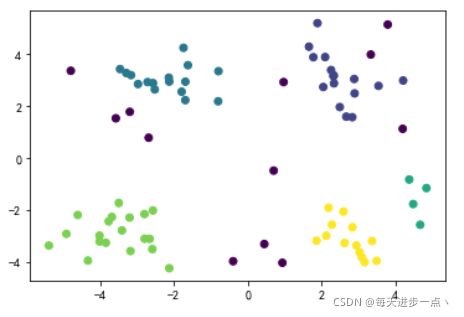
【机器学习】DBSCAN聚类算法
DBSCAN聚类算法
DBSCAN(Density-Based Spatial Clustering of Applications with Noise,具有噪声的基于密度的聚类方法)是一种基于密度的空间聚类算法。
1.基本概念
- 核心对象:若某个点的密度达到算法设定的阈值则其为核心点。(即r邻域内点的数量不小于minPts )。其中minPts是自己设定的点的个数,即以r为圆心的圆包含的点多余minPts,那么它就是一个核心对象
- ε-邻域的距离阈值∶设定的半径ε。
- 直接密度可达︰若某点p在点q的ε 邻域内,且q是核心点则p->q直接密度可达。可以理解为p在核心点q的圆内。
- 密度可达∶若有一个关于点的序列q0、q1、…qk,对任意qi->qi-1是直接密度可达的,则称从q0到qk密度可达,这实际上是直接密度可达的“传播”。
- 边界点:属于某一个类的非核心点,即它的邻域内的点少于minPts。
- 噪声点:不属于任何一个类簇的点,即任何一个核心点都不包括这个点,从任何一个核心点到这个点都是密度不可达的。
需要指定的参数:阈值minPts以及半径ε。
可用于异常点的检测。
2.参数选择
半径r:找突变点
K距离:对于数据集P={p(i);i=0,1,…n},计算点P(i)到P的子集S的距离并从小到大排序,找到距离突变的点,则认为突变点前面的就离了比较合适。
minPts:K距离中的K值,一般取小一点,多次尝试
3.算法思路
对于数据集D:
首先将所有数据都标记为unvisited;
DO
任取一个未标记数据点p:
将p标记为visited;
if p是核心点:
将其添加到新的簇C中;
将p邻域中的每个点添加到N中;
for p' in N:
if p'是 unvisited:
将p'标记为visited;
if p'是核心点:
将p'邻域内的点添加到N中;
if p'未被分配到簇中,将其添加到簇C中;
else p为噪声,将其添加到-1簇中;
Until 没有unvisited的对象
4.优缺点
优点:
- 不需要指定簇的个数
- 只需要两个参数(半径r和阈值minPts)
- 擅长找到离群点(用于异常值监测)
缺点:
- 高维数据有点困难
- 参数难以选择
- SKlearn中效率很慢
5.python代码实现
数据集
1.导入相关包
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
2.读取数据
data = pd.read_csv("./data/dataset1.csv",header=None)
data = data.values.tolist()
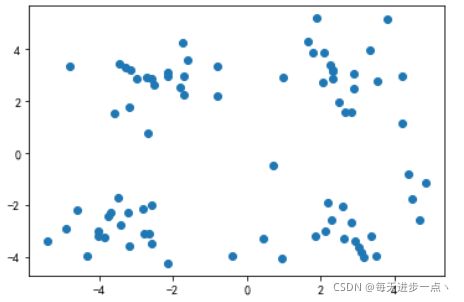
3.画出原始图像
# 画出原始图像
fig, ax = plt.subplots()
plt.rcParams['font.sans-serif'] = ['SimHei']
plt.rcParams['axes.unicode_minus'] = False
plt.scatter([i[0] for i in data], [i[1] for i in data])
plt.show()
4.计算欧氏距离
'''
计算欧氏距离
'''
def calDist(a,b):
a = np.array(a)
b = np.array(b)
dist = np.sqrt(np.dot((a-b),(a-b).T))
return dist
5.获取某个点邻域内的点的个数以及列表
'''
获取某个点邻域内的点的个数以及列表
'''
def findNeibors(p,epsilon,data):
neibors = [] #用于存储这个点邻域内的点
for q in data:
dist = calDist(p,q)
if dist <= epsilon:
neibors.append(q)
cnt = len(neibors)
return cnt,neibors
6.返回一个未被选择点.若没有未选择点,返回-1
'''
返回一个未被选择点.若没有未选择点,返回-1
'''
def getUnvisited(selected):
for i in range(len(selected)):
if selected[i] == 0:
return i
return -1
7.判断是否将q添加到簇中
'''
判断是否将q添加到簇中
'''
def isInClusters(q,all_clusters):
for clusters in all_clusters:
if q in clusters:
return True
return False
8.设置参数
# 设置参数
minPts = 3
epsilon = 1.0
9.算法实现
'''
DBSCAN算法
'''
def DBSCAN(epsilon,minPts,data):
all_clusters = [] # 所有簇
noiseList = []
selected = [0 for i in range(len(data))]
while getUnvisited(selected) != -1:
C = [] # 保存同一个簇的点
i = getUnvisited(selected) # 找未选择点
selected[i] = 1 # 修改选择状态
p = data[i]
cnts,neibors = findNeibors(p,epsilon,data) #获取邻域内的点
if cnts > minPts: # p为核心点
C.append(p) # 将p添加到簇中
for q in neibors: # 遍历核心点p的邻域点
if selected[data.index(q)] == 0:
selected[data.index(q)] = -1
q_cnt,q_neibors = findNeibors(q,epsilon,data)
if q_cnt > minPts: # 如果q是核心点,将其邻域内的点添加到neibors中
for i in q_neibors:
if i not in neibors:
neibors.append(i)
#判断q是否已经添加到簇
if not isInClusters(q,all_clusters):
C.append(q)
else:
noiseList.append(p)
if len(C) != 0:
all_clusters.append(C) #找完一个簇,添加到all_clusters中
all_clusters.append(noiseList) # 将噪声点添加到all_clusters中
return all_clusters
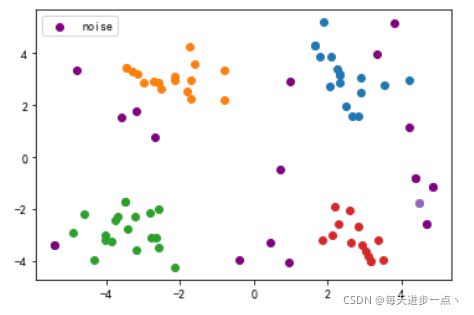
10.运行并展示聚类结果
if __name__ == "__main__":
all_clusters = DBSCAN(epsilon,minPts,data)
fig,ax = plt.subplots()
n = len(all_clusters)
for i in range(len(all_clusters)):
cluster = all_clusters[i]
if i!= len(all_clusters) -1:
ax.scatter([j[0] for j in cluster],[j[1] for j in cluster])
else:
ax.scatter([j[0] for j in cluster],[j[1] for j in cluster],label="noise",c='purple')
plt.legend()
plt.show()
调库实现DBSCAN
from sklearn.cluster import DBSCAN
db = DBSCAN(eps=epsilon,min_samples=minPts)
db.fit(data)
plt.scatter([i[0] for i in data],[i[1] for i in data],c = db.labels_)
plt.show()