论文研读2018:卷积中的注意力和keras实现。CBAM: Convolutional Block Attention Module
文章目录
- Abstract
- 1 Introduction
- 2 Related Work
- 3 Convolutional Block Attention Module
-
- Channel attention module
-
- 代码
- Spatial attention module
-
- 代码
- Arrangement of attention modules
- 4 Experiments
-
- 4.1 Ablation studies
-
- Channel attention
- Spatial attention
- Arrangement of the channel and spatial attention
- Final module design.
- 4.3 Network Visualization with Grad-CAM
论文原版下载
Abstract
提出了Convolutional Block Attention Module (CBAM),
轻量级,能嵌入任何CNN之间。
在通道和空间中增减了注意力机制。
模块在MS COCO,imagenet-1k,VOC2007目标检测数据集上测试,测试结果表明加上我们的模块有巨大的提升。
1 Introduction
深度,宽度,基数,注意力
影响CNN的三个重要因素:深度,宽度,基数(即更多的分支)。
基数增加影响模型效果如:Xception and ResNeXt。它们的经验表明,基数不仅节省了参数的总数,而且比其他两个因素:深度和宽度具有更强的表示能力。
除了前面的这些点,我们探究了注意力机制对卷积的影响。
参数量
参数量确实不太大,但我不知道为什么我自己直接套用的时候为什么会出现模型收敛慢的情况,建议大家多尝试。
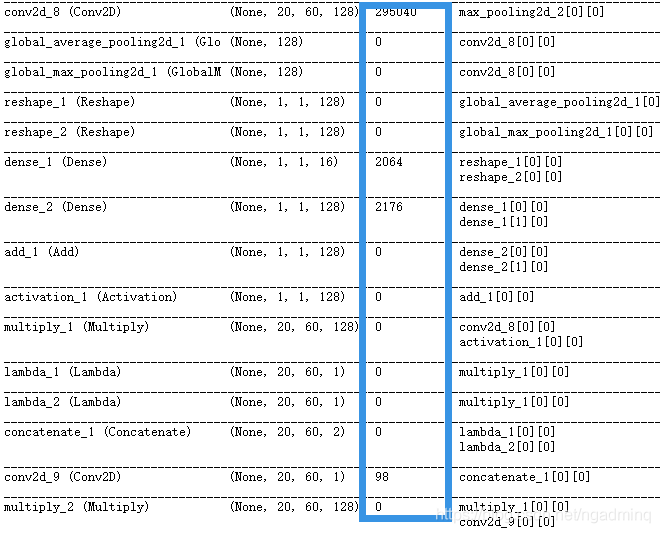
下图是我在训练时加上的本论文提出来的模块。
2 Related Work
Residual Attention Network
与我们类似的工作是Residual Attention Network ,他用了编码器解码器的风格来构造注意力。通过细化特征映射,网络不仅性能良好,而且对噪声输入具有鲁棒性。
我们不直接对三维特征图做计算,而是分别分解学习信道注意和空间注意的过程。这种做法将减少参数计算量,并且我们的模块返回的维度与输入维度相同,这将能够使得其能够完成即插即用特点(感觉这是现在很多注意力机制都怎么做,即最低需求就是对输入维度的重分配权重)。
** Squeeze-and-Excitation**
介绍了一种紧凑的模块利用信道间的关系。
用全局平均池化特征去计算通道的注意力机制。
然而,我们发现这些都是次优特征,以推断精细的信道注意,我们建议也使用最大池特征。
我们的工作是不仅仅考虑了通道间的信息,还考虑了空间信息。【其实感觉也没什么大的创新的】
3 Convolutional Block Attention Module
spatial attention:
channel attention


Channel attention module
意义
顾名思义是关注各个通道的信息,通道注意力机制关注输入的图像“什么”是有意义的。
为了有效计算通用的注意力机制,会压缩输入的特征维度。
使用模块
**平均池化:**用于聚集空间信息,这在一些论文中被表面他能有效的学习空间信息。
**最大池化:**为了有更丰富的信息,我们还多使用了最大池化。
作者实验证明了这两种池化合用比单个使用更好。
如下图空间子模块利用类似的两个输出,它们沿着信道轴汇集并转发到卷积层

共享网络:由一个隐藏层组成。为了降低参数开销,隐藏层的激活函数设置为了C/r,r代表降低率。然后再将两个网络进行相加
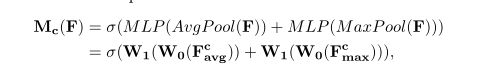
注意W0和W1是共享输入的,它后面跟了一个relu。
图有个错误:dense_2没有接relu层,但我太懒得再修改图了,这个修改要重头画,其他注解地方都是正确的。

代码
def channel_attention(input_feature, ratio=8):
channel_axis = 1 if K.image_data_format() == "channels_first" else -1
channel = input_feature._keras_shape[channel_axis]
# 折扣率,用来节省开销
shared_layer_one = Dense(channel // ratio,
activation='relu',
kernel_initializer='he_normal',
use_bias=True,
bias_initializer='zeros')
shared_layer_two = Dense(channel,
kernel_initializer='he_normal',
use_bias=True,
bias_initializer='zeros')
avg_pool = GlobalAveragePooling2D()(input_feature)
avg_pool = Reshape((1, 1, channel))(avg_pool)
assert avg_pool._keras_shape[1:] == (1, 1, channel)
avg_pool = shared_layer_one(avg_pool)
assert avg_pool._keras_shape[1:] == (1, 1, channel // ratio)
avg_pool = shared_layer_two(avg_pool)
assert avg_pool._keras_shape[1:] == (1, 1, channel)
max_pool = GlobalMaxPooling2D()(input_feature)
max_pool = Reshape((1, 1, channel))(max_pool)
assert max_pool._keras_shape[1:] == (1, 1, channel)
max_pool = shared_layer_one(max_pool)
assert max_pool._keras_shape[1:] == (1, 1, channel // ratio)
max_pool = shared_layer_two(max_pool)
assert max_pool._keras_shape[1:] == (1, 1, channel)
cbam_feature = Add()([avg_pool, max_pool])
cbam_feature = Activation('sigmoid')(cbam_feature)
if K.image_data_format() == "channels_first":
cbam_feature = Permute((3, 1, 2))(cbam_feature)
return multiply([input_feature, cbam_feature])
Spatial attention module
做了什么
与通道注意力不同,空间注意力机制关注的是“哪里”,这是对通道注意力机制的补充。

模块
**卷积层:**模块的开头接了一个卷积层是为了生成一个注意力映射空间。
![]()
这与通道的不同最明显的就是映射的维度不同。

代码
def spatial_attention(input_feature):
kernel_size = 7
if K.image_data_format() == "channels_first":
channel = input_feature._keras_shape[1]
cbam_feature = Permute((2, 3, 1))(input_feature)
else:
channel = input_feature._keras_shape[-1]
cbam_feature = input_feature
avg_pool = Lambda(lambda x: K.mean(x, axis=3, keepdims=True))(cbam_feature)
assert avg_pool._keras_shape[-1] == 1
max_pool = Lambda(lambda x: K.max(x, axis=3, keepdims=True))(cbam_feature)
assert max_pool._keras_shape[-1] == 1
concat = Concatenate(axis=3)([avg_pool, max_pool])
assert concat._keras_shape[-1] == 2
cbam_feature = Conv2D(filters=1,
kernel_size=kernel_size,
strides=1,
padding='same',
activation='sigmoid',
kernel_initializer='he_normal',
use_bias=False)(concat)
assert cbam_feature._keras_shape[-1] == 1
if K.image_data_format() == "channels_first":
cbam_feature = Permute((3, 1, 2))(cbam_feature)
return multiply([input_feature, cbam_feature])
Arrangement of attention modules
我们发现,顺序排列比平行排列提供了更好的结果。
并且实验表明先关注通道再关注空间比顺序反过来效果会好一点。
4 Experiments
实验给出了CBAM嵌入resblock的图。
4.1 Ablation studies
实验部分,常规操作,所以我只贴截图了

Channel attention
实验目的
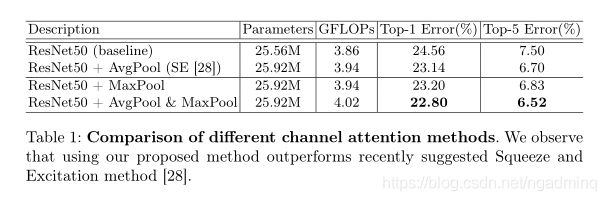
两个池联合使用有没有用?还是单个更有用?
实验设置
我们比较了信道注意的3个变量:平均池、最大池和两个池的联合使用
请注意,具有平均池的信道注意模块与se模块相同。 此外,当使用这两个池时,我们使用共享的MLP进行注意推理以保存参数,因为聚合的信道特征都位于相同的语义嵌入空间中。 **在本实验中,我们只使用通道注意模块,**并将 reduction ratio固定为16。
结果
下表表明联合使用的效果更好,联合使用最大池化的效果会好点儿。
Spatial attention
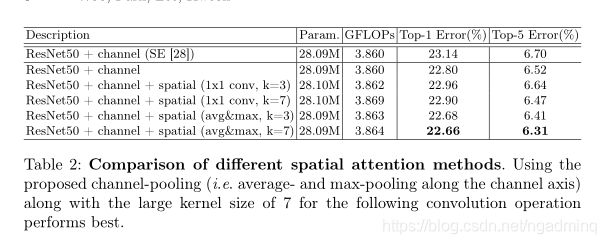
实验目的
信道池使用平均和最大池跨越信道轴和标准1×1的卷积,将信道维数减少到1。
实验结果
Arrangement of the channel and spatial attention
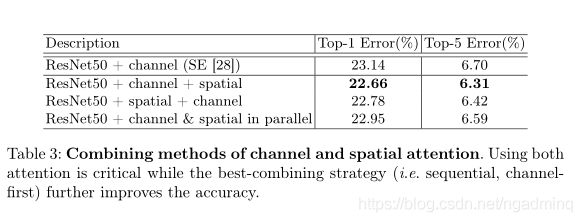
Final module design.
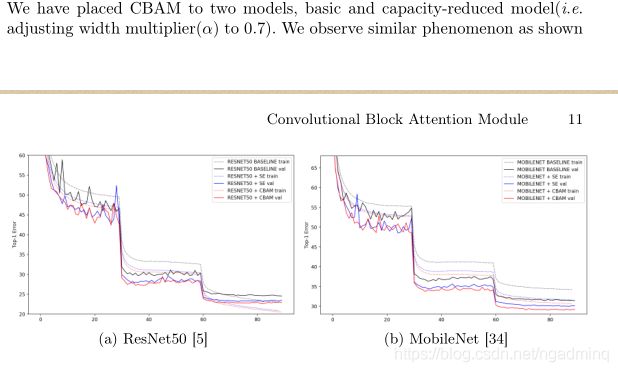
证明CBAM可以很好地推广到大规模数据集中的各种模型上。

We also find that the overall overhead of CBAM is quite small in terms of both
parameters and computation.
4.3 Network Visualization with Grad-CAM
为了证明它效果好,还用了可视化。
Grad-CAM是最近提出的一种利用梯度来计算卷积层空间位置重要性的可视化方法。
The softmax scores for a target class are also shown in the figure
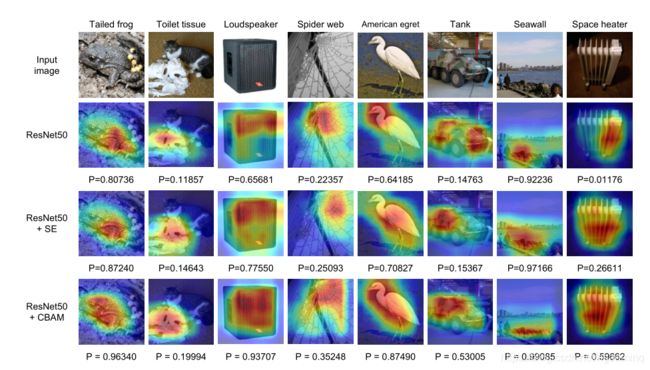
p denotes the softmax score of each network for the ground-truth class.