Doris Join 优化原理
Doris 支持两种物理算子,一类是 Hash Join,另一类是 Nest Loop Join。
- Hash Join:在右表上根据等值 Join 列建立哈希表,左表流式的利用哈希表进行 Join 计算,它的限制是只能适用于等值 Join。
- Nest Loop Join:通过两个 for 循环,很直观。然后它适用的场景就是不等值的 Join,例如:大于小于或者是需要求笛卡尔积的场景。它是一个通用的 Join 算子,但是性能表现差。
作为分布式的 MPP 数据库, 在 Join 的过程中是需要进行数据的 Shuffle。数据需要进行拆分调度,才能保证最终的 Join 结果是正确的。举个简单的例子,假设关系S 和 R 进行Join,N 表示参与 Join 计算的节点的数量;T 则表示关系的 Tuple 数目。
Doris Shuffle 方式
Doris 支持 4 种 Shuffle 方式
Broadcast Join
它要求把右表全量的数据都发送到左表上,即每一个参与 Join 的节点,它都拥有右表全量的数据,也就是 T(R)。
它适用的场景是比较通用的,同时能够支持 Hash Join 和 Nest loop Join,它的网络开销 N * T(R)。
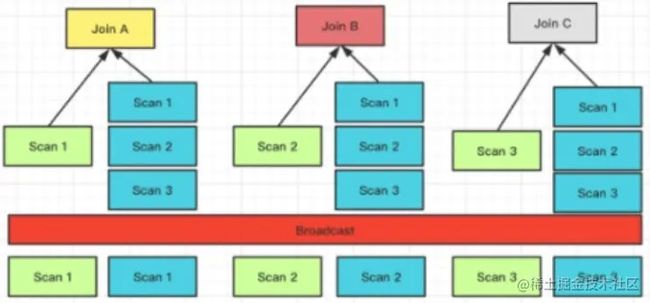
左表数据不移动,右表数据发送到左表数据的扫描节点。
Shuffle Join
当进行 Hash Join 时候,可以通过 Join 列计算对应的 Hash 值,并进行 Hash 分桶。
它的网络开销则是:T(R) + T(N),但它只能支持 Hash Join,因为它是根据 Join 的条件也去做计算分桶的。
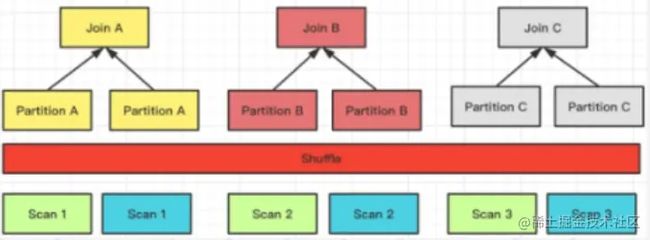
左右表数据根据分区,计算的记过发送到不同的分区节点上。
Bucket Shuffle Join
Doris 的表数据本身是通过 Hash 计算分桶的,所以就可以利用表本身的分桶列的性质来进行 Join 数据的 Shuffle。假如两张表需要做 Join,并且 Join 列是左表的分桶列,那么左表的数据其实可以不用去移动右表通过左表的数据分桶发送数据就可以完成 Join 的计算。
它的网络开销则是:T(R)相当于只 Shuffle 右表的数据就可以了。
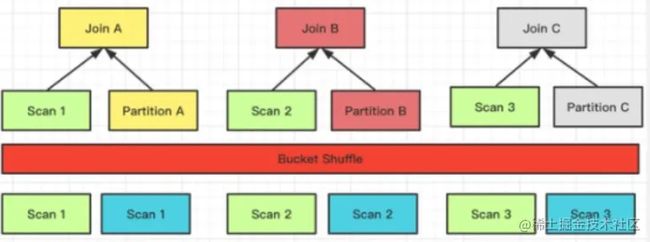
左表数据不移动,右表数据根据分区计算的结果发送到左表扫表的节点
Colocate
它与 Bucket Shuffle Join 相似,相当于在数据导入的时候,根据预设的 Join 列的场景已经做好了数据的 Shuffle。那么实际查询的时候就可以直接进行 Join 计算而不需要考虑数据的 Shuffle 问题了。
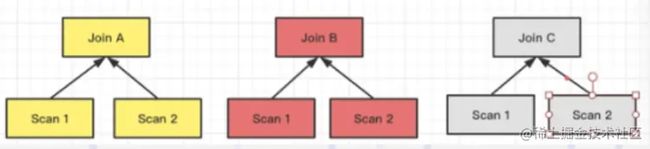
数据已经预先分区,直接在本地进行 Join 计算
四种 Shuffle 方式对比
| Shuffle方式 | 网络开销 | 物理算子 | 适用场景 |
|---|---|---|---|
| BroadCast | N * T(R) | Hash Join / Nest Loop Join | 通用 |
| Shuffle | T(S) + T(R) | Hash Join | 通用 |
| Bucket Shuffle | T(R) | Hash Join | Join条件中存在左表的分布式列,且左表执行时为单分区 |
| Colocate | 0 | Hash Join | Join条件中存在左表的分布式列,切左右表同属于一个Colocate Group |
N : 参与 Join 计算的 Instance 个数
T(关系) : 关系的 Tuple 数目
上面这 4 种方式灵活度是从高到低的,它对这个数据分布的要求是越来越严格,但 Join 计算的性能也是越来越好的。
Runtime Filter Join 优化
Doris 在进行 Hash Join 计算时会在右表构建一个哈希表,左表流式的通过右表的哈希表从而得出 Join 结果。而 RuntimeFilter 就是充分利用了右表的 Hash 表,在右表生成哈希表的时,同时生成一个基于哈希表数据的一个过滤条件,然后下推到左表的数据扫描节点。通过这样的方式,Doris 可以在运行时进行数据过滤。
假如左表是一张大表,右表是一张小表,那么利用右表生成的过滤条件就可以把绝大多数在 Join 层要过滤的数据在数据读取时就提前过滤,这样就能大幅度的提升 Join 查询的性能。
当前 Doris 支持三种类型 RuntimeFilter
- 一种是 IN,很好理解,将一个 hashset 下推到数据扫描节点。
- 第二种就是 BloomFilter,就是利用哈希表的数据构造一个 BloomFilter,然后把这个 BloomFilter 下推到查询数据的扫描节点。。
- 最后一种就是 MinMax,就是个 Range 范围,通过右表数据确定 Range 范围之后,下推给数据扫描节点。
Runtime Filter 适用的场景有两个要求:
- 第一个要求就是左表大右表小,因为构建 Runtime Filter是需要承担计算成本的,包括一些内存的开销。
- 第二个要求就是左右表 Join 出来的结果很少,说明这个 Join 可以过滤掉左表的绝大部分数据。
当符合上面两个条件的情况下,开启 Runtime Filter 就能收获比较好的效果
当 Join 列为左表的 Key 列时,RuntimeFilter 会下推到存储引擎。Doris 本身支持延迟物化,
延迟物化简单来说是这样的:假如需要扫描 A、B、C 三列,在 A 列上有一个过滤条件: A 等于 2,要扫描 100 行的话,可以先把 A 列的 100 行扫描出来,再通过 A = 2 这个过滤条件过滤。之后通过过滤完成后的结果,再去读取 B、C 列,这样就能极大的降低数据的读取 IO。所以说 Runtime Filter 如果在 Key 列上生成,同时利用 Doris 本身的延迟物化来进一步提升查询的性能。
Runtime Filter 类型
Doris 提供了三种不同的 Runtime Filter 类型:
- IN 的优点就是效果过滤效果明显,且快速。它的缺点首先第一个它只适用于 BroadCast,第二,它右表超过一定数据量的时候就失效了,当前 Doris 目前配置的是1024,即右表如果大于 1024,IN 的 Runtime Filter 就直接失效了。
- MinMax 的优点是开销比较小。它的缺点就是对数值列还有比较好的效果,但对于非数值列,基本上就没什么效果。
- Bloom Filter 的特点就是通用,适用于各种类型、效果也比较好。缺点就是它的配置比较复杂并且计算较高。
Join Reorder
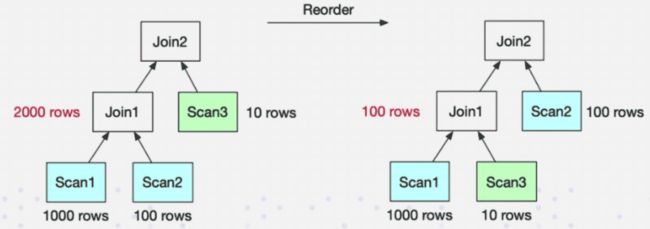
数据库一旦涉及到多表 Join,Join 的顺序对整个 Join 查询的性能是影响很大的。假设有三张表 Join,参考下面这张图,左边是 a 表跟 b 张表先做 Join,中间结果的有 2000 行,然后与 c 表再进行 Join 计算。
接下来看右图,把 Join 的顺序调整了一下。把 a 表先与 c 表 Join,生成的中间结果只有 100,然后最终再与 b 表 Join 计算。最终的 Join 结果是一样的,但是它生成的中间结果有 20 倍的差距,这就会产生一个很大的性能 Diff 了。
Doris 目前支持基于规则的 Join Reorder 算法。它的逻辑是:
- 让大表、跟小表尽量做 Join,它生成的中间结果是尽可能小的。
- 把有条件的 Join 表往前放,也就是说尽量让有条件的 Join 表进行过滤
- Hash Join 的优先级高于 Nest Loop Join,因为 Hash join 本身是比 Nest Loop Join 快很多的。
Doris Join 调优方法
Doris Join 调优的方法:
- 利用 Doris 本身提供的 Profile,去定位查询的瓶颈。Profile 会记录 Doris 整个查询当中各种信息,这是进行性能调优的一手资料。。
- 了解 Doris 的 Join 机制,这也是第二部分跟大家分享的内容。知其然知其所以然、了解它的机制,才能分析它为什么比较慢。
- 利用 Session 变量去改变 Join 的一些行为,从而实现 Join 的调优。
- 查看 Query Plan 去分析这个调优是否生效。
上面的 4 步基本上完成了一个标准的 Join 调优流程,接着就是实际去查询验证它,看看效果到底怎么样。
如果前面 4 种方式串联起来之后,还是不奏效。这时候可能就需要去做 Join 语句的改写,或者是数据分布的调整、需要重新去 Recheck 整个数据分布是否合理,包括查询 Join 语句,可能需要做一些手动的调整。当然这种方式是心智成本是比较高的,也就是说要在尝试前面方式不奏效的情况下,才需要去做进一步的分析。
调优案例实战
案例一
一个四张表 Join 的查询,通过 Profile 的时候发现第二个 Join 耗时很高,耗时 14 秒。
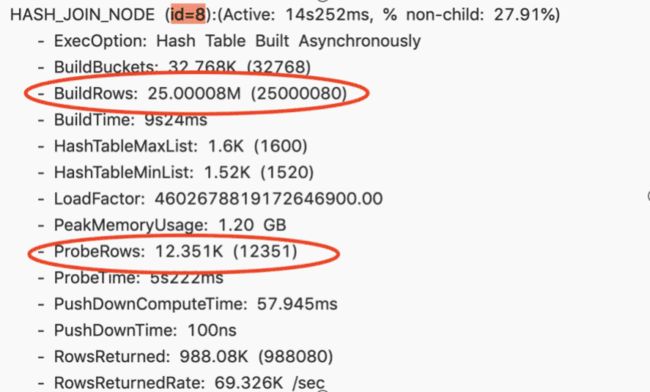
进一步分析 Profile 之后,发现 BuildRows,就是右表的数据量是大概 2500 万。而 ProbeRows ( ProbeRows 是左表的数据量)只有 1 万多。这种场景下右表是远远大于左表,这显然是个不合理的情况。这显然说明 Join 的顺序出现了一些问题。这时候尝试改变 Session 变量,开启 Join Reorder。
set enable_cost_based_join_reorder = true
这次耗时从 14 秒降到了 4 秒,性能提升了 3 倍多。
此时再 Check Profile 的时候,左右表的顺序已经调整正确,即右表是大表,左表是小表。基于小表去构建哈希表,开销是很小的,这就是典型的一个利用 Join Reorder 去提升 Join 性能的一个场景
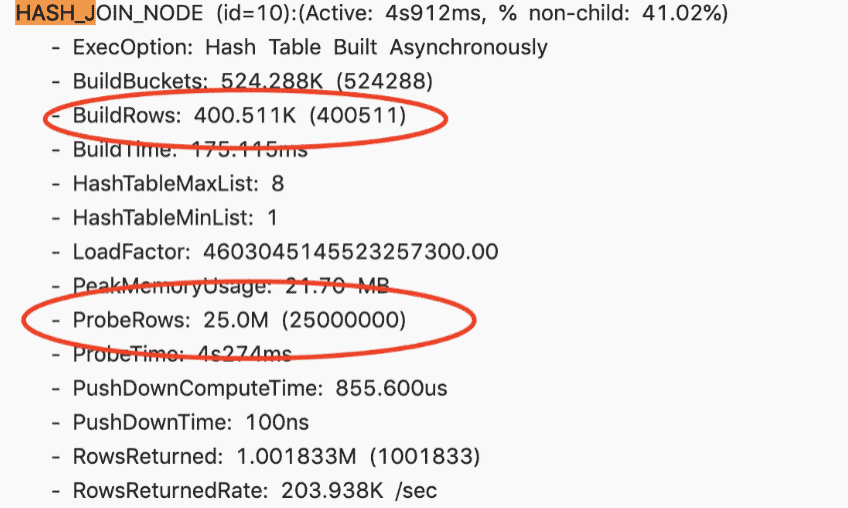
案例二
存在一个慢查询,查看 Profile 之后,整个 Join 节点耗时大概44秒。它的右表有 1000 万,左表有 6000 万,最终返回的结果也只有 6000 万。
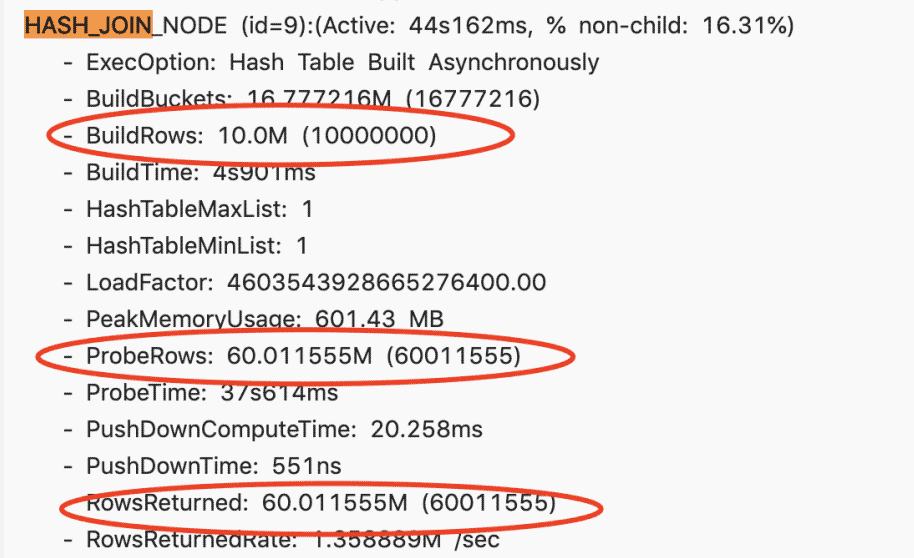
这里可以大致的估算出过滤率是很高的,那为什么 Runtime Filter 没有生效呢?通过 Query Plan 去查看它,发现它只开启了 IN 的 Runtime Filter。
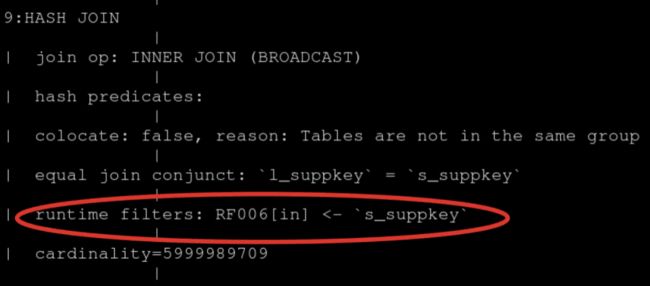
当右表超过1024行的话, IN 是不生效的,所以根本起不到什么过滤的效果,所以尝试调整 RuntimeFilter 的类型。
这里改为了 BloomFilter,左表的 6000 万条数据过滤了 5900 万条。基本上 99% 的数据都被过滤掉了,这个效果是很显著的。查询也从原来的 44 秒降到了 13 秒,性能提升了大概也是三倍多。
案例三
下面是一个比较极端的 Case,通过一些环境变量调优也没有办法解决,因为它涉及到 SQL Rewrite,所以这里列出来了原始的 SQL 。
select 100.00 * sum (case
when P_type like 'PROMOS'
then 1 extendedprice * (1 - 1 discount)
else 0
end ) / sum(1 extendedprice * (1 - 1 discount)) as promo revenue
from lineitem, part
where
1_partkey = p_partkey
and 1_shipdate >= date '1997-06-01'
and 1 shipdate < date '1997-06-01' + interval '1' month
这个 Join 查询是很简单的,单纯的一个左右表的 Join 。当然它上面有一些过滤条件,打开 Profile 的时候,发现整个查询 Hash Join 执行了三分多钟,它是一个 BroadCast 的 Join,它的右表有 2 亿条,左表只有 70 万。在这种情况下选择了 Broadcast Join 是不合理的,这相当于要把 2 亿条做一个 Hash Table,然后用 70 万条遍历两亿条的 Hash Table ,这显然是不合理的。
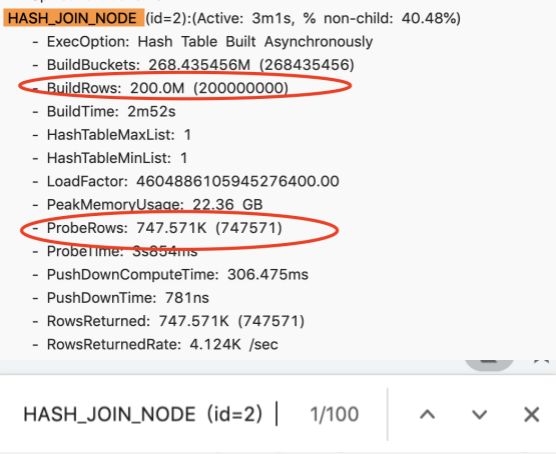
为什么会产生不合理的 Join 顺序呢?其实这个左表是一个 10 亿条级别的大表,它上面加了两个过滤条件,加完这两个过滤条件之后, 10 亿条的数据就剩 70 万条了。但 Doris 目前没有一个好的统计信息收集的框架,所以它不知道这个过滤条件的过滤率到底怎么样。所以这个 Join 顺序安排的时候,就选择了错误的 Join 的左右表顺序,导致它的性能是极其低下的。
下图是改写完成之后的一个 SQL 语句,在 Join 后面添加了一个Join Hint,在Join 后面加一个方括号,然后把需要的 Join 方式写入。这里选择了 Shuffle Join,可以看到右边它实际查询计划里面看到这个数据确实是做了 Partition ,原先 3 分钟的耗时通过这样的改写完之后只剩下 7 秒,性能提升明显
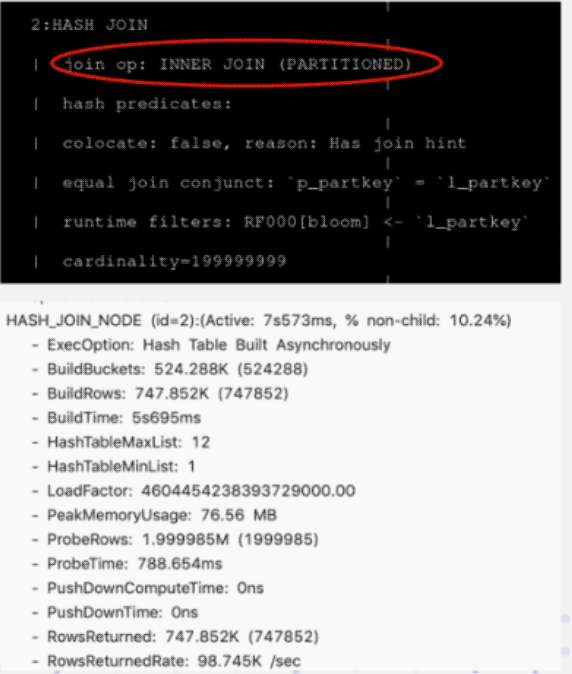
Doris Join 调优建议
最后我们总结 Doris Join 优化调优的四点建议:
- 第一点:在做 Join 的时候,要尽量选择同类型或者简单类型的列,同类型的话就减少它的数据 Cast,简单类型本身 Join 计算就很快。
- 第二点:尽量选择 Key 列进行 Join, 原因前面在 Runtime Filter 的时候也介绍了,Key 列在延迟物化上能起到一个比较好的效果。
- 第三点:大表之间的 Join ,尽量让它 Co-location ,因为大表之间的网络开销是很大的,如果需要去做 Shuffle 的话,代价是很高的。
- 第四点:合理的使用 Runtime Filter,它在 Join 过滤率高的场景下效果是非常显著的。但是它并不是万灵药,而是有一定副作用的,所以需要根据具体的 SQL 的粒度做开关。
- 最后:要涉及到多表 Join 的时候,需要去判断 Join 的合理性。尽量保证左表为大表,右表为小表,然后 Hash Join 会优于 Nest Loop Join。必要的时可以通过 SQL Rewrite,利用 Hint 去调整 Join 的顺序。
以上就是Doris Join 优化原理文档详解的详细内容,更多关于Doris Join 优化原理的资料请关注脚本之家其它相关文章!