01 背景介绍
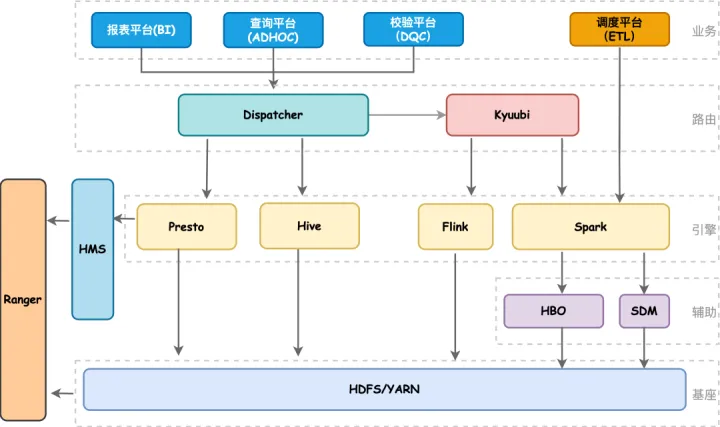
近几年随着B站业务高速发展,数据量不断增加,离线计算集群规模从最初的两百台发展到目前近万台,从单机房发展到多机房架构。在离线计算引擎上目前我们主要使用Spark、Presto、Hive。架构图如下所示,我们的BI、ADHOC以及DQC服务都是通过自研的Dispatcher路由服务来实现统一SQL调度,Dispatcher会结合查询SQL语法特征、读HDFS量以及当前引擎的负载情况,动态地选择当前最佳计算引擎执行任务。如果用户SQL失败了会做引擎自动降级,降低用户使用门槛;其中对于Spark查询早期我们都是走STS,但是STS本身有很多性能和可用性上的问题,因此我们引入了Kyuubi,通过Kyuubi提供的多租户、多引擎代理以及完全兼容Hive Thrift协议能力,实现各个部门Adhoc任务的资源隔离和权限验证。
Query查询情况
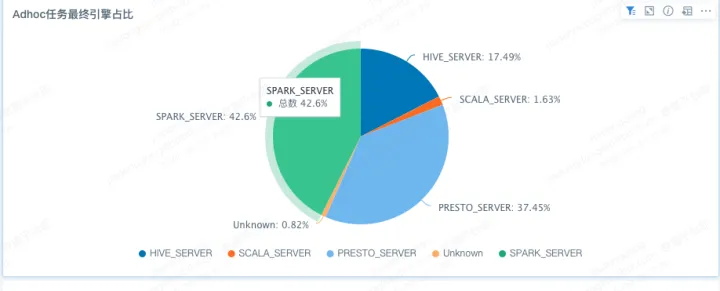
目前在Adhoc查询场景下,SparkSQL占比接近一半,依赖Kyuubi对于Scala语法的支持,目前已经有部分高级用户使用scala语法提交语句执行,并且可以在SQL和Scala模式做自由切换,这大大丰富了adhoc的使用场景。
02 Kyuubi应用
Kyuubi 是网易数帆大数据团队贡献给 Apache 社区的开源项目。Kyuubi 主要应用在大数据领域场景,包括大数据离线计算、adhoc、BI等方向。Kyuubi 是一个分布式、支持多用户、兼容 JDBC 或 ODBC 的大数据处理服务。
为目前热门的计算引擎(例如Spark、Presto或Flink等)提供SQL等查询服务。
我们选择Kyuubi的原因:
1. 完全兼容Hive thrift 协议,符合B站已有的技术选型。
2. 高可用和资源隔离,对于大规模的生产环境必不可少。
3. 灵活可扩展,基于kyuubi可以做更多适配性开发。
4. 支持多引擎代理,为未来统一计算入口打下基础。
5. 社区高质量实现以及社区活跃。
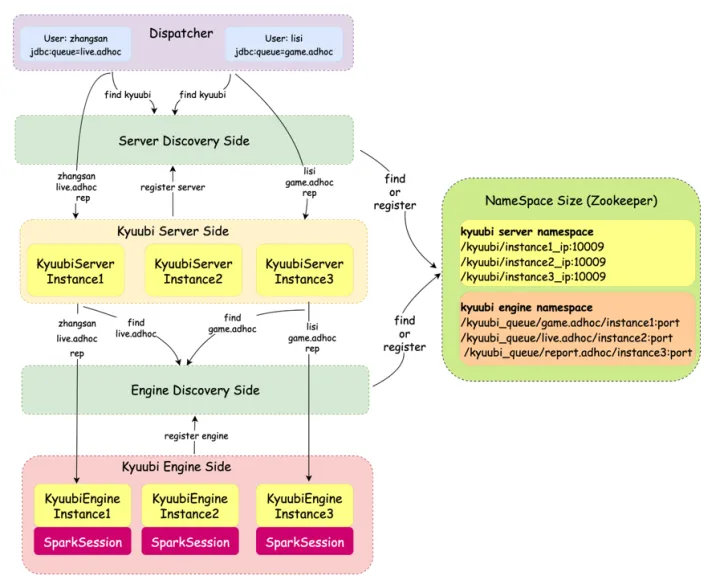
Kyuubi 的架构可以分成三个部分:
1.客户端: 用户使用jdbc或者restful协议来提交作业获取结果。
2.kyuubi server: 接收、管理和调度与客户端建立的Kyuubi Session,Kyuubi Session最终被路由到实际的引擎执行。
3.kyuubi engine: 接受处理 kyuubi server发送过来的任务,不同engine有着不同的实现方式。

03 基于Kyuubi的改进
Kyuubi已经在B站生产环境稳定运行一年以上,目前所有的Adhoc查询都通过kyuubi来接入大数据计算引擎。 在这一年中我们经历了两次大版本的演进过程,从最初kyuubi 1.3到kyuubi 1.4版本,再从kyuubi 1.4升级kyuubi 1.6版本。与之前的STS相比,kyuubi在稳定性和查询性能方面有着更好的表现。在此演进过程中,我们结合B站业务以及kyuubi功能特点,对kyuubi进行部分改造。
3.1 增加QUEUE模式
Kyuubi Engine原生提供了CONNECTION、USER、GROUP和SERVER多种隔离级别。在B站大数据计算资源容量按照部门划分,不同部门在Yarn上对应不同的队列。我们基于GROUP模式进行了改造,实现Queue级别的资源隔离和权限控制。
用户信息和队列的映射由上层工具平台统一配置和管理,Kyuubi只需关心上游Dispatcher提交过来user和queue信息,进行调度并分发到对应队列的spark engine上进行计算。目前我们有20+个adhoc队列,每个队列都对应一个或者多个Engine实例(Engine pool)。
3.2 在QUEUE模式下支持多租户
kyuubi server端由超级用户Hive启动,在spark场景下driver和executor共享同一个的用户名。不同的用户提交不同的sql, driver端和executor端无法区分当前的任务是由谁提交的,在数据安全、资源申请和权限访问控制方面都存在着问题。
针对该问题,我们对以下几个方面进行了改造。
3.2.1 kyuubi server端
1. kyuubi server以hive principal身份启动。
2. Dispatcher以username proxyUser身份提交SQL。
3.2.2 spark engine端
1. Driver和Executor以hive身份启动。
2. Driver以username proxyUser身份提交SQL。
3. Executor启动Task线程需要以username proxyUser身份执行Task。
4. 同时需要保证所有的公共线程池,绑定的UGI信息正确。如ORC Split线程池上,当Orc文件达到一定数量会启用线程池进行split计算,线程池是全局共享,永久绑定的是第一次触发调用的用户UGI信息,会导致用户UGI信息错乱。

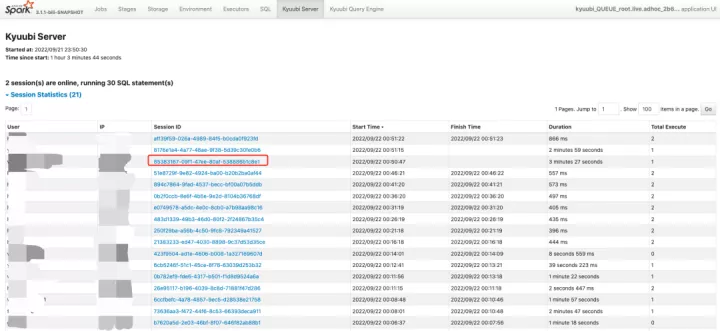
3.3 kyuubi engine UI 展示功能
在日常使用中我们发现 kyuubi 1.3 Engine UI页面展示不够友好。不同的用户执行不同的SQL无法区分的开,session 、job、stage、task无法关联的起来。
导致排查定位用户问题比较困难,我们借鉴STS拓展了kyuubi Engine UI页面。我们对以下几个方面进行了改造。
1. 自定义kyuubi Listener监听Spark Job、Stage、Task相关事件以及SparkSQL相关事件:SessionCreate、SessionClose、executionStart、executionRunning、executionEnd等
2. Engine执行SQL相关操作时,绑定并发送相关SQL Event,构造SQL相关状态事件,将采集的Event进行状态分析、汇总以及存储。
3. 自定义Kyuubi Page进行Session以及SQL相关状态实时展示。
Session Statistics信息展示
SQL Statistics信息展示

3.4 kyuubi支持配置中心加载Engine参数
为了解决队列之间计算资源需求的差异性,如任务量大的队列需要更多计算资源(Memory、Cores),任务量小的队列需要少量资源,每个队列需求的差异,我们将所有队列的Engine相关资源参数统一到配置中心管理。每个队列第一次启动Engine前,将查询自己所属队列的参数并追加到启动命令中,进行参数的覆盖。

3.5 Engine执行任务的进度显示与消耗资源上报功能
任务在执行过程中,用户最关心的就是自己任务的进度以及健康状况,平台比较关心的是任务所消耗的计算资源成本。我们在Engine端,基于事件采集user、session、job、stage信息并进行存储,启动定时任务将收集的user、session、job、stage信息进行关联并进行资源消耗成本计算,并将结果注入对应operation log中, 回传给前端日志展示。
任务进度信息展示

查询消耗资源上报展示

04 Kyuubi稳定性建设
4.1 大结果集溢写到磁盘
在adhoc 场景中用户通常会拉取大量结果到 driver 中,同一时间大量的用户同时拉取结果集,会造成大量的内存消耗,导致spark engine内存紧张,driver性能下降问题,直接影响着用户的查询体验,为此专门优化了driver fetch result 的过程,在获取结果时会实时监测driver内存使用情况,当driver内存使用量超过阈值后会先将拉取到的结果直接写出到本地磁盘文件中,在用户请求结果时再从文件中分批读出返回,增加driver的稳定性。

4.2 单个 SQL 的task并发数、执行时间和 task 数量的限制
在生产过程中,我们经常性的遇到单个大作业直接占用了整个Engine的全部计算资源,导致短作业长时间得不到计算资源,一直 pending的情况,为了解决这种问题我们对以下几个方面进行优化。
- Task并发数方面:默认情况下Task调度时只要有资源就会全部调度分配出去,后续SQL过来就面临着完全无资源可用的情况,我们对单个SQL参与调度的task数进行了限制,具体的限制数随着可用资源大小进行动态调整。
- 单个 SQL 执行时间方面:上层Dispatcher和下层Engine都做了超时限制,规定adhoc任务超过1小时,就会将该任务kill掉。
- 单个Stage task数量方面:同时我们也对单个stage的task数进行限制,一个stage最大允许30W个task。
4.3 单次 table scan 的文件数和大小的限制
为保障kyuubi的稳定性,我们对查询数据量过大的SQL进行限制。通过自定义外部optimization rule(TableScanLimit)来达到目的。TableScanLimit匹配LocalLimit,收集子节点project、filter。匹配叶子结点HiveTableRelation和HadoopFsRelation。即匹配Hive表和DataSource表的Logical relation,针对不同的表采取不同的计算方式。
1. HiveTableRelation:
- 非分区表, 通过table meta 拿到表的totalSize、numFiles、numRows值。
- 分区表,判断是否有下推下来的分区。若有,则拿对应分区的数据 totalSize、numFiles、numRows。若没有,则拿全表的数据。
2. HadoopFsRelation:判断partitionFilter是否存在动态filter
- 不存在,则通过partitionFilter得到需要扫描的分区
- 存在,则对partitionFilter扫描出来的分区进一步过滤得到最终需要扫描的分区

获取到SQL查询的dataSize、numFiles、numRows后, 还需要根据表存储类型、不同字段的类型、是否存在limit、在根据下推来的project、filter 得出最终需要扫描的列,估算出需要table scan size,如果table scan size超过制定阈值则拒绝查询并告知原因。
4.4 危险join condition发现&Join膨胀率的限制
4.4.1 危险join condition发现
为保障kyuubi的稳定性,我们也对影响Engine性能的SQL进行限制。用户在写sql时可能并不了解spark对于join的底层实现,可能会导致程序运行的非常慢甚至OOM,这个时候如果可以为用户提供哪些join condition可能是导致engine运行慢的原因,并提醒用户改进和方便定位问题,甚至可以拒绝这些危险的query提交。
在选择 join 方式的时候如果是等值 join 则按照 BHJ,SHJ,SMJ 的顺序选择,如果还没有选择join type则判定为 Cartesian Join,如果 join 类型是InnerType的就使用 Cartesian Join,Cartesian Join会产生笛卡尔积比较慢,如果不是 InnerType,则使用 BNLJ,在判断 BHJ 时,表的大小就超过了broadcast 阈值,因此将表broadcast出去可能会对driver内存造成压力,性能比较差甚至可能会 OOM,因此将这两种 join 类型定义为危险 join。
如果是非等值 join 则只能使用 BNLJ 或者 Cartesian Join,如果在第一次 BNLJ 时选不出 build side 说明两个表的大小都超过了broadcast阈值,则使用Cartesian Join,如果Join Type不是 InnerType 则只能使用 BNLJ,因此Join策略中选择Cartesian Join和第二次选择 BNLJ 时为危险 join。

4.4.2 Join膨胀率的限制
在shareState 中的 statusScheduler 用于收集 Execution 的状态和指标,这其中的指标就是按照 nodes 汇总了各个 task 汇报上来的 metrics,我们启动了一个 join检测的线程定时的监控 Join 节点的 "number of output rows"及Join 的2个父节点的 "number of output rows" 算出该 Join 节点的膨胀率。
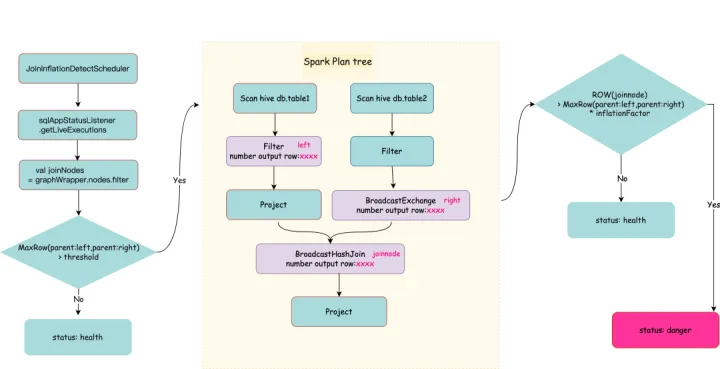
Join 节点的膨胀检测:

05 kyuubi 新应用场景
5.1 大查询connection&scala模式的使用
5.1.1 connection模式的使用
adhoc大任务和复杂的SQL会导致kyuubi engine在一定时间内性能下降,严重影响了其他正常的adhoc任务的执行效率。我们在adhoc前端开放了大查询模式,让这些复杂、查询量大的任务走kyuubi connection模式。在kyuubi connection模式下一个用户任务单独享有自己申请的资源,独立的Driver,任务的大小快慢都由自身的SQL特征决定,不会影响到其他用户的SQL任务,同时我们也会适当放开前面一些限制条件。
connection 模式在B站的使用场景:
- table scan判定该adhoc任务为大任务,执行时间超过1个小时。
- 复杂的SQL任务, 该任务存在笛卡尔积或Join膨胀超过阈值。
- 单个SQL单个stage的task数超过30W。
- 用户自行选择connection模式。

5.1.2 scala模式的使用
SQL模式可以解决大数据80%的业务问题,SQL模式加上Scala模式编程可以解决99%的业务问题;SQL是一种非常用户友好的语言,用户不用了解Spark内部的原理,就可以使用SQL进行复杂的数据处理,但是它也有一定的局限性。
SQL模式不够灵活,无法以dataset以及rdd两种方式进行数据处理操作。无法处理更加复杂的业务,特别是非数据处理相关的需求。另一方面,用户执行scala code项目时必须打包项目并提交到计算集群,如果code出错了就需来回打包上传,非常的耗时。
Scala模式可以直接提交code,类似Spark交互式Shell,简化流程。针对这些问题, 我们将SQL模式、Scala模式的优点结合起来,两者进行混合编程,这样基本上可以解决数据分析场景下大部分的case。
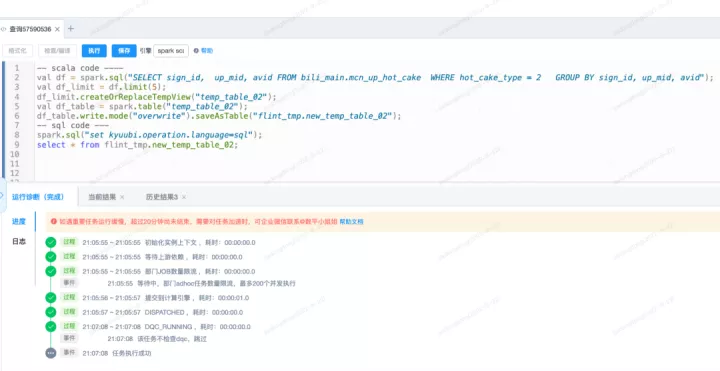
5.2 Presto on spark
Presto为了保证集群的稳定性,每个Query的最大内存进行了限制,超过配置内存的Query会被Presto oom kill掉。部分ETL任务会出现随着业务增长,数据量增大,占用内存也会增多,当超过阈值后,流程就会出现失败。
为了解决这个问题,prestodb社区开发了一个presto on spark的项目,通过将query提交到Spark来解决query的内存占用过大导致的扩张性问题,但是社区方案对于已经存在的查询并不是很友好,用户的提交方式有presto-cli、pyhive等方式,而要使用Presto on spark项目,则必须通过spark-submit方式将query提交到yarn。
为了让用户无感知的执行presto on spark查询,我们在presto gateway上做了一些改造,同时借助kyuubi restulful的接口,和service + engine的调度能力,在kyuubi内开发了Presto-Spark Engine,该engine能够比较友好的来提交查询到Yarn。

主要实现细节如下:
1. presto gateway将query的执行历史进行保存,包括query的资源使用情况、报错信息等。
2. presto gateway请求HBO服务,判断当前query是否需要通过presto on spark提交查询。
3. presto gateway通过zk获取可用的kyuubi server列表,随机选择一台,通过http向kyuubi open一个session。
4. presto gateway根据获取到的sessionHandle信息,再提交语句。
5. kyuubi server接收到query后,会启动一个独立的Presto-Spark Engine,构建启动命令,执行命令提交spark-submit 到yarn。
6. Presto gateway根据返回的OperatorHandle信息, 通过http不断获取operation status。
7. 作业成功,则通过fetch result请求将结果获取并返回给客户端。
06 kyuubi部署方式
6.1 Kyuubi server接入K8S
整合 Engine on yarn label的实践
生产实践中遇到的问题:
1.目前kyuubi server/engine部署在混部集群上,环境复杂,各组件环境相互依赖、发布过程中难免会存在环境不一致、误操作等问题,从而导致服务运行出错。
2.资源管理问题。最初engine使用的是client模式,不同的队列的engine driver使用的都是大内存50g-100g不等 ,同时AM、NM 、DN、kyuubi server都共享着同一台物理机器上的资源,当AM启动过多, 占满整个机器的资源,导致机器内存不足,engine无法启动。
针对于该问题,我们研发了一套基于Queue模式资源分配调度实现:每个kyuubi server 和 spark engine在znode上都记录着当前资源使用情况。每个kyuubi server znode信息:当前kyuubi注册SparkEngine数量、当前kyuubi server注册SparkEngine实例、kyuubi server内存总大小以及当前kyuubi server剩余内存总大小等。
每个engine znode信息:所属kyuubi server IP/端口、当前SparkEngine内存、当前SparkEngine所属队列等 。每次Spark engine的启动/退出,都会获取该队列的目录锁,然后对其所属的kyuubi server进行资源更新操作。kyuubi server如果宕机,在启动时,遍历获取所有engine在znode的信息,进行资源和状态的快速恢复。
3.针对资源管理功能也存在着一些问题: 资源碎片化问题、新功能的拓展不友好以及维护成本大。Engine使用的是client模式,过多大内存的AM会占用客户端的过多计算资源,导致engine水平拓展受限。
针对以上提出的问题,我们做了对应的解决方案:
1. kyuubi server接入k8s
我们指定了一批机器作为kyuubi server在k8s上调度资源池,实现kyuubi server环境、资源的隔离。实现了kyuubi server快速部署、提高kyuubi server水平扩展能力,降低了运维成本。
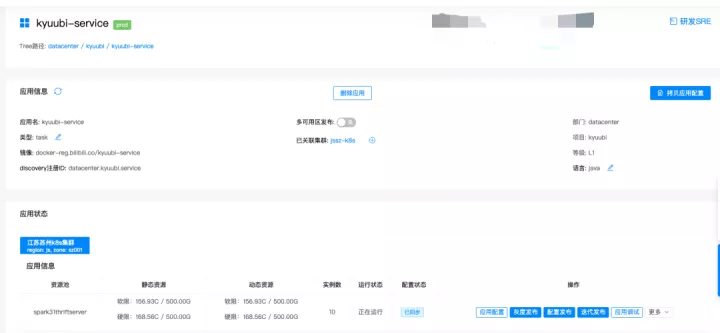

2. Engine on yarn label
我们将kyuubi engine资源管理交给yarn,由yarn负责engine的分配和调度。我们采用了cluster模式以防engine在水平拓展时受到资源限制。采用cluster模式后,我们遇到了新的问题:在queue模式下engine driver使用的都是50g-100g不等的大内存,但是由于yarn集群的配置限制,能够申请的最大Container资源量为<28G, 10vCore>。为了在cluster模式的情况下保证Driver能够获取到足够的资源,我们改造了yarn以适应此类场景。我们将需求拆分为以下三项:
- 将kyuubi Driver放置于独立的Node Label中,该Node Label中的服务器由kyuubi driver独立使用;
- kyuubi Executor仍然放置在Default Label的各对应队列的adhoc叶子队列内,承接adhoc任务处理工作;
- Driver申请的资源需要大于MaxAllocation,即上文所述的<28G, 10vCore>。希望能够根据Node Label动态设置Queue级别的MaxAllocation,使得kyuubi Driver能够获得较大资源量。
首先,我们在yarn上建立了kyuubi\_label,并在label内与Default Label映射建立kyuubi队列,以供所有的Driver统一提交在kyuubi队列上。并通过“spark.yarn.am.nodeLabelExpression=kyuubi\_label”指定Driver提交至kyuubi_label,通过“spark.yarn.executor.nodeLabelExpression= ”指定Executor提交至default label,实现如下的效果:

其次,我们将yarn的资源最大值由原先的“集群”级别管控下放至“队列+Label”级别管控,通过调整"queue name + kyuubi_label"的Conf,我们能够将Driver的Container资源量最大值提高至<200G, 72vCore>,且保证其他Container的最大值仍为<28G, 10vCore>。同样申请50G的Driver,在default集群中会出现失败提示:

而在kyuubi_lable的同队列下则能够成功运行, 这样我们既借助了yarn的资源管控能力,又保证了kyuubi driver获得的资源量。
07 未来规划
1. 小的ETL任务接入kyuubi,减少ETL任务资源申请时间
2. Kyuubi Engine(Spark和Flink)云原生,接入K8S统一调度
3. Spark jar 任务也统一接入Kyuubi
以上是今天的分享内容,如果你有什么想法或疑问,欢迎大家在留言区与我们互动,如果喜欢本期内容的话,请给我们点个赞吧!
