yolov4
yolov4
百度网盘ppt:https://pan.baidu.com/s/1lDHreC-iCR9jQ7WyDhx0qA?_at_=1624432312136
提取码:7c28
YOLO-v4算法是在原有YOLO目标检测架构的基础上,采用了近些年CNN领域中最优秀的优化策略,从数据处理、主干网络、网络训练、激活函数、损失函数等各个方面都有着不同程度的优化,没有理论上的创新。
①论文主要有以下三点贡献:
1.开发了一个高效而强大的模型,使得任何人都可以使用一张1080Ti或者2080Ti GPU去训练一个超级快速和精确的目标检测器。
2.验证了一系列state-of-the-art的目标检测器训练方法的影响。
3.修改了state-of-the-art方法,使得他们在使用单个GPU进行训练时更加有效和适配,包括CBN,PAN,SAM等。
②作者把训练的方法分成了两类:
1.Bag of freebies:只改变训练策略或者只增加训练成本,比如数据增强。
2.Bag of specials:插件模块和后处理方法,它们仅仅增加一点推理成本,但是可以极大地提升目标检测的精度。
0 摘要
目前有很多可以提高CNN准确性的算法。这些算法的组合在庞大数据集上进行测试、对实验结果进行理论验证都是非常必要的。有些算法只在特定的模型上有效果,并且只对特定的问题有效,或者只对小规模的数据集有效;然而有些算法,比如batch-normalization和residual-connections,对大多数的模型、任务和数据集都适用。我们认为这样通用的算法包括:Weighted-Residual-Connections(WRC), Cross-Stage-Partial-connections(CSP), Cross mini-Batch Normalization(CmBN), Self-adversarial-training(SAT)以及Mish-activation。我们使用了新的算法:WRC, CSP, CmBN, SAT, Mish activation, Mosaic data augmentation, CmBN, Dropblock regularization 和CIoU loss以及它们的组合,获得了最优的效果:在MS COCO数据集上的AP值为43.5%(65.7% AP50),在Tesla V100上的实时推理速度为65FPS。
1 介绍
大部分基于CNN的目标检测器主要只适用于推荐系统。举例来说,通过城市相机寻找免费停车位置的系统使用着慢速但是高精度的模型,然而汽车碰撞警告却使用着快速但是低精度的模型。提高实时目标检测器的精度不经能够应用在推荐系统上,而且还能用于独立的流程管理以及降低人员数量上。目前大部分高精度的神经网络不仅不能实时运行,并且需要较大的mini-batch-size在多个GPUs上进行训练。我们构建了仅在一块GPU上就可以实时运行的CNN解决了这个问题,并且它只需要在一块GPU上进行训练。
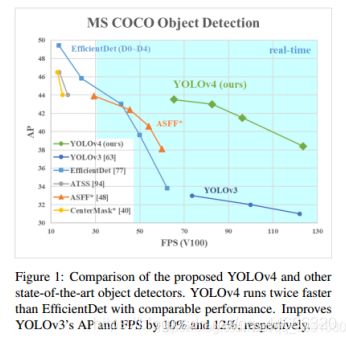
我们工作的主要目标就是设计一个仅在单个计算系统(比如单个GPU)上就可以快速运行的目标检测器并且对并行计算进行优化,并非减低计量计算量理论指标(BFLOP)。我们希望这个检测器能够轻松的训练和使用。具体来说就是任何一个人仅仅使用一个GPU进行训练和测试就可以得到实时的,高精度的以及令人信服的目标检测结果,正如在图片1中所示的YOLOv4的结果。我们的贡献总结如下:
(1)我们提出了一个高效且强大的目标检测模型。任何人可以使用一个1080Ti或者2080Ti的GPU就可以训练出一个快速并且高精度的目标检测器。
(2)我们在检测器训练的过程中,测试了目标检测中最高水准的Bag-of-Freebies和Bat-of-Specials方法。
(3)我们改进了最高水准的算法,使得它们更加高效并且适合于在一个GPU上进行训练,比如CBN, PAN, SAM等。
2 相关工作
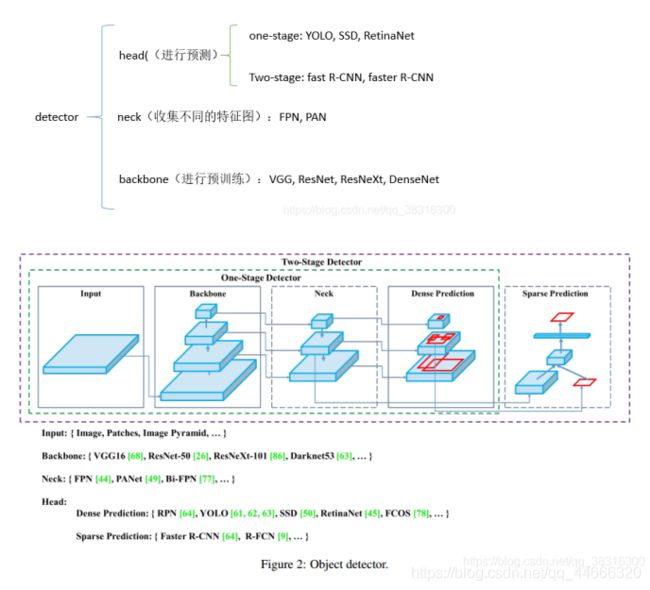
2.1 目标检测模型
检测器通常由两部分组成:backbone和head。前者在ImageNet上进行预训练,后者用来预测类别信息和目标物体的边界框。在GPU平台上运行的检测器,它们的backbone可能是VGG, ResNet, ResNetXt,或者是DenseNet。在CPU平台上运行的检测器,它们的backbone可能是SqueezeNet,MobileNet或者是ShuffleNet。对于head部分,通常分为两类:one-stage和two-stage的目标检测器。Two-stage的目标检测器的代表是R-CNN系列,包括:fast R-CNN, faster R-CNN,R-FCN和Libra R-CNN. 还有基于anchor-free的Two-stage的目标检测器,比如RepPoints。One-stage目标检测器的代表模型是YOLO, SSD和RetinaNet。在最近几年,出现了基于anchor-free的one-stage的算法,比如CenterNet, CornerNet, FCOS等等。在最近几年,目标检测器在backbone和head之间会插入一些网络层,这些网络层通常用来收集不同的特征图。我们将其称之为目标检测器的neck。通常,一个neck由多个bottom-up路径和top-down路径组成。使用这种机制的网络包括Feature Pyramid Network(FPN),Path Aggregation Network(PAN),BiFPN和NAS-FPN。

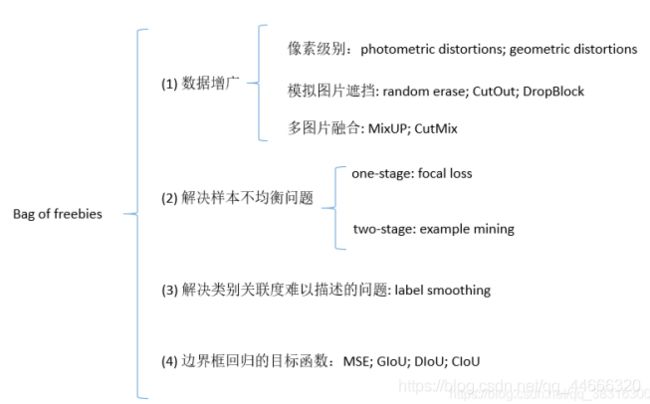
2.2 Bag of freebies
通常来说,目标检测器都是进行离线训练的(训练的时候对GPU数量和规格不限制)。因此,研究者总是喜欢扬长避短,使用最好的训练手段,因此可以在不增加推理成本的情况下,获得最好的检测精度。我们将只改变训练策略或者只增加训练成本的方法称之为“bag of freebies"。在目标检测中经常使用并且满足bag of freebies的定义的算法称是①数据增广。数据增广的目的是增加输入图片的可变性,因此目标检测模型对从不同场景下获取的图片有着更高的鲁棒性。举例来说,photometric distoitions和geometric distortions是用来数据增强方法的两个常用的手段。在处理photometric distortion中,我们会调整图像的亮度,对比度,色调,饱和度以及噪声。对于geometric distortion,我们会随机增加尺度变化,裁剪,翻转以及旋转。
上面提及的数据增广的手段都是像素级别的调整,它保留了调整区域的所有原始像素信息。此外,一些研究者将数据增广的重点放在了②模拟目标物体遮挡问题上。他们在图像分类和目标检测上已经取得了不错的结果。具体来说,random erase和CutOut可以随机选择图像上的矩形区域,然后进行随机融合或者使用零像素值来进行融合。对于hide-and-seek和grid mask,他们随机地或者均匀地在一幅图像中选择多个矩形区域,并且使用零来代替矩形区域中的像素值。如果将相似的概念用来特征图中,出现了DropOut, DropConnect和DropBlock方法。此外,一些研究者提出一起使用多张图像进行数据增强的方法。举例来说,MixUp使用两张图片进行相乘并且使用不同的系数比进行叠加,然后使用它们的叠加比来调整标签。对于CutMix,它将裁剪的图片覆盖到其他图片的矩形区域,然后根据混合区域的大小调整标签。除了上面提及的方法,style transfer GAN也用来数据增广,CNN可以学习如何有效的减少纹理偏差。
一些和上面所提及的不同的方法用来解决数据集中的语义分布可能存在偏差的问题。处理语义分布偏差的问题,一个非常重要的问题就是在不同类别之间存在数据不平衡,并且这个问题在two-stage目标检测器中,通常使用hard negative example mining或者online hard example mining来解决。但是example mining 方法并不适用于one-stage的目标检测器,因为这种类型的检测器属于dense prediction架构。因此focal loss算法用来解决不同类别之间数据不均衡的问题。③另外一个非常重要的问题就是使用one-hot很难描述不同类别之间关联度的关系。Label smothing提出在训练的时候,将hard label转换成soft label,这个方法可以使得模型更加的鲁棒性。为了得到一个最好的soft label, Islam引入了知识蒸馏的概念来设计标签细化网络。

在深度学习的研究中,一些人重点关心去寻找一个优秀的激活函数。一个优秀的激活函数可以让梯度更有效的进行传播,与此同时它不会增加额外的计算量。在2010年,Nair和Hinton提出了ReLU激活函数充分地解决了梯度消失的问题,这个问题在传统的tanh和sigmoid激活函数中会经常遇到。随后,LReLU,PReLU,ReLU6,Scaled Exponential Linear Unit(SELU),Swish, hard-Swish和Mish等等相继提出,它们也用来解决梯度消失的问题。LReLU和PReLU主要用来解决当输出小于零的时候,ReLU的梯度为零的问题。ReLU6和hard-Swish主要为量化网络而设计。对于神经网络的自归一化,提出SELU激活函数去实现这个目的。需要注意的是Swish和Mish都是连续可导的激活函数。

3 方法
我们工作基本的目标就是在生产系统和优化并行预算中加快神经网络的速度,而非降低计算量理论指标(BFLOP)。我们提供了两个实时神经网络的选择:
(1)GPU 在卷积层中,我们使用少量的组(1-8): CSPResNeXt50 / CSPDarknet53;
(2)VPU 我们使用分组卷积,但是我们不使用Squeeze-and-excitement(SE)模块,具体包括以下模型:EfficientNet-lite / MixNet / GhostNet / MobileNetV3。
3.1 网络架构的选择

3.3 额外的改进
为了让检测器更适合在单个GPU上进行训练,我们做了以下额外的设计和改进:
(1)我们提出了数据增广的新的方法:Mosaic和Self-Adversarial Training(SAT);
(2)在应用遗传算法去选择最优的超参数;
(3)我们改进了一些现有的算法,让我们的设计更适合高效的训练和检测 - 改进SAM, 改进PAN以及Cross mini-Batch Normalization(CmBN);
自适应对抗训练(SAT)也表示了一个新的数据增广的技巧,它在前后两阶段上进行操作。在第一阶段,神经网络代替原始的图片而非网络的权重。用这种方式,神经网络自己进行对抗训练,代替原始的图片去创建图片中此处没有期望物体的描述。在第二阶段,神经网络使用常规的方法进行训练,在修改之后的图片上检测物体。
3.4 YOLOv4

6 结论
我们提出了一个最先进的目标检测器,它比所有检测器都要快而且更准确。这个检测器可以仅在一块8-16GB的GPU上进行训练,这使得它可以广泛的使用。One-stage的anchor-based的检测器的原始概念证明是可行的。我们已经验证了大量的特征,并且其用于提高分类器和检测器的精度。这些算法可以作为未来研究和发展的最佳实践。
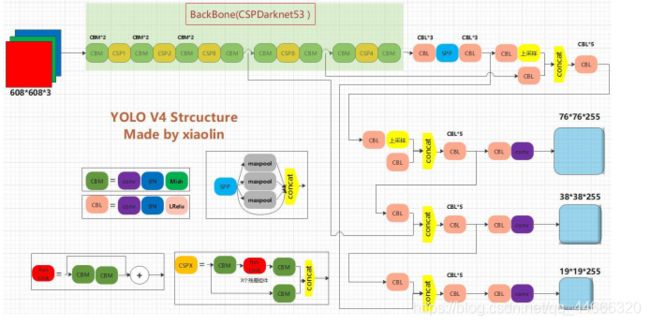
基本组件
上图三个蓝色方框内表示Yolov3的三个基本组件:
CBL:Yolov3网络结构中的最小组件,由Conv+Bn+Leaky_relu激活函数三者组成。
Res unit:借鉴Resnet网络中的残差结构,让网络可以构建的更深。
ResX:由一个CBL和X个残差组件构成,是Yolov3中的大组件。每个Res模块前面的CBL都起到下采样的作用,因此经过5次Res模块后,得到的特征图是608->304->152->76->38->19大小。
其他基础操作
Concat:张量拼接,会扩充两个张量的维度,例如2626256和2626512两个张量拼接,结果是2626768。Concat和cfg文件中的route功能一样。
add:张量相加,张量直接相加,不会扩充维度,例如104104128和104104128相加,结果还是104104128。add和cfg文件中的shortcut功能一样。
Backbone中卷积层的数量
每个ResX中包含1+2xX个卷积层,因此整个主干网络Backbone中一共包含1+(1+2x1)+(1+2x2)+(1+2x8)+(1+2x8)+(1+2x4)=52,再加上一个FC全连接层,即可以组成一个Darknet53分类网络。不过在目标检测Yolov3中,去掉FC层,不过为了方便称呼,仍然把Yolov3的主干网络叫做Darknet53结构。
网络结构详细可视化
如下图以416x416x3输入为例

YoloV4的4个创新部分总述
输入端:这里指的创新主要是训练时对输入端的改进,主要包括Mosaic数据增强、cmBN、SAT自对抗训练;
BackBone主干网络:将各种新的方式结合起来,包括:CSPDarknet53、Mish激活函数、Dropblock;
Neck:目标检测网络在BackBone和最后的输出层之间往往会插入一些层,比如Yolov4中的SPP模块、FPN+PAN结构;
Prediction:输出层的锚框机制和Yolov3相同,主要改进的是训练时的损失函数CIOU_Loss,以及预测框筛选的nms变为DIOU_nms。
参考文献,内容来源于一下参考文献,仅作为本人学习记录!
https://zhuanlan.zhihu.com/p/137393450
https://blog.csdn.net/qq_38316300/article/details/105759305
https://blog.csdn.net/andyjkt/article/details/107590669
https://www.cnblogs.com/icetree/p/13111746.html