2021MathorCup高校数学建模大数据竞赛解题思路
赛道 B:信息流智能推荐算法中的序列评估问题
随着互联网信息的蓬勃发展,用户在使用互联网应用时面临着信息过载的问题。推荐算法的出现,满足了用户个性化的内容消费需求, 提升了用户获取有用信息的效率,在互联网 APP 里已被广泛应用。信息流作为推荐算法的主要应用场景,是用户触达互联网信息的主要入口,已经完全融入了人们的日常生活中,成为了人们了解世界的主要方式。
图 1 为信息流产品示例。该示例中,用户在执行刷新操作后,推荐系统返回了 K 条推荐结果,构成了一个推荐序列。其中前 4 条推荐内容占满了一个手机屏幕,用户继续下滑可浏览剩余内容。一个推荐 序列由多种内容类型构成,例如,内容 1 为图文内容,内容 4 为视频内容。需要说明的是,推荐系统每次返回的内容条数 K 可以是不固定的,系统可以根据用户的具体请求环境进行动态调整,以此得到最佳的用户浏览体验,如何确定 K 的大小在本题目中不做讨论。
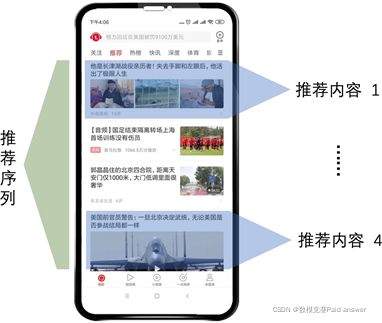
图 1 信息流产品示例
传统推荐算法的核心思想是挖掘被推荐内容与用户兴趣的匹配 关系,以及内容本身的优质程度,选择与用户最相关或者最优质的内容推荐给用户。如图 2 中(a)所示,推荐系统会对单条候选内容进行打分评估,通过内容是否匹配用户兴趣以及内容质量的高低,来预估给用户推荐这条内容后带来的综合收益大小(综合收益通常包含用户是否会点击这条内容,以及用户在这条内容上的浏览时长)。系统 打出的分值则是对每条内容带来的综合收益大小的刻画。然后,系统选择出预估分值最大的 K 条内容,并按照分值从大到小的顺序推荐给用户。这种推荐方式我们称之为 point wise。
但是,研究发现,除了内容本身因素以外,内容之间的排列组合关系,也会影响用户的浏览体验,进而影响推荐收益的大小。例如, 相似内容的高度集中,往往会带来较差的结果反馈,即使它们都高度匹配用户兴趣或者具有较高的内容质量。于是,越来越多的研究集中在如何选择最优的内容排列组合上,而不仅仅是最优的内容上。如图
2 中(b)所示,同样的 ABC 三条内容,按照不同的顺序(A→B→C、
A→C→B、……)推荐给用户,会带来不一样的收益大小。推荐系统需要先根据候选内容生成候选推荐序列,然后对每一个候选序列进行打分评估,系统打出的分值则是对每个序列带来的整体综合收益大小的刻画。最后,系统选择出预估分值最高的一个序列,按照该序列的排列顺序将内容推荐给用户。这种推荐方式我们称之为 list wise。本题目要求参赛者设计数学模型对给定的候选序列进行序列整体收益评估。
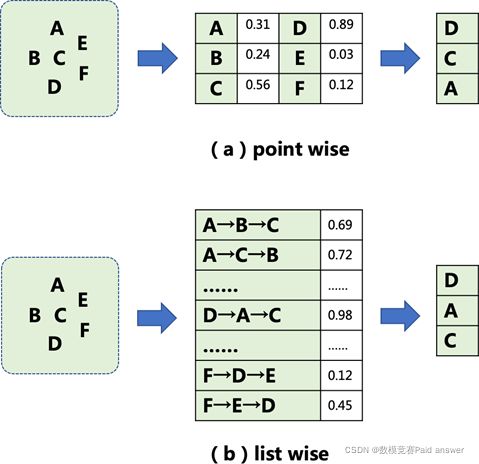
图 2 单内容评估和序列评估
题目提供近一周时间内用户在信息流产品上的曝光历史
(train_data.txt)作为训练集,以供参赛者进行建模分析。附件中 的 train_data.样例.txt 给出了数据格式示例,方便参赛者查看。涉及字段包括:
-
用户 ID:用户唯一标识,例如 1000024368;
-
请求 ID : 用户单次请求推荐服务的唯一标识,例如
500012184_1635188998881_5305;
-
日期:用户单次请求推荐服务的日期,例如 20211026;
-
时间:用户单次请求推荐服务的时间,例如 22(代表晚上 22
点);
- 推荐序列:用户单次请求推荐服务,推荐服务返回的内容列表。内容的排列顺序即为内容的真实推荐顺序,多个内容之间用
“;”分隔,单个内容包括三个字段:内容 ID、用户是否点击
(0 代表未点击,1 代表点击)、用户浏览时长(单位为秒),
多 个 字 段 之 间 用 “ : ” 分 隔 。 例 如133672454001:0:0;508896132:1:111;508969800:0:0;50887
0333:1:10;
同时,题目提供内容的基础属性(doc_info.txt)。附件中的
doc_info.样例.txt 给出了数据格式示例。涉及字段包括:
-
内容 ID:内容的唯一标识,例如 133342615958;
-
内容类型:推荐内容分为视频(video)和图文(news)两种类型;
-
内容类别:内容的一二级分类,例如综艺/内地综艺;
最后,题目提供在训练集时间之后的一部分用户推荐序列作为测试集(test_data.txt),附件中的 test_data.样例.txt 给出了数据格式示例。参赛者需要根据训练集数据预测测试集序列的收益大小。 涉及字段包括:
- 请求 ID : 用户单次请求推荐服务的唯一标识,例如
500012184_1635188998881_5305;
-
用户 ID:用户唯一标识,例如 1000024368;
-
日期:用户单次请求推荐服务的日期,例如 20211026;
-
时间:用户单次请求推荐服务的时间,例如 22(代表晚上 22
点);
- 推荐序列:用户单次请求推荐服务,推荐服务返回的内容列表。内容的排列顺序即为内容的真实推荐顺序,多个内容之间用“ ;” 分 隔 , 单 个 内 容 只 提 供 内 容 ID , 例 如
508681374;133681260394;508767175;508767175;
上 述 完 整 数 据 集 通 过 https://pan.yidian-
inc.com/index.php/s/QB7lhh7YPKLJWfL 进行下载获取。请参赛者对
上述数据进行分析并建立模型,解决以下问题。参赛者需要将最终解决方案以论文方式进行详细阐述,包括主要模型、算法和计算结果, 并以单独文件提交问题 2 的预测结果到竞赛系统中,不改变文件的格式。
问题 1:建立评估推荐序列总点击收益(序列中单条内容的点击量之和)和总时长收益(序列中单条内容的浏览时长之和)的数学模 型,以及如何根据点击收益和时长收益对综合收益进行量化。不同于 评估单个推荐内容收益的数学模型,在序列评估模型设计中,需要详 细阐述如何考虑不同排列组合对收益大小的影响。
问题 2:基于问题 1 设计的数学模型,预测测试集(test_data.txt)中推荐序列的总点击量和总时长(单位为秒), 将预测结果写入
result.csv 并提交。文件包含三列:请求 ID、总点击量、总浏览时长。请求 ID 对应测试集中的请求 ID,总点击量和总浏览时长为预估出的测试集中每个请求 ID 对应推荐序列的点击量和时长之和。附件
result.csv 中已给出的总点击量和总时长为随机生成的示例数据,
参赛者需要将其替换为自己预测的总点击量和总时长值再提交。
问题 3:假设有 N 条候选内容,从中选择长度为 K(N≥K)的最优推荐序列,需要参与收益评估的序列量为A" 。在真实推荐场景中, 由于计算性能的考虑,系统无法对所有可能序列进行收益评估,往往
需要先采用计算复杂度更低的方式对序列集合进行剪枝,圈定出少量 候选序列进行精确收益评估。而剪枝策略的目标是保证候选序列集更 大可能包含最优序列。请详细阐述你的建模思路,以及剪枝策略的精 准度和时间复杂度。
详细解题文档及程序
'''如有问题if you want my model and word'''
'''小编QQ:631183848'''
def __init__(self,board, currentPlayer=1, last_move = [0,0]):
self.board = board #五子棋棋盘
self.currentPlayer = currentPlayer # 执黑还是执白,1是黑,-1是白
self.last_move = last_move # 上一手棋的位置
def getPossibleActions(self):
"""
最开始考虑用以下的代码,但是搜索空间实在是太大了
possibleActions = []
for i in range(len(self.board)):
for j in range(len(self.board[i])):
if self.board[i][j] == 0:
possibleActions.append(Action(player=self.currentPlayer, x=i, y=j))
return possibleActions
"""
# 此处改成在上一手棋周围进行搜索
possibleActions = []
search_size = 1
while len(possibleActions)==0:
for i in range(self.last_move[0]-search_size,self.last_move[0]+search_size+1):
for j in range(self.last_move[1]-search_size,self.last_move[1]+search_size+1):
if i<0 or j<0 or i>=len(self.board) or j>=len(self.board[i]):
continue
if self.board[i][j] == 0:
possibleActions.append(Action(player=self.currentPlayer, x=i, y=j))
search_size+=1
return possibleActions
def takeAction(self, action):
newState = deepcopy(self)
newState.board[action.x][action.y] = action.player
newState.currentPlayer = self.currentPlayer * -1
return newState
def isTerminal(self):
# judge函数引自https://www.jianshu.com/p/cd3805a56585
flag = judge(self.board)
if flag!=0:
return True
# 要注意无处落子的情况
for i in range(len(self.board)):
for j in range(len(self.board[i])):
if self.board[i][j]==0:
return False
return True
'''如有问题if you want my model and word'''
'''小编QQ:631183848'''
def getReward(self):
flag = judge(self.board)