Spark 3.0参数详解之 spark.sql.files.maxPartitionBytes
1、对应源码位置
在接口FileScan的partitions方法中
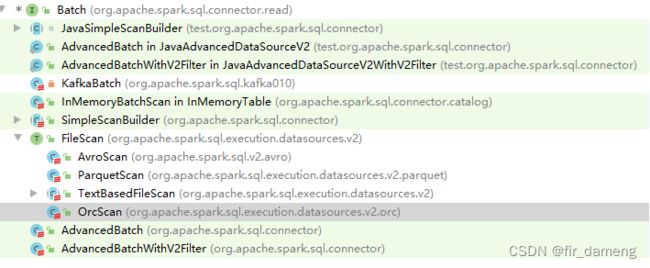
org.apache.spark.sql.execution.datasources.v2.FileScan#partitions:
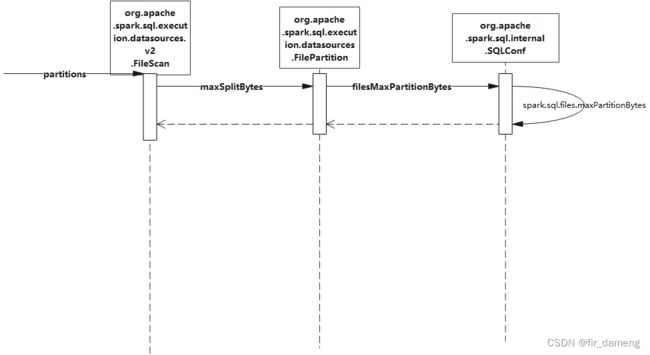
2、生效原理
2.1、关键方法之 partitions
org.apache.spark.sql.execution.datasources.v2.FileScan#partitions:
protected def partitions: Seq[FilePartition] = {
val selectedPartitions = fileIndex.listFiles(partitionFilters, dataFilters)
// 下面这行代码底层会读取spark.sql.files.maxPartitionBytes参数配置
val maxSplitBytes = FilePartition.maxSplitBytes(sparkSession, selectedPartitions)
val partitionAttributes = fileIndex.partitionSchema.toAttributes
val attributeMap = partitionAttributes.map(a => normalizeName(a.name) -> a).toMap
val readPartitionAttributes = readPartitionSchema.map { readField =>
attributeMap.getOrElse(normalizeName(readField.name),
throw QueryCompilationErrors.cannotFindPartitionColumnInPartitionSchemaError(
readField, fileIndex.partitionSchema)
)
}
lazy val partitionValueProject =
GenerateUnsafeProjection.generate(readPartitionAttributes, partitionAttributes)
// 返回切分后的文件
val splitFiles = selectedPartitions.flatMap { partition =>
// Prune partition values if part of the partition columns are not required.
val partitionValues = if (readPartitionAttributes != partitionAttributes) {
partitionValueProject(partition.values).copy()
} else {
partition.values
}
partition.files.flatMap { file =>
val filePath = file.getPath
// 开始所选分区内的文件按maxSplitBytes进行切分
PartitionedFileUtil.splitFiles(
sparkSession = sparkSession,
file = file,
filePath = filePath,
isSplitable = isSplitable(filePath),
maxSplitBytes = maxSplitBytes,
partitionValues = partitionValues
)
}.toArray.sortBy(_.length)(implicitly[Ordering[Long]].reverse)
}
if (splitFiles.length == 1) {
val path = new Path(splitFiles(0).filePath)
if (!isSplitable(path) && splitFiles(0).length >
sparkSession.sparkContext.getConf.get(IO_WARNING_LARGEFILETHRESHOLD)) {
logWarning(s"Loading one large unsplittable file ${path.toString} with only one " +
s"partition, the reason is: ${getFileUnSplittableReason(path)}")
}
}
// 获取切分后分区数据
FilePartition.getFilePartitions(sparkSession, splitFiles, maxSplitBytes)
}
2.2、关键方法之 maxSplitBytes
org.apache.spark.sql.execution.datasources.FilePartition#maxSplitBytes:
def maxSplitBytes(
sparkSession: SparkSession,
selectedPartitions: Seq[PartitionDirectory]): Long = {
// 这里获取配置的spark.sql.files.maxPartitionBytes值,默认128M,表示每个分区读取的最大数据量
val defaultMaxSplitBytes = sparkSession.sessionState.conf.filesMaxPartitionBytes
// 默认为4M,小于这个大小的文件将会合并到一个分区,可以理解为每个分区的最小量,避免碎文件造成的大量碎片任务。
val openCostInBytes = sparkSession.sessionState.conf.filesOpenCostInBytes
// 默认为spark.default.parallelism,yarn默认为应用cores数量或2,建议的最小分区数
val minPartitionNum = sparkSession.sessionState.conf.filesMinPartitionNum
.getOrElse(sparkSession.leafNodeDefaultParallelism)
// 计算所选择分区的大小(加上分区最小量)
val totalBytes = selectedPartitions.flatMap(_.files.map(_.getLen + openCostInBytes)).sum
// 计算每个core所分摊的数据大小
val bytesPerCore = totalBytes / minPartitionNum
// min(分区最大数据量,max(分区最小数据量, 1core所分摊数据量))
// 其实这就限制了分区大小一定在 [openCostInBytes,defaultMaxSplitBytes] 之间
Math.min(defaultMaxSplitBytes, Math.max(openCostInBytes, bytesPerCore))
}
2.3、关键方法之 splitFiles
org.apache.spark.sql.execution.PartitionedFileUtil#splitFiles
def splitFiles(
sparkSession: SparkSession,
file: FileStatus,
filePath: Path,
isSplitable: Boolean,
maxSplitBytes: Long,
partitionValues: InternalRow): Seq[PartitionedFile] = {
if (isSplitable) {
(0L until file.getLen by maxSplitBytes).map { offset =>
val remaining = file.getLen - offset
val size = if (remaining > maxSplitBytes) maxSplitBytes else remaining
val hosts = getBlockHosts(getBlockLocations(file), offset, size)
PartitionedFile(partitionValues, filePath.toUri.toString, offset, size, hosts,
file.getModificationTime, file.getLen)
}
} else {
Seq(getPartitionedFile(file, filePath, partitionValues))
}
}
3、如何使用
调小 spark.sql.files.maxPartitionBytes 可提高map任务数,但注意最后要合并小文件,否则数据写入hdfs会造成小文件过多
4、参考
https://blog.csdn.net/longlovefilm/article/details/119734637
http://www.jasongj.com/spark/committer/
https://juejin.cn/post/6844903535889383438