventory,Item。在前面的设计中,这些对象已经被抽象为对应的接口,而其实现则根据数据库的不同而有所不同。也就是说,创建的对象有多种类别,而每种类别又有不同的实现,这是典型的抽象工厂模式的应用场景。而上面所述的两个问题,也都可以通过抽象工厂模式来解决。标准的抽象工厂模式类图如下:
 例如,创建SQL Server的Order对象如下: PetShopFactory factory = new SQLServerFactory(); IOrder = factory.CreateOrder(); 要考虑到数据库的可移植性,则factory必须作为一个全局变量,并在主程序运行时被实例化。但这样的设计虽然已经达到了“封装变化”的目的,但在创建PetShopFactory对象时,仍不可避免的出现了具体的类SQLServerFactory,也即是说,程序在这个层面上产生了与SQLServerFactory的强依赖。一旦整个系统要求支持Oracle,那么还需要修改这行代码为: PetShopFactory factory = new oracleFactory(); 修改代码的这种行为显然是不可接受的。解决的办法是“依赖注入”。“依赖注入”的功能通常是用专门的IoC容器提供的,在Java平台下,这样的容器包括Spring,PicoContainer等。而在.Net平台下,最常见的则是Spring.Net。不过,在PetShop系统中,并不需要专门的容器来实现“依赖注入”,简单的做法还是利用配置文件和反射功能来实现。也就是说,我们可以在web.config文件中,配置好具体的Factory对象的完整的类名。然而,当我们利用配置文件和反射功能时,具体工厂的创建就显得有些“画蛇添足”了,我们完全可以在配置文件中,直接指向具体的数据库对象实现类,例如PetShop.SQLServerDAL.IOrder。那么,抽象工厂模式中的相关工厂就可以简化为一个工厂类了,所以我将这种模式称之为“具有简单工厂特质的抽象工厂模式”,其类图如下:
例如,创建SQL Server的Order对象如下: PetShopFactory factory = new SQLServerFactory(); IOrder = factory.CreateOrder(); 要考虑到数据库的可移植性,则factory必须作为一个全局变量,并在主程序运行时被实例化。但这样的设计虽然已经达到了“封装变化”的目的,但在创建PetShopFactory对象时,仍不可避免的出现了具体的类SQLServerFactory,也即是说,程序在这个层面上产生了与SQLServerFactory的强依赖。一旦整个系统要求支持Oracle,那么还需要修改这行代码为: PetShopFactory factory = new oracleFactory(); 修改代码的这种行为显然是不可接受的。解决的办法是“依赖注入”。“依赖注入”的功能通常是用专门的IoC容器提供的,在Java平台下,这样的容器包括Spring,PicoContainer等。而在.Net平台下,最常见的则是Spring.Net。不过,在PetShop系统中,并不需要专门的容器来实现“依赖注入”,简单的做法还是利用配置文件和反射功能来实现。也就是说,我们可以在web.config文件中,配置好具体的Factory对象的完整的类名。然而,当我们利用配置文件和反射功能时,具体工厂的创建就显得有些“画蛇添足”了,我们完全可以在配置文件中,直接指向具体的数据库对象实现类,例如PetShop.SQLServerDAL.IOrder。那么,抽象工厂模式中的相关工厂就可以简化为一个工厂类了,所以我将这种模式称之为“具有简单工厂特质的抽象工厂模式”,其类图如下:
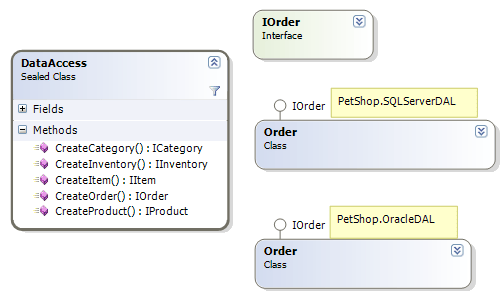
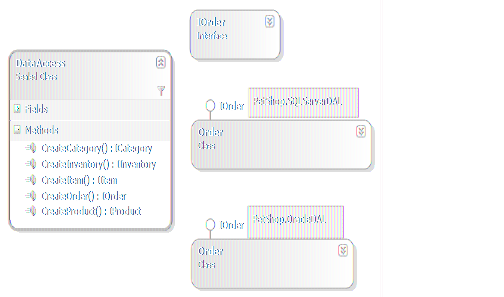 DataAccess类完全取代了前面创建的工厂类体系,它是一个sealed类,其中创建各种数据对象的方法,均为静态方法。之所以能用这个类达到抽象工厂的目的,是因为配置文件和反射的运用,如下的代码片断所示: public sealed class DataAccess { // Look up the DAL implementation we should be using private static readonly string path = ConfigurationManager.AppSettings[”WebDAL”]; private static readonly string orderPath = ConfigurationManager.AppSettings[”OrdersDAL”]; public static PetShop.IDAL.IOrder CreateOrder() { string className = orderPath + “.Order”; return (PetShop.IDAL.IOrder)Assembly.Load(orderPath).CreateInstance(className); } } 在PetShop中,
这种依赖配置文件和反射创建对象的方式极其常见,包括IBLLStategy、CacheDependencyFactory等等。这些实现逻辑散布于整个PetShop系统中,在我看来,是可以在此基础上进行重构的。也就是说,我们可以为整个系统提供类似于“Service Locator”的实现: public static class ServiceLocator { private static readonly string dalPath = ConfigurationManager.AppSettings[”WebDAL”]; private static readonly string orderPath = ConfigurationManager.AppSettings[”OrdersDAL”]; //…… private static readonly string orderStategyPath = ConfigurationManager.AppSettings[”OrderStrategyAssembly”]; public static object LocateDALObject(string className) { string fullPath = dalPath + “.” + className; return Assembly.Load(dalPath).CreateInstance(fullPath); } public static object LocateDALOrderObject(string className) { string fullPath = orderPath + “.” + className; return Assembly.Load(orderPath).CreateInstance(fullPath); } public static object LocateOrderStrategyObject(string className) { string fullPath = orderStategyPath + “.” + className; return Assembly.Load(orderStategyPath).CreateInstance(fullPath); } //…… } 那么和所谓“依赖注入”相关的代码都可以利用ServiceLocator来完成。例如类DataAccess就可以简化为: public sealed class DataAccess { public static PetShop.IDAL.IOrder CreateOrder() { return (PetShop.IDAL.IOrder)ServiceLocator. LocateDALOrderObject(”Order”); } } 通过ServiceLocator,将所有与配置文件相关的namespace值统一管理起来,这有利于各种动态创建对象的管理和未来的维护。
DataAccess类完全取代了前面创建的工厂类体系,它是一个sealed类,其中创建各种数据对象的方法,均为静态方法。之所以能用这个类达到抽象工厂的目的,是因为配置文件和反射的运用,如下的代码片断所示: public sealed class DataAccess { // Look up the DAL implementation we should be using private static readonly string path = ConfigurationManager.AppSettings[”WebDAL”]; private static readonly string orderPath = ConfigurationManager.AppSettings[”OrdersDAL”]; public static PetShop.IDAL.IOrder CreateOrder() { string className = orderPath + “.Order”; return (PetShop.IDAL.IOrder)Assembly.Load(orderPath).CreateInstance(className); } } 在PetShop中,
这种依赖配置文件和反射创建对象的方式极其常见,包括IBLLStategy、CacheDependencyFactory等等。这些实现逻辑散布于整个PetShop系统中,在我看来,是可以在此基础上进行重构的。也就是说,我们可以为整个系统提供类似于“Service Locator”的实现: public static class ServiceLocator { private static readonly string dalPath = ConfigurationManager.AppSettings[”WebDAL”]; private static readonly string orderPath = ConfigurationManager.AppSettings[”OrdersDAL”]; //…… private static readonly string orderStategyPath = ConfigurationManager.AppSettings[”OrderStrategyAssembly”]; public static object LocateDALObject(string className) { string fullPath = dalPath + “.” + className; return Assembly.Load(dalPath).CreateInstance(fullPath); } public static object LocateDALOrderObject(string className) { string fullPath = orderPath + “.” + className; return Assembly.Load(orderPath).CreateInstance(fullPath); } public static object LocateOrderStrategyObject(string className) { string fullPath = orderStategyPath + “.” + className; return Assembly.Load(orderStategyPath).CreateInstance(fullPath); } //…… } 那么和所谓“依赖注入”相关的代码都可以利用ServiceLocator来完成。例如类DataAccess就可以简化为: public sealed class DataAccess { public static PetShop.IDAL.IOrder CreateOrder() { return (PetShop.IDAL.IOrder)ServiceLocator. LocateDALOrderObject(”Order”); } } 通过ServiceLocator,将所有与配置文件相关的namespace值统一管理起来,这有利于各种动态创建对象的管理和未来的维护。
这些对象并不具有持久化的功能,简单地说,它们是作为数据的载体,便于业务逻辑针对相应数据表进行读/写操作。
虽然这些类的属性分别映射了数据表的列,而每一个对象实例也恰恰对应于数据表的每一行,但这些实体类却并不具备对应的数据库访问能力。 由于数据访问层和业务逻辑层都将对这些数据实体进行操作,因此程序集Model会被这两层的模块所引用。 第二类数据库对象则
是数据的业务逻辑对象。这里所指的业务逻辑,并非业务逻辑层意义上的领域(domain)业务逻辑(从这个意义上,我更倾向于将业务逻辑层称为“领域逻辑层”),一般意义上说,这些
业务逻辑即为基本的数据库操作,包括Select,Insert,Update和Delete。由于这些业务逻辑对象,仅具有行为而与数据无关,因此它们均被抽象为一个单独的接口模块IDAL,例如数据表Order对应的接口IOrder:
将数据实体与相关的数据库操作分离出来,符合面向对象的精神。首先,它体现了“职责分离”的原则。将数据实体与其行为分开,使得两者之间依赖减弱,当数据行为发生改变时,并不影响Model模块中的数据实体对象,避免了因一个类职责过多、过大,从而导致该类的引用者发生“灾难性”的影响。其次,它体现了“抽象”的精神,或者说是“面向接口编程”的最佳体现。抽象的接口模块IDAL,与具体的数据库访问实现完全隔离。这种与实现无关的设计,保证了系统的可扩展性,同时也保证了数据库的可移植性。在PetShop中,可以支持SQL Server和Oracle,那么它们具体的实现就分别放在两个不同的模块SQLServerDAL、OracleDAL中。 以Order为例,在SQLServerDAL、OracleDAL两个模块中,有不同的实现,但它们同时又都实现了IOrder接口,如图:
 从数据库的实现来看,PetShop体现出了没有ORM框架的臃肿与丑陋。由于要对数据表进行Insert和Select操作,以SQL Server为例,就使用了SqlCommand,SqlParameter,SqlDataReader等对象,以完成这些操作。尤其复杂的是Parameter的传递,在PetShop中,使用了大量的字符串常量来保存参数的名称。此外,PetShop还专门为SQL Server和Oracle提供了抽象的Helper类,包装了一些常用的操作,如ExecuteNonQuery、ExecuteReader等方法。 在
没有ORM的情况下,使用Helper类是一个比较好的策略,利用它来完成数据库基本操作的封装,可以减少很多和数据库操作有关的代码,这体现了对象复用的原则。PetShop将这些Helper类统一放到
DBUtility模块中,不同数据库的Helper类暴露的方法基本相同,只除了一些特殊的要求,例如Oracle中处理bool类型的方式就和SQL Server不同,从而专门提供了OraBit和OraBool方法。此外,Helper类中的方法均为static方法,以利于调用。OracleHelper的类图如下:
对于数据访问层来说,最头疼的是SQL语句的处理。在早期的CS结构中,由于未采用三层式架构设计,数据访问层和业务逻辑层是紧密糅合在一起的,因此,SQL语句遍布与系统的每一个角落。这给程序的维护带来极大的困难。此外,由于
Oracle使用的是PL-SQL,而SQL Server和Sybase等使用的是T-SQL,两者虽然都遵循了标准SQL的语法,但在很多细节上仍有区别,如果将SQL语句大量的使用到程序中,无疑为可能的数据库移植也带来了困难。
最好的方法是采用存储过程。这种方法使得程序更加整洁,此外,由于存储过程可以以数据库脚本的形式存在,也便于移植和修改。但这种方式
仍然有缺陷。一是存储过程的测试相对困难。虽然有相应的调试工具,但比起对代码的调试而言,仍然比较复杂且不方便。
二是对系统的更新带来障碍。如果数据库访问是由程序完成,在.Net平台下,我们仅需要在修改程序后,将重新编译的程序集xcopy到部署的服务器上即可。如果使用了存储过程,出于安全的考虑,必须有专门的DBA重新运行存储过程的脚本,部署的方式受到了限制。 我曾经在一个项目中,利
用一个专门的表来存放SQL语句。
如要使用相关的SQL语句,就利用关键字搜索获得对应语句。这种做法
近似于存储过程的调用,但却避免了部署上的问题。然而这种方式却在性能上无法得到保证。它仅适合于SQL语句较少的场景。不过,利用良好的设计,我们可以为各种业务提供不同的表来存放SQL语句。同样的道理,这些SQL语句也可以存放到XML文件中,更有利于系统的扩展或修改。不过前提是,我们需要为它提供专门的SQL语句管理工具。 SQL语句的使用无法避免,如何更好的应用SQL语句也无定论,但有一个
原则值得我们遵守,就是“
应该尽量让SQL语句尽存在于数据访问层的具体实现中”。 当然,如果应用ORM,那么一切就变得不同了。因为ORM框架已经为数据访问提供了基本的Select,Insert,Update和Delete操作了。例如在NHibernate中,我们可以直接调用ISession对象的Save方法,来Insert(或者说是Create)一个数据实体对象: public void Insert(OrderInfo order) { ISession s = Sessions.GetSession(); ITransaction trans = null; try { trans = s.BeginTransaction(); s.Save( order); trans.Commit(); } finally { s.Close(); } } 没有SQL语句,也没有那些烦人的Parameters,甚至不需要专门去考虑事务。此外,这样的设计,也是与数据库无关的,NHibernate可以通过Dialect(方言)的机制支持不同的数据库。唯一要做的是,我们需要为OrderInfo定义hbm文件。 当然,ORM框架并非是万能的,面对纷繁复杂的业务逻辑,它并不能完全消灭SQL语句,以及替代复杂的数据库访问逻辑,但它却很好的体现了“80/20(或90/10)法则”(也被称为“帕累托法则”),也就是说:花比较少(10%-20%)的力气就可以解决大部分(80%-90%)的问题,而要解决剩下的少部分问题则需要多得多的努力。至少,那些在数据访问层中占据了绝大部分的CRUD操作,通过利用ORM框架,我们就仅需要付出极少数时间和精力来解决它们了。这无疑缩短了整个项目开发的周期。 还是回到对PetShop的讨论上来。现在我们已经有
了数据实体,数据对象的抽象接口和实现,可以说有关数据库访问的主体就已经完成了。留待我们的还有两个问题需要解决:
1、数据对象创建的管理 2、利于数据库的移植 在PetShop中,要创建的数据对象包括Order,Product,Category,Inventory,Item。在前面的设计中,这些对象已经被抽象为对应的接口,而其实现则根据数据库的不同而有所不同。也就是说,创建的对象有多种类别,而每种类别又有不同的实现,这是典型的抽象工厂模式的应用场景。而上面所述的两个问题,也都可以通过抽象工厂模式来解决。标准的抽象工厂模式类图如下:
从数据库的实现来看,PetShop体现出了没有ORM框架的臃肿与丑陋。由于要对数据表进行Insert和Select操作,以SQL Server为例,就使用了SqlCommand,SqlParameter,SqlDataReader等对象,以完成这些操作。尤其复杂的是Parameter的传递,在PetShop中,使用了大量的字符串常量来保存参数的名称。此外,PetShop还专门为SQL Server和Oracle提供了抽象的Helper类,包装了一些常用的操作,如ExecuteNonQuery、ExecuteReader等方法。 在
没有ORM的情况下,使用Helper类是一个比较好的策略,利用它来完成数据库基本操作的封装,可以减少很多和数据库操作有关的代码,这体现了对象复用的原则。PetShop将这些Helper类统一放到
DBUtility模块中,不同数据库的Helper类暴露的方法基本相同,只除了一些特殊的要求,例如Oracle中处理bool类型的方式就和SQL Server不同,从而专门提供了OraBit和OraBool方法。此外,Helper类中的方法均为static方法,以利于调用。OracleHelper的类图如下:
对于数据访问层来说,最头疼的是SQL语句的处理。在早期的CS结构中,由于未采用三层式架构设计,数据访问层和业务逻辑层是紧密糅合在一起的,因此,SQL语句遍布与系统的每一个角落。这给程序的维护带来极大的困难。此外,由于
Oracle使用的是PL-SQL,而SQL Server和Sybase等使用的是T-SQL,两者虽然都遵循了标准SQL的语法,但在很多细节上仍有区别,如果将SQL语句大量的使用到程序中,无疑为可能的数据库移植也带来了困难。
最好的方法是采用存储过程。这种方法使得程序更加整洁,此外,由于存储过程可以以数据库脚本的形式存在,也便于移植和修改。但这种方式
仍然有缺陷。一是存储过程的测试相对困难。虽然有相应的调试工具,但比起对代码的调试而言,仍然比较复杂且不方便。
二是对系统的更新带来障碍。如果数据库访问是由程序完成,在.Net平台下,我们仅需要在修改程序后,将重新编译的程序集xcopy到部署的服务器上即可。如果使用了存储过程,出于安全的考虑,必须有专门的DBA重新运行存储过程的脚本,部署的方式受到了限制。 我曾经在一个项目中,利
用一个专门的表来存放SQL语句。
如要使用相关的SQL语句,就利用关键字搜索获得对应语句。这种做法
近似于存储过程的调用,但却避免了部署上的问题。然而这种方式却在性能上无法得到保证。它仅适合于SQL语句较少的场景。不过,利用良好的设计,我们可以为各种业务提供不同的表来存放SQL语句。同样的道理,这些SQL语句也可以存放到XML文件中,更有利于系统的扩展或修改。不过前提是,我们需要为它提供专门的SQL语句管理工具。 SQL语句的使用无法避免,如何更好的应用SQL语句也无定论,但有一个
原则值得我们遵守,就是“
应该尽量让SQL语句尽存在于数据访问层的具体实现中”。 当然,如果应用ORM,那么一切就变得不同了。因为ORM框架已经为数据访问提供了基本的Select,Insert,Update和Delete操作了。例如在NHibernate中,我们可以直接调用ISession对象的Save方法,来Insert(或者说是Create)一个数据实体对象: public void Insert(OrderInfo order) { ISession s = Sessions.GetSession(); ITransaction trans = null; try { trans = s.BeginTransaction(); s.Save( order); trans.Commit(); } finally { s.Close(); } } 没有SQL语句,也没有那些烦人的Parameters,甚至不需要专门去考虑事务。此外,这样的设计,也是与数据库无关的,NHibernate可以通过Dialect(方言)的机制支持不同的数据库。唯一要做的是,我们需要为OrderInfo定义hbm文件。 当然,ORM框架并非是万能的,面对纷繁复杂的业务逻辑,它并不能完全消灭SQL语句,以及替代复杂的数据库访问逻辑,但它却很好的体现了“80/20(或90/10)法则”(也被称为“帕累托法则”),也就是说:花比较少(10%-20%)的力气就可以解决大部分(80%-90%)的问题,而要解决剩下的少部分问题则需要多得多的努力。至少,那些在数据访问层中占据了绝大部分的CRUD操作,通过利用ORM框架,我们就仅需要付出极少数时间和精力来解决它们了。这无疑缩短了整个项目开发的周期。 还是回到对PetShop的讨论上来。现在我们已经有
了数据实体,数据对象的抽象接口和实现,可以说有关数据库访问的主体就已经完成了。留待我们的还有两个问题需要解决:
1、数据对象创建的管理 2、利于数据库的移植 在PetShop中,要创建的数据对象包括Order,Product,Category,Inventory,Item。在前面的设计中,这些对象已经被抽象为对应的接口,而其实现则根据数据库的不同而有所不同。也就是说,创建的对象有多种类别,而每种类别又有不同的实现,这是典型的抽象工厂模式的应用场景。而上面所述的两个问题,也都可以通过抽象工厂模式来解决。标准的抽象工厂模式类图如下:
 例如,创建SQL Server的Order对象如下: PetShopFactory factory = new SQLServerFactory(); IOrder = factory.CreateOrder(); 要考虑到数据库的可移植性,则factory必须作为一个全局变量,并在主程序运行时被实例化。但这样的设计虽然已经达到了“封装变化”的目的,但在创建PetShopFactory对象时,仍不可避免的出现了具体的类SQLServerFactory,也即是说,程序在这个层面上产生了与SQLServerFactory的强依赖。一旦整个系统要求支持Oracle,那么还需要修改这行代码为: PetShopFactory factory = new oracleFactory(); 修改代码的这种行为显然是不可接受的。解决的办法是“依赖注入”。“依赖注入”的功能通常是用专门的IoC容器提供的,在Java平台下,这样的容器包括Spring,PicoContainer等。而在.Net平台下,最常见的则是Spring.Net。不过,在PetShop系统中,并不需要专门的容器来实现“依赖注入”,简单的做法还是利用配置文件和反射功能来实现。也就是说,我们可以在web.config文件中,配置好具体的Factory对象的完整的类名。然而,当我们利用配置文件和反射功能时,具体工厂的创建就显得有些“画蛇添足”了,我们完全可以在配置文件中,直接指向具体的数据库对象实现类,例如PetShop.SQLServerDAL.IOrder。那么,抽象工厂模式中的相关工厂就可以简化为一个工厂类了,所以我将这种模式称之为“具有简单工厂特质的抽象工厂模式”,其类图如下:
例如,创建SQL Server的Order对象如下: PetShopFactory factory = new SQLServerFactory(); IOrder = factory.CreateOrder(); 要考虑到数据库的可移植性,则factory必须作为一个全局变量,并在主程序运行时被实例化。但这样的设计虽然已经达到了“封装变化”的目的,但在创建PetShopFactory对象时,仍不可避免的出现了具体的类SQLServerFactory,也即是说,程序在这个层面上产生了与SQLServerFactory的强依赖。一旦整个系统要求支持Oracle,那么还需要修改这行代码为: PetShopFactory factory = new oracleFactory(); 修改代码的这种行为显然是不可接受的。解决的办法是“依赖注入”。“依赖注入”的功能通常是用专门的IoC容器提供的,在Java平台下,这样的容器包括Spring,PicoContainer等。而在.Net平台下,最常见的则是Spring.Net。不过,在PetShop系统中,并不需要专门的容器来实现“依赖注入”,简单的做法还是利用配置文件和反射功能来实现。也就是说,我们可以在web.config文件中,配置好具体的Factory对象的完整的类名。然而,当我们利用配置文件和反射功能时,具体工厂的创建就显得有些“画蛇添足”了,我们完全可以在配置文件中,直接指向具体的数据库对象实现类,例如PetShop.SQLServerDAL.IOrder。那么,抽象工厂模式中的相关工厂就可以简化为一个工厂类了,所以我将这种模式称之为“具有简单工厂特质的抽象工厂模式”,其类图如下:
 DataAccess类完全取代了前面创建的工厂类体系,它是一个sealed类,其中创建各种数据对象的方法,均为静态方法。之所以能用这个类达到抽象工厂的目的,是因为配置文件和反射的运用,如下的代码片断所示: public sealed class DataAccess { // Look up the DAL implementation we should be using private static readonly string path = ConfigurationManager.AppSettings[”WebDAL”]; private static readonly string orderPath = ConfigurationManager.AppSettings[”OrdersDAL”]; public static PetShop.IDAL.IOrder CreateOrder() { string className = orderPath + “.Order”; return (PetShop.IDAL.IOrder)Assembly.Load(orderPath).CreateInstance(className); } } 在PetShop中,
这种依赖配置文件和反射创建对象的方式极其常见,包括IBLLStategy、CacheDependencyFactory等等。这些实现逻辑散布于整个PetShop系统中,在我看来,是可以在此基础上进行重构的。也就是说,我们可以为整个系统提供类似于“Service Locator”的实现: public static class ServiceLocator { private static readonly string dalPath = ConfigurationManager.AppSettings[”WebDAL”]; private static readonly string orderPath = ConfigurationManager.AppSettings[”OrdersDAL”]; //…… private static readonly string orderStategyPath = ConfigurationManager.AppSettings[”OrderStrategyAssembly”]; public static object LocateDALObject(string className) { string fullPath = dalPath + “.” + className; return Assembly.Load(dalPath).CreateInstance(fullPath); } public static object LocateDALOrderObject(string className) { string fullPath = orderPath + “.” + className; return Assembly.Load(orderPath).CreateInstance(fullPath); } public static object LocateOrderStrategyObject(string className) { string fullPath = orderStategyPath + “.” + className; return Assembly.Load(orderStategyPath).CreateInstance(fullPath); } //…… } 那么和所谓“依赖注入”相关的代码都可以利用ServiceLocator来完成。例如类DataAccess就可以简化为: public sealed class DataAccess { public static PetShop.IDAL.IOrder CreateOrder() { return (PetShop.IDAL.IOrder)ServiceLocator. LocateDALOrderObject(”Order”); } } 通过ServiceLocator,将所有与配置文件相关的namespace值统一管理起来,这有利于各种动态创建对象的管理和未来的维护。
DataAccess类完全取代了前面创建的工厂类体系,它是一个sealed类,其中创建各种数据对象的方法,均为静态方法。之所以能用这个类达到抽象工厂的目的,是因为配置文件和反射的运用,如下的代码片断所示: public sealed class DataAccess { // Look up the DAL implementation we should be using private static readonly string path = ConfigurationManager.AppSettings[”WebDAL”]; private static readonly string orderPath = ConfigurationManager.AppSettings[”OrdersDAL”]; public static PetShop.IDAL.IOrder CreateOrder() { string className = orderPath + “.Order”; return (PetShop.IDAL.IOrder)Assembly.Load(orderPath).CreateInstance(className); } } 在PetShop中,
这种依赖配置文件和反射创建对象的方式极其常见,包括IBLLStategy、CacheDependencyFactory等等。这些实现逻辑散布于整个PetShop系统中,在我看来,是可以在此基础上进行重构的。也就是说,我们可以为整个系统提供类似于“Service Locator”的实现: public static class ServiceLocator { private static readonly string dalPath = ConfigurationManager.AppSettings[”WebDAL”]; private static readonly string orderPath = ConfigurationManager.AppSettings[”OrdersDAL”]; //…… private static readonly string orderStategyPath = ConfigurationManager.AppSettings[”OrderStrategyAssembly”]; public static object LocateDALObject(string className) { string fullPath = dalPath + “.” + className; return Assembly.Load(dalPath).CreateInstance(fullPath); } public static object LocateDALOrderObject(string className) { string fullPath = orderPath + “.” + className; return Assembly.Load(orderPath).CreateInstance(fullPath); } public static object LocateOrderStrategyObject(string className) { string fullPath = orderStategyPath + “.” + className; return Assembly.Load(orderStategyPath).CreateInstance(fullPath); } //…… } 那么和所谓“依赖注入”相关的代码都可以利用ServiceLocator来完成。例如类DataAccess就可以简化为: public sealed class DataAccess { public static PetShop.IDAL.IOrder CreateOrder() { return (PetShop.IDAL.IOrder)ServiceLocator. LocateDALOrderObject(”Order”); } } 通过ServiceLocator,将所有与配置文件相关的namespace值统一管理起来,这有利于各种动态创建对象的管理和未来的维护。