比啃西瓜书更好的机器学习视频教程
在当下行业大地震的环境中,如何不让自己陷入被替代或被裁员的危机?掌握硬技术,向技术要红利非常重要!
继续看下去,你就已经领先90%的程序猿小哥哥们了!

N1
机器学习领域的“常青树”
当今社会已经不再歌颂个人英雄主义,不再传唱“一夫当关,万夫莫敌”这类流芳百世的传世之奇。
这个时代更加传颂的是“团结就是力量”、“众人拾柴火焰高”等凝聚力量干大事的显著优势。

来源:谷歌图片
“团队”这一概念和意识已经深刻融入于工作、生活和学习的方方面面,往往由于实际问题的复杂性远高于一个人或者一个方法的处理能力,所以在解决实际问题的过程中基本都是由团队高效率、高质量的完成。
在数据挖掘领域常用的机器学习方法中,我们经常听说各种算法,例如线性判别分析、支持向量机、决策树等。今天我们将介绍被誉为机器学习的先进算法的“集成学习”算法。因为它用“身体力行”的证明着“团结就是力量”,集成学习方法训练多个学习器并将它们结合起来解决一个问题,并且在实践中获得了巨大成功,成为机器学习领域的“常青树”,受到学术界和产业界的广泛关注。
N2
集成学习:解决问题的“大管家”
集成学习可能是你第一次听说,但是你知道吗?算法来源于生活,你在生活中可能不止一次用过这个思想。当你为了实现某一目标而合理协调每一个个体(人或事)解决问题时,你已经初步认识了集成学习算法,并且和它打交道不止一次了。
集成学习技术已被证明可以在机器学习问题上产生更好的性能。我们可以将这些技术用于回归和分类问题,这些集成技术的最终预测是通过组合几个基本模型的结果获得的,平均、投票和堆叠是将结果组合起来以获得最终预测的一些方式。在本文中,我们将探讨如何使用集成学习来提出最佳机器学习模型。
1
什么是集成学习?
集成学习是将多个机器学习模型组合到一个问题中。这些模型被称为弱学习器。直觉是,当你将几个弱学习器组合在一起时,它们可以成为强学习器。每个弱学习器都适合训练集并提供获得的预测。最终的预测结果是通过组合所有弱学习器的结果来计算的。

2
基本的集成学习方法
01
最大投票数(Max voting)
在分类中,每个模型的预测都是一次投票。在最大投票中,最终预测来自得票最多的预测。让我们举一个例子,你有三个分类器,预测如下:
分类器 1 – A 类
分类器 2 – C 类
分类器 3 – C 类
这里的最终预测将是C 类,因为它拥有最多的选票。
02
平均(Averaging)
在求平均值时,最终输出是所有预测的平均值。这适用于回归问题。例如,在随机森林回归中,最终结果是来自各个决策树的预测的平均值。我们以预测商品价格的三个回归模型为例,如下所示:
回归量 1 – 100
回归量 2 – 300
回归量 3 – 400
最终预测将是 100、300 和 400 的平均值。
03
加权平均(Weighted average)
在加权平均中,具有更高预测能力的基础模型更为重要。在价格预测示例中,将为每个回归量分配一个权重。权重之和等于一。假设回归变量的权重分别为 0.15、0.45 和 0.4。最终的模型预测可以计算如下:
0.15 * 100 + 0.45*300 + 0.4*400 = 310
3
高级集成学习方法
01
堆叠(Stacking)
堆叠是组合各种估计量以减少它们的偏差的过程。来自每个估计器的预测堆叠在一起,并用作计算最终预测的最终估计器(通常称为元模型)的输入。最终估计器的训练通过交叉验证进行。堆叠可以用于回归和分类问题。
可以认为堆叠发生在以下步骤中:
1. 将数据拆分为训练集和验证集
2. 将训练集分成K个折叠,例如10个
3. 在第 9 次训练基础模型(比如 SVM)并在第 10 次进行预测
4. 重复直到你对每一次折叠都有一个预测
5. 在整个训练集上拟合基础模型
6. 使用模型对测试集进行预测
7. 对其他基本模型(例如决策树)重复步骤 3-6
8. 使用来自测试集的预测作为新模型(元模型)的特征
9. 使用元模型对测试集进行最终预测
对于回归问题,传递给元模型的值是数字。对于分类问题,它们是概率或类标签。
02
混合(Blending)
混合类似于堆叠,但使用训练集中的一个保持集来进行预测。因此,仅在保留集上进行预测。预测和保持集用于构建对测试集进行预测的最终模型。你可以将混合视为一种堆叠,其中元模型根据基本模型在保留验证集上所做的预测进行训练。
可以将混合过程视为:
1、将数据拆分为测试和验证集
2、在验证集上拟合基本模型
3、对验证集和测试集进行预测
4、使用验证集及其预测来构建最终模型
5、使用此模型进行最终预测
混合的概念在Kaggle奖竞赛中流行起来,根据Kaggle集成指南:“混合是 Netflix 获奖者引入的一个词。它非常接近于堆叠泛化,但更简单一点,信息泄漏的风险也更小。一些研究人员交替使用“堆叠集成”和“混合”。通过混合,你不是为训练集创建折叠预测,而是创建一个小的保持集,比如训练集的 10%。然后 stacker 模型只在这个保持集上训练。”
03
混合与堆叠(Blending vs stacking)
混合比堆叠更简单,可以防止模型中的信息泄漏。泛化器和堆栈器使用不同的数据集。但是,混合使用较少的数据并可能导致过度拟合。交叉验证在堆叠上比混合更可靠。与在混合中使用小的保留数据集相比,它计算了更多的折叠。
04
装袋(Bagging)
Bagging 随机抽取数据样本,构建学习算法,并使用均值来寻找 Bagging 概率。它也称为bootstrap 聚合。Bagging 聚合了来自多个模型的结果,以获得一个概括的结果。
该方法包括:
1、从原始数据集创建多个带有替换的子集
2、为每个子集建立一个基本模型
3、并行运行所有模型
4、结合所有模型的预测以获得最终预测
05
增强(Boosting)
Boosting是一种机器学习集成技术,通过将弱学习器转换为强学习器来减少偏差和方差。弱学习器以顺序方式应用于数据集。第一步是构建初始模型并将其拟合到训练集中。然后拟合试图修复第一个模型产生的错误的第二个模型。
下面是整个过程的样子:
1、从原始数据创建一个子集
2、用这些数据建立一个初始模型
3、对整个数据集运行预测
4、使用预测值和实际值计算误差
5、为错误的预测分配更多的权重
6、创建另一个模型,尝试修复上一个模型中的错误
7、使用新模型对整个数据集运行预测
8、用每个模型创建多个模型,旨在纠正前一个模型产生的错误
9、通过对所有模型的均值进行加权得到最终模型
4
集成学习常用库
集成学习常用库广义可以分为有两类:Bagging算法和Boosting算法。
01
Bagging算法
Bagging算法基于上述Bagging技术。让我们来看看其中的几个。
02
Bagging meta估计器
Scikit-learn让我们实现了一个“BaggingClassifier”和一个“BaggingRegressor”。Bagging meta估计器将每个基本模型拟合到原始数据集的随机子集上。然后它通过聚合各个基本模型预测来计算最终预测。聚合是通过投票或平均来完成的。该方法通过在其构建过程中引入随机化来减少估计量的方差。
Bagging有几种:
1、将数据的随机子集绘制为样本的随机子集称为粘贴。
2、当样本被替换抽取时,该算法被称为Bagging。
3、如果将随机数据子集作为特征的随机子集,则该算法称为Random Subspaces。
4、当从样本和特征的子集创建基本估计量时,它是Random Patches。
让我们来看看如何使用 Scikit-learn 创建Bagging估计器。这需要几个步骤:
1、导入“BaggingClassifier”
2、导入一个基本估计器——一个决策树分类器
3、创建一个“BaggingClassifier”的实例

Bagging分类器有几个参数:
1、基本估计器——这里是一个决策树分类器,
2、集成中的估计器数量
3、“max_samples”定义将从每个基估计器的训练集中抽取的样本数,
4、“max_features”指定将用于训练每个基本估计器的特征数量。
接下来,可以在训练集上拟合这个分类器并对其进行评分。
![]()
回归问题的过程将相同,唯一的区别是使用回归估计器。

03
随机森林(Forests of randomized trees)
一个随机森林是随机的决策树的集合。每个决策树都是从数据集的不同样本创建的。样本是替换抽取的。每棵树都会产生自己的预测。在回归中,将这些结果平均以获得最终结果。在分类中,最终结果可以作为得票最多的类。平均和投票通过防止过度拟合来提高模型的准确性。在Scikit-learn中,可以通过“RandomForestClassifier”和“ExtraTreesClassifier”来实现随机树的森林。类似的估计量可用于回归问题。

04
Boosting算法
这些算法基于前面描述的 boosting 框架。让我们来看看其中的几个。
05
AdaBoost
AdaBoost 通过拟合一系列弱学习器来工作。它在后续迭代中为不正确的预测提供更多的权重,而纠正预测的权重较小。这迫使算法专注于更难预测的观察。最终预测来自权衡多数票或总和。AdaBoost 可用于回归和分类问题。让我们花点时间看看如何使用 Scikit-learn 将算法应用于分类问题。
我们使用“AdaBoostClassifier”,“n_estimators”决定了集成中弱学习器的数量。每个弱学习器对最终组合的贡献由“learning_rate”控制。默认情况下,决策树用作基础估计量。为了获得更好的结果,可以调整决策树的参数。你还可以调整基本估计量的数量。

06
梯度树Boosting(Gradient tree boosting)
梯度树Boosting也将一组弱学习器组合成一个强学习器。就梯度Boosting而言,需要注意三个主要事项:
1、必须使用微分损失函数
2、决策树被用作弱学习器
3、它是一个加法模型,所以树是一个接一个地添加的。梯度下降用于在添加后续树时最小化损失。
可以使用 Scikit-learn 构建基于梯度树Boosting的模型。
07
XGBoosting
eXtreme Gradient Boosting,俗称XGBoost,是一个极限梯度Boosting框架。它基于一组弱决策树。它可以在单台计算机上进行并行计算。该算法使用回归树作为基础学习器。它还内置了交叉验证。开发人员喜欢它的准确性、效率和可行性。

08
LightGBM
LightGBM是一种基于树学习的梯度Boosting算法。与其他使用深度增长的基于树的算法不同,LightGBM 使用叶方向的树增长。Leaf-wise 增长算法往往比基于 dep-wise 的算法收敛得更快。
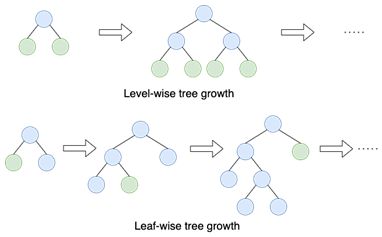
通过设置适当的目标,LightGBM 可用于回归和分类问题。以下是如何将 LightGBM 应用于二元分类问题。

5
何时使用集成学习?
当你想提高机器学习模型的性能时,你可以使用集成学习技术。例如,提高分类模型的准确性或降低回归模型的平均绝对误差。集成还可以产生更稳定的模型。当你的模型在训练集上过度拟合时,你还可以使用集成学习方法来创建更复杂的模型。然后,集成中的模型将通过组合它们的预测来提高数据集的性能。
6
什么时候集成学习效果最好?
当基本模型不相关时,集成学习效果最好。例如,你可以在不同的数据集或特征上训练不同的模型,例如线性模型、决策树和神经网络。基础模型的相关性越小越好。使用不相关模型背后的想法是,每个模型可能都在解决另一个模型的弱点。它们还具有不同的优势,将它们结合起来将产生性能良好的估算器。例如,创建一个仅包含基于树的模型的集成可能不如将树型算法与其他类型的算法相结合那样有效。


由此可见,在职场中,我们一定要提高自己,让自己可以闲下来做有意义的事,不能忙得要死干无意义的活。拥有人工智能思维,会数据分析,利用好数据价值,使用好机器学习算法,能够深入业务帮企业创造价值,才是职场晋升的关键!
作为见证了这次行业动荡的互联网从业者,如果不想被危机感紧紧压迫着,我们必须跟上科技的快车,要成为坐在车厢里的人。
否则,就别抱怨车轮从脸上压过去。

上面说了这么多,你想要掌握更多的机器学习入门的知识以及实践能力,搭建更加有价值的机器学习模型吗?想要年薪40万吗?机会来了!11月2日20点特邀多年实战讲师刘老师将通过2天时间带你入门数据挖掘与机器学习,结合理论知识与实际操作让你零基础入门数据挖掘和机器学习,学完即可用于工作!
为了让大家学好机器学习,并具备向上发展的能力,今天特别给大家申请的优惠,限时0元给到你!
本次课程,今天在本公众号内,前300名学习名额限时免费!报名后福利多多,你将有机会获得:西部数据移动硬盘1个+异步社区15天VIP会员卡+抽3本异步社区纸书!(福利详情继续往下看)更多福利先到先得!

大厂CV研发
多年实战讲师亲自带队
2天数据挖掘/机器学习实战案例分析
6大能力掌握和提升
还在等什么?
扫描二维码0元名听课!
领取密码回复"DM08"
▼

领取密码回复"DM08"
领取参与抽奖名额及开通VIP权限
哇哦!学习+福利两不误!
扫描码添加助教老师
领取密码回复"DM08"
免费领取课程
《SVM与xgboost特训》


 点击“阅读原文”,0元抢限量大神课!
点击“阅读原文”,0元抢限量大神课!