手把手实操系列|信贷风控中的额度管理和额度模型设计
序言:
如今的个人信贷行业步入合规发展阶段后,额度管理和差异化定价成为金融机构是否能最大化盈利的核心竞争力,其中额度管理包括贷前阶段的授信额度,贷中阶段的提额,降额等,本文将着重讲解这两个阶段的额度设计和额度模型开发,适用的场景为个人零售信贷/小微企业等的中小额现金贷/消费贷产品。
首先介绍下额度的分类,市面上的信贷产品可分为循环贷和非循环贷,循环贷的额度用户能多次支用,可以存在多笔订单在贷的情况,用户支用及归还贷款,额度都会相应的减少和增加。而非循环贷的额度用户只能支用一次,例如给你5000额度,支用时就一次性把5000全取出来,很多机构的非循环贷产品是单笔在贷的模式,即当前借款的订单全部还清后才能重新授信借下一笔。可以看出非循环贷是没有贷中提降额场景的,所以本文讲的内容更适用于循环贷产品。
本次整体的内容较多,除了公众号上的内容更会在知识星球上为大家提供本次内容所涉及的实操数据与代码,手把手实操带领大家领略整个额度管理和额度模型的内容,本次整体目录如下:
PART 1.授信阶段的额度管理
授信额度的设计步骤
1.1.额度范围的设计
1.2.差异化定额设计
1.3.增信额度和人工额度设计
1.4.额度测算方式
PART 2.贷中阶段的额度管理—提额降额
2.1.主动提额
场景①:对还款表现良好且借贷需求高的用户进行提额
场景②:对授信成功但未支用的用户进行提额
场景③:对沉默/流失用户进行提额
2.2.降额或冻额管理
PART 3.谈谈额度模型设计的难点
PART 4.实操—额度模型中相关预测模型开发(数据集+代码内容)
在整个信贷业务流程开发中,额度管理与额度模型的设计都是一个重要的流程节点,特别是在整体信贷环节中白热化竞争的当下,千人千价,差异化的额度授信策略,就是在众多金融机构中脱颖而出的制胜点。
本文也将围绕着以上大纲内容就额度管理与额度模型设计,介绍实际工作中的落地应用方法。
以下为正文部分:
首先介绍下额度的分类,市面上的信贷产品可分为循环贷和非循环贷,循环贷的额度用户能多次支用,可以存在多笔订单在贷的情况,用户支用及归还贷款,额度都会相应的减少和增加。而非循环贷的额度用户只能支用一次,例如给你5000额度,支用时就一次性把5000全取出来,很多机构的非循环贷产品是单笔在贷的模式,即当前借款的订单全部还清后才能重新授信借下一笔,所以可以看出提降额场景的更适用于循环贷产品。
Part1.授信阶段的额度管理
授信额度是给用户的最大借款额度,授信额度作用在贷前授信阶段的尾部,授信对象即为没有命中贷前策略的用户,有些场景下授信额度还要做人工复核。

授信额度的设计有以下几步:
1)确定额度的上下限,即额度范围
2)在额度范围内做差异化定额
3)在差异化额度基础上再加增信额度,人工额度等补充
1.1.额度范围的设计
额度范围的设定要考虑到三个因素,一是产品的定位,例如小额产品额度一般定在1千-1万之间,中等额度产品在1万-10万之间,二是目标客群的风险及还款能力,如果产品面向的是比较下沉的蓝领,农民群体,额度的上限会跟他们的平均收入相关,也会考虑到这些人的逾期风险较高,额度会给的比较低。三是同行竞争对手的参考,比如A公司给予的平均额度在8000左右,那B公司在设计同类产品的额度时,也会参照A公司的额度,如果额度比A公司低很多,用户可能就偏向选择A公司的产品造成用户流失。额度范围也可以做差异化,例如对高中低三类不同风险的用户,设置不同的额度范围。
1.2.差异化定额设计
额度的差异化主要考量用户的还款意愿和还款能力这两个维度,最常见的方式就是做交叉矩阵了,两个维度交叉来细分每个客群的额度系数或额度值(如下图)

衡量还款意愿一般用模型来解决,因为是在贷前阶段,所以设计模型的思路和A卡类似,两者的异同有以下几点:
1)目标Y的定义,两者都用首笔订单的逾期表现来界定好坏用户。
2)数据的使用,因为额度模型是在授信流程最后阶段使用,所以用的数据相比那些前置A卡更丰富,建模的特征偏向于多头,信用历史,消费支付等行为。
3)使用的方式,A卡放在授信或首笔支用环节,前置或后置都可以,额度模型就固定使用在授信最后一步,有些机构也会把额度模型当做A卡使用,先用模型过滤掉一部分人群,再对通过人群划分额度,这样额度模型也会作为一条拒绝策略。
4)模型评估角度,A卡因为是做拒绝策略,所以评估时看重尾部Lift表现,额度模型要做差异化,因而更看重整体的排序性,即对人群分组后badrate的单调性,且组别之间的badrate要有明显的区隔。
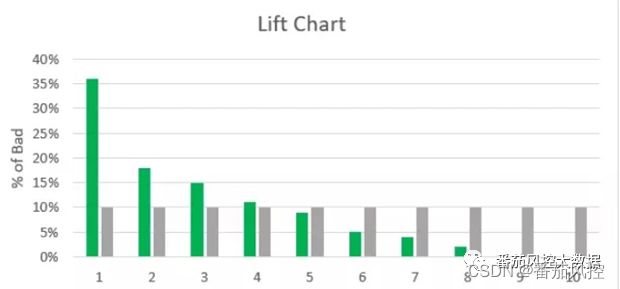
这里介绍下lift这个指标,lift(提升度)衡量的是一个模型分(或特征)对坏用户的预测能力好于随机划分的倍数。通常计算lift时需要先对模型分进行分箱,然后计算每个箱体中的badrate,再除以随机划分(整体)的badrate即为lift值。
计算公式为 lift=箱体的badrate/整体的badrate。
下面举个例子讲一下,这张图里将一份样本根据模型分从低到高等频分为10份,然后计算每份样本经过模型预测的badrate(绿色)和随机划分的badrate(灰色),两者通过对比发现,随机划分的badrate近似等于整体的badrate,每组随机划分的badrate为10%,然后看第一组模型预测的badrate为 35%,那第一组的lift为35%/10% = 3.5,说明第一组中,模型预测出的坏用户数是随机的3.5倍,比随机划分更加精准的识别出了坏用户。前面几组模型预测的badrate都比随机要高,lift都是大于1的,后面几组要比随机的低。Lift都是小于1的,可看出模型的lift呈单调变化,说明分数越低,用户坏的概率越大,模型对好坏用户有一定的区分能力。
还款能力维度比较看重用户的收入情况,但收入作为比较私密的信息,很难获取到真实的数据,如何判断收入有几种常见的方式:
1)开发收入预测模型,经过人工打标等方式积累样本,用多头,消费支付等数据做收入预测。这种方式数据积累的周期较长,但通过模型预测有比较好的排序性。
2)用社保,公积金缴纳基数判断收入高低,有些公司会全额缴纳社保公积金,所以社保/公积金的月缴纳额如果很高,大概率收入也高。但这种方式有两个缺点,一是数据覆盖率低,尤其对于下沉人群,二是判断不太准,因为很多公司不管工资高低,都是按最低基数交的。
3)调用三方的收入数据,相对社保/公积金数据会准一些,不过三方的收入数据是比较贵的,单个调用基本在2元以上,数据成本较高。
我们的建议是在业务初期,可以调用三方数据来判断收入,等积累一定的样本后,再开发收入预测模型。
不同产品对还款意愿,还款能力两个维度的侧重点也有区别,小额产品的人群比较下沉,坏账风险高,所以更关注还款意愿,像一些机构都不会考虑收入情况,直接用逾期风险模型做额度差异化。额度大的产品客群优质一些,且上限较高,会比较看重收入,职业这一类信息,对高收入,工作稳定的人也会重点照顾,给予更高的额度。
1.3.增信额度和人工额度设计
接下来说一下增信额度和人工额度,增信就是用户主动提供其他数据来提升自己的信用等级,增信触发的节点可以放在授信填写资料的时候让用户上传信息,也可以放在授信通过后的阶段(提额阶段),引导用户补充其他信息来提升额度。常见的增信方式有以下几种:
1)学历增信:用户上传学历证书,人审通过学信网核查学历是否真实
2)社保增信:用户授权机构查询自己的社保数据,然后跑对应的社保策略,一般对社保增信是有门槛的,例如要求社保目前为正常缴纳状态,且连续缴纳月份大于3个月,如果机构获取到的社保数据比较丰富,还可以做个社保增信模型对增信额度做差异化。
3)公积金增信:和社保增信类似,相比于社保,公积金还有提取,贷款的记录,反映的信息更加丰富,如果用户既有社保又有公积金,那资质会更好一些。
4)信用增信:用户授权查询人行征信数据,人行征信相比三方征信更有权威性,可信度更高,不过前提是机构要有接人行征信的资质。
5)收入资产增信:用户上传能直观反映还款能力的信息,例如房产证明,收入证明,人审也需要对其核查真实性。
增信额度也会做差异化,例如不同的学历给予不同的额度,想做的精细化一点,学历也可以跟信用模型做交叉矩阵。增信的用户资质更好,在后面的支用,营销,贷后等环节也可做差异化管理。
人工额度是用户不满意机审给到的授信额度,主动发起人审来重新给出额度,发起人审前要过一遍审核门槛的策略,因为人审的资源是有限的,我们只对资质比较好的用户进行审核。审核员会对用户评估其工作,收入,借贷历史,贷款用途等情况来判断是否通过及给出多少的额度,若在审核时发现用户有风险,也会修改机审授信通过的结果将其拒绝。
1.4.额度测算方式
通过以上内容的介绍,我们引出额度测算的几种常见方式:
1)授信额度 = min[max(基础额度*风险系数,额度下限)+增信额度,额度上限],若有人工额度,则以人工额度为最终生效额度,风险系数用规则或模型来定。
2)授信额度 = min[max(交叉矩阵定额,额度下限)+增信额度,额度上限],若有人工额度,则以人工额度为最终生效额度,交叉矩阵可以用规则+模型,或者用双模型。
3)授信额度 = min[max(单模型差异化定额,额度下限)+增信额度,额度上限],若有人工额度,则以人工额度为最终生效额度。
最后还有一个额度有效期的概念,考虑到大部分用户的资质在短期内不会发生显著变化,额度有效期会设置的比较长,一般设为1年,有些机构甚至干脆不设有效期。有效期会在前端展示给用户,额度过期后用户需重新跑授信流程来定额度。
Part2.贷中阶段的额度管理—提额降额
提额可以提高信贷资产和收益,也能巩固用户的忠诚度,减少用户流失,降额可以控制风险,减少潜在的坏账损失。下面先介绍提额的方式和流程,提额分为主动提额和被动提额,主动是金融机构发起,被动是用户自己发起,被动提额就是上文提到的增信和人工额度,这里不再赘述。
2.1.主动提额
提额这个模块有这样一些要素:提哪些人?提多少额度?提额的节点?提额的时效性?怎么评估提额效果?根据以上这些问题,我们将具体的细节拆分到以下三个场景中进行阐述,分别是:
场景①:对还款表现良好且借贷需求高的用户进行提额
场景②:对授信成功但未支用的用户进行提额
场景③:对沉默/流失用户进行提额
以上相关内容,更详细的细节,可以优先移步知识星球,参见详细内容。在以上场景中,我们跟大家介绍了,应该关注跟关注哪些用户来进行提额。如何制定筛选提额用户的规则。
另外详细的提额中也分有临时额度和非临时额度,这两个额度应该如何设置。最后在设置完相关的额度策略后,怎么评估制定的策略效果如何?这里我们需要制定一个额度策略效果评估的要点:
以上策略行文要点,都已同步至知识星球,星球同学可直接前往学习查阅。
另外本文中剩余部分,第三与第四部分会介绍:
Part3. 谈谈额度模型设计的难点
Part4.实操—额度模型中相关预测模型开发
第三部分(Part3部分),我们会介绍目前在市面上额度模型开发的情况,比如与违约预测模型相比较,额度模型开发有哪些需要注意的要点;以及额度模型目前整体上开发而言,为什么说效果会较难衡量?
综上这些要点,我们在实操中有哪些可以改进的操作要点等。
第四部分(Part4部分),第四部分我们在行文实操中,本次为大家带来额度设计过程中,与之相关的收入和风险相关的数据,来预测与额度相关的数据情况。
本次我们为提供了为一份打标好的数据集,样本量35718,包含:
①用户id(user_id),
②授信回溯时间(target_date),
③Y标签(label),
④300个特征(var_1…var_300)
特征主要是一些三方的多头,负债,消费支付数据等,能从侧面反映用户的收入情况。模型的目标是预测用户是否为低收入群体,标签的数据来源为信审人员根据用户反馈信息及自身经验所评估的收入。
以下为部分的实操截图:

【以上为额度模型开发细节截图,详情见知识星球实操内容】
最后在模型开放后,如何使用额度模型来预测收入,我们也给与了相关的参考方法:
【详情见知识星球实操内容】
关于所提到的额度管理与额度模型相关的实操内容,教研组的童鞋已经同步相关的内容至知识星球后台,查看完整版本,欢迎星球同学移步到知识星球查收完整内容:

另外,此完整版本配套的数据集+代码内容,也欢迎参与本周的知识星球《星球打榜赛的作业》,相关的答案也将在本周末内提供给大各位同学实际相关实操练习:

…
~原创文章