encoder, decoder, attention机制理解
1.encoder-decoder
在提attention之前,我们先回顾一下encoder-decoder机制。
encoder-decoder在NLP领域的使用会比较广泛,按照我个人的理解,encoder-decoder本质上是一种思维方式,一种框架。encoder环节,将现实输入环节进行抽象编码转化为一个数学问题。decoder环节,则是求解该数学问题,并转化为现实世界的答案。
而输入环节输入的不同,则代表了不同的应用场景。
如果输入是中文句子,输出是英文翻译,则是典型的机器翻译问题,encoder-decoder框架在该领域的应用也最为深入。
如果输入是问题,输出是答案,那这就是典型的对话系统或者自动客服服务系统。
如果输入是一篇文章,输出是一段文字总结,那这就是文本摘要系统。
如果输入是一张图片,输出是对该图片的描述,那这就是看图说话。
如果输入是一段语音,输出是语音对应的句子,那这就是语音识别。
…
等等,还有许多场景。
2.encoder-decoder
相信大家都见过下面这张图,为了避免版权问题,自己用画图软件重新画了一遍,也更加清晰。
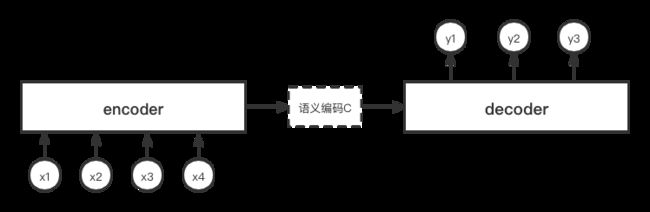
上面这张图就比较简单清楚地描述了encoder-decoder框架的过程。比如对于一个机器翻译系统,输入x1, x2, x3, x4是一个句子,先对其进行编码,会得到一个中间语义向量c,然后在decoder端解码,得到结果y1, y2, y3。而其中的编码器、解码器的网络结构,可以使用传统的像rnn, lstm等结构。
不难看出来,encoder-decoder框架的优点比较明显:
1.可以高效处理变长序列问题。
2.如果输入是像图片这种维度很高的数据,可以达到降维的目的。
3.学习方式为end-to-end。
3.为什么要attention
上面的encoder-decoder框架,有一个缺点也很明显:
encoder把所有的输入,最后边变成了一个统一的特征向量C,再去decoder解码。很明显,系统的性能瓶颈就在C这里,要求C不能包含原始输入的所有信息,最后的效果就要打折扣。比如说机器翻译问题,如果要翻译的句子或者文章很长,C的表达能力,无法涵盖原来句子所有信息,那么翻译精度会大打折扣。
如果我们模仿人脑的思考问题方式,人的大脑在工作的时候,其实是有一定注意力区域的。比如我们观察某一张图片,很容易找到一张图片中最显著的位置。浏览某个网页的时候,也是习惯性看左上方的位置,所以搜索引擎的设计也是搜索结果放在左上方方便查看。因此,我们同样可以将这一思维过程运行到神经网络中来。
具体来说,attention机制通过在每个时间输入不同的中间向量C,来模拟不同时间注意力不同的问题。举个翻译的例子:我们要翻译knowledge is power这句话,知识就是力量。对应的知识这个结果,只需将注意力放在源句中knowledge的部分,is power两个词的贡献度很小。这样,当我们decoder去解码预测最终结果的时候,不仅可以看到原句encoder完毕的所有信息,而且可以不仅仅依赖于原来的定长向量C, 从而提高整个翻译的精度。
用一张图来表示与encoder-decoder框架的区别,如下所示。

从上面的结构可以看出,attention的核心改变,是将之前的定长向量C,变成了不同时刻输入不同向量C1, C2, C3。所以,attention的核心也就变成了如果去计算向量C1, C2, C3。
4.attention注意力计算
为了让计算过程更为清晰明了,我们将encoder, decoder过程中的隐变量展开,再画两幅图:


上面图为encoder-decoder框架,下面图为attention机制。
对于传统的encoder-decoder框架,解码器decode某一时间的隐状态输出,只与上一时间的隐状态输出有关。而对于attention来讲,还与当前时刻的上下文向量C有关系。C是通过encoder中所有时间隐藏状态的加权平均得到的。而加权使用的权值,是根据编码时刻的隐含状态与当前解码时刻的隐含状态相似度计算出来。这样在当前时刻解码,网络就能将“注意力”尽可能多的集中于对应编码时刻的隐含状态。
具体的计算逻辑如下:
e j i = s c o r e ( h i i n , h j o u t ) α j i = e j i ∑ i e j i c j = ∑ i α j i h i i n h j o u t + 1 = f ( h j o u t , c j ) \begin{aligned} e_{ji} &= score(h_i^{in}, h_j^{out}) \\ \alpha_{ji} &= \frac{e_{ji}}{\sum_i e_{ji}} \\ c_j &= \sum_i \alpha_{ji} h_i^{in} \\ h_j^{out+1} &= f(h_j^{out}, c_j) \end{aligned} ejiαjicjhjout+1=score(hiin,hjout)=∑iejieji=i∑αjihiin=f(hjout,cj)
其中, e j i e_{ji} eji是未归一化的attention score,即表示对encode端隐藏状态应该施加注意力的程度, c j c_j cj是当前时刻的中间向量,score表示具体的相似度计算方法。
5.相似度计算方法
对于score的计算,常用的方式有如下几种
s j i = h j T h i s j i = h j T W h i s j i = W 2 t a n h ( W 1 [ h j ; h i ] ) s j i = σ ( W 2 t a n h ( W 1 [ h j ; h i ] + b 1 ) + b 2 ) \begin{aligned} s_{ji} &= h_j^T h_i \\ s_{ji} & = h_j^T W h_i \\ s_{ji} & = W_2 tanh(W_1[h_j; h_i]) \\ s_{ji} & = \sigma (W_2 tanh(W_1[h_j; h_i] + b_1) + b_2) \end{aligned} sjisjisjisji=hjThi=hjTWhi=W2tanh(W1[hj;hi])=σ(W2tanh(W1[hj;hi]+b1)+b2)
其中,第一,二种计算方式为点乘,又名luong’s multiplicative style。第三种计算方式为相加,又名Bahdanau’s additive style。第四种计算方式为MLP。
参考文献
1.https://zhuanlan.zhihu.com/p/28054589 完全图解RNN、RNN变体、Seq2Seq、Attention机制