【飞桨PaddleSpeech语音技术课程】— 语音翻译
(以下内容搬运自飞桨PaddleSpeech语音技术课程,点击链接可直接运行源码)
End-to-End Speech (to Text) Translation
前言
背景知识
语音翻译(ST, Speech Translation)是一项从一段源语言音频中翻译出目标语言的任务。
本章主要针对语音到文本的翻译,比如,从一段英文语音中,得到中文的翻译文本。
基本方法
级联模型(Cascaded), ASR -> MT
级联模型由独立的两个模型,语音识别模型(ASR)和机器翻译模型(MT)组成。先通过 ASR 模型从语音中识别出源语言的相应文本,在利用 MT 模型将相应文本翻译成目标语言。

端到端模型 (End-to-End)
端到端模型不显式对输入语音做文字识别,而直接生成翻译结果。

相对于端到端模型,级联模型存在以下一些问题:
1.错误传播(error propagation),由 ASR 识别错误所产生的错误文本,也会传递给 MT 模型,往往会导致生成更糟糕的翻译结果。
2.时延叠加(latency accumulation),因为使用两个级联的模型,需要对输入数据进行多次处理,实际的时延是两个模型时延的累加,效率低于端到端模型。
使用Transformer进行端到端语音翻译的的基本流程
基础模型
由于 ASR 章节已经介绍了 Transformer 以及语音特征抽取,在此便不做过多介绍,感兴趣的同学可以去相关章节进行了解。
本小节,主要讨论利用 transformer(seq2seq)进行ST与ASR的异同。
相似之处在于,两者都可以看做是从语音(speech)到文本(text)的任务。将语音作为输入,而将文字作为输出,区别只在于生成结果是对应语言的识别结果,还是另一语言的翻译结果。
因此,我们只需要将数据中的目标文本替换为翻译文本( Y Y Y),便可利用 ASR 的模型结构实现语音翻译。
规范化地讲,对于 ASR,利用包含语音( S S S)和转写文本( X X X)的数据集,训练得到一个模型 M A S R M_{ASR} MASR,能对任意输入的源语言语音 S ^ \hat{S} S^ 进行文字识别,输出结果 X ^ \hat{X} X^。
而ST的语料集,通常包含语音( S S S)、转写文本( X X X)以及翻译文本( Y Y Y),只需将ASR实践中的转写文本 X X X替换为对应的翻译文本 Y Y Y,便可利用同样的流程得到一个翻译模型 M S T M_{ST} MST,其能对任意输入的源语言语音 S ^ \hat{S} S^ 进行翻译,输出结果 Y ^ \hat{Y} Y^
值得注意的是,相较于 ASR 任务而言,在 ST 中,因为翻译文本与源语音不存在单调对齐(monotonic aligned)的性质,因此 CTC 模块不能将翻译结果作为目标来使用,此处涉及一些学术细节,感兴趣的同学可以自行去了解 CTC 的具体内容。
我们会在 PaddleSpeech 中放一些 Topic 的技术文章(如 CTC ),欢迎大家 star 关注。
辅助任务训练,提升效果(ASR MTL)
相比与 ASR 任务,ST 任务对于数据的标注和获取更加困难,通常很难获取大量的训练数据。
因此,我们讲讨论如何更有效利用已有数据,提升 ST 模型的效果。
1.先利用 ASR 对模型进行预训练,得到一个编码器能够有效的捕捉语音中的语义信息,在此基础上再进一步利用翻译数据训练ST模型。
2.相较于 ASR 任务的二元组数据( S S S, X X X),通常包含三元组数据( S S S, X X X, Y Y Y)的ST任务能够自然有效的进行多任务学习。
顾名思义,我们可以将ASR任务作为辅助任务,将两个任务进行联合训练,利用ASR任务的辅助提升 ST 模型的效果。
具体上讲,如图所示,可以利用一个共享的编码器对语音进行编码,同时利用两个独立的解码器,分别执行 ASR 和 ST 任务。

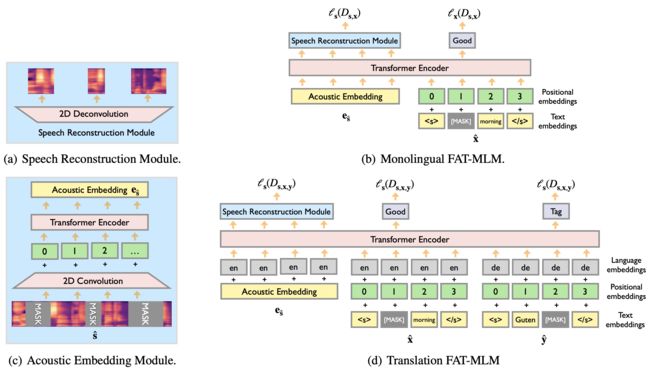
引入预训练模型,提升效果 (FAT-ST PT)
相比于文本到文本的机器翻译具有充足的语料(通常上百万条),语音到文本的翻译的语料很匮乏。那是否可以将文本到文本的翻译语料利用上来提升 ST 的模型效果呢?答案是肯定的。
FAT 模型[1],借鉴了 Bert[2] 和 TLM[3]的 masked language model 预训练思路,并将其拓展到语音翻译的跨语言、跨模态(语音和文本)的场景。可以应对三元组( S S S, X X X, Y Y Y)中任意的单一或组合的数据类型。
举例来说,它可以利用纯语音或文本数据集( S S S| X X X| Y Y Y),也可以利用 ASR 数据集( S S S, Y Y Y),甚至文本翻译数据( X X X, Y Y Y)。在这种预训练模型的基础上进行 ST 的训练,能够有效解决训练数据匮乏的困境,提升最终的翻译效果。
实战
ST 多任务学习,将 ASR 作为辅助任务
数据集: Ted语音翻译数据集(英文语音 → \rightarrow →中文文本)[4]
准备工作
特征抽取
参考语音识别的相关章节,略。
多任务模型
Transformer 内容参考语音识别的相关章节,略。
Stage 1 准备工作
安装 paddlespeech
!pip install paddlespeech==1.2.0
导入 python 包
import os
import paddle
import numpy as np
import kaldiio
import subprocess
from kaldiio import WriteHelper
from yacs.config import CfgNode
import IPython.display as dp
import warnings
warnings.filterwarnings("ignore")
from paddlespeech.s2t.frontend.featurizer.text_featurizer import TextFeaturizer
from paddlespeech.s2t.models.u2_st import U2STModel
获取预训练模型和参数并配置
!wget -nc https://paddlespeech.bj.bcebos.com/s2t/ted_en_zh/st1/fat_st_ted-en-zh.tar.gz
!tar xzvf fat_st_ted-en-zh.tar.gz
config_path = "conf/transformer_mtl_noam.yaml"
# 读取 conf 文件并结构化
st_config = CfgNode(new_allowed=True)
st_config.merge_from_file(config_path)
st_config
下载并配置 kaldi 环境
!wget -nc https://paddlespeech.bj.bcebos.com/s2t/ted_en_zh/st1/kaldi_bins.tar.gz
!tar xzvf kaldi_bins.tar.gz
kaldi_bins_path = os.path.abspath('kaldi_bins')
print(kaldi_bins_path)
if 'LD_LIBRARY_PATH' not in os.environ:
os.environ['LD_LIBRARY_PATH'] = f'{kaldi_bins_path}'
else:
os.environ['LD_LIBRARY_PATH'] += f':{kaldi_bins_path}'
os.environ['PATH'] += f':{kaldi_bins_path}'
Stage 2 获取特征
提取 kaldi 特征
def get_kaldi_feat(wav_path, config=st_config):
"""
Input preprocess and return paddle.Tensor stored in self.input.
Input content can be a file(wav).
"""
wav_file = os.path.abspath(wav_path)
cmvn = config.collator.cmvn_path
utt_name = '_tmp'
# Get the object for feature extraction
fbank_extract_command = [
'compute-fbank-feats', '--num-mel-bins=80', '--verbose=2',
'--sample-frequency=16000', 'scp:-', 'ark:-'
]
fbank_extract_process = subprocess.Popen(fbank_extract_command,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
fbank_extract_process.stdin.write(
f'{utt_name} {wav_file}'.encode('utf8'))
fbank_extract_process.stdin.close()
fbank_feat = dict(kaldiio.load_ark(
fbank_extract_process.stdout))[utt_name]
extract_command = ['compute-kaldi-pitch-feats', 'scp:-', 'ark:-']
pitch_extract_process = subprocess.Popen(extract_command,
stdin=subprocess.PIPE,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
pitch_extract_process.stdin.write(
f'{utt_name} {wav_file}'.encode('utf8'))
process_command = ['process-kaldi-pitch-feats', 'ark:', 'ark:-']
pitch_process = subprocess.Popen(process_command,
stdin=pitch_extract_process.stdout,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
pitch_extract_process.stdin.close()
pitch_feat = dict(kaldiio.load_ark(
pitch_process.stdout))[utt_name]
concated_feat = np.concatenate((fbank_feat, pitch_feat), axis=1)
raw_feat = f"{utt_name}.raw"
with WriteHelper(f'ark,scp:{raw_feat}.ark,{raw_feat}.scp') as writer:
writer(utt_name, concated_feat)
cmvn_command = [
"apply-cmvn", "--norm-vars=true", cmvn, f'scp:{raw_feat}.scp',
'ark:-'
]
cmvn_process = subprocess.Popen(cmvn_command,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
process_command = ['copy-feats', '--compress=true', 'ark:-', 'ark:-']
process = subprocess.Popen(process_command,
stdin=cmvn_process.stdout,
stdout=subprocess.PIPE,
stderr=subprocess.PIPE)
norm_feat = dict(kaldiio.load_ark(process.stdout))[utt_name]
audio = paddle.to_tensor(norm_feat).unsqueeze(0)
audio_len = paddle.to_tensor(audio.shape[1], dtype='int64')
return audio, audio_len
构建文本特征提取对象
text_feature = TextFeaturizer(
unit_type=st_config.collator.unit_type,
vocab=st_config.collator.vocab_filepath,
spm_model_prefix=st_config.collator.spm_model_prefix)
Stage 3 使用模型获得结果
构建 ST 模型
model_conf = st_config.model
model_conf.input_dim = st_config.collator.feat_dim
model_conf.output_dim = text_feature.vocab_size
print(model_conf)
model = U2STModel.from_config(model_conf)
加载预训练模型
params_path = "exp/transformer_mtl_noam/checkpoints/fat_st_ted-en-zh.pdparams"
model_dict = paddle.load(params_path)
model.set_state_dict(model_dict)
model.eval()
预测
# 下载wav
# !wget -nc https://paddlespeech.bj.bcebos.com/PaddleAudio/74109_0147917-0156334.wav
# !wget -nc https://paddlespeech.bj.bcebos.com/PaddleAudio/120221_0278694-0283831.wav
# !wget -nc https://paddlespeech.bj.bcebos.com/PaddleAudio/15427_0822000-0833000.wav
wav_file = '74109_0147917-0156334.wav'
# wav_file = '120221_0278694-0283831.wav'
# wav_file = '15427_0822000-0833000.wav'
transcript = "my hair is short like a boy 's and i wear boy 's clothes but i 'm a girl and you know how sometimes you like to wear a pink dress and sometimes you like to wear your comfy jammies"
dp.Audio(wav_file)
audio, audio_len = get_kaldi_feat(wav_file)
cfg = st_config.decoding
res = model.decode(audio,
audio_len,
text_feature=text_feature,
decoding_method=cfg.decoding_method,
beam_size=cfg.beam_size,
word_reward=cfg.word_reward,
decoding_chunk_size=cfg.decoding_chunk_size,
num_decoding_left_chunks=cfg.num_decoding_left_chunks,
simulate_streaming=cfg.simulate_streaming)
print("对应英文: {}".format(transcript))
print("翻译结果: {}".format("".join(res[0].split())))
参考文献
1.Zheng, Renjie, Junkun Chen, Mingbo Ma, and Liang Huang. “Fused acoustic and text encoding for multimodal bilingual pretraining and speech translation.” ICML 2021.
2.Devlin, Jacob, Ming-Wei Chang, Kenton Lee, and Kristina Toutanova. “Bert: Pre-training of deep bidirectional transformers for language understanding.” NAACL 2019.
3.Conneau, Alexis, and Guillaume Lample. “Cross-lingual language model pretraining.” NIPS 2019.
4.Liu, Yuchen, Hao Xiong, Zhongjun He, Jiajun Zhang, Hua Wu, Haifeng Wang, and Chengqing Zong. “End-to-end speech translation with knowledge distillation.” Interspeech 2019.
PaddleSpeech
请关注我们的 Github Repo,非常欢迎加入以下微信群参与讨论:
- 扫描二维码
- 添加运营小姐姐微信
- 通过后回复【语音】
- 系统自动邀请加入技术群

P.S. 欢迎关注我们的 github repo PaddleSpeech, 是基于飞桨 PaddlePaddle 的语音方向的开源模型库,用于语音和音频中的各种关键任务的开发,包含大量基于深度学习前沿和有影响力的模型。