背景
为了快速适应业务变化,聚焦业务迭代,各大厂商都进行了分布式架构的升级改造。特别是近几年,随着微服务与云原生的流行,分布式系统的规模愈发庞大,内部服务之间的调用也越来越复杂。
然而,引入分布式架构的同时,也带来相应的稳定性问题。各项服务的开发人员、开发语言和部署节点等情况很可能各不相同,当分布式系统整体出现异常或者性能瓶颈的时候,依靠传统的指标监控和日志排查已经很难快速定位到出问题的地方。因此当下分布式系统对可观测性提出了更高的要求,需要能够解决以下痛点:
● 如何动态的展示各服务之间的调用链路?
● 如何快速定位故障?
● 如何分析性能瓶颈并加以调优?
分布式链路追踪系统
基于上述痛点,分布式链路追踪系统应运而生,其目的在于通过洞察分布式服务之间的相互调用,自动发现系统存在的稳定性隐患,从而为 SRE & 研发 定位风险提供有效的数据支撑。分布式链路追踪可以通过以下两块内容完整还原一整条调用链路:
● Trace ID: 代表唯一一次请求的 ID,此 ID 一般由集群中第一个处理请求的系统产生,并在分布式调用下通过网络传递到下一个被请求系统。
● Span: 代表了本次请求的完整信息,包括调用是否成功,调用类型,调用耗时等等。其中最核心是Span ID,代表了本次请求在整个调用链路中的位置或者说层次。
同时,基于链路聚合可以产生站点内部流量的全局视角,形成网络拓扑。
分布式链路追踪系统近年来发展迅速,业内也涌现出了一些开源项目和框架,并且为了实现各项目和框架的接口的统一,发展出了 OpenTracing 与 OpenTelemetry 等标准。通过链路标准的制定和推广,有利于用户通过一套数据采集、处理、导出流程,轻松对接多种云厂商,避免vendor锁定,有效的降低了对接和使用的成本。
BOS一直以来致力于为用户提供无缝的可观测能力,持续拥抱可观测性标准,作为OpenTelemetry项目的重要贡献者,率先在业内提供了完整的异构应用 OpenTelemetry 链路接入方案,并已经在众多机构中成功落地。
产品能力
业务智能可观测服务 BOS(Business-Intelligent Observability Service)是基于蚂蚁大规模技术风险防控实践自研的一套运维平台,具有业务数字化运维、全息可观测定位、智能场景化防控、一体化数据分析和大规模实践等产品特性,将业务场景可视化和数据业务语义化,赋能云上/云下的异构应用开箱即用的智能可观测能力,为业务提供全方位的稳定性保障,建设业务观测新范式,让稳定更有力量。
BOS的分布式链路追踪系统提供了以下丰富的产品功能,致力于帮助用户定位和解决微服务架构下的性能问题:
● 应用调用拓扑及详细性能指标
○ 根据链路数据动态生成,帮助用户梳理微服务架构下各应用之间的调用关系。
○ 根据调用耗时,调用错误率等性能指标,自动定位和标注异常应用和异常调用关系,帮助用户快速定位故障。
● 链路数据查询
○ 支持多维度的查询条件,例如超过多少耗时,调用是否失败,具体的调用接口和方法等等,准确定位到感兴趣的调用关系,进而跳转到具体而详细的链路详情展示。
● 链路详情展示
○ 通过多种展现方式,例如树状图,拓扑图、时序图等,帮助用户观测到单条链路的完整调用关系。
○ 根据每次调用的成功与否以及耗时,自动标注出整条链路中异常或者潜在性能瓶颈的调用,帮助用户快速定位具体的单次调用,通过详尽的单次调用详情,助力用户进行应用调优。
○ 在链路详情中同时打通了与监控和日志数据的关联,用户可以非常容易的查看到相关联的全量可观测性数据,帮助定位问题的根本原因。
为了方便用户完成接入,BOS提供了业内所有常用的链路数据格式的对接能力,涵盖了OpenTelemetry,SofaTracer,Skywalking,Zipkin以及Jaeger等等,用户应用无论之前是否已经接入了链路框架,都可以快速的接入并体验BOS分布式链路追踪系统的完整能力。
通过上述BOS分布式链路追踪产品提供的丰富功能,将赋予用户以下的宏观能力:
风险定位
在分布式场景下,服务调用错综复杂,并且涉及到众多中间件的调用,出现问题的时候如何排查和定位具体的问题应用和服务,如果依靠传统的单应用监控指标或者日志,必然要涉及整条调用链路所有相关应用指标的来回切换,费时费力非常困难。
通过BOS分布式链路跟踪产品能够帮助用户迅速定位到有问题的应用和服务,协助快速解决风险。
● 完整的应用调用拓扑关系:自动发现该服务的历史调用,以及对所有中间件的调用,绘制整个系统调用关系的拓扑图。
● 快速定位不健康应用:在调用关系拓扑中,对不健康应用进行显式标识,便于快速发现有问题应用并进行分析。
● 服务性能详情:调用拓扑中的应用都可以单独进行下钻分析,可以从吞吐量、错误率、响应时间等指标出发,对应用性能进行详细分析。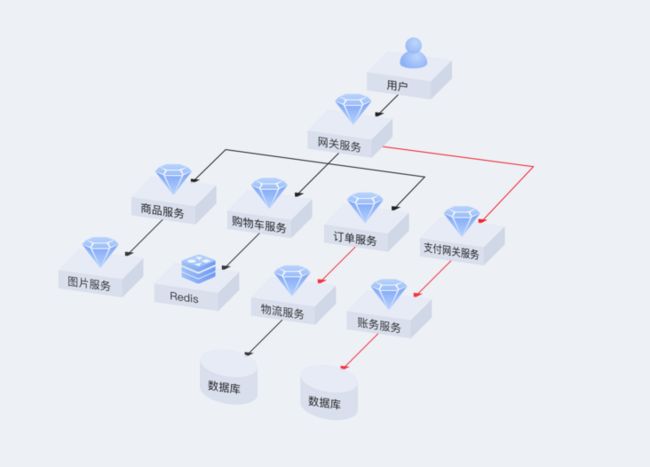
问题分析与快速定位示意图应用性能优化
BOS分布式链路产品通过应用调用拓扑和链路详情等分析能力,全方位的展示应用以及具体接口方法层面的性能数据,可以帮助用户快速定位到具体的单个造成性能瓶颈的调用所在或者是否存在不合理的调用关系,进而帮助用户进行应用的性能优化。
● 调用链路聚合汇总:对所有的调用信息进行聚合汇总,对各个应用的调用情况以及响应情况进行分析。
● 关键路径:快速发现整个系统调用拓扑中,关键应用的路径。
● 优化不合理调用:及时发现某些不合理的调用并进行处理,如频繁进行数据库操作等。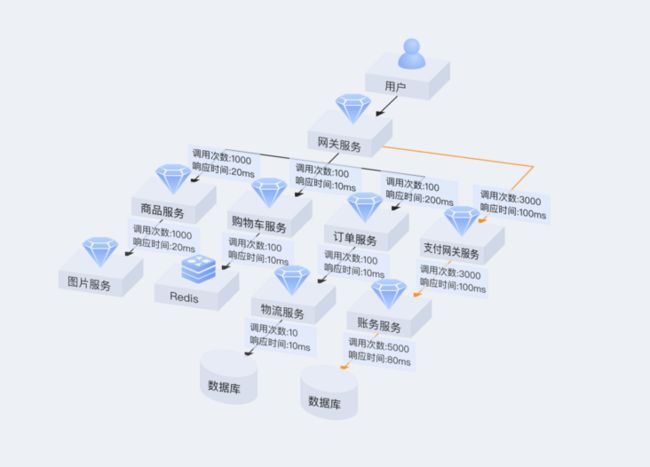
性能优化示意图使用场景
洞察微服务调用拓扑
在大规模的微服务系统中,完整的链路调用拓扑可以提供一个全局的视角,帮助发现不同应用之间的依赖关系,实时的以端到端的方式展示微服务应用架构。
此外针对应用开发者,也可以实时展示单个应用上下游调用关系的拓扑图。
通过如下的服务调用拓扑图,用户可以获得:
● 全链路信息展示:展示应用程序及其关联内部、外部服务系统的响应时间、吞吐量和状态,同时显示了各个服务之间的相互影响。如果一项服务中断,您可以立即看到其他服务所受到的影响。
● 后端服务性能管理:快速、持续地监控应用性能,第一时间发现定位应用问题。
● 实时运行状态:通过监控黄金指标(吞吐量,响应时间, 错误率)、可视化的应用的性能监控描述,快速了解每个应用的运行状态。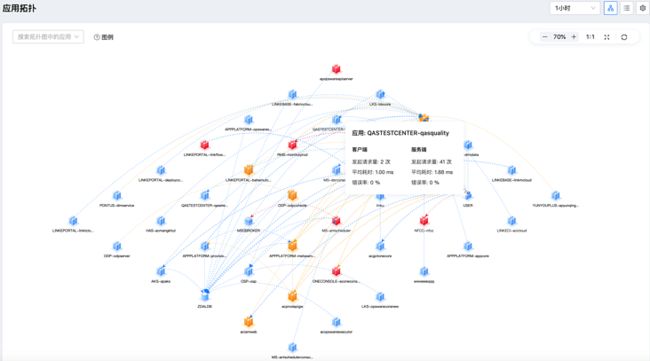
服务调用拓扑图更进一步,对于感兴趣的应用,可以查看具体的应用性能详情,了解应用在指定时间范围内的性能指标数据。具体的数据涵盖了HTTP调用、RPC调用、SQL调用、NoSQL调用、消息调用的黄金指标统计(比如吞吐量、平均响应耗时、错误率、满意度等)趋势和指标明细。
同时应用性能详情支持基于应用 > 上下游应用 > 接口等逐层下钻分析,建立从底层至上层间的数据关联信息,从而深度分析分布式场景下影响应用性能的问题根因。若发现某个接口调用异常,可跳转链路查询界面,按照相关参数查询链路。
服务调用拓扑-应用性能详情图定位异常调用与应用
服务调用的最关键的指标是 错误率 和 平均耗时,通过实时计算这两项指标,配合上可自定义的评判标准,可以生成上述服务调用拓扑图中部分呈现为黄色异常与红色错误状态的服务调用和应用自身。
应用评价标准
异常应用的评价是通过实时计算应用的平均接口耗时以及错误率实现的,用户可以配置阈值,一旦超过阈值,将分别呈现为黄色异常与红色错误状态。
调用评价标准
异常调用的评判采用的是Apdex标准,Apdex全称是Application Performance Index,是用于评估应用性能的开放标准,从用户的角度出发,将响应时间的表现转化为对应用性能的可量化满意度评价。
Apdex根据响应时间以及代表用户满意的响应时间界限T,定义了三种性能表现:
● 满意:响应时间小于 T。
● 可接受:响应时间介于 T 到 4T 之间。
● 不可接受: 响应时间大于 4T。
将一段时间的响应时间统计出来后,便可根据下述计算公式得出Apdex指数:
Apdex指数 = (满意数 + 0.5 * 可接受数)/ 总样本数 。
Apdex指数大于0.7的被认为拥有较为良好的性能,低于0.7将会被标红,提醒可能存在的性能问题。
应用性能调优
当排查到异常调用或者异常应用存在的时候,研发人员可以借助分布式链路追踪服务进行性能调优。
在应用性能分析过程中,对于技术研发来说,最为关键的指标是吞吐量、平均响应耗时、错误率。因此,分布式链路产品设计过程中,BOS 通过聚合链路数据,轻松展示服务调用明细,提供分钟级数据统计。如上述 服务调用拓扑-应用性能详情图 所示。
当发现平均响应耗时较高或者错误率较高请求时,通过点击明细最右边一栏的实时链路查询按钮,可以跳转到包含相关调用信息的链路查询页面,通过对耗时的排序,可以定位到耗时较高的单条链路。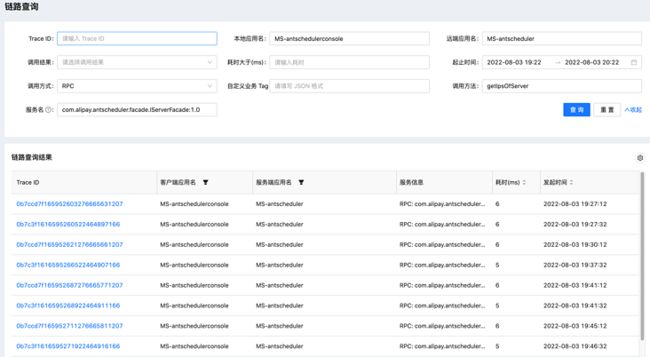
链路查询页面图进而通过点击感兴趣的调用链路,可以看到更为详细的调用树状图,单链路拓扑图以及时序图:
链路详情-树状图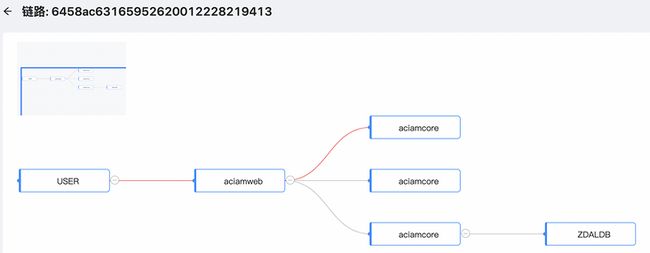
链路详情-拓扑图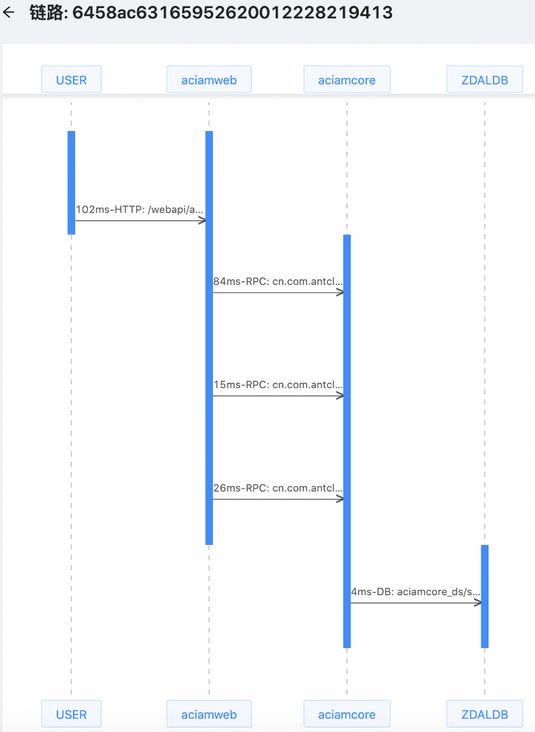
链路详情-时序图通过以上三种链路详情展示图,可以很方便的找到在整条链路中,哪些调用出现了失败的情况,哪些调用的耗时过长需要优化。
更进一步:
● 点击链路详情:可以看到更多链路的细节信息,并且可以查到相关联的业务日志和错误日志。
● 点击监控详情:可以跳转至BOS的应用监控页面,查到更为详细的应用监控指标,比如系统指标和JVM指标等。
通过链路、日志和监控的全方位信息,应用的研发人员可以很方便的发现问题和瓶颈所在,并加以优化,进入 性能优化->链路分析->性能优化 的正循环中,最终达到满意的性能结果。
应用接入
看到前面的链路分析使用场景,是不是已经很迫不及待要把应用接入到分布式链路追踪系统了?
别着急,接入的方法很多样,也很方便。
接入的核心就是如何为应用生成链路数据,并让分布式链路追踪系统采集到。
我们可以利用业内优秀的链路框架帮助应用进行链路改造,目前业内常用的链路框架有OpenTelemetry,SofaTracer,Skywalking,Zipkin与Jaeger等等,其中一些框架针对部分开发语言和部分中间件可以做到无侵入式的链路改造,还有一些场景需要通过相应的SDK进行链路能力的引入增强。
随后,BOS分布式链路追踪系统可以接收应用框架主动上报上来的链路数据,或者通过采集应用框架打印落盘的链路日志文件来收集链路数据。
以OpenTelemetry为例,Java应用只要接入一个探针,无需修改任何应用代码,即可自动生成链路数据,并通过RPC接口上报至BOS。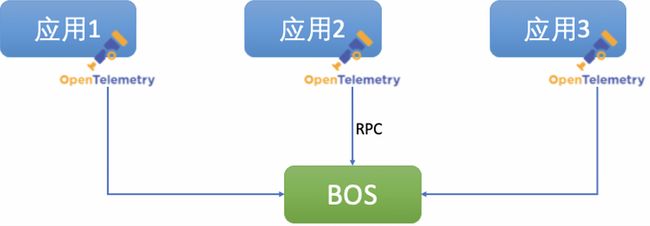
技术内幕
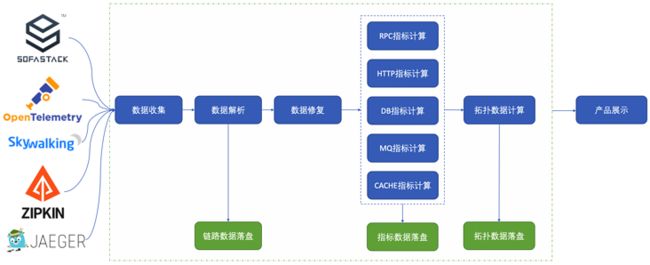
数据收集与解析
通过应用接入,BOS分布式链路追踪系统会根据接入方式的不同,分别用不同的方法来接受框架生成的原始链路数据,比如日志采集、RPC接收或者是HTTP协议接收等等。
然后不同原始链路数据的格式也各不相同,因此首先需要对这些原始数据按照不同的规则进行解析,解析后将构建出与框架无关的链路Span数据,这些数据将被保存至链路数据库中。
数据修复
接下来,需要对链路数据进行修复操作,这块修复的原因是,分布式链路数据是一种很特殊的数据类型,两个应用之间的一次调用实际上会产生两条链路数据,分别为客户端Span和服务端Span,而从单个应用的角度出发,应用的视角里不会很清楚的知道调用对端的详细信息,所以这两条链路数据通常情况下都会缺少部分对端的信息。
因此,分布式链路追踪系统会收集链路调用两端各自的Span,然后进行数据修复,借助双方各自的数据修复出调用的完整信息,为后续的指标和拓扑数据计算做准备。
指标计算
下一步,根据链路数据的不同调用类型(HTTP,RPC,SQL,NoSQL,消息等),分别进行相应的性能指标计算和聚合,并将相关指标信息存入时序性数据库中。
拓扑计算
接下来,由于之前已经经过了数据修复,从一个Span里可以同时获取到两端的应用信息,因此可以从应用拓扑的角度分别计算和保存两端的拓扑节点,以及这次调用代表的拓扑边的相关数据。
为了从更多的角度观测拓扑节点和拓扑边的细节:
● 在拓扑节点的服务指标计算过程中,会根据拓扑节点处在调用方还是服务方分别进行汇总统计。
● 在拓扑边的服务指标计算过程中,会根据调用类型的不同而分别进行汇总统计。
当拓扑节点和拓扑边的相关数据计算以后,会经过序列化最终存入相关的数据库之中。
产品展示
至此,链路分析所需要的所有数据都已经被解析落盘,当用户进行应用拓扑查询或者单条链路查询的时候,BOS分布式链路追踪系统会针对不同场景查询不同类型的数据,进行拓扑或者调用链的还原。其中:
● 应用拓扑:需要先将拓扑关系绘制出来,并根据拓扑查询时间范围,将拓扑节点、拓扑边的相关联指标数据进行一定程度的降采样,并为调用明细信息进行指标的合并计算。
● 链路详情:需要将一条链路所有的Span信息全部获取到,紧接着根据父子关系,兄弟关系等等进行调用链的精确还原。在实际应用过程中,经常还会遇到某些应用因为一些原因无法接入链路系统的情况,进而导致调用出现Span部分缺失的情况,这种时候 BOS 也会根据相关Span接入方式的不同,从链路框架的数据生成原理出发,尽可能的排除掉这些干扰,还原出完整的链路调用关系。
总结
最后,总结一下BOS分布式链路追踪产品的核心特性:
● 完全兼容业内常用的各种链路框架,方便业务以各种形式进行接入。
● 提供完整的应用调用拓扑关系,可以从全局的角度快速定位不健康的应用以及应用间调用。
● 从吞吐量、错误率、响应时间等指标出发,提供详细的应用性能分析。
● 提供丰富的链路查询功能,准确定位到感兴趣的链路。
● 对于单条链路,提供丰富的分析能力,通过树状图,拓扑图以及时序图帮助发现关键路径以及不合理和异常的调用。
● 通过链路、监控与日志的三位一体能力,提供完整的应用可观测能力,可以细化观察到某一次调用相关的所有可观测数据。
目前,BOS分布式链路追踪产品已经广泛应用在包括交通银行,中华财险,宁波银行,四川农信在内的多家机构,持续帮助用户发现和解决应用故障以及性能问题。
后续我们会持续分享分布式链路追踪能力持续演进过程中的落地与思考,欢迎大家提出任何意见与建议。