20 分钟学会 DBSCAN 聚类算法
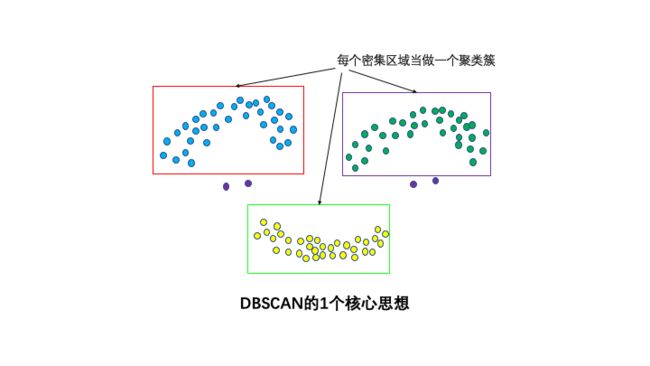
大家好,DBSCAN是一种非常著名的基于密度的聚类算法。其英文全称是 Density-Based Spatial Clustering of Applications with Noise,意即:一种基于密度,对噪声鲁棒的空间聚类算法。直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。
DBSCAN算法具有以下特点:
-
基于密度,对远离密度核心的噪声点鲁棒
-
无需知道聚类簇的数量
-
可以发现任意形状的聚类簇
推荐文章
-
有人把吴恩达老师的机器学习和深度学习做成了中文版
-
上瘾了,最近又给公司撸了一个可视化大屏(附源码)
-
如此优雅,4款 Python 自动数据分析神器真香啊
-
梳理半月有余,精心准备了17张知识思维导图,这次要讲清统计学
-
年终汇总:20份可视化大屏模板,直接套用真香(文末附源码)
DBSCAN通常适合于对较低维度数据进行聚类分析。
一、基本概念
DBSCAN的基本概念可以用1,2,3,4来总结。
1个核心思想:基于密度。
直观效果上看,DBSCAN算法可以找到样本点的全部密集区域,并把这些密集区域当做一个一个的聚类簇。
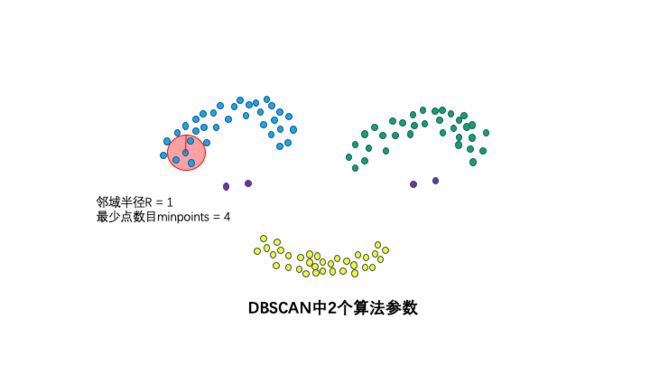
 2个算法参数: 邻域半径R和最少点数目minpoints。**
2个算法参数: 邻域半径R和最少点数目minpoints。**
这两个算法参数实际可以刻画什么叫密集——当邻域半径R内的点的个数大于最少点数目minpoints时,就是密集。
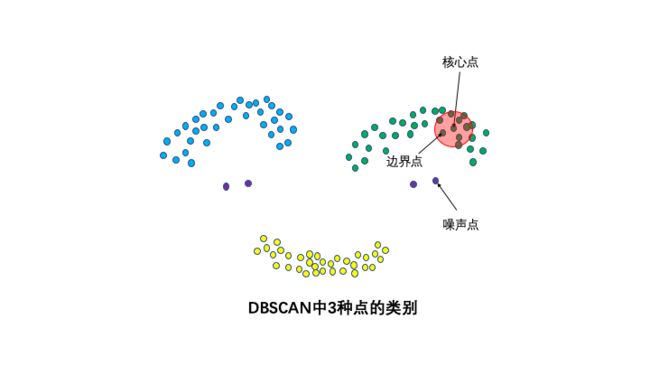
3种点的类别: 核心点,边界点和噪声点。**
邻域半径R内样本点的数量大于等于minpoints的点叫做核心点。不属于核心点但在某个核心点的邻域内的点叫做边界点。既不是核心点也不是边界点的是噪声点。
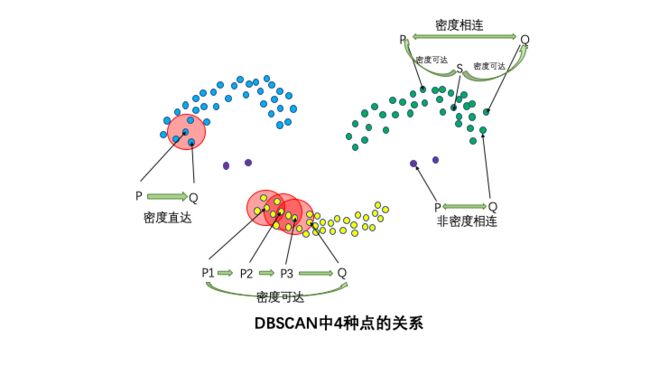
4种点的关系:密度直达,密度可达,密度相连,非密度相连。
如果P为核心点,Q在P的R邻域内,那么称P到Q密度直达。任何核心点到其自身密度直达,密度直达不具有对称性,如果P到Q密度直达,那么Q到P不一定密度直达。
如果存在核心点P2,P3,……,Pn,且P1到P2密度直达,P2到P3密度直达,……,P(n-1)到Pn密度直达,Pn到Q密度直达,则P1到Q密度可达。密度可达也不具有对称性。
如果存在核心点S,使得S到P和Q都密度可达,则P和Q密度相连。密度相连具有对称性,如果P和Q密度相连,那么Q和P也一定密度相连。密度相连的两个点属于同一个聚类簇。
如果两个点不属于密度相连关系,则两个点非密度相连。非密度相连的两个点属于不同的聚类簇,或者其中存在噪声点。
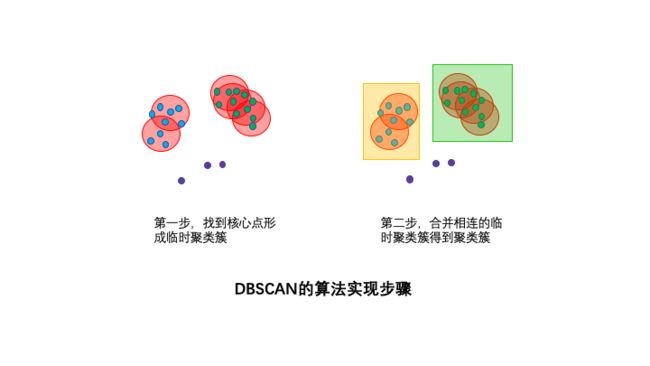
二、DBSCAN算法步骤
DBSCAN的算法步骤分成两步。
1,寻找核心点形成临时聚类簇。
扫描全部样本点,如果某个样本点R半径范围内点数目>=MinPoints,则将其纳入核心点列表,并将其密度直达的点形成对应的临时聚类簇。
2,合并临时聚类簇得到聚类簇。
对于每一个临时聚类簇,检查其中的点是否为核心点,如果是,将该点对应的临时聚类簇和当前临时聚类簇合并,得到新的临时聚类簇。
重复此操作,直到当前临时聚类簇中的每一个点要么不在核心点列表,要么其密度直达的点都已经在该临时聚类簇,该临时聚类簇升级成为聚类簇。
继续对剩余的临时聚类簇进行相同的合并操作,直到全部临时聚类簇被处理。
三、DBSCAN使用范例
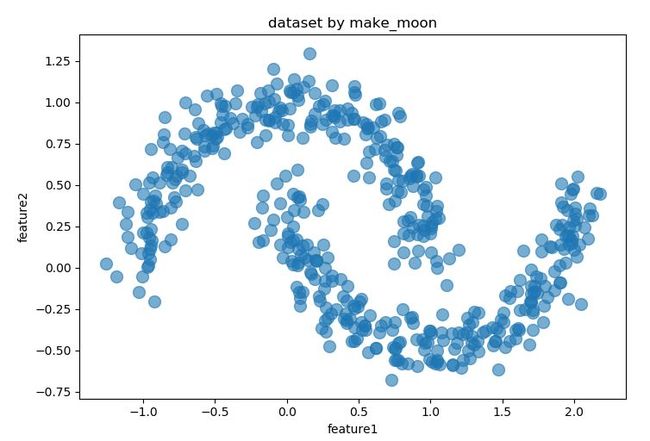
1、生成样本点
import numpy as np
import pandas as pd
from sklearn import datasets
%matplotlib inline
X,_ = datasets.make_moons(500,noise = 0.1,random_state=1)
df = pd.DataFrame(X,columns = ['feature1','feature2'])
df.plot.scatter('feature1','feature2', s = 100,alpha = 0.6, title = 'dataset by make_moon')
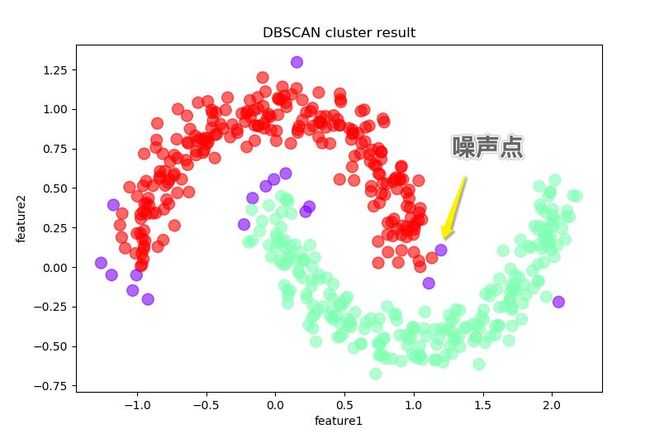
2、调用dbscan接口完成聚类
from sklearn.cluster import dbscan
# eps为邻域半径,min_samples为最少点数目
core_samples,cluster_ids = dbscan(X, eps = 0.2, min_samples=20)
# cluster_ids中-1表示对应的点为噪声点
df = pd.DataFrame(np.c_[X,cluster_ids],columns = ['feature1','feature2','cluster_id'])
df['cluster_id'] = df['cluster_id'].astype('i2')
df.plot.scatter('feature1','feature2', s = 100,
c = list(df['cluster_id']),cmap = 'rainbow',colorbar = False,
alpha = 0.6,title = 'DBSCAN cluster result')
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

目前开通了面试技术交流群,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
- 方式①、发送如下图片至微信,长按识别,后台回复:加群;
- 方式②、添加微信号:dkl88191,备注:来自CSDN
- 方式③、微信搜索公众号:Python学习与数据挖掘,后台回复:加群
