Linux 权限
目录
find指令:
find -name:按照文件名查找文件
which命令:
whereis
grep指令:
grep -i忽略大小写:
grep -v表示反转的意思:
wc:wordcount的缩写
sort:排序:
uniq:去重
zip指令
unzip指令:
tar指令。
bc指令
uname 指令
uname -a
Tab热键
ctrl+x表示保存:
ctrl+x终止前台的异常程序
ctrl+r
ctrl+d ——退出当前用户,退出一层。
\反斜杠
ctrl+c退出
shutdown
lscpu
lsmem
df -h
who
命令行解释器:
shell
扩展知识
Linux权限
1:基本的具体用户认识:
用户级切换
find指令:


find -name:按照文件名查找文件
例如:
我们的文件排布如图所示:

我们的根目录下有两个test.txt文件,假如我们要查找test.txt文件,我们可以这样操作:
![]()
执行指令之后:

我们可以发现,find -name查找出了在根目录下的全部的test.txt文件,查找的方式是递归,我们进行证明:
我们可以多插入几个test.txt文件:

我们一顿操作下来,出现了好多test.txt文件,假如我们的查找方式是递归时,我们查找的顺序如图所示:

我们进行证明:

我们的顺序完全相符,证明:find -name 在查找文件名时,进行的是递归式的拷贝。
find指令不仅要访问内存,还要访问硬盘,这个就决定了find命令的效率并不会太高。
which命令:
which:搜索用过的指令在什么路径下:
例如:

which+指令搜索对应指令的地址。
我们用以下ll指令:查看对应目录的文件属性:

我们可以发现:显示的文件名既有白色的,也有蓝色的,原因是什么?
我们可以通过which解答:

其中,alias表示对一个命令进行重命名。color=auto'就是文件有颜色的由来。
![]()
这串代码表示显示文件的路径。
我们知道了如何进行重命名,所以我们也可以自己写重命名代码:
![]()
我们把zhangsan重命名为我们的ll操作:
我们再输入zhangsan对应的结果就是这样:

which指令的查找范围是比较小的。
whereis
whereis也是一种查找执行,这种查找指令的范围是:
which
whereis是一种近似匹配的方案:
例如:
我们要查找指定的文件名test.c

我们查找除了三个对应文件,但是这三种文件名都与test.c不同,只是文件名近似相等。
所以whereis是一种近似匹配的方案。
grep指令:
grep是一种文本行过滤工具。
默认会匹配文本中的关键字,匹配上的进行行显示:
我们新建了一个test.txt文件,文件中有一万行内容
![]()
我们显示文件内容:

我们使用grep工具:
![]()
文本文件中只有一个包含9999的文件,所以只显示了一个文件。
假如我们显示999呢?

这里就会显示所有含有999的文件。
grep -n ‘文本’ +对应文件表示显示行号:

注意:我们这里显示的行号是源文件中对应文本的行号。
grep默认是区分大小写的
例如:我们对test.txt文件中的部分内容进行修改:
我们输入vim test.txt表示对test.txt文本中的内容进行修改:

我们把其中的两项内容进行修改。
我们使用grep找‘bit’
如图所示:
![]()
如图所示,我们仅仅显示了小写的bit,我们再尝试大写的BIT

由此可见,grep默认是区分大小写的。
grep -i忽略大小写:
-i表示的ignore,忽略大小写:
例如:

这样我们既显示了小写,也显示了大写。
grep -v表示反转的意思:
例如:
假如我们要求没有文件名没有‘99’的全部文件,我们可以这样写:

这样,我们显示的就是文件名不包含‘99’的全部文件。
这些 -i -v -n可以任意组合
例如:假如我们查看不分大小写,显示行数,除文件名为’99‘的全部文件对应的内容:

对应的结果:

假如我们要求这些文件一共有多少行?我们引入一个命令wc
wc:wordcount的缩写
我们可以采用管道的知识:
![]()
![]()
我们对思路进行分析:
我们使用grep来查看文件,我们要看的是test.txt中不带有'99'的文件,显示行数,并忽视大小写的文件,将这些文件通过管道传递到另一端,另一端的wc -l对这些文件进行操作。-l表示以行的形式显示。
sort:排序:
例如:我们首先来创建一个文件file.txt,对文件内容进行编辑:

我们首先使用cat看文件内容:
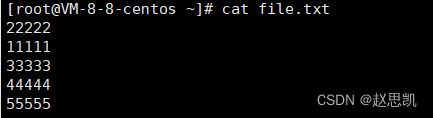
sort排序的方式是按行排序,以ascii码的形式进行排序的方式:
例如:我们对file.txt文本内容进行排序:

可以发现,ascii码相对小的放在上面,ascii码相对大的放在下面。
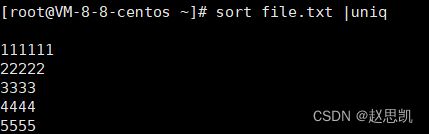
uniq:去重
我们使用vim对文件的内容进行修改,修改为这样:

我们可以发现,文本中有许多相同的项目,我们如何把这些相同的项目去掉呢?
uniq是unique的简称,作用是去掉重复项

为什么最后一行的四个5没有被去掉呢?
原因是这样:因为我们的uniq去重去的是相邻且相等的内容,对于不相邻的即便内容相等也不去重。
我们该如何处理呢?
我们可以先对文件内容进行排序,再进行去重(通过管道)
zip指令
zip指令是压缩
例如:
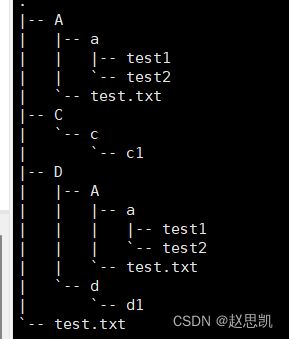
我们对应的根目录的树状结构

我们尝试对目录A进行打包压缩:
![]()
A表示我们要压缩的文件名,my.zip表示我们压缩A之后对应的压缩文件的名称,zip指令表示压缩。
这个0%表示压缩文件的大小占源文件的大小的0%
unzip指令:
unzip指令是解压缩:
接着我们的zip指令:我们刚刚把目录a压缩成为了名称为my.zip的压缩文件
我们使用解压指令:
![]()
表示我们对my.zip压缩文件进行解压。
我们解压之后发现目录A对应的树目录依旧什么都没有,原因是什么?
zip默认对一个目录进行打包压缩时,只会对目录文件进行打包压缩。
所以我们要把一个文件全部压缩的话需要加 -r

这时候相当于我们把A中的文件递归式的全部压缩到my.zip文件中了。
为什么这里的stored全部都是0%
原因是我们创建在目录A中的都是文件夹,没有实质的文件,所以所占空间为0字节,解压后也依然时0字节,所以是0%
zip -r 你的压缩包(自定义) dir(要打包压缩的目录)
unzip 你的压缩包(自定义) --在当前目录进行解包解压的功能。
文件越大,压缩效果越好。
假如我们要把压缩包解压到指定的文件夹:
unzip 文件包 -d 对应的路径
例如:

我们举一个例子。
我们对应的根目录:

我们对A目录进行压缩,压缩文件为my.zip

我们再进行解压,我们把my.zip压缩到我们的D目录中。
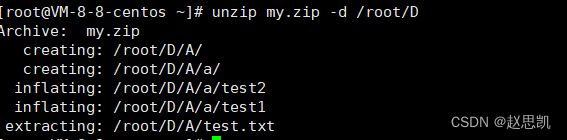
我们就会把对应的路径也显示出来。
为什么要打包和压缩呢?
答:打包是把对应的文件放在一起,压缩是指把对应的文件进行压缩。



总结:为什么要进行打包和压缩:
1:压缩文件的大小,提升下载的效率
2:把多个文件转换成一个文件,防止文件丢失。
tar指令。
tar:打包/解包,不打开它,直接看内容。
例如:
我们对应的根目录:
假如我们要对A目录进行压缩,我们可以这样写:
![]()
我们对这行代码进行分析:tar表示压缩或解压,如何区分,后面的三个字符可以帮我们区分,c对应的是创建压缩文件,所以我们要进行压缩,z表示以zip的算法进行压缩,f表示我们要压缩的文件名, my.tgz表示压缩后的压缩文件,我们的A表示我们要压缩的文件名。
假如我们要进行解压,我们这样写就可以了:
![]()
我们把c换成x即可,c对应的是创建压缩文件,x则对应的解压。
所以:
假如我们要看解包的具体过程,我们加一个v即可,例如。
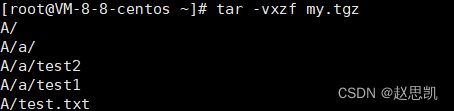
这个v的位置不做限制,只要能够保证f在最后即可。
tar -tf表示不解压的情况下看压缩包内部的文件属性:
例如:

-t:表示不打开压缩文件,直接查看压缩包内的文件内容。
-v:解压或者压缩时,同步显示压缩文件列表。
我们使用tar怎么把文件解压到指定目录下。
例如:

上图是我们对应的根目录,假如我们想要解压使用tar解压,把my.tgz解压到根目录下,我们可以这样写:

我们对这行代码进行分析:-xzvf,x表示的意思是解压,z表示的意思是以zip的算法进行解压,v表示显示解包过程, -C表示解压到指定目录。~表示家目录。
bc指令
bc指令就是Linux中的计算器。
例如:

我们输入bc,下面的这些是对bc的注解,我们忽略。
接下来,我们就可以使用计算机了:
我们输入2+6
![]()
![]()
我们再输入1.2*12

由此可见,该计算器不仅能够计算整型数据,也能够计算浮点型数据。
我们输入quit退出计算器。

bc还支持管道,例如:
我们知道echo是把我们输入的字符打印到屏幕上:
我们可以通过echo和bc来支持我们把计算输入的字符顺便打印到屏幕上
例如:
uname 指令
我们输入uname在Linux进行尝试:
![]()
uname显示计算机或操作系统相关的知识:
![]()
uname -a
uname -a可以把我们的机器属性全部显示出来:
例如:

3表示主版本,10表示次版本,0表示修订次数,el是centos的简称,el7就是centos7的意思。
×86_64是计算机体系结果,也就是cpu架构,简称×64
uname -r可以查看内核版本。
![]()
Tab热键
我们输入whi:
按Tab
![]()
我们可以显示全部以whi开头的指令。
我们再举一个例子:
我们输入a
再按Tab

我们会把所有以a开头的指令全部显示出来。
tab的自动补齐:
例如:
![]()
我们可以发现以whi开头的指令一共有3个,但是以whic开头的指令有且只有一个which,所以我们输入whic就锁定了which
我们输入whic
![]()
然后直接按Tab
![]()
然后就会对whic进行自动补齐。
ctrl+x表示保存:
例如:
我们创建一个文件test.c
![]()
然后我们使用nano对文件内容进行修改:
![]()
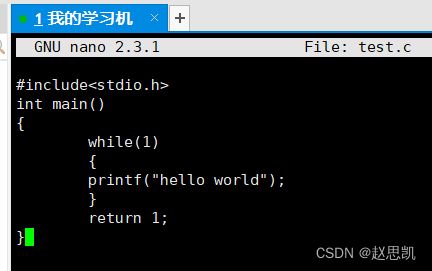
我们对文件内容进行如下修改:
我们按CTRL+X

我们输入y
![]()
我们来查看文件的内容:

我们可以发现文件内容的确完成了修改。
ctrl+x终止前台的异常程序
例如:我们刚刚在test.c写了一个死循环程序,我们进行运行编译:
![]()

死循环打印hello bit,我们可以按ctrl+c来终止异常程序。
ctrl+r
搜索历史命令,左右选中:
例如:
我们按ctrl+r
我们输入l

系统就会自动给我们匹配一个我们使用过的指令ll。
我们输入t
![]()
系统给我自动匹配了tree。
按左右即可选中。
ctrl+r的原理是输入片段找整体。
ctrl+d ——退出当前用户,退出一层。
例如:
我们的ctrl+d会直接让我们的当前用户下线:
\反斜杠
可以起到换行的作用:
例如:

对应的信息:

ctrl+c退出
例如:

我们使用续行,直接按ctrl+c

直接就退出了。
shutdown
作用是关机:

这个我们就不再做实验了。
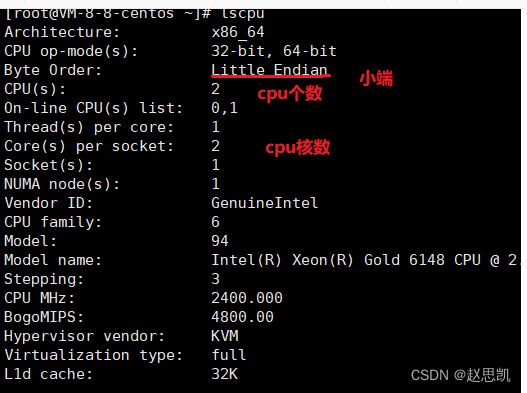
lscpu
查看cpu的属性:
lsmem
可以查看内存属性:

df -h
可以查看磁盘结构

who
可以用来查看谁登录了我的账户:
![]()
因为我们只创建了一个用户,所以我们只能查看一个。
命令行解释器:
例如:我们看到的命令行,指示符,以及我们输入的指令。
命令行解释器其实是一个外壳程序shell
我们在linux环境下能看见的这些字符都是命令行解释器。
我们对shell进行理解:
shell
我们可以这样理解:人并不善于和操作系统打交道,但是人善于与shell外壳打交道,于是,我们人就通过shell外壳,来对操作系统进行处理。
我们把对应的指令传递给shell,让shell来处理操作系统,操作系统把结果交给shell,shell再把结果返回给我们的用户。
但是shell外壳还有另外一种作用,那就是保护操作系统,假如用户输入的代码是违法的或者是乱码,shell为了保护操作系统,就会拒绝执行用户的指令。
shell在执行指令的时候是通过派生子进程的方式来执行用户的指令,shell本身并不执行。
原因是shell外壳是唯一的操作系统和用户之间的桥梁,假如我们的指令致使shell外壳损坏,那我们就无法访问操作系统了,所以我们要派发子进程。
总结:shell外壳的作用有两种
1:方便用户访问操作系统
2:同时也防止用户误操作导致操作系统的损害,来保护操作系统。
扩展知识
我们日常口中说的Linux其实就是Linux操作系统和一个shell外壳组成的。
这个Linux操作系统也可以叫做Linxu内核。
我们所熟知的windows图形界面也Linux的命令行解释器本质上都是外壳程序。
注意:Linux shell命令行外壳和win图形化界面是兄弟关系。
不存在把windows图形化界面转换为命令行再传递给操作系统,这两种外壳是互不相关的。
我们平常熟知的安卓和鸿蒙
安卓:操作系统使用Linux内核,外壳程序写手机图形化界面库。
鸿蒙:操作系统使用Linux内核,外壳程序创建新的。
我们使用的centox 7使用的外壳是bash外壳。
Linux权限
1:基本的具体用户认识:
root用户:超级管理员
普通用户:受权限约束的用户。
用户级切换
su能够切换用户:
假如我们想要从普通用户切换成root,我们直接输入su或su -
然后输入root的密码即可。
su 和su -的区别是:


su只是切换用户,但是su -相当于让root重新登陆了,对应的路径就是root的家路径。
假如我们要从root用户转换为普通用户
1:我们可以直接exit退出。

或者我们可以su+用户名直接切换对应的用户,不需要输入密码。
总结:从普通用户变成root使用su和su -即可,需要输入密码
从root用户变成普通用户直接su+用域名即可,不需要输入密码。