进阶版的Pandas数据分析神器:Polars
相信对于不少的数据分析从业者来说呢,用的比较多的是Pandas以及SQL这两种工具,Pandas不但能够对数据集进行清理与分析,并且还能够绘制各种各样的炫酷的图表,但是遇到数据集很大的时候要是还使用Pandas来处理显然有点力不从心。
今天我就来介绍另外一个数据处理与分析工具,叫做Polars,它在数据处理的速度上更快,当然里面还包括两种API,一种是Eager API,另一种则是Lazy API,其中Eager API和Pandas的使用类似,语法类似差不太多,立即执行就能产生结果。喜欢本文记得收藏、关注、点赞。
【注】完整版代码、数据、技术交流,文末获取

而Lazy API和Spark很相似,会有并行以及对查询逻辑优化的操作。
模块的安装与导入
我们先来进行模块的安装,使用pip命令
pip install polars
在安装成功之后,我们分别用Pandas和Polars来读取数据,看一下各自性能上的差异,我们导入会要用到的模块
import pandas as pd
import polars as pl
import matplotlib.pyplot as plt
%matplotlib inline
用Pandas读取文件
本次使用的数据集是某网站注册用户的用户名数据,总共有360MB大小,我们先用Pandas模块来读取该csv文件
%%time
df = pd.read_csv("users.csv")
df.head()
output
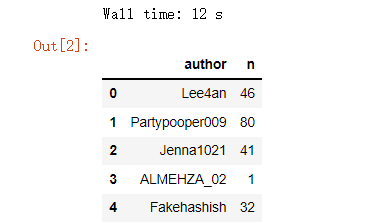
可以看到用Pandas读取CSV文件总共花费了12秒的时间,数据集总共有两列,一列是用户名称,以及用户名称重复的次数“n”,我们来对数据集进行排序,调用的是sort_values()方法,代码如下
%%time
df.sort_values("n", ascending=False).head()
output

用Polars来读取操作文件
下面我们用Polars模块来读取并操作文件,看看所需要的多久的时间,代码如下
%%time
data = pl.read_csv("users.csv")
data.head()
output

可以看到用polars模块来读取数据仅仅只花费了730毫秒的时间,可以说是快了不少的,我们根据“n”这一列来对数据集进行排序,代码如下
%%time
data.sort(by="n", reverse=True).head()
output

对数据集进行排序所消耗的时间为1.39秒,接下来我们用polars模块来对数据集进行一个初步的探索性分析,数据集总共有哪些列、列名都有哪些,我们还是以熟知“泰坦尼克号”数据集为例
df_titanic = pd.read_csv("titanic.csv")
df_titanic.columns
output
['PassengerId',
'Survived',
'Pclass',
'Name',
'Sex',
'Age',
......]
和Pandas一样输出列名调用的是columns方法,然后我们来看一下数据集总共是有几行几列的,
df_titanic.shape
output
(891, 12)
看一下数据集中每一列的数据类型
df_titanic.dtypes
output
[polars.datatypes.Int64,
polars.datatypes.Int64,
polars.datatypes.Int64,
polars.datatypes.Utf8,
polars.datatypes.Utf8,
polars.datatypes.Float64,
......]
填充空值与数据的统计分析
我们来看一下数据集当中空值的分布情况,调用null_count()方法
df_titanic.null_count()
output

我们可以看到“Age”以及“Cabin”两列存在着空值,我们可以尝试用平均值来进行填充,代码如下
df_titanic["Age"] = df_titanic["Age"].fill_nan(df_titanic["Age"].mean())
计算某一列的平均值只需要调用mean()方法即可,那么中位数、最大/最小值的计算也是同样的道理,代码如下
print(f'Median Age: {df_titanic["Age"].median()}')
print(f'Average Age: {df_titanic["Age"].mean()}')
print(f'Maximum Age: {df_titanic["Age"].max()}')
print(f'Minimum Age: {df_titanic["Age"].min()}')
output
Median Age: 29.69911764705882
Average Age: 29.699117647058817
Maximum Age: 80.0
Minimum Age: 0.42
数据的筛选与可视化
我们筛选出年龄大于40岁的乘客有哪些,代码如下
df_titanic[df_titanic["Age"] > 40]
output

最后我们简单地来绘制一张图表,代码如下
fig, ax = plt.subplots(figsize=(10, 5))
ax.boxplot(df_titanic["Age"])
plt.xticks(rotation=90)
plt.xlabel('Age Column')
plt.ylabel('Age')
plt.show()
output
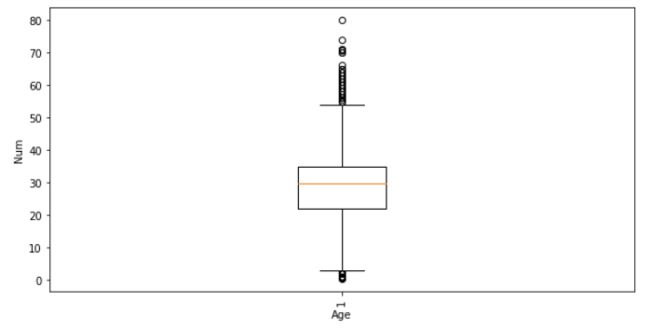
总体来说呢,polars在数据分析与处理上面和Pandas模块有很多相似的地方,其中会有一部分的API存在着差异,感兴趣的童鞋可以参考其官网:https://www.pola.rs/
推荐文章
-
李宏毅《机器学习》国语课程(2022)来了
-
有人把吴恩达老师的机器学习和深度学习做成了中文版
-
上瘾了,最近又给公司撸了一个可视化大屏(附源码)
-
如此优雅,4款 Python 自动数据分析神器真香啊
-
梳理半月有余,精心准备了17张知识思维导图,这次要讲清统计学
-
年终汇总:20份可视化大屏模板,直接套用真香(文末附源码)
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
