计算机视觉&深度学习 相关整理
1、计算机视觉
1.1 发展历程
- 深度学习发展历程—目标分类:
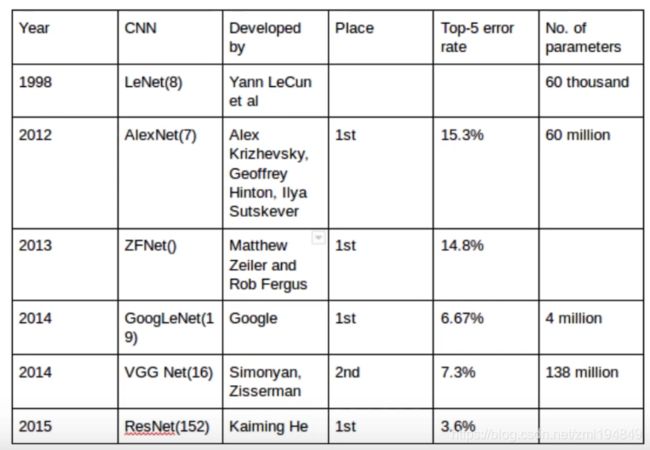
- 分类模型和精度
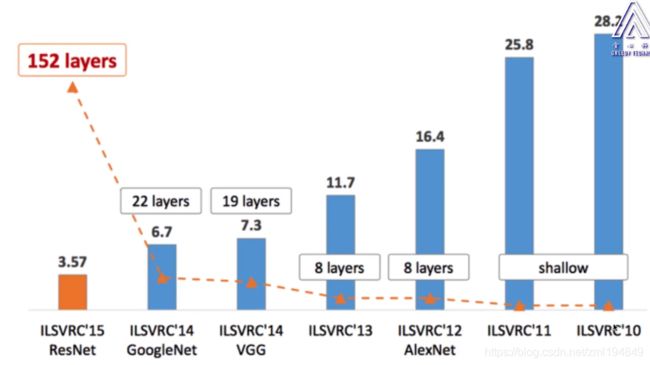
- LeNet
串联,2个卷积3个全连接,最早用于数字识别 - AlexNet(12年ImageNet冠军)
- 残差,5个卷积3个全连接,多个小卷积代替单一大卷积;
- 使用ReLu激活函数,解决梯度小数问题;
- 引入dropout避免模型过拟合;
- 最大池化;
- ZF-Net(13年ImageNet冠军)
- 只用了一块GPU的稠密连接结构;
- 将AlexNet第一层卷积核由11变成7,步长由4变为2。
- VGG-Net(14年ImageNet分类第二名)
- 更深的网络,卷积层使用更小的filter尺寸和间隔;
- 多个小卷积让网络有更多的非线性,更少的参数。
- GoogLenet(14年ImageNet分类第一名)。
- 引入Inception模块,采用不同大小的卷积核意味着不同大小的卷积核(感受野),最后拼接意味着不同尺度特征的融合,
- 采用了average pooling来代替全连接层;
- 避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。
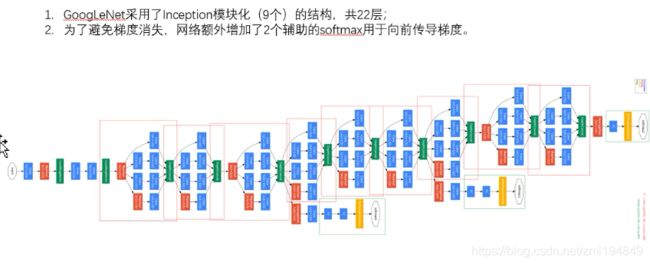
- Resnet:
(1)引入残差单元,简化学习目标和难度,加快训练速度,模型加深时,不会产生退化问题;能够有效解决训练过程中梯度消失和梯度爆炸问题。
(2)第二个版本:v2的BN和ReLu是在卷积之前使用的。好处是:反向传播基本符合假设,信息传递无阻碍;BN层作为pre-activation,起到了正则化的作用。 - DenseNet:密集连接;加强特征传播,鼓励特征复用,极大地减少了参数量。
- Inception:并联,谷歌发明的。
- Inceptionv1–GoogLenet,
为什么不在同一层级上运行具备多个尺寸的滤波器呢?网络本质上会变得稍微宽一些,而不是更深。因此提出了Inception模块。
(1)GoogLeNet采用了Inception模块化(9个)的结构,共22层;
(2)为了避免梯度消失,网络额外增加了2个辅助的softmax用于向前传导梯度。
(3)采用不同大小的卷积核意味着不同大小的感受野,最后拼接意味着不同尺度特征的融合
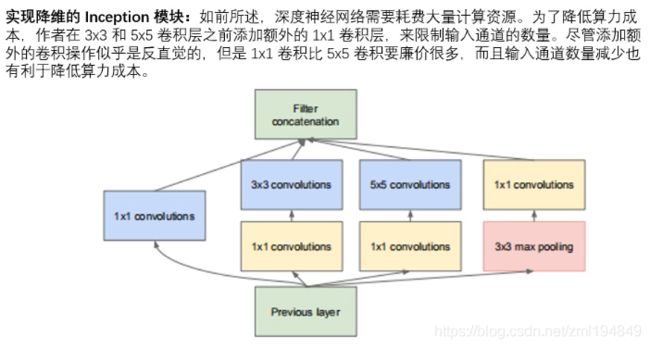
(4)将CNN中常见的卷积(1* 1,3* 3,5* 5)、池化操作(3 * 3)堆叠在一起(卷积、池化后的尺寸相同,将通道相加),一方面增加了网络的宽度,另一方面增加了网络对尺度的适应性。然而这个Inception原始版本,所有的卷积和都在上一层的输出上来做,而那个5*5的卷积核所需的计算量就太大了,约需要1.2亿次的计算量,造成了特征图的厚度很大。
(5)为了减少计算量,增加了 1 * 1 卷积在3 * 3、5 * 5之前,以起到降低特征图厚度的作用,形成InceptionV1的网络结构。

- Inceptionv2: 三个优化
一是 在输入的时候增加了BN:
(1)所有输出保证在0~1之间。
(2)所有输出数据的均值接近0,标准差接近1的正太分布。使其落入激活函数的敏感区,避免梯度消失,加快收敛。BN某种意义上起到了正则化的作用,BN会对每一个mini-batch数据的内部进行标准化,使输出规范到N(0,1)的正态分布,加快了网络的训练速度,还可以增大学习率。
(3)加快模型收敛速度,并且具有一定的泛化能力。
(4) 可以减少或者取消dropout,简化网络结构。V2在训练达到了V1准确率时快了14倍,最后收敛的准确率也比V1高。
二是 5 * 5 卷积核替换为2个3 * 3 降低参数量。25降为2 * 3 * 3=18
卷积分解,将耽搁的5*5卷积层用2个连续的3 * 3卷积层组成的小网络来代替,在保持感受野范围的同时又减少了参数量,也加深了网络。
三是将n * n的卷积核尺寸分解为1 * n和n * 1两个卷积
- InceptionV3
整合了前面 Inception v2 中提到的所有升级,还使用了7x7 卷积
(1)分解成小卷积很有效,考虑了N* 1卷积核,将一个较大的二维卷积拆成两个较小的一维卷积(7 * 7拆成了7* 1和1* 7),一方面节约了大量参数,加速运算并减轻了过拟合,同时网络深度进一步加深,增加了网络的非线性。
(2)优化了Inception Module的结构。卷积网络从输入到输出,应该让图片尺寸逐渐减小,输出通道数逐渐增加,即让空间结构化,将空间信息转化为高阶抽象的特征信息(所有inception共性);Inception Module用多个分支提取不同抽象程度的高阶特征的思路很有效,可以丰富网络的表达能力
- InceptionV4
利用残差链接(Residual Connection)来改进V3结构。
- inception优势:
1、采用了1x1卷积核,性价比高,用很少的计算量既可以增加一层的特征变换和非线性变换。
2、提出Batch Normalization,通过一定的手段,把每层神经元的输入值分布拉到均值0方差1的正态分布,使其落入激活函数的敏感区,避免梯度消失,加快收敛。
3、引入Inception module,4个分支结合的结构。
- MobileNet:
MobileNet是为移动端和嵌入式设备提出的高效模型。MobileNet基于流水线型架构(streamlined),使用深度可分离卷积(即Xception变体结构)来构建轻量级深度神经网络。宽度因子a用于控制输入和输出的通道数,分辨率因子p控制输入的分辨率。例如,对于深度分离卷积,把标准卷积(4,4,3,5)whcn分解为:
(1)深度卷积部分:大小为(4,4,1,3),作用在输入的每个通道上,输出的特征映射为(3,3,3,3)
(2)逐点卷积部分:大小为(1,1,3,5),作用在深度卷积的输出特征映射上,得到最终输出为(3,3,4)。
- shuffleNet:专门应用于计算力受限的移动设备,主要包含两个操作:逐点群卷积(降低计算复杂度)和通道混洗(帮助信息流通)
1.2 目标检测
-
RCNN流程:
(1)预训练:在ImageNet上面训练一个分类神经网络
(2)使用selective search 找出候选区域
(3)将候选区域resize成CNN输入的尺寸
(4)fine-tuning:在自己的训练数据集中fine-tune CNN,作为一个识别K+1种类别的分类问题,K为感兴趣的目标种类数,1为背景类别。Fine-tune使用较小的learning-rate,在正样本上面oversample(selective search出来的候选区域大多为背景)。
(5)去掉fine-tune后的CNN的最后一个分类层,将每一个候选区域通过CNN,输出为一个特征向量。
(6)使用特征向量为每一个类别训练一个二元SVM分类器(正样本为候选区域和真实区域IOU大于等于0.6的区域,其它为负样本)
(7)为了减少Selective Search候选区域定位误差,使用regression 模型预测新的定位。 -
BBOX
bounding box regression
损失函数,regression模型的输出为 d i ( p ) d_{i}(p) di(p) 其中 p = ( p x , p y , p w , p h ) p=(p_{x},p_{y},p_{w},p_{h}) p=(px,py,pw,ph)为Selective Search输出候选区域的中心坐标,宽度和高度。 g = ( g x , g x , g y , g w , g h ) g=(g_{x},g_{x},g_{y},g_{w},g_{h}) g=(gx,gx,gy,gw,gh)为真实坐标的中心坐标,宽度和高度。
L r e g = ∑ i ∈ { x , y , w , h } ( t i − d i ( p ) ) 2 + λ ∥ w ∥ 2 L_{reg}=\sum_{i\in \left \{ x,y,w,h \right \}}\left ( t_{i}-d_{i}\left ( p \right ) \right )^{2}+\lambda \left \| w \right \|^{2} Lreg=∑i∈{x,y,w,h}(ti−di(p))2+λ∥w∥2
t x = ( g x − p x ) p w t_{x}=\frac{\left ( g_{x}-p_{x}\right )}{p_{w}} tx=pw(gx−px)
t y = ( g y − p y ) p h t_{y}=\frac{\left ( g_{y}-p_{y}\right )}{p_{h}} ty=ph(gy−py)
t w = l o g ( g w p w ) t_{w}=log\left ( \frac{g_{w}}{p_{w}} \right ) tw=log(pwgw)
t h = l o g ( g h p h ) t_{h}=log\left ( \frac{g_{h}}{p_{h}} \right ) th=log(phgh)
训练结束后,预测的中心目标的中心坐标,高度和宽度:
g ^ x = p w d x ( p ) + p x \hat{g}_{x}=p_{w}d_{x}\left ( p \right )+p_{x} g^x=pwdx(p)+px
g ^ y = p h d y ( p ) + p y \hat{g}_{y}=p_{h}d_{y}\left ( p \right )+p_{y} g^y=phdy(p)+py
g ^ w = p w e x p ( d w ( p ) ) \hat{g}_{w}=p_{w}exp\left ( d_{w}\left ( p \right ) \right ) g^w=pwexp(dw(p))
g ^ h = p h e x p ( d h ( p ) ) \hat{g}_{h}=p_{h}exp\left ( d_{h}\left ( p \right ) \right ) g^h=phexp(dh(p))
正则化的值是通过交叉验证(cross validation)确定的。
并非所有的Selection Search输出的候选区域都包含真是的目标,对于这些区域,无需加入Bbox regression的计算过程。
R-CNN只把IoU的值大于等于0.6的候选区域加入Bbox regression的计算过程
- Fast R_CNN
将R_CNN中下面3个独立模块整合在一起,减少计算量:
CNN:提取图像特征
SVM:目标分类识别
Regression模型:定位
不对每个候选区域独立通过CNN提取特征,将整个图像通过CNN提取特征,然后从CNN的特征图中根据Selection Search的候选区域通过RoI Pooling层提取区域特征。
损失函数:
 Fast R-CNN 的总结
Fast R-CNN 的总结
- 由于图像只通过CNN一次,而不是让每一个候选区独立通过CNN,减少了运算量。
- 将R-CNN中的多个SVM的分类合并为一个DNN,让分类和定位可以同时训练。
- 但是依然依靠Selective Search选择候选区域
-
Faster R-CNN的改进:
(1)去掉Selective Search,将候选区域的选择整合到深度学习网络模型中(Region Proposal Network:RPN和fast R-CNN结合)
(2)RPN:sliding window ,有K个boxes,每个boxes有2个类别及2K个类别,有4K个定位。Faster R-CNN步骤:
(1)预训练一个用于分类的CNN
(2)使用CNN的特征图作为输出,端到端的fine-tune RPN +CNN。当IOU>0.7为正样本,IOU<0.3为负样本
在特征图上面使用滑动窗口
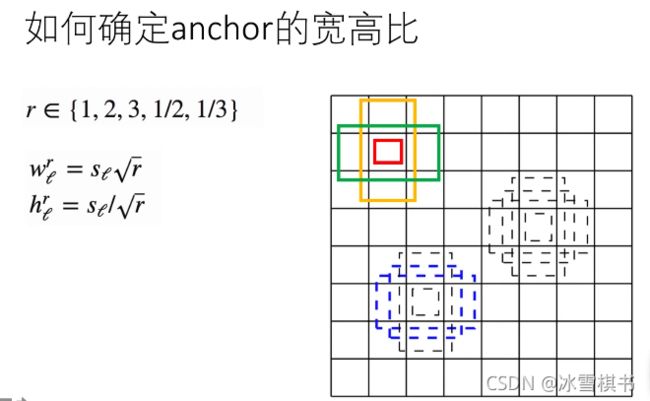
对每个滑动窗口,产生多个Anchor(相当于Selective Search选中的候选区域)。一个anchor由滑动窗口的中心位置,窗口尺寸,窗口宽高比决定。论文中使用3个尺寸和3个宽高比,所以一个滑动窗口位置对应9(3*3)个anchor。
(3)固定RPN的权值,使用当前的RPN训练一个FastR-CNN .
(4)固定CNN,Fast R-CNN的权值,训练RPN。
(5)固定CNN,RPN,训练Fast R-CNN的权值
(6)重复步骤4和5直到满意为止。
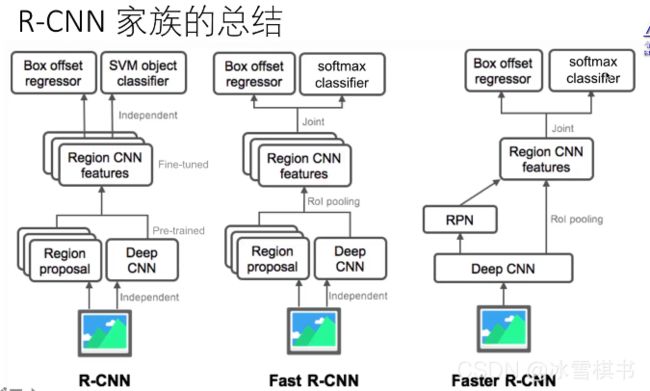
-
SSD网络结构:
(1)没有全连接层的网络,
(2)借鉴了VGG16的网络模型,
(3)将VGG16的第一个和第二个全连接层替换为卷积层,
(4)去掉了最后一个全连接层,
(5)加上了4组卷积层(Conv8,Conv9,Conv10,Conv11)
(6)Conv4的输出特征图用于检测最小的物体
(7)Conv11的输出特征图用于检测最大的物体
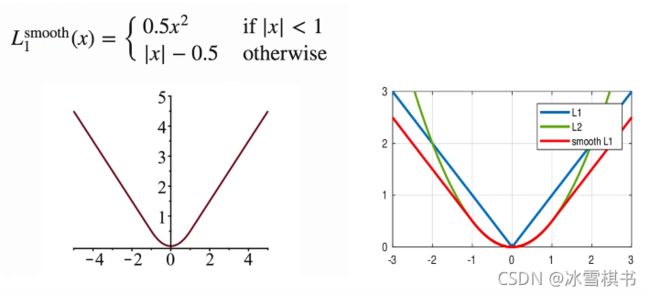
ssd分类损失函数:softmax。
ssd的边框预测使用相对值。smooth L1 loss:结合了L1的优势(随着x的增大,梯度的增长是恒定的) L2的优势:当x特别小的时候,梯度迅速减小,减少震荡。
-
如何确定anchor的宽高和中心:

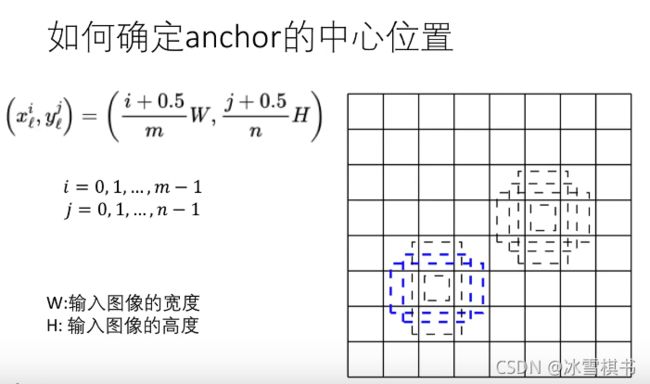
i个anchor j个groundtruth真是物体边界框 -
预测层的滤波器数量:
- 预测层的宽和高,等于输入特征图的宽和高
- 对应特征图的每一个像素点,需要预测4个包含位置信息的值,加上c个包含类别概率的值,c为总的类别数量(包含背景类别)
- 每个卷积核为3*3 * p的tensor,其中p为输入特征图的通道数量
- 如果输入的特征图设定为K个anchor boxes,对于m*n像素的特征图,需要kmn(c+4)个卷积核。
-
VGG16 不算maxpooling 计算了Conv 和Fc 共16层
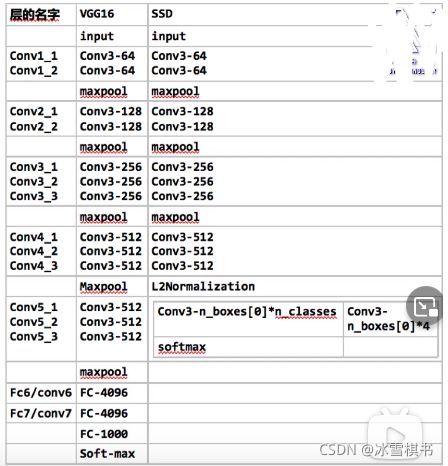
-
空洞卷积
(1)Atrous convolution(Dilated convolution)
(2)SSD的基础网络时VGG16在ILSVRC分类数据上完成了预训练。FC6和FC7被替换为Atrous卷积层,pool5从22-s2被替换为33-s1
(3)Atrous convolution可以在较少的参数情况下增大了市场。带洞卷积减少了核的大小(减少了参数的数量),可以达到节省内存的作用。
(4)而且带洞卷积的有效性基于一个假设:紧密相邻的像素几户相同,全部纳入属于冗余,不如跳H(hole size)个取一个。传统方式预测类别和位置:卷积层+全连接层,预测物体中心位置和宽高,只能预测一个位置
现在预测类别和位置:卷积层+卷积层。同时预测物体概率和边界框 -
SSD vs YOLO
(1)使用比较小的卷积核
(2)对不同长宽比的物体使用不同的预测期
(3)使用不同的卷积层的输出预测不同尺寸的物体 -
SSD 总结
(1)多个类别同时定位
(2)使用多个卷积层的输出特征图为不同的尺度目标做预测
(3)使用的Anchor越丰富,效果越好
(4)与Faster R-CNN效果相当,而且更快 -
GAN(Ganerative Adversarial Networks)
(1)Ian Goodfellow 2014年提出
(2)非监督式学习任务
(3)使用两个深度神经网络:Generator(生成器),Discrimination(判别器)
训练GAN的基本步骤:
(1)对噪声及和实际数据集进行采样,选择m个
(2)使用这些数据训练判别器
(3)采样大小为m的不同的噪声集
(4)在此数据上训练生成器
(5)从步骤1开始重复 -
二值化神经网络
(1)做预测时,网络的权值,激活值都是二值(-1/+1)
(2)做训练时,二值化的权值和激活值参数与梯度的计算
(3)由于网络的权值,激活值都是二值的,带来两个好处:1.模型的大小减少了32倍。
2.数学计算(加减乘除)可以使用bit-wise位运算来实现,便于硬件实现算法,更快,更节能。
1.3 图像分割
-
图像分割之语义分割(semantic segmentation):
(1)定义:语义图像分割的目标是标记图像每个像素的类别。因为我们需要预测图像中的每个像素,所以此任务通常被称为密集预测。
(2) 应用:(1)自动驾驶—自动驾驶是一项复杂的任务,需要在不断变化的环境中进行感知。由于安全性至关重要,因此还需要以最高精度执行此任务。语义分割提供有关道路上空间的信息,以及检测车道标记和交通标志。
(2)医学图像处理:可以辅助放射科医师进行图像分析,大大减少了诊断所需的时间。
(3)地理感应(开发数据集spacenet):卫星图像用于检测土地覆盖信息,对于应用:例如检测毁林的区域。
(4)精准农业:精准农业机器人可以减少需要在田间喷洒的除草剂的计量,并且作物和杂草的语义分割可以帮助它们实时触发除草行为。 -
图像分割之实例分割(instance segmentation):实例分割比语义分割更近一步,除了像素级分类,还需要分别对类的每个实例进行分类。语义分割不区分特定类的实例。
-
U-Net:
conv2DTranspose的问题
(1)与插值法(双三次差值bicubic)或者最近邻插值相比,Conv2DTranspose是监督式学习算法的,是需要训练的
(2)会产生棋盘效应,其中一个解决方案是先插值,再使用Conv2DTranspose
2、深度学习
-
为什么使用1*1卷积核
(1)11卷积的目的是为了减少维度,还用于修正线性激活(ReLu)。比如上一层的输出为100100128,经过具有256个通道的55卷积层之后(stride=1,pad=2),输出数据位100100256,其中,卷积层的参数为12855256=819200。而加入上一层输出先经过具有32个通道的11卷积层,再经过具有256个输出的55卷积层,那么输出数据仍为100100256,但卷积参数量已经减少为1281132+3255*256=204800,大约减少了4倍。
(2)加深了网络的层次,同时也增强了网络的非线性。 -
pooling层反向传播
CNN网络中另外一个不可导的环节就是Pooling池化操作,因为Pooling操作使得feature map的尺寸变化,假如做2×2的池化(步长也为2),假设那么第l+1层的feature map有16个梯度,那么第l层就会有64个梯度,这使得梯度无法对位的进行传播下去。其实解决这个问题的思想也很简单,就是把1个像素的梯度传递给4个像素,但是需要保证传递的loss(或者梯度)总和不变。根据这条原则,mean pooling和max pooling的反向传播也是不同。
(1)mean pooling: mean pooling的前向传播就是把一个patch中的值求取平均来做pooling,那么反向传播的过程也就是把某个元素的梯度等分为n份分配给前一层,这样就保证池化前后的梯度(残差)之和保持不变
(2)max poolingmax pooling也要满足梯度之和不变的原则,max pooling的前向传播是把patch中最大的值传递给后一层,而其他像素的值直接被舍弃掉。那么反向传播也就是把梯度直接传给前一层某一个像素,而其他像素不接受梯度,也就是为0。所以max pooling操作和mean pooling操作不同点在于需要记录下池化操作时到底哪个像素的值是最大,也就是max id,这个变量就是记录最大值所在位置的,因为在反向传播中要用到 -
元学习:learning to learn
元学习meta learning 又称为“学会学习”,即利用以往的知识经验来指导新任务的学习,是网络具备学会学习的能力,是解决小样本问题(few-shot learning)常用的方法之一。
元学习中的“元”是什么意思:元学习的本质是增加学习器在多任务的泛化能力,元学习对于任务和数据都需要采样,因此学习到的F(x)可以在未出现的任务中迅速(依赖很少的样本)建立起mapping。因此,“元”体现在网络对于每个任务的学习,通过不断的适应每个具体任务,使网络具备了一种抽象的学习能力。
元学习中的训练和测试:meta-learning中为了区别概念,将训练过程定义为“meta-training”、测试过程定义为“Meta-testing”。区别于一般神经网络端到端的训练方式,元学习的训练过程和测试过程各需要两类数据集(Support/Query set).
小样本分类任务属于“N-way k-shot”问题,其中,N代表选择的Testing data中样本的种类,k代表选择的K类Testing data中每类样本的数量,一般来说N小于Testing data的总类别数。
如何构建S'和Q':我们从Testing data中随机选出N个类。然后,再从这N类中按照类别一次随机选出k+x个样本(x代表可以选任意个),其中的k个样本将被用作Support set S’,另外的x个样本将被用作Query set Q'。S和Q的构建同理,不同的是从Training data中选择的样本累呗和每类样本数量均不作约束。
如何训练:Meta-learning通常采用一种被称为Episodic Training的方法来训练。
- “元学习”和“迁移学习”的区别和联系:
从目标上看,元学习和迁移学习的本质都是增加学习器在多任务的泛化能力,但元学习更偏重于任务和数据的双重采样,即任务和数据一样是需要采样的,具体来说对于一个10分类任务,元学习通过可能只会建立起一个5分类器,每个训练的episode都可以看成是一个子任务,而学习到的F(x)可以帮助在未见过的任务里迅速建立mapping。而迁移学习更多是指从一个任务到其它任务的能力迁移,不太强调任务空间的概念。
元学习:学习如何学习,思想挺突破的,不过应用还不算太广,有待考究
NAS: 神经架构搜索,可用于搜索最优的模型参数,类似于贝叶斯方法搜索最优超参数,算不上深度学习的突破。
自监督:学习数据特征,不需要标签,具有一定的现实意义,但是思想不难想到,算不上突破。
- 常见的两类迁移学习场景:
1.卷积网络当做特征提取器。使用在ImageNet上预训练的网络,去掉最后的全连接层,剩余部分当做特征提取器(例如AlexNet在最后分类器前,是4096维的特征向量)。这样提取的特这公交坐CNN codes。得到这样的特征后,可以使用线性分类器(Liner SVM,Softmax等)来分类图像。
2.Fine-tuning卷积网络。替换掉网络的输入层(数据),使用新的数据继续训练。Fine-tune时可以选择fine-tune全部层或部分层。通常,前面的层提取的是图像的通用特征(generic features)(例如边缘检测,色彩检测),这些特征对许多任务都有用。后面的层提取的是与特定类别有关的特征,因此fine-tune时常只需要Fine-tuning后面的层。
- 迁移学习transfer learning 和微调fine-tuning:
1.Fine-tuning 微调是实现迁移学习的手段之一。
2.一般来说,在数据量足够的情况下,迁移学习的效果不如完全重新训练。
3.但是迁移学习所需要的训练时间和训练成本要远远小于训练完整的模型。
- 特征工程:
1.在中小数据集上表现良好。
2.对数据的人为处理提取,人工提取的过程。有时候也代指“洗数据”
- 表示学习:
1.在大量复杂数据集上表现好。
2.自动学习有用的数据特征,模型自动学习的过程。
3.表示学习的另外一个好处是高度抽象化的特征可以通过迁移学习用在其他相关的问题上
- 迁移学习:
1、现在在工程中最为常用的还是vgg、resnet、inception这几种结构,设计者通常会先直接套用原版的模型对数据进行训练一次,然后选择效果较为好的模型进行微调与模型缩减。
2、工程上使用的模型必须在精度高的同时速度要快。
3、常用的模型缩减的方法是减少卷积和个数与减少resnet的模块数。
-
RoIAlign:
之所以提出RoIAlign,是因为之前的 RoIPooling 的操作会让实例分割有较大的重叠,而 RoIAlign 很好地解决了RoI Pooling操作中两次量化造成的区域不匹配(mis-alignment)的问题。详解 ROI Align 的基本原理和实现细节
-
使用卷积层替代CNN末尾的全连接层:
参考 突破了输入尺寸的限制; -
FPN:参考
FPN 能很好的处理小目标,利用底层特征可以获得更准确的位置信息,利用高层获得强语义信息,融合了多层特征信息,并在不同的特征层进行输出,提高了检测性能。 -
YOLOv3原理
-
残差结构大小维度不匹配怎么解决:
-
map:
-
深度学习的深度选择?
1、一个直观的解释,从模型复杂度角度。如果我们能够增强一个学习模型的复杂度,那么它的学习能力能够提升。如何增加神经网络的复杂度呢?要么变宽,即增加隐层网络神经元的个数;要么变深,即增加隐层的层数。当变宽的时候,只不过是增加了一些计算单元,增加了函数的个数,在变深的时候不仅增加了个数,还增加了函数间的嵌入的程度。
2、深度学习可以通过多个layer的转换学习更高维度的特征来解决更加复杂的任务。
3、那现在我们为什么可以用这样的模型?有很多因素,第一我们有了更大的数据;第二我们有强力的计算设备;第三我们有很多有效的训练技巧
4、像在ZFNet网络中已经体现,特征间存在层次性,层次更深,特征不变性强,类别分类能力越强,要学习复杂的任务需要更深的网络。 -
如何改善训练模型的效果呢?
1、通过提升数据,获取良好的数据。对数据预处理;零均值1方差化,数据扩充或者增强,
2、诊断网络是否过拟合欠拟合。通过偏差方差。正则化解决过拟合,早停法遏制过拟合。
3、通过学习率,激活函数的选择,改善网络全连接层个数啊层数啊,优化算法,随机梯度,RMSprop,动量,adam,使用batchnormlization.
4、权值初始化Xavier初始化,保持输入与输出端方差一致,避免了所有输出都趋向于0;
-
为什么会产生梯度消失和梯度爆炸:
目前优化神经网络的方法都是基于BP,即根据损失函数计算的误差通过梯度反向传播的方式,指导深度网络权值的更新优化。其中将误差从末层往前传递的过程需要链式法则(Chain Rule)的帮助,因此反向传播算法可以说是梯度下降在链式法则中的应用。而链式法则是一个连乘的形式,所以当层数越深的时候,梯度将以指数形式传播。梯度消失问题和梯度爆炸问题一般随着网络层数的增加会变得越来越明显。在根据损失函数计算的误差通过梯度反向传播的方式对深度网络权值进行更新时,得到的梯度值接近0或特别大,也就是梯度消失或爆炸。梯度消失或梯度爆炸在本质原理上其实是一样的。
-
分析产生梯度消失和梯度爆炸的原因
【梯度消失】经常出现,产生的原因有:一是在深层网络中,二是采用了不合适的激活函数,比如sigmoid。当梯度消失发生时,接近于输出层的隐藏层由于其梯度相对正常,所以权值更新时也就相对正常,但是当越靠近输入层时,由于梯度消失现象,会导致靠近输入层的隐藏层权值更新缓慢或者更新停滞。这就导致在训练时,只等价于后面几层的浅层网络的学习。【梯度爆炸】一般出现在深层网络和权值初始化值太大的情况下。在深层神经网络或循环神经网络中,误差的梯度可在更新中累积相乘。如果网络层之间的梯度值大于 1.0,那么重复相乘会导致梯度呈指数级增长,梯度变的非常大,然后导致网络权重的大幅更新,并因此使网络变得不稳定。
梯度爆炸会伴随一些细微的信号,如:①模型不稳定,导致更新过程中的损失出现显著变化;②训练过程中,在极端情况下,权重的值变得非常大,以至于溢出,导致模型损失变成 NaN等等。
-
如何解决梯度爆炸与消失。
梯度消失和梯度爆炸问题都是因为网络太深,网络权值更新不稳定造成的,本质上是因为梯度反向传播中的连乘效应。解决梯度消失、爆炸主要有以下几种方法:
1、预训练加微调 -
2、 梯度剪切:对梯度设定阈值
3、权重正则(针对梯度爆炸) -
4、使用不同的激活函数 -选择relu等梯度大部分落在常数上的激活函数
5、使用batchnorm -
6、使用残差结构 -
7、使用LSTM网络
具体地:
(1) pre-training+fine-tunning
此方法来自Hinton在2006年发表的一篇论文,Hinton为了解决梯度的问题,提出采取无监督逐层训练方法,其基本思想是每次训练一层隐节点,训练时将上一层隐节点的输出作为输入,而本层隐节点的输出作为下一层隐节点的输入,此过程就是逐层“预训练”(pre-training);在预训练完成后,再对整个网络进行“微调”(fine-tunning)。此思想相当于是先寻找局部最优,然后整合起来寻找全局最优,此方法有一定的好处,但是目前应用的不是很多了。
(2) 梯度剪切:对梯度设定阈值
梯度剪切这个方案主要是针对梯度爆炸提出的,其思想是设置一个梯度剪切阈值,然后更新梯度的时候,如果梯度超过这个阈值,那么就将其强制限制在这个范围之内。这可以防止梯度爆炸。
(3) 权重正则化
另外一种解决梯度爆炸的手段是采用权重正则化(weithts regularization),正则化主要是通过对网络权重做正则来限制过拟合。如果发生梯度爆炸,那么权值就会变的非常大,反过来,通过正则化项来限制权重的大小,也可以在一定程度上防止梯度爆炸的发生。比较常见的是 L1 正则和 L2 正则,在各个深度框架中都有相应的API可以使用正则化。
关于 L1 和 L2 正则化的详细内容可以参考我之前的文章——欠拟合、过拟合及如何防止过拟合
(4) 选择relu等梯度大部分落在常数上的激活函数
relu函数的导数在正数部分是恒等于1的,因此在深层网络中使用relu激活函数就不会导致梯度消失和爆炸的问题。
关于relu等激活函数的详细内容可以参考我之前的文章——温故知新——激活函数及其各自的优缺点
(5) batch normalization
BN就是通过对每一层的输出规范为均值和方差一致的方法,消除了权重参数放大缩小带来的影响,进而解决梯度消失和爆炸的问题,或者可以理解为BN将输出从饱和区拉倒了非饱和区。
关于Batch Normalization(BN)的详细内容可以参考我之前的文章——常用的 Normalization 方法:BN、LN、IN、GN
(6) 残差网络的捷径(shortcut)
说起残差结构的话,不得不提这篇论文了:Deep Residual Learning for Image Recognition。论文链接:http://openaccess.thecvf.com/content_cvpr_2016/papers/He_Deep_Residual_Learning_CVPR_2016_paper.pdf
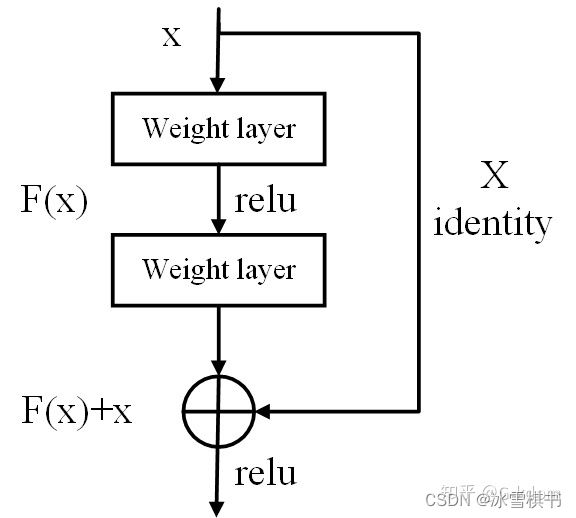
相比较于以前直来直去的网络结构,残差中有很多这样(如上图所示)的跨层连接结构,这样的结构在反向传播中具有很大的好处,可以避免梯度消失。
(7) LSTM的“门(gate)”结构
LSTM全称是长短期记忆网络(long-short term memory networks),LSTM的结构设计可以改善RNN中的梯度消失的问题。主要原因在于LSTM内部复杂的“门”(gates),如下图所示。
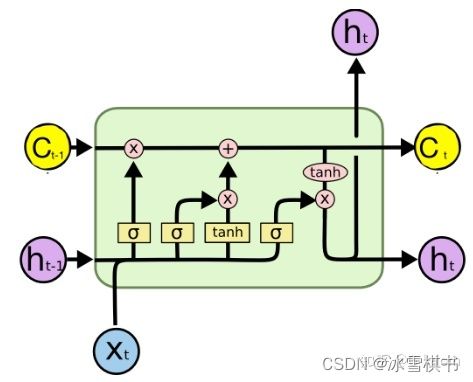
LSTM 通过它内部的“门”可以在接下来更新的时候“记住”前几次训练的”残留记忆“。
15. 你做过其他与职位申请相关项目吗,解释现在的硕士研究内容,有什么效果吗?
解答建议。自己做的事情和学的任何技能能够与申请的岗位建立联系。
- 为什么要使用许多小卷积核(如3x 3 )而不是几个大卷积核?
这在VGGNet的原始论文中得到了很好的解释。
原因有二:
首先,您可以使用几个较小的核而不是几个较大的核来获得相同的感受野并捕获更多的空间上下文,但是使用较小的内核时,您使用的参数和计算量较少。
其次,因为使用更小的核,您将使用更多的滤波器,您将能够使用更多的激活函数,从而使您的CNN学习到更具区分性的映射函数。
- 为什么在图像分割中CNNs通常具有编码器-解码器结构?
编码器CNN基本上可以被认为是特征提取网络,
而解码器使用该信息通过“解码”特征并放大到原始图像大小来预测图像分割区域。
- 为什么我们对图像使用卷积而不仅仅是FC层?
这个很有趣,因为公司通常不会问这个问题。正如你所料,我是从一家专注于计算机视觉的公司那里得到这个问题的。这个答案有两部分。
首先,卷积保存、编码和实际使用来自图像的空间信息。如果我们只使用FC层,我们将没有相对的空间信息。
其次,卷积神经网络( CNNs )具有部分内建的平移不变性,因为每个卷积核充当其自身的滤波器/特征检测器。而且这样减少大量的参数,减轻过拟合。
- 卷积翻转180度
(1)卷积神经网络图像处理卷积时,没有旋转180度。是为了提取图像的特征,其实只是借鉴了“加权求和”的特点。
(2)数学上的卷积,比如信号处理/传统图像处理,处理卷积时,旋转180度。根据问题的需要而确定。
(3)数学中的卷积核都是已知的或者给定的,卷积神经网络中的卷积核本来就是trainable的参数,不是给定的,根据数据训练学习的,无论翻转与否对应的都是位置的参数。
- dropout
dropout来源于这样的假设
当网络对训练集拟合的很好而对验证集的拟合的很差时,可不可以让每次跌代随机的去更新网络参数(weights),而不是全部更新,引入这样的随机性就可以增加网络generalize 的能力。所以就有了dropout 。
dropout作用原理?
每层神经元代表一个学习到的中间特征,当数据量过小,出现过拟合时,显然这时神经元表示的特征相互之间重复和冗余。
dropout直接作用是:减少冗余,即增加每层各个特征之间的正交性。每次迭代只有一部分参数更新,减慢收敛速度。
dropout的具体方法?
Dropout 一般在全连接层使用,被drop的神经元不参加当前轮的参数优化。只有训练时使用dropout,测试时所有神经元都参与运算。
在训练的时候,我们只需要按一定的概率(retaining probability)p 来对weight layer 的参数进行随机采样,将这个子网络作为此次更新的目标网络。可以想象,如果整个网络有n个参数,那么我们可用的子网络个数为 2^n 。
测试时,不对网络的参数做任何丢弃,这时dropout layer相当于进来什么就输出什么。然后,把测试时dropout layer的输出乘以训练时使用的retraining probability p 。是为了使得dropout layer 下一层的输入和训练时具有相同的“意义”和“数量级”。
dropout调用?
在tensorflow中:tf.nn.dropout(上层输出,暂时舍弃的概率)
-
L2normalization:解决特征图中的特征大小差别太大的问题
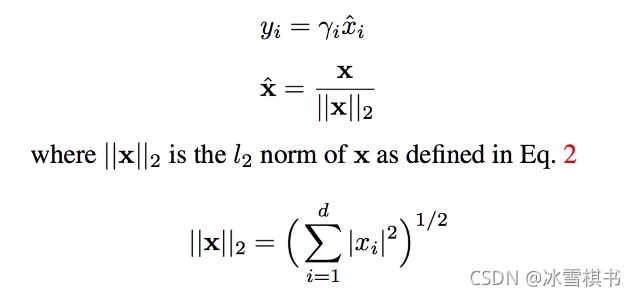
-
Hard Negative Mining:如何生成负样本
(1)随机选择一些非目标区域作为负样本
(2)训练目标检测器
(3)使用目标检测器在一些随机选择的图像上运行,收集那些被误认为是目标的区域,加入负样本
(4)回到第二步 -
Non-max suppression
我们可能会以不同的大小和长宽比检测到同一目标,为了避免对同一目标的多次检测而使用Non-max suppression
(1)按照检测到目标的输出概率排序
(2)丢弃概率太低的预测位置
(3)重复:选中概率最大的预测位置,如果和另外一个预测位置有重叠(例如,重叠率IoU大于0.5),保留概率最大的预测位置,丢弃另外一个。 -
卷积和反卷积
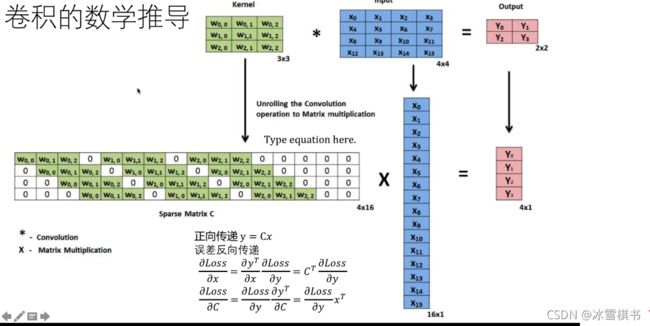
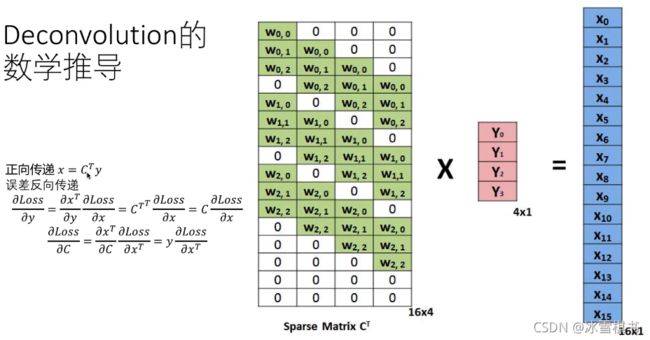 反卷积
反卷积
transposed convojutions /deconvolution /up convolutions
(1)卷积和池化的输出相对于输入尺寸缩小
(2)池化通过增加视场,帮助我们理解图像中的物体是什么,但是这个操作也丢失了物体的位置信息
(3)在语义分割中,我们不但需要知道图像中的物体是什么,还需要知道物体在哪儿。我们需要一种将图像放大同时保留物体位置信息的操作。
(4)Transposed convolution 是图像过采样(up sampling)的最佳选择,它通过误差向后传递学习最佳的权值使得低分辨率图像转换为高分辨率图像的效果最好。
conv2DTranspose的问题
(1)与插值法(双三次差值bicubic)或者最近邻插值相比,Conv2DTranspose是监督式学习算法的,是需要训练的
(2)会产生棋盘效应,其中一个解决方案是先插值,再使用Conv2DTranspose
-
GAN(Ganerative Adversarial Networks)
(1)Ian Goodfellow 2014年提出 (2)非监督式学习任务 (3)使用两个深度神经网络:Generator(生成器),Discrimination(判别器)
训练GAN的基本步骤:
(1)对噪声及和实际数据集进行采样,选择m个
(2)使用这些数据训练判别器
(3)采样大小为m的不同的噪声集
(4)在此数据上训练生成器
(5)从步骤1开始重复
-
二值化神经网络
(1)做预测时,网络的权值,激活值都是二值(-1/+1)
(2)做训练时,二值化的权值和激活值参数与梯度的计算
(3)由于网络的权值,激活值都是二值的,带来两个好处:
1、模型的大小减少了32倍。
2、数学计算(加减乘除)可以使用bit-wise位运算来实现,便于硬件实现算法,更快,更节能。 -
常见的损失函数,常见的激活函数,ELU函数了解吗:
常见的损失函数:0-1损失函数,绝对值损失函数,log对数损失函数,平方损失函数,指数损失函数,hinge损失函数,交叉熵损失函数。
(1)0-1损失函数
L ( Y , f ( X ) ) = { 1 , Y ≠ f ( X ) 0 , Y = f ( X ) L(Y,f(X))=\left\{\begin{matrix} 1,Y\neq f(X) & \\ 0,Y=f(X) & \end{matrix}\right. L(Y,f(X))={1,Y=f(X)0,Y=f(X)
(2)绝对值损失函数
L(Y,f(X))=|Y-f(X)|
(3)log对数损失函数
L(Y,P(Y|X))=-logP(Y|X)
(4)平方损失函数
L ( Y ∣ f ( X ) ) = ∑ N ( Y − f ( X ) ) 2 L(Y|f(X))=\sum_{N}(Y-f(X))^2 L(Y∣f(X))=∑N(Y−f(X))2
(5)指数损失函数
L(Y|f(X))=exp[-yf(x)]
(6)hinge损失函数
L(y,f(x))=max(0,1-yf(x))
(7)交叉熵损失函数
C = − 1 n ∑ x [ y l n a + ( 1 − y ) l n ( 1 − a ) ] C=-\frac{1}{n}\sum_{x}^{}[ylna+(1-y)ln(1-a)] C=−n1∑x[ylna+(1−y)ln(1−a)]
常见的激活函数有:Sigmoid,Tanh, ReLU, leaky ReLU
(1)Sigmoid函数:
f ( x ) = 1 1 + e − x f(x)=\frac{1}{1+e^{-x}} f(x)=1+e−x1
特点:它能够把输入的连续实值变换为0和1之间的输出,特别的,如果是非常大的负数,那么输出就是0;如果是非常大的正数,输出就是1.
缺点:
-
缺点1:在深度神经网络中梯度反向传递时导致梯度消失,其中梯度爆炸发生的概率非常小,而梯度消失发生的概率比较大。
-
缺点2:sigmoid的output不是0均值(即zero-centered)。
-
缺点3:其解析式中含有幂运算,计算机求解时相对来讲比较耗时。对于规模比较大的深度网络,这会较大地增加训练时间。
(2)Tanh函数:t a n h ( x ) = e x − e − x e x + e − x tanh(x)=\frac{e^{x}-e^{-x}}{e^{x}+e^{-x}} tanh(x)=ex+e−xex−e−x
特点:它解决了sigmoid函数的不是zero-centered输出问题,收敛速度比sigmoid要快,然而,梯度消失(gradient vanishing)的问题和幂运算问题仍然存在。(3)ReLU函数:f(x)=max(0,x)
特点: -
1.ReLU函数是利用阈值来进行因变量的输出,因此其计算复杂度会比剩下两个函数低(后两个函数都是进行指数运算)
-
2. ReLU函数的非饱和性可以有效地解决梯度消失的问题,提供相对宽的激活边界。
-
3.ReLU的单侧抑制提供了网络的稀疏表达能力。
-
4.ReLU的局限性:在于其训练过程中会导致神经元死亡的问题。
这是由于函数导致负梯度在经过该ReLU单元时被置为0,且在之后也不被任何数据激活,即流经该神经元的梯度永远为0,不对任何数据产生响应。在实际训练中,如果学习率设置较大,会导致超过一定比例的神经元不可逆死亡,进而参数梯度无法更新,整个训练过程失败。(4)LeaKy ReLU函数:f ( x ) = { x ( x > 0 ) a x ( x ≤ 0 ) f(x)=\left\{\begin{matrix} x &(x>0) & \\ ax& (x\leq 0) & \end{matrix}\right. f(x)={xax(x>0)(x≤0)
LReLU与ReLU的区别在于,当x<0时,其值不为0,而是一个斜率为a的线性函数,一般a为一个很小的正常数,这样既实现了单侧抑制,又保留了部分负梯度信息以致不完全丢失。但另一方面,a值的选择增加了问题难度,需要较强的人工先验或多次重复训练以确定合适的参数值。(5) PReLU基于此,参数化的PReLU(Parametric ReLU)应运而生。它与LReLU的主要区别是将负轴部分斜率a作为网络中一个可学习的参数,进行反向传播训练,与其他含参数网络层联合优化。而另一个LReLU的变种增加了“随机化”机制,具体地,在训练过程中,斜率a作为一个满足某种分布的随机采样;测试时再固定下来。Random ReLU(RReLU)在一定程度上能起到正则化的作用。
(6)ELU函数:f ( x ) = { x , x > 0 a ( e x − 1 ) , x ≤ 0 f(x)=\left\{\begin{matrix} x &, &x>0 \\ a(e^{x}-1)& ,& x\leq 0 \end{matrix}\right. f(x)={xa(ex−1),,x>0x≤0
ELU 函数是针对ReLU函数的一个改进型,相比于ReLU函数,在输入为负数的情况下,是有一定的输出的,而且这部分输出还具有一定的抗干扰能力。这样可以消除ReLU死掉的问题,不过还是由梯度饱和和指数运算的问题。
- 分类问题为什么不用MSE,而是要用交叉熵
LR的基本表达形式如下:
h θ x = g ( θ T x ) = 1 1 + e − θ T x h_\theta {x}=g(\theta ^{T}x)=\frac{1}{1+e^{-\theta ^{T}}x} hθx=g(θTx)=1+e−θTx1
使用交叉熵作为损失函数的梯度下降更新求导的结果如下:
首先得到损失函数如下:
C = 1 n ∑ [ y l n y ^ + ( 1 − y ) l n ( 1 − y ^ ) ] C=\frac{1}{n}\sum [yln\hat{y}+(1-y)ln(1-\hat{y})] C=n1∑[ylny^+(1−y)ln(1−y^)]
如果我们使用MSE(均方误差)作为损失函数的话,那损失函数以及求导的结果如下所示:
C = ( y − y ^ ) 2 2 C=\frac{\left ( y-\hat{y} \right )^{2}}{2} C=2(y−y^)2
∂ C ∂ w = ( y ^ − y ) σ ′ ( z ) ( x ) \frac{\partial C}{\partial w}=(\hat{y}-y){\sigma }'(z)(x) ∂w∂C=(y^−y)σ′(z)(x)
使用平方损失函数,会发现梯度更新的速度和sigmoid函数本身的梯度是很相关的。sigmoid函数在它定义域内的梯度都不大于0.25.这样训练就会非常慢。使用交叉熵的话就不会出现这样的情况,它的导数就是一个差值,误差大的话更新的就快,误差小的话就更新的慢点,这正是我们想要的。
在使用sigmoid函数作为正样本的概率时,同时将平方损失作为损失函数,这时所构造出来的损失函数是非凸的,不容易求解,容易得到其局部最优解。如果使用极大似然,其目标函数就是对数似然函数,该损失函数是关于未知参数的高阶连续可导的凸函数,便于求其全局最优解。(关于是否是凸函数,由凸函数的定义得,对于一元函数,其二阶导数总是非负,对于多元函数,其Hessian矩阵(Hessian矩阵是由多元函数的二阶导数组成的方阵)的正定性来判断。) - F1score的计算公式
要计算F1score,首先要计算Precision和Recall,公式如下:
P r e c i s i o n = T P T P + F P Precision=\frac{TP}{TP+FP} Precision=TP+FPTP
R e c a l l = T P T P + F N Recall=\frac{TP}{TP+FN} Recall=TP+FNTP
F − s c o r e = 2 P R P + R F-score=\frac{2PR}{P+R} F−score=P+R2PR - 蒸馏的思想,为什么要蒸馏
知识蒸馏就是将已经训练好的模型包含的知识,蒸馏到另一个模型中去。具体来说,知识蒸馏,可以将一个网络的知识转移到另一个网络,两个网络可以是同构或者异构。做法是先训练一个teacher网络,然后使用这个teacher网络的输出和数据的真实标签去训练student网络。
在训练过程中,需要使用复杂的模型,大量的计算资源,以便从非常大、高度冗余的数据集中提取出信息。在实验中,效果最好的模型往往规模很大,甚至由多个模型集成得到。而大模型不方便部署到服务中去,常见的瓶颈如下:
(1)推断速度慢
(2)对部署资源要求高(内存、显存等),在部署时,我们对延迟以及就散资源都有着严格的限制。
因此,模型压缩(在保证性能的前提下减少模型的参数量)成为了一个重要的问题。而“模型蒸馏”属于模型压缩的一种方法。 - 消融实验
类似于“控制变量法”。
假设在某目标检测系统中,使用了A,B,C,取得了不错的效果,但是这个时候你并不知道这不错的效果是由于A,B,C中哪一个起的作用,于是你保留A,B,移除C进行实验来看一下C在整个系统中所起的作用。
3、机器学习
3.1 KNN
KNN算法的思想:
在训练数据集中数据和标签已知的情况下,输入测试数据,将测试数据的特征与训练集中对应的特征进行相互比较,找到训练集中与之最为相似的前K个数据,则该测试数据对应的类别就是K个数据中出现次数最多的那个分类,其算法的描述为:
(1)计算测试数据与各个训练数据之间的距离;
(2)按照距离的递增关系进行排序;
(3)选取距离最小的K个点;
(4)确定前K个点坐在的类别的出现频率;
(5)返回前K个点中出现频率最高的类别作为测试数据的预测分类。
KNN的K设置的过大会有什么问题
KNN中的K值选取对K近邻算法的结果会产生重大影响。
如果选择较小的K 值,就相当于用较小的领域中的训练实例进行预测,“学习”近似误差(近似误差:可以理解为对现有训练集的训练误差)会减小,只有与输入实例较近或相似的训练实例才会对预测结果起作用,与此同时带来的问题是“学习”的估计误差会增大,换句话说,K值的减小就意味着整体模型变得复杂,容易发生过拟合;
如果选择较大的K值,就相当于用较大的领域中的训练实例进行预测,其优点是可以减少学习的估计误差,但缺点是学习的近似误差会增大。这时候,与输入实例较远(不相似的)训练实例也会对预测起作用,使预测发生错误,且K值的增大就意味着整体的模型变得简单。
在实际应用中,K值一般取一个比较小的数值,例如采用交叉验证法来选择最优的K值。经验规则:K一般低于训练样本数的平方根。
3.2 GBDT 和bagging的区别,样本权重为什么会改变
GBDT是基于Boosting的算法。
Bagging和Boosting的区别:
(1)样本选择上:
Bagging:训练集是原始集中有放回选取的,从原始集中选出的各轮训练集之间是独立的。
Boosting:每一轮的训练集不变,只是训练集中每个样例在分类器中的权重发生变化。而权值是根据上一轮的分类结果进行调整。
(2)样例权重:
Bagging:使用均匀取样,每个样例的权重相等。
Boosting:根据错误率不断调整样例的权值,错误率越大则权重越大。
(3)预测函数:
Bagging:所有预测函数的权重相等。
Boosting:每个弱分类器都有相应的权重,对于分类误差小的分类器会有更大的权重。
(4)并行计算:
Bagging:各个预测函数可以并行生成。
Boosting:各个预测函数只能顺序生成,因为后一个模型参数需要前一轮模型的结果。
Boosting中样本权重发生改变的原因:
通过提高哪些在前一轮被弱分类器分错样例的权值,减小前一轮对样例的权值,来使得分类器对误分的数据有较好的效果。
3.3 梯度下降思想
梯度下降是一种非常通用的优化算法,能够为大范围的问题找到最优解.梯度下降的中心思想是迭代地调整参数从而使损失函数最小化.
假设你迷失在山上的迷雾中,你能感觉到只有你脚下路面的坡度。快速到达山脚的一个策略就是沿着最陡的方向下坡,这就是梯度下降的做法。即通过测量参数向量相关的损失函数的局部梯度,并不断沿着降低梯度的方向调整,知道梯度降为0,达到最小值。
梯度下降公式如下:
Θ : = Θ − η Δ l o s s \Theta :=\Theta -\eta \Delta loss Θ:=Θ−ηΔloss
对应到每个权重公式为:
w i : = w i − η ∂ l o s s ∂ w i w_{i}:=w_{i}-\eta \frac{\partial loss}{\partial w_{i}} wi:=wi−η∂wi∂loss
3.4 最小二乘法
最小二乘法(又称最小平方法)是一种数学优化技术。通过最小化误差的平方和寻找数据的最佳函数匹配。利用最小二乘法可以简便地求得未知的数据,并使得这些求得的数据与实际数据之间误差的平方和为最小。最小二乘法还可以用于曲线拟合,来解决回归问题。回归学习最常用的损失函数是平方损失函数,在此种情况下,回归问题可以用著名的最小二乘法来解决。最小二乘法是机器学习领域最有名和有效的算法之一,是机器学习最基础的算法。
所谓“二乘”就是平方的意思。
S ϵ 2 = ∑ ( y − y i ) 2 m i n = = = > ( t r u e − v a l u e ) y S_{\epsilon ^{2}}=\sum \left ( y-y_{i} \right )^{2} min ===> (true-value) y Sϵ2=∑(y−yi)2min===>(true−value)y
同一组数据,选择不同的f(x),通过最小二乘法可以得到不一样的拟合曲线。
不同的数据,更可以选择不同的f(x),通过最小二乘法可以得到不一样的拟合曲线。
3.5 线性模型
监督学习中,如果预测的变量是离散的,我们称其为分类(如决策树,支持向量机等),如果预测的变量是连续的,我们称其为回归。回归分析中,如果只包括一个自变量和一个因变量,且二者的关系可用一条直线近似表示,这种回归分析称为一元线性回归分析。如果回归分析中包括两个或两个以上的自变量,且因变量和自变量之间是线性关系,则称为多元线性回归分析。对于二维空间线性是一条直线;对于三维空间线性是一个平面,对于多维空间线性是一个超平面…
多元线性回归(n元1次):y=ax1+bx2+cx3+…
多项式回归 (n元n次): y = a x 1 n + b x 2 n − 1 + . . . y=ax_{1}^{n}+bx_{2}^{n-1}+... y=ax1n+bx2n−1+...
最小二乘法跟梯度下降法都是通过求导来求损失函数的最小值。
相同点:
1、本质相同:都是在给定已知数据(independent & dependent variables)的前提下对dependent variables算出一个一般性的估值函数。然后对给定数据的dependent variables进行估值。
2、目标相同:都是在已知数据的框架内,使得估算值与实际值的总平方差尽量更小(事实上未必一定要使用平方)。
3.6 FM vs SVM 的比较
FM和SVM最大的不同,在于特征组合时权重的计算方法
SVM的二元特征交叉参数是独立的,而FM的二元特征交叉参数是两个K维的向量v_i,v_j,交叉参数不是独立的,而是互相影响的。
FM可以在原始形势下进行优化学习,而基于kernel的非线性SVM通常需要在对偶形势下进行
FM的模型预测与训练样本独立,而SVM则与部分训练样本有关,即支持向量。
FM模型有两个优势:
(1)在高度稀疏的情况下特征之间的交叉仍然能够估计,而且可以泛化到未被观察的交叉参数的学习。
(2)模型的预测的时间复杂度是线性的。
3. 7 随机森林的随机性
随机森林的随机性体现在每棵树的训练样本是随机的,树中每个节点的分裂属性集合也是随机选择确定的。有了这两个随机的保证,随机森林就不会产生过拟合的现象了。
3.8 k-means 和谱聚类
(1)聚类算法属于无监督的机器学习算法,即没有类别标签y,需要根据数据特征将相似的数据分为一组。K-means聚类算法即随机选取K个点作为聚类中心,计算其它点与中心点的距离,选择距离最近的中心并归类,归类完成后计算每类的新中心点,重新计算每个点与中心点的聚类并选择距离最近的归类,重复此过程,直到中心点不再变化。
(2)谱聚类的思想是将样本看做顶点,样本间的相似度看做带权的边,从而将聚类问题转为图分割问题:找到一种图分割的方法使得连接不同组的边的权重尽可能低(这意味着组间相似度要尽可能低),组内的边的权重尽可能高(这意味着组内相似度要尽可能高),从而达到聚类的目的。
4、数据处理
4.1 归一化+标准化+中心化
1、定义
归一化:将样本的特征值转换到同一量纲下,把数据映射到[0,1]或者[-1,1]区间内,仅由变量的极值决定,因区间缩放法是归一化的一种。
标准化:依照特征矩阵的列处理数据,其通过求z-score的方法,转换为标准正态分布,和整体样本分布相关,每个样本点都能对标准化产生影响。
他们的相同点在于都能取消由于量纲不同引起的误差;都是一种线性变换,都是对向量X按照比例压缩再进行平移。线性变换不会改变原始数据的数值排序。
中心化:平均值为0,对标准差无要求。
标准化和中心化的区别:标准化是原始分数减去平均数然后除以标准差,中心化是原始分数减去平均数。所以一般流程为先中心化再标准化。
2、为什么要归一化/标准化:
(1)某些模型求解需求:
在使用梯度下降的方法求解最优化问题时,归一化/标准化后可以加快梯度下降的求解速度,即提升模型的收敛速度。未归一化/标准化时形成的等高线偏椭圆,迭代时很有可能走“之”字型路线(垂直长轴),从而导致迭代很多次才能收敛。对特征进行归一化后,对应的等高线就会变圆,在梯度下降进行求解时能较快的收敛。
在一些分类器需要计算样本之间的距离(如欧氏距离),例如KNN。如果一个特征值域范围非常大,那么距离计算就主要取决于这个特征,从而与实际情况相悖(比如这时实际情况是值域范围小的特征更重要)。
(2)无量纲化:归一化
(3)避免数值问题:太大的数会引发数值的问题。
3、数据预处理时:
3.1归一化:
(1)Min-Max归一化:
x’ = (x - X_min) / (X_max - X_min)
(2)平均归一化:
x’ = (x - μ) / (MaxValue - MinValue)
以上两个归一化有一个缺陷就是当有新数据加入时,可能导致max和min的变化,需要重新定义。
(3) 非线性归一化:
1)对数函数归一化:y=log10(x)
2)反余切函数转换:y=atan(x)*2/pai
经常用在数据分化比较大的场景,有些数据很大,有些很小。通过一些数学函数,将原始值进行映射。该方法包括log、指数、正切等。需要根据数据分布的情况,决定非线性函数的曲线,比如log(v,2)还是log(v,10)等。
3.2标准化
Z-score规范化(标准差标准化/零均值标准化):x’ = (x - μ)/σ
正态分布的期望、均数、中位数、众数相同,均等于μ,是正态分布的位置参数,描述正态分布的集中趋势位置。概率规律为取与μ邻近的值的概率大,而取离μ越远的值的概率越小。正态分布以X=μ为对称轴,左右完全对称。
σ描述正态分布资料数据分布的离散程度,σ越大,数据分布越分散,σ越小,数据分布越集中。也称为是正态分布的形状参数,σ越大,曲线越扁平,反之,σ越小,曲线越瘦高。
3.3中心化:
x’ = x - μ
4、什么时候用归一化/标准化
(1)如果对输出结果范围有要求,用归一化。
(2)如果数据较为稳定,不存在极端的最大最小值,用归一化。
(3)如果数据存在异常值和较多噪音,用标准化,可以间接通过中心化避免异常值和极端值的影响。一般优先使用标准化。
(4)在分类、聚类算法中,需要使用距离来度量相似性的时候、或者使用PCA技术进行降维的时候,用z-score 标准化表现更好。
(5)在不涉及距离度量、协方差计算、数据不符合正态分布的时候,可以使用线性归一化或其它归一化方法。比如图像处理中,将RGB图像转换为灰度图像后将其值限定在[0,255]的范围。
5、哪些模型必须归一化/标准化
(1)SVM
(2)KNN
(3)神经网络
4.2 pandas
panda如何读取超大型文件
data_path=r"E:\demo.csv"
def read_bigfile(path):
#分块,每一块是一个chunk,之后将chunk进行拼接
df=pd.read_csv(path,engine='python',encoding="gbk",iterator=True)
loop=True
chunkSize=10000
chunks=[]
while loop:
try:
chunk= df.get_chunk(chunkSize)
chunks.append(chunk)
except StopIteration:
loop =False
print("Iteration is stopped.")
df=pd.concat(chunks,ignore_index=True)
after_df=read_bigfile(path=data_path)
4.3 Python在内存上做了哪些优化?
python通过内存池来减少内存碎片化,提高执行效率。主要通过引用计数来完成垃圾回收,通过标记-清除解决容器对象循环引用造成的问题,通过分代回收提高垃圾回收的效率。
4.4 怎么节省内存
手动回收不需要用的变量;
将数值型数据转化为32位或16位(对数据类型进行限制)
代码示例如下:
def reduce_mem_usage(props):
# 计算当前内存
start_mem_usg = props.memory_usage().sum() / 1024 ** 2
print("Memory usage of the dataframe is:", start_mem_usg, "MB")
# 哪些列包含空值,空值用-999填充。why:因为np.nan当做float处理
NAlist = []
for col in props.columns:
# 这里只过滤了object格式,如果你的代码中还包含其他类型,请一并过滤
if (props[col].dtypes != object):
print('*******************')
print("columns:",col)
print("dtype before",props[col].dtype)
#判断是否是int类型
isInt =False
mmax=props[col].max()
mmin=props[col].min()
#Integer does not support NA,therefore Na needs to be filled
if not np.isfinite(props[col]).all():
NAlist.append(col)
props.fillna(-999,inplace=True)#用-999填充
#test if column can be conberted to an integer
asint=props[col].fillna(0).astype(np.int64)
result=np.fabs(props[col]-asint)
result=result.sum()
if result < 0.01:#绝对误差和小于0.01认为可以转换的,要根据task修改
isInt =True
#make integer /unsigned Integer datatypes
if isInt:
if mmin >=0: # 最小值大于0,转换成无符号整型
if mmax <=255:
props[col]=props[col].astype(np.uint8)
elif mmax<=65535:
props[col]=props[col].astype(np.uint16)
elif mmax<=4294967295:
props[col]=props[col].astype(np.uint32)
else:
props[col]=props[col].astype(np.uint64)
else:#转换为有符号整型
if mmin>np.iinfo(np.int8).min and mmax<np.iinfo(np.int8).max:
props[col]=props[col].astype(np.int8)
elif mmin>np.iinfo(np.int16).min and mmax<np.iinfo(np.int16).max:
props[col]=props[col].astype(np.int16)
elif mmin>np.iinfo(np.int32).min and mmax<np.iinfo(np.int32).max:
props[col]=props[col].astype(np.int32)
elif mmin>np.iinfo(np.int64).min and mmax<np.iinfo(np.int64).max:
props[col]=props[col].astype(np.int64)
else:#注意:这里对于float都转换成float16,需要根据情况更改
props[col]=props[col].astype(np.float16)
print('dtype after',props[col].dtype)
print("****************")
print("__MEMORY USAGE AFTER COMPLETION:__")
mem_usg=props.memory_usage().sum()/1024**2
print("Memory usage is :",mem_usg,"MB")
print("This is ",100*mem_usg/start_mem_usg,"%of the iniitial sise")
if __name__=="__main__":
props??? dataframe??
reduce_mem_usage(props)
4.5 如何解决数据不平衡问题?
答:
1、利用重采样中的下采样和上采样,对小数据类别采用上采样,通过复制来增加数据,不过这种情况容易出现过拟合,建议用数据扩增的方法,对原有数据集进行翻转,旋转,平移,尺度拉伸,对比度,亮度,色彩变化来增加数据。对大数据类别剔除一些样本量。
2、组合不同的重采样数据集:假设建立十个模型,选取小数据类1000个数据样本,然后将大数据类别10000个数据样本分为十份,每份为1000个,并训练十个不同的模型。
3、更改分类器评价指标: 在传统的分类方法中,准确率是常用的指标。 然而在不平衡数据分类中,准确率不再是恰当的指标,采用精准率即查准率P:真正例除以真正例与假正例之和。召回率即查全率F。真正例除以真正例与假反例之和。或者F1分数查全率和查准率加权衡=2*P*R/(P+R)。
4.6 对于训练集与验证集测试集分布不同的处理办法
1、若训练集与验证集来自不同分布,比如一个网络爬虫获取的高清图像,一个是手机不清晰图像,人工合成图像,比如不清晰图像,亮度高的图像。
2、两种来源的数据一个来源数据大比如20万张,一个来源数据小,如五千张小数据集是我们优化目标,一种情况是将两组数据合并在一起,然后随机分配到训练验证测试集中。好处是,三个数据集来自同一分布。缺点:瞄准目标都是大数据那一类的数据,而不是我们的目标小数据集。另外一种情况是训练集全部用大数据集,开发与测试集都是小数据集数据,优点:瞄准目标,坏处是不同分布。
3、分析偏差和方差方法和同一分布的方法不一样,加一个训练开发集(从训练集留出一部分数据)。总共四个数据集,训练集、训练开发集、开发集、测试集。看训练开发集的准确率与训练集验证集的区别来判别式方差还是数据分布不匹配的造成的误差。
具体看如下链接:https://blog.csdn.net/koala_tree/article/details/78319908
4.7 什么是数据正则化/归一化(normalization)?为什么我们需要它?
我觉得这一点很重要。数据归一化是非常重要的预处理步骤,用于重新缩放输入的数值以适应特定的范围,从而确保在反向传播期间更好地收敛。一般来说采取的方法都是减去每个数据点的平均值并除以其标准偏差。如果我们不这样做,那么一些特征(那些具有高幅值的特征)将在cost函数中得到更大的加权(如果较高幅值的特征改变1 %,则该改变相当大,但是对于较小的特征,该改变相当小)。数据归一化使所有特征的权重相等。
4.8 降维
解释降维(dimensionality reduction),降维在哪里使用,降维的好处是什么?
降维是通过获得一组基本上是重要特征的主变量来减少所考虑的特征变量的过程。特征的重要性取决于特征变量对数据信息表示的贡献程度
数据集降维的好处可以是:
( 1 )减少所需的存储空间。
( 2 )加快计算速度(例如在机器学习算法中),更少的维数意味着更少的计算,并且更少的维数可以允许使用不适合大量维数的算法。
( 3 )将数据的维数降低到2D或3D可以允许我们绘制和可视化它,可能观察模式,给我们提供直观感受。
( 4 )太多的特征或太复杂的模型可以导致过拟合。
4.9 opencv-python图片 数据类型
用opencv读入图像时:读入默认是uint8格式的numpy array(矩阵)
src=cv2.imread('1.jpg')
print('0',type(src),src.shape,src.dtype)
#0 (1405, 2500, 3) uint8
filter=np.array([[1, 1], [1, 2]])
print(filter.dtype)
#int32
res=cv2.filter2D(src,-1,filter)
print('1',type(res))
#1 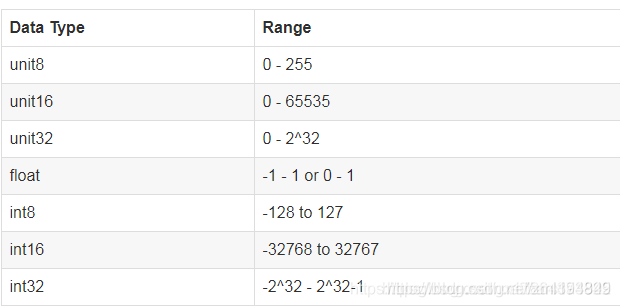
4.10 逻辑回归
逻辑回归是一个分类算法,那么它是在回归什么呢?
逻辑回归是在数据服从伯努利分布的假设下,通过极大似然的方法,运用梯度下降法来求解参数,从而达到将数据二分类的目的。
逻辑回归就是一种减小预测范围,将预测值限定为[0,1]间的一种广义线性回归模型,解决的是分类问题。
4.11GBDT
GBDT了解吗?基分类器用的是什么?分类时也是用的那个吗?
- GBDT是梯度提升决策树,是一种基于Boosting的算法,采用以决策树为基学习器的加法模型,通过不断拟合上一个弱学习器的残差,最终实现分类或回归的模型。关键在于利用损失函数的负梯度在当前模型的值作为残差的近似值,从而拟合一个回归树。
- GBDT的基分类器用的是决策树,分类时也是用的决策树。
- 对于分类问题:常使用指数损失函数;对于回归问题:常使用平方误差损失函数(此时,其负梯度就是通常意义的残差),对于一般损失函数来说就是残差的近似。
4.12 XGBoosting相对GBDT原理上有哪些改进。
改进主要为一下方面:
- 传统的GBDT以CART树作为基学习器,XGBoost还支持线性分类器,这个时候XGBoost相当于L1和L2正则化的逻辑回归(分类)或者线性回归(回归);
- 传统的GBDT在优化的时候只用到一阶导数信息,XGBoost则对代价函数进行了二阶泰勒展开,得到一阶和二阶导数;
- XGBoost在代价函数中加入了正则项,用于控制模型的复杂度。从权衡方差偏差来看,它降低了模型的方差,使学习出来的模型更加简单,防止过拟合,这也是XGBoost优于传统GBDT的一个特性;
- shrinkage(缩减),相当于学习速率(XGBoost中的eta)。XGBoost在进行完一次迭代时,会将叶子节点的权值乘上该系数,主要是为了削弱每棵树的影响,让后面有更大的学习空间。(GBDT也有学习速率);
- 列抽样:XGBoost借鉴了随机森林的做法,支持列抽样,不仅防止过拟合,还能减少计算;
- 对缺失值的处理:对于特征的值有缺失的样本,XGBoost还可以自动学习出它的分裂方向;
- XGBoost 工具支持并行。Boosting不是一种串行的结构吗?怎么并行的?注意XGBoost的并行不是tree粒度的并行,XGBoost也是一次迭代完才能进行下一次迭代的(第t次迭代的代价函数里包含了前面t-1次迭代的预测值)。XGBoost的并行是在特征粒度上的。我们知道,决策树的学习最耗时的一个步骤是对特征的值进行排序(因为要确定最佳分割点),XGBoost在训练之前,预先对数据进行了排序,然后保存为block结构,后面的迭代中重复地使用这个结构,大大减小计算量。这个block结构也使得并行成为了可能,在进行节点的分裂时,需要计算每个特征的增益,最终选增益最大的那个特征去做分裂,那么各个特征的增益计算就可以开多线程进行。
参考链接:https://blog.csdn.net/comway_Li/article/details/82532573