【NLP基础理论】01 数据预处理
注:
Unimelb Comp90042 NLP笔记
相关tutorial代码链接
目录
- 1 Preprocessing Steps(预处理步骤)
-
- 1.1 Sentence Segmentation(句子分段)
- 1.2 Word Tokenisation(词语分段)
- 1.3 Subword Tokenisation(子词分段)
-
- 1.3.1 Byte Pair Encoding
- 1.4 Word Normalisation(词规范化)
-
- 1.4.1 Inflectional Morphology(屈折词法)
- 1.4.2 Lemmatisation(词形还原)
- 1.4.3 Derivational Morphology(派生形态)
- 1.4.4 Stemming(词干提取)
- 1.4.5 The Porter Stemmer
- 1.5 Stop Words
- 1.6 代码
因为语言都是组合形态出现,所以要去理解一句话的意思,必须先将它进行拆分,也就是做个preprocessing
1 Preprocessing Steps(预处理步骤)
- Remove unwanted formatting (HTML). 大部分语句可能自网页,所以需要去除
<\p>等格式。
- Sentence Segementation: 从documents into sentences
- Word Tokenisation:从sentences 到 words
- Word Normalisation:变成更普通的形式(canonical forms)
- Stopword Removal:删除不想要的单词

1.1 Sentence Segmentation(句子分段)
Naive approach:根据标点符号([.?!])的正则来判断。但是像缩写或者商标如“This is Yahoo! website.” 就会出错。
Second try:用正则来规定标点符号后面还会出现大写字母 ([.?!] [A-Z]),但是像“Mr. Brown”,“U.S.A”就不行了。
Better Yet:用lexicons
Machine learning:用Binary Classifier(二值分类器),判断标点符号是不是一个句子的结尾。
Binary Classifier:
- 判断每个“.”并决定这个是不是句末。一般会用Decision Tree和Logistic Regression。
- 特征:查看“.”前后的单词;查看单词形状(大小写、全部大写、数字、字符长度);词性(part-of-speech tag)是不是通常表示了一个句子的开头。
1.2 Word Tokenisation(词语分段)
Naive approach:
用空格划分(\w+)
缩写(U.S.A)
杠- Hyphen(merry-go-round)
数字(1,000,00.01)
日期(3/1/2016)
附着成分Clitics(n’t in can’t)
网络用语(#metoo,http://www.google.com)
Standard Approach:
一般会假设有个字典,然后用MaxMatch Algorithm去Greedily匹配字典里最长的单词。
比如“thisisinsane”,"t"会一直匹配到“this”,(TODO:这里要看以前ucsd的笔记,关于统计一个字符串里面有多少个字的组合),"is"和"insane"同理。
但这种情况就会出现问题:“去买新西兰花”,此时会变成“去;买;新西兰;花”,但其实更有意义的分法(或者语义)是“去;买;新;西兰花”。
优点:能完整的保持单词内容,也是最直观的切分方法。
缺点1:
- 如果misspelling或者稀缺词语(那些没有在训练集里出现的单词),就无法正确划分单词,此时就会出现OOV问题(Out of Vocabulary是指不属于自然语言处理环境中的正常词汇的术语);
- 当待处理的语句很大的时候,每个空格或者按照规则分割之后每一个不一样的单词都是一个单独的集合(比如boy,boys就算两个),所以会产生Big Vocabulary。超大词汇表就会让模型将巨大的嵌入矩阵作为输入层和输出层,增加了内存和时间复杂性。
spaCy 和 Moses 是两个热门的rule-based的分词工具。
另一种是Character Tokenisation,即把一句话中出现全部拆分成一个个字符,那这样词表基本上就是26个因为字母和一些符合组成,但是单单去看一个字母是没有任何意义的,如果让模型从字母中学会有意义的和上下文无关的内容,肯定比从一个词语中学到的少很多。
因此引入Subword Tokenisation
1.3 Subword Tokenisation(子词分段)
Subword分割出来的不一定是一个完整的或者正确的词语。
例如:
“Colorless green ideas sleep furiously” → \rightarrow → “[color] [less] [green] [idea] [s] [sleep] [furious] [ly]”。
这类分词方法主要有三种算法实现:Byte Pair Encoding (BPE), WordPiece, Unigram Language Model。其中BPE最常用。
1.3.1 Byte Pair Encoding
核心思想:迭代合并出现频率高的字符对。
例子:
1.准备一个语料库(corpus),并统计这个语料库中每个词语的词频,通过“[词频]词语_”的形式存储,这里的“_”表示词语结尾。
注:“er_”和“er”意思不同,“er_”只能放在结尾,组成“newer_”等,“er”则不表示结尾,可以组成“era”等。
Corpus:
[5] low_
[2] lowest_
[6] newer_
[3] wider_
[2] new_
2.设置token词表的大小,或者循环的次数,作为终止条件。
3. 统计每个字符出现的次数,结尾“_”的次数也要统计。这张表就是vocabulary,后续迭代结束之后就会利用这张表进行分词。
| 字符 | 频次 |
|---|---|
| _ | 18 |
| d | 3 |
| e | 19 |
| i | 3 |
| l | 7 |
| n | 8 |
| o | 7 |
| r | 9 |
| s | 2 |
| t | 2 |
| w | 22 |
4.选择两个连续的字符(序)进行合并,并且合并后有着最高的频次。第一次迭代,选择“r”和“_”,组合成“r_”,总共有 6 + 3 = 9次。然后我们将“r_”和它的频次加入vocabulary,并且减去“r”和“_”的次数。
| 字符 | 频次 |
|---|---|
| _ | 9 |
| d | 3 |
| e | 19 |
| i | 3 |
| l | 7 |
| n | 8 |
| o | 7 |
| r | 0 |
| s | 2 |
| t | 2 |
| w | 22 |
| r_ | 9 |
此时,“r”的频次变成0,说明“r”的出现一定会与“_”关联,也就是说“r”一定是最后一个单词。这个时候可以把“r”从词表里删除,词表由于增加了一个“r_”,减少了一个“r”,所以长度不变。(这里也是为什么大家总说词表一般情况是先增加后减少)
5.接下来合并“e”和“r_”,因为“er_”总共出现了 6 + 3 = 9次是当前频次最高的,同样更新词表。增加了“er_”,减少了“r_”,所以词表长度不变。
| 字符 | 频次 |
|---|---|
| _ | 9 |
| d | 3 |
| e | 10 |
| i | 3 |
| l | 7 |
| n | 8 |
| o | 7 |
| s | 2 |
| t | 2 |
| w | 22 |
| er_ | 9 |
6.然后合并“ew”,共出现8次,更新后的表(_, d, e, i, l, n, o, s, t, w, er_, ew)。这次“ew”没有消除所有的“e”或“w”,也就是说“e”或“w”除了出现在“ew”中还会出现在别的地方,比如“wider”中的“e”和“w”就是分开的。所以词表的长度增加了1。
7.接着就是“new”,总共8次,更新后的表(_, d, e, i, l, o, s, t, w, er_, new)。此时的“new”消除了所有的“n”和“ew”,也就是“n”和“ew”只会出现在“new”里面。这时词表增加了一个“new”但消除了两个,所以词表的长度减少了1。
8.假设我设置循环四次后终止,那么此时的词表就是(_, d, e, i, l, o, s, t, w, er_, new)。
9.根据上述描述,也就可以发现,词表长度的变化总共有三种,+1、-1、不变。
代码:分为两个主要函数,一个专门统计vocabulary,另一个负责合并字符串。
统计词频很暴力,就是遍历vocabulary里每一个元素,利用像两个元素的滑动窗口,挨个组合并且记录频次。找到频次最高的之后进行合并并且输出新的vocabulary。
超详细代码和注释可参考week2/02-bpe.ipynb
注:如果没有看懂可以看这篇(也有知乎翻译的)或者这篇中间提到BPE的地方(我借助了这两篇的表现方式来讲解)。详细实现代码可以参考这篇,每行代码都有注释。
优点:
- Data-informed tokenisation (理解下来可能是这样分出来的词表具有一定数据启示,因为同时根据字符出现的频率来进行分割)
- 不同语种通用
- 对于未知单词也适用
缺点:就是会产生一些不完整的单词(subword)。
其他:
1.实际操作中,BPE会运行成千上万次merge,产生很大的vocabulary
2.经常出现的词会完整的呈现在vocabulary,因为他的词频很高
3.相反,出现少的词就会以subword的形式呈现
4.最糟的情况就是测试集中出现了从来没见过的词(也有可能是Missspelling),那它就会被分成一个个单词。
TODO:另外两个算法也看一眼。
1.4 Word Normalisation(词规范化)
- 统统变小写: Australia → \rightarrow → australia
- 去除形态(morphology): cooking → \rightarrow → cook
- 拼写正确:definately → \rightarrow → definitely
- 扩展缩写:U.S.A → \rightarrow → USA
目的:为了减少词表vocabulary内容,以及让单词能对应到同一种类型。
1.4.1 Inflectional Morphology(屈折词法)
涉及到一定语言学,了解即可。
英语中包含八类2:
- -'s (possessive) 名词所有格,如my father’s dog
- -s (plural) 名词复数, 如two dogs
- -ing (present participle) 动词现在分词,如 reading a book
- -s (third person present singular)动词第三人称单数, 如 goes to school
- -ed (past tense) 过去时,如 washed
- -en (past participle)过去分词,如 taken, written
- -er (comparative) 比较级 ,如faster
- -est (superlative)最高级,如fastest
1-2是关于名词的,3-6是关于动词,最后两个是关于形容词和副词。
1.4.2 Lemmatisation(词形还原)
指去除所有变形从而还原词本身的样子(词元)。
规则变形: speaking → \rightarrow → speak
不规则变形:
poked → \rightarrow → poke
stopping → \rightarrow → stop
was → \rightarrow → be
watches → \rightarrow → watch
所以我们需要一套完整的词元才能保证词形还原的准确性。
1.4.3 Derivational Morphology(派生形态)
一个词的派生形态就是另一个不同的词了。
- 英语中,加上后缀通常都改变了词汇范畴(lexical category):
-ly (personal → \rightarrow → personally)
-ise (final → \rightarrow → finalise)
-er (write → \rightarrow → writer) - 英语中,加上前缀通常改变意思但不改变词汇范畴:
write → \rightarrow → rewrite
healthy → \rightarrow → unhealthy
1.4.4 Stemming(词干提取)
它会去除所有后缀,只留下一个词干:automate, automatic, automation → \rightarrow → automat.
可以看出一般词干都不会是一个有实际意义的单词,也不总是可解释的。
通常会用于信息提取(information retrieval)。
1.4.5 The Porter Stemmer
(很完整详细的一篇参考)
英语中最常使用的词干提取算法,它把重写的规则分成了几部分:
- 去除变形的后缀(inflectional suffixes): -ies → \rightarrow → -i
- 去除派生后缀(derivational suffixes):-isation → \rightarrow → -ise → \rightarrow → -i
假设:
c c c 代表所有的辅音(consonant),比如 ‘b’, ‘c’, ‘d’
v v v 代表所有的元音(vowel),‘aeiou’
C C C 代表一串连续的辅音:‘s’, ‘tr’, ‘bl’
V V V 代表一串连续的元音:‘o’, ‘oo’, ‘iu’
那么,一个英文单词就可以总结成如下四个结构:
C V C V . . . C CVCV ... C CVCV...C = [ C ] V C V C . . . [ V ] [C]VCVC...[V] [C]VCVC...[V] = [ C ] ( V C ) m [ V ] [C](VC)^m[V] [C](VC)m[V] (一定是VC)
C V C V . . . V CVCV ... V CVCV...V
V C V C . . . C VCVC ... C VCVC...C
V C V C . . . V VCVC ... V VCVC...V
此处, m = m e a s u r e m=measure m=measure 可以理解为词或部分单词组合的度量。
例: TREE = CV = C(VC ) 0 )^0 )0V , m = 0
TREES = CVC = C(VC ) 1 )^1 )1 , m = 1
TROUBLES = CVCVC = C(VC ) 2 )^2 )2 , m = 2
Rule Format:
用于删除或者替换词语后缀的规则可以总结为以下公式:
(condition) S1 → \rightarrow → S2,即在条件condition下,后缀S1可以变成S2。
例: (m>1)EMENT → \rightarrow → null
即当 m>1 的时候,后缀EMENT可以直接删除,如“REPLACEMENT”(CVCVC = C(VC ) 2 )^2 )2, m=2),可以变成“REPLAC”。
Conditions:
- *S - 表示词干是S结尾,也可以用于表示其他字母。
- *v* - 表示词干包含一个元音
- *d - 表示词干结尾是由两个重复辅音组成(比如 -TT,-SS)
- *o - 词干以cvc结尾,且第二个c不是W、X、Y(比如-WIL,-HOP)
条件里面也可以包含与或非。比如:
(m>1 and (*S or *T)) 表示m>1的词干以S或T结尾。
(*d and not (*L or *S or *Z)) 表示以双辅音结尾且不以字母L, S或Z结尾的词干。
维持条件
用词语去匹配最长的S1。
步骤
Step1 去除复数和变形。分步骤a,b,c.
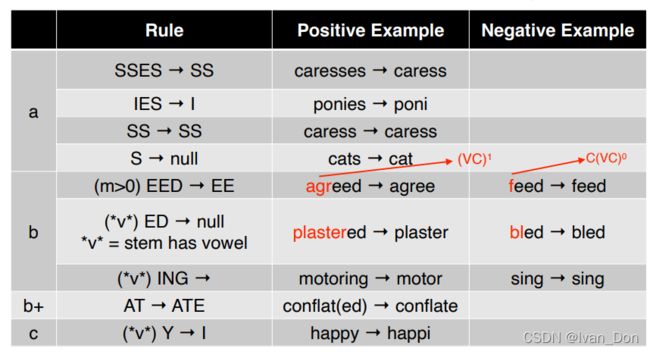
Step2, 3, 4 去除派生形态
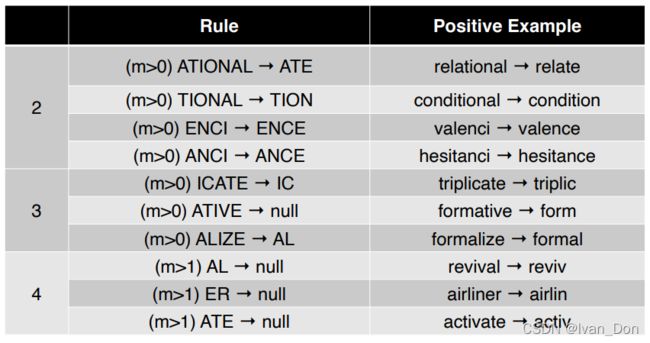
Step 5 整理一下后缀

例:
computational → \rightarrow → comput
step 2: ATIONAL → \rightarrow → ATE: compute
step 4: ATE → \rightarrow → NULL: comput
为什么要纠正拼写错误?
- 拼写错误会造成新的、稀少的类型
- 会扰乱很多语言分析
- 经常会出现在互联网语料库中
- 在网页搜索中,对于用户的提问很重要
通常怎么纠错?
- String distance(Levenshtein,TODO:ucsd的笔记上去看一下伪代码):两个字串之间,由一个转成另一个所需的最少的编辑操作次数。编辑操作包括将一个字符替换成另一个字符,插入一个字符,删除一个字符。一般来说,编辑距离越小,两个串的相似度越大。
- 对错误类型建模(包括语音(phonetic)、打字时产生的missspelling)
- 用n-gram语言模型(后文会讲到)
1.5 Stop Words
定义:一些需要从文档里移除的词语
- 通常以bag-of-word(BOW)的形式出现
- 当语句很重要,移除一些词语就不合适了
如何选择停用词:
- 所有的closed-class(介词、冠词、连词、代词)或者功能行的词:the, a, of, for
- 任何高频出现的单词
- NLTK, spaCy NLP toolkits中有的
1.6 代码
简单的preprocessing
代码链接week2\01-preprocessing
text = '''
COMP90042 Natural Language Processing
The aims for this subject is for students to develop an understanding of the main algorithms used in natural
language processing, for use in a diverse range of applications including text classification, machine
translation, and question answering. Topics to be covered include part-of-speech tagging, n-gram language
modelling, syntactic parsing and deep learning. The programming language used is Python, see
the detailed configuration instructions for more information on its use in the
workshops, assignments and installation at home.
'''
import re
# 消除所有html标签,正则的意思表示匹配"左尖括号,不包含右尖括号的内容,右尖括号",然后将匹配上的东西变成空
text = re.sub("<[^>]+>", "", text).strip()
# 如果这里不写“不包括右尖括号的内容”则会出现< html>xxx