365天深度学习训练营-第P4周:猴痘病识别
- 本文为365天深度学习训练营 中的学习记录博客
- 参考文章:Pytorch实战 | 第P4周:猴痘病识别
- 原作者:K同学啊|接辅导、项目定制
要求: 训练过程中保存效果最好的模型参数。 加载最佳模型参数识别本地的一张图片。
调整网络结构使测试集accuracy到达88%(重点)。
拔高(可选): 调整模型参数并观察测试集的准确率变化。
尝试设置动态学习率。 测试集accuracy到达90%。
本周的代码相对于上周增加指定图片预测与保存并加载模型这个两个模块,在学习这个两知识点后,时间有余的同学请自由探索更佳的模型结构以提升模型是识别准确率,模型的搭建是深度学习程度的重点。
我的环境:
语言环境:Python3.8
编译器:Jupyter Lab
深度学习环境:Pytorch
数据:百度网盘
一、 前期准备
1. 设置GPU
如果设备上支持GPU就使用GPU,否则使用CPU
import torch
import torch.nn as nn
import torchvision.transforms as transforms
import torchvision
from torchvision import transforms, datasets
import os,PIL,pathlib
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
device
笔记:
笔记1.总结一下用到的几个包
PyTorch本身是一个基于Python的科学计算库,特点是可以在GPU上运算。
import torch导入的torch:张量的有关运算。如创建、索引、连接、转置、加减乘除、切片等。功能如下图所示:
1.简介

2.神经网络基础

3.建造第一个神经网络
4.张量

笔记2: torch.device的作用
Pytorch torch.device()的简单用法
一般来说我们最常见到的用法是这样的:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
if torch.cuda.is_available():
device = torch.device("cuda")
else:
device = torch.device("cpu")
这个device的用处是作为Tensor或者Model被分配到的位置。因此,在构建device对象后,紧跟的代码往往是:
data = data.to(device)
model = Model(...).to(device)
表示将构建的张量或者模型分配到相应的设备上。
更一般的,可以通过:
torch.device('cuda', 0)
torch.device('cuda:0')
来指定使用的具体设备。如果没有显式指定设备序号的话则使用torch.cuda.current_device()对应的序号。
笔记3:torch.nn
一、torch.nn是什么?
torch.nn是pytorch中自带的一个函数库,里面包含了神经网络中使用的一些常用函数,如具有可学习参数的nn.Conv2d(),nn.Linear()和不具有可学习的参数(如ReLU,pool,DropOut等)(后面这几个是在nn.functional中),这些函数可以放在构造函数中,也可以不放。
二、torch.nn的应用。
通常引入的时候写成:
import torch.nn as nn
import torch.nn.functional as F
这里我们把函数写在了构造函数中:
class ConvNet(nn.Module):
def __init__(self):
super().__init__()
self.conv1 = nn.Conv2d(1, 10, 5) # 输入通道数1,输出通道数10,核的大小5
self.conv2 = nn.Conv2d(10, 20, 3) # 输入通道数10,输出通道数20,核的大小3
# 下面的全连接层Linear的第一个参数指输入通道数,第二个参数指输出通道数
self.fc1 = nn.Linear(20*10*10, 500) # 输入通道数是2000,输出通道数是500
self.fc2 = nn.Linear(500, 10) # 输入通道数是500,输出通道数是10,即10分类
def forward(self,x):
in_size = x.size(0)
out = self.conv1(x)
out = F.relu(out)
out = F.max_pool2d(out, 2, 2)
out = self.conv2(out)
out = F.relu(out)
out = out.view(in_size, -1)
out = self.fc1(out)
out = F.relu(out)
out = self.fc2(out)
out = F.log_softmax(out, dim=1)
return out
笔记4: torchvision
很多基于Pytorch的工具集都非常好用,比如处理自然语言的torchtext,处理音频的torchaudio,以及处理图像视频的torchvision。
torchvision包含一些常用的数据集、模型、转换函数等等。当前版本0.5.0包括图片分类、语义切分、目标识别、实例分割、关键点检测、视频分类等工具,它将mask-rcnn功能也都包含在内了。mask-rcnn的Pytorch版本最高支持torchvision 0.2.*,0.3.0之后mask-rcnn就包含到tensorvision之中了。
计算机视觉是深度学习中最重要的一类应用,为了方便研究者使用,PyTorch 团队专门开发了一个视觉工具包torchvision,这个包独立于 PyTorch,需通过 pip instal torchvision 安装。
torchvision 主要包含三部分:
models:提供深度学习中各种经典网络的网络结构以及预训练好的模型,包括 AlexNet 、VGG 系列、ResNet 系列、Inception 系列等;
datasets: 提供常用的数据集加载,设计上都是继承 torch.utils.data.Dataset,主要包括 MNIST、CIFAR10/100、ImageNet、COCO等;
transforms:提供常用的数据预处理操作,主要包括对 Tensor 以及 PIL Image 对象的操作;
from torchvision import models
from torch import nn
from torchvision import datasets
'''加载预训练好的模型,如果不存在会进行下载
预训练好的模型保存在 ~/.torch/models/下面'''
resnet34 = models.squeezenet1_1(pretrained=True, num_classes=1000)
'''修改最后的全连接层为10分类问题(默认是ImageNet上的1000分类)'''
resnet34.fc=nn.Linear(512, 10)
'''加上transform'''
transform = T.Compose([
T.ToTensor(),
T.Normalize(mean=[0.4,], std=[0.2,]),
])
'''
# 指定数据集路径为data,如果数据集不存在则进行下载
# 通过train=False获取测试集
'''
dataset = datasets.MNIST('data/', download=True, train=False, transform=transform)
Transforms 中涵盖了大部分对 Tensor 和 PIL Image 的常用处理,这些已在上文提到,这里就不再详细介绍。需要注意的是转换分为两步,
第一步:构建转换操作,例如 transf = transforms.Normalize(mean=x, std=y),
第二步:执行转换操作,例如 output = transf(input) 。另外还可将多个处理操作用 Compose 拼接起来,形成一个处理转换流程。
from torchvision import transforms
to_pil = transforms.ToPILImage()
to_pil(t.randn(3, 64, 64))
输出随机噪声,待补充:
torchvision 还提供了两个常用的函数。
一个是 make_grid ,它能将多张图片拼接成一个网格中;
另一个是 save_img ,它能将 Tensor 保存成图片。
len(dataset) # 10000
dataloader = DataLoader(dataset, shuffle=True, batch_size=16)
from torchvision.utils import make_grid, save_image
dataiter = iter(dataloader)
img = make_grid(next(dataiter)[0], 4) # 拼成4*4网格图片,且会转成3通道
to_img(img)
输出:(待补充)
save_image(img, ‘a.png’)
Image.open(‘a.png’)
输出:(待补充)
- datasets
使用 torchvision.datasets 可以轻易实现对这些数据集的训练集和测试集的下载,只需要使用 torchvision.datasets 再加上需要下载的数据集的名称就可以了。
比如在这个问题中我们要用到手写数字数据集,它的名称是 MNIST,那么实现下载的代码就是
torchvision.datasets.MNIST。其他常用的数据集如 COCO、ImageNet、CIFCAR 等都可以通过这个方法快速下载和载入。实现数据集下载的代码如下:
import torch as t
from torchvision import datasets, transforms
data_train = datasets.MNIST(root="./data", transform=transform, train=True, download=True)
data_test = datasets.MNIST(root="./data", transform=transform, train=False)
其中,
root 用于指定数据集在下载之后的存放路径,这里存放在根目录下的 data 文件夹中;
transform 用于指定导入数据集时需要对数据进行哪种变换操作;
注意,要提前定义这些变换操作;train 用于指定在数据集下载完成后需要载入哪部分数据,
如果设置为 True,则说明载入的是该数据集的训练集部分;
如果设置为 False,则说明载入的是该数据集的测试集部分;
2. transforms
在计算机视觉中处理的数据集有很大一部分是图片类型的,而在 PyTorch 中实际进行计算的是 Tensor 数据类型的变量,所以我们首先需要解决的是数据类型转换的问题,如果获取的数据是格式或者大小不一的图片,则还需要进行归一化和大小缩放等操作,庆幸的是,这些方法在 torch.transforms 中都能找到。
在 torch.transforms 中有大量的数据变换类,其中有很大一部分可以用于实现数据增强(DataArgumentation)。若在我们需要解决的问题上能够参与到模型训练中的图片数据非常有限,则这时就要通过对有限的图片数据进行各种变换,来生成新的训练集了,这些变换可以是缩小或者放大图片的大小、对图片进行水平或者垂直翻转等,都是数据增强的方法。
不过在手写数字识别的问题上可以不使用数据增强的方法,因为可用于模型训练的数据已经足够了。对数据进行载入及有相应变化的代码如下:
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize(mean=[0.5,0.5,0.5],
std=[0.5,0.5,0.5])])
我们可以将以上代码中的 torchvision.transforms.Compose 类看作一种容器,它能够同时对多种数据变换进行组合。传入的参数是一个列表,列表中的元素就是对载入的数据进行的各种变换操作。
在以上代码中,在 torchvision.transforms.Compose 中只使用了一个类型的转换变换 transforms.ToTensor 和一个数据标准化变换transforms.Normalize。
这里使用的标准化变换也叫作标准差变换法,这种方法需要使用原始数据的均值(Mean)和标准差(StandardDeviation)来进行数据的标准化,在经过标准化变换之后,数据全部符合均值为0、标准差为1的标准正态分布。
下面看看在 torchvision.transforms 中常用的数据变换操作。
torchvision.transforms.Resize:用于对载入的图片数据按我们需求的大小进行缩放。传递给这个类的参数可以是一个整型数据,也可以是一个类似于(h, w)的序列,其中,h 代表高度,w 代表宽度,但是如果使用的是一个整型数据,那么表示缩放的宽度和高度都是这个整型数据的值。
torchvision.transforms.Scale:用于对载入的图片数据按我们需求的大小进行缩放,用法和
torchvision.transforms.Resize类似。
torchvision.transforms.CenterCrop:用于对载入的图片以图片中心为参考点,按我们需要的大小进行裁剪。传递给这个类的参数可以是一个整型数据,也可以是一个类似于(h,w)的序列。* torchvision.transforms.RandomCrop:用于对载入的图片按我们需要的大小进行随机裁剪。传递给这个类的参数可以是一个整型数据,也可以是一个类似于(h,w)的序列。
torchvision.transforms.RandomHorizontalFlip:用于对载入的图片按随机概率进行水平翻转。我们可以通过传递给这个类的参数自定义随机概率,如果没有定义,则使用默认的概率值 0.5。
torchvision.transforms.RandomVerticalFlip:用于对载入的图片按随机概率进行垂直翻转。我们可以通过传递给这个类的参数自定义随机概率,如果没有定义,则使用默认的概率值 0.5。
torchvision.transforms.ToTensor:用于对载入的图片数据进行类型转换,将之前构成 PIL 图片的数据转换成 Tensor 数据类型的变量,让 PyTorch 能够对其进行计算和处理。
torchvision.transforms.ToPILImage:用于将 Tensor 变量的数据转换成 PIL 图片数据,主要是为了方便图片内容的显示。
3. 数据预览和加载
在数据下载完成并且载入后,我们还需要对数据进行装载。我们可以将数据的载入理解为对图片的处理,在处理完成后,我们就需要将这些图片打包好送给我们的模型进行训练了,而装载就是这个打包
的过程。
在装载时通过 batch_size 的值来确认每个包的大小,通过 shuffle 的值来确认是否在装载的过程中打乱图片的顺序。装载图片的代码如下:
data_loader_train = torch.utils.data.DataLoader(dataset=data_train, batch_size = 64,
shuffle = True
)
data_loader_test = torch.utils.data.DataLoader(dataset=data_test, batch_size=64,
shuffle = True
)
对数据的装载使用的是 torch.utils.data.DataLoader 类,类中的
dataset 参数用于指定我们载入的数据集名称;
batch_size 参数设置了每个包中的图片数据个数,代码中的值是 64,所以在每个包中会包含64张图片;
shuffle 参数设置为 True,在装载的过程会将数据随机打乱顺序并进行打包;
在装载完成后,我们可以选取其中一个批次的数据进行预览。进行数据预览的代码如下:
images, labels = next(iter(data_loader_train))
img = torchvision.utils.make_grid(images)
img = img.numpy().transpose(1,2,0)
std = [0.5, 0.5, 0.5]
mean = [0.5, 0.5, 0.5]
img = img * std + mean
print([labels[i] for i in range(64))
在以上代码中使用了 iter 和 next 来获取一个批次的图片数据和其对应的图片标签,然后使用torchvision.utils 中的 make_grid 类方法将一个批次的图片构造成网格模式。
需要传递给 torchvision.utils.make_grid 的参数就是一个批次的装载数据,每个批次的装载数据都是 4 维的,维度的构成从前往后分别为 batch_size 、channel 、height 和 weight ,分别对应一个批次中的数据个数、每张图片的色彩通道数、每张图片的高度和宽度。
在通过 torchvision.utils.make_grid 之后,图片的维度变成了( channel , height , weight ),这个批次的图片全部被整合到了一起,所以在这个维度中对应的值也和之前不一样了,但是色彩通道数保持不变。
若我们想使用Matplotlib将数据显示成正常的图片形式,则使用的数据首先必须是数组,其次这个数组的维度必须是(height,weight,channel),即色彩通道数在最后面。所以我们要通过 numpy 和 transpose 完成原始数据类型的转换和数据维度的交换,这样才能够使用Matplotlib绘制出正确的图像。
- 模型搭建和参数优化
(1)torch.nn.Conv2d:用于搭建卷积神经网络的卷积层,主要的输入参数有输入通道数、输出通道数、卷积核大小、卷积核移动步长和Paddingde值。其中,输入通道数的数据类型是整型,用于确定输入数据的层数;输出通道数的数据类型也是整型,用于确定输出数据的层数;卷积核大小的数据类型是整型,用于确定卷积核的大小;卷积核移动步长的数据类型是整型,用于确定卷积核每次滑动的步长;Paddingde 的数据类型是整型,值为0时表示不进行边界像素
的填充,如果值大于0,那么增加数字所对应的边界像素层数。
(2)torch.nn.MaxPool2d:用于实现卷积神经网络中的最大池化层,主要的输入参数是池化窗口大小、池化窗口移动步长和Paddingde值。同样,池化窗口大小的数据类型是整型,用于确定池化窗口的大小。池化窗口步长的数据类型也是整型,用于确定池化窗口每次移动的步长。Paddingde值和在torch.nn.Conv2d中定义的Paddingde值的用法和意义是一样的。
(3)torch.nn.Dropout:torch.nn.Dropout类用于防止卷积神经网络在训练的过程中发生过拟合,其工作原理简单来说就是在模型训练的过程中,以一定的随机概率将卷积神经网络模型的部分参数归零,以达到减少相邻两层神经连接的目的。图 6-3显示了 Dropout方法的效果。
笔记5:torchvision.transforms简介
PyTorch之torchvision.transforms详解[原理+代码实现]
前言
torchvision.transforms常用变换类
transforms.Compose
transforms.Normalize(mean, std)
transforms.Resize(size)
transforms.Scale(size)
transforms.CenterCrop(size)
transforms.RandomCrop(size)
transforms.RandomResizedCrop(size,scale)
transforms.RandomHorizontalFlip
transforms.RandomVerticalFlip
transforms.RandomRotation
transforms.ToTensor
transforms.ToPILImage
torchvision.transforms编程实战
前言
我们知道,在计算机视觉中处理的数据集有很大一部分是图片类型的,如果获取的数据是格式或者大小不一的图片,则需要进行归一化和大小缩放等操作,这些是常用的数据预处理方法。如果参与模型训练中的图片数据非常有限,则需要通过对有限的图片数据进行各种变换,如缩小或者放大图片的大小、对图片进行水平或者垂直翻转等,这些都是数据增强的方法。庆幸的是,这些方法在torch.transforms中都能找到,在torch.transforms中有大量的数据变换类,有很大一部分可以用于实现数据预处理(Data Preprocessing)和数据增广(Data Argumentation)。
torchvision.transforms常用变换类
transforms.Compose
transforms.Compose类看作一种容器,它能够同时对多种数据变换进行组合。传入的参数是一个列表,列表中的元素就是对载入的数据进行的各种变换操作。
首先使用PIL加载原始图片
#Pyton Image Library PIL 一个python图片库
from PIL import Image
from torchvision import transforms
import matplotlib.pyplot as plt
%matplotlib inline
img = Image.open("./imgs/dianwei.jpg")
print(img.size)
plt.imshow(img)
输出:
(1102, 735)
transformer = transforms.Compose([
transforms.Resize(256),
transforms.transforms.RandomResizedCrop((224), scale = (0.5,1.0)),
transforms.RandomHorizontalFlip(),
])
test_a = transformer(img)
plt.imshow(test_a)
输出:
transforms.Normalize(mean, std)
这里使用的是标准正态分布变换,这种方法需要使用原始数据的均值(Mean)和标准差(Standard Deviation)来进行数据的标准化,在经过标准化变换之后,数据全部符合均值为0、标准差为1的标准正态分布。计算公式如下:
一般来说,mean和std是实现从原始数据计算出来的,对于计算机视觉,更常用的方法是从样本中抽样算出来的或者是事先从相似的样本预估一个标准差和均值。如下代码,对三通道的图片进行标准化:
# 标准化是把图片3个通道中的数据整理到规范区间 x = (x - mean(x))/stddev(x)
# [0.485, 0.456, 0.406]这一组平均值是从imagenet训练集中抽样算出来的
normalize = transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
transforms.Resize(size)
对载入的图片数据按照我们的需要进行缩放,传递给这个类的size可以是一个整型数据,也可以是一个类似于 (h ,w) 的序列。如果输入是个(h,w)的序列,h代表高度,w代表宽度,h和w都是int,则直接将输入图像resize到这个(h,w)尺寸,相当于force。如果使用的是一个整型数据,则将图像的短边resize到这个int数,长边则根据对应比例调整,图像的长宽比不变。
# 等比缩放
test1 = transforms.Resize(224)(img)
print(test1.size)
plt.imshow(test1)
输出:
(335, 224)
transforms.Scale(size)
对载入的图片数据我们的需要进行缩放,用法和torchvision.transforms.Resize类似。。传入的size只能是一个整型数据,size是指缩放后图片最小边的边长。举个例子,如果原图的height>width,那么改变大小后的图片大小是(size*height/width, size)。
# 等比缩放
test2 = transforms.Scale(224)(img)
print(test2.size)
plt.imshow(test2)
输出:
(335, 224)
transforms.CenterCrop(size)
以输入图的中心点为中心点为参考点,按我们需要的大小进行裁剪。传递给这个类的参数可以是一个整型数据,也可以是一个类似于(h,w)的序列。如果输入的是一个整型数据,那么裁剪的长和宽都是这个数值
test3 = transforms.CenterCrop((500,500))(img)
print(test3.size)
plt.imshow(test3)
输出:
(500, 500)
test4 = transforms.CenterCrop(224)(img)
print(test4.size)
plt.imshow(test4)
输出:
(224, 224)
transforms.RandomCrop(size)
用于对载入的图片按我们需要的大小进行随机裁剪。传递给这个类的参数可以是一个整型数据,也可以是一个类似于(h,w)的序列。如果输入的是一个整型数据,那么裁剪的长和宽都是这个数值
test5 = transforms.RandomCrop(224)(img)
print(test5.size)
plt.imshow(test5)
输出:
(224, 224)
test6 = transforms.RandomCrop((300,300))(img)
print(test6.size)
plt.imshow(test6)
输出:
(300, 300)
transforms.RandomResizedCrop(size,scale)
先将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为size的大小。即先随机采集,然后对裁剪得到的图像安装要求缩放,默认scale=(0.08, 1.0)。scale是一个面积采样的范围,假如是一个100100的图片,scale = (0.5,1.0),采样面积最小是0.5100100=5000,最大面积就是原图大小100100=10000。先按照scale将给定图像裁剪,然后再按照给定的输出大小进行缩放。
test9 = transforms.RandomResizedCrop(224)(img)
print(test9.size)
plt.imshow(test9)
输出:
(224, 224)
test9 = transforms.RandomResizedCrop(224,scale=(0.5,0.8))(img)
print(test9.size)
plt.imshow(test9)
输出:
(224, 224)
transforms.RandomHorizontalFlip
用于对载入的图片按随机概率进行水平翻转。我们可以通过传递给这个类的参数自定义随机概率,如果没有定义,则使用默认的概率值0.5。
test7 = transforms.RandomHorizontalFlip()(img)
print(test7.size)
plt.imshow(test7)
输出:
(1102, 735)
transforms.RandomVerticalFlip
用于对载入的图片按随机概率进行垂直翻转。我们可以通过传递给这个类的参数自定义随机概率,如果没有定义,则使用默认的概率值0.5。
test8 = transforms.RandomVerticalFlip()(img)
print(test8.size)
plt.imshow(test8)
输出:
(1102, 735)
transforms.RandomRotation
transforms.RandomRotation(
degrees,
resample=False,
expand=False,
center=None,
fill=None,
)
功能:按照degree随机旋转一定角度
degree:加入degree是10,就是表示在(-10,10)之间随机旋转,如果是(30,60),就是30度到60度随机旋转
resample是重采样的方法
center表示中心旋转还是左上角旋转
test10 = transforms.RandomRotation((30,60))(img)
print(test10.size)
plt.imshow(test10)
transforms.ToTensor
用于对载入的图片数据进行类型转换,将之前构成PIL图片的数据转换成Tensor数据类型的变量,让PyTorch能够对其进行计算和处理。
transforms.ToPILImage
用于将Tensor变量的数据转换成PIL图片数据,主要是为了方便图片内容的显示。
torchvision.transforms编程实战
# RandomResizedCrop 将给定图像随机裁剪为不同的大小和宽高比,然后缩放所裁剪得到的图像为制定的大小
print("原图大小:",img.size)
# Crop代表剪裁到某个尺寸
data1 = transforms.RandomResizedCrop(224)(img)
# data1、data2、data3尺寸一样,长宽都是224*224 size也可以是一个Integer,在这种情况下,切出来的图片的形状是正方形
print("随机裁剪后的大小:",data1.size)
data2 = transforms.RandomResizedCrop(224)(img)
data3 = transforms.RandomResizedCrop(224)(img)
# 放四个格,布局为2*2
plt.subplot(2,2,1),plt.imshow(img),plt.title("Original")
plt.subplot(2,2,2),plt.imshow(data1),plt.title("Transform 1")
plt.subplot(2,2,3),plt.imshow(data2),plt.title("Transform 2")
plt.subplot(2,2,4),plt.imshow(data3),plt.title("Transform 3")
plt.show()
输出:
原图大小: (1102, 735)
随机裁剪后的大小: (224, 224)
# 以输入图的中心点为中心点做指定size的crop操作
img1 = transforms.CenterCrop(224)(img)
img2 = transforms.CenterCrop(224)(img)
img3 = transforms.CenterCrop(224)(img)
# img1、img2、img3三个图是一样的
plt.subplot(2,2,1),plt.imshow(img),plt.title("Original")
plt.subplot(2,2,2), plt.imshow(img1), plt.title("Transform 1")
plt.subplot(2,2,3), plt.imshow(img2), plt.title("Transform 2")
plt.subplot(2,2,4), plt.imshow(img3), plt.title("Transform 3")
plt.show()
输出:
# 以给定的概率随机水平旋转给定的PIL的图像,默认为0.5
img1 = transforms.RandomHorizontalFlip()(img)
img2 = transforms.RandomHorizontalFlip()(img)
img3 = transforms.RandomHorizontalFlip()(img)
plt.subplot(2,2,1),plt.imshow(img),plt.title("Original")
plt.subplot(2,2,2), plt.imshow(img1), plt.title("Transform 1")
plt.subplot(2,2,3), plt.imshow(img2), plt.title("Transform 2")
plt.subplot(2,2,4), plt.imshow(img3), plt.title("Transform 3")
plt.show()
输出:
源码在PyTorch之torchvision.transforms实战,请自提!
参考文档
深度学习pytoch实战计算机视觉(唐进民著)
笔记6:os,pathlib
对比老式的 os.path,pathblib有几个优势:
- 传统操作导入模块不统一。 既可以导入 os,又可以导入 os.path,而新的用法统一可以用 pathlib 管理。
- 传统操作在不同操作系统之间切换麻烦。 换了操作系统常常要改代码,还经常需要进行一些额外操作。
- 返回的数据类型不同。
(1)传统主要是函数形式,返回的数据类型通常是字符串。
(2)但是路径和字符串并不等价,所以在使用 os 操作路径的时候常常还要引入其他类库协助操作。
(3)Pathlib模块是面向对象,处理起来更灵活方便。 - pathlib 简化了很多操作,用起来更轻松
Pathlib模块 与 os.path模块对操作系统路径操作方法进行对比差异
pathlib 模块较于os.path 模块提供的方法更加简单方便,提高我们代码简单和可维护
如果你的新项目可以直接用 3.6 以上,建议用 pathlib。


笔记7:pil简介
PIL,全称 Python Imaging Library,是 Python 平台一个功能非常强大而且简单易用的图像处理库。但是,由于 PIL 仅支持到Python 2.7,加上年久失修,于是一群志愿者在 PIL 的基础上创建了兼容 Python 3 的版本,名字叫 Pillow ,我们可以通过安装 Pillow 来使用 PIL。
- pip 安装 pillow
在 Ubuntu 下通过一个简单的命令sudo pip3 install pillow即可成功安装库。 - 打开、保存、显示图片
from PIL import Image
image = Image.open('2092.jpg')
image.show()
image.save('1.jpg')
print(image.mode, image.size, image.format)
# RGB (481, 321) JPEG
mode 属性为图片的模式,RGB 代表彩色图像,L 代表光照图像也即灰度图像等
size 属性为图片的大小(宽度,长度)
format 属性为图片的格式,如常见的 PNG、JPEG 等
3. 转换图片模式
image.show()
grey_image = image.convert('L')
grey_image.show()


任何支持的图片模式都可以直接转为彩色模式或者灰度模式,但是,若是想转化为其他模式,则需要借助一个中间模式(通常是彩色)来进行过转
4. 通道分离合并
r, g, b = image.split()
im = Image.merge('RGB', (b, g, r))
彩色图像可以分离出 R、G、B 通道,但若是灰度图像,则返回灰度图像本身。然后,可以将 R、G、B 通道按照一定的顺序再合并成彩色图像。
5. 图片裁剪、旋转和改变大小
box = (100, 100, 300, 300)
region = image.crop(box)
region = region.transpose(Image.ROTATE_180)
image.paste(region, box)
image.show()

通过定义一个 4 元组,依次为左上角 X 坐标、Y 坐标,右下角 X 坐标、Y 坐标,可以対原图片的某一区域进行裁剪,然后进行一定处理后可以在原位置粘贴回去。
im = image.resize((300, 300))
im = image.rotate(45) # 逆时针旋转 45 度
im = image.transpose(Image.FLIP_LEFT_RIGHT) # 左右翻转
im = im.transpose(Image.FLIP_TOP_BOTTOM)# 上下翻转
- 像素值操作
out = image.point(lambda i: i * 1.2) # 对每个像素值乘以 1.2
source = image.split()
out = source[0].point(lambda i: i > 128 and 255) # 对 R 通道进行二值化
i > 128 and 255,当 i <= 128 时,返回 False 也即 0,;反之返回 255 。

- 和 Numpy 数组之间的转化
array = np.array(image)
print(array.shape) #(321, 481, 3)
out = Image.fromarray(array)
2. 导入数据
import os,PIL,random,pathlib
data_dir = './4-data/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[1] for path in data_paths]
classeNames
total_datadir = './4-data/'
# 关于transforms.Compose的更多介绍可以参考:https://blog.csdn.net/qq_38251616/article/details/124878863
train_transforms = transforms.Compose([
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理-->转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std=[0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
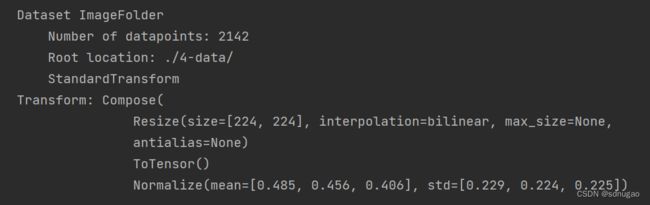
total_data = datasets.ImageFolder(total_datadir,transform=train_transforms)
total_data
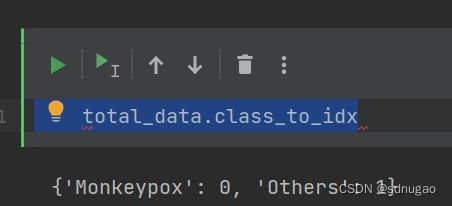
total_data.class_to_idx
笔记8:random简介
在python中用于生成随机数的模块是random,在使用前需要import。
注意: 以下代码在Python3.6下测试通过, 下面看下它的用法。
1、random.random
random.random()用于生成一个0到1的随机符点数: 0 <= n < 1.0
#!/usr/bin/python
import random
# 生成第一个随机数
print ("random 1 : ", random.random())
# 生成第二个随机数
print ("random 2 : ", random.random())
结果: 结果: 结果: 结果: 结果: 结果: 结果: [Python] glob 模块(查找文件路径) 通配符: 详解: 要列出子目录中的文件,必须把子目录包含在模式中。 第一种情况显示列出子目录名,第二种情况则依赖一个通配符查找目录。 单配符-问号?:问号?会匹配文件名中该位置的单个字符。 字符区间-[a-z]:使用字符区间[a-z],可以匹配多个字符中的一个字符。 区间可以匹配所有小写字母。 from torchvision.transforms import transforms train_transforms = transforms.Compose([ torchvision已经预先实现了常用的Dataset,包括前面使用过的CIFAR-10,以及ImageNet、COCO、MNIST、LSUN等数据集,可通过诸如torchvision.datasets.CIFAR10来调用。在这里介绍一个会经常使用到的Dataset——ImageFolder。ImageFolder假设所有的文件按文件夹保存,每个文件夹下存储同一个类别的图片,文件夹名为类名,其构造函数如下: 它主要有四个参数: root:在root指定的路径下寻找图片 label是按照文件夹名顺序排序后存成字典,即{类名:类序号(从0开始)},一般来说最好直接将文件夹命名为从0开始的数字,这样会和ImageFolder实际的label一致,如果不是这种命名规范,建议看看self.class_to_idx属性以了解label和文件夹名的映射关系。 图片结构如下所示: 加上transform ———————————————— 简单来说就是调整PILImage对象的尺寸,注意不能是用io.imread或者cv2.imread读取的图片,这两种方法得到的是ndarray。 将图片短边缩放至x,长宽比保持不变: 而一般输入深度网络的特征图长宽是相等的,就不能采取等比例缩放的方式了,需要同时指定长宽: 例如transforms.Resize([224, 224])就能将输入图片转化成224×224的输入特征图。 这样虽然会改变图片的长宽比,但是本身并没有发生裁切,仍可以通过resize方法返回原来的形状: 需要注意的一点是PILImage对象size属性返回的是w, h,而resize的参数顺序是h, w。 torchvision.transforms transforms.ToTensor() ToTensor就是把一个取值范围是[0,255]的PIL.Image图像或者shape为(H,W,C)(Height,Width,Channel)的numpy.ndarray,转换成形状为[C,H,W],取值范围是[0,1.0]的torch.FloadTensor transforms.Normalize(mean, std) transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) (0.5, 0.5, 0.5)就是RGB三通道上分别给定的均值和方差。标准化经过下面公式进行变换。 Normalized_image=(image-mean)/std 官方文档也有详细说明 为什么要这样处理? 1、transforms.ToTensor()作用 2、transforms.Normalize()作用 可我看很多代码里面是这样的: 不用自己写划分数据集的函数,pytorch已经给我们封装好了,那就是torch.utils.data.random_split()。 用法详解 描述 参数 输出: [4, 1, 7, 5, 3, 9, 0] 代码: 输出: [4, 1, 7, 5, 3, 9, 0] 1.Dataset和DataLoader的区别 详情可以参照这个博客:Dataset和Dataloader的理解。 2.DataLoader的使用 (1)查看数据集CIFAR10中第1张图片的基本信息,代码如下: 上述代码输出结果如下,展示的是读取到的CIFAR10中第一张照片的形状信息和类别target信息。 (2)batch_size=4对数据读取的作用,表示一次性读取数据集中的4张图片,并且集合在一起进行返回,代码如下: 上述代码输出结果如下,展示的是batch_size=4时返回的结果。 (3)将epoch设置为2时,对数据集进行两次完整的遍历加载,同时设置batch_size=4,代码如下: 此时借助Tensorboard,对代码效果进行展示,得到如下的结果: 从Tensorboard中的运行结果可知,设置参数batch_size=4时,每次取了4张照片,并获得4个targets标签。将DataLoader()函数用图示如下: (4)shuffle=True对数据读取的作用,每个epoch读完数据之后,在下次读取数据时是否会将数据打乱顺序,如果设置shuffle=True,那么在下一次epoch时,会将数据打乱顺序,然后再进行下一次读取,从而两次epoch读到的数据顺序是不同的;如果设置shuffle=False,那么在下一次数据读取时,不会打乱数据的顺序,从而两次读取到的数据顺序是相同的。 3.学习小结 测试函数和训练函数大致相同,但是由于不进行梯度下降对网络权重进行更新,所以不需要传入优化器 四、 结果可视化 output_27_0.png 预测结果是:Monkeypox
random 1 : 0.3558774735558118
random 2 : 0.46006891154492147
2、random.uniform
random.uniform的函数原型为:random.uniform(a, b),用于生成一个指定范围内的随机符点数,两个参数其中一个是上限,一个是下限。如果a > b,则生成的随机数n: b <= n <= a。如果 a import random
print (random.uniform(1, 10))
print (random.uniform(10, 1))
2.1520386126536115
3.1391272747538731
3、random.randint
random.randint()的函数原型为:random.randint(a, b),用于生成一个指定范围内的整数。其中参数a是下限,参数b是上限,生成的随机数n: a <= n <= b,
注意: 下限必须小于上限import random
print (random.randint(11, 20)) #生成的随机数n: 11 <= n <= 20
print (random.randint(20, 20)) #结果永远是20
11
20
4、random.randrange
random.randrange的函数原型为:random.randrange([start], stop[, step]),从指定范围内,按指定基数递增的集合中 获取一个随机数。如:random.randrange(10, 100, 2),结果相当于从[10, 12, 14, 16, … 96, 98]序列中获取一个随机数。random.randrange(10, 100, 2)在结果上与 random.choice(range(10, 100, 2) 等效。import random
print (random.randrange(10, 18, 2))
14
5、random.choice
random.choice从序列中获取一个随机元素。其函数原型为:random.choice(sequence)。参数sequence表示一个有序类型。这里要说明 一下:sequence在python不是一种特定的类型,而是泛指一系列的类型。list, tuple, 字符串都属于sequence。有关sequence可以查看python手册数据模型这一章import random
print (random.choice("Pythontab.com"))
print (random.choice(["python", "tab", "com"]))
print (random.choice(("python", "tab", "com")))
t
python
tab
6、random.shuffle
random.shuffle的函数原型为:random.shuffle(x[, random]),用于将一个列表中的元素打乱。如:import random
list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
random.shuffle(list)
print (list)
[4, 1, 9, 3, 2, 7, 10, 6, 8, 5]
7、random.sample
random.sample的函数原型为:random.sample(sequence, k),从指定序列中随机获取指定长度的片断。sample函数不会修改原有序列。import random
list = [1, 2, 3, 4, 5, 6, 7, 8, 9, 10]
slice = random.sample(list, 5) #从list中随机获取5个元素,作为一个片断返回
print (slice)
print (list) #原有序列不会改变。
[8, 2, 6, 7, 9]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10]笔记9:glob函数简介
通配符-星号*:星号*匹配一个文件名段中的0个或多个字符
单配符-问号?:问号?会匹配文件名中该位置的单个字符。
字符区间-[a-z]:使用字符区间[a-z],可以匹配多个字符中的一个字符。
基本用法:
glob.glob(pathname)
返回所有匹配的文件路径列表。它只有一个参数pathname,定义了文件路径匹配规则,这里可以是绝对路径,也可以是相对路径。
glob.iglob(pathname),
获取一个可编历对象,使用它可以逐个获取匹配的文件路径名。与glob.glob()的区别是:glob.glob同时获取所有的匹配路径,而glob.iglob一次只获取一个匹配路径。
Eg:import glob
print glob.glob(r'E:\*\*.doc') print glob.glob(r'.\*.py')
f = glob.iglob(r'.\*.py')
for py in f:
print py
>>>
['E:\\test_file\\adplus.doc']
['.\\perfrom_test.py', '.\\pyTest.py', '.\\simulation_login.py', '.\\widget.py', '.\\__init__.py']
.\perfrom_test.py
.\pyTest.py
.\simulation_login.py
.\widget.py
.\__init__.py
通配符-星号匹配一个文件名段中的0个或多个字符
import globfor name in glob.glob('tmp/'):
print name
这个模式会匹配所有的路径名,但是不会递归搜索到子目录。>>>
tmp\checklog_status.sh
tmp\check_Adwords_v1.2.sh
tmp\check_traffic.sh
tmp\cut_nginxlog_V1.2.sh
tmp\ip_conn.sh
tmp\ip_keepalive.sh
tmp\nagios使用手册.doc
tmp\nmap_ping
tmp\nrpe_install-1.3.sh
tmp\one
tmp\syn.sh
tmp\zabbix_agentd_2.0.10_win_V1.2.bat
tmp\zabbix_agentd_2.0.8_V1.3.sh
tmp\工作内容.doc
import globprint 'Name explicitly:'for name in glob.glob('tmp/one/*'):
print '\t', nameprint 'Name with wildcard:'for name in glob.glob('tmp/*/*'):
print '\t', name
>>>
Name explicitly:
tmp/one\another.txt
tmp/one\file.txt
Name with wildcard:
tmp\one\another.txt
tmp\one\file.txt
import globfor name in glob.glob('tmp/chec?_traffic.sh'):
print name
>>> tmp\check_traffic.sh
import globfor name in glob.glob('tmp/one/[a-z]*'):
print name
>>>
tmp/one\another.txt
tmp/one\file.txt
笔记10:从路径中取指定的文件名
data_dir = './4-data/'
data_dir = pathlib.Path(data_dir)
data_paths = list(data_dir.glob('*'))
classeNames = [str(path).split("\\")[1] for path in data_paths]
for path in data_paths:
print(path)
print(str(path).split("\\"))

笔记11:transforms.Compose
transforms.Resize([224, 224]), # 将输入图片resize成统一尺寸
transforms.RandomRotation(degrees=(-10, 10)), # 随机旋转,-10到10度之间随机选
transforms.RandomHorizontalFlip(p=0.5), # 随机水平翻转 选择一个概率概率
transforms.RandomVerticalFlip(p=0.5), # 随机垂直翻转
transforms.RandomPerspective(distortion_scale=0.6, p=1.0), # 随机视角
transforms.GaussianBlur(kernel_size=(5, 9), sigma=(0.1, 5)), # 随机选择的高斯模糊模糊图像
transforms.ToTensor(), # 将PIL Image或numpy.ndarray转换为tensor,并归一化到[0,1]之间
transforms.Normalize( # 标准化处理–>转换为标准正太分布(高斯分布),使模型更容易收敛
mean=[0.485, 0.456, 0.406],
std = [0.229, 0.224, 0.225]) # 其中 mean=[0.485,0.456,0.406]与std=[0.229,0.224,0.225] 从数据集中随机抽样计算得到的。
])
————————————————
版权声明:本文为CSDN博主「K同学啊」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_38251616/article/details/124878863笔记12:pytorch的ImageFolder简介
ImageFolder(root, transform=None, target_transform=None, loader=default_loader)
transform:对PIL Image进行的转换操作,transform的输入是使用loader读取图片的返回对象
target_transform:对label的转换
loader:给定路径后如何读取图片,默认读取为RGB格式的PIL Image对象
from torchvision import transforms as T
import matplotlib.pyplot as plt
from torchvision.datasets import ImageFolder
dataset = ImageFolder('data/dogcat_2/')
# cat文件夹的图片对应label 0,dog对应1
print(dataset.class_to_idx)
# 所有图片的路径和对应的label
print(dataset.imgs)
# 没有任何的transform,所以返回的还是PIL Image对象
#print(dataset[0][1])# 第一维是第几张图,第二维为1返回label
#print(dataset[0][0]) # 为0返回图片数据
plt.imshow(dataset[0][0])
plt.axis('off')
plt.show()
normalize = T.Normalize(mean=[0.4, 0.4, 0.4], std=[0.2, 0.2, 0.2])
transform = T.Compose([
T.RandomResizedCrop(224),
T.RandomHorizontalFlip(),
T.ToTensor(),
normalize,
])
dataset = ImageFolder('data1/dogcat_2/', transform=transform)
# 深度学习中图片数据一般保存成CxHxW,即通道数x图片高x图片宽
#print(dataset[0][0].size())
to_img = T.ToPILImage()
# 0.2和0.4是标准差和均值的近似
a=to_img(dataset[0][0]*0.2+0.4)
plt.imshow(a)
plt.axis('off')
plt.show()
笔记13:Pytorch transforms.Resize()的简单用法
transforms.Resize(x)
transforms.Resize([h, w])
from PIL import Image
from torchvision import transforms
img = Image.open('1.jpg')
w, h = img.size
resize = transforms.Resize([224,244])
img = resize(img)
img.save('2.jpg')
resize2 = transforms.Resize([h, w])
img = resize2(img)
img.save('3.jpg')
————————————————
版权声明:本文为CSDN博主「xiongxyowo」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_40714949/article/details/115393592笔记14:transforms.ToTensor()与transforms.Normalize()函数解析
transforms.ToTensor
torchvision 数据集的输出是范围 [0, 1] 的 PILImage 图像。我们将它们转换为标准化范围 [-1, 1] 的张量。转换就要用到上面的代码。
Normalize就是对图像进行标准化,给定均值mean:(R,G,B) 方差std:(R,G,B),就会把Tensor正则化。
比如前面的ToTensor转换为[0,1.0]的Tensor,然后最小值0就转换成(0-0.5)/0.5=-1,最大值1就转换成(1-0.5)/0.5=1,三通道R,G,B都如此经过Normalize()变换后,每个样本图像就符合了均值为0方差为1的标准正态分布。
数据经过归一化和标准化后可以加快梯度下降的求解速度,让数据远离Sigmoid激活函数的饱和区,这就是Batch Normalization等技术非常流行的原因,它使得可以使用更大的学习率更稳定地进行梯度传播,甚至增加网络的泛化能力。总而言之,提高训练速度,好处多多。
————————————————
版权声明:本文为CSDN博主「whis学习随记」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_44766592/article/details/125262986
ToTensor()将shape为(H, W, C)的nump.ndarray或img转为shape为(C, H, W)的tensor,其将每一个数值归一化到[0,1],其归一化方法比较简单,直接除以255即可。具体可参见如下代码:import torchvision.transforms as transforms
import numpy as np
from __future__ import print_function
# 定义转换方式,transforms.Compose将多个转换函数组合起来使用
transform1 = transforms.Compose([transforms.ToTensor()]) #归一化到(0,1),简单直接除以255
# 定义一个数组
d1 = [1,2,3,4,5,6]
d2 = [4,5,6,7,8,9]
d3 = [7,8,9,10,11,14]
d4 = [11,12,13,14,15,15]
d5 = [d1,d2,d3,d4]
d = np.array([d5,d5,d5],dtype=np.float32)
d_t = np.transpose(d,(1,2,0)) # 转置为类似图像的shape,(H,W,C),作为transform的输入
# 查看d的shape
print('d.shape: ',d.shape, '\n', 'd_t.shape: ', d_t.shape)
# 输出
d.shape: (3, 4, 6)
d_t.shape: (4, 6, 3)
d_t_trans = transform1(d_t) # 直接使用函数归一化
# 手动归一化,下面的两个步骤可以在源码里面找到
d_t_temp = torch.from_numpy(d_t.transpose((2,0,1)))
d_t_trans_man = d_t_temp.float().div(255)
print(d_t_trans.equal(d_t_trans_man))
# 输出
True
在transforms.Compose([transforms.ToTensor()])中加入transforms.Normalize(),如下所示:transforms.Compose([transforms.ToTensor(),transforms.Normalize(std=(0.5,0.5,0.5),mean=(0.5,0.5,0.5))]),则其作用就是先将输入归一化到(0,1),再使用公式"(x-mean)/std",将每个元素分布到(-1,1)
transform2 = transforms.Compose([transforms.ToTensor(),transforms.Normalize(std=(0.5,0.5,0.5),mean=(0.5,0.5,0.5))])# 归一化到(0,1)之后,再 (x-mean)/std,归一化到(-1,1),数据中存在大于mean和小于mean
d_t_trans_2 = transform2(d_t)
d_t_temp1 = torch.from_numpy(d_t.transpose((2,0,1)))
d_t_temp2 = d_t_temp1.float().div(255)
d_t_trans_man2 = d_t_temp2.sub_(0.5).div_(0.5)
print(d_t_trans_2.equal(d_t_trans_man2))
#输出
True
torchvision.transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
这一组值是怎么来的?
这一组值是从imagenet训练集中抽样算出来的。
————————————————
版权声明:本文为CSDN博主「我是天才很好」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43593330/article/details/1075437373. 划分数据集
train_size = int(0.8 * len(total_data))
test_size = len(total_data) - train_size
train_dataset, test_dataset = torch.utils.data.random_split(total_data, [train_size, test_size])
train_dataset, test_dataset

train_size,test_size
batch_size = 32
train_dl = torch.utils.data.DataLoader(train_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
test_dl = torch.utils.data.DataLoader(test_dataset,
batch_size=batch_size,
shuffle=True,
num_workers=1)
for X, y in test_dl:
print("Shape of X [N, C, H, W]: ", X.shape)
print("Shape of y: ", y.shape, y.dtype)
break

笔记15:【pytorch】使用torch.utils.data.random_split()划分数据集
torch.utils.data.random_split(dataset, lengths, generator=
随机将一个数据集分割成给定长度的不重叠的新数据集。可选择固定生成器以获得可复现的结果(效果同设置随机种子)。
dataset (Dataset) – 要划分的数据集。
lengths (sequence) – 要划分的长度。
generator (Generator) – 用于随机排列的生成器。
示例
代码:import torch
from torch.utils.data import random_split
dataset = range(10)
train_dataset, test_dataset = random_split(
dataset=dataset,
lengths=[7, 3],
generator=torch.Generator().manual_seed(0)
)
print(list(train_dataset))
print(list(test_dataset))
[8, 6, 2]
torch.Generator().manual_seed(0)和torch.manual_seed(0)的效果相同,我们验证一下。import torch
from torch.utils.data import random_split
dataset = range(10)
torch.manual_seed(0)
train_dataset, test_dataset = random_split(
dataset=dataset,
lengths=[7, 3]
)
print(list(train_dataset))
print(list(test_dataset))
[8, 6, 2]
1
2
引用参考
https://pytorch.org/docs/stable/data.html#torch.utils.data.random_split
————————————————
版权声明:本文为CSDN博主「Xavier Jiezou」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/qq_42951560/article/details/115445317笔记16:DataLoader的使用
torch.utils.data.Dataset是代表这一数据的抽象类(也就是基类)。我们可以通过继承和重写这个抽象类实现自己的数据类,只需要定义__len__和__getitem__这个两个函数。
DataLoader是Pytorch中用来处理模型输入数据的一个工具类。组合了数据集(dataset) + 采样器(sampler),并在数据集上提供单线程或多线程(num_workers )的可迭代对象。在DataLoader中有多个参数,这些参数中重要的几个参数的含义说明如下: 1. epoch:所有的训练样本输入到模型中称为一个epoch;
2. iteration:一批样本输入到模型中,成为一个Iteration;
3. batchsize:批大小,决定一个epoch有多少个Iteration;
4. 迭代次数(iteration)=样本总数(epoch)/批尺寸(batchszie)
5. dataset (Dataset) – 决定数据从哪读取或者从何读取;
6. batch_size (python:int, optional) – 批尺寸(每次训练样本个数,默认为1)
7. shuffle (bool, optional) –每一个 epoch是否为乱序 (default: False);
8. num_workers (python:int, optional) – 是否多进程读取数据(默认为0);
9. drop_last (bool, optional) – 当样本数不能被batchsize整除时,最后一批数据是否舍弃(default: False)
10. pin_memory(bool, optional) - 如果为True会将数据放置到GPU上去(默认为false)
由于tensorvision中自带了很多数据集,对于练手和神经网络的训练都十分有利,因此需要用Dataset和DataLoader来帮助我们学习。
2.1DataLoader的基础使用
通过查看PyTorch官网 中关于DataLoader类的介绍,所以这里以CIFAR10数据集的使用为例子,简单介绍DataLoader的使用。# coding :UTF-8
# 文件功能: 代码实现dataloader类的基本功能
# 开发人员: dpp
# 开发时间: 2021/8/13 12:10 上午
# 文件名称: dataloader_test.py.py
# 开发工具: PyCharm
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集 数据放在了CIFAR10文件夹下
test_data = torchvision.datasets.CIFAR10("./CIFAR10", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
# coding :UTF-8
# 文件功能: 代码实现dataloader类的基本功能
# 开发人员: dpp
# 开发时间: 2021/8/13 12:10 上午
# 文件名称: dataloader_test.py.py
# 开发工具: PyCharm
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集 数据放在了CIFAR10文件夹下
test_data = torchvision.datasets.CIFAR10("./CIFAR10", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
# 测试数据集中第一张图片及target
img, target = test_data[0]
print(img.shape)
print(target)
# 在定义test_loader时,设置了batch_size=4,表示一次性从数据集中取出4个数据
for data in test_loader:
imgs, targets = data
print(imgs.shape)
print(targets)
# coding :UTF-8
# 文件功能: 代码实现dataloader类的基本功能
# 开发人员: dpp
# 开发时间: 2021/8/13 12:10 上午
# 文件名称: dataloader_test.py.py
# 开发工具: PyCharm
import torchvision
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
# 准备的测试数据集 数据放在了CIFAR10文件夹下
test_data = torchvision.datasets.CIFAR10("./CIFAR10", train=False, transform=torchvision.transforms.ToTensor())
test_loader = DataLoader(dataset=test_data, batch_size=4, shuffle=True, num_workers=0, drop_last=False)
# 在定义test_loader时,设置了batch_size=4,表示一次性从数据集中取出4个数据
writer = SummaryWriter("logs")
for epoch in range(2):
step = 0
for data in test_loader:
imgs, targets = data
writer.add_images("Epoch: {}".format(epoch), imgs, step)
step = step + 1
writer.close()
在本文中总结了DataLoader的使用方法,并通过读取CIFAR10中的数据,借助Tensorboard的展示各种参数的功能,能为后续神经网络的训练奠定基础,同时也能更好的理解pytorch。
————————————————
版权声明:本文为CSDN博主「我这一次」的原创文章,遵循CC 4.0 BY-SA版权协议,转载请附上原文出处链接及本声明。
原文链接:https://blog.csdn.net/weixin_43981621/article/details/119685671二、构建简单的CNN网络
import torch.nn.functional as F
class Network_bn(nn.Module):
def __init__(self):
super(Network_bn, self).__init__()
"""
nn.Conv2d()函数:
第一个参数(in_channels)是输入的channel数量
第二个参数(out_channels)是输出的channel数量
第三个参数(kernel_size)是卷积核大小
第四个参数(stride)是步长,默认为1
第五个参数(padding)是填充大小,默认为0
"""
self.conv1 = nn.Conv2d(in_channels=3, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn1 = nn.BatchNorm2d(12)
self.conv2 = nn.Conv2d(in_channels=12, out_channels=12, kernel_size=5, stride=1, padding=0)
self.bn2 = nn.BatchNorm2d(12)
self.pool = nn.MaxPool2d(2,2)
self.conv4 = nn.Conv2d(in_channels=12, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn4 = nn.BatchNorm2d(24)
self.conv5 = nn.Conv2d(in_channels=24, out_channels=24, kernel_size=5, stride=1, padding=0)
self.bn5 = nn.BatchNorm2d(24)
self.fc1 = nn.Linear(24*50*50, len(classeNames))
def forward(self, x):
x = F.relu(self.bn1(self.conv1(x)))
x = F.relu(self.bn2(self.conv2(x)))
x = self.pool(x)
x = F.relu(self.bn4(self.conv4(x)))
x = F.relu(self.bn5(self.conv5(x)))
x = self.pool(x)
x = x.view(-1, 24*50*50)
x = self.fc1(x)
return x
device = "cuda" if torch.cuda.is_available() else "cpu"
print("Using {} device".format(device))
model = Network_bn().to(device)
model
Network_bn(
(conv1): Conv2d(3, 12, kernel_size=(5, 5), stride=(1, 1))
(bn1): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv2): Conv2d(12, 12, kernel_size=(5, 5), stride=(1, 1))
(bn2): BatchNorm2d(12, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv4): Conv2d(12, 24, kernel_size=(5, 5), stride=(1, 1))
(bn4): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(conv5): Conv2d(24, 24, kernel_size=(5, 5), stride=(1, 1))
(bn5): BatchNorm2d(24, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(fc1): Linear(in_features=60000, out_features=2, bias=True)
)
三、 训练模型
loss_fn = nn.CrossEntropyLoss() # 创建损失函数
learn_rate = 1e-4 # 学习率
opt = torch.optim.SGD(model.parameters(),lr=learn_rate)
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
# 训练循环
def train(dataloader, model, loss_fn, optimizer):
size = len(dataloader.dataset) # 训练集的大小,一共60000张图片
num_batches = len(dataloader) # 批次数目,1875(60000/32)
train_loss, train_acc = 0, 0 # 初始化训练损失和正确率
for X, y in dataloader: # 获取图片及其标签
X, y = X.to(device), y.to(device)
# 计算预测误差
pred = model(X) # 网络输出
loss = loss_fn(pred, y) # 计算网络输出和真实值之间的差距,targets为真实值,计算二者差值即为损失
# 反向传播
optimizer.zero_grad() # grad属性归零
loss.backward() # 反向传播
optimizer.step() # 每一步自动更新
# 记录acc与loss
train_acc += (pred.argmax(1) == y).type(torch.float).sum().item()
train_loss += loss.item()
train_acc /= size
train_loss /= num_batches
return train_acc, train_loss
def test (dataloader, model, loss_fn):
size = len(dataloader.dataset) # 测试集的大小,一共10000张图片
num_batches = len(dataloader) # 批次数目,313(10000/32=312.5,向上取整)
test_loss, test_acc = 0, 0
# 当不进行训练时,停止梯度更新,节省计算内存消耗
with torch.no_grad():
for imgs, target in dataloader:
imgs, target = imgs.to(device), target.to(device)
# 计算loss
target_pred = model(imgs)
loss = loss_fn(target_pred, target)
test_loss += loss.item()
test_acc += (target_pred.argmax(1) == target).type(torch.float).sum().item()
test_acc /= size
test_loss /= num_batches
return test_acc, test_loss
4. 正式训练epochs = 20
train_loss = []
train_acc = []
test_loss = []
test_acc = []
for epoch in range(epochs):
model.train()
epoch_train_acc, epoch_train_loss = train(train_dl, model, loss_fn, opt)
model.eval()
epoch_test_acc, epoch_test_loss = test(test_dl, model, loss_fn)
train_acc.append(epoch_train_acc)
train_loss.append(epoch_train_loss)
test_acc.append(epoch_test_acc)
test_loss.append(epoch_test_loss)
template = ('Epoch:{:2d}, Train_acc:{:.1f}%, Train_loss:{:.3f}, Test_acc:{:.1f}%,Test_loss:{:.3f}')
print(template.format(epoch+1, epoch_train_acc*100, epoch_train_loss, epoch_test_acc*100, epoch_test_loss))
print('Done')
Epoch: 1, Train_acc:62.2%, Train_loss:0.672, Test_acc:65.3%,Test_loss:0.627
Epoch: 2, Train_acc:68.1%, Train_loss:0.606, Test_acc:69.0%,Test_loss:0.578
Epoch: 3, Train_acc:70.5%, Train_loss:0.564, Test_acc:72.7%,Test_loss:0.542
Epoch: 4, Train_acc:75.9%, Train_loss:0.505, Test_acc:73.4%,Test_loss:0.539
Epoch: 5, Train_acc:76.5%, Train_loss:0.490, Test_acc:71.1%,Test_loss:0.547
Epoch: 6, Train_acc:79.1%, Train_loss:0.452, Test_acc:73.9%,Test_loss:0.527
Epoch: 7, Train_acc:81.3%, Train_loss:0.436, Test_acc:75.1%,Test_loss:0.490
Epoch: 8, Train_acc:83.9%, Train_loss:0.405, Test_acc:76.5%,Test_loss:0.472
Epoch: 9, Train_acc:84.9%, Train_loss:0.388, Test_acc:78.1%,Test_loss:0.465
Epoch:10, Train_acc:85.6%, Train_loss:0.374, Test_acc:74.1%,Test_loss:0.521
Epoch:11, Train_acc:87.7%, Train_loss:0.356, Test_acc:77.6%,Test_loss:0.438
Epoch:12, Train_acc:87.9%, Train_loss:0.344, Test_acc:79.3%,Test_loss:0.434
Epoch:13, Train_acc:89.3%, Train_loss:0.331, Test_acc:79.0%,Test_loss:0.447
Epoch:14, Train_acc:89.0%, Train_loss:0.323, Test_acc:79.7%,Test_loss:0.434
Epoch:15, Train_acc:89.4%, Train_loss:0.319, Test_acc:79.3%,Test_loss:0.432
Epoch:16, Train_acc:90.0%, Train_loss:0.299, Test_acc:80.9%,Test_loss:0.420
Epoch:17, Train_acc:90.8%, Train_loss:0.288, Test_acc:80.2%,Test_loss:0.411
Epoch:18, Train_acc:91.9%, Train_loss:0.282, Test_acc:79.3%,Test_loss:0.404
Epoch:19, Train_acc:91.5%, Train_loss:0.273, Test_acc:80.2%,Test_loss:0.397
Epoch:20, Train_acc:91.7%, Train_loss:0.266, Test_acc:80.2%,Test_loss:0.397
Done
import matplotlib.pyplot as plt
#隐藏警告
import warnings
warnings.filterwarnings("ignore") #忽略警告信息
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
plt.rcParams['figure.dpi'] = 100 #分辨率
epochs_range = range(epochs)
plt.figure(figsize=(12, 3))
plt.subplot(1, 2, 1)
plt.plot(epochs_range, train_acc, label='Training Accuracy')
plt.plot(epochs_range, test_acc, label='Test Accuracy')
plt.legend(loc='lower right')
plt.title('Training and Validation Accuracy')
plt.subplot(1, 2, 2)
plt.plot(epochs_range, train_loss, label='Training Loss')
plt.plot(epochs_range, test_loss, label='Test Loss')
plt.legend(loc='upper right')
plt.title('Training and Validation Loss')
plt.show()

6. 指定图片进行预测
⭐torch.squeeze()详解
对数据的维度进行压缩,去掉维数为1的的维度
函数原型:
torch.squeeze(input, dim=None, *, out=None)
关键参数说明:
input (Tensor):输入Tensor
dim (int, optional):如果给定,输入将只在这个维度上被压缩
实战案例:
⭐torch.unsqueeze()
对数据维度进行扩充。给指定位置加上维数为一的维度
函数原型:
torch.unsqueeze(input, dim)
关键参数说明:
input (Tensor):输入Tensor
dim (int):插入单例维度的索引
实战案例:# 预测训练集中的某张照片
predict_one_image(image_path='./4-data/Monkeypox/M01_01_00.jpg',
model=model,
transform=train_transforms,
classes=classes)
五、保存并加载模型# 模型保存
PATH = './model.pth' # 保存的参数文件名
torch.save(model.state_dict(), PATH)
# 将参数加载到model当中
model.load_state_dict(torch.load(PATH, map_location=device))