CentOS 7配置Hadoop3.X环境 附部分原理说明
需要工具:
VMware, jdk, centOS7, hadoop,Mobaxterm (或其他终端如Xshell)
Ⅰ.准备工作:虚拟机安装
CentOS操作系统(Linux) 官网链接: The CentOS Project
VMware虚拟机 自行下载
-
CentOS安装建议选用以下安装方式:
图形化界面更直观 后续方便VMtools等工具使用 (复制粘贴文本 等主机交互命令)
桌面模式下设置root直接登录:
CentOS7自动以root身份登陆gnome桌面_DanylZhang的博客-CSDN博客_gnome root登录
-
设置和主机互传文件 (VMtools设置共享文件)(如果安装终端则不需要这步)
安装VMware:
如何给CentOS 安装Vmware Tools(Linux桌面版安装)_键盘林的博客-CSDN博客_centos安装vmware tools
设置共享文件夹后 在Linux内/mnt/hgfs/目录下能找到共享文件
一些方便的命令(/快捷键):
#centOS默认上下翻页
shift + pgUp
shift + pgDn
#linux一些命令(快捷键)
输入智能补全: "Alt+/" 或者 "Tab"键
查看文件:cat 文件名
#修改文件时间属性,若文件不存在则新建文件
touch fileCentOS最常用命令及快捷键整理_腾讯数据架构师的博客-CSDN博客
Ⅱ.开始配置:ip设置
这里使用NAT模式(地址转换模式,不需要和主机网关相同)
虚拟机VMware三种网络模式工作原理和配置:
虚拟机网络ip设置 - 今天也是阳光正好 - 博客园
以下三个界面都需要设置
-
VMware界面
进入虚拟网络编辑器

查看上图VMnet8(虚拟交换机)的子网ip地址 (记录或者自行设置)
第三个网段可以随便设置 (如果更改了,需要在NAT设置里同样更改网关的第三个网段

子网ip:是和后面的子网掩码一起来确定网段,以及网段里可使用的IP数
(虚拟出的局域网)
-
Windows界面
1. 找到VMnet8 (虚拟网卡) 主机与虚拟机的通信接口(不用来联网)
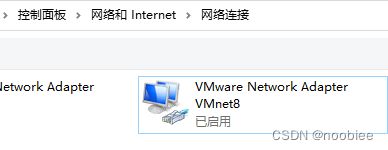
2.设置IP地址和虚拟网络子网网段一致
附:NAT模式原理图解

-
Linux界面
1. 设置静态ip (以免每次开虚拟机重设ip)
vim /etc/sysconfig/network-scripts/ifcfg-ens33BOOTPROTO改为static,ONBOOT改为yes,后续添加IP,网关,DNS (要注意和前面网段设置一致)
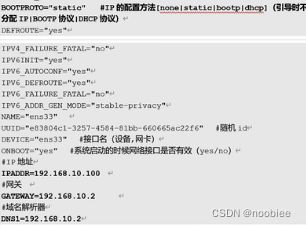
2. 修改主机和ip映射 (以免相同主机使用时需要修改多个ip地址)
vim /etc/hosts添加 主机名 + ip地址:
hadoop100 192.168.10.100
hadoop101 192.168.10.101
hadoop102 192.168.10.102附:一些Linux命令
#进入root用户
su root
#重置root密码
sudo passwd
#查看ip
ifconfig
#查看主机名
hostname
#永久修改主机名为XXX
hostnamectl set-hostname XXX
#主机和ip映射 伪分布下只有主机
vi /etc/hosts以上全部设置完后测试一下:
#外网
ping www.baidu.com
#内网
ping 物理机ip
#物理机连虚拟机
ping 192.168.10.100Ⅲ.使用终端管理多台虚拟机(可选)
使用Mobaxterm终端对节点同时管理 (通过SSH连接)
可以通过Mobaxterm终端实现文件上传

关闭防火墙:保证多节点通讯顺畅
例如物理机web访问虚拟机hadoop服务时
Centos7防火墙firewalld的基本配置操作和基本常用命令合集_Dong hua的博客-CSDN博客_centos7防火墙配置命令
systemctl status firewalld 查看防火墙状态
systemctl stop firewalled 临时关闭防火墙
systemctl disable firewalld 彻底关闭防火墙开启SSH服务 (免密登录):主机间免密通信
虚拟机不同用户也需要各自设置ssh
cd ~/.ssh
#生成公钥
ssh-keygen -t rsa
#放到目标机器上(本地也需要)
ssh-copy-id -i ~/.ssh/id_rsa.pubssh原理:结合Hadoop,简单理解SSH - jiapeng - 博客园
centos7开启ssh服务_想做一个开森的胖纸的博客-CSDN博客_centos7 ssh
Ⅳ.配置JDK
-
卸载/下载jdk
#进入根用户
su root先卸载系统自带jdk (openjdk不能使用javac) (最小安装不需要删)
#查看
java -version
#查找含有java的文件
rpm -qa | grep java
#删除XXX和所有依赖包(慎用)
yum -y remove XXX
#只删除XXX
rpm -e --nodeps XXX【Linux】CentOS7下安装JDK详细过程 - Angel挤一挤 - 博客园
yum 安装jdk (devel 版本) 或者官网下载
#查看可安装jdk
yum search java|grep jdk
#安装XXX 这里是jdk1.8 dlevel (支持javac)
yum install -y XXX官网下载压缩包后解压
tar -zxvf 文件名.tar.gz-
配置jdk环境变量
linux有多个入口可用来配置环境变量:
linux系统中的profile、bashrc、~/.bash_profile、~/.bashrc、~/.bash_profile之间的区别和联系以及执行的顺序_裁二尺秋风的博客-CSDN博客
这里使用 .bach_profile:
#到根目录
cd ~
#打开.bash_profile文件
vi .bash_profile
#插入以下
export JAVA_HOME=/app/java/jdk1.8
export CLASSPATH=.:$JAVA_HOME/lib/dt.jar:$JAVA_HOME/lib/tools.jar
export PATH=$PATH:$JAVA_HOME/bin
#保存退出后,执行以下命令使配置生效
source ~/.bash_profile
#完成后检查
java -versionHadoop安装/配置
环境配置:
sudo vim /etc/profile.d/my_env.sh
#HADOOP_HOME
export HADOOP_HOME=/opt/module/hadoop-3.1.3 #具体路径是你自己的
export PATH=$PATH:$HADOOP_HOME/bin
export PATH=$PATH:$HADOOP_HOME/sbin
#单节点还需要配置如下:
export HDFS_NAMENODE_USER=root
export HDFS_DATANODE_USER=root
export HDFS_SECONDARYNAMENODE_USER=root
export YARN_RESOURCEMANAGER_USER=root
export YARN_NODEMANAGER_USER=root
#生效
source /etc/profile
#配置完后检查
hadoop version附: Hadoop运行模式:
单机模式(独立模式)(Local或Standalone Mode)
-使用本地文件系统,而不是分布式文件系统。
-Hadoop不会启动NameNode、DataNode、JobTracker、TaskTracker等守护进程,Map()和Reduce()任务作为同一个进程的不同部分来执行的。
-用于对MapReduce程序的逻辑进行调试,确保程序的正确。
伪分布式模式(Pseudo-Distrubuted Mode)
-Hadoop的守护进程运行在本机机器,模拟一个小规模的集群
-在一台主机模拟多主机。
全分布式集群模式(Full-Distributed Mode)
Hadoop文件配置 (只用单机/独立模式则不需要配置) (注意根据需要调整value):
core-site.xml:
fs.defaultFS
hdfs://hadoop100:9000
hadoop.tmp.dir
${HADOOP_HOME}/data/tmp
hdfs-site.xml:
dfs.replication
2
dfs.secondary.http.address
hadoop102:9870
mapred-site.xml:
mapreduce.framework.name
yarn
mapreduce.jobhistory.address
hadoop101:10020
mapreduce.jobhistory.webapp.address
hadoop101:19888
yarn.log-aggregation-enable
true
yarn.log-aggregation.retain-seconds
604800
yarn-site.xml:
yarn.nodemanager.aux-services
mapreduce_shuffle
yarn.resourcemanager.hostname
hadoop101
yarn.nodemanager.resource.memory-mb
20480
yarn.scheduler.minimum-allocation-mb
2048
yarn.nodemanager.vmem-pmem-ratio
2.1
配置完成后初始化hadoop:
hdfs namenode -format
hdfs datanode -format
开启服务:
#namenode和datanode的开关指令:
hdfs --daemon start/stop namenode/datanode
#resourcemanager和nodemanager的开关指令:
yarn --daemon start/stop resourcemanager/nodemanager
#historyserver的开关指令:
mapred --daemon start/stop historyserverⅤ.Hadoop设置伪分布模式(Pseudo-Distributed Operation)
伪分布模式:只有一台主机机器
对Hadoop相关文件进行配置
Centos之hadoop伪分布模式_大树下躲雨的博客-CSDN博客
Centos7 安装Hadoop (HDFS) 及HDFS的启动 - 九月江 - 博客园
启动服务后web管理页面:
http://localhost:8088
http://localhost:9870
Ⅵ. Hadoop设置全分布模式
1. 克隆虚拟机 (关闭防火墙, 静态ip, 主机名)
设置ens33的ip 和 设置hostname
- 编写集群分发脚本xsync(文件拷贝)[这步一般拷贝jdk或hadoop到其他虚拟机]
#scp(secure copy)安全拷贝
scp -r file/path user@host:path/file
scp -r 文件路径/名称 目的地用户@主机:文件路径/名称
#rsync 文件远程同步:只对差异文件更新
rsync -av file/path user@host:path/file
#xsync 集群分发脚本:循环复制文件到所有节点相同目录下
#依赖rsync编写的脚本2. 终端(Mobaxterm)内添加ssh
(可以在物理机host文件中设置ip映射)
另:简单版本:windows本地单节点配置Hadoop(伪分布)
仅需下载jdk和hadoop然后配置hadoop相关文件即可
Windows安装使用Hadoop3.0.0_weixin_33843409的博客-CSDN博客
winutils指路:Windows本地IDEA运行mapreduce报错java.io.FileNotFoundException: HADOOP_HOME and hadoop.home.dir are unset._noobiee的博客-CSDN博客
HDFS文件系统的本地位置?
Hadoop中HDFS的文件到底存储在集群节点本地文件系统哪里_YuanOo。的博客-CSDN博客_hdfs在哪里
图解HDFS存储原理:
hadoop文件存储位置_Hadoop——HDFS_子月二二的博客-CSDN博客
References
CentOS安装Hadoop - 玄同太子 - 博客园
Hadoop运行模式-完全分布式模式_weixin_47621995的博客-CSDN博客
Hadoop3.x配置流程(Linux) - 知乎